一、冯诺依曼体系结构
无论现在的超级计算机多么强大,绝大多数依然遵循着 1945 年诞生的冯诺依曼体系结构。理解这个结构,是理解一切软件逻辑的前提。
1. 核心组件
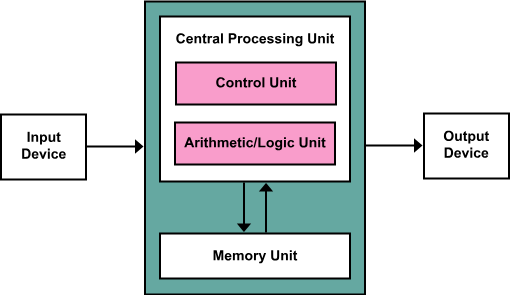
它将计算机抽象为五大核心部分:
| 组成部分 | 描述 |
|---|---|
| 输入设备 | 采集外部数据(键盘、鼠标、网卡等) |
| 输出设备 | 将处理结果反馈(显示器、音箱、网卡等) |
| 存储器 | 指内存。程序运行时的临时数据中转 |
| 运算器 (ALU) | 负责所有的算术运算和逻辑判断 |
| 控制器 (CU) | 指挥各部件协同工作,负责指令译码 |
为什么 CPU 不直接和外设打交道
CPU 直接从硬盘读数据、直接往显示器写数据不是更快吗?为什么要中间加个内存?
答案是:木桶效应
CPU 的运算速度是纳秒(ns)级的,而磁盘(外设)的读写速度通常是毫秒(ms)级的。如果 CPU 直接和外设打交道,CPU 执行一条指令只要 1 秒,而等磁盘传数据要花 1 天。那么 CPU 99.9% 的时间都在等待

用 C/C++ 写的程序,编译后生成的 .exe 或 a.out 是存储在磁盘上的
因为 CPU 只认识内存, 在冯·诺依曼体系中,CPU 只能从存储器(内存)中读取指令和数据。为了不让 CPU 被磁盘的慢速拖累,操作系统必须先把程序从磁盘拷贝到内存,然后 CPU 再去内存里取指令运行
内存的核心作用在于作为外设与 CPU 之间的高速缓冲。其读写速度远胜硬盘,虽不及 CPU迅捷,但已能基本匹配处理节奏。通过将数据预先从低速磁盘调入内存,可确保 CPU 持续高效运转
2. 数据流动的本质
如果我们要给计算机的运行效率下一个定义,那本质上就是设备间数据拷贝的效率
在计算机内部,数据永远在做搬运运动:
外设 (输入)
内存
计算机本质上并不生成数据,而是扮演着数据"加工厂"和"搬运工"的角色。其运算过程实际上是在数据拷贝的同时,由 CPU 附带执行逻辑处理操作
情景示例
假设你在给北京的朋友发了一句"吃了吗?"。在冯诺依曼体系下,这段数据是怎么样流动的呢
第一阶段:数据流出
-
输入 :你点击发送,文字通过键盘 / 触摸屏进入内存
-
处理:CPU 从内存读取这段文字,进行加密、打包,然后再写回内存
-
输出 :内存将处理好的数据包拷贝到网卡(输出设备),网卡通过光纤发往互联网
第二阶段:数据流入
-
输入 :北京朋友的手机网卡(输入设备)接收到电信号,将其拷贝到内存
-
处理:CPU 从内存读取加密包,进行解密、拆包,还原成文字和图片,再写回内存
-
输出 :内存将还原好的数据拷贝到显示器 / 屏幕(输出设备),朋友看到了你的问候
发送信息的本质:基于冯诺依曼体系结构 ,从我的键盘文件拷贝数据到对方的显示器文件
二、计算机与操作系统
让程序员直接操控硬件无异于一场灾难
想象一下:如果写一个 printf("Hello") 都要亲自动手控制显卡的每一个像素点、处理磁盘的磁道寻址、管理电压波动等等
-
开发门槛极高:你得是电子工程师才能写程序
-
资源利用率极低:如果程序 A 占着打印机不用,程序 B 只能干等
-
安全性极低:一个程序的 Bug 可能会直接烧毁硬件或者偷窥另一个程序的数据
这里引出了计算机科学中著名的大卫·惠勒金句:
"任何计算机问题都可以通过添加一层软件层(间接层)来解决。"
操作系统正是那一层至关重要的软件层,其诞生正是为了高效处理这些繁琐事务
1. 操作系统的概念与定位
操作系统 是一款专门针对计算机硬件和软件资源进行管理的软件,笼统的理解,操作系统包括:
-
内核(负责:进程管理、内存管理、文件管理、驱动管理)
-
其他程序(例如函数库、shell 程序等等)
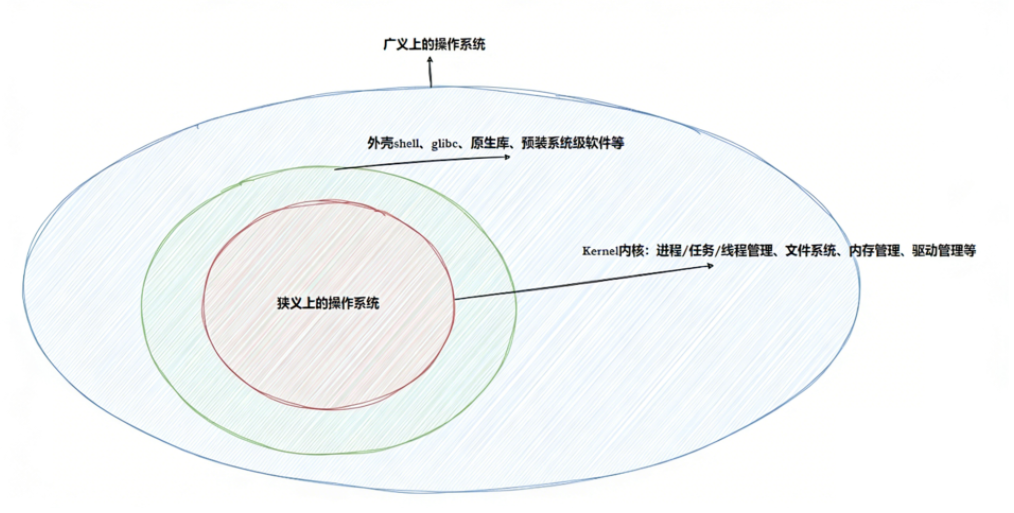
操作系统的定位 :它处于硬件之上,应用软件之下
-
向下:它与硬件交互,通过驱动程序管理复杂的物理设备。
-
向上:它为用户(及程序员)提供一个高效、稳定、安全的执行环境
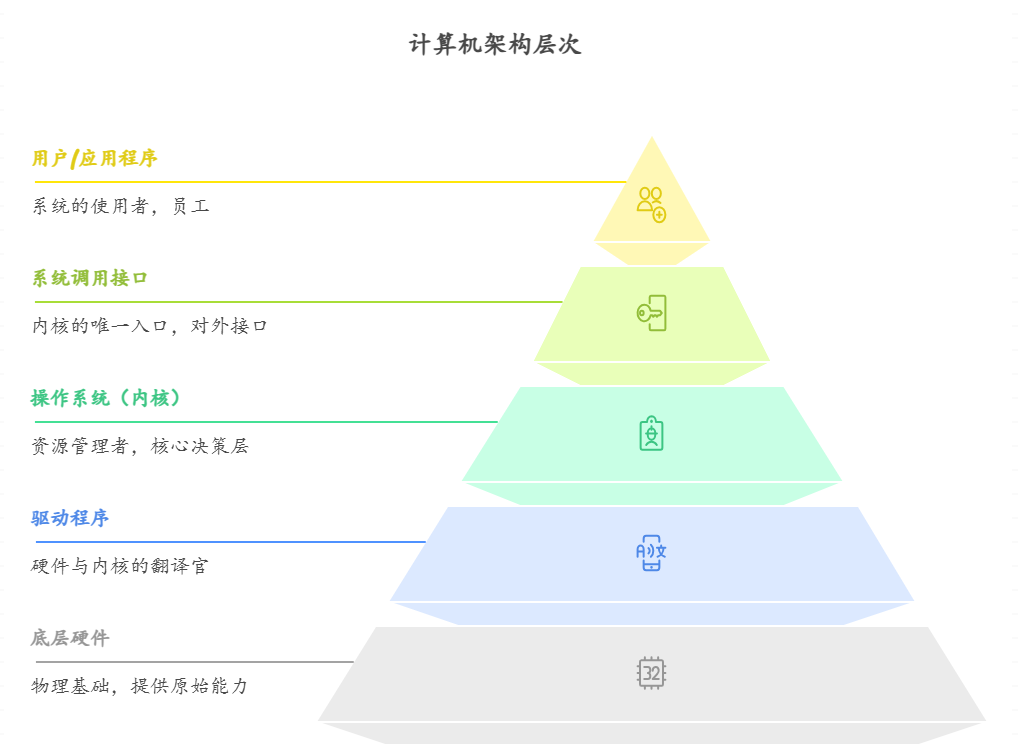
操作系统的本质定义: 操作系统是一个协调者 。它的存在是为了通过合理的管理,让计算机变得更好用、更稳定
2. 操作系统的核心功能
为了确保计算机高效运行,操作系统主要承担四项核心职责:
-
进程管理: 决定哪个程序什么时候运行,运行多久,如何处理多程序并发
-
内存管理: 为每个程序分配生存空间,处理虚拟地址与物理内存的映射,防止越界访问。
-
文件管理: 将磁盘上的 0 和 1 抽象成我们熟悉的文件夹和文件,处理数据的读写与持久化
-
设备管理: 管理各种外设(磁盘、网卡等),通过中断和驱动机制实现数据的输入输出
3. 如何理解 "管理"
这是学习进程概念前最重要的一步。操作系统是如何管理千万个进程或硬件的
管理的本质:先描述,再组织
描述
就像校长管理学生,他不需要认识每个学生,只需要每个人的学籍档案。 在 C 语言中,这就是一个 struct 结构体。操作系统会将每个被管理对象的属性(学号、姓名、成绩、状态等)抽取出来,封装成一个结构体
cpp
struct Student
{
const char* num;
const char* name;
int score;
bool state;
}组织
有了成千上万份档案,校长只需要用链表、树或其他数据结构将这些结构体连起来
-
所谓管理学生 :变成了对学籍档案链表的增删查改
-
所谓管理进程:变成了对进程控制块链表的维护
三、用户与内核的交互
为了保证系统的绝对安全,操作系统不信任任何用户程序。它禁止你直接操作内存、直接往磁盘写数据或直接控制网卡
我们可以把操作系统看作一家银行:
-
内核:是银行的内部柜台和金库,存储着核心资源(硬件)
-
用户:是办理业务的顾客
-
系统调用 :是银行的业务窗口

你不能直接冲进金库自己拿钱(直接操作硬件),你必须通过窗口(系统调用),向柜员(内核)提交申请。柜员会检查你的身份和权限,确认无误后,由他替你进入金库完成操作
系统调用是操作系统内核 提供给外界的接口。它是用户程序访问内核资源的唯一合法通道。 而库函数其实是编程语言对系统调用的二次封装
库函数封装的意义
既然最终都要通过系统调用完成操作,为什么编程语言不直接暴露系统调用接口呢
编程语言的可移植性
这是封装最伟大的贡献。 不同的操作系统,系统调用的接口是不一样的。Linux 下叫 write,Windows 下可能叫 WriteFile
-
如果你的程序直接用 write,你的代码就只能在 Linux 上跑,windows 根本不认识什么 write
-
如果用 C 语言标准库的 printf,库函数会根据你所在的系统自动选择调用 write 还是 WriteFile。这实现了 "一份代码,到处编译"
让我们拆解一下当你调用 printf("Hello World\n") 时,底层发生了什么:
-
用户层(库函数):你的程序调用 printf
-
缓冲区处理 :printf 将字符串存入 C 语言级别的缓冲区 ,进行格式化处理。当满足刷新条件时,printf 内部会调用底层的系统接口 write
-
内核执行:CPU 找到对应的显示器驱动程序,将数据发送到显存
-
返回结果:printf 执行完毕,程序继续往下走
四、进程概念
在很多教科书中,进程被定义为 "一个正在执行的程序"。但这个定义过于抽象,无法触达操作系统的运行本质。要理解进程,我们必须先厘清程序 与进程的边界
1. 什么是进程
-
程序(Program) :它是一个存储在磁盘中的二进制文件,本质上是一组静态的指令和数据集合。就像电影的剧本一样,它包含着预先编排好的内容
-
进程(Process) :进程是指程序被加载并由 CPU 执行时的运行状态 。它是动态的,会经历创建、运行、挂起和终止等生命周期阶段。可以将其类比为正在根据剧本放映的电影
在 Linux 操作系统的视角下,一个进程的本质可以这么表达:
进程 = 内核数据结构 + 自己的程序代码和数据
1. 代码和数据
当我们运行 ./a.out 时,操作系统首先会将磁盘上的二进制指令(代码)和初始变量(数据)拷贝到内存中
-
代码:定义了进程的执行逻辑
-
数据:定义了进程的内容
但仅有这些是不够的,如果只有代码和数据,操作系统根本不知道这个程序运行到了哪一行、谁在运行它、它的优先级是多少
2. 内核数据结构 (task_struct)
操作系统通过创建 "数字化替身" 来管理运行中的程序,这个替身就是PCB(进程控制块)。在Linux 系统中,PCB的具体实现是 struct task_struct 结构体
当进程被创建时,系统会同步创建一个 task_struct 对象,并将其填入该进程的各种属性(如 PID、状态、内存指针等)
为什么必须包含内核数据结构
回到先描述,再组织的原则:
-
如果不描述:操作系统只看到内存里有一堆乱七八糟的 0 和 1(代码和数据),它无法感知这到底是一个进程还是仅仅是一块废弃的内存
-
有了 task_struct:操作系统只需管理这些结构体即可。例如,调度进程的过程实际上是将 task_struct 从等待队列移动到运行队列;而终止进程则意味着将该进程对应的 task_struct 从内核链表中移除,并释放其占用的内存资源
2. 描述进程------PCB
操作系统作为一个管理者,它并不直接盯着内存里那几兆、几百兆的代码看。它管理进程的方式,就是通过 PCB
-
唯一性:每个进程有且仅有一个 PCB
-
状态切换:当 CPU 要从进程 A 切换到 进程 B 时,OS 必须先把 A 的当前进度记录在 PCB 里,再从 B 的 PCB 里读取它上次运行到的位置
-
资源分配:操作系统通过检查 PCB 来获取该进程打开的文件数量、内存使用情况以及运行时长等信息
虽然不同操作系统的 PCB 实现各有差异,但它们包含的核心信息大同小异(在 Linux 中叫 task_struct)。我们可以将其归纳为以下几大类:
| 属性类别 | 功能描述与技术细节 |
|---|---|
| 进程标识符 | 系统分配的全局唯一编号,用于区分不同的活跃进程 |
| 任务状态 | 运行 (R)、睡眠 (S/D)、停止 (T)、僵尸 (Z) 等状态,含退出码与信号 |
| 调度优先级 | 决定进程获取 CPU 时间片的先后顺序 |
| 程序计数器 | 存储下一条即将执行的指令地址,确保进程被切回时能准确接续进度 |
| 内存指针 | 指向程序代码段、数据段、堆栈以及共享内存块的虚拟地址映射表 |
| 上下文数据 | 进程切出 CPU 时,寄存器中数据的瞬时快照 |
| I/O 状态信息 | 包含进程打开的文件描述符列表及待处理的 I/O 请求 |
| 记账信息 | 记录 CPU 耗时总和、内核/用户态时间、时间配额及计费信息 |
为什么 PCB 必须常驻内存?
代码和数据在不运行的时候可以留在磁盘上,但 PCB 必须始终留在内存的内核空间中
操作系统需要随时扫描所有 PCB 以进行调度决策。如果 PCB 也在磁盘上,OS 还要先发起磁盘 I/O 去读 PCB,而磁盘 I/O 本身又需要 OS 进行进程调度......这就陷入了逻辑死循环
3. 组织进程------task_struct
Linux 内核的进程管理机制并非简单的静态线性存储。在进程的生命周期内,其 task_struct 实例会被编排进不同的逻辑容器中
如果按照传统的思维,我们要把一个 task_struct 放入不同的链表,似乎需要不断的拷贝这个巨大的结构体。但 Linux 内核采用了另一种设计:不让链表包含进程,而让进程包含链表节点
这种设计被称为 "嵌入式链表"。task_struct 内部包含多个 list_head 成员作为连接点,使得单个进程对象能够同时被挂载到不同的管理结构中
代码示例:
我们简化一下 Linux 内核的逻辑,用一段 C 语言伪代码来展示这个神奇的结构:
cpp
// 内核通用的双向链表节点
struct list_head {
struct list_head *next, *prev;
};
// 描述进程的 PCB
struct task_struct {
int pid; // 进程身份证号
int status; // 状态:运行、睡眠等
char comm[16]; // 进程名称
/* --- 核心:组织进程的成员 --- */
// 全量链表节点,用于将系统中所有进程串在一起
struct list_head all_list;
// 运行队列节点,当进程处于就绪态时,挂载在 CPU 的运行队列中
struct list_head run_queue;
// 等待队列节点,当进程在等磁盘/网卡 I/O 时,挂载在设备等待队列中
struct list_head wait_queue;
};你可能会问:OS 遍历链表时,拿到的只是 all_list 这样的成员的地址,它是怎么找回整个 task_struct 的首地址,从而读取 pid 或 status 的呢
在 Linux 内核中,有一个宏定义叫做 container_of。它的逻辑如下
cpp
container_of(成员地址, 结构体类型, 成员名)它利用 C 语言的偏移量(Offset)计算:用当前的成员地址,减去该成员在结构体内部的偏移字节量,从而精准反推回整个结构体的起始位置
五、进程操作
1. 查看进程信息
在 Linux 系统中,可通过多种文件和工具来查看进程信息
/proc 系统文件夹
Linux 的设计哲学秉承 "一切皆文件"。为了让用户能看到内核里的 task_struct 信息,Linux 提供了一个名为 /proc 的伪文件系统
它不是磁盘文件, /proc 并不占用磁盘空间,它存在于内存中。当你访问它时,内核会动态地把进程信息转换成文本呈现给你,我们可以这么查看:
bash
ls /proc我们会看到大量以数字命名的文件夹,每一个数字对应的就是进程的 PID

如果要获取PID为1的进程信息,查看 /proc/1 这个文件夹即可
ps 命令
ps (Process Status) 是最常用的查看进程的工具。它能瞬间拉取当前系统的进程列表
常用组合:
ps aux(偏向查看所有进程占用情况)
-
a:显示终端上的所有进程。
-
u:以用户为主的格式显示。
-
x:显示没有控制终端的进程。
ps ajx(偏向查看进程间的父子关系、会话关系)
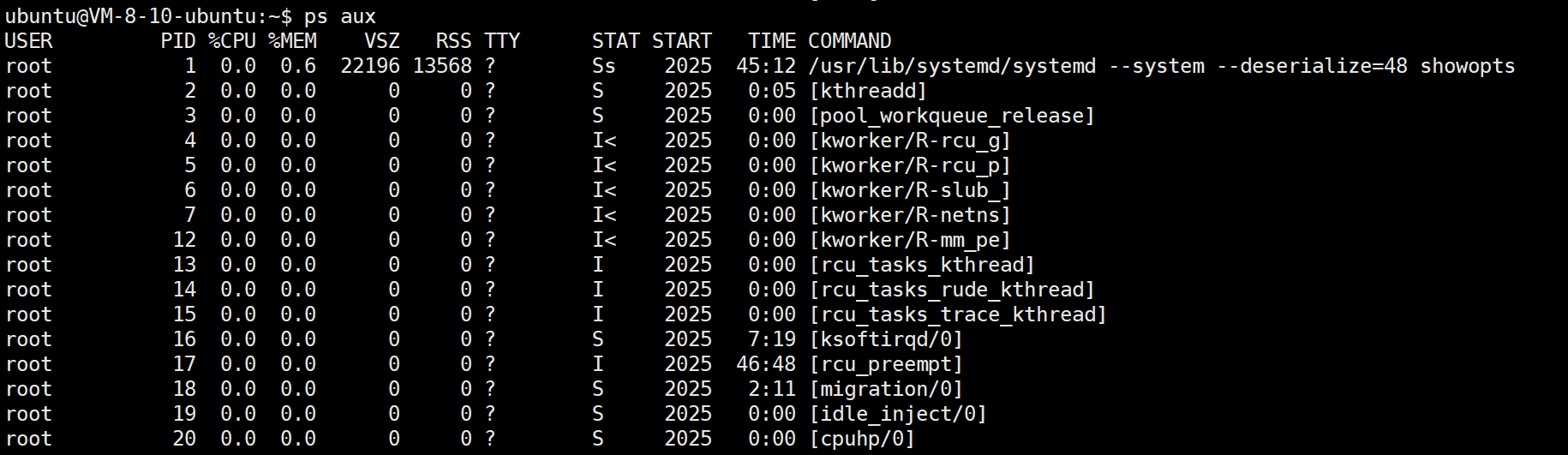
输出字段解析:
-
USER:启动该进程的用户
-
PID:进程 ID
-
PPID:父进程 ID
-
%CPU:占用 CPU 百分比
-
STAT:进程状态
我们可以配合 grep 命令来过滤想查看的进程
bash
# 先打印表头,再打印目标进程信息
ps ajx | head -1 && ps ajx | grep 'my_process'top 命令
它是一个交互式的实时监控工具,类似于 Windows 的任务管理器
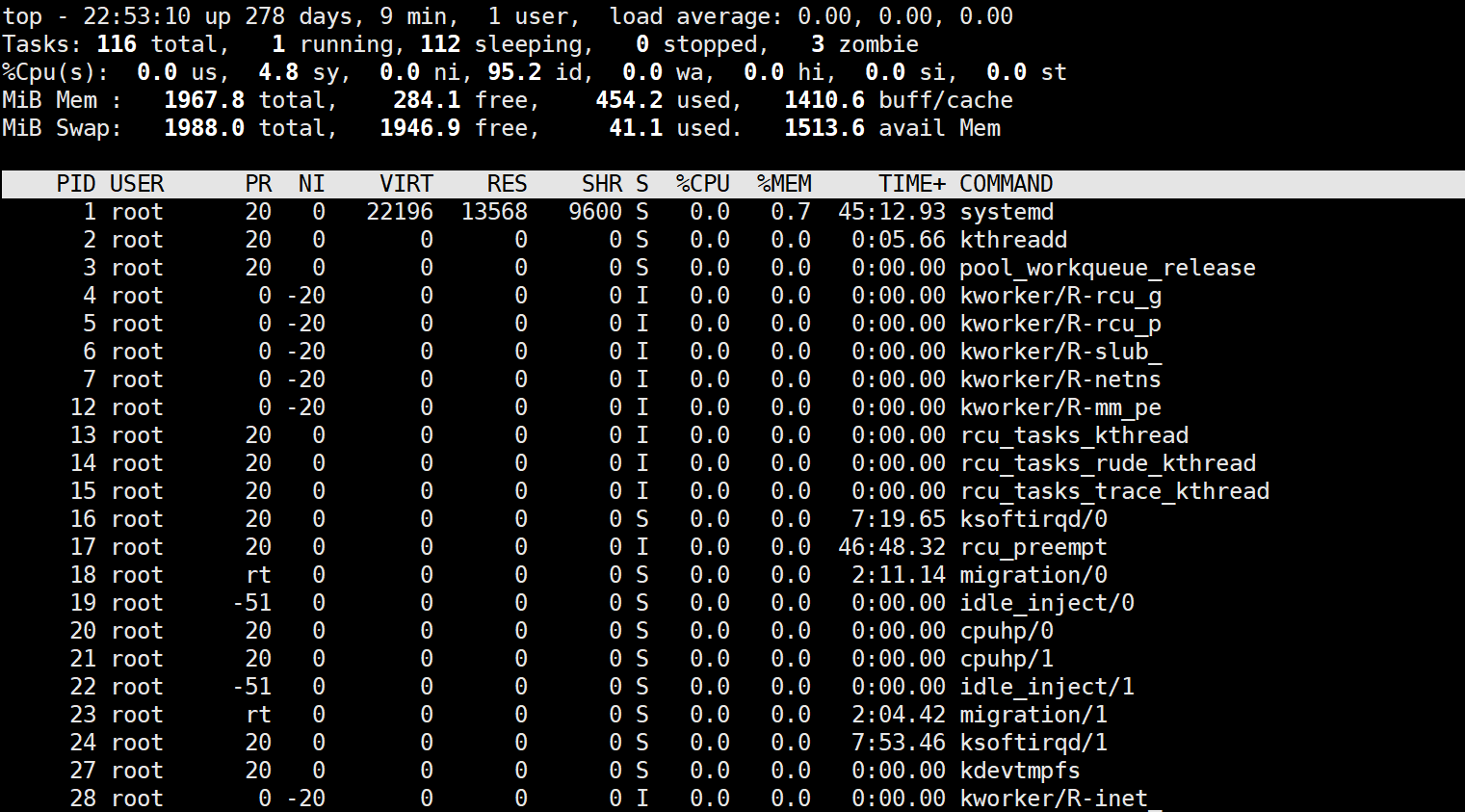
-
关键指标:
-
load average:系统的负载情况(1分钟、5分钟、15分钟的平均负载)
-
%CPU / %MEM:按资源占用排序
-
-
交互操作:
-
按 M:按内存占用排序。
-
按 P : 按 CPU 占用排序。
-
按 q:退出监控
-
2. 获取进程标识符(PID)
PID (Process Identifier) 是操作系统分配给每个进程的一个非负整数
-
唯一性:在任何给定的时刻,系统中的每一个 PID 都是独一无二的
-
复用性:当一个进程彻底销毁后,它的 PID 可能会被回收,并在一段时间后分配给新的进程
PID 的核心作用
为什么我们需要这个数字?
-
操作系统能通过 PID 快速定位该进程的 task_struct
-
要终止死循环程序,可以通过执行命令 kill -9 1234 来实现,其中1234代表目标进程的PID号
-
每个进程都会记录自己的 PID 和父进程的 PID (PPID),从而构建出类似家族族谱的进程树
必须通过系统调用来获取标识符
这是一个极其重要的知识点:PID 存储在内核的 task_struct 结构体中。
根据我们之前提到的 "银行柜台" 理论,用户程序严禁直接翻阅内核态的数据。因此,我们无法通过简单的内存访问去拿 PID
必须通过操作系统提供的系统调用,委派内核帮你把 PID 读出来并返回给你
代码示例
cpp
#include <stdio.h>
#include <unistd.h> // 系统调用接口头文件
#include <sys/types.h> // 提供 pid_t 类型定义
int main()
{
pid_t pid = getpid();
pid_t ppid = getppid();
printf("pid: %d, ppid: %d\n", pid, ppid);
return 0;
}细节拆解:
-
pid_t 类型:本质上是一个被 typedef 过的整数类型(通常是 int),但使用 pid_t 能提供更好的跨平台兼容性
-
父进程是谁? :如果你在 Bash 命令行里运行这个编译后的程序,你会发现它的 PPID 永远是同一个数字------Bash 解释器 的 PID。这意味着,你在命令行启动的所有程序,都是 Bash 的子进程
3. fork 创建进程
fork 是一个系统调用,其功能是以父进程为模板,创建一个新的子进程
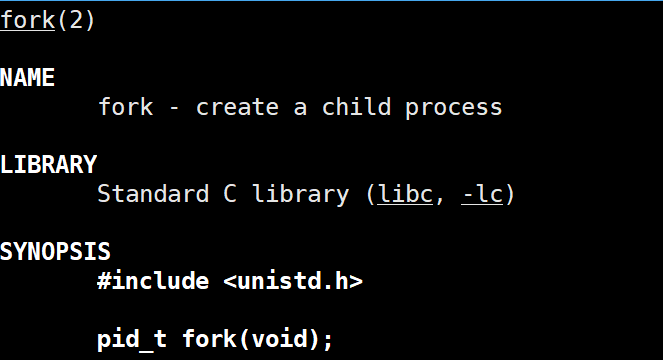
-
父进程:原本正在运行的那个进程
-
子进程:通过 fork 产生的新进程
fork 的返回值
-
给父进程返回:子进程的 PID
-
给子进程返回:0(子进程可以通过 getppid() 随时找到父亲,它只需要知道自己创建成功了)
-
失败返回:-1
为什么要这么设计?
父进程需要记录所有子进程的 PID 才能准确发送指令,而子进程只需通过 getppid() 系统调用即可随时获取父进程信息,无需额外存储
父子进程数据的关系
-
共享的:
- 程序代码:由于代码是只读的,父子进程共用同一份内存中的代码段,这样可以节省大量空间
-
独立的:
-
内核数据结构:子进程拥有自己独立的 task_struct
-
数据段:虽然初始内容一样,但在逻辑上,子进程拥有自己独立的一份数据副本
-
写实拷贝
如果父进程占用了 1GB 内存,fork 时 OS 是否要立刻拷贝 1GB 数据给子进程?
答案是否定的。 这样做的代价太高,且如果子进程后续立刻去加载新程序,这 1GB 的拷贝就全白费了
写时拷贝(COW)逻辑:
-
fork 之后,父子进程的物理内存是共享的,且被标记为"只读"
-
只要父子进程都不改数据,就一直共享下去
-
谁先尝试修改数据,OS 就会立刻为该进程开辟新的物理内存并拷贝一份数据
写时拷贝确保了 fork 的高效,实现了 "按需分配" 的懒加载哲学
fork 为什么有两个返回值?
在 Linux 下,我们通常这样写 fork
cpp
int main() {
pid_t id = fork();
if (id < 0) {
// 创建失败
perror("fork");
return 1;
} else if (id == 0) {
// 子进程
while (1) {
printf("I am Child! pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
}
} else {
// 父进程
while (1) {
printf("I am Parent! pid: %d, my_child_pid: %d\n", getpid(), id);
sleep(1);
}
}
return 0;
}要理解 fork 的两个返回值,不能简单地将其视为普通 C 函数,而应将其看作内核的一次 "细胞分裂" 过程
当你的程序执行到 fork() 这一行时,它会陷入内核。内核会做以下几件事:
-
分配新的内存块和内核数据结构给子进程
-
将父进程的 tast_struct 属性拷贝给子进程
-
将子进程添加到系统调度队列中
关键点:
在 fork() 函数内部,所有的准备工作(拷贝、创建)完成后,在即将执行函数内部的 return 语句之前,子进程已经创建成功了
此时,系统中存在两个一模一样的执行流。既然是拷贝,子进程的 PC(程序计数器)指向的也是 fork() 函数内部即将返回的那一行
-
父进程:从内核的 fork() 函数里准备返回
-
子进程:也从内核的 fork() 函数里准备返回
这就是 fork 函数,返回两次的真相:两个独立的进程分别执行了各自的 return
变量 id 怎么能既是 0 又是非 0?
如果运行上面的代码,我们会惊奇地发现 if 和 else if 里面都在打印。这意味着 id == 0 和 id > 0 在同一时刻同时成立了
从内存角度来看:
-
初始状态:fork 刚刚完成时,父子进程共享同一块物理内存
-
返回时刻 :内核在向 id 变量写入返回值时,触发了写时拷贝
-
结果:
-
内核为父进程的 id 变量写了一个值(子进程 PID)
-
内核为子进程的 id 变量写了另一个值(0)
-
虽然在代码里的变量名都叫 id,但在 fork 之后,它们已经是两个完全独立的变量了
总结
从冯诺依曼体系到操作系统的引入,再到进程与 PCB 的概念,本质上是在逐步回答一个问题:计算机如何高效地管理和运行程序。操作系统通过先描述、再组织的方式,将进程这一抽象实体转化为可被统一管理的数据结构,并借助系统调用实现用户态与内核态之间的交互
在此基础上,进程不再只是 "程序的运行" ,而成为操作系统调度与资源分配的基本单位。理解这一点,意味着我们已经从 "写程序" 迈入了 "理解系统如何运行程序" 的层面
在下一篇中,我们将进一步深入进程的运行机制,探讨进程的创建细节、地址空间以及调度等更底层的问题,逐步揭开操作系统内部工作的全貌
