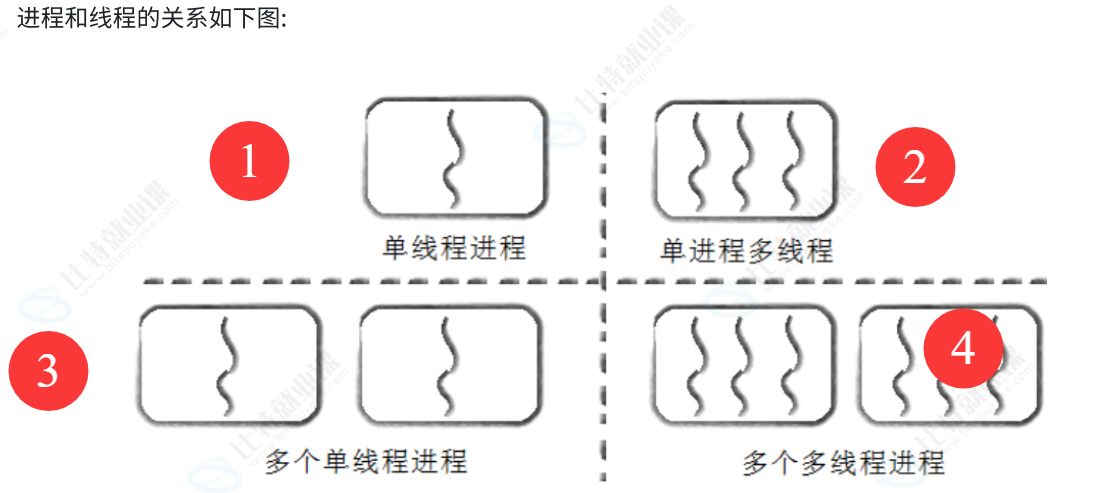
线程作为 Linux 系统中轻量级进程的本质存在,其资源特性核心围绕 "共享进程绝大部分资源,仅保留少量独立私有资源" 展开,这也是线程相比进程更轻量、创建与上下文切换开销更低的根本原因,而进程的独立性则对应着较高的进程间通信成本,线程的资源设计恰好解决了这一核心痛点。
从资源归属来看,进程是 Linux 系统中资源分配的基本单位,线程作为资源调度的基本单位 ,无法脱离进程独立存在,必须依托进程的虚拟地址空间、页表、文件描述符表、信号处理表、全局数据段、堆内存等核心资源,所有线程共享所属进程的这部分资源,因此线程之间无需通过复杂的进程间通信(IPC)机制就能直接访问同一块内存、打开的文件等,极大降低了数据交互的成本。
而线程独有的不可共享的私有资源, 是支撑其作为独立执行流的基础,具体包括:一是线程 ID ,用于区分同一进程内的不同轻量级进程,是线程在进程内的唯一标识;二是一组寄存器与线程上下文数据 ,这是线程调度的核心依赖,当 CPU 切换线程执行时,需保存和恢复这些寄存器的值,保证每个线程的执行状态不被破坏;三是栈结构 ,线程拥有独立的栈空间,用于存储函数调用、局部变量、返回地址等,压栈、出栈等栈操作均在各自的栈空间中完成,避免线程间栈数据互相干扰;四是errno ,每个线程都有独立的 errno 变量,确保线程调用系统函数出错时,能准确获取自身的错误码,不会出现多线程下错误码覆盖的问题;五是信号屏蔽字 ,线程可独立屏蔽指定信号,不影响进程内其他线程和整个进程的信号处理逻辑;六是调度优先级,线程可拥有独立的调度优先级,操作系统根据优先级对线程进行调度,保证不同线程的执行策略差异化。
除上述私有资源外,线程的其余资源均与进程共享,包括进程的虚拟地址空间、页表、文件描述符、信号处理方式、全局变量、堆内存等,这种 "大部分共享、少量私有" 的资源设计,既实现了线程之间的高效数据交互,又通过独立的私有资源保障了线程的独立调度与执行,完美契合了 Linux "一切皆轻量级进程" 的线程实现逻辑。
进程不等于主线程,二者是包含关系:进程是资源分配的基本单位,拥有完整的虚拟地址空间、页表、文件描述符等所有系统资源;主线程是进程创建时自动生成的第一个执行流,是 CPU 调度的基本单位,和进程内其他子线程共享进程的绝大部分资源,仅保留线程 ID、寄存器上下文、独立栈等私有资源。主线程是进程的核心执行入口,主线程退出则整个进程随之终止,进程必须依托主线程等执行流才能运行,二者不可等同。
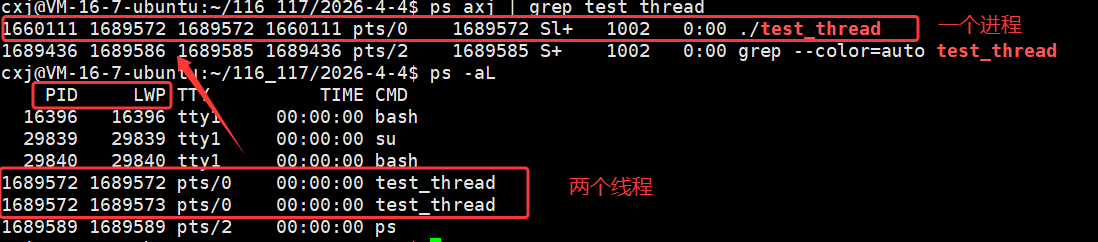
我们在上一篇文章中讲过,从用户视角与内核视角的分别来看,pthread_t 类型的线程 ID(tid)与内核的 LWP 轻量级进程 ID 属于不同层级、不同用途,但高度统一的标识体系:用户态只关心线程的逻辑执行流,因此 tid 是用户视角下用于识别、管理线程的唯一标识,是pthread库为用户封装的, **服务于线程库与应用程序;而 Linux 内核并不直接识别 "线程",只调度作为内核执行实体的轻量级进程(LWP),因此轻量级进程 LWP 是内核视角下用于调度、管理、分配资源的唯一标识。**二者虽然分属用户态与内核态两个不同层面,却一一对应、高度统一,每一个用户态线程都唯一绑定一个内核 LWP,共同构成 Linux 上线程 "用户看线程、内核看轻量级进程 LWP" 的完整运行模型。
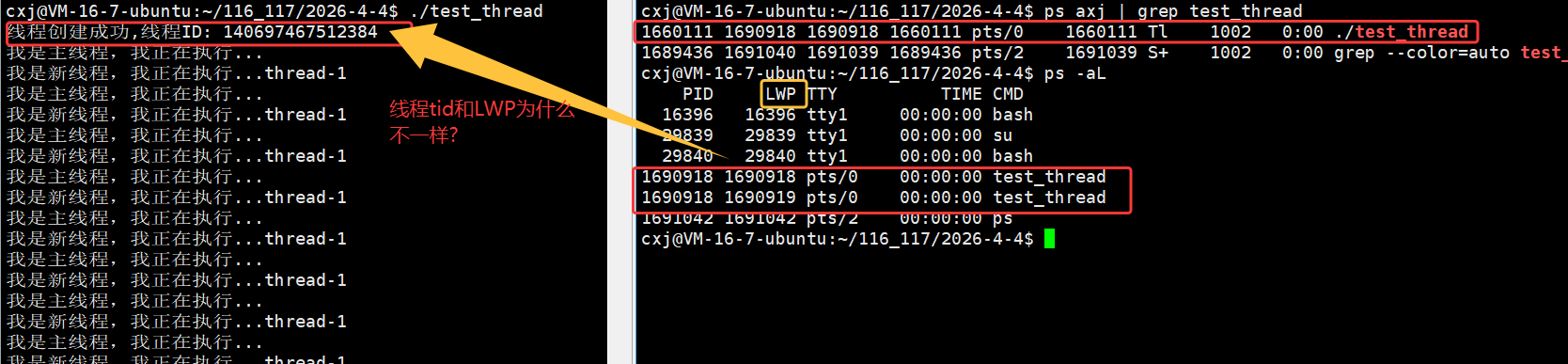
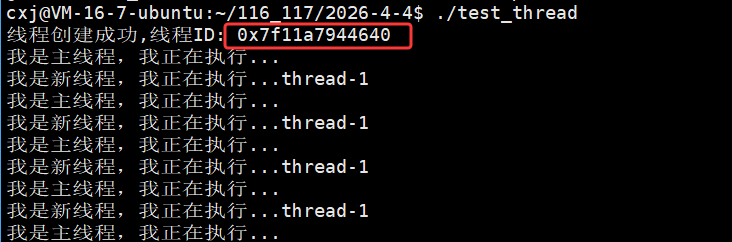
我们再继续以16进制的形式打印出这个 tid :
是一个非常大的数字,这个tid其实是一个地址,具体是什么地址我们后面再介绍
那我们怎么保证这个 tid 就是我们每次创建出的新线程的 id 呢?
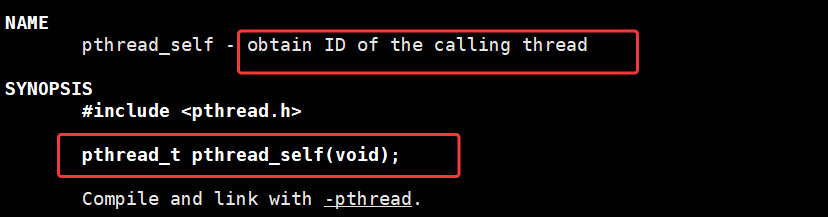
下面我们再来介绍一个函数 pthread_self
pthread_self
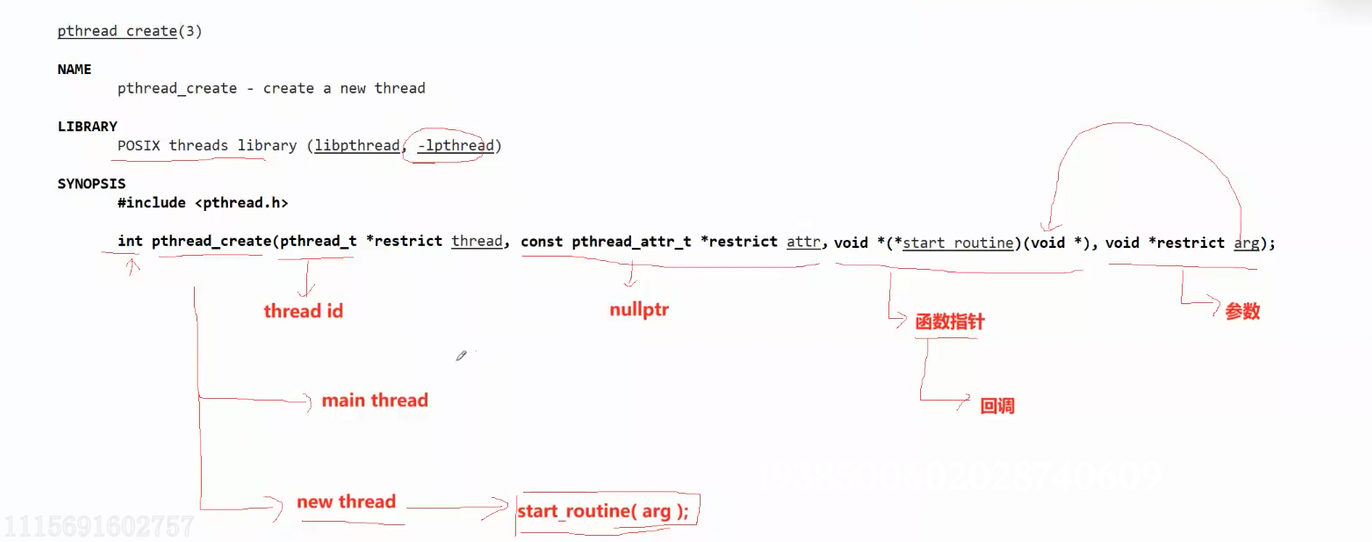
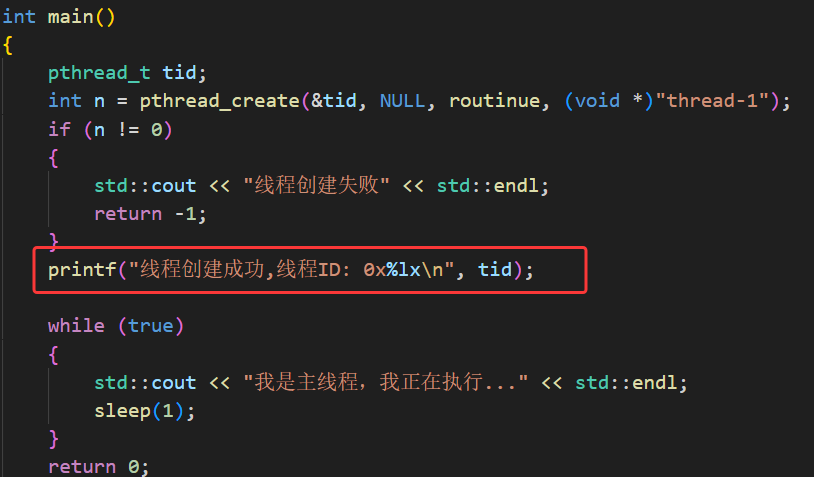
pthread_self() 用于获取调用线程自身用户态 ID 的核心函数,返回值为调用该函数的线程对应的 pthread_t 类型用户态线程 ID。该函数的核心作用是解决 pthread_create 传参可能存在的时序与标识一致性问题:主线程通过 pthread_create 输出参数获取的新线程 ID ,是主线程视角的标识,而新线程内部可通过 pthread_self() 直接获取自身唯一的用户态线程 ID,确保线程在任何执行阶段都能精准识别自身。
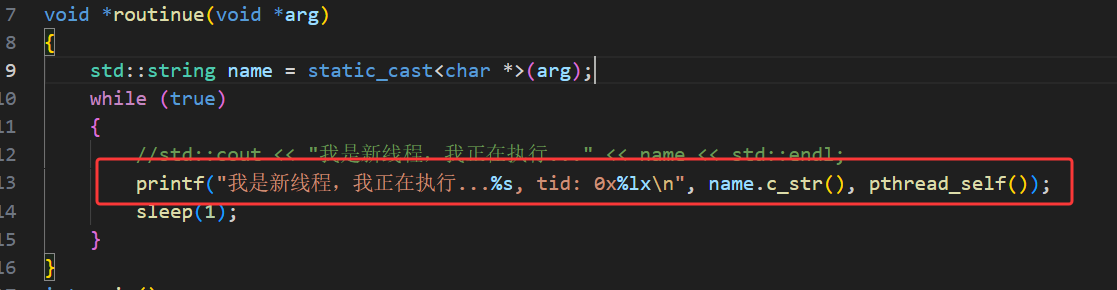
下面我们在线程调用函数中改一下并用 pthread_self 打印出线程的 tid:
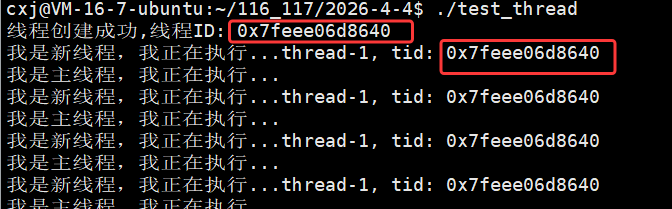
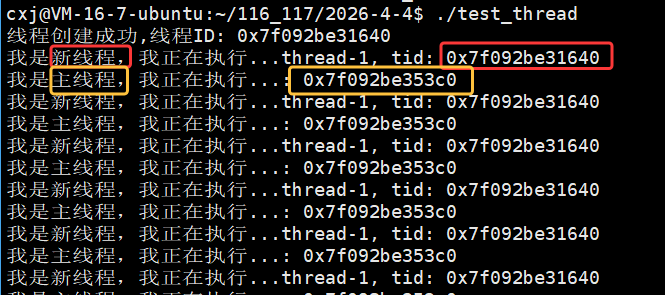
所以就可以证明我们在主线程中打印出新线程自己的 tid 和新线程自己用 ptherad_self 打印出来的tid是一样的,也就是说主线程创建新线程,主线程也能拿到新线程的tid。
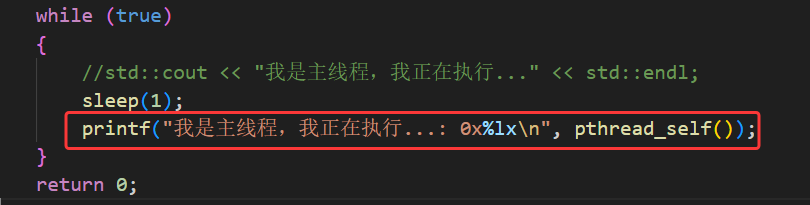
那我们也可以在主线程的while循环中用 pthread_self 打印出主线程自己的 tid :
此时我们就可以看出,主线程和新线程各自都有自己的 tid。
那我们又如何证明这两个线程属于同一个进程的呢?
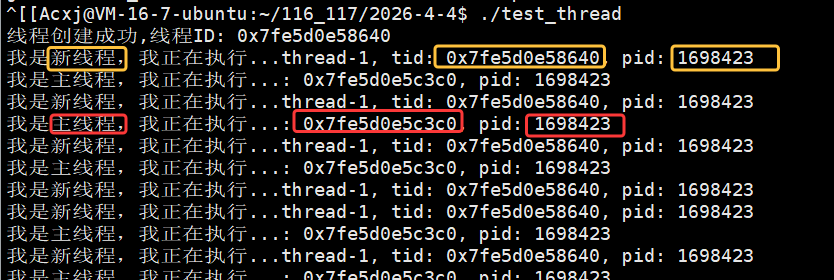
所以我们可以分别在主线程和新线程各自的循环中用 getpid() 打印进程的pid 观察:
pid一样,证明了这两个线程属于同一个进程,所以在用户角度就可以看到一个进程内部存在了两个线程。
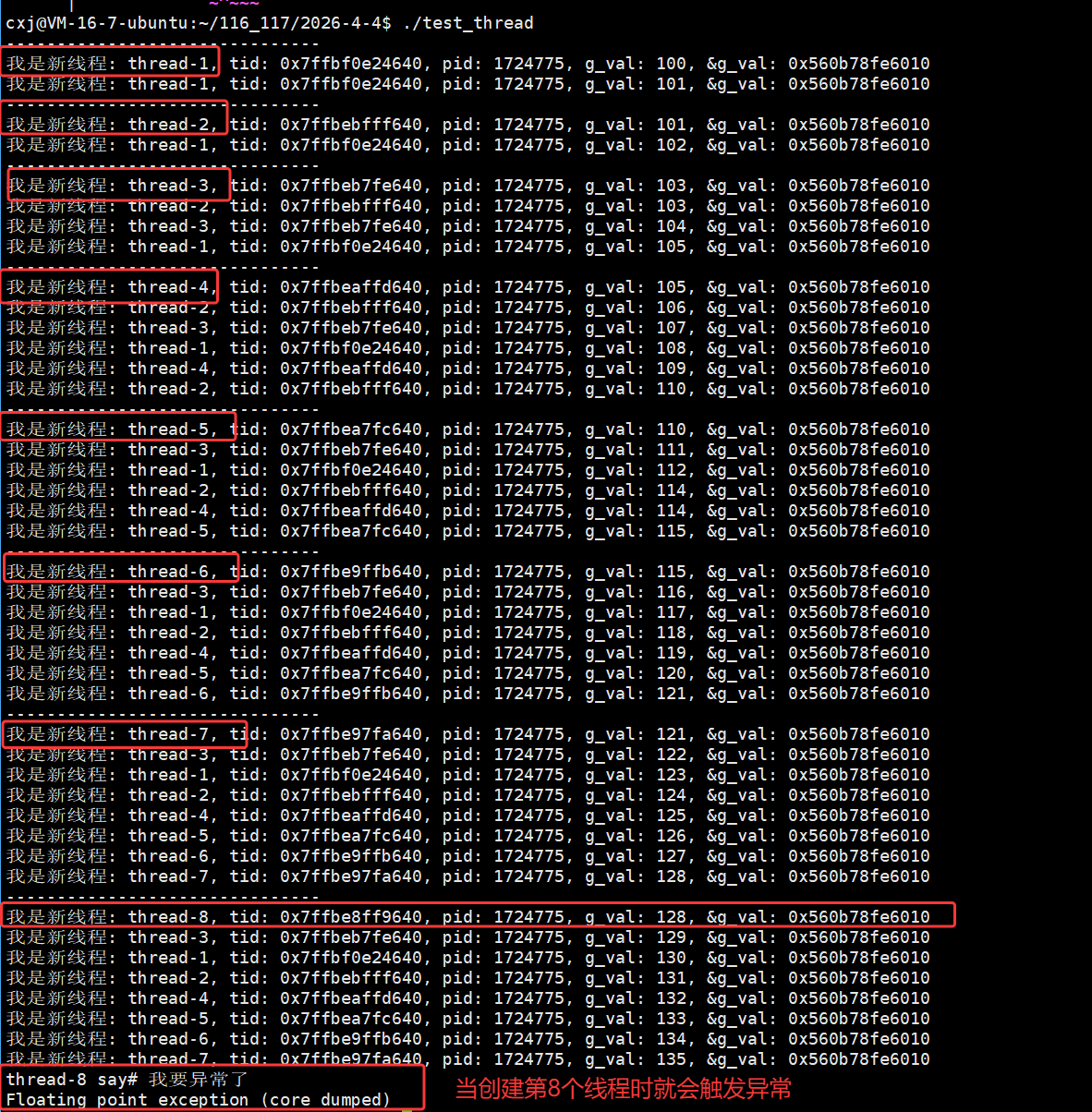
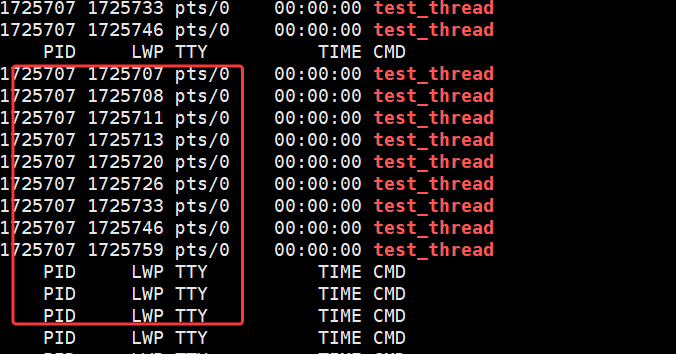
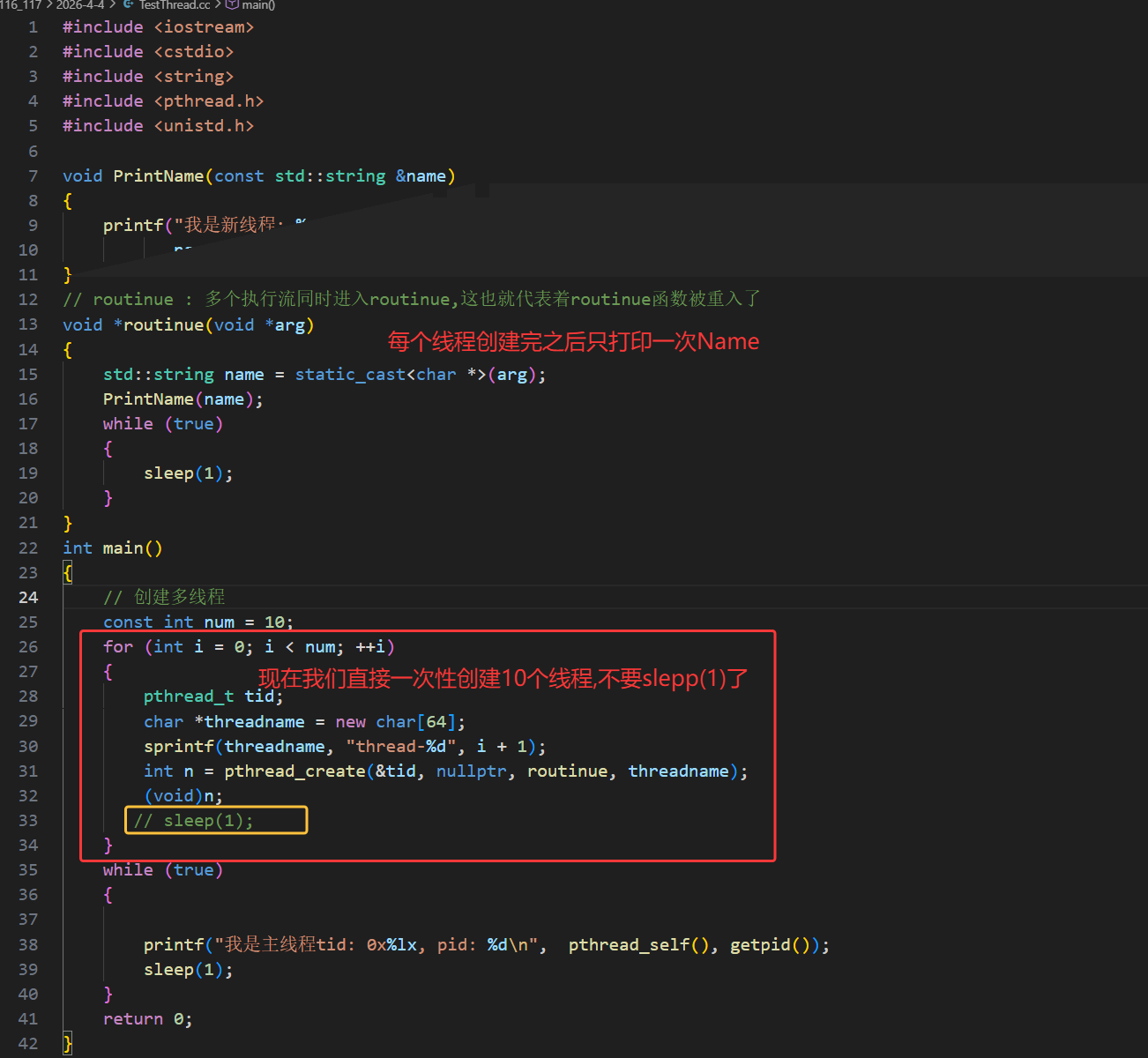
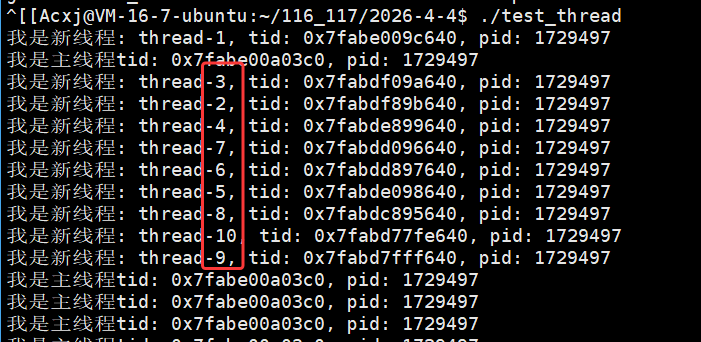
四、创建多线程
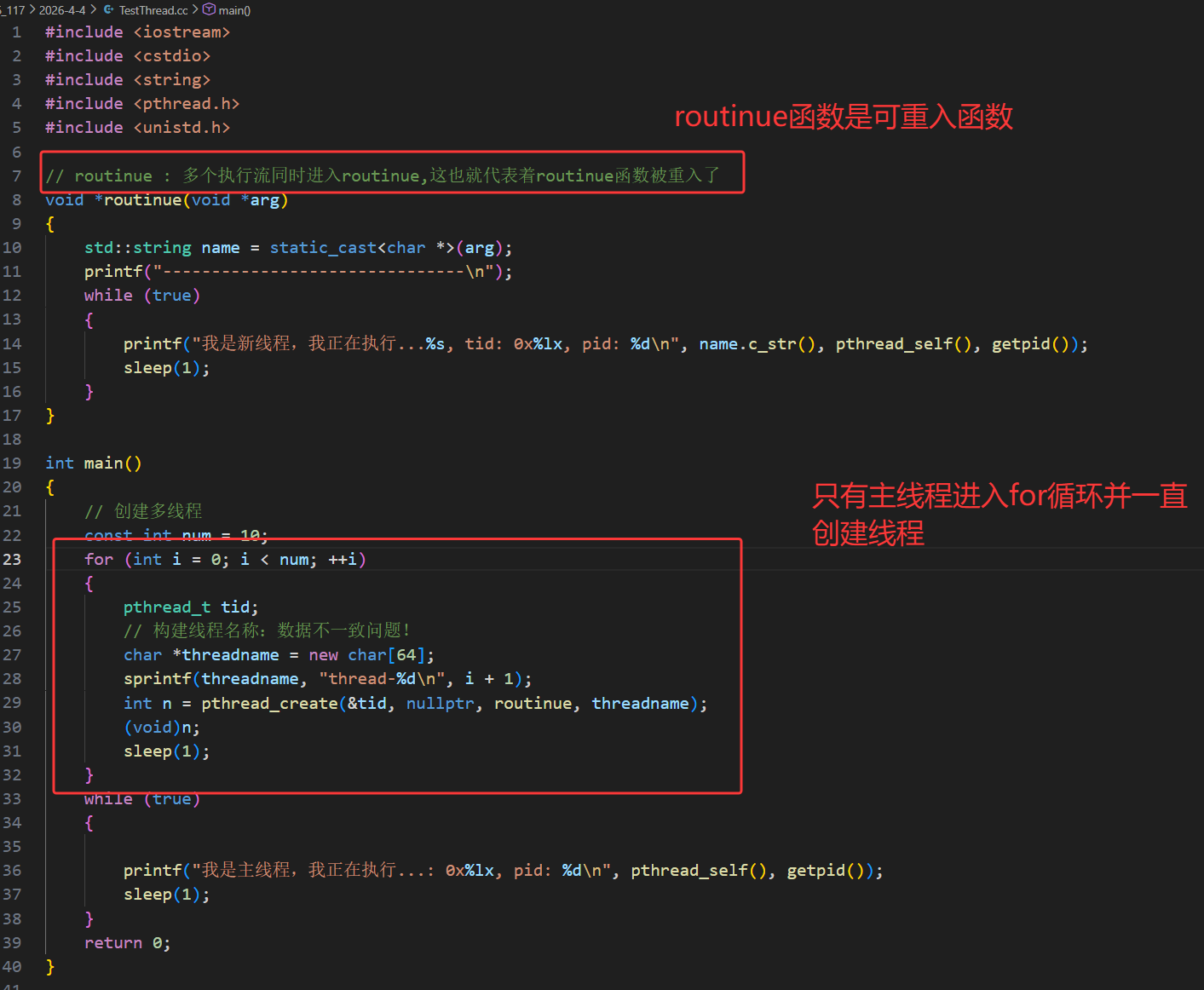
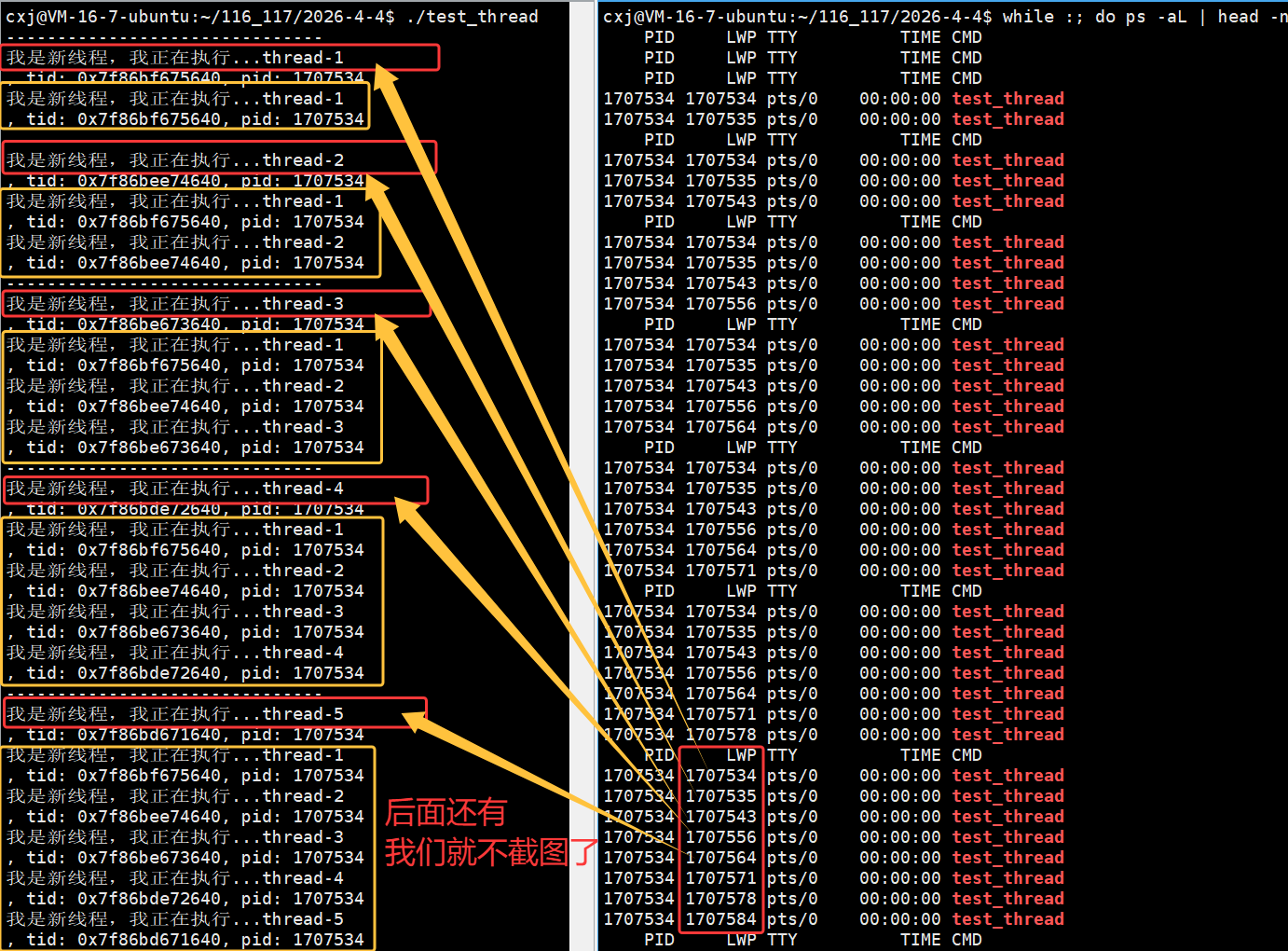
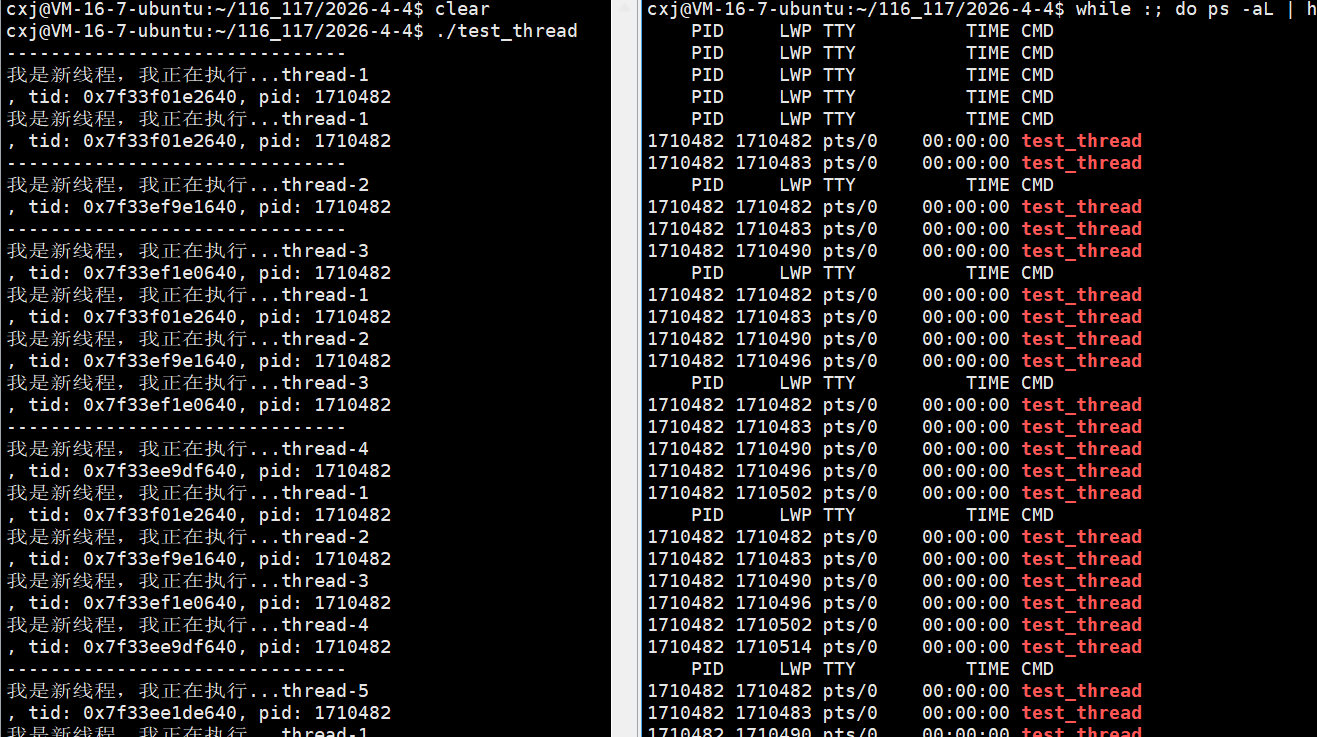
我们可以用for循环创建多线程:
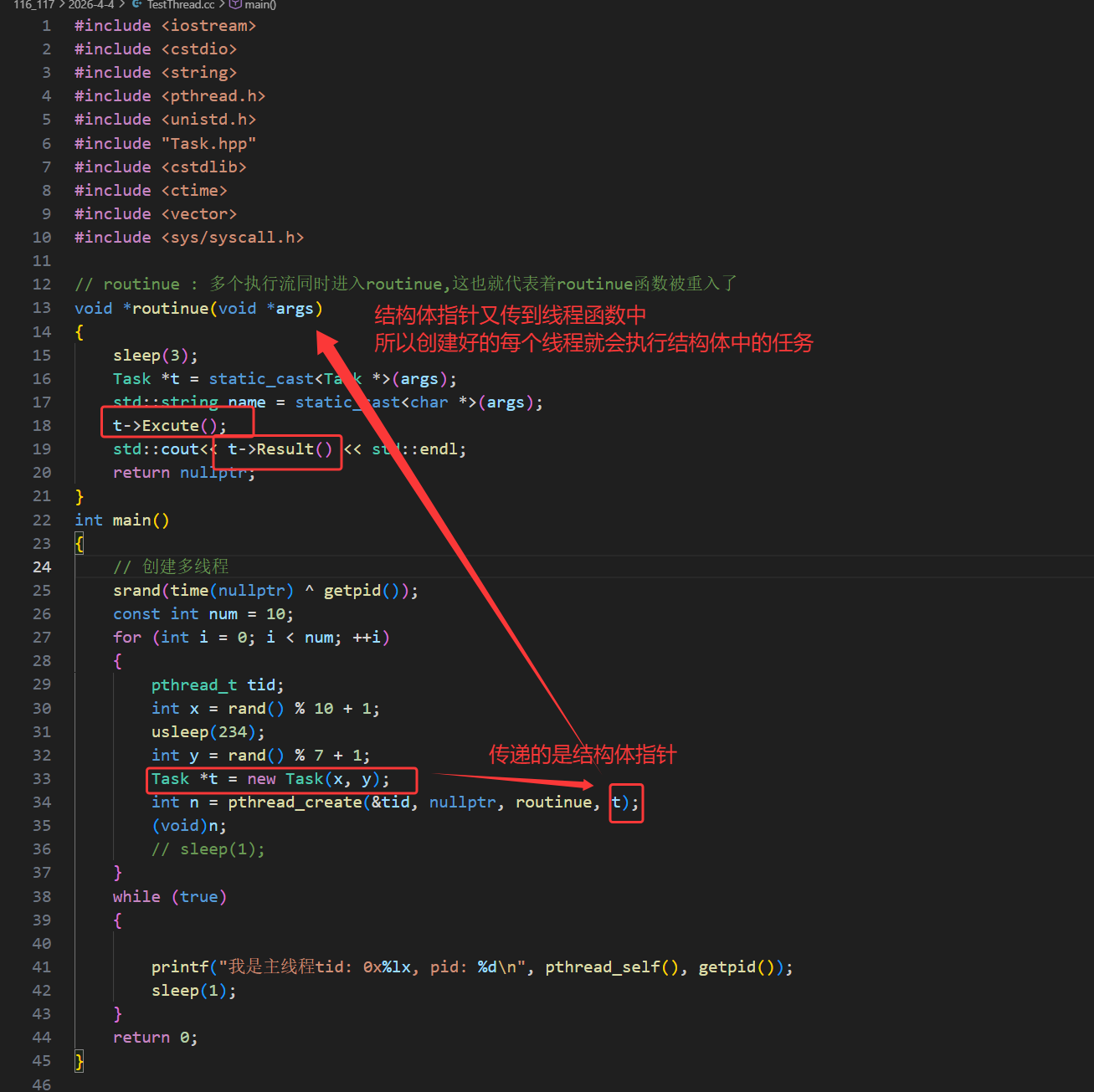
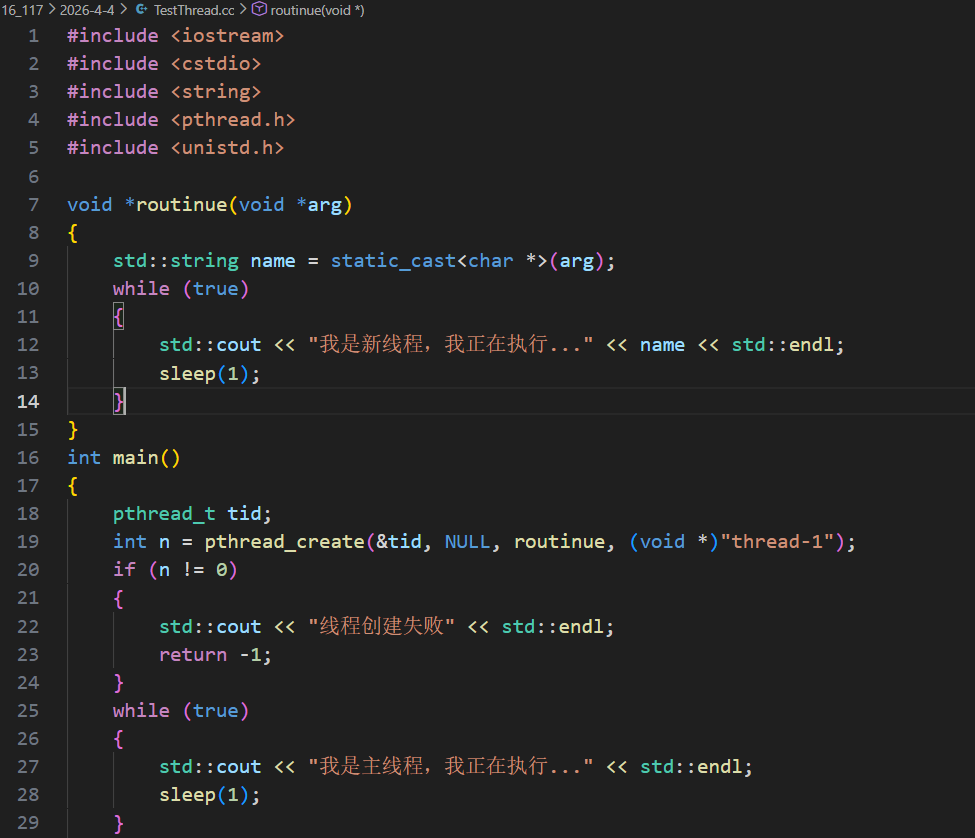
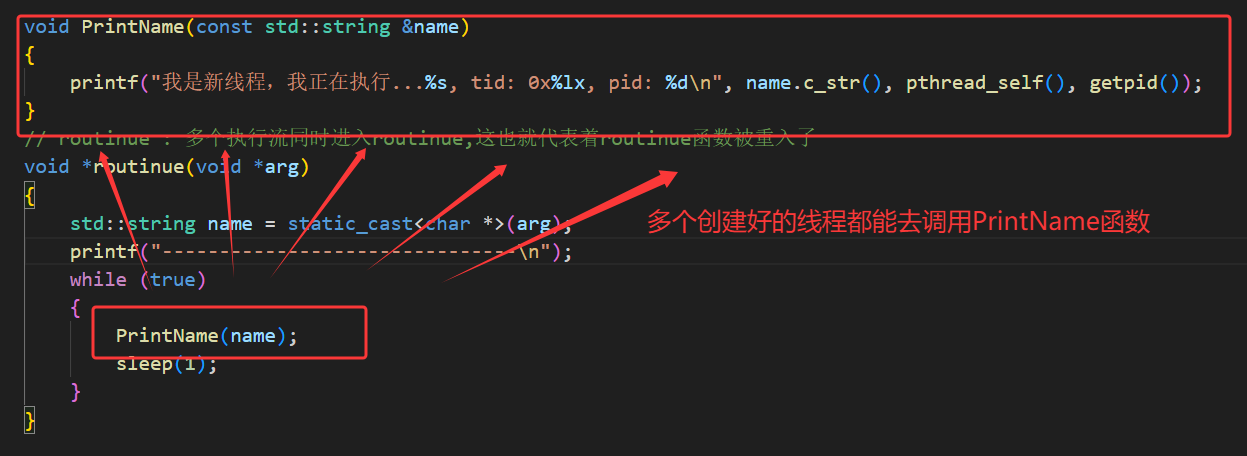
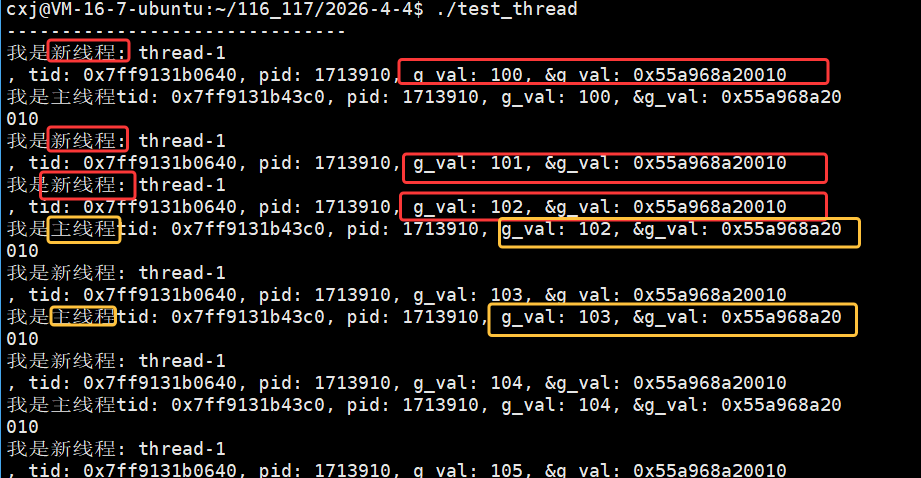
主线程在 for 循环中循环创建 10 个线程,每个线程传入不同的线程名称参数(如 thread-1);入口函数 routine 作为可重入函数,会被多个线程同时执行,通过 static 修饰的局部变量 name 接收传入的线程名,并结合 pthread_self() 获取用户态线程 ID、getpid() 获取轻量级进程 ID(LWP),实现线程自身的标识与日志输出。
运行:
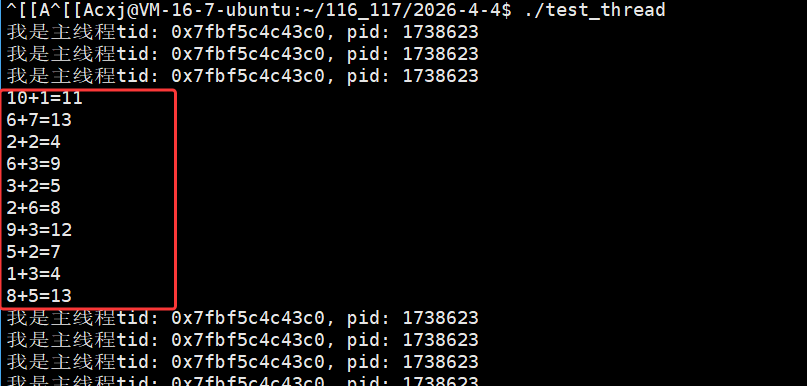
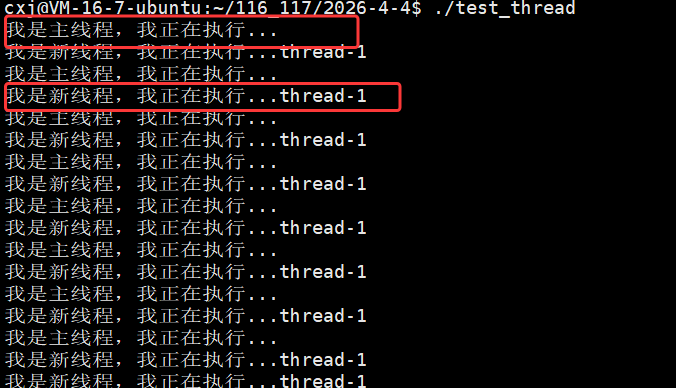
运行结果显示每个线程的 pthread_t 用户态 ID(tid)数值不同,但对应的内核态 LWP(pid)数值完全一致(均为 1707534),这印证了 Linux 中 "一个用户态线程对应一个内核轻量级进程" 的模型,用户态 tid 用于线程库管理,内核态 LWP 用于系统调度,二者高度统一但数值体系独立。
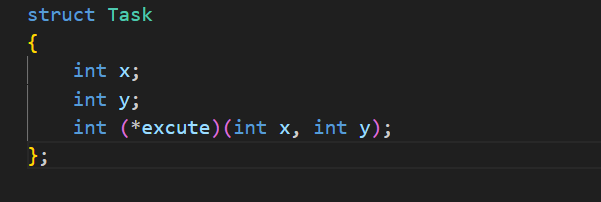
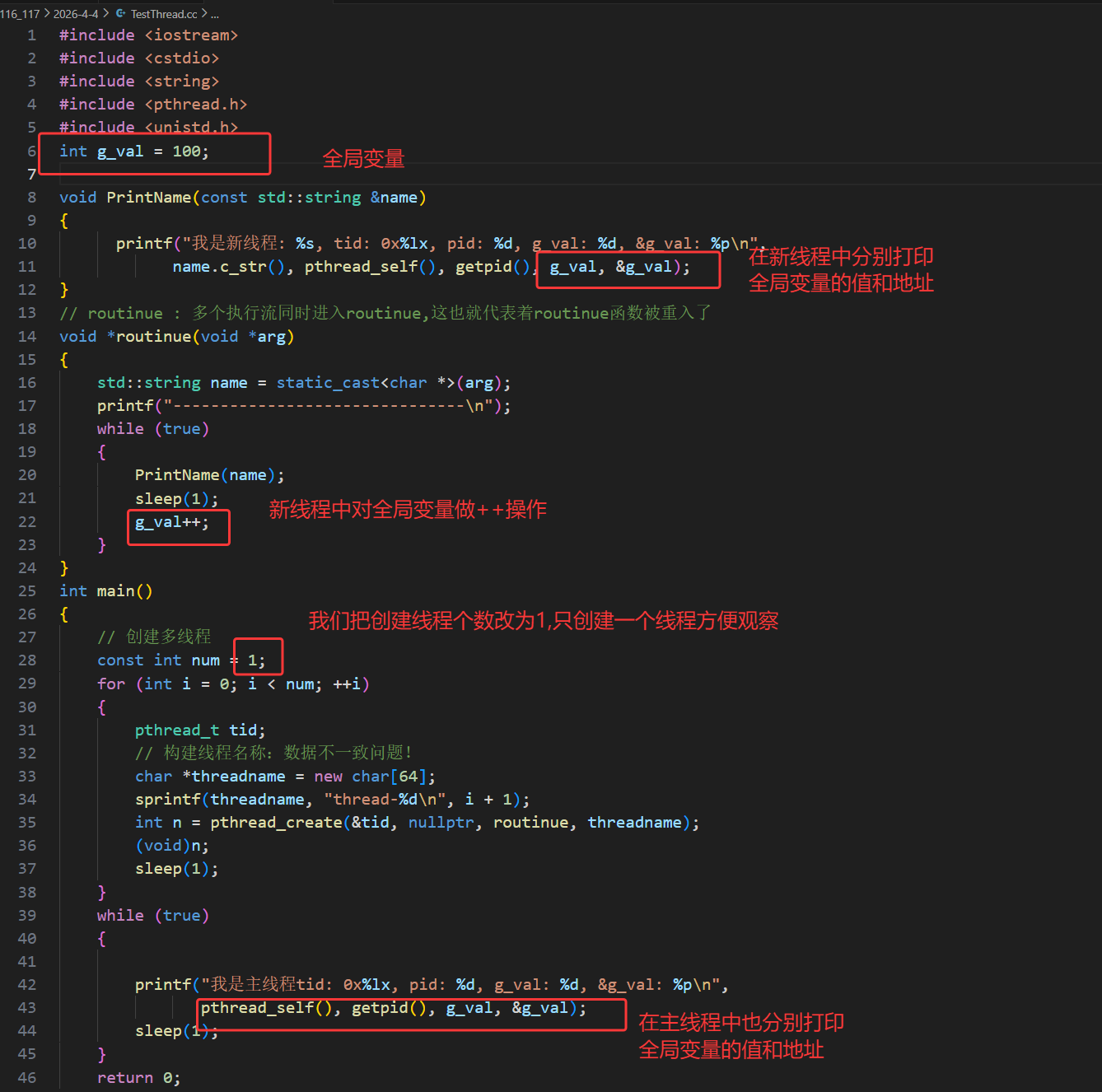
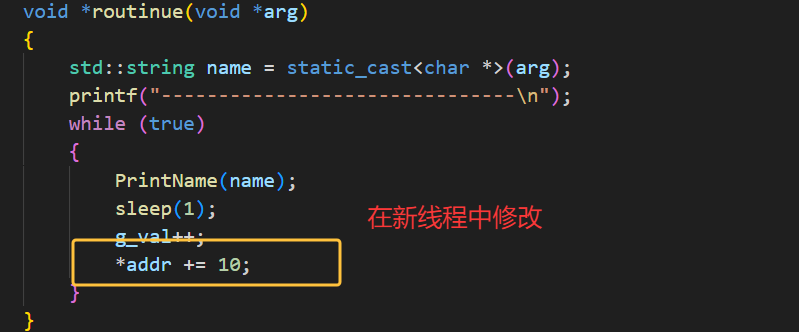
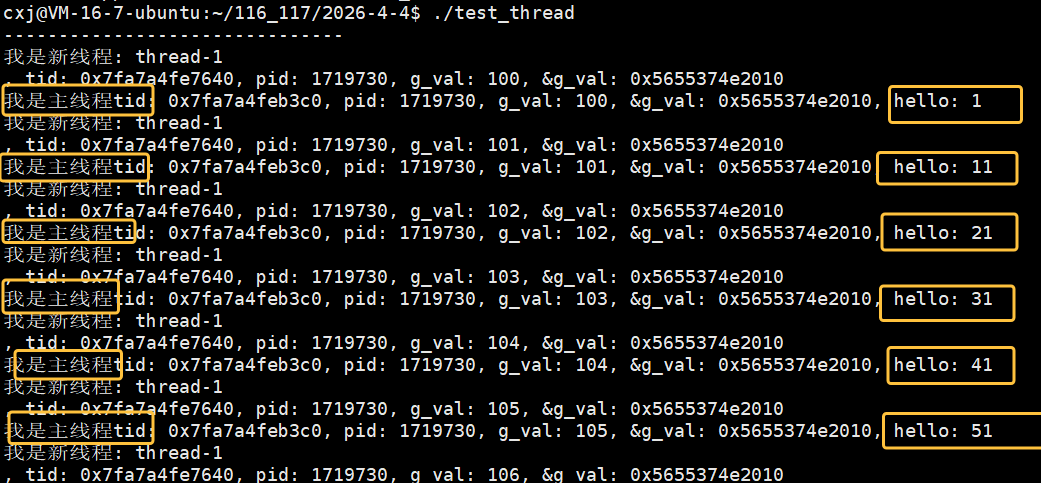
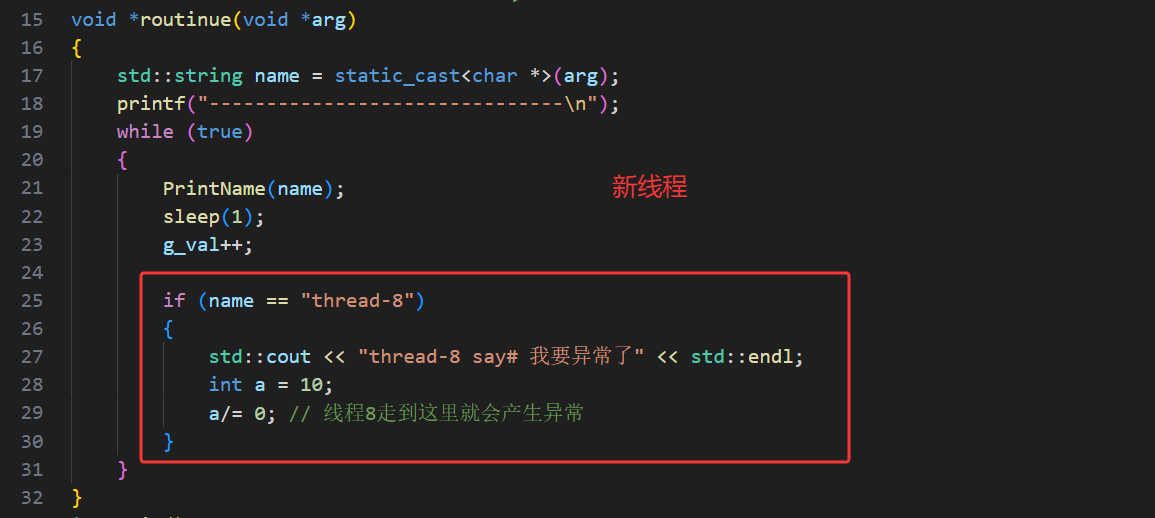
我们也可以用C语言,但是不推荐,有更好的C++写法,无论是 C 语言的结构体,还是 C++ 的类对象,都可以通过传递地址的方式传给线程,结构体可直接传结构体变量的地址,在线程中强转回结构体指针即可访问成员。类对象可传对象地址(需保证对象存活),或传动态分配的对象指针,线程中强转回类指针调用成员方法,这是多线程中传递复杂任务参数的常用方式。










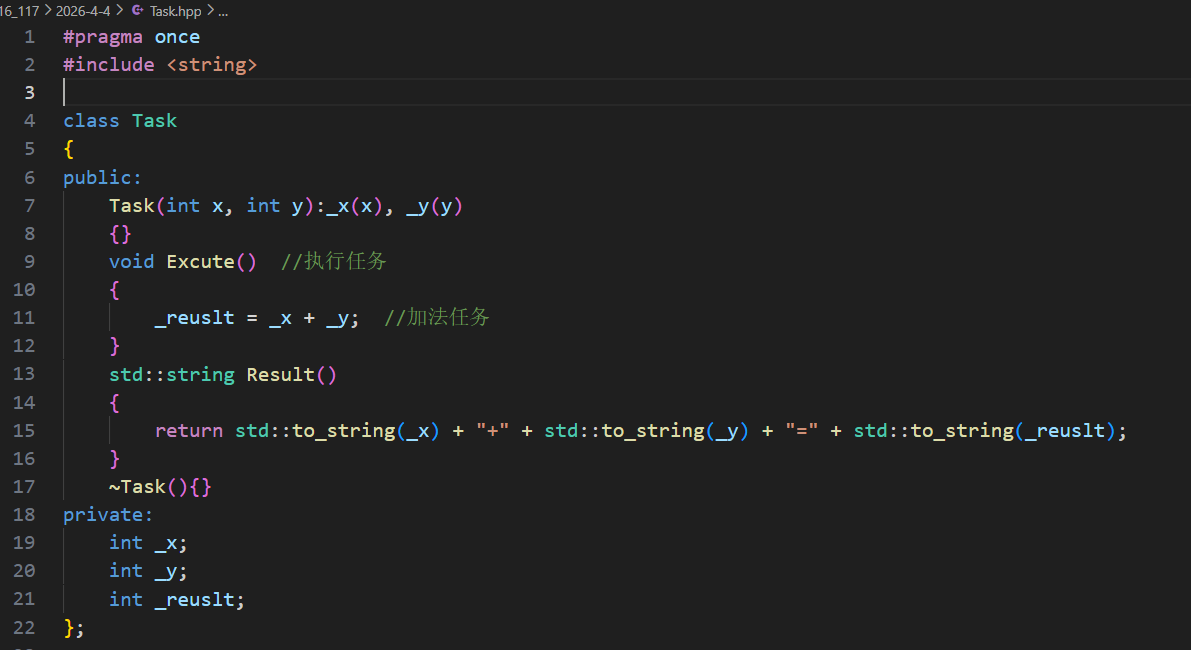
先创建一个任务hpp文件 任务的声明和实现都包含在一起 :