并查集的原理
- 并查集就是森林,这个集合的每个有关系的元素可以构成一个集合,集合形式相当于是一个树 (也就是一个小集合)【这就是 「Set 集」】;
- 当不同树上的元素产生关联时,就把这两棵树合并成一棵树【这就是「Union 并」 】。
- 在「并」的过程中,需要反复查询某个元素属于哪个集合【这就是「Find 查」】
对于「查」来说:为什么必须要「查」?
因为合并两棵树,其实是合并两棵树的根 。要合并,必须先找到两个元素的根节点 ,看是不是同一棵树:
- 根不同 → 才合并
- 根相同 → already 同一集合,不用合并
所以:Union(并)依赖 Find(查)
该数据结构是用树形结构来表示的,其功能就是查询你这个元素是哪一个集合的,带有实现两个集合合并的算法能力。
在一些应用问题中,需要将 n 个不同的元素划分成一些不相交的集合。开始时,每个元素自成一个单元素集合,然后按一定的规律将归于同一组元素的集合合并。 在此过程中要反复用到查询某一个元素归属于那个集合的运算。适合于描述这类问题的抽象数据类型称为并查集 (union-find set)。
比如:某公司今年校招全国总共招生 10 人,西安招 4 人,成都招 3 人,武汉招 3 人,10 个人来自不同的学校,起先互不相识,每个学生都是一个独立的小团体,现给这些学生进行编号:{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}(编完号之后,通过编号进行分组就可以了);
给以下数组用来存储该小集体,数组中的数字代表:该小集体中具有成员的个数。(负号下文解释)

采用双亲表示法实现:
- 以数组模拟多棵树(类似堆结构),下标对应元素,值存储父节点索引;
- 本质是用数组实现树结构的抽象映射。
初始时数组值为 -1,表示每个元素独立成集合,共 10 棵树、10 个集合。
毕业后学生按城市组队:
- 西安:s1={0,6,7,8}
- 成都:s2={1,4,9}
- 武汉:s3={2,3,5}
10 人合并为 3 个集合,以 0、1、2 作为各集合根节点(队长)。
一趟火车之旅后,每个小分队成员就互相熟悉,构成了一个朋友圈。

特点:
- 一个位置的值是负数,那他就是树的根,这个负数的绝对值就是这棵树数据个数;【包括自己,也就是为什么刚开始的时候是 -1】
- 一个位置的值是非负数,那他就是双亲的下标
那如果我们给的这 10 个人是名字,而不是编号呢(也就是起初并没有 10 个人对应的编号),那我们这么知道谁代表的是哪一个编号呢?
解决方法:通过建立相应的映射关系:
比如给的是 10 个人的名字,我们可以使用两个数据结构:vector,map。
vector 的作用就是使用数组下标进行映射关系的维护:
- 假如数组的第一个元素是
string类型:张三,那么,张三对应的编号就是 0,也就是实现通过编号进行对应人的查找; map的作用就是通过人找到所属的编号,不然使用vector的话,查找效率会比较低
cpp
template<class T>
class UnionFindSet
{
public:
//假设刚开始给我的是带有n个元素的类型为const T的数组a
UnionFindSet(const T* a, size_t n)
{
for (size_t i = 0; i < n; i++)
{
_a.push_back(a[i]);
_Indexmap[a[i]] = i;
}
}
private:
vector<T> _a; // 通过编号进行对应人的查找
map<T, int> _Indexmap; // 通过人找到所属的编号
};映射关系的演示:
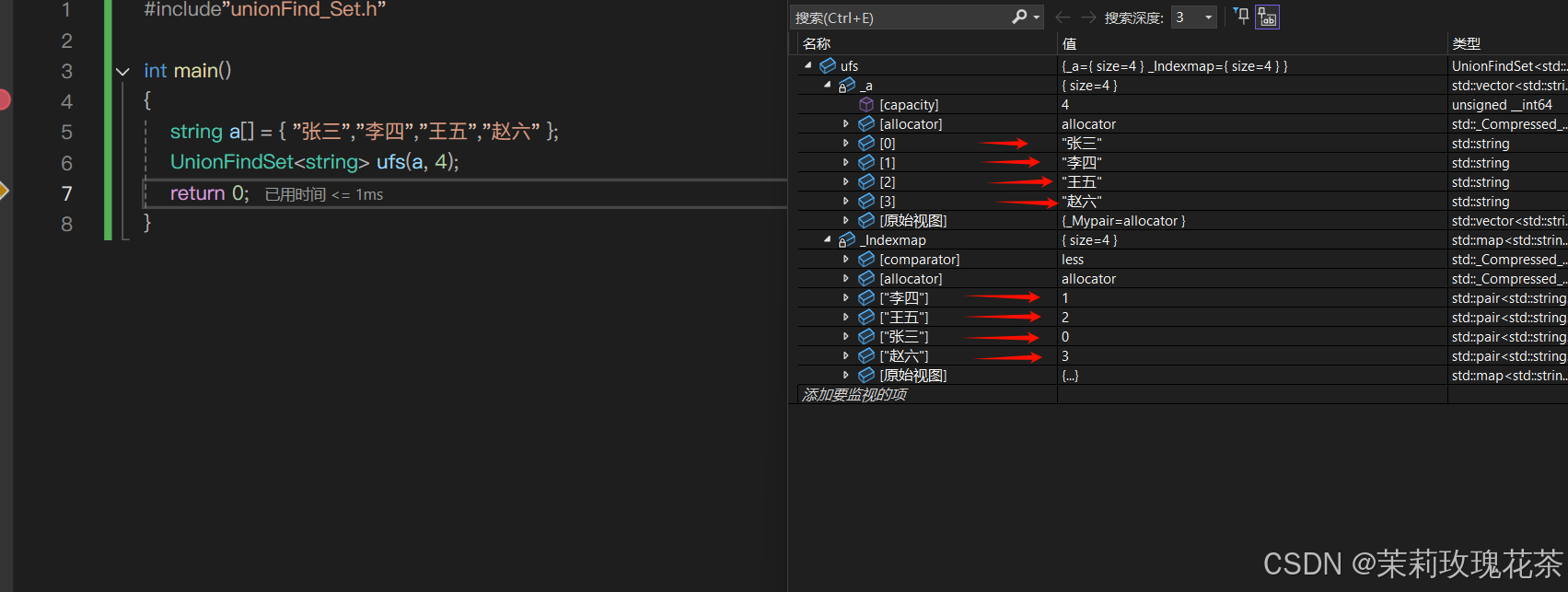
从上图可以看出:编号 6,7,8 同学属于 0 号小分队,该小分队中有 4 人(包含队长 0);编号为 4 和 9 的同学属于 1 号小分队,该小分队有 3 人(包含队长 1),编号为 3 和 5 的同学属于 2 号小分队,该小分队有 3 个人(包含队长 2)。
仔细观察数组中内容,可以得出以下结论:
- 数组的下标对应集合中元素的编号
- 数组中如果为负数,负号代表根,数字代表该集合中元素个数
- 数组中如果为非负数,代表该元素双亲在数组中的下标
在公司工作一段时间后,西安小分队中 8 号同学与成都小分队 1 号同学奇迹般的走到了一起,两个小圈子的学生相互介绍,最后成为了一个小圈子:
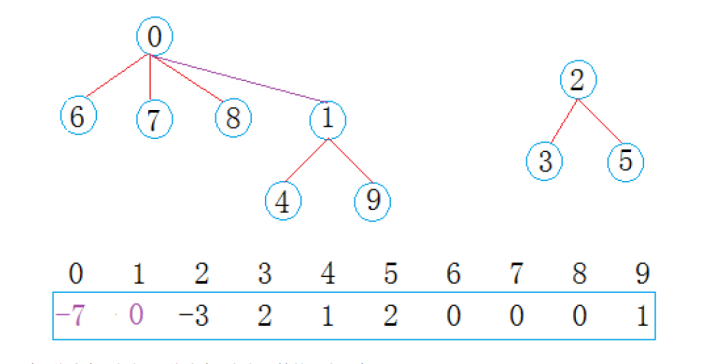
西安小分队的 8 号同学与成都小分队的 1 号同学建立联系后,我们需要将两个集合合并:
- 查根定位 :先查询 8 号的根节点为 0(西安队队长,集合大小 4),1 号的根节点为 1(成都队队长,集合大小 3);
- 按秩合并 :将规模更小的成都队(根 1)挂到规模更大的西安队(根 0)下,完成两个集合的合并;
- 结构更新 :合并后,0 号成为新集合的根节点,数组中 0 号位置的值更新为-7(表示根节点,集合总人数为 4+3=7),1 号位置的值更新为0(表示父节点为 0 号),其余节点的父节点关系保持不变,最终形成以 0 为根、包含 0,1,4,6,7,8,9 共 7 个元素的新树,武汉小分队(根 2,集合大小 3)保持独立。
合并后的数组完全符合并查集规则:
- 根节点:
0(-7)(7 人集合)、2(-3)(3 人集合) - 非根节点:值为父节点下标(如
1→0、4→1、6→0等)
这里顺带提一嘴,关于操作结构的时候的优化:
① 路径压缩(Path Compression):在「查」的时候优化
- 触发时机 :执行
find(x)(查询元素 x 的根节点)的时候 - 做了什么 :在递归 / 迭代找根的过程中,把路径上所有节点的父节点直接改成根节点
- 效果:把树拉平,让后续所有查询都几乎 O (1)
② 按秩合并 / 按大小合并(Union by Rank / Size):在「并」的时候优化
- 触发时机 :执行
union(x, y)(合并两个集合)的时候 - 做了什么 :把规模更小 / 高度更矮 的树,挂到规模更大 / 高度更高的树的根下面
- 效果:避免树退化成链表,控制树的高度
所以现在 0 集合有 7 个人,2 集合有 3 个人,总共两个朋友圈。
通过以上例子可知,并查集一般可以解决以下问题:
**查找元素属于哪个集合:**沿着数组表示的树形关系向上一直找到根(即:数组中元素为负数的位置)
**查看两个元素是否属于同一个集合:**沿着数组表示的树形关系往上一直找到树的根,如果根相同表明在同一个集合,否则不在
将两个集合归并成一个集合
- 将两个集合中的元素合并
- 将一个集合的根节点指向另一个集合的根节点
**统计集合的个数:**遍历数组,数组中元素为负数的个数即为集合的个数。
我们一直说朋友圈,可是真的的朋友圈往往是复杂得多的:
假设三个人:A、B、C
- A 和 B 是好友,B 和 C 是好友,但 A 和 C不是好友
- B 发了一条朋友圈
用并查集的错误逻辑:A、B、C 会被合并到同一个集合,导致 A 能看到 C 的评论,C 能看到 A 的评论,这完全不符合微信的实际规则!
所以我们也是为了铺垫「图」,那么用图的正确逻辑:图的边:A-B、B-C
B 发朋友圈:
- 只有直接好友 A 和 C能看到这条朋友圈
- A 只能看到 B 和自己的评论,看不到 C 的评论(因为 A 和 C 不是好友)
- C 只能看到 B 和自己的评论,看不到 A 的评论
- B 能看到 A 和 C 的所有评论(因为 B 是发布者,且是 A、C 的共同好友)
核心矛盾点:并查集的「连通性」是等价关系 ,而微信好友关系是无向图的邻接关系,两者本质完全不同
| 特性 | 并查集(等价关系) | 微信好友关系(无向图) |
|---|---|---|
| 传递性 | ✅ 若 A~B,B~C,则 A~C(A 和 C 一定连通) | ❌ 若 A 是 B 好友,B 是 C 好友,A不一定是 C 好友 |
| 可见性逻辑 | 同一集合内所有人互相可见 | 仅直接好友可见,非直接好友不可见 |
| 适用场景 | 连通分量、等价类、最小生成树等 | 社交网络、好友关系、路径查询等 |
其实说白了,这里的并查集的学习就是为了图做铺垫的,特别是后面涉及到的最小生成树!
下面,我们来实现一个比较简单的并查集!
并查集的实现
cpp
#pragma once
#include <iostream>
#include <vector>
// 简单的并查集的实现
// 还有如果想要进行不仅仅是按照编号来实现的并查集,可以多加入一个数据结构[map...]进行映射
class UnionFindSet {
public:
UnionFindSet(size_t n) : _ufs(n, -1) {}
// 合并两个元素所在的集合[合并两棵树][两个编号建立联系]
bool Union(size_t x, size_t y) {
size_t rootX = FindRoot(x), rootY = FindRoot(y);
if(rootX == rootY) return false;
// 将较小的树合并到较大的树上[按秩合并]
if(_ufs[rootX] < _ufs[rootY]) {
_ufs[rootX] += _ufs[rootY]; // 更新集合大小
_ufs[rootY] = rootX; // 将rootY的父节点指向rootX
} else {
_ufs[rootY] += _ufs[rootX]; // 更新集合大小
_ufs[rootX] = rootY; // 将rootX的父节点指向rootY
}
return true;
}
// 通过编号, 查找元素所在的集合的根节点
// 后续可以优化点: [路径压缩优化: 在查找过程中将路径上的节点直接连接到根节点上, 以加速后续的查找操作]
// size_t FindRoot(size_t x) {
// int parent = x;
// while(_ufs[parent] >= 0) {
// parent = _ufs[parent];
// }
// // 此处可以进行路径压缩
// return parent;
// }
size_t FindRoot(size_t x) {
int root = x;
while(_ufs[root] >= 0) {
root = _ufs[root];
}
// 此处可以进行路径压缩
while(_ufs[x] >= 0) {
int parent = _ufs[x];
_ufs[x] = root;
x = parent;
}
return root;
}
// 通过编号, 判断两个元素是否在同一个集合中
bool IsConnected(size_t x, size_t y) {
return FindRoot(x) == FindRoot(y);
}
// 获取数组中有多少个集合
size_t GetSetCount() {
size_t count = 0;
for(size_t i = 0; i < _ufs.size(); ++i) {
if(_ufs[i] < 0) { // 根节点
++count;
}
}
return count;
}
private:
std::vector<int> _ufs; // 存储每个元素的父节点[如果是根节点,则存储该集合的大小(负数)]
};并查集的应用
理解了并查集的原理和实现之后,我们可以写几道算法题来练练手!