1958年《纽约时报》曾预言:"海军希望电子计算机能够孕育出能走路、会说话、能看会写、还能自我复制并有自我意识的东西。"
近70年后的今天,我们拥有的AI虽然没有完全实现那个预言,但却以另一种方式颠覆了世界。2026年,AI正在从"生成式对话"迈入"代理式行动"的全新纪元。
这一切的起点,是一个叫做"感知机"的简单数学模型。
本文将带你从感知机的诞生开始,一步步理解这个改变世界的算法,并用Python代码亲手实现它。
一、1957年:当心理学教授造出了"会思考的机器"
1957年,康奈尔大学的心理学教授弗兰克·罗森布拉特(Frank Rosenblatt)做了一件疯狂的事------他试图用电子元件模拟人类大脑的神经元。
他设计了一台名为 Mark I 感知机 的硬件设备。这台机器由400个光电探测器组成,用电位器模拟神经元的连接权重,用电机来完成权重的更新。
-
Mark I的目标很简单:识别图像。
-
它在当时引起了轰动,甚至让人们产生了一种错觉:真正的人工智能即将到来。
-
然而,由于当时算力与理论的双重局限,它最终只能识别极其简单的图像,离"会思考的机器"还差得很远。
但罗森布拉特的伟大之处在于:他不仅造出了机器,还提出了一个影响至今的数学模型------感知机。
二、感知机到底是什么?------从数学公式到代码实现
感知机的核心思想其实非常简单:接收多个输入信号,乘以各自的权重,加起来,如果总和超过某个阈值就"激活",否则就"沉默"。
下图是接收两个输入信号的感知机结构:
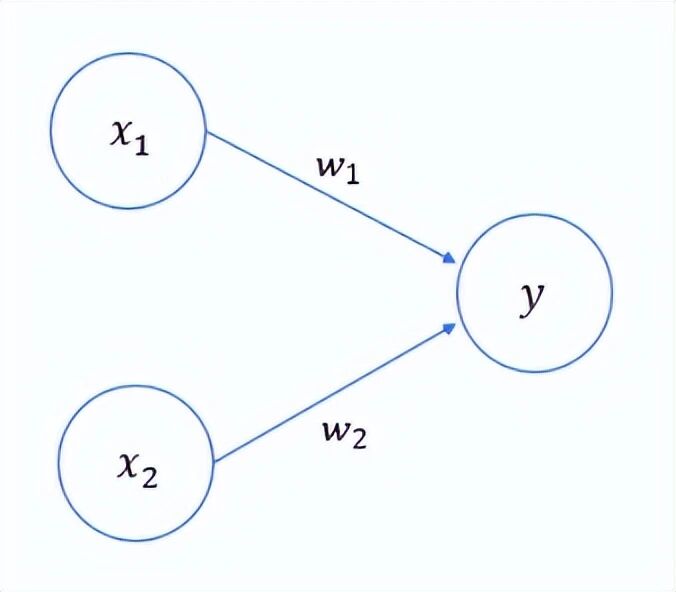
数学上可以这样表示:
y={0(w1x1+w2x2≤θ)1(w1x1+w2x2>θ)y={01(w1x1+w2x2≤θ)(w1x1+w2x2>θ)
其中:
-
x₁、x₂
是输入信号(0或1)
-
w₁、w₂
是权重(控制各输入的重要性)
-
θ
是阈值(决定激活的难易程度)
为了编程方便,我们通常把阈值改写为偏置 b:
y={0(b+w1x1+w2x2≤0)1(b+w1x1+w2x2>0)y={01(b+w1x1+w2x2≤0)(b+w1x1+w2x2>0)
代码实现:用NumPy打造感知机
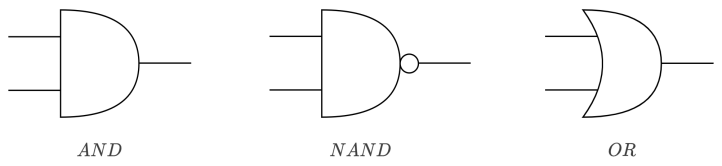
下面我们用NumPy实现一个完整的感知机,先来实现与门(AND gate)------只有两个输入都为1时,输出才为1:

import numpy as np
def AND(x1, x2):
x = np.array([x1, x2]) # 输入信号
w = np.array([0.5, 0.5]) # 权重
b = -0.7 # 偏置
tmp = np.sum(w * x) + b # 加权和 + 偏置
if tmp <= 0:
return 0
else:
return 1
# 测试与门
print(AND(0, 0)) # 输出 0
print(AND(1, 0)) # 输出 0
print(AND(0, 1)) # 输出 0
print(AND(1, 1)) # 输出 1代码解析:
np.array(x1, x2) 将两个输入信号封装成NumPy数组,便于进行向量化运算。
np.sum(w * x) 将权重与对应输入相乘后求和,再与偏置相加,得到总加权输入。
最后通过条件判断决定输出结果。
用同样的结构,只需要改变权重和偏置的值,就能实现不同的逻辑门:
与非门(NAND)------与门的输出取反:
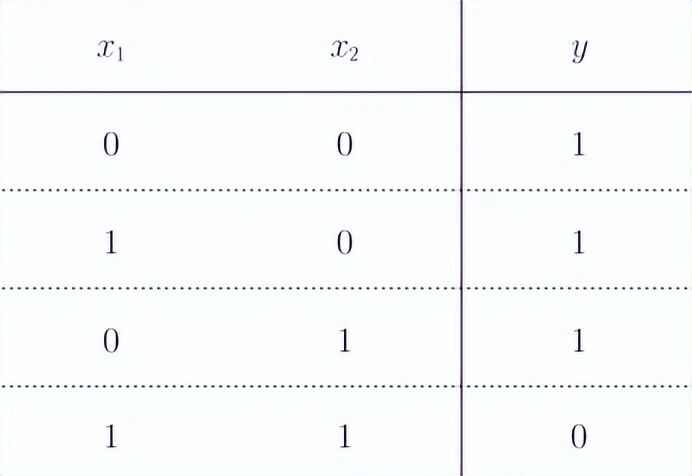
def NAND(x1, x2):
x = np.array([x1, x2])
w = np.array([-0.5, -0.5]) # 权重取负
b = 0.7 # 偏置取正
tmp = np.sum(w * x) + b
return 0 if tmp <= 0 else 1
# 测试与非门
print(NAND(0, 0)) # 输出 1
print(NAND(1, 0)) # 输出 1
print(NAND(0, 1)) # 输出 1
print(NAND(1, 1)) # 输出 0或门(OR)------只要有一个输入为1就输出1:
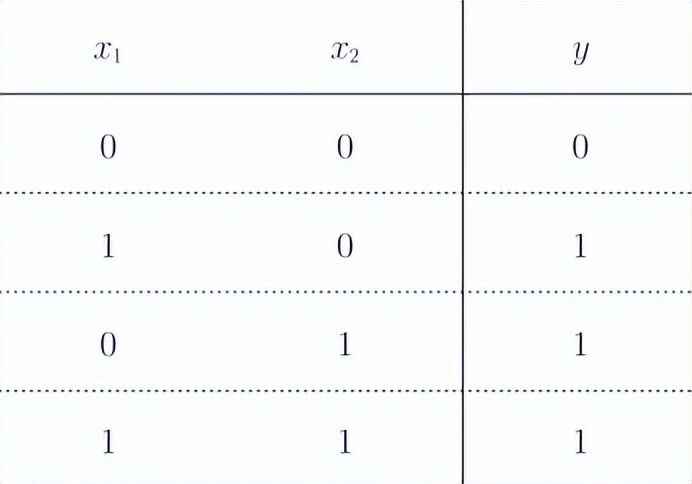
def OR(x1, x2):
x = np.array([x1, x2])
w = np.array([0.5, 0.5])
b = -0.2 # 偏置比与门更大
tmp = np.sum(w * x) + b
return 0 if tmp <= 0 else 1
# 测试或门
print(OR(0, 0)) # 输出 0
print(OR(1, 0)) # 输出 1
print(OR(0, 1)) # 输出 1
print(OR(1, 1)) # 输出 1与门、与非门、或门具有完全相同的构造,区别仅在于权重和偏置的值。
三、感知机的致命局限:为什么一个门都搞不定?
逻辑门的问题还没完。现在来看异或门(XOR):
|----|----|---|
| x₁ | x₂ | y |
| 0 | 0 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 1 | 0 |
异或门的特点是:当两个输入不同时输出1,相同时输出0。
问题来了:单层感知机无论如何都实现不了异或门。
3.1 几何视角:为什么一条直线不够用?
把四个输入点(0,0)、(1,0)、(0,1)、(1,1)画在平面上,标记输出值------你会发现:没有任何一条直线能把输出为0和输出为1的点完全分开。
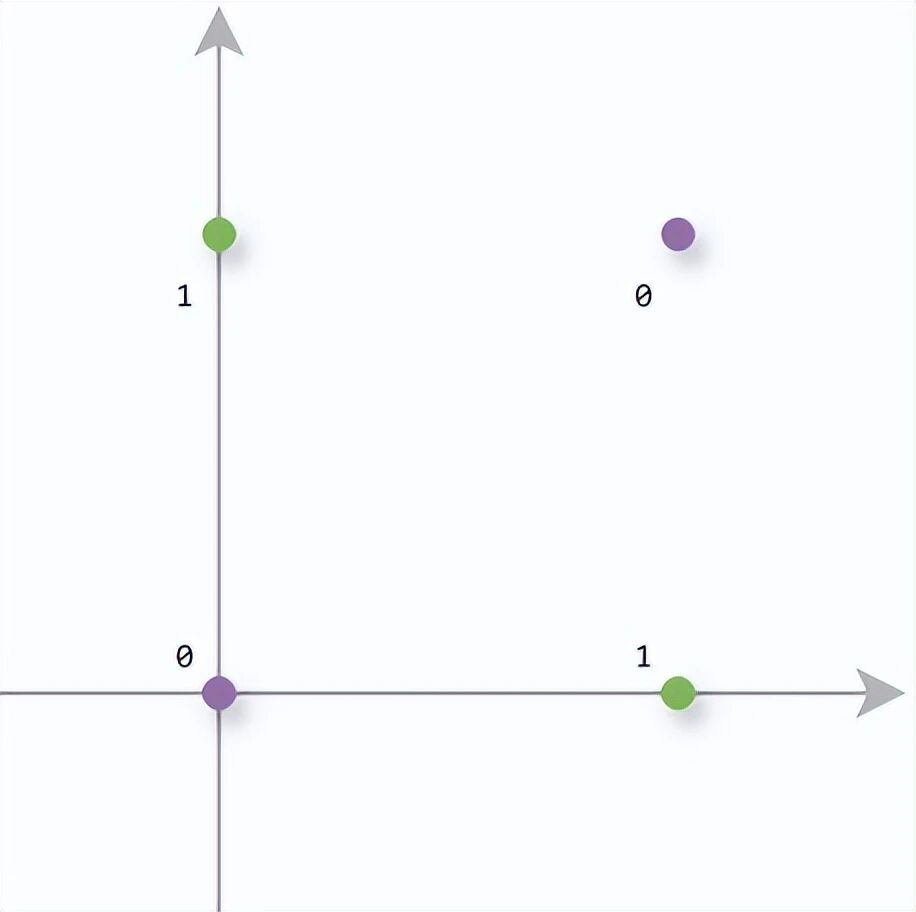
这个发现就是后来著名的 XOR问题。
但如果将直线这个限制条件去掉就可以了:
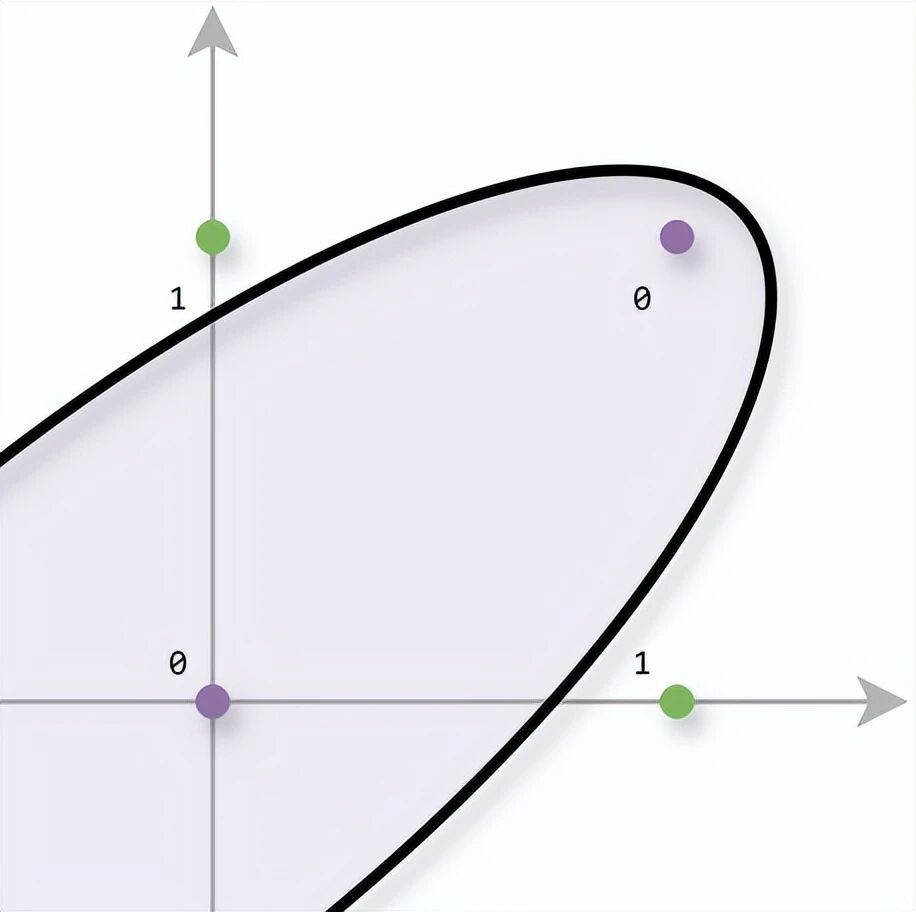
感知机的局限性就在于它只能表示由一条直线划分的空间,而上图中的曲线无法用感知机表示。由曲线划分的空间称为非线性空间,由直线划分的空间称为线性空间。
3.2 历史转折:1969年的"AI寒冬"
1969年,人工智能领域的泰斗马文·明斯基(Marvin Minsky)和西摩·佩珀特(Seymour Papert)出版了《感知机》一书,用严格的数学证明了:单层感知机无法解决XOR这样的线性不可分问题。
-
这本书的出版,加上当时算力的极度匮乏,直接导致整个神经网络研究进入了长达十几年的"AI寒冬"。
-
很多人错误地以为多层感知机也存在类似的根本性缺陷,事实上,多层感知机完全可以解决XOR问题。
好消息是:感知机学习算法有一个重要的理论保证------收敛定理 。如果训练数据是线性可分的,感知机算法一定能在有限次迭代后找到正确的分类超平面,且错误更新次数有一个上界。这条定理证明了感知机在适用场景下的可靠性。
四、破解XOR:多层感知机的诞生
既然单层不行,那就用多层。用两个感知机组合起来:
将其组合构成异或门:
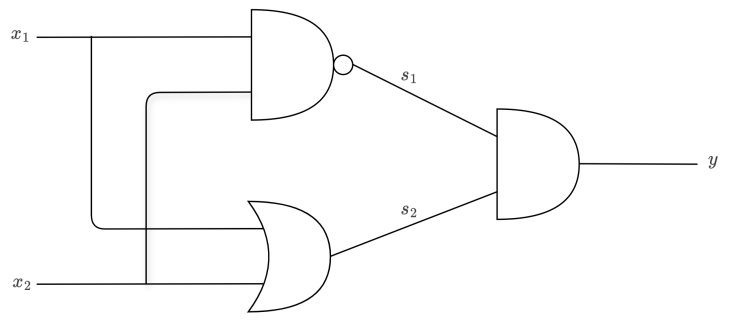
具体来说:
-
第一层用与非门 和或门分别处理输入
-
第二层用与门对两个结果再做一次判断
下面是完整的代码实现:
import numpy as np
def AND(x1, x2):
x = np.array([x1, x2])
w = np.array([0.5, 0.5])
b = -0.7
return 1 if np.sum(w * x) + b > 0 else 0
def NAND(x1, x2):
x = np.array([x1, x2])
w = np.array([-0.5, -0.5])
b = 0.7
return 1 if np.sum(w * x) + b > 0 else 0
def OR(x1, x2):
x = np.array([x1, x2])
w = np.array([0.5, 0.5])
b = -0.2
return 1 if np.sum(w * x) + b > 0 else 0
def XOR(x1, x2):
s1 = NAND(x1, x2) # 第一层:与非门
s2 = OR(x1, x2) # 第一层:或门
y = AND(s1, s2) # 第二层:与门
return y
# 测试异或门
print(XOR(0, 0)) # 输出 0
print(XOR(1, 0)) # 输出 1
print(XOR(0, 1)) # 输出 1
print(XOR(1, 1)) # 输出 0代码解析:
XOR 函数内部调用了之前实现的 NAND 和 OR 作为第一层,它们的输出作为 AND 的输入。
通过两层组合,XOR 这个单层感知机无法解决的逻辑被完美实现。
这,就是多层感知机(MLP) 的雏形。
为什么多层就能行?
多层感知机的核心秘密在于:通过叠加多个感知机层,并引入非线性激活函数,模型能够学习极其复杂的非线性映射关系。
-
单层感知机只能学习线性分类边界,就像只能用直线分割数据。
-
多层感知机通过隐藏层(Hidden Layer)对输入数据进行非线性转换,让分类边界变成曲线、折线甚至更复杂的形状。
-
本质上,MLP将输入特征不断转换到新的特征空间,在这个新空间里,原本线性不可分的数据变得线性可分。
一个典型的MLP结构包含输入层、隐藏层和输出层,各层之间的神经元全连接。
反向传播:让多层网络"学会"参数
多层感知机之所以能真正发挥作用,离不开反向传播算法(Backpropagation) 的发明。它的核心思路是:
-
前向传播
:输入数据从输入层流向输出层,计算预测结果。
-
计算误差
:用损失函数衡量预测结果与真实标签之间的差距。
-
反向传播
:从输出层向输入层逐层计算梯度,确定每个权重应该如何调整。
-
梯度下降
:根据梯度更新所有权重和偏置,减小误差。
整个过程循环迭代,直到模型收敛。
1986年,Geoffrey Hinton等人推广了反向传播算法,直接终结了AI寒冬,开启了神经网络的复兴时代。
五、从感知机到Transformer:一条跨越70年的进化之路
感知机的故事并没有在1969年终结。恰恰相反,它的核心思想------通过加权求和、非线性激活、多层叠加来学习复杂模式------成为整个深度学习大厦的基石。
下面这张时间线,展示了从感知机到GPT的进化脉络:
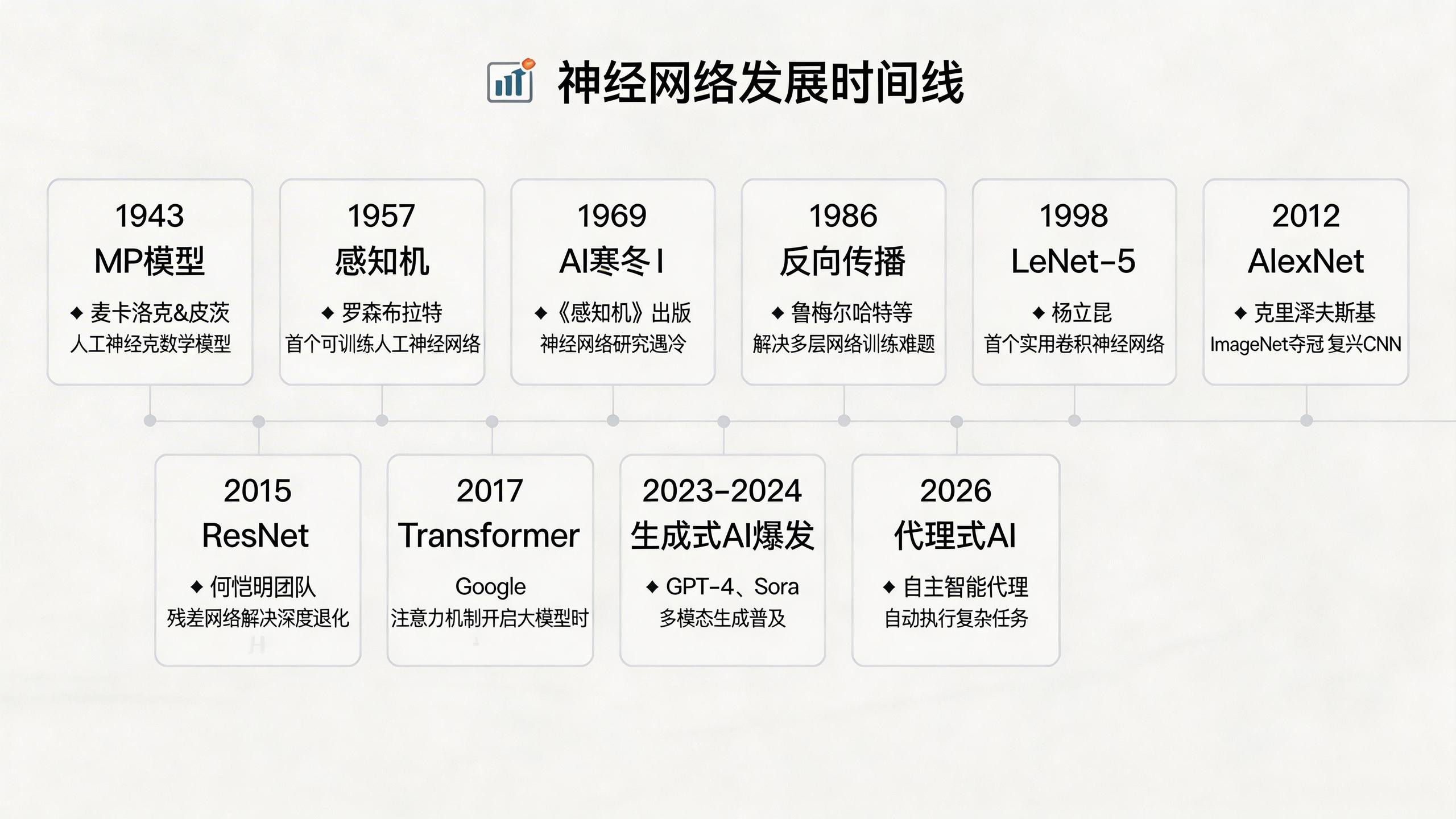
关键里程碑回顾:
|-----------|-----------------|----------------------|
| 年份 | 里程碑 | 意义 |
| 1943 | MP模型 | 神经网络的理论奠基 |
| 1957 | 感知机(Rosenblatt) | 第一个可学习的神经网络 |
| 1969 | 《感知机》出版 | 揭示单层感知机局限,导致AI寒冬 |
| 1986 | 反向传播普及 | 多层网络可训练,AI寒冬结束 |
| 1998 | LeNet-5 | 第一个商用卷积神经网络 |
| 2012 | AlexNet | 深度学习在ImageNet竞赛中一战成名 |
| 2015 | ResNet | 152层网络解决梯度消失问题 |
| 2017 | Transformer | 注意力机制架构,GPT的基础 |
| 2023-2024 | 生成式AI爆发 | ChatGPT引爆全球AI热潮 |
| 2026 | 代理式AI兴起 | AI从"对话"走向"行动" |
2026年的AI正在发生深刻转变:如果说2023-2024年是生成式AI的"对话"时代,那么2026年将是 "行动"时代 。代理式AI(Agentic AI) 将成为新的前沿,AI系统能够自主感知环境、设定目标、规划步骤并执行复杂的任务序列,无需人类持续干预。
与此同时,前沿研究也在不断突破传统架构的局限。2026年伊始,普林斯顿和UCLA提出的 Deep Delta Learning(DDL) 新架构,通过让残差连接本身具备学习能力,突破了传统ResNet"只能累加信息、无法修改状态"的天花板,为深度网络的表达能力开辟了新方向。
六、总结:为什么我们今天还要学感知机?
感知机是一个极其简单的模型,但它的意义远不止于此:
-
理解深度学习的基础
:感知机里"加权求和 → 激活函数 → 输出"的模式,是每一个神经网络的基础构建单元。掌握了感知机,就掌握了神经网络的核心思想。
-
理解AI的局限与突破
:XOR问题告诉我们:简单的模型有其天然边界 。而多层感知机的解法告诉我们:组合与叠加可以打破边界。这种思维方式贯穿整个深度学习的发展。
-
理解AI的进化逻辑
:从感知机到MLP,从CNN到RNN,从Transformer到GPT,每一次突破都是在前人基础上的叠加与组合。理解起点,才能理解方向。
-
掌握可运行的代码
:文中所有感知机代码都是可以直接运行的,亲手敲一遍代码,远比只看理论来得深刻。
感知机是一座桥梁------连接着神经科学的生物灵感与计算机科学的数学严谨,连接着1957年的硬件实验与2026年的前沿AI。理解它,你就抓住了深度学习的源头。
💡 一句话总结 :感知机是深度学习的"原子"------本身极其简单,但正是它的组合与叠加,构建了今天整个AI世界的复杂性。