DeepSeek-V3 Technical Report
https://arxiv.org/abs/2412.19437
核心亮点:
多头潜在注意力机制MLA、DeepSeek MoE架构、多Token预测训练目标MTP
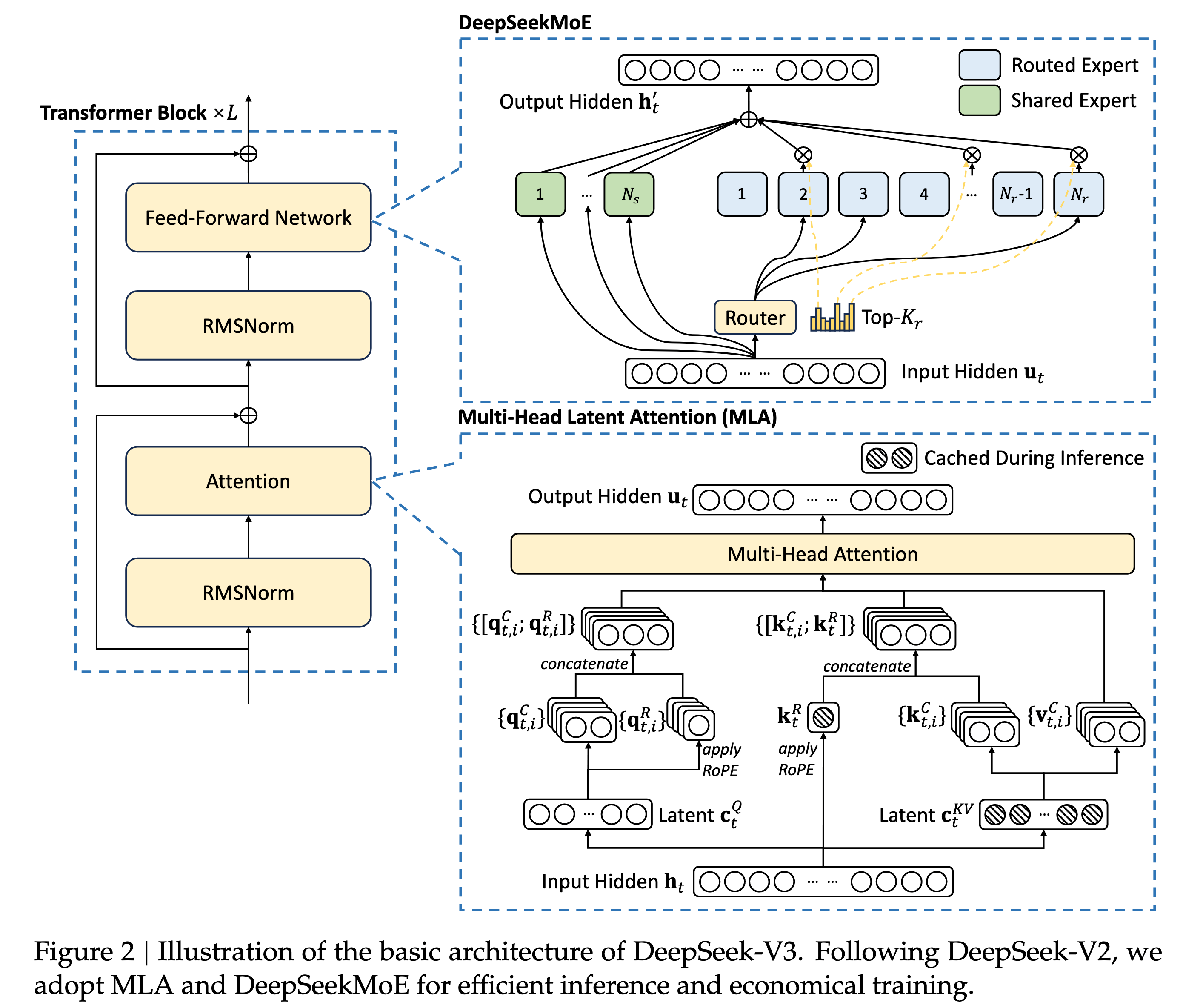
这张图其实已经可以比较清晰地说明MLA和MoE架构了。
对于MLA,主要的策略是把输入的hiddenstates进行降维,使得KV Cache的量更小,需要运算的时候再升维处理。MoE则是添加了Router,来决定当前token的隐状态走哪些公开的专家头,以及所有token一定都会走通用的专家头。
MLA
综合来开,MLA的核心思想仍然是压缩KV Cache的缓存量,采取的方法是把hidden states给使用低秩矩阵给压缩处理,需要用到的时候再升维处理。
还有是实现了RoPE和低秩压缩方案的解藕:
将 Query 和 Key 的维度拆分为两部分:
一部分(如 128 维)用于低秩压缩,不加 RoPE。
另一部分(如 64 维)单独加 RoPE,然后与压缩部分的输出拼接 。
这样既保留了相对位置信息,又兼容了压缩机制。

对照图2的内容
输入 X ──┬──→ W^DQ ──→ Q(标准,多头)
│
├──→ W^DKV ──→ c^KV(压缩 latent)──┬──→ W^UK ──→ K
│ │
│ └──→ W^UV ──→ V
│
└──→ W^KR ──→ k^R(解耦 RoPE)───────→ 与 K 拼接
具有辅助无损负载平衡的 DeepSeekMoE
主要亮点有以下内容:
- 门控机制+共享专家头机制
- 无损负载均衡,体现在动态的token对专家对偏好分数偏置值
- 互补序列辅助损失防止不平衡现象,损失的本质还是调整router的参数,损失使用的常规MoE架构中的损失,参考token分配比例、分配分数以及专家数量
- 节点限制路由,对每一个token进行限制,约束它最多被发送到M个专家节点中;
- 无token丢弃,针对的是上一代MoE架构中的专家容量超参数导致部分token溢出处理区而被丢弃的问题,核心的解决方法是前面的策略保证负载均衡,理论不溢出。

辅助无损负载平衡(不让某些热门专家垄断)

可以看到,这里的偏置是bi,而不是一个固定的b,所以表达的意思是每一个专家都有一个可以学习的偏置值,只用来路由,不参与其他计算。对于过载的专家,bias减小以降低被选择的概率;对于欠载的专家,bias增大以提高被选择的概率
互补序列辅助损失

f_i 是分配给专家 i 的 token 比例,p_i 是路由给专家 i 的平均门控分数,N_r 是专家数量,\alpha 是平衡系数。这个损失鼓励专家被均匀使用。

限制每一个token被分配的专家数目

这里其实强调的就是传统的MoE架构,比如deepseek v2版本中,引入了一个叫做专家容量的参数,限制每一个专家被分配的token数目,如果某一个专家已经到达了处理容量上限,那么下一个被分配的token将不被使用专家计算,而是直接跳过该专家,使用残差链接处理,也就是这里提到的"Token被丢弃"
多Token预测,MTP
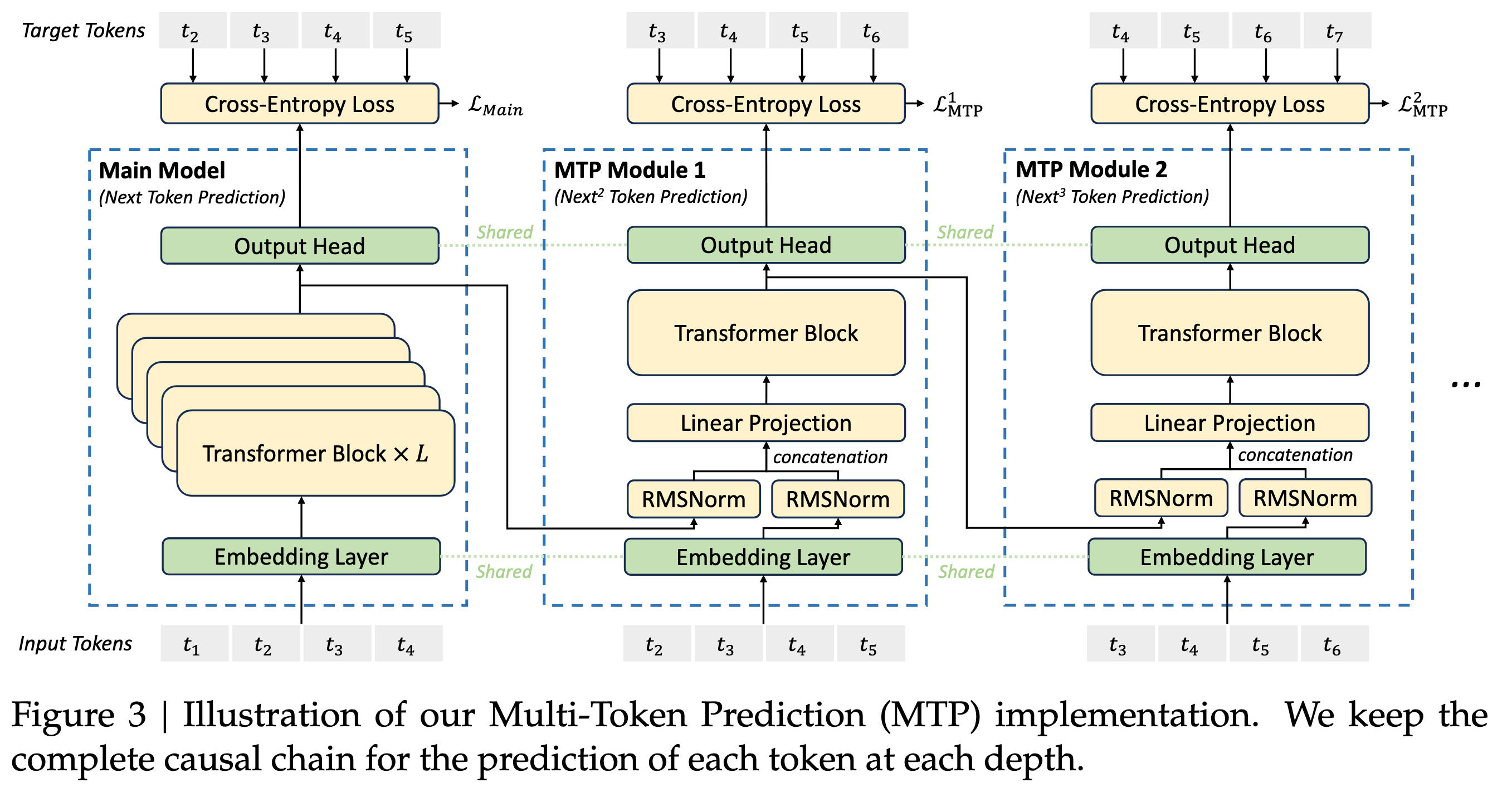
MTP模块

MTP 不改变主模型的主体结构(如 Transformer 层、MoE 层等),而是在输出端增加额外的预测头(prediction heads)。假设我们设定预测深度为 D,即每个位置除了预测下一个 token 外,还额外预测未来第 2, 3, \dots, D 个 token。
标准: 输入 t 个token,预测第 t+1 个token MTP: 输入 t 个token,同时预测第 t+1, t+2, ..., t+D 个token D = 深度(Depth),DeepSeek-V3 中 D=4
原始的输出头(称为 head₁)负责预测下一个 token。
新增的 D-1 个独立输出头(head₂ 到 headₕ)分别负责预测未来第 2 至第 D 个 token。
这些额外的头可以共享底层的 Transformer 表示,也可以有自己的轻量级参数(如一层线性变换 + softmax)。
在 DeepSeek-V3 的实现中,MTP 模块被设计为与主模型共享所有专家参数,仅增加少量额外的输出投影层,因此参数开销极小。
MTP训练目标

MTP 的额外头可以天然地用作投机采样中的草稿模型。在推理时,可以用 head₁ 生成下一个 token,同时用 head₂ 预测未来第二个 token,从而实现一次前向传播产出多个 token 的猜测,配合目标模型验证加速生成。