文章目录
摘要
学习LLaVA-OneVision-1.5的核心工作:通过8500万概念平衡的预训练数据和2200万指令数据,配合离线并行数据打包策略实现高效训练。模型采用RICE-ViT与Qwen3架构,创新性地引入区域聚类判别损失和两阶段强化学习(仅答案RL→思维链RL),显著提升了复杂多模态推理能力。重点记录了概念平衡采样、区域感知注意力、差异驱动的RL数据选择等可借鉴方法。
abstract
This study focuses on the core work of LLaVA-OneVision-1.5: achieving efficient training through 85 million concept-balanced pre-training data points and 22 million instruction data points, coupled with an offline parallel data packaging strategy. The model employs the RICE-ViT and Qwen3 architectures, innovatively introducing region clustering discriminative loss and two-stage reinforcement learning (answer-only RL → thought chain RL), significantly improving complex multimodal reasoning capabilities. Key methods for reference, such as concept-balanced sampling, region-aware attention, and difference-driven RL data selection, are documented.
一、LaVA-OneVision-1.5 :
主要内容:1.8500 万概念平衡的预训练数据集 LLaVA-OneVision-1.5-Mid-Training,精心策划的 2200 万指令数据集 LLaVA-OneVision-1.5-Instruct。
2.离线并行数据打包策略,端到端高效训练框架下训练。
3.轻量级的强化学习(RL)阶段释放模型的潜在能力,激发出稳健的思维链推理能力,提升复杂多模态推理任务的性能。
1.1概括
思想:发现仅在中训练阶段扩展数据本身即可产生最先进的 LMMs,无需复杂的训练范式。
数据:8500 万概念平衡的预训练数据集 LLaVA-OneVision-1.5-Mid-Training,精心策划的 2200 万指令数据集 LLaVA-OneVision-1.5-Instruct。平衡策略。
LLaVA 系列的ViT--MLP--LLM结构:RICE-ViT作为视觉编码器。Qwen2.5-VL,将空间上相邻的四个补丁特征分组,然后将它们拼接并通过一个两层多层感知机(MLP)映射到 LLM 的文本嵌入空间。Qwen3 作为语言骨干。
训练:阶段 1)语言-图像对齐,阶段 1.5)高质量知识学习,阶段 2)视觉指令微调。数据打包策略提高效率。
后训练:强化学习
1.2 数据
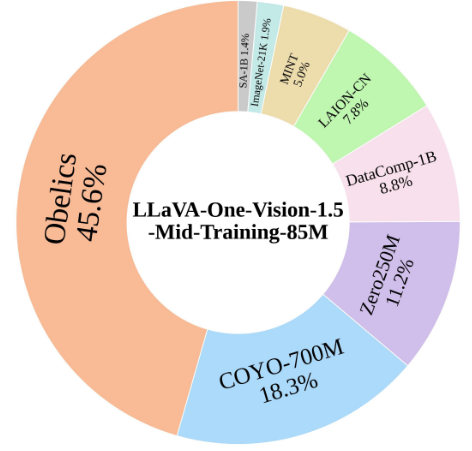
数据:LLaVA-OneVision-1.5-Mid-Training 支撑,该数据集包含 8500 万高质量图像-文本对(2000 万中文和 6500 万英文)。
解决原始数据的长尾分布问题,受 MetaCLIP启发的概念平衡采样策略:采用基于特征的匹配方法来粗略分组图像来源。使用预训练的 MetaCLIP-H/14-Full-CC2.5B 编码器,将图像和 MetaCLIP 的 50 万概念条目投影到共享嵌入空间。
由于 MetaCLIP 嵌入已经是概念平衡的,使得基于相似性的概念归纳成为可能:对于每张图像,检索其 Top-K 最近邻概念嵌入,以构建增强的伪标题,从而提升语义对齐。
1.3 结构
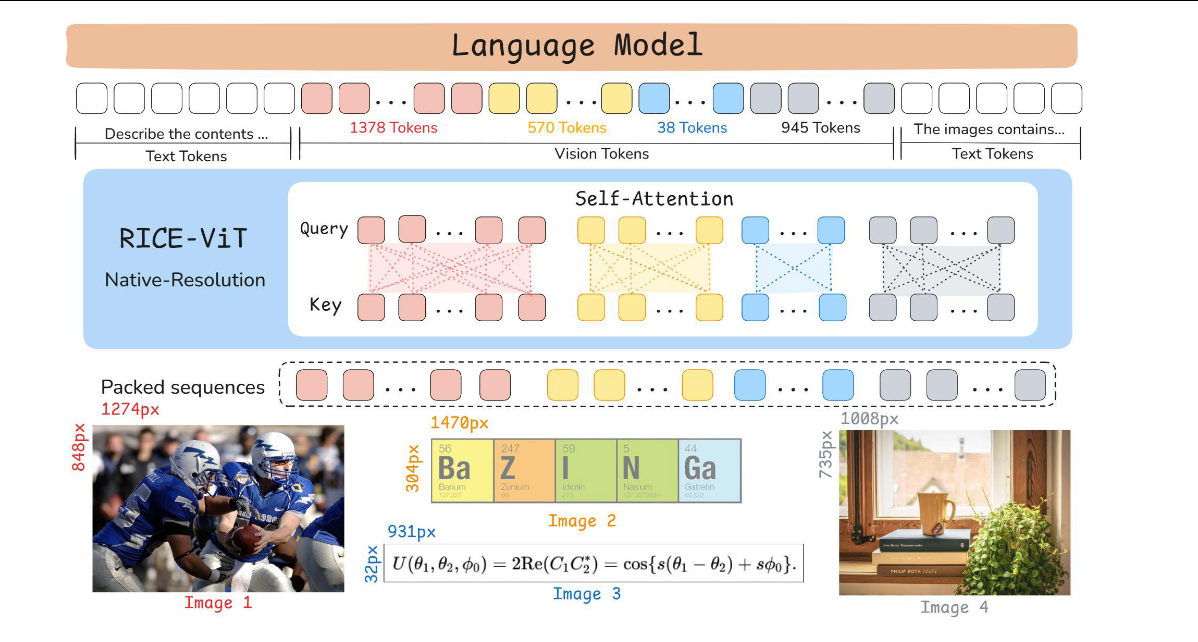
RICE-ViT 保留标准的基本流程,但在位置编码、注意力机制和训练目标上进行了关键修改。
输入层:分块后,支持可变输入分辨率(采用2D旋转位置编码)根据补丁在图像中的绝对坐标动态生成位置嵌入,无需针对特定分辨率进行微调。
标准注意力:计算所有 Patch 之间的相关性。
区域感知注意力:聚类机制动态计算相关性。
区域聚类判别损失:语义相似的区域(即使来自不同图像,非传统图像整体作为正负样本)聚类在一起,同一聚类内的区域特征应相互靠近,反之远离。
投影器:将空间上相邻的四个补丁特征分组,然后将它们拼接并通过一个两层多层感知机映射到 LLM 的文本嵌入空间。下采样减少3/4的数据量,拼接保证视觉信息的完整性。
1.4 训练
阶段1:语言-图像对齐。使用 LLaVA-1.5 558K 预训练投影层,将视觉特征对齐到 LLM 的词嵌入空间。
阶段 1.5:高质量知识学习。对齐阶段的基础上,引入高质量知识学习阶段,以在计算效率和向 LMMs 注入新知识之间取得平衡。此阶段,使用 LLaVA-OneVision-1.5-Mid-Training 数据集对所有模块进行全参数训练。(之前没有的)
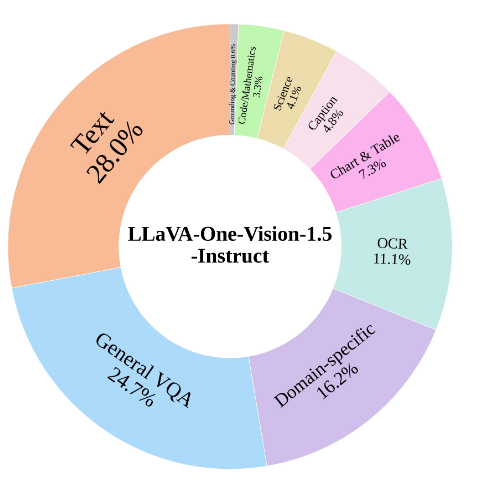
阶段 2:视觉指令微调。为使 LMMs 以期望的响应处理各种视觉任务,使用提出的 LLaVA-OneVision-1.5-Instruct 以及 FineVision数据集进行全参数训练。
1.5阶段数据打包实现负载均衡:传统填充数据,提出了一种离线并行数据打包方法,在预处理阶段将多个较短样本合并为打包序列。采用哈希桶来高效处理大规模数据,并利用多线程、策略感知的批处理来控制打包成功率、样本数量和批次组成。实现 11 倍的压缩比。
1.5 后训练:强化学习
差异驱动的数据选择:通过测量不同基准测试上 Pass@N 和 Pass@1 性能之间的差异来筛选训练数据。显著的差距表明模型具有解决该任务的潜在能力,因为正确的解确实出现在其采样分布中,但其策略分布未能可靠地为正确的推理路径分配高概率。RL激发机制而非知识注入,将概率质量重定向到模型已经能够生成但未一致优先选择的解上。
聚合多样化的公共数据源构建 RL 训练语料库:涵盖了广泛的能力,如 STEM 推理、编码、接地、计数、空间推理、图表理解和 OCR。
在这基础上:基于奖励的采样,进一步筛选高质量的训练实例,使用基础模型为每个样本生成多个候选响应,并计算它们的自动奖励。仅保留那些候选响应的平均奖励落在指定范围内的示例,使语料库偏向于提供最有价值学习信号的中等难度实例。
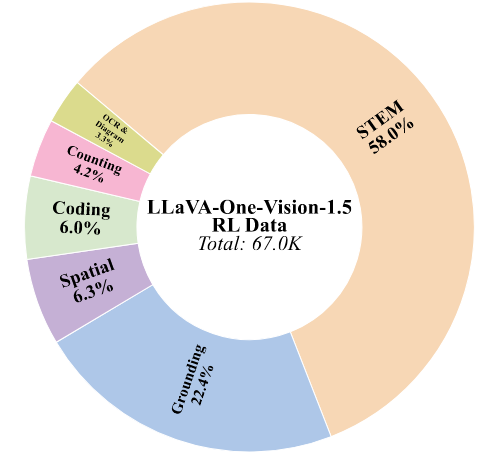
奖励系统:
RL 设置采用基于规则的奖励范式,奖励直接从任务结果推导,非学习的偏好模型。
不同类型的答案需要不同的验证策略。如:接地数据通过预测边界框与参考边界框之间的交并比(IoU)进行评估,并结合相关多选题的标准准确率。图表问题通过多选题准确率进行判断。...
训练过程:
采用组相对策略优化(GRPO)作为核心强化学习算法。为最大化训练效率和吞吐量,采用 AReaL中的 GRPO 实现,最先进的异步 RL 框架。AReaL 将生成与训练解耦,允许滚动工作器持续生成数据,同时训练工作器并行更新模型,与同步实现相比显著提高了 GPU 利用率。
关于优化目标,简化了标准的 GRPO 公式,省略了 KL 散度惩罚,转而依赖 PPO 风格的裁剪来维持训练稳定性。丢弃了常用于强制结构约束(如 XML 标记)的显式格式奖励。相反,仅依赖基于结果的正确性奖励。
两阶段训练:阶段 1:正常数据上的仅答案 RL,要求模型仅输出最终答案(防止简单问题过度思考)。阶段 2:长推理数据上的思维链 RL ,鼓励模型生成显式推理轨迹(混合策略在小批量中穿插少量仅答案示例,作为锚点防止模型遗忘简洁任务的能力。)。根据 内的内容计算, 内的推理作为辅助指导。
1.6性能
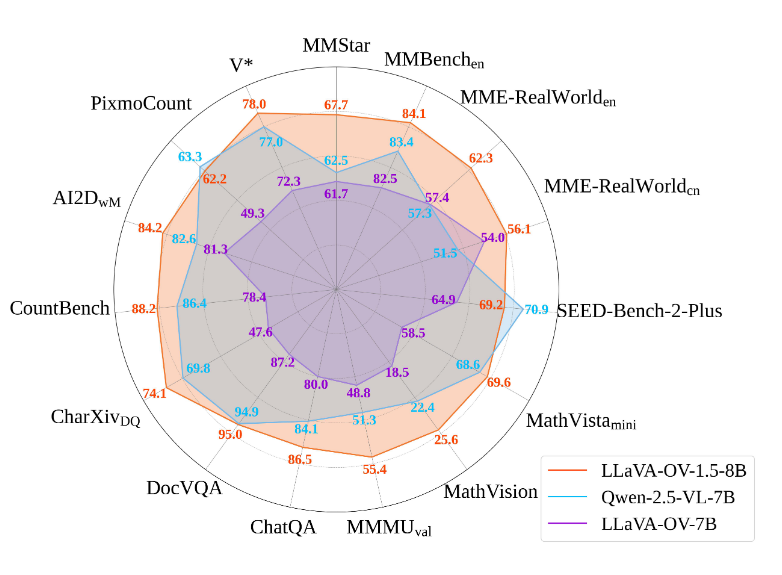
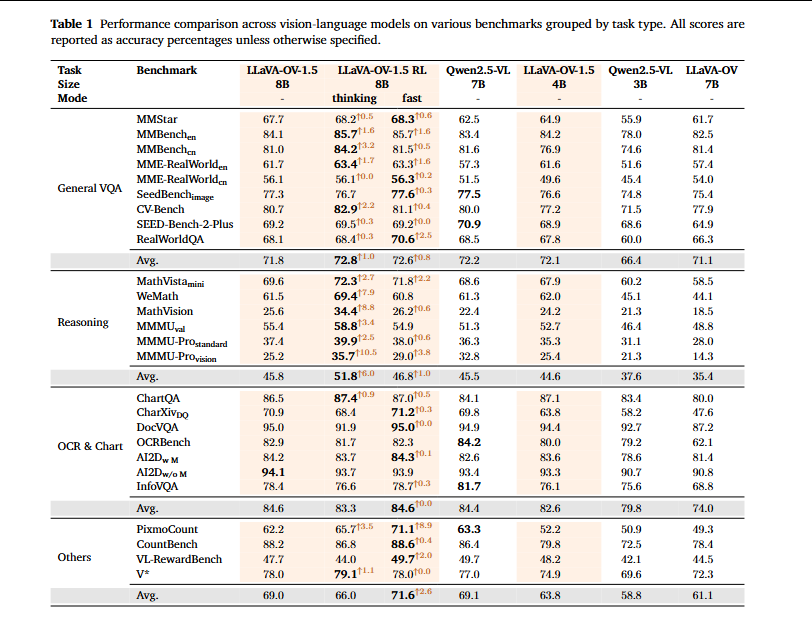
消融实验:强化学习的拓展能力分析。
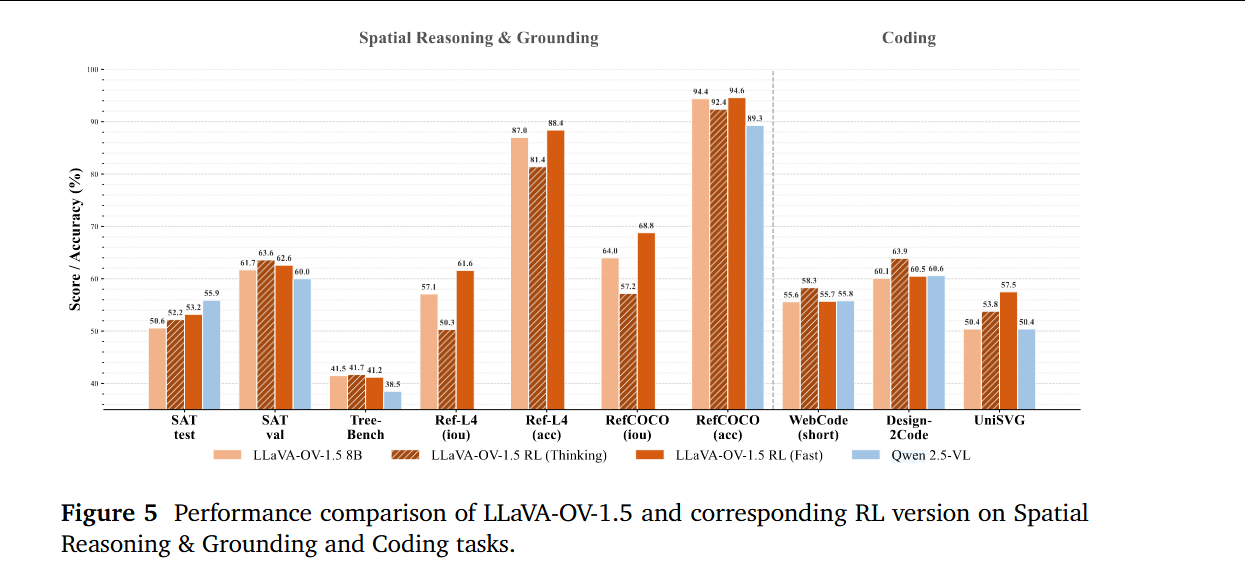
高质量数据增加对模型性能的影响。
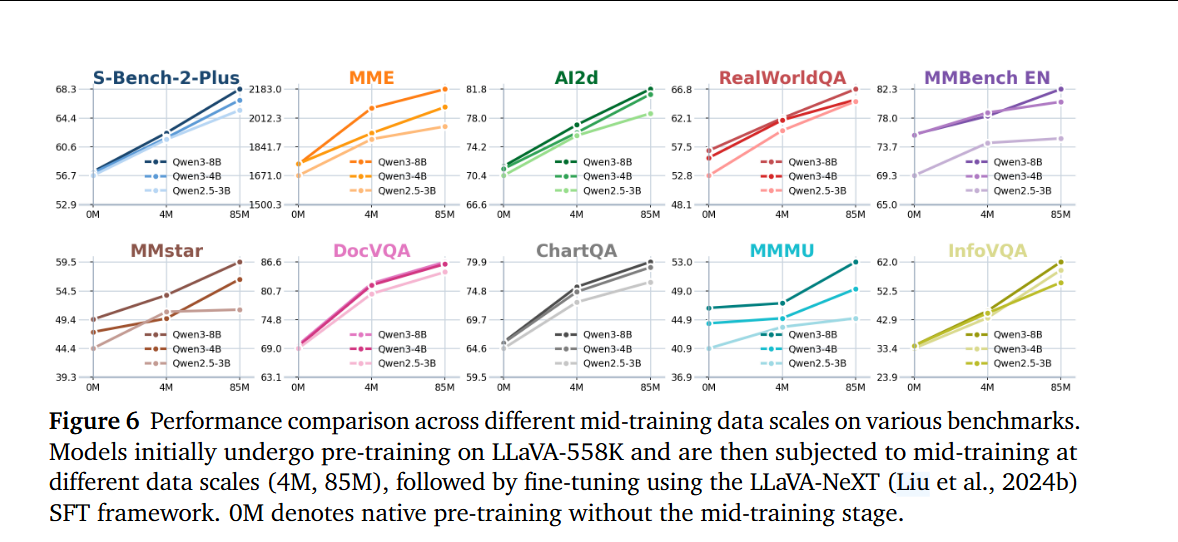
概念平衡数据,增强模型吸收更全面知识的能力。200 万概念平衡数据上训练的模型与在 200 万随机采样数据上训练的模型进行了比较分析。
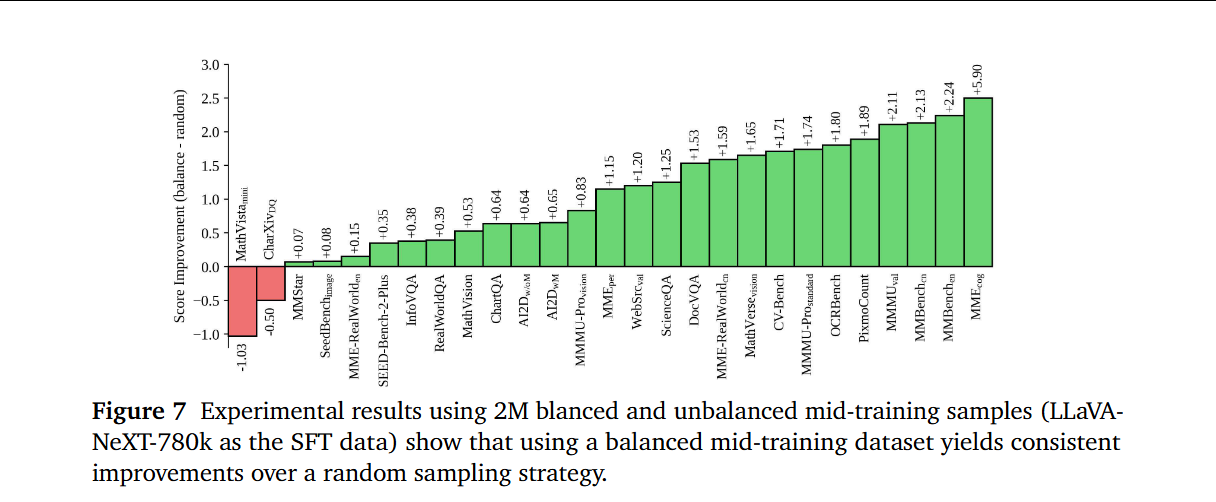
总结
论文可学习使用的:1.数据的收集。基于特征的匹配,逆频率采样。解决原始大规模数据集中的长尾分布。
2.RICE-ViT的特征提取,不改变数据的像素,分辨率。同时平衡效率和性能。区域聚类判别损失:语义相似的区域(即使来自不同图像,非传统图像整体作为正负样本)聚类在一起,同一聚类内的区域特征应相互靠近,反之远离。
3.强化学习使用在最后结果生成和选择上。
代码还在继续实践。