在MySQL数据库中,事务的ACID特性是数据可靠性的核心保障,而redo log、undo log、binlog这三大日志,就是支撑ACID的"三驾马车"。很多开发者在工作中会遇到这些问题:事务提交后MySQL宕机,数据却没丢;误删数据能通过binlog恢复;并发更新时不会出现数据错乱------这些背后,都是三大日志在协同工作。
多数开发者只知道"有这三个日志",却不清楚它们各自的核心作用、写入机制和刷盘策略,更不懂三者如何配合保证数据一致性,遇到日志相关的线上问题(比如主从同步失败、数据恢复异常)就无从下手。
一、先搞懂核心:三大日志各自的"分工"
我们先通过一个生活场景,快速理解三大日志的作用,避免一开始就陷入复杂的技术细节:
- redo log(重做日志):相当于"记事本",记录你做过的事,就算中途忘记(MySQL宕机),只要看记事本,就能重新做到和之前一样的状态,保证"做过的事不会白做"(事务持久性)。
- undo log(回滚日志):相当于"后悔药",记录你做事情之前的状态,要是做错了(事务回滚),就能通过它恢复到没做之前的样子,保证"做错了能撤回"(事务原子性)。
- binlog(二进制日志):相当于"监控录像",完整记录所有数据变更操作,不仅能用来恢复数据,还能同步给从库,保证"所有操作可追溯、可复制"(主从同步、数据备份)。
简单总结:redo log保"持久",undo log保"原子",binlog保"可追溯、可同步",三者协同,才能实现事务的ACID特性和数据一致性。
二、详解redo log:事务持久性的"守护者"
2.1 核心作用
redo log 是 InnoDB 存储引擎特有的日志(MyISAM 没有),核心作用是保证事务的持久性------即使MySQL在事务提交后宕机,重启后也能通过redo log恢复未写入磁盘的数据,避免数据丢失。
这里要明确一个关键前提:InnoDB 中,数据的修改不会直接写入磁盘(磁盘IO太慢),而是先写入内存中的"缓冲池"(Buffer Pool),之后再通过"刷盘"操作将缓冲池中的数据同步到磁盘。如果在刷盘前MySQL宕机,缓冲池中的数据就会丢失,而redo log 正是用来解决这个问题的------它会记录"数据修改的动作",而非数据本身,就算缓冲池数据丢失,也能通过redo log 重新执行修改动作,恢复数据。
2.2 核心特性:循环写+固定大小
redo log 的存储空间是固定的,默认由两个文件组成(ib_logfile0 和 ib_logfile1),采用"循环写"的方式,类似一个环形缓冲区:
- 有两个指针:write pos(当前写入位置)和 checkpoint(当前刷盘位置)。
- 写入时,从 write pos 开始写,写满一圈后回到开头,覆盖 checkpoint 之后的内容。
- 当 write pos 追上 checkpoint 时,MySQL 会暂停所有写入操作,先将 checkpoint 向前推进(将 redo log 中的内容刷到磁盘),腾出空间后再继续写入。
这种设计的优势是:redo log 体积小、写入速度快(顺序写,比磁盘随机写快得多),能高效保障事务持久性,避免频繁刷盘带来的性能损耗。
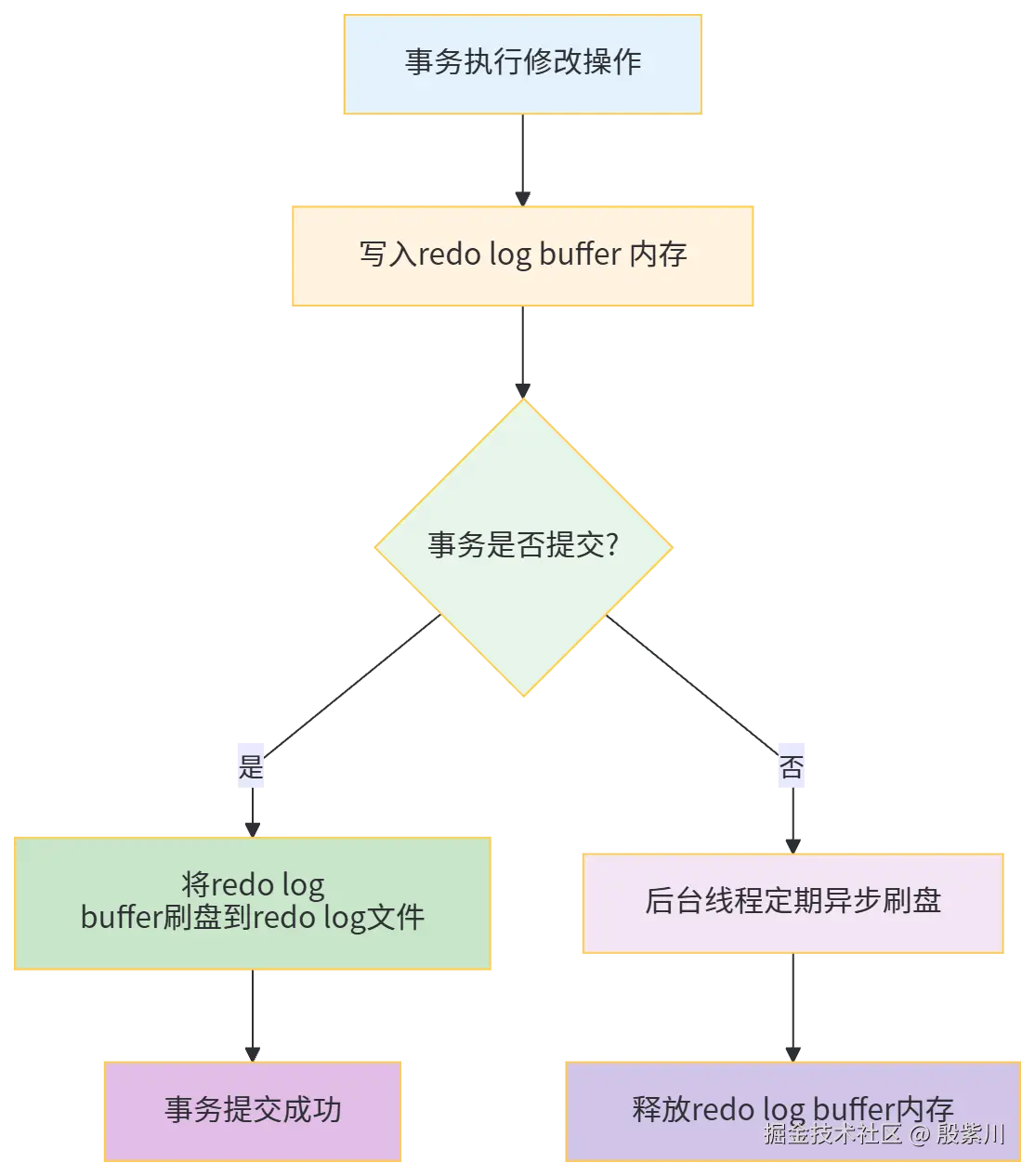
2.3 写入机制(分步骤拆解)
redo log 的写入不是一次性完成的,而是分"三步"进行,每一步都有明确的逻辑,我们结合实例拆解:
步骤1:事务执行时,写入redo log buffer(内存)
当执行数据修改操作(如 insert、update、delete)时,InnoDB 会先将"修改动作"写入内存中的 redo log buffer(redo日志缓冲区),此时数据还在内存中,未持久化到磁盘。
步骤2:事务提交时,触发redo log刷盘(默认策略)
事务提交时,InnoDB 会将 redo log buffer 中的内容刷到磁盘(redo log 文件),这一步是保证事务持久性的关键。这里要注意:事务提交的"成功",是以 redo log 刷盘完成为准,而非数据刷盘完成------只要 redo log 刷盘成功,就算数据还在缓冲池、未写入磁盘,后续MySQL宕机,也能通过 redo log 恢复数据。
步骤3:后台线程异步刷盘(补充)
除了事务提交时的主动刷盘,InnoDB 还有后台线程(如 master thread),会定期将 redo log buffer 中的内容刷到磁盘,避免 redo log buffer 占用过多内存,同时进一步降低宕机丢失数据的风险。
写入机制流程图
2.4 刷盘策略(4种,重点记默认)
redo log 的刷盘策略由参数 innodb_flush_log_at_trx_commit 控制,该参数有3个取值,对应不同的刷盘逻辑,直接决定了"数据安全性"和"性能"的平衡,我们逐一拆解(结合MySQL 8.0 官方文档规范):
| 参数值 | 刷盘策略 | 数据安全性 | 性能 | 适用场景 |
|---|---|---|---|---|
| 0 | 事务提交时,不刷盘,仅写入redo log buffer;后台线程每1秒刷盘1次 | 最低(宕机可能丢失1秒内的数据) | 最高 | 非核心业务,追求极致性能(如日志采集) |
| 1 | 事务提交时,必须将redo log buffer刷盘到磁盘(默认值) | 最高(宕机不丢失已提交事务的数据) | 中等 | 核心业务,追求数据安全(如金融、电商订单) |
| 2 | 事务提交时,将redo log buffer写入操作系统缓存(OS Cache),不直接刷盘;操作系统每1秒将OS Cache刷盘1次 | 中等(宕机可能丢失操作系统缓存中的数据,概率低于0) | 较高 | 兼顾性能和安全的非核心业务(如用户画像) |
关键提醒
- 生产环境中,核心业务必须设置
innodb_flush_log_at_trx_commit = 1,这是保证事务持久性的基础,也是MySQL官方推荐的配置。 - 刷盘的"最小单位"是扇区(磁盘的最小读写单位,通常为512字节),InnoDB 会保证 redo log 的刷盘操作是"原子的"------要么全部刷盘成功,要么全部失败,避免出现"部分刷盘"导致的数据错乱。
2.5 实例:验证redo log的作用(MySQL 8.0)
我们通过"故意宕机"的场景,验证redo log 的恢复能力,步骤如下:
步骤1:准备环境(创建表+插入初始数据)
sql
-- 创建测试数据库
CREATE DATABASE IF NOT EXISTS log_demo;
USE log_demo;
-- 创建测试表(InnoDB引擎,必须用InnoDB,MyISAM无redo log)
CREATE TABLE IF NOT EXISTS user_info (
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(50) NOT NULL,
balance INT NOT NULL DEFAULT 0
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 插入初始数据
INSERT INTO user_info (username, balance) VALUES ('zhangsan', 1000);步骤2:修改数据,不提交事务(观察redo log buffer)
sql
-- 开启事务
START TRANSACTION;
-- 修改数据(将zhangsan的余额改为2000)
UPDATE user_info SET balance = 2000 WHERE username = 'zhangsan';
-- 此时未提交事务,修改仅写入redo log buffer和Buffer Pool,未刷盘步骤3:故意宕机(模拟MySQL异常崩溃)
直接关闭MySQL服务(Windows:服务中停止MySQL;Linux:systemctl stop mysqld),此时:
- Buffer Pool 中的修改(balance=2000)未刷盘,磁盘中数据仍为1000;
- redo log buffer 中的内容(修改动作)未刷盘(因为事务未提交,刷盘策略为1时,仅提交才刷盘)。
步骤4:重启MySQL,观察数据
重启MySQL服务后,执行查询:
ini
USE log_demo;
SELECT * FROM user_info WHERE username = 'zhangsan';结果:balance 仍为 1000,因为事务未提交,redo log 未刷盘,宕机后修改丢失,符合预期。
步骤5:重复步骤2-4,提交事务后宕机
sql
-- 开启事务
START TRANSACTION;
-- 修改数据
UPDATE user_info SET balance = 2000 WHERE username = 'zhangsan';
-- 提交事务(触发redo log刷盘)
COMMIT;
-- 故意宕机,重启MySQL后查询
SELECT * FROM user_info WHERE username = 'zhangsan';结果:balance 为 2000,即使数据未刷盘到磁盘,redo log 已刷盘,重启后MySQL通过redo log 恢复了修改,验证了redo log 的持久性保障作用。
2.6 常见误区(避坑重点)
- 误区1:redo log 记录的是"数据本身"------错!redo log 记录的是"数据修改的动作"(如"将id=1的balance从1000改为2000"),而非修改后的数据,这样体积更小、写入更快。
- 误区2:redo log 可以替代数据刷盘------错!redo log 是"恢复工具",不能替代数据刷盘,后台线程仍会定期将Buffer Pool中的数据刷盘,redo log 仅在宕机时用于恢复未刷盘的数据。
- 误区3:所有存储引擎都有redo log------错!redo log 是 InnoDB 特有的,MyISAM 没有,这也是 MyISAM 不支持事务持久性的核心原因。
三、详解undo log:事务原子性的"后悔药"
3.1 核心作用
undo log 也是 InnoDB 特有的日志,核心作用有两个:
- 保证事务原子性:事务执行过程中,如果发生错误(如代码异常、手动回滚),可以通过undo log 恢复到事务开始前的状态,实现"要么全部成功,要么全部失败"。
- 支持MVCC(多版本并发控制) :InnoDB 的MVCC机制,通过undo log 保存数据的历史版本,让不同事务可以同时读取不同版本的数据,避免幻读、不可重复读等并发问题(后续会详细说明)。
和redo log 不同,undo log 是"逻辑日志",它记录的是"数据修改前的状态",比如执行update操作时,undo log 会记录"修改前的值",回滚时就将数据恢复为这个值;执行delete操作时,undo log 会记录"被删除的数据",回滚时就重新插入这条数据。
3.2 核心特性:逻辑日志+可回滚
-
逻辑日志:undo log 不记录磁盘物理地址,只记录"操作的逆过程",比如:
- insert 操作:undo log 记录"delete 该条数据",回滚时执行delete;
- update 操作:undo log 记录"update 该条数据回滚到修改前的值",回滚时执行该update;
- delete 操作:undo log 记录"insert 该条数据",回滚时执行insert。
-
可回滚:undo log 会为每个事务分配独立的undo空间,事务结束后(提交或回滚),undo log 不会立即删除,而是标记为"可回收",由后台线程(purge thread)异步回收,避免影响当前事务和MVCC的正常使用。
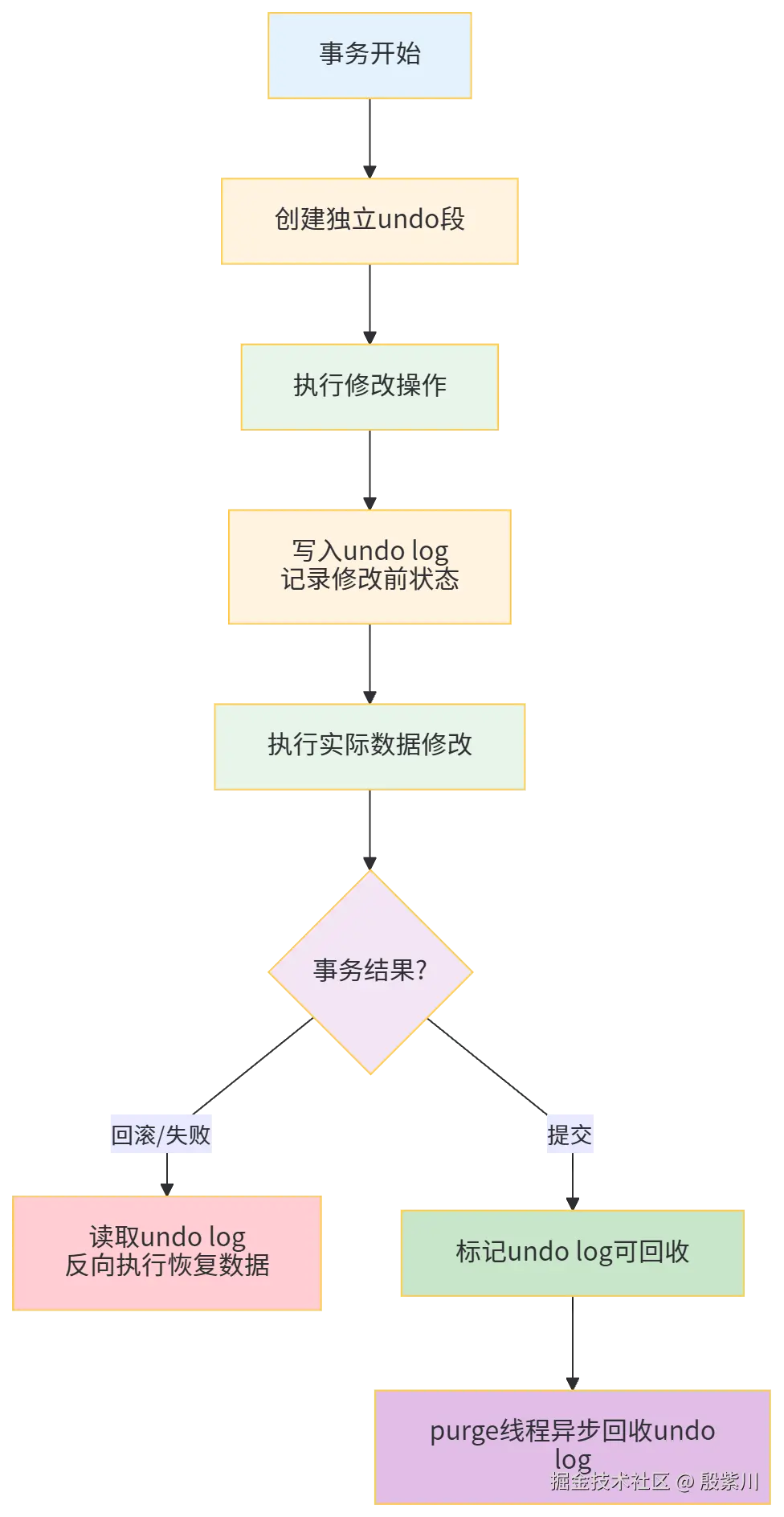
3.3 写入机制(分步骤拆解)
undo log 的写入时机和redo log 类似,但逻辑相反,步骤如下:
步骤1:事务开始时,创建undo段
InnoDB 会为每个事务分配一个独立的undo段(存储在undo表空间中),用于存储该事务的所有undo log 记录。
步骤2:执行修改操作时,同步写入undo log
每执行一次数据修改操作(insert/update/delete),InnoDB 会先将"修改前的状态"写入undo log(先写入内存中的undo buffer,再定期刷盘到undo表空间),然后再执行实际的修改操作。
步骤3:事务回滚时,利用undo log 恢复数据
当执行 ROLLBACK 语句,或事务执行失败时,InnoDB 会读取该事务的undo log,反向执行其中的操作,将数据恢复到事务开始前的状态。
步骤4:事务提交时,标记undo log 可回收
事务提交后,undo log 不会立即删除(因为可能被MVCC用于读取历史版本),而是标记为"可回收",后台的purge线程会定期扫描,将已过期(没有事务再需要读取该版本)的undo log 回收,释放存储空间。
写入机制流程图
3.4 刷盘策略
undo log 的刷盘策略和redo log 类似,由两个参数控制,核心是"异步刷盘为主,同步刷盘为辅",保证性能的同时,避免宕机丢失undo log:
innodb_flush_log_at_trx_commit:该参数同时控制redo log 和 undo log 的刷盘策略(因为undo log 的刷盘依赖redo log 的保障),当参数为1时,undo log 会和redo log 一起刷盘,确保事务提交后,undo log 也能持久化。innodb_undo_log_truncate:开启后,当undo表空间达到指定大小(由innodb_max_undo_log_size控制)时,会自动截断undo log,释放空间(默认开启,MySQL 8.0 新增特性)。
3.5 实例1:事务回滚(验证undo log的原子性保障)
sql
USE log_demo;
-- 开启事务
START TRANSACTION;
-- 插入一条数据
INSERT INTO user_info (username, balance) VALUES ('lisi', 1500);
-- 修改zhangsan的余额
UPDATE user_info SET balance = 2500 WHERE username = 'zhangsan';
-- 查看当前数据(事务内可见)
SELECT * FROM user_info;
-- 回滚事务
ROLLBACK;
-- 再次查看数据(恢复到事务开始前)
SELECT * FROM user_info;执行结果解析
- 事务内查看:能看到 lisi 的记录(balance=1500)和 zhangsan 的余额(2500);
- 回滚后查看:lisi 的记录消失,zhangsan 的余额恢复为2000(之前提交的值),说明undo log 成功恢复了数据,保证了事务原子性。
3.6 实例2:MVCC依赖undo log(验证历史版本读取)
InnoDB 的MVCC机制,通过undo log 保存数据的历史版本,让不同事务可以并行读取,我们用两个事务验证:
事务1(修改数据,不提交)
sql
-- 事务1:开启事务,修改数据
START TRANSACTION;
UPDATE user_info SET balance = 3000 WHERE username = 'zhangsan';
-- 不提交事务事务2(读取数据,查看历史版本)
ini
-- 事务2:开启事务,读取数据(此时事务1未提交,读取的是历史版本)
START TRANSACTION;
SELECT * FROM user_info WHERE username = 'zhangsan';
-- 结果:balance = 2000(undo log 保存的历史版本)
COMMIT;事务1提交后,事务3读取
sql
-- 事务1提交
COMMIT;
-- 事务3:读取数据
START TRANSACTION;
SELECT * FROM user_info WHERE username = 'zhangsan';
-- 结果:balance = 3000(最新版本)
COMMIT;原理解析
事务2读取时,事务1的修改未提交,InnoDB 会通过undo log 找到 zhangsan 余额的历史版本(2000),返回给事务2,这就是MVCC的核心逻辑------undo log 保存历史版本,实现"读不加锁、写不阻塞读",提升并发性能。
3.7 常见误区(避坑重点)
- 误区1:undo log 只用于事务回滚------错!undo log 还有一个核心作用是支持MVCC,没有undo log,InnoDB 就无法实现多版本并发控制,会出现大量锁冲突。
- 误区2:事务提交后,undo log 会立即删除------错!事务提交后,undo log 会被标记为可回收,不会立即删除,因为可能有其他事务需要读取该历史版本(MVCC),只有当所有依赖该undo log 的事务结束后,purge线程才会回收。
- 误区3:undo log 可以替代redo log------错!两者作用完全不同:undo log 负责"回滚"(原子性),redo log 负责"恢复"(持久性),缺一不可。
四、详解binlog:数据可追溯、主从同步的"核心"
4.1 核心作用
binlog(二进制日志)是MySQL 服务器层的日志(所有存储引擎都支持,包括MyISAM和InnoDB),核心作用有两个:
- 数据恢复:通过binlog 可以恢复指定时间点的数据,比如误删表、误更新数据后,能通过binlog 回放操作,恢复数据(弥补redo log 只能恢复未刷盘数据的不足)。
- 主从同步:主库将binlog 发送给从库,从库通过回放binlog 中的操作,保持主从数据一致,这是MySQL 主从架构的核心基础。
和redo log 相比,binlog 有两个关键区别:
- 范围不同:binlog 是服务器层日志,所有存储引擎都支持;redo log 是InnoDB 引擎特有。
- 内容不同:binlog 记录的是"完整的SQL操作"(或数据行的变更),是"逻辑日志";redo log 记录的是"数据修改的动作",是"物理日志"(针对InnoDB 数据页)。
- 写入时机不同:binlog 只在事务提交时写入;redo log 在事务执行过程中就会写入。
4.2 核心特性:追加写+不循环
binlog 采用"追加写"的方式,不会循环覆盖,当一个binlog 文件写满(默认大小1G,可通过参数配置),会自动创建一个新的binlog 文件,文件名按"mysql-bin.000001、mysql-bin.000002"的顺序递增。
这种设计的优势是:可以完整保留所有数据变更记录,便于数据恢复和主从同步,即使某个binlog 文件损坏,也不会影响其他文件的内容。
4.3 三种格式(重点记Row格式)
binlog 有三种记录格式,由参数 binlog_format 控制,不同格式的适用场景不同,MySQL 8.0 默认格式为 Row,这也是生产环境推荐的格式:
1. Statement 格式(语句级)
- 记录内容:完整的SQL语句,比如"UPDATE user_info SET balance=2000 WHERE username='zhangsan'"。
- 优势:体积小,写入速度快,占用存储空间少。
- 劣势:存在"数据不一致"风险,比如SQL语句中包含函数(如NOW()、RAND()),主库执行时函数值和从库执行时可能不同,导致主从数据不一致。
- 适用场景:非核心业务,对数据一致性要求不高,且SQL语句中不包含随机函数、存储过程等。
2. Row 格式(行级)
- 记录内容:数据行的"变更前后的状态",不记录SQL语句本身,比如"将id=1的行,balance从1000改为2000"。
- 优势:数据一致性高,不会出现函数执行不一致的问题,支持细粒度的数据恢复(可恢复单条数据),是主从同步的首选格式。
- 劣势:体积大,写入速度相对较慢,占用存储空间多(比如批量更新1000条数据,会记录1000条行变更)。
- 适用场景:核心业务,对数据一致性要求高,需要主从同步的场景(生产环境首选)。
3. Mixed 格式(混合级)
- 记录内容:自动判断SQL语句类型,简单SQL(如不含函数的insert、update)用Statement格式,复杂SQL(如含函数、存储过程)用Row格式。
- 优势:兼顾体积和一致性,是MySQL 5.7 之前的默认格式。
- 劣势:逻辑复杂,排查问题时难度大,不如Row格式稳定。
- 适用场景:过渡场景,目前已基本被Row格式替代。
格式对比表
| 格式 | 记录内容 | 一致性 | 体积 | 适用场景 |
|---|---|---|---|---|
| Statement | 完整SQL语句 | 低 | 小 | 非核心业务,无复杂SQL |
| Row | 数据行变更前后状态 | 高 | 大 | 核心业务,主从同步 |
| Mixed | 自动切换格式 | 中 | 中 | 过渡场景 |
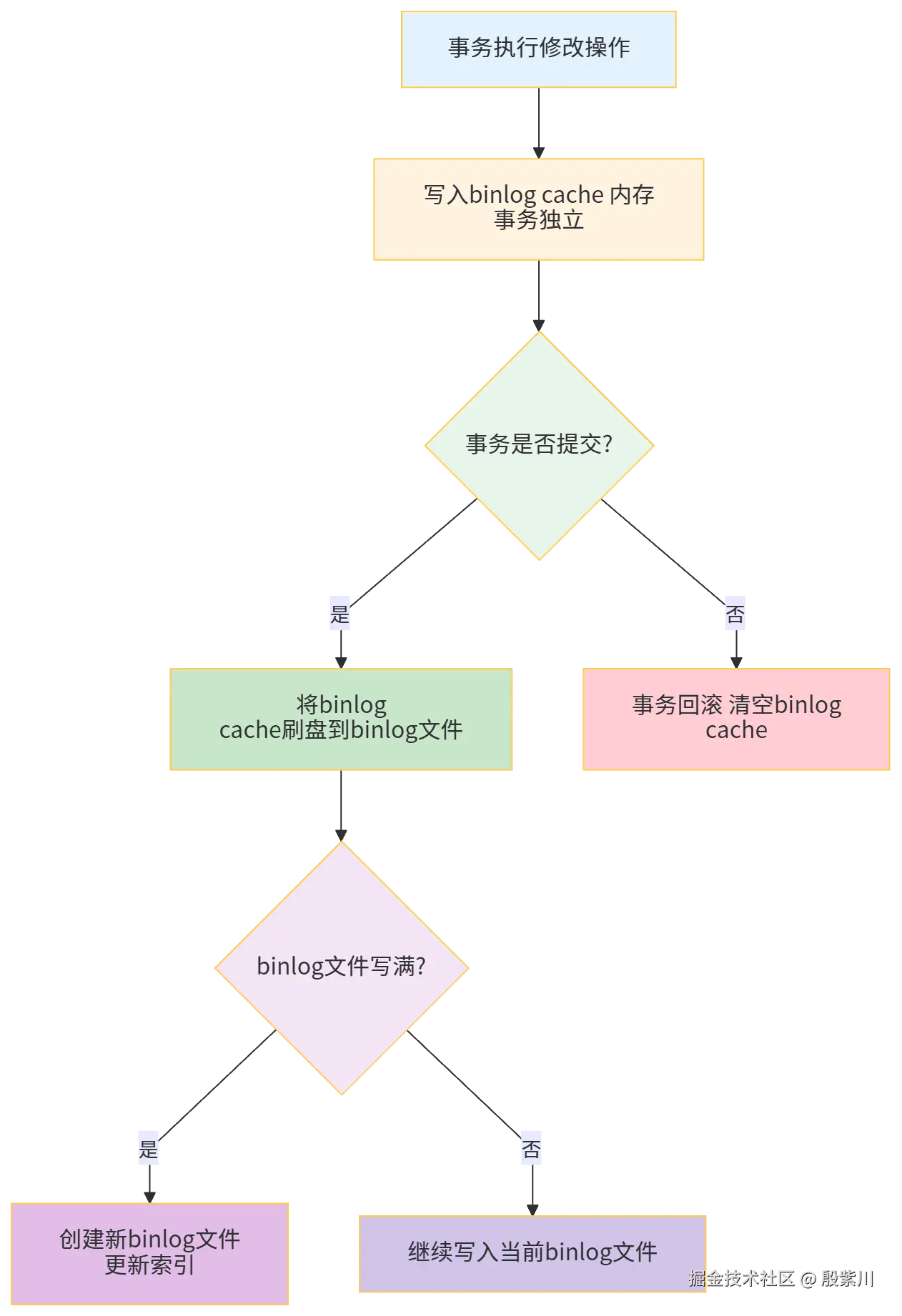
4.4 写入机制(分步骤拆解)
binlog 的写入机制比redo log 简单,核心是"事务提交时一次性写入",步骤如下:
步骤1:事务执行时,记录SQL操作到binlog cache(内存)
当执行数据修改操作时,MySQL 会将该操作的SQL语句(或行变更)写入内存中的 binlog cache(binlog缓冲区),每个事务有独立的binlog cache,避免事务间相互干扰。
步骤2:事务提交时,将binlog cache刷盘到binlog文件
当执行 COMMIT 语句时,MySQL 会将该事务的binlog cache 中的内容一次性刷盘到binlog 文件,此时binlog 写入完成。这里要注意:binlog 的刷盘时机,由参数 sync_binlog 控制。
步骤3:binlog 文件滚动
当当前binlog 文件写满(默认1G),MySQL 会自动创建一个新的binlog 文件,继续写入,同时更新binlog 索引文件(mysql-bin.index),记录所有binlog 文件的路径和顺序。
写入机制流程图
4.5 刷盘策略(由sync_binlog控制,重点记1)
binlog 的刷盘策略由参数 sync_binlog 控制,该参数决定了"binlog cache 何时刷盘到binlog 文件",直接影响数据恢复和主从同步的可靠性,有3个常见取值:
| 参数值 | 刷盘策略 | 数据安全性 | 性能 | 适用场景 |
|---|---|---|---|---|
| 0 | 事务提交时,不刷盘,仅写入binlog cache;操作系统定期将binlog cache刷盘(由操作系统控制) | 最低(宕机可能丢失多个事务的binlog) | 最高 | 非核心业务,追求极致性能 |
| 1 | 事务提交时,必须将binlog cache刷盘到binlog文件(默认值,生产环境推荐) | 最高(宕机不丢失已提交事务的binlog) | 中等 | 核心业务,主从同步场景 |
| N(N>1) | 事务提交时,将binlog cache写入操作系统缓存;每累积N个事务,再将操作系统缓存刷盘到binlog文件 | 中等(宕机可能丢失N-1个事务的binlog) | 较高 | 兼顾性能和安全的非核心业务 |
关键提醒
- 生产环境中,核心业务必须设置
sync_binlog = 1,同时配合innodb_flush_log_at_trx_commit = 1,这是保证"数据一致性+主从同步可靠"的基础,称为MySQL的"双1配置"。 - 当
sync_binlog = 1时,binlog 的刷盘是"同步的",会增加一定的性能损耗,但能确保binlog 不丢失,避免主从同步数据不一致。
4.6 实例1:查看binlog文件,解析数据变更
步骤1:开启binlog(默认开启,MySQL 8.0)
查看binlog 是否开启:
sql
SHOW VARIABLES LIKE 'log_bin';
-- 结果:ON 表示开启,OFF 表示关闭查看binlog 文件列表:
sql
SHOW BINARY LOGS;
-- 结果:显示所有binlog文件,包括文件名、大小、创建时间步骤2:执行数据修改,查看binlog内容
sql
-- 执行修改操作
USE log_demo;
START TRANSACTION;
UPDATE user_info SET balance = 3500 WHERE username = 'zhangsan';
COMMIT;
-- 查看最新的binlog文件(替换为实际文件名)
SHOW BINLOG EVENTS IN 'mysql-bin.000001';步骤3:解析binlog内容(Row格式)
由于binlog 是二进制格式,无法直接查看,需要用 mysqlbinlog 工具解析(命令行执行):
ini
# 解析指定binlog文件,输出为SQL格式(替换为实际文件名)
mysqlbinlog --base64-output=decode-rows -v mysql-bin.000001解析结果关键内容(简化)
shell
# 事务开始
BEGIN
# 数据行变更(Row格式):将zhangsan的balance从3000改为3500
### UPDATE log_demo.user_info
### WHERE
### id=1
### username='zhangsan'
### balance=3000
### SET
### balance=3500
# 事务提交
COMMIT从解析结果可以看到,Row格式的binlog 记录了数据行变更前后的状态,便于精准恢复数据。
4.7 实例2:通过binlog恢复误删数据
假设我们误删了 user_info 表中的 lisi 记录,通过binlog 恢复,步骤如下:
步骤1:找到误删操作对应的binlog位置
ini
# 解析binlog文件,查找delete操作(替换为实际文件名)
mysqlbinlog --base64-output=decode-rows -v mysql-bin.000001 | grep -i delete步骤2:记录误删操作的起始和结束位置
假设解析结果中,误删操作的起始位置为 156,结束位置为 320(实际位置以自己的binlog为准)。
步骤3:执行binlog回放,恢复数据
arduino
# 回放binlog,恢复误删数据(从起始位置前1位开始,到结束位置前1位结束,避免重复执行误删操作)
mysqlbinlog --start-position=100 --stop-position=155 mysql-bin.000001 | mysql -u root -p步骤4:验证恢复结果
ini
USE log_demo;
SELECT * FROM user_info WHERE username = 'lisi';
-- 结果:lisi 的记录被恢复,说明binlog 恢复成功4.8 常见误区(避坑重点)
- 误区1:binlog 是InnoDB 特有------错!binlog 是MySQL 服务器层的日志,所有存储引擎都支持,包括MyISAM,这也是MyISAM 能通过binlog 恢复数据的原因。
- 误区2:binlog 写入后,数据就一定安全------错!binlog 的安全性由 sync_binlog 参数控制,当 sync_binlog = 0 时,binlog 可能丢失,只有设置为1,才能保证提交后binlog 不丢失。
- 误区3:binlog 可以替代redo log------错!binlog 负责数据恢复和主从同步,redo log 负责事务持久性,两者作用互补,缺一不可。比如,MySQL 宕机后,先通过redo log 恢复未刷盘的数据,再通过binlog 恢复未提交的事务(如果有)。
五、三大日志协同工作:如何保证事务持久性与数据一致性?
前面我们分别讲解了三大日志的核心作用、写入机制和刷盘策略,现在重点拆解它们如何协同工作,共同保证事务的ACID特性和数据一致性。
5.1 核心协同逻辑(事务提交全流程)
事务从执行到提交,三大日志的协同步骤如下(以InnoDB 引擎、双1配置为例),这也是MySQL 保证数据一致性的核心流程:
流程图

步骤详解(关键重点)
-
事务执行修改操作时,先写入undo log(保证可回滚),再写入redo log buffer(保证宕机可恢复),最后写入binlog cache(保证可追溯、可同步)------这三步都是在内存中完成,速度极快,不影响事务执行性能。
-
事务提交时,先刷盘binlog,再刷盘redo log(这个顺序是核心,不能颠倒):
- 为什么先刷binlog?因为binlog 用于主从同步和数据恢复,如果先刷redo log,再刷binlog,此时MySQL 宕机,redo log 已刷盘(事务标记为提交),但binlog 未刷盘,主从同步时从库会缺失该事务,导致主从数据不一致。
- 先刷binlog,再刷redo log,即使MySQL 宕机,redo log 未刷盘,事务也不会被标记为提交,主从同步不会受影响,重启后通过redo log 恢复未刷盘的数据即可。
-
刷盘完成后,事务标记为提交成功,此时即使MySQL 宕机,数据也不会丢失(redo log 已刷盘),主从同步也能正常进行(binlog 已刷盘)。
-
事务提交后,后台线程异步将Buffer Pool 中的数据刷盘到磁盘数据文件,同时异步回收undo log,不影响当前事务的执行效率。
5.2 宕机恢复时的协同逻辑
当MySQL 宕机后,重启时会通过三大日志协同恢复数据,步骤如下:
- 首先读取redo log,将未刷盘到磁盘的数据恢复到Buffer Pool(保证事务持久性);
- 然后读取binlog,对比redo log 中的事务,确保所有已提交的事务都有对应的binlog 记录(保证主从同步一致性);
- 最后,清理未提交事务的redo log 和binlog,通过undo log 回滚未提交的事务(保证事务原子性);
- 完成恢复后,MySQL 正常启动,后台线程继续执行数据刷盘和undo log 回收操作。
5.3 主从同步时的协同逻辑
主从同步的核心,是三大日志在主库和从库之间的协同工作,步骤如下(以Row格式binlog为例):
架构图
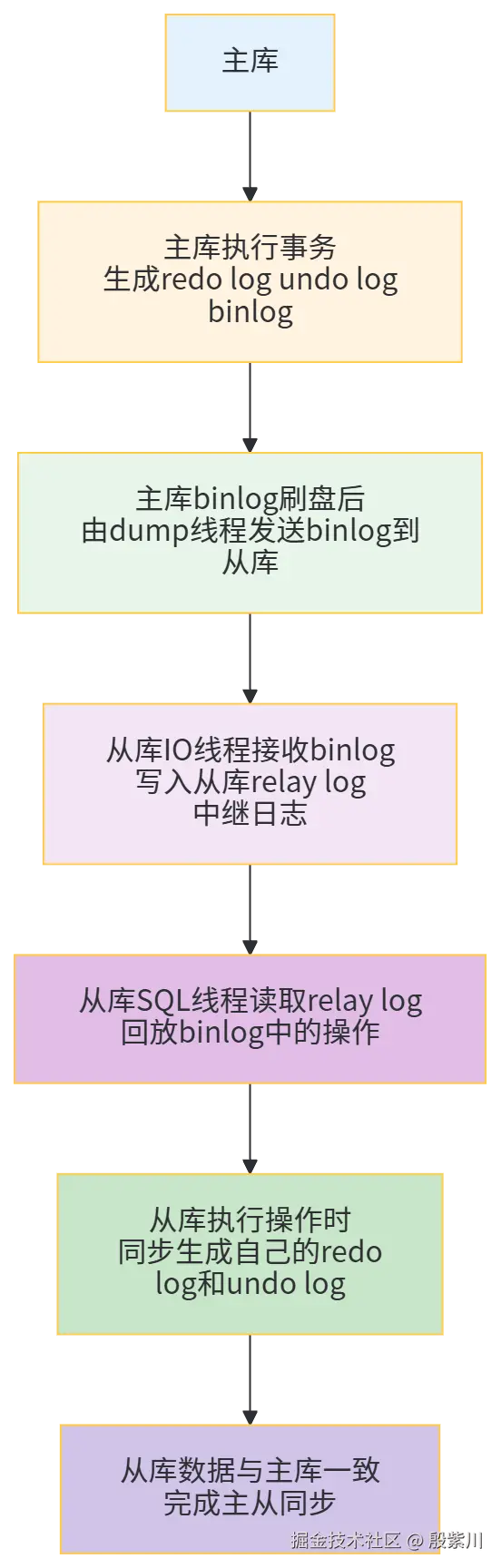
协同细节(重点)
- 主库:事务提交时,先刷binlog,再刷redo log,确保binlog 完整、可同步;
- 主库的dump线程:负责将binlog 发送给从库,不会影响主库的正常操作(异步发送);
- 从库的relay log:相当于"中转日志",接收主库的binlog 后,不会直接执行,而是由SQL线程异步回放,避免影响从库的查询性能;
- 从库:回放binlog 时,会同步生成自己的redo log 和undo log,保证从库自身的事务原子性和持久性,即使从库宕机,也能通过自身的日志恢复数据;
- 关键保障:主库的binlog 是Row格式,确保从库回放时数据一致,不会出现函数执行不一致的问题。
5.4 实例:Java + MyBatis-Plus 实战,验证三大日志协同(JDK 17)
我们用Java 代码实现一个简单的转账功能,验证三大日志的协同工作。
第一步:pom.xml 依赖
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.jam.demo</groupId>
<artifactId>mysql-log-demo</artifactId>
<version>1.0.0</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.4</version>
<relativePath/>
</parent>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<mybatis-plus.version>3.5.5.1</mybatis-plus.version>
<fastjson2.version>2.0.45</fastjson2.version>
<swagger.version>3.0.0</swagger.version>
</properties>
<dependencies>
<!-- Spring Boot Web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring Boot 事务 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- MyBatis-Plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<!-- MySQL 驱动 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<!-- Lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
<scope>provided</scope>
</dependency>
<!-- FastJSON2 -->
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>${fastjson2.version}</version>
</dependency>
<!-- Google Guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>33.1.0-jre</version>
</dependency>
<!-- Swagger3 -->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-boot-starter</artifactId>
<version>${swagger.version}</version>
</dependency>
<!-- 测试 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>第二步:application.yml 配置(双1配置,开启binlog)
yaml
spring:
datasource:
url: jdbc:mysql://localhost:3306/log_demo?useUnicode=true&characterEncoding=utf8mb4&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: root(替换为自己的MySQL密码)
driver-class-name: com.mysql.cj.jdbc.Driver
# 事务配置
transaction:
default-timeout: 30000
# MyBatis-Plus 配置
mybatis-plus:
mapper-locations: classpath:mapper/**/*.xml
type-aliases-package: com.jam.demo.entity
configuration:
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# MySQL 日志配置(双1配置)
server:
port: 8080
# 自定义配置(binlog 相关)
mysql:
binlog:
enabled: true
format: ROW
sync-binlog: 1
innodb:
flush-log-at-trx-commit: 1第三步:实体类(UserInfo)
kotlin
package com.jam.demo.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import java.io.Serializable;
/**
* 用户信息实体类
* @author ken
*/
@Data
@TableName("user_info")
@ApiModel(value = "UserInfo对象", description = "用户信息表")
public class UserInfo implements Serializable {
private static final long serialVersionUID = 1L;
@ApiModelProperty(value = "主键ID")
@TableId(type = IdType.AUTO)
private Integer id;
@ApiModelProperty(value = "用户名")
private String username;
@ApiModelProperty(value = "余额")
private Integer balance;
}第四步:Mapper 接口(UserInfoMapper)
java
package com.jam.demo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.jam.demo.entity.UserInfo;
import org.apache.ibatis.annotations.Mapper;
/**
* 用户信息Mapper接口
* @author ken
*/
@Mapper
public interface UserInfoMapper extends BaseMapper<UserInfo> {
}第五步:Service 接口及实现(编程式事务)
typescript
package com.jam.demo.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.jam.demo.entity.UserInfo;
import io.swagger.annotations.ApiOperation;
/**
* 用户信息Service接口
* @author ken
*/
public interface UserInfoService extends IService<UserInfo> {
/**
* 转账操作
* @param fromUsername 转出用户名
* @param toUsername 转入用户名
* @param amount 转账金额
* @return 转账是否成功
*/
@ApiOperation(value = "转账操作", notes = "实现两个用户之间的转账,保证事务一致性")
boolean transfer(String fromUsername, String toUsername, Integer amount);
}
java
package com.jam.demo.service.impl;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.jam.demo.entity.UserInfo;
import com.jam.demo.mapper.UserInfoMapper;
import com.jam.demo.service.UserInfoService;
import com.google.common.collect.Maps;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.TransactionStatus;
import org.springframework.transaction.support.DefaultTransactionDefinition;
import org.springframework.util.ObjectUtils;
import org.springframework.util.StringUtils;
import java.util.Map;
/**
* 用户信息Service实现类(编程式事务)
* @author ken
*/
@Service
@Slf4j
public class UserInfoServiceImpl extends ServiceImpl<UserInfoMapper, UserInfo> implements UserInfoService {
@Autowired
private UserInfoMapper userInfoMapper;
@Autowired
private PlatformTransactionManager transactionManager;
/**
* 转账操作,采用编程式事务控制,保证原子性
* @param fromUsername 转出用户名
* @param toUsername 转入用户名
* @param amount 转账金额
* @return 转账是否成功
*/
@Override
public boolean transfer(String fromUsername, String toUsername, Integer amount) {
// 1. 参数校验
StringUtils.hasText(fromUsername, "转出用户名不能为空");
StringUtils.hasText(toUsername, "转入用户名不能为空");
if (ObjectUtils.isEmpty(amount) || amount <= 0) {
log.error("转账金额异常,金额:{}", amount);
throw new IllegalArgumentException("转账金额必须大于0");
}
if (fromUsername.equals(toUsername)) {
log.error("转出用户名与转入用户名不能相同");
throw new IllegalArgumentException("转出用户名与转入用户名不能相同");
}
// 2. 编程式事务定义
DefaultTransactionDefinition transactionDefinition = new DefaultTransactionDefinition();
// 事务隔离级别:读已提交(MySQL默认)
transactionDefinition.setIsolationLevel(DefaultTransactionDefinition.ISOLATION_READ_COMMITTED);
// 事务传播行为: REQUIRED(默认)
transactionDefinition.setPropagationBehavior(DefaultTransactionDefinition.PROPAGATION_REQUIRED);
TransactionStatus transactionStatus = transactionManager.getTransaction(transactionDefinition);
try {
// 3. 查询转出用户和转入用户
UserInfo fromUser = userInfoMapper.selectOne(new LambdaQueryWrapper<UserInfo>()
.eq(UserInfo::getUsername, fromUsername));
UserInfo toUser = userInfoMapper.selectOne(new LambdaQueryWrapper<UserInfo>()
.eq(UserInfo::getUsername, toUsername));
// 4. 校验用户是否存在、余额是否充足
if (ObjectUtils.isEmpty(fromUser)) {
log.error("转出用户不存在,用户名:{}", fromUsername);
throw new RuntimeException("转出用户不存在");
}
if (ObjectUtils.isEmpty(toUser)) {
log.error("转入用户不存在,用户名:{}", toUsername);
throw new RuntimeException("转入用户不存在");
}
if (fromUser.getBalance() < amount) {
log.error("转出用户余额不足,用户名:{},余额:{},转账金额:{}", fromUsername, fromUser.getBalance(), amount);
throw new RuntimeException("转出用户余额不足");
}
// 5. 执行转账操作(扣减转出用户余额,增加转入用户余额)
fromUser.setBalance(fromUser.getBalance() - amount);
userInfoMapper.updateById(fromUser);
log.info("转出用户余额扣减成功,用户名:{},扣减后余额:{}", fromUsername, fromUser.getBalance());
// 模拟异常(测试事务回滚,可注释)
// int i = 1 / 0;
toUser.setBalance(toUser.getBalance() + amount);
userInfoMapper.updateById(toUser);
log.info("转入用户余额增加成功,用户名:{},增加后余额:{}", toUsername, toUser.getBalance());
// 6. 提交事务(触发binlog和redo log刷盘)
transactionManager.commit(transactionStatus);
log.info("转账事务提交成功,转出用户:{},转入用户:{},转账金额:{}", fromUsername, toUsername, amount);
return true;
} catch (Exception e) {
// 7. 回滚事务(利用undo log 恢复数据)
transactionManager.rollback(transactionStatus);
log.error("转账事务回滚,异常信息:{}", e.getMessage(), e);
return false;
}
}
}第六步:Controller 层(Swagger3 注解)
less
package com.jam.demo.controller;
import com.jam.demo.service.UserInfoService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import io.swagger.annotations.ApiParam;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
/**
* 用户信息Controller
* @author ken
*/
@RestController
@RequestMapping("/user")
@Api(tags = "用户信息接口", description = "包含转账、查询等操作,验证MySQL三大日志协同")
public class UserInfoController {
@Autowired
private UserInfoService userInfoService;
/**
* 转账接口
*/
@PostMapping("/transfer")
@ApiOperation(value = "转账操作", notes = "实现两个用户之间的转账,事务由编程式控制")
public String transfer(
@ApiParam(value = "转出用户名", required = true) @RequestParam String fromUsername,
@ApiParam(value = "转入用户名", required = true) @RequestParam String toUsername,
@ApiParam(value = "转账金额", required = true, example = "100") @RequestParam Integer amount) {
boolean result = userInfoService.transfer(fromUsername, toUsername, amount);
return result ? "转账成功" : "转账失败";
}
}第七步:启动类
kotlin
package com.jam.demo;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import springfox.documentation.oas.annotations.EnableOpenApi;
/**
* 启动类
* @author ken
*/
@SpringBootApplication
@MapperScan("com.jam.demo.mapper")
@EnableOpenApi
public class MysqlLogDemoApplication {
public static void main(String[] args) {
SpringApplication.run(MysqlLogDemoApplication.class, args);
}
}实例验证步骤
- 启动Spring Boot 项目,访问 Swagger3 地址:http://localhost:8080/swagger-ui/index.html
- 调用
/user/transfer接口,传入参数:fromUsername=zhangsan,toUsername=lisi,amount=500 - 查看数据库数据:zhangsan 余额变为 3000(3500-500),lisi 余额变为 2000(1500+500),事务提交成功。
- 查看binlog:能看到转账相关的两行update操作(Row格式)。
- 模拟异常:取消Service 中"int i = 1 / 0;"的注释,再次调用接口,转账失败,数据恢复到转账前的状态(undo log 起作用)。
- 模拟宕机:在事务提交后,关闭MySQL 服务,重启后数据依然存在(redo log 起作用)。
协同逻辑解析
- 转账过程中,执行update操作时,InnoDB 会自动写入undo log(记录修改前的余额)和redo log buffer(记录修改动作),同时MySQL 写入binlog cache(记录行变更)。
- 事务提交时,先刷盘binlog,再刷盘redo log,确保binlog 和redo log 都完整持久化。
- 若出现异常(如代码报错),事务回滚,通过undo log 恢复到转账前的状态,保证原子性。
- 若MySQL 宕机,重启后通过redo log 恢复未刷盘的数据,通过binlog 保证主从同步一致性。
5.5 易混淆点区分
| 对比维度 | redo log | undo log | binlog |
|---|---|---|---|
| 所属层级 | InnoDB 引擎层 | InnoDB 引擎层 | MySQL 服务器层 |
| 核心作用 | 保证事务持久性(宕机恢复) | 保证事务原子性(回滚)、支持MVCC | 数据恢复、主从同步 |
| 日志类型 | 物理日志(记录数据页修改动作) | 逻辑日志(记录修改前状态) | 逻辑日志(记录SQL/行变更) |
| 写入时机 | 事务执行过程中持续写入 | 事务执行过程中持续写入 | 事务提交时一次性写入 |
| 写入方式 | 循环写(固定大小) | 追加写(可回收) | 追加写(不循环) |
| 适用引擎 | 仅InnoDB | 仅InnoDB | 所有引擎 |
| 刷盘策略 | 由 innodb_flush_log_at_trx_commit 控制 | 依赖redo log 刷盘策略 | 由 sync_binlog 控制 |
六、生产环境最佳实践
6.1 生产环境核心参数配置(MySQL 8.0 官方推荐)
以下配置均为生产环境核心业务的标准配置,兼顾数据安全性、一致性与性能,所有参数均可在MySQL 8.0中直接执行,静态参数需写入my.cnf/my.ini配置文件重启生效,动态参数可在线修改。
ini
-- ====================== redo log 核心配置 ======================
-- 双1配置核心1:事务提交必须刷盘redo log,保证持久性
SET GLOBAL innodb_flush_log_at_trx_commit = 1;
-- redo log文件组数量,推荐2-4个,避免单文件过大
SET GLOBAL innodb_log_files_in_group = 2;
-- 单个redo log文件大小,推荐4G(最大不超过512G,最小不低于48M),避免频繁checkpoint导致性能抖动
SET GLOBAL innodb_log_file_size = 4294967296;
-- redo log缓冲区大小,高并发场景推荐64M,减少缓冲区满导致的刷盘阻塞
SET GLOBAL innodb_log_buffer_size = 67108864;
-- ====================== binlog 核心配置 ======================
-- 开启binlog,主从架构与数据恢复必备
SET GLOBAL log_bin = ON;
-- 双1配置核心2:事务提交必须刷盘binlog,保证主从一致性
SET GLOBAL sync_binlog = 1;
-- binlog格式强制使用ROW,生产环境唯一推荐格式,杜绝主从数据不一致
SET GLOBAL binlog_format = ROW;
-- 行级binlog记录模式,MINIMAL仅记录变更的字段,大幅减少binlog体积,推荐生产使用
SET GLOBAL binlog_row_image = MINIMAL;
-- binlog过期自动清理时间,推荐7-30天,根据合规要求调整,避免磁盘占满
SET GLOBAL binlog_expire_logs_seconds = 2592000;
-- 单个binlog文件最大大小,默认1G,高并发场景可调整为2G,减少文件切换开销
SET GLOBAL max_binlog_size = 1073741824;
-- 开启binlog校验,防止网络传输或磁盘损坏导致的binlog损坏
SET GLOBAL binlog_checksum = CRC32;
-- ====================== undo log 核心配置 ======================
-- 开启undo表空间自动截断,解决undo log膨胀问题,MySQL 8.0默认开启
SET GLOBAL innodb_undo_log_truncate = ON;
-- undo表空间最大阈值,超过后触发自动截断,推荐10G
SET GLOBAL innodb_max_undo_log_size = 10737418240;
-- undo表空间数量,高并发场景推荐8个,分散IO压力,减少锁竞争
SET GLOBAL innodb_undo_tablespaces = 8;
-- 回滚段数量,高并发事务场景推荐128个,提升并发处理能力
SET GLOBAL innodb_rollback_segments = 128;6.2 三大日志的监控与运维规范
生产环境中,日志相关的故障90%以上源于监控缺失与不规范运维,以下为必须落地的监控指标与运维规则:
6.2.1 核心监控指标
| 日志类型 | 监控指标 | 告警阈值 | 监控目的 |
|---|---|---|---|
| redo log | 空间使用率 | 超过80%告警 | 避免write pos追上checkpoint,导致写入阻塞 |
| redo log | checkpoint延迟 | 超过100M告警 | 避免刷盘不及时导致的性能抖动与宕机恢复时间过长 |
| binlog | 磁盘占用率 | 超过85%告警 | 避免binlog占满数据盘,导致数据库无法写入 |
| binlog | 主从同步延迟 | 超过30s告警 | 避免主从数据不一致,影响业务与容灾能力 |
| undo log | 表空间大小 | 超过10G告警 | 及时发现undo log膨胀,避免磁盘占用过高与查询性能下降 |
| undo log | 历史版本保留时长 | 超过30min告警 | 避免长事务导致undo log无法回收,引发膨胀 |
6.2.2 强制运维规范
-
binlog清理规范 :绝对禁止手动删除binlog物理文件,必须使用
PURGE BINARY LOGS命令清理,否则会导致binlog索引文件损坏,主从同步直接崩溃。sql-- 正确清理方式:清理指定时间之前的binlog PURGE BINARY LOGS BEFORE '2026-04-01 00:00:00'; -- 清理指定文件之前的binlog PURGE BINARY LOGS TO 'mysql-bin.000010'; -
redo log变更规范:修改redo log文件大小与数量时,必须先正常关闭MySQL,删除旧的ib_logfile文件,再修改配置重启,否则会导致MySQL无法启动。
-
undo log运维规范:禁止手动修改undo表空间文件,长事务是undo log膨胀的唯一核心原因,出现膨胀时优先终止长事务,再触发自动截断,不要手动操作文件。
-
日志备份规范:核心业务必须每日备份binlog文件,与数据备份配合,实现任意时间点的数据恢复,备份保留时长与合规要求一致。
6.3 数据恢复标准化流程
基于三大日志的恢复能力,我们整理了生产环境两种高频场景的标准化恢复流程,杜绝二次故障。
6.3.1 场景1:MySQL宕机重启后的自动恢复流程
MySQL宕机重启后,会自动执行崩溃恢复(Crash Recovery),无需人工干预,核心执行逻辑与人工校验步骤如下:
- 恢复阶段1:redo log重做:读取redo log,将所有已提交但未刷盘到数据文件的事务,重新应用到Buffer Pool,保证已提交事务的数据不丢失。
- 恢复阶段2:undo log回滚:读取undo log,将所有未提交的事务执行回滚操作,恢复到事务开始前的状态,保证事务原子性。
- 恢复阶段3:一致性校验:对比redo log与binlog的事务记录,确保所有已提交的事务在binlog中都有完整记录,保证主从同步的一致性。
- 人工校验步骤 :重启完成后,执行
SHOW ENGINE INNODB STATUS查看恢复状态,校验核心业务表的数据完整性,确认无异常后再恢复业务流量。
6.3.2 场景2:误操作数据的标准化恢复流程(基于binlog)
针对误删表、误更新全表、误删数据等高频场景,必须严格按照以下流程执行,避免二次伤害:
-
第一步:紧急保护现场 立即将数据库设置为只读模式,禁止新的写入操作,避免新的binlog覆盖误操作的记录,同时全量备份当前的binlog文件与数据文件。
ini-- 全局只读,仅超级管理员可写入 SET GLOBAL super_read_only = ON; -
第二步:定位误操作的binlog位置 先通过
SHOW BINARY LOGS查看误操作时间段的binlog文件,再用mysqlbinlog工具解析binlog,精准定位误操作的起始位置(start-position)与结束位置(stop-position)。ini# 解析binlog,过滤误操作语句,记录位置点 mysqlbinlog --base64-output=decode-rows -v --start-datetime="2026-04-07 10:00:00" --stop-datetime="2026-04-07 10:30:00" mysql-bin.000012 > binlog_analysis.sql -
第三步:在测试环境验证恢复脚本 搭建与生产环境一致的测试实例,先恢复误操作前的全量备份,再通过binlog回放误操作之前的所有正常操作,验证恢复脚本的正确性,确保数据恢复后符合预期。
arduino# 测试环境回放正常操作,跳过误操作的位置区间 mysqlbinlog --start-position=4 --stop-position=1560 mysql-bin.000012 | mysql -u root -p -
第四步:生产环境执行恢复 测试验证无误后,在生产环境执行恢复脚本,恢复完成后校验数据完整性,确认无误后关闭只读模式,恢复业务流量。
-
第五步:事后复盘 分析误操作原因,落地权限管控、操作审计、SQL预审核等措施,避免同类问题再次发生。
6.4 性能优化核心技巧
三大日志的写入是MySQL写入性能的核心瓶颈点,以下优化技巧在保证数据安全的前提下,最大化提升数据库性能,所有方案均经过生产环境验证。
- 批量提交减少刷盘次数 高并发写入场景,将多条单条insert语句合并为批量insert,将多个小事务合并为合理的大事务,减少事务提交次数,从而减少binlog与redo log的刷盘次数,大幅提升写入性能。注意:事务大小需控制在合理范围,避免大事务导致undo log膨胀与锁等待。
- binlog体积优化 生产环境设置
binlog_row_image = MINIMAL,仅记录变更的字段,相比默认的FULL模式,可减少50%以上的binlog体积,降低磁盘IO与网络传输开销,同时提升主从同步性能。 - redo log文件大小合理设置 高并发写入场景,将redo log单个文件大小设置为4G,文件组数量设置为2个,避免redo log空间不足导致的频繁checkpoint,减少刷盘带来的性能抖动。注意:redo log总大小不建议超过8G,否则会导致宕机恢复时间过长。
- 日志文件与数据文件分离部署 将redo log、binlog与数据文件分别部署在不同的物理磁盘上,避免数据读写与日志刷盘的IO竞争,充分发挥顺序写的性能优势,同时降低单磁盘故障导致的日志与数据同时损坏的风险。
- 关闭不必要的日志功能 非必要场景,关闭binlog的额外日志功能,如
binlog_rows_query_log_events(记录原始SQL),避免binlog体积不必要的增大;关闭general_log通用查询日志,仅在排查问题时临时开启,减少磁盘IO开销。
6.5 高频生产事故避坑指南
我们整理了互联网行业90%以上的MySQL日志相关生产事故,总结出以下避坑指南,从根源上杜绝同类故障。
-
事故1:双1配置未开启,宕机丢失已提交事务数据
- 事故原因:为了提升性能,将
innodb_flush_log_at_trx_commit设置为0或2,sync_binlog设置为0,服务器宕机后,操作系统缓存中的日志未刷盘,导致已提交的事务数据丢失。 - 避坑方案:核心业务必须强制开启双1配置,非核心业务如需调整参数,必须经过风险评估与审批,同时做好数据备份。
- 事故原因:为了提升性能,将
-
事故2:手动删除binlog物理文件,导致主从同步崩溃
- 事故原因:磁盘占满后,运维人员手动删除binlog文件,导致binlog索引文件与实际文件不一致,主库dump线程无法读取binlog,主从同步直接断连,无法自动恢复。
- 避坑方案:严格执行binlog清理规范,必须使用
PURGE命令清理,配置binlog自动过期策略,提前监控磁盘使用率,杜绝手动删除文件。
-
事故3:redo log文件设置过小,导致数据库写入阻塞
- 事故原因:redo log单个文件设置为默认的48M,高并发写入场景下,redo log快速写满,write pos追上checkpoint,MySQL必须暂停所有写入操作,推进checkpoint刷盘,导致业务写入超时,出现雪崩。
- 避坑方案:生产环境必须调整redo log文件大小,高并发场景推荐4G,提前监控redo log空间使用率,避免写满阻塞。
-
事故4:长事务导致undo log膨胀,磁盘占满+查询性能暴跌
- 事故原因:业务代码中存在未关闭的长事务,或大查询事务,导致undo log中的历史版本无法被purge线程回收,undo表空间持续膨胀,占满磁盘,同时undo log过大导致多版本查询时扫描耗时变长,查询性能暴跌。
- 避坑方案:严格禁止长事务,设置事务超时时间,监控长事务与undo表空间大小,出现长事务立即终止,定期优化大查询SQL。
-
事故5:binlog格式使用Statement,导致主从数据严重不一致
- 事故原因:为了减少binlog体积,将binlog格式设置为Statement,SQL语句中包含
NOW()、RAND()、LIMIT等非确定性函数,主库与从库执行结果不一致,导致主从数据偏差,最终引发业务故障。 - 避坑方案:生产环境强制使用ROW格式binlog,杜绝Statement格式,从根源上避免主从数据不一致。
- 事故原因:为了减少binlog体积,将binlog格式设置为Statement,SQL语句中包含
-
事故6:binlog过期时间设置过短,导致数据无法恢复
- 事故原因:为了节省磁盘空间,将binlog过期时间设置为1天,业务误操作3天后才发现,此时binlog已被自动清理,无法通过binlog恢复数据,造成永久性数据丢失。
- 避坑方案:binlog过期时间至少设置7天,核心业务设置30天,同时每日备份binlog文件,备份保留时长与合规要求一致。
6.6 总结
redo log、undo log、binlog是MySQL事务与数据一致性的核心基石,三者各司其职,又深度协同:
- undo log 为事务提供了"撤回"的能力,保证了事务的原子性,同时支撑了MVCC多版本并发控制,让MySQL实现了高性能的并发读写;
- redo log 为事务提供了"兜底"的能力,保证了事务的持久性,即使数据库宕机,也能完整恢复已提交的事务数据,杜绝数据丢失;
- binlog 为数据提供了"追溯"与"复制"的能力,支撑了MySQL的主从同步架构与数据恢复能力,是MySQL高可用架构的核心基础。
三者的协同,构成了MySQL事务ACID特性的完整闭环,从执行、提交、回滚到宕机恢复、主从同步,每一个环节都离不开三大日志的支撑。