

🔥个人主页:北极的代码(欢迎来访)
🎬作者简介:java后端学习者
✨命运的结局尽可永在,不屈的挑战却不可须臾或缺!
前言:
我们已经完成了对链表章节算法的学习,关于这些方法思路的总结,我准备找一个专门的时间总结出来,以思维导图为发散,将知识点串联起来,接下来我们继续学习哈希表及其相关的算法题目,覆盖基础知识到实战演练。
哈希表
(英文名字为Hash table,国内也有一些算法书籍翻译为散列表,大家看到这两个名称知道都是指hash table就可以了)。
我学习的是java,这里分享的就是在java中的哈希表,跟c语言或者其他的语言差别挺大的,java的哈希表是已经封装好了的,不需要自己去实现,直接拿来用就可以。
Java 哈希表(Hash Table)全基础讲解
要刷力扣哈希表题型,Java 里哈希表核心就是 2 个类:HashMap + HashSet,我把所有刷题必需的基础知识、用法、区别、技巧一次性讲全。
哈希表到底是什么
哈希表 = 数组 + 哈希函数(本质定义)
类比一下:
哈希表 = 快递柜系统
- 数组 = 快递柜格子
- 哈希函数 = 按手机号分配格子(计算出哈希值)
Java HashMap = 带挂袋和大箱子的快递柜
- 链表 = 格子放不下,挂个袋子串起来
- 红黑树 = 袋子太长,换成有序大箱子
哈希函数又是什么:
把任意对象,算出一个 int 类型的哈希值,用来定位数组下标的公式。
hashCode()方法
javapublic native int hashCode();
- 给每个对象返回一个
int数字- 同一个对象多次调用,结果应该一样
- 想让两个对象视为同一个 key,必须 equals 为 true 且 hashCode 相同
HashMap 自己的哈希函数(真正用的)
HashMap 不会直接用
key.hashCode(),它会再做一次扰动,让分布更均匀,减少冲突。JDK 源码里的哈希函数:
javastatic final int hash(Object key) { int h; // key 为 null 时哈希值固定为 0 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
h >>> 16:把哈希值右移 16 位
^:异或运算
目的:把高 16 位和低 16 位混合,让哈希值更散列,减少冲突。
最后一步:算出数组下标
有了哈希值,还要转成数组下标:
index = hash & (table.length - 1);等价于取模,但位运算更快。
补充:这里是怎么减少冲突的,通过一个例子理解
假设我们有两个字符串:
"Aa""BB"我们直接算它们的
hashCode和 原始下标:
字符串 hashCode 原始值 直接 &15(无扰动) 扰动后 hash 值 扰动后 &15 "Aa"2080 0 2080 ^ (2080 >>>16) = 2080 0 "BB"2080 0 2080 ^ (2080 >>>16) = 2080 0 灾难发生了!如果没有扰动,
"Aa"和"BB"这两个完全不同的字符串,会被映射到同一个数组下标(下标 0)!它们会发生严重的哈希冲突,都挤在一个链表后面。**但扰动之后?**扰动是把高位和低位异或,改变了低位信息,让它们落在不同位置,完美避开冲突。
总结:
无扰动计算 :就是直接用
hashCode & (len-1)。核心目的 :扰动不是为了改这次的结果,而是为了保证大量不同的字符串,低位信息也不同,从而最大限度避免哈希冲突。
所以,Java 必须加那个
hash()扰动函数。
完整流程(背下来)
key ↓ key.hashCode() // 原始哈希 ↓ hash() 扰动函数 // 优化哈希 ↓ & (数组长度-1) // 转成数组下标这一套,就是 Java 里哈希表真正使用的哈希函数。
- 用哈希函数把「键 key」转换成数组下标
- 时间复杂度:插入 / 查找 / 删除 平均 O (1)(力扣哈希题核心优势)
- 解决问题:快速判重、快速查找、统计次数
Java 哈希表两大核心类
| 类 | 用途 | 底层 | 重复规则 |
|---|---|---|---|
HashMap<K,V> |
存键值对(统计次数、映射关系) | 数组 + 链表 + 红黑树 | key 不可重复,重复会覆盖 |
HashSet<E> |
只存值(去重、判断存在) | 基于 HashMap | 元素不可重复 |
HashMap 最全用法
HashMap是力扣哈希题使用频率最高的工具,专门处理:
- 统计字符 / 数字出现次数
- 两数之和这类映射查找
- 记录索引位置
导包
import java.util.HashMap;
创建对象
// 常见写法(key 和 value 可任意类型)
HashMap<Integer, Integer> map = new HashMap<>();
HashMap<String, Integer> map = new HashMap<>();核心方法(背会这 10 个足够刷所有哈希题)
// 1. 添加/修改元素:key 不存在=添加,存在=覆盖
map.put(key, value);// 2. 获取元素:根据 key 拿 value
map.get(key);// 3. 判断是否包含某个 key
map.containsKey(key);// 4. 判断是否包含某个 value(很少用)
map.containsValue(value);// 5. 删除元素
map.remove(key);// 6. 获取键值对数量
map.size();// 7. 清空
map.clear();// 8. 判断是否为空
map.isEmpty();// 9. 获取所有 key(遍历用)
map.keySet();// 10. 获取所有 value(遍历用)
map.values();遍历 HashMap(刷题必背 2 种)
方式 1:遍历 key(最常用)
for (Integer key : map.keySet()) { int value = map.get(key); System.out.println(key + " : " + value); }方式 2:遍历键值对
for (Map.Entry<Integer, Integer> entry : map.entrySet()) { int key = entry.getKey(); int value = entry.getValue(); }
HashSet 最全用法
HashSet用于:
- 判断一个元素是否出现过
- 去重
- 找重复元素
导包
import java.util.HashSet;
创建对象
HashSet
set = new HashSet<>(); 核心方法(6 个足够)
// 1. 添加元素,重复添加会自动失败
set.add(element);// 2. 判断是否包含
set.contains(element);// 3. 删除元素
set.remove(element);// 4. 大小
set.size();// 5. 清空
set.clear();// 6. 是否为空
set.isEmpty();遍历
for (Integer num : set) {
// 遍历所有不重复元素
}
HashMap vs HashSet 怎么选
- 要统计次数、存映射关系 → HashMap
- 只要去重、判断是否存在 → HashSet
Java 哈希表高频面试 / 刷题知识点
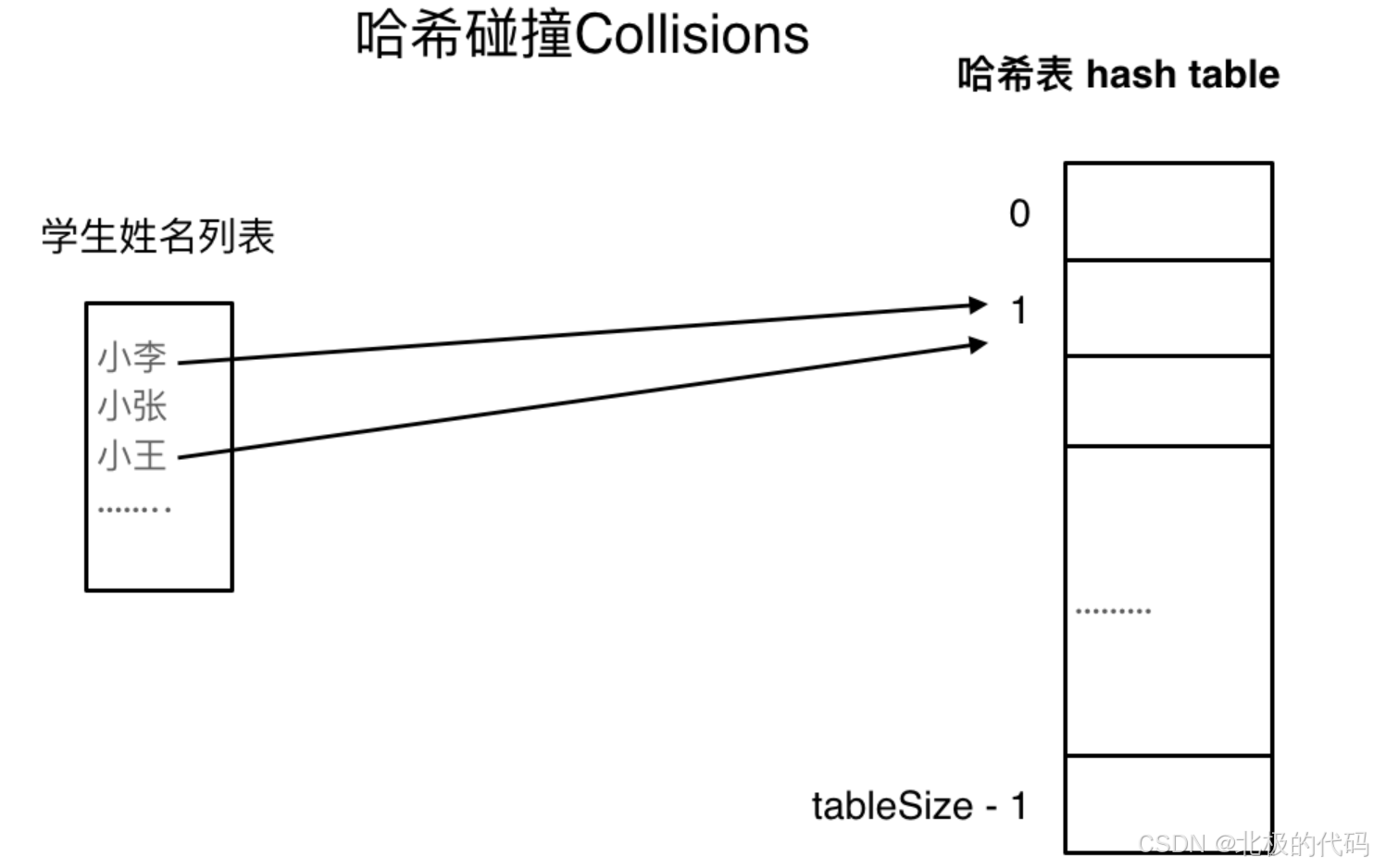
1. 哈希冲突是什么
- 两个不同 key 算出同一个数组下标
- Java 解决:链地址法(链表)+ 红黑树优化
- 链地址法(最核心)
哈希表底层是一个数组
每个数组位置是一个链表头
冲突的 key 就挂在这个链表后面
结构:
数组下标 0 → null 下标 1 → node1 → node2 → node3(冲突了就往后链) 下标 2 → null ...
- JDK 1.8 升级:链表太长 → 转红黑树
为了防止链表太长导致查询退化成 O (n),Java 做了优化:
链表长度 ≥ 8 并且 数组长度 ≥ 64→ 自动转换成 红黑树
树节点数量 ≤ 6→ 退化成链表
为什么这样
链表:短的时候快
红黑树:长的时候查询 O (log n),比 O (n) 快很多
三、除了链地址法,还有哪些解决冲突方式?(面试常问对比)
Java 只用链地址法,但你要知道别的方法:
开放寻址法 冲突了就往后找空位置:线性探测、二次探测→ 比如 ThreadLocalMap 用这个
再哈希法冲突就换一个哈希函数再算一次
建立公共溢出区冲突的统一放另一个数组
四、HashMap 减少冲突的其他手段(高频)
1. 哈希扰动(让 hash 更散列)
Java 不会直接用
key.hashCode(),而是做了高低位异或扰动:
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }目的:让哈希值分布更均匀,减少冲突。
2. 负载因子 loadFactor
默认 0.75
意思:数组满 75% 就扩容
太大 → 冲突变多
太小 → 空间浪费
3. 扩容机制
默认容量 16,扩容 ×2扩容后重新计算所有位置,打散冲突。
两者核心区别
对比 哈希扰动 扩容机制 作用对象 hash 值 数组容量 发生时间 每次 put 时 满负载时 结果 让 hash 更散 数组变大 ×2 是否迁移数据 不迁移 必须迁移所有数据 目的 减少冲突 整体降低冲突频率 层级 前端优化 后端扩容
五、一句话总结
Java 中 HashMap 解决哈希冲突:采用链地址法,链表过长转为红黑树,配合哈希扰动、负载因子、扩容来减少冲突。
2. 为什么哈希表操作是 O (1)
- 哈希函数直接定位下标,不遍历全表
- 最坏 O (n),但力扣题目全部按平均 O (1) 算
3. 允许 null 吗
- HashMap:key 允许 1 个 null,value 允许多个 null
- HashSet:允许 1 个 null
4. 有序吗
- 无序! 不保证插入顺序
- 要有序用
LinkedHashMap(极少用)
为什么要重写 hashCode () 和 equals ()
面试必考:
- 如果两个对象 equals 为 true,hashCode 必须相同
- 否则它们会被当成不同 key,存到不同位置,HashMap 就错乱了
所以:用自定义对象当 HashMap 的 key,必须同时重写 equals 和 hashCode。
为什么不重写 equals 和 hashCode,HashMap 就会 "错乱"。
先记住一个铁律(HashMap 的灵魂规则)
HashMap 判断两个 key 是否相等,分两步:
先比 hashCode
- 不一样 → 直接判定不是同一个 key
再比 equals
- 不一样 → 也判定不是同一个 key
只有 hashCode 相同,且 equals 为 trueHashMap 才认为:这是同一个 key。
场景:你自己写了个类,没重写 hashCode 和 equals
class Student { String id; String name; public Student(String id, String name) { this.id = id; this.name = name; } }现在你做一件事:往 HashMap 里 put 一个学生,再想 get 出来。
Student s1 = new Student("001", "张三"); map.put(s1, "高三一班"); Student s2 = new Student("001", "张三"); map.get(s2); // 你以为能取到,结果是 null!
为什么会 null?(核心原因)
- 默认的 hashCode ()
Object 里的 hashCode 是根据对象内存地址算的。
s1 是 new 出来的一个对象
s2 是另一个 new 出来的对象
地址不一样 → hashCode 不一样
HashMap 第一步就判定:hashCode 不同 → 不是同一个 key直接去别的位置找,找不到,返回 null。
- 默认的 equals ()
默认 equals 也是比地址:
return this == obj;s1 和 s2 是两个对象,== 肯定是 false。
所以:hashCode 不同 + equals 不同HashMap 认为:这是两个完全不同的 key。
结果就 "错乱" 了
在你的逻辑里:
学号一样,就是同一个学生
但在 HashMap 眼里:
地址不一样,就是两个人
于是:
- put 进去的是 s1
- get 用 s2 找不到
- 你甚至可以 put 两次,HashMap 会存两条
- 这就叫错乱、不符合预期
易混点:
一张表看懂区别(面试必背)
| 实现类 | 底层结构 | 是否有序 | 线程安全 | null 允许 | 时间复杂度 |
|---|---|---|---|---|---|
| HashMap | 数组 + 链表 + 红黑树 | 无序 | ❌ | 1 个 null key | O(1) |
| Hashtable | 数组 + 链表 | 无序 | ✅ | 不允许 | O(1) |
| LinkedHashMap | HashMap + 双向链表 | 插入有序 | ❌ | 允许 | O(1) |
| TreeMap | 红黑树 | 按键排序 | ❌ | key 不能为 null | O(log n) |
关于HashMap和HashSet,TreeMap:
在 Java 里:
- HashSet 底层就是 HashMap
- TreeSet 底层就是 TreeMap
- 哈希表本质是 key-value 结构 ,Set 只是 "只存 key、忽略 value" 的马甲
所以大家聊哈希表底层原理、哈希冲突、数组 + 链表 时,默认都是在说 HashMap,因为 HashSet 根本没有自己的底层,它就是套了层壳的 HashMap。
一句话说清它们的真实关系
- HashSet = 只存 key 的 HashMap
- TreeSet = 只存 key 的 TreeMap
- LinkedHashSet = 只存 key 的 LinkedHashMap
看一眼源码你就彻底懂了:
public class HashSet<E> { private transient HashMap<E,Object> map; // 所有 value 都塞一个固定的空对象 private static final Object PRESENT = new Object(); public boolean add(E e) { return map.put(e, PRESENT) == null; } }所以:
- 你往 HashSet 里 add 元素
- 底层其实是往 HashMap 里 put (key, 固定小对象)
HashSet 本身没有任何 "哈希表实现",它完全依赖 HashMap。
TreeSet / TreeMap 算不算哈希表
不算!严格来说它们不是哈希表。
- TreeMap / TreeSet 底层是 红黑树
- 没有哈希函数、没有数组、没有哈希冲突
- 时间复杂度是 O (log n),不是 O (1)
所以:
- 叫 哈希表 → 只有 HashMap、HashSet、LinkedHashMap、LinkedHashSet
- TreeMap / TreeSet 是 有序树结构,不属于哈希表
总结
- HashSet 不是独立实现,就是 HashMap
- 所以聊哈希表底层、哈希冲突时,默认讲 HashMap 没问题
- TreeSet/TreeMap 跟哈希表没关系,是树
- 真正的哈希表家族:
- HashMap
- LinkedHashMap
- HashSet(基于 HashMap)
- LinkedHashSet(基于 LinkedHashMap
- 结语:如果对你有帮助,请点赞,关注,收藏,你的支持就是我最大的鼓励!
