多模态大模型时代的黎明:GPT-4V(ision)全面能力深度测评
当AI还在为"看图说话"磕磕绊绊时,GPT-4V已经悄悄解锁了"看懂世界"的超能力。它不仅能识别图片里的物体,还能理解梗图的笑点、解数学题、读X光片、甚至帮你操作电脑完成网购。今天我们就来深度拆解这篇来自微软研究院的重磅测评论文,看看GPT-4V到底有多强,又有哪些"软肋"。
论文信息
- 标题:The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)
- 会议:arXiv 2023预印本
- 单位:微软研究院
- 代码:无官方测评代码(可通过OpenAI API调用GPT-4V)
- 论文:https://arxiv.org/pdf/2309.17421.pdf
一、什么是LMM?GPT-4V的"超能力"从何而来
LMM(Large Multimodal Model,大语言多模态模型) 通俗来说就是"能同时看懂文字和图片的AI"。它把强大的大语言模型(LLM)和视觉编码器结合起来,让AI拥有了"眼睛",能够理解视觉世界并和语言世界打通。
GPT-4V是OpenAI推出的最新多模态模型,它在GPT-4的基础上增加了视觉理解能力。这篇论文通过200多个实验,从16个维度全面评估了GPT-4V的能力,发现它在很多任务上已经达到甚至超越了人类水平。
二、基础视觉能力:从"认得出"到"看得懂"
2.1 图像描述:不止是"看图说话"
GPT-4V不仅能描述图片里有什么,还能理解场景的上下文和隐含信息。比如给它一张婚礼照片,它能说出这是中式还是西式婚礼,甚至能描述人物的表情和动作。
2.2 细粒度视觉识别:能区分双胞胎的"火眼金睛"
细粒度识别就是区分同一大类下的不同子类,比如区分不同品种的狗、不同型号的汽车。GPT-4V在这方面表现出色,甚至能识别出不同品牌的logo和产品细节。
2.3 医学图像理解:AI医生初露锋芒
最让人惊喜的是GPT-4V在医学图像上的表现。它能看懂X光片、CT和MRI,甚至能生成初步的放射报告。
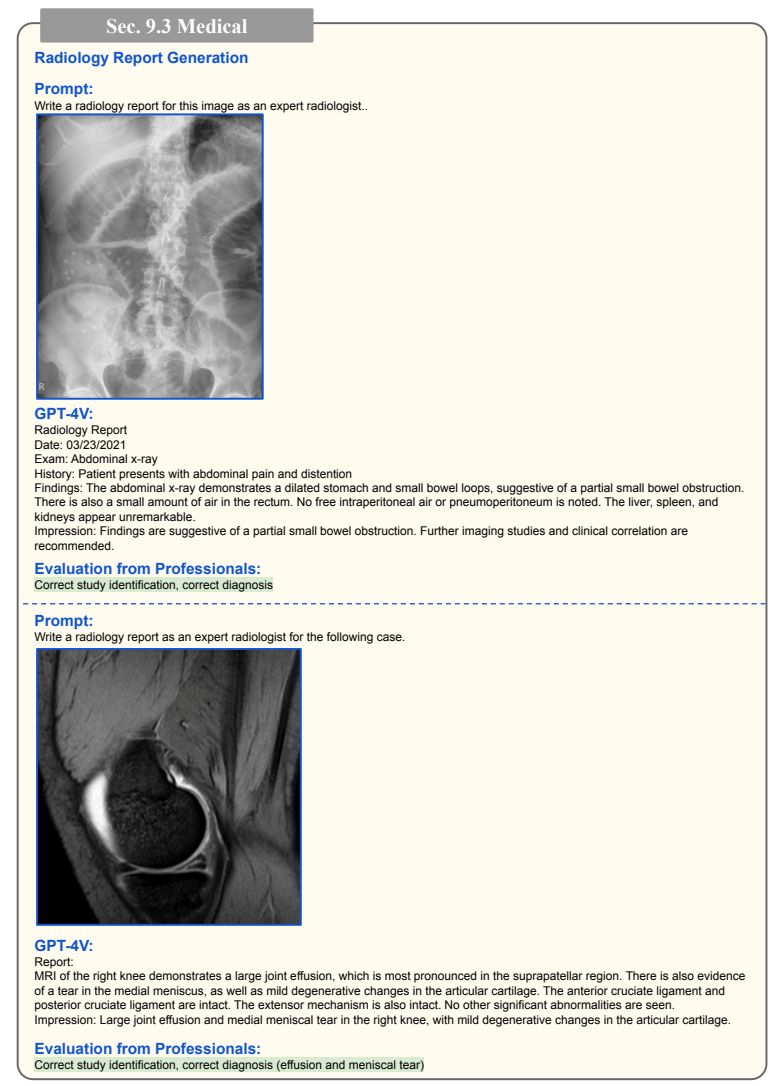
图1:GPT-4V生成的腹部X光报告(原文Figure 75)
分析:GPT-4V准确识别出这是腹部X光片,并诊断出部分小肠梗阻,这和专业放射科医生的判断一致。不过论文也指出,GPT-4V偶尔会出现"幻觉",比如凭空捏造结节的大小和位置,所以目前只能作为辅助工具,不能替代医生。
三、目标定位与密集描述:精准锁定每一个像素
3.1 目标定位:给物体画个框
目标定位就是用Bounding Box(边界框)标出图片中物体的位置。GPT-4V能根据文字描述,准确找到对应的物体并输出坐标。

表1:GPT-4V目标定位示例(原文Figure 26)
| 人物 | 边界框坐标(x1,y1,x2,y2) |
|---|---|
| Person 1 | (120, 250, 420, 950) |
| Person 2 | (500, 240, 800, 940) |
| Person 3 | (880, 230, 1180, 930) |
| Person 4 | (1260, 220, 1560, 920) |
坐标解释:
- (x1,y1)(x1, y1)(x1,y1):边界框左上角的坐标
- (x2,y2)(x2, y2)(x2,y2):边界框右下角的坐标
- 所有坐标都归一化到0-1之间,0代表图片的最左/最上,1代表最右/最下
3.2 密集描述:给每个物体写"小作文"
密集描述就是对图片中的每个物体都生成详细的描述。GPT-4V不仅能识别出人物,还能说出他们的身份和成就。比如给它一张深度学习三巨头的合影,它能准确认出Yann LeCun、Geoffrey Hinton和Yoshua Bengio,并介绍他们的贡献。
四、多模态知识与常识:AI也有"生活经验"
4.1 梗图与笑话理解:AI也能get你的笑点
这绝对是最有趣的部分!GPT-4V不仅能看懂文字笑话,还能理解梗图的笑点。
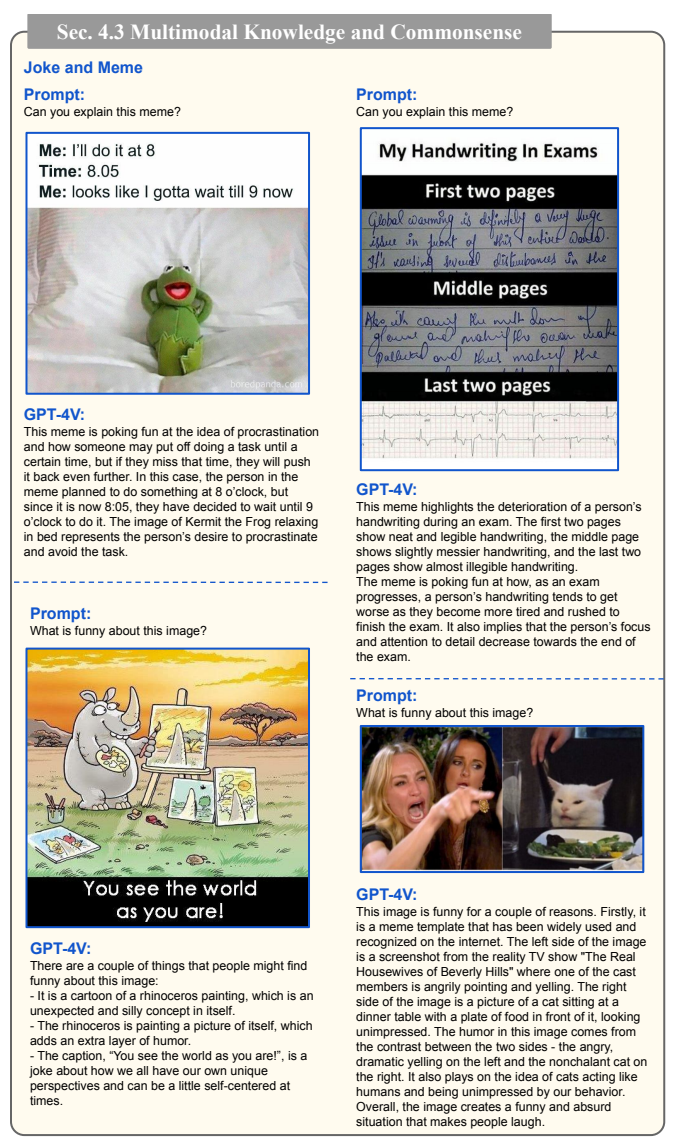
图2:拖延症梗图理解(原文Figure 28)
案例分析:
- 梗图内容:"我:8点再做。时间:8:05。我:看来得等到9点了。"
- GPT-4V的解释:"这个梗讽刺了拖延症,如果你错过了原定的时间点,就会干脆把任务推迟到下一个整点。图中的科米蛙躺在床上,代表了拖延者不想做事的心态。"
4.2 科学知识推理:AI学霸上线
GPT-4V能结合图片和科学知识进行推理。比如给它一张粒子运动图,它能根据粒子速度判断温度高低;给它一张食物网图,它能找出生产者和消费者。
五、场景文本与图表理解:AI的"阅读能力"
5.1 场景文本识别:能看懂路牌和菜单
场景文本识别就是识别图片中的文字,比如路牌、菜单、广告牌。GPT-4V在这方面表现出色,能识别多种语言的文字,包括手写体。
5.2 视觉数学推理:AI也会做数学题
GPT-4V能看懂图片中的数学公式并解题,包括代数方程和几何题。
示例 :
题目:求解方程 (x+3)2=4(x+3)^2=4(x+3)2=4
GPT-4V的解答:
对等式两边开平方得:
x+3 = ±2
解得:
x = -1 或 x = -55.3 图表与文档理解:能读财报和论文
GPT-4V能看懂柱状图、折线图、流程图,甚至能理解多页的技术报告。比如给它一张公司财报的图表,它能分析出哪个产品的利润最高。
六、多语言多模态理解:精通多国语言的AI
GPT-4V支持20多种语言的多模态理解。你可以用中文提问,让它描述一张英文海报;也可以用西班牙语提问,让它用法语回答。
有趣案例:给它一张写着"武汉热干面"的中文海报,它不仅能认出文字,还能告诉你这是武汉的特色小吃,是中国十大早餐之一。
七、视觉编码能力:从图片到代码
GPT-4V最神奇的能力之一就是能把图片转换成代码。它能根据手写的公式生成LaTeX代码,根据表格生成Markdown或LaTeX代码,甚至能根据图表生成Python绘图代码。
核心代码:根据图片生成Python绘图代码
下面是GPT-4V根据一张折线图生成的Python代码:
python
import matplotlib.pyplot as plt
import numpy as np
# 数据
x = np.array([10**6, 10**7, 10**8]) # 预训练图像数量
y_base = np.array([80, 100, 120])
y_large = np.array([90, 110, 130])
y_huge = np.array([100, 120, 140])
# 创建图形
plt.figure(figsize=(8, 6))
plt.plot(x, y_base, label='Base', marker='o')
plt.plot(x, y_large, label='Large', marker='s')
plt.plot(x, y_huge, label='Huge', marker='^')
# 设置坐标轴
plt.xscale('log')
plt.xlabel('10 million images in pre-training')
plt.ylabel('Performance')
plt.legend()
plt.title('Model Performance vs Pre-training Data Size')
plt.show()八、人机交互:视觉指向提示
8.1 什么是视觉指向提示?
视觉指向提示(Visual Referring Prompting) 通俗来说就是"在图片上画圈圈、箭头来告诉AI要看哪里"。这是一种非常自然的人机交互方式,就像我们平时指着图片和别人交流一样。

图3:视觉指向提示示例(原文Figure 50)
分析:你可以在图片上画个圈问"这个杯子里是什么",也可以画个箭头问"这条边有多长"。GPT-4V能准确理解这些视觉提示,并给出针对性的回答。
8.2 生成指向输出:AI也会"指东西"
GPT-4V不仅能理解人类的指向,还能自己生成指向输出。比如你问"蓝色的车在哪里",它会输出蓝色车的边界框坐标,告诉你它在图片的哪个位置。
九、时序与视频理解:AI也能"看视频"
虽然GPT-4V主要处理静态图片,但它能通过分析视频的关键帧来理解视频内容。它能识别动作的先后顺序,预测接下来会发生什么,甚至能定位某个动作发生在哪个帧。
有趣案例:给它一段足球点球的视频帧序列,它能准确指出球员在哪一帧踢到了球,以及守门员有没有扑到球。
十、抽象视觉推理与IQ测试:AI的智商有多高?
论文用人类的IQ测试题来评估GPT-4V的抽象推理能力,包括韦氏成人智力量表和瑞文渐进矩阵。
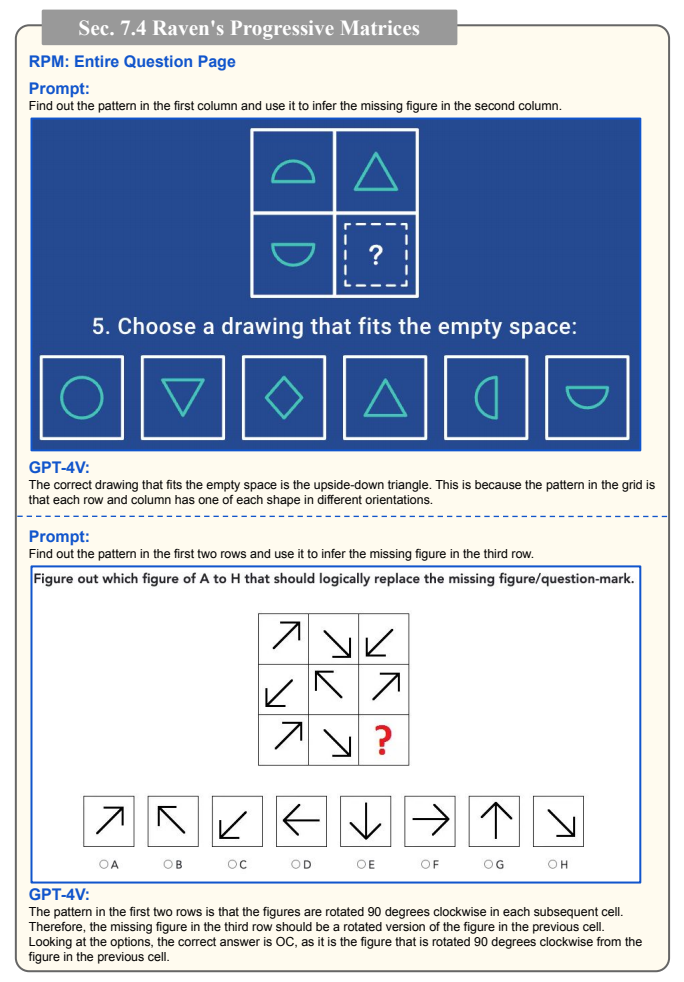
图4:瑞文渐进矩阵测试(原文Figure 62)
分析:瑞文渐进矩阵是一种非语言的智力测试,要求根据图形的规律找出缺失的图形。GPT-4V在这类测试中表现良好,说明它具备较强的抽象推理能力。
十一、情商测试:AI也有"同理心"
11.1 面部表情识别:能看懂你的喜怒哀乐
GPT-4V能准确识别人类的面部表情,包括开心、悲伤、愤怒、恐惧等。
11.2 情感条件输出:能根据情绪调整回答
你可以让GPT-4V用不同的语气描述同一张图片。比如让它用幽默的语气描述一张日落图,或者用恐怖的语气描述一张楼梯图。
十二、新兴应用亮点:GPT-4V能做什么?
12.1 工业应用:缺陷检测与安全检查
- 缺陷检测:给GPT-4V一张产品图片和一张合格产品的参考图片,它能准确找出产品的缺陷。
- 安全检查 :能识别工地上有没有人没戴安全帽,有没有安全隐患。

图5:缺陷检测示例(原文Figure 72)
分析:单张图片时,GPT-4V可能无法判断什么是缺陷。但加入参考图片后,它能准确找出轮胎上的划痕和轮毂的损坏。
12.2 医疗应用:放射报告生成
如前所述,GPT-4V能根据医学图像生成初步的放射报告,大大减轻医生的工作负担。
12.3 具身智能:AI机器人的"大脑"
GPT-4V可以作为机器人的大脑,让机器人看懂周围的环境并完成任务。比如让它去厨房拿一瓶水,它能通过分析摄像头的画面,规划路线,找到冰箱并打开门。
12.4 GUI导航:能操作电脑和手机
GPT-4V能看懂电脑和手机的界面,并模拟人类的操作。比如让它在亚马逊上买一个50-100美元的人体工学键盘,它能一步步完成搜索、筛选、加购和结账的全过程。
十三、LMM驱动的智能体:未来的方向
论文最后探讨了如何进一步增强GPT-4V的能力,构建更强大的LMM智能体:
- 多模态插件:让GPT-4V调用外部工具,比如搜索引擎、计算器、图像生成器。
- 多模态链:把多个任务串联起来,比如先检测图片中的人,再判断他们有没有戴安全帽。
- 自我反思:让GPT-4V自己检查和修正自己的回答。
- 自洽性:多次生成回答,然后用多数投票的方式选出最准确的答案。
- 检索增强:让GPT-4V从数据库中检索相关信息,提高回答的准确性。
十四、结论与展望
GPT-4V的出现标志着多模态大模型时代的正式到来。它在视觉理解、知识推理、人机交互等方面展现出了惊人的能力,为很多行业带来了革命性的变化。
但我们也要清醒地看到,GPT-4V还有很多不足:
- 偶尔会出现"幻觉",生成虚假信息
- 空间定位能力还不够精确
- 对复杂场景的理解还有待提高
- 缺乏实时感知和交互能力
未来,LMM将朝着更强大、更通用、更安全的方向发展。它不仅会成为我们的工作助手,还会融入我们生活的方方面面,改变我们与世界交互的方式。