
🔥小叶-duck:个人主页
❄️个人专栏:《Data-Structure-Learning》《C++入门到进阶&自我学习过程记录》
《算法题讲解指南》--优选算法
《算法题讲解指南》--递归、搜索与回溯算法
《算法题讲解指南》--动态规划算法
✨未择之路,不须回头
已择之路,纵是荆棘遍野,亦作花海遨游
目录
32.最长的斐波那契子序列的长度
题目链接:
题目描述:
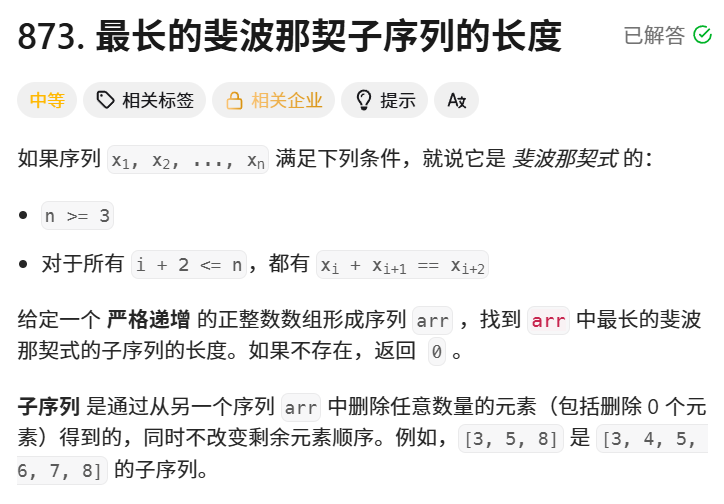
题目示例:

解法(动态规划):
算法思路:
1.状态表示:
对于线性dp,我们可以用「经验+题目要求」来定义状态表示:
i.以某个位置为结尾,巴拉巴拉;
ii.以某个位置为起点,巴拉巴拉。
这里我们选择比较常用的方式,以某个位置为结尾,结合题目要求,定义一个状态表示:
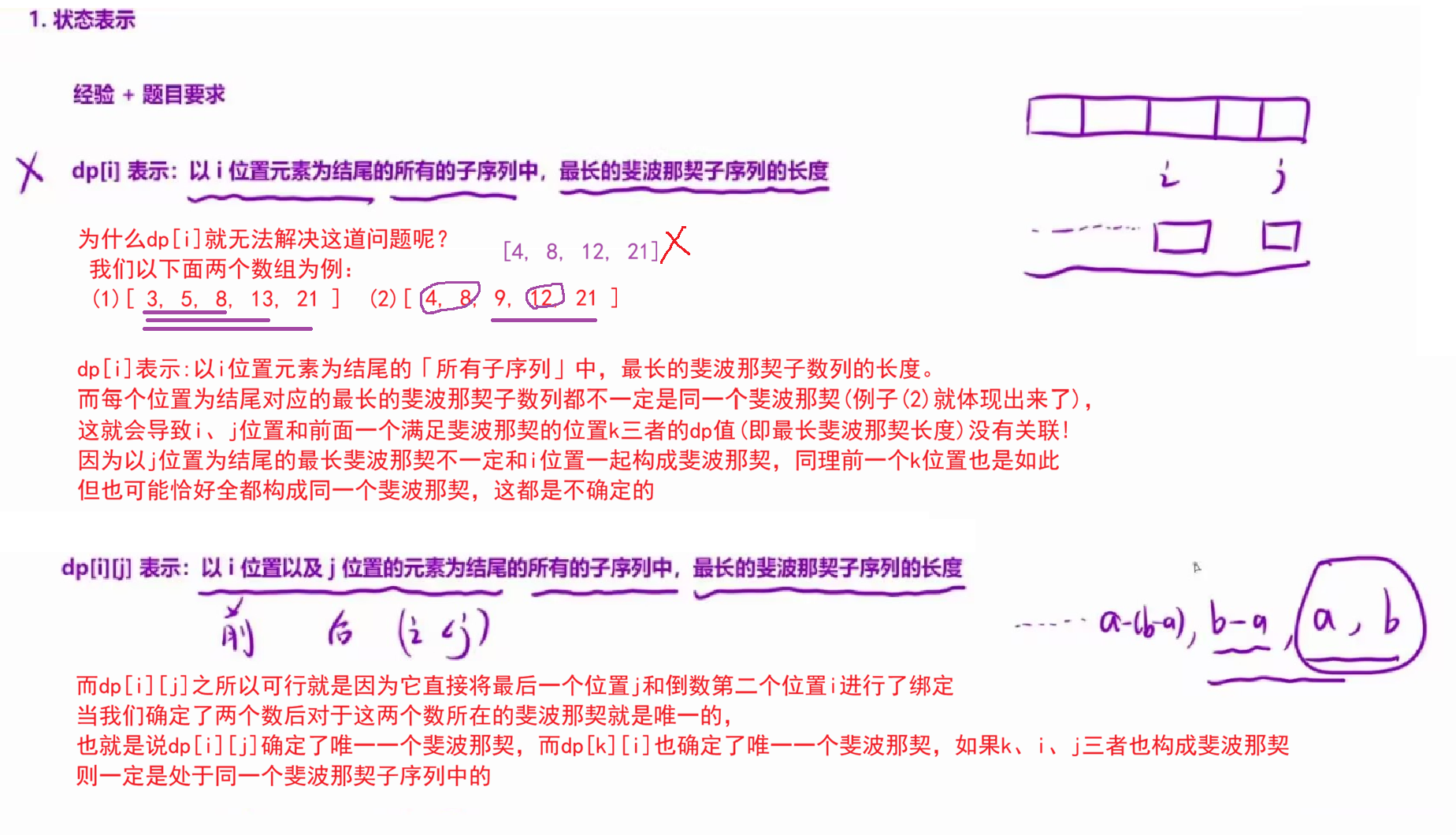
dpi表示:以i位置元素为结尾的「所有子序列」中,最长的斐波那契子数列的长度。
但是这里有一个非常致命的问题,那就是我们无法确定i结尾的斐波那契序列的样子 。这样就会导致我们无法推导状态转移方程 ,因此我们定义的状态表示需要能够确定一个斐波那契序列。
根据斐波那契数列的特性,我们仅需知道序列里面的最后两个元素,就可以确定这个序列的样子。
因此,我们修改我们的状态表示为:
dpij表示:以 i 位置以及 j 位置的元素为结尾的所有的子序列中,最长的斐波那契子序列的长度。规定一下i<j。
2.状态转移方程:
设numsi=b,numsj=c ,那么这个序列的前一个元素就是a=c-b。我们根据a的情况讨论:
i.a存在,下标为k,并且a<b:此时我们需要以k位置以及i位置元素为结尾的最长斐波那契子序列的长度,然后再加上j位置的元素即可。于是dpij=dpki + 1;
ii.a存在,但是b<a<c:此时只能两个元素自己玩了,dpij=2;
iii.a不存在:此时依旧只能两个元素自己玩了,dpij=2。
综上,状态转移方程分情况讨论即可。
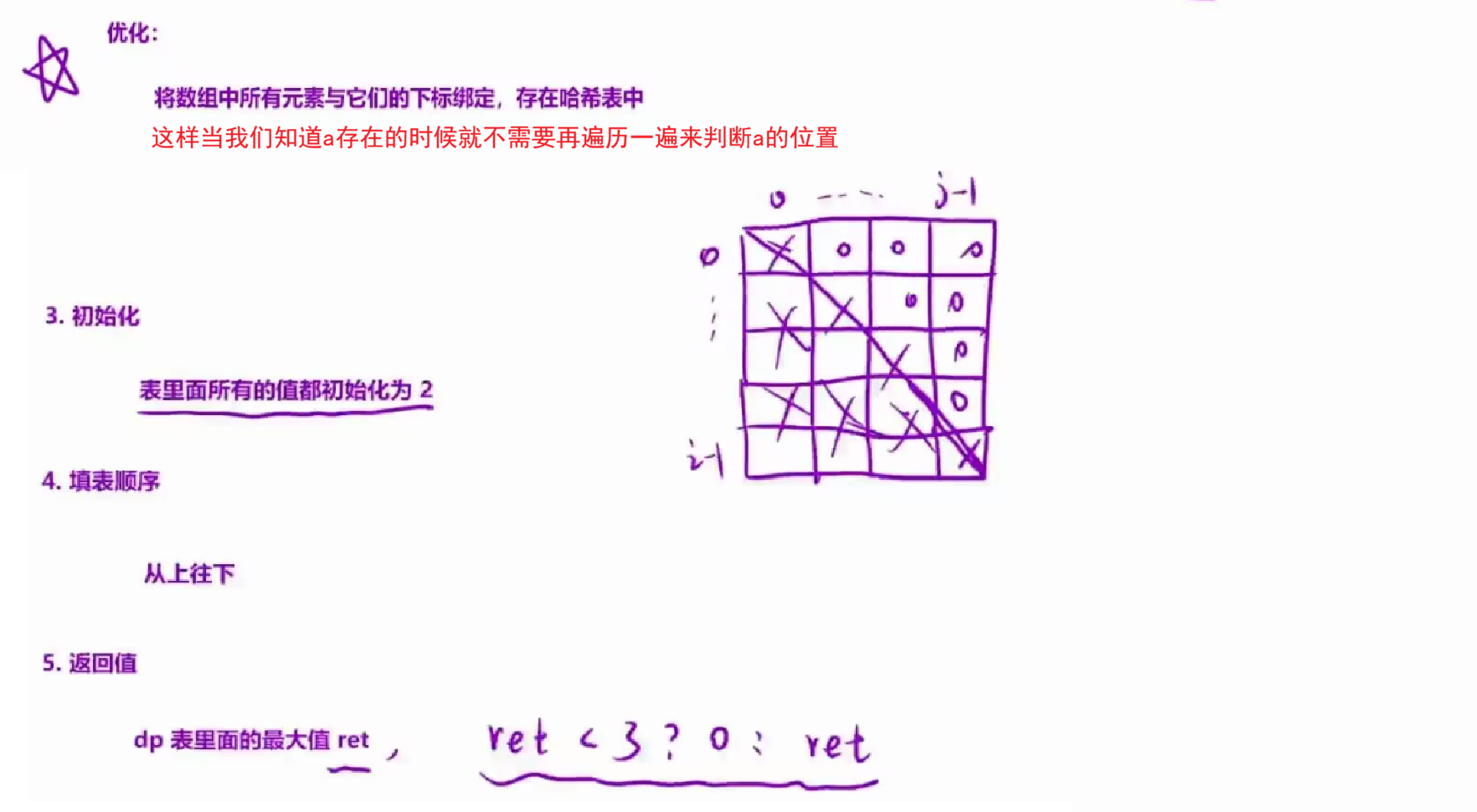
优化点:我们发现,在状态转移方程中,我们需要确定a元素的下标。因此我们可以在dp之前,将所有的「元素+下标」绑定在一起,放到哈希表中。
3.初始化:
可以将表里面的值都初始化为2 。
4.填表顺序:
a.先固定最后一个数;
b.然后枚举倒数第二个数。
5.返回值:
因为不知道最终结果以谁为结尾,因此返回dp表中的最大值ret 。
但是ret可能小于3,小于3的话说明不存在。
因此需要判断一下。
C++算法代码:
cpp
class Solution {
public:
int lenLongestFibSubseq(vector<int>& arr)
{
int n = arr.size();
//将元素和下标进行绑定,这样我们计算出元素也就能快速找到对应的位置,无需进行遍历查找
unordered_map<int, int> hash;
for(int i = 0; i < n; i++)
{
hash[arr[i]] = i;
}
vector<vector<int>> dp(n, vector<int>(n, 2));
//初始化为2的目的是斐波那契构成的最小长度为3,后续的加1操作正好可以满足所有情况
int len = 2;
for(int j = 2; j < n; j++)//固定斐波那契子序列最后一个位置
{
for(int i = j - 1; i >= 1; i--)//固定斐波那契倒数第二个位置
{
int a = arr[j] - arr[i];//获取倒数第三个斐波那契数,判断是否存在
if(hash.count(a))
{
//我们需要保证a < arr[i] < arr[j]三者相对位置不能改变
if(a >= arr[i])
{
//因为数组严格递增,当i位置时a大于等于arr[i],说明i前面所有情况都是如此
//则三者位置不满足要求,无需再往前遍历i了
break;
}
dp[i][j] = dp[hash[a]][i] + 1;
}
len = max(len, dp[i][j]);
}
}
return len == 2 ? 0 : len;
}
};算法总结及流程解析:
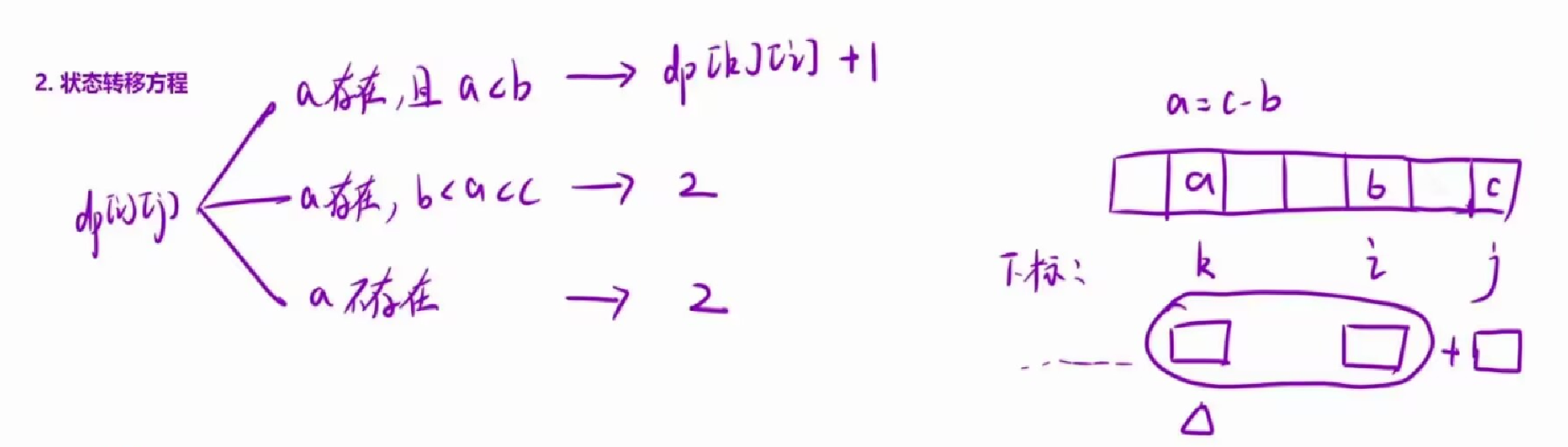
33.最长等差数列
题目链接:
题目描述:

题目示例:

解法(动态规划):
算法思路:
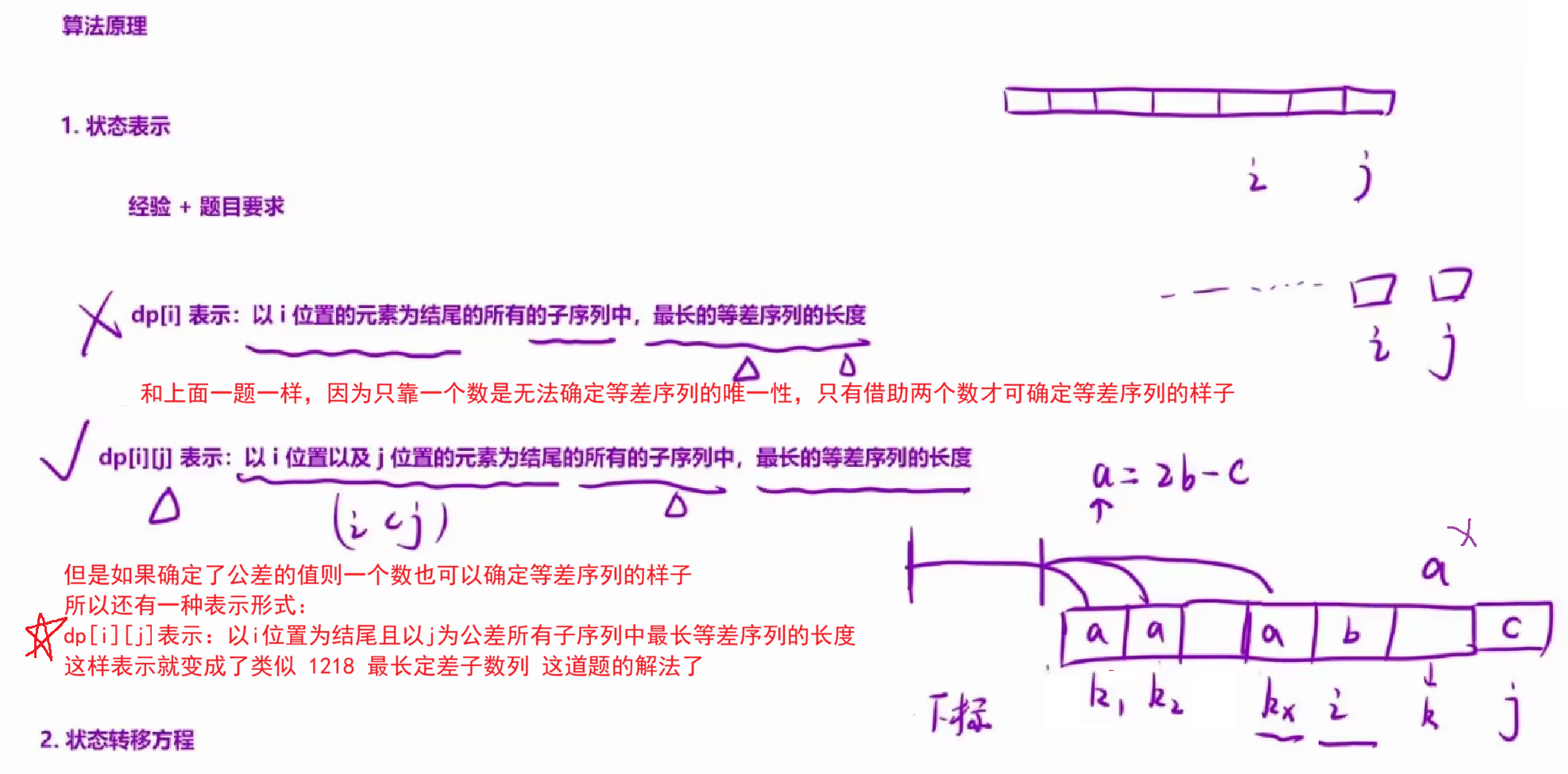
1.状态表示:
对于线性dp,我们可以用「经验+题目要求」来定义状态表示:
i.以某个位置为结尾,巴拉巴拉;
ii.以某个位置为起点,巴拉巴拉。
这里我们选择比较常用的方式,以某个位置为结尾,结合题目要求,定义一个状态表示:
dpi表示:以i位置元素为结尾的「所有子序列」中,最长的等差序列的长度。
但是这里有一个非常致命的问题,那就是我们无法确定结尾的等差序列的样子。这样就会导致我们无法推导状态转移方程,因此我们定义的状态表示需要能够确定一个等差序列。
根据等差序列的特性,我们仅需知道序列里面的最后两个元素,就可以确定这个序列的样子。因此,我们修改我们的状态表示为:
dpij表示:以 i 位置以及 j 位置的元素为结尾的所有的子序列中,最长的等差序列的长度。规定一下i<j。
2.状态转移方程:
设numsi=b,numsj= c ,那么这个序列的前一个元素就是a=2*b-c。我们根据a的情况讨论:
a.a存在,下标为k,并且a<b:此时我们需要以k位置以及i位置元素为结尾的最长等差序列的长度,然后再加上j位置的元素即可。于是dpij=dpki+1 。这里因为会有许多个k,我们仅需离i最近的k即可(离i最近的k所表示的dpki的值一定是大于等于前面的情况) 。因此任何最长的都可以以k为结尾;
b.a存在,但是b<a<c:此时只能两个元素自己玩了,dpij=2 ;
c.a不存在:此时依旧只能两个元素自己玩了,dpij=2。
综上,状态转移方程分情况讨论即可。
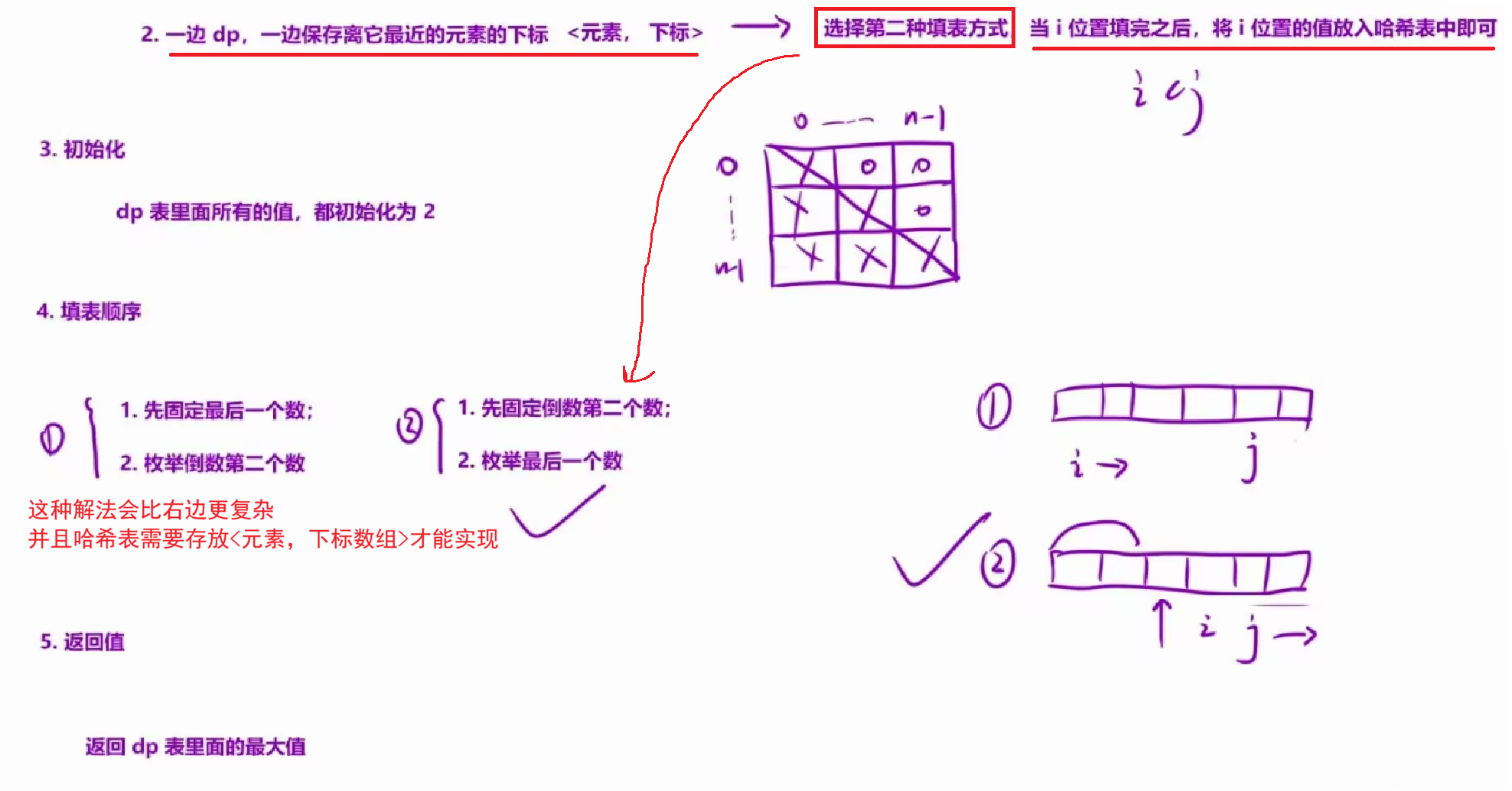
优化点:我们发现,在状态转移方程中,我们需要确定a元素的下标。因此我们可以将所有的元素 + 下标绑定在一起,放到哈希表中,这里有两种策略:
a.在dp之前,放入哈希表中。这是可以的,但是需要将下标形成一个数组放进哈希表中 。这样时间复杂度较高,而且如果在一开始就将所有元素和下标绑定放入哈希表后续遍历查找是会超时的。但是如果按照下面的b策略一边dp一边保存,查找范围就能缩短,是可以通过的。
b.一边dp,一边保存。这种方式,我们仅需保存最近的元素的下标 ,不用保存下标数组 。但是用这种方法的话,我们在遍历顺序那里,需要先固定倒数第二个数,再遍历倒数第一个数。这样就可以在i 使用完时候,将 numsi扔到哈希表中。
3.初始化:
根据实际情况,可以将所有位置初始化为2。
4.填表顺序:
a.先固定倒数第二个数;
b.然后枚举倒数第一个数。
5.返回值:
由于不知道最长的结尾在哪里,因此返回dp表中的最大值。
C++算法代码(解法一):
dpij表示:以i和j位置为结尾(i<j)所有子序列中最长等差序列的长度
先固定最后一个数,再枚举倒数第二个数
cpp
class Solution {
public:
int longestArithSeqLength(vector<int>& nums)
{
//解法一:dp[i][j]表示:以i和j位置为结尾(i<j)所有子序列中最长等差序列的长度
// 先固定最后一个数,再枚举倒数第二个数
int n = nums.size();
unordered_map<int, vector<int>> hash;
//因为会出现多个相同的数在不同的下标中,
//而我们枚举倒数第二个数时需要找到离它最近前一个的倒数第三个数的下标
//如果只用int则可能无法找到枚举当前倒数第二个数离它最近前一个的倒数第三个数的下标
//所以我们需要放在一个数组中存放
hash[nums[0]].push_back(0);
vector<vector<int>> dp(n, vector<int>(n, 2));
int len = 2;
for(int j = 1; j < n; j++)
{
for(int i = 0; i < j; i++)
{
int differ = nums[j] - nums[i];
int a = nums[i] - differ;
if(hash.count(a))
{
int index = -1;
for(int in = hash[a].size() - 1; in >= 0; in--)
{
//找到离i左边最近的a对应的下标
if(hash[a][in] < i)
{
index = in;
break;
}
}
if(index != -1)
{
dp[i][j] = dp[hash[a][index]][i] + 1;
}
}
len = max(len, dp[i][j]);
}
hash[nums[j]].push_back(j);
}
return len;
}
};C++算法代码(解法二):
dpij表示:以i和j位置为结尾(i<j)所有子序列中最长等差序列的长度
先固定倒数第二个数,再枚举最后一个数
cpp
class Solution {
public:
int longestArithSeqLength(vector<int>& nums)
{
//解法二:dp[i][j]表示:以i和j位置为结尾(i<j)所有子序列中最长等差序列的长度
// 先固定倒数第二个数,再枚举最后一个数
int n = nums.size();
unordered_map<int, int> hash;
//当我们固定倒数第二个数,往后枚举最后一个数时
//hash存的倒数第三个数的下标就一定是离倒数第二个数最近的下标(下面代码进行了解释)
hash[nums[0]] = 0;
vector<vector<int>> dp(n, vector<int>(n, 2));
int len = 2;
for(int i = 1; i < n; i++)
{
for(int j = i + 1; j < n; j++)
{
int differ = nums[j] - nums[i];
int a = nums[i] - differ;
if(hash.count(a))
{
dp[i][j] = dp[hash[a]][i] + 1;
}
len = max(len, dp[i][j]);
}
hash[nums[i]] = i;
//倒数第二个数往后走之前,将其元素和下标绑定放入hash中
//这样如果该元素在前面重复出现则下标进行更新
//并且能确定后面当该元素作为倒数第三个数,
//更新后的下标一定是在倒数第二个数的前面而且是最近的
}
return len;
}
};C++算法代码(解法三):
dpij表示:以i位置为结尾且以j为公差所有子序列中最长等差序列的长度
cpp
class Solution {
public:
int longestArithSeqLength(vector<int>& nums)
{
//解法三:dp[i][j]表示:以i位置为结尾且以j为公差所有子序列中最长等差序列的长度
int n = nums.size();
//因为公差范围:-500~500,而下标必须>=0,所以需要进行映射
vector<vector<int>> dp(n, vector<int>(1001, 1));
int len = 1;
//通过二维中的j表示公差,就不需要类似上面两个解法需要两个数才能确定等差序列
//而仅仅一个数也能确定对应的等差序列的样子
//1218 最长定差子数列 就是题目已经给定了公差所以只需要知道一个数(dp[i])就能确定等差序列
//而这道题借助二维的j也就变相类似上面一题的逻辑了
for(int i = 1; i < n; i++)//固定最后一个位置
{
for(int j = 0; j < i; j++)//固定倒数第二个位置
{
int differ = nums[i] - nums[j];
dp[i][differ + 500] = dp[j][differ + 500] + 1;
//上面可以理解为在公差相同(differ)的情况下
//dp[i] = dp[j] + 1 (j < i)
//因为相同公差的情况下最后一个数和倒数第二个数一定是处于同一个等差序列中
//并且因为我们dp初始化为1,如果以j位置为结尾公差为differ的等差序列不存在
//+1长度为2也能满足只有i、j位置两个数构成等差序列的情况
len = max(len, dp[i][differ + 500]);
}
}
return len;
}
};解法三的巧妙之处在于:通过** j 下标表示公差的值** 相当于直接将公差进行了确定,也就保证了仅需要知道一个数就能确定等差序列的样子了。
确定了公差值其实这道题也就类似于前面讲解的1218 最长定差子数列 这道算法题了,因为这道算法题就是题目给定了公差值,所以一维dp就可以实现,而这道题通过二维dp的下标 j 来表示公差的值,解决思路也就和前面那道题类似了。
算法总结及流程解析:

34.等差数列划分II-子序列
题目链接:
题目描述:

题目示例:

解法(动态规划):
算法思路:
1.状态表示:
对于线性dp,我们可以用「经验+题目要求」来定义状态表示:
i.以某个位置为结尾,巴拉巴拉;
ii.以某个位置为起点,巴拉巴拉。
这里我们选择比较常用的方式,以某个位置为结尾,结合题目要求,定义一个状态表示:
dpi表示:以i位置元素为结尾的「所有子序列」中,等差子序列的个数。
但是这里有一个非常致命的问题,那就是我们无法确定i结尾的等差序列的样子。这样就会导致我们无法推导状态转移方程,因此我们定义的状态表示需要能够确定一个等差序列。
根据等差序列的特性,我们仅需知道序列里面的最后两个元素,就可以确定这个序列的样子。因此,我们修改我们的状态表示为:
dpij表示:以 i 位置以及 j 位置的元素为结尾的所有的子序列中,等差子序列的个数。规定一下 i < j。
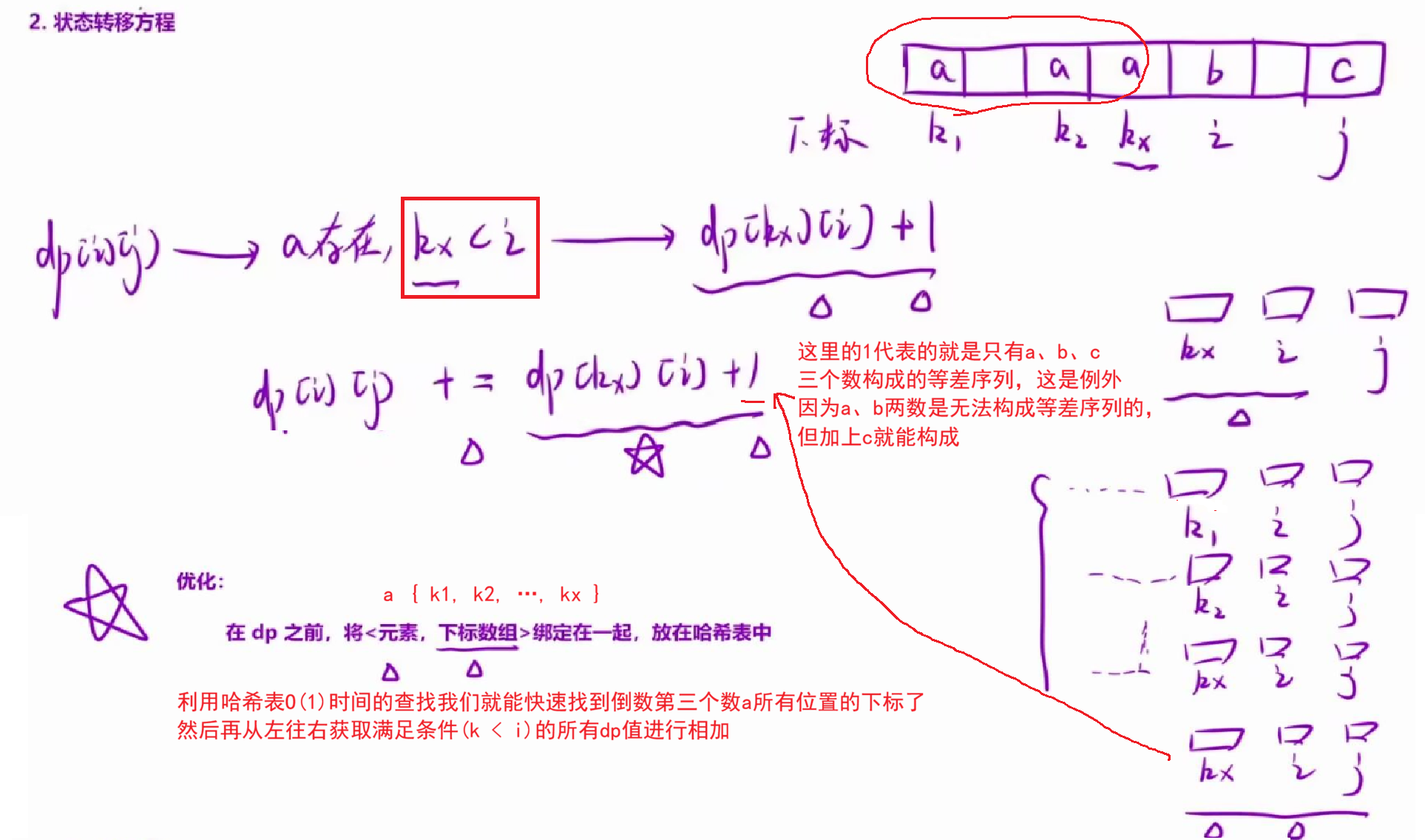
2.状态转移方程:
设numsi=b,numsj=c ,那么这个序列的前一个元素就是a = 2*b-c 。我们根据a的情况讨论:
a.a存在,下标为k,并且a<b:此时我们知道以k元素以及i元素结尾的等差序列的个数dpki,在这些子序列的后面加上j位置的元素依旧是等差序列。但是这里会多出来一个以 k,i,j 位置的元素组成的新的等差序列,因此 dpij = dpki + 1;
b.因为a可能有很多个,我们需要全部累加起来。
综上,dpij += dpki + 1 。
优化点:我们发现,在状态转移方程中,我们需要确定a元素的下标。因此我们可以在 dp 之前,将所有元素+下标数组绑定在一起,放到哈希表中。这里为何要保存下标数组,是因为我们要统计个数,所有的下标都需要统计。
3.初始化:
刚开始是没有等差数列的,因此初始化dp表为 0 。
4.填表顺序:
a.先固定倒数第一个数;
b.然后枚举倒数第二个数。
5.返回值:
我们要统计所有的等差子序列,因此返回dp表中所有元素的和。
C++算法代码:
cpp
class Solution {
public:
int numberOfArithmeticSlices(vector<int>& nums)
{
//解法:dp[i][j]表示:以i和j位置为结尾(i<j)所有子序列中满足等差序列的个数
int n = nums.size();
vector<vector<int>> dp(n, vector<int>(n, 0));
unordered_map<long long, vector<int>> hash;
for(int i = 0; i < n; i++)
{
//因为会出现多个相同的数在不同的下标中,
//所以我们需要放在一个数组中存放
hash[nums[i]].push_back(i);
}
int ret = 0;
for(int j = 2; j < n; j++)//固定倒数第一个数
{
for(int i = 1; i < j; i++)//枚举倒数第二个数
{
long long differ = (long long)nums[j] - nums[i];
long long a = (long long)nums[i] - differ;
if(hash.count(a))
{
for(int index = 0; index < hash[a].size(); index++)
{
//dp[i][j]需要将i位置前面所有dp[k][i]的情况全部相加
//因为倒数第三个数下标k可能存在多个位置,但是必须保证相加的情况为k<i
if(hash[a][index] >= i)
{
break;
}
dp[i][j] += dp[hash[a][index]][i] + 1;
}
}
ret += dp[i][j];
}
}
return ret;
}
};算法总结及流程解析:

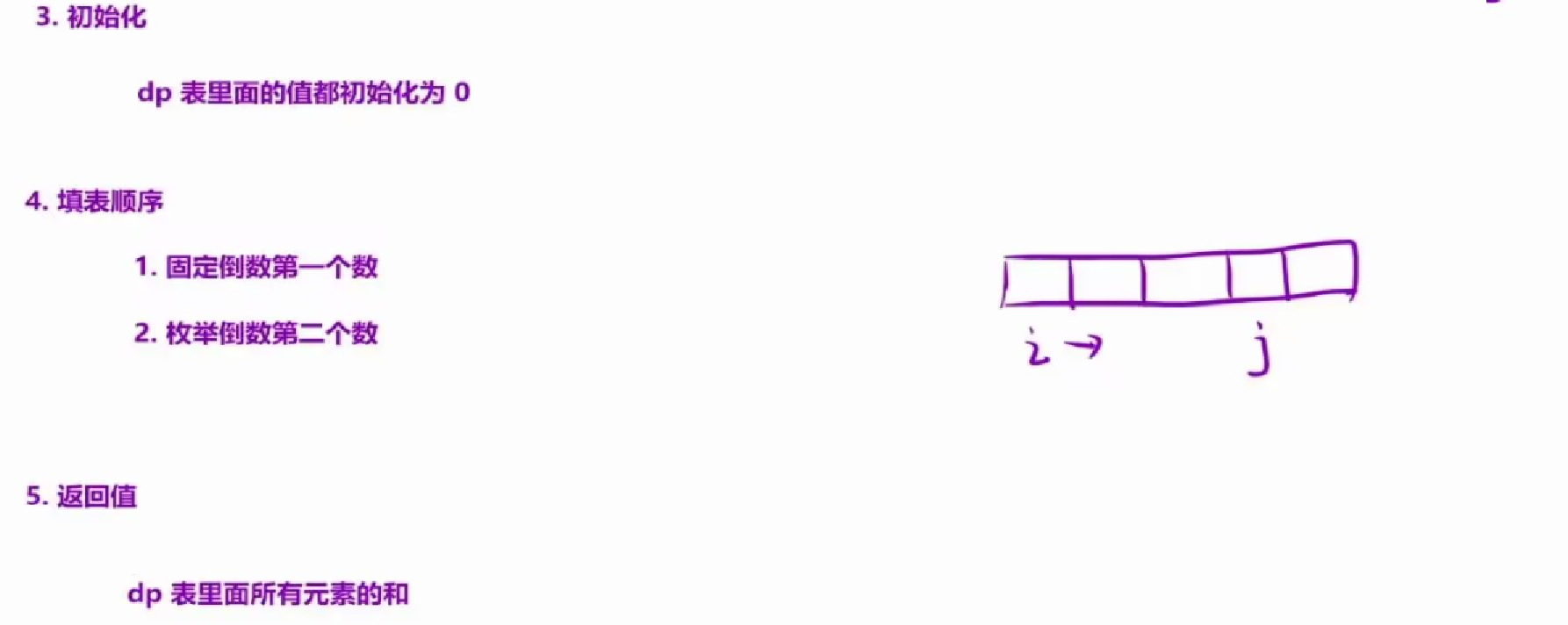
子序列问题总结

结束语
到此,32.最长的斐波那契子序列的长度,33.最长等差数列,34.等差数列划分II-子序列 这三道算法题就讲解完了。**最长斐波那契子序列:使用二维dp记录以i,j为结尾的最长序列长度,通过哈希表优化查找;最长等差数列:提供三种解法,其中最优解法利用公差映射将问题转化为类似定差子序列问题;等差子序列计数:统计所有可能的等差子序列,通过哈希表存储元素下标数组。**希望大家能有所收获!