在区块链中,有大量序列化的需求,比如进行哈希运算时,要将类对象序列化再进行哈希。
存储到磁盘里也需要序列化和反序列化,网络传输也是。
而serialize.h这个文件里的代码就是充当这样的作用,用来实现序列化的功能。
1.参数说明
可以看到这个文件里有一些类,比如CDataStream,CAutoFile(磁盘存储序列化相关)
而CDataStream是负责,哈希,网络相关的序列化。可以看到
cpp
uint256 SerializeHash(const T& obj, int nType = SER_GETHASH, int nVersion = VERSION)
{
// Most of the time is spent allocating and deallocating CDataStream's
// buffer. If this ever needs to be optimized further, make a CStaticStream
// class with its buffer on the stack.
CDataStream ss(nType, nVersion);
ss.reserve(10000);
ss << obj;
return Hash(ss.begin(), ss.end());
}在定义CDataStream ,有这样一个参数,nType,为SER_GETHASH,表明是用于哈希序列化。
如果为SER_NETWORK表明是网络。
2.VERSION
在上一章中,单独测试CDataStream使用,则没有问题,将它添进到我的项目中,之后。又报错,
在serialize.h中报常数错误,static const int VERSION = 101;这句,为什么会报错呢?应该还是编译器版本的原因,VERSION这个词在后来的编译器中可能被占用了,比如这样:#define VERSION 999;那么这句:static const int VERSION = 101; 可能就会变成这样
static const int 999 = 101;
具体是哪个(系统)文件不清楚,我们现在只能这样解决:
cpp
#undef VERSION
static const int VERSION = 101;加上#undef VERSION 取消这个宏定义,当然这样可能会有冲突(影响系统默认值),当下并不重要。
或者你为了不冲突,你将static const int VERSION = 101; 改为static const int MY_VERSION = 101;不使用VERSION这个命名,但是你自己的所有代码都要跟着修改。这里暂时不采用这种方法。
3.CDataStream序列化逻辑
来看一下我的测试代码:
cpp
//处理和存储交易数据的类
class CTransaction
{
public:
string vin;
string vout;
uint256 GetHash() const
{
return SerializeHash(*this);
}
};
int main() {
CTransaction tx;
tx.vin = "a:50";
tx.vout = "b:50";
uint256 txhash = tx.GetHash();
cout << txhash.ToString() << endl;
//BitcoinMiner();
}这里还是会报错,为什么呢?因为你通过CDataStream来序列化(发生于GetHash函数中),而CDataStream自带的,只支持默认类型的,比如int ,string这样的。
你要序列化CTransaction这个你自己定义的类,它是通过调用这个对象的Serialize来实现的。
cpp
template<typename Stream, typename T>
inline void Serialize(Stream& os, const T& a, long nType, int nVersion = VERSION)
{
a.Serialize(os, (int)nType, nVersion);
}可以看到CDataStream里的重载函数Serialize的第二个参数,如果不是默认类型,比如int,string,
它就会调用这个对象自身的Serialize方法来实现序列化,即a.Serialize;
而你的CTransaction类中并没有实现这个方法,所以在a.Serialize这句会报错,提示a对象并没有Serialize这个成员。
那么在bitcoin源码中,它是怎样实现的呢,如下:
4.IMPLEMENT_SERIALIZE宏定义
cpp
class CTransaction
{
public:
int nVersion;
vector<CTxIn> vin;
vector<CTxOut> vout;
int nLockTime;
CTransaction()
{
SetNull();
}
IMPLEMENT_SERIALIZE
(
READWRITE(this->nVersion);
nVersion = this->nVersion;
READWRITE(vin);
READWRITE(vout);
READWRITE(nLockTime);
)注意源码,多了nVersion ,nLockTime,版本和时间这些参数,并且vin和vout是数组形式的,这些我们先不管,我们按之前简单的来,这里的关键是IMPLEMENT_SERIALIZE 和READWRITE这两个实现了类里的Serialize方法,怎么实现的呢,这两个其实是宏定义,看如下代码:
cpp
#define IMPLEMENT_SERIALIZE(statements) \
unsigned int GetSerializeSize(int nType=0, int nVersion=VERSION) const \
{ \
CSerActionGetSerializeSize ser_action; \
const bool fGetSize = true; \
const bool fWrite = false; \
const bool fRead = false; \
unsigned int nSerSize = 0; \
ser_streamplaceholder s; \
s.nType = nType; \
s.nVersion = nVersion; \
{statements} \
return nSerSize; \
} \
template<typename Stream> \
void Serialize(Stream& s, int nType=0, int nVersion=VERSION) const \
{ \
CSerActionSerialize ser_action; \
const bool fGetSize = false; \
const bool fWrite = true; \
const bool fRead = false; \
unsigned int nSerSize = 0; \
{statements} \
} \
template<typename Stream> \
void Unserialize(Stream& s, int nType=0, int nVersion=VERSION) \
{ \
CSerActionUnserialize ser_action; \
const bool fGetSize = false; \
const bool fWrite = false; \
const bool fRead = true; \
unsigned int nSerSize = 0; \
{statements} \
}
#define READWRITE(obj) (nSerSize += ::SerReadWrite(s, (obj), nType, nVersion, ser_action))可以看到, IMPLEMENT_SERIALIZE就是把这段语句传进去:
READWRITE(this->nVersion);
nVersion = this->nVersion;
READWRITE(vin);
READWRITE(vout);
READWRITE(nLockTime); 注意这里并不是五个参数,用;隔开的,这只是一整句代码。
所以将 {statements} 部分用上述代码代替,就得到了完整的函数代码,我们就可以来看看它干了什么事。写了三个函数。
分别是GetSerializeSize获取,类对象序列化数据的大小,Serialize序列化类对象,Unserialize反序列化。
这里底层都是调用READWRITE(obj),单独对每个成员实现序列化,然后再拼接,是这样的方法。
那么READWRITE(obj)展开就是:
(nSerSize += ::SerReadWrite(s, (obj), nType, nVersion, ser_action))
最终关键方法浮出水面,调用了SerReadWrite这个函数,从前面大概可以分析出,这个函数可以实现获取序列化对象的大小,它的返回值就是,在这里,用nSerSize来接收了,那么序列化后的数据,通过s来接收,而反序列化,这个s又变成传数据进去,(obj),就是类成员对象。
我们来看一下SerReadWrite函数,它在源码中有三个重载:
cpp
template<typename Stream, typename T>
inline unsigned int SerReadWrite(Stream& s, const T& obj, int nType, int nVersion, CSerActionGetSerializeSize ser_action)
{
return ::GetSerializeSize(obj, nType, nVersion);
}
template<typename Stream, typename T>
inline unsigned int SerReadWrite(Stream& s, const T& obj, int nType, int nVersion, CSerActionSerialize ser_action)
{
::Serialize(s, obj, nType, nVersion);
return 0;
}
template<typename Stream, typename T>
inline unsigned int SerReadWrite(Stream& s, T& obj, int nType, int nVersion, CSerActionUnserialize ser_action)
{
::Unserialize(s, obj, nType, nVersion);
return 0;
}分别对应了,获取序列化大小,序列化,和反序列化,这三个功能这个函数都实现了,通过重载的方法。但是怎么知道该调用哪个函数呢?看这个函数的最后一个参数:
CSerActionGetSerializeSize ser_action
CSerActionSerialize ser_action
CSerActionUnserialize ser_action
你传什么类型,就会执行对应的函数,我们回到IMPLEMENT_SERIALIZE这个宏定义的三个函数里。每一个开头第一句就定义了这个类型,指明调用哪个重载函数。
好,明白了原理后,我们最终发现,此序列化最终还是调用的serialize.h里的通用全局序列函数,就是默认的CDataStream序列化int ,string 类型所使用的函数,即:
::Serialize(s, obj, nType, nVersion);
所以最终还是一样,因为你不管定义了什么自定义类,你的类成员最终还是由基本类型组成的,比如int ,string之类的。
所以这个方法就是,先将你的类成员拆分成基本类型,序列化,然后再拼在一起。
5.编写支持序列化的类
那么现在我们可以自己写一个类,然后通过上面的方法让它支持序列化:
cpp
class CTransaction
{
public:
string vin;
string vout;
uint256 GetHash() const
{
return SerializeHash(*this);
}
IMPLEMENT_SERIALIZE
(
READWRITE(vin);
READWRITE(vout);
)
};基本就是调用IMPLEMENT_SERIALIZE宏,然后你有几个成员,就写几个READWRITE。
然后再如下代码测试:
cpp
int main() {
CTransaction tx;
tx.vin = "a:50";
tx.vout = "b:50";
uint256 txhash = tx.GetHash();
cout << txhash.ToString() << endl;
//BitcoinMiner();
}结果:
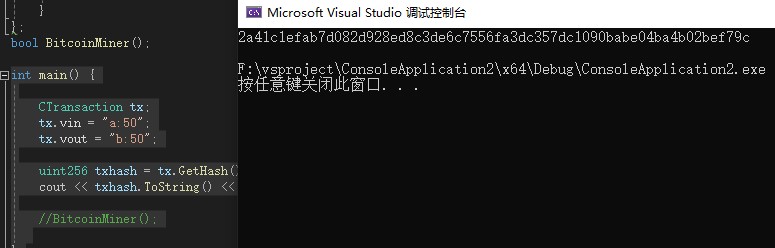
可以看到代码已经不报错了,可以顺利执行。但是这个结果,是否正确呢?
就是这个哈希值,以2a开头,9c结尾这个。
我们可以手动来分析计算一下。
a:50 分别是'a' ':' '5' '0' 这四个字符,对应的ASCII码是:
97 58 53 48(可用在线工具查询)
那么用十六进制表达就是:
61 3A 35 30
又因为,CDataStream的序列化,前面要加上描述数据大小的值,这里是4个字节。所以前面还得加上04,所以最终这个数据就是04 61 3A 35 30。
那么b:50按上面的计算就是 04 62 3a 35 30,所以这两个拼在一起,就是:
04613a353004623a3530
我们也可以用代码来输出一下,看序列化后的结果:
cpp
int main() {
CTransaction tx;
tx.vin = "a:50";
tx.vout = "b:50";
CDataStream ss;
ss << tx;
for (auto it = ss.begin(); it != ss.end(); ++it) {
printf("%02x ", (unsigned char)*it);
}
printf("\n");
uint256 txhash = tx.GetHash();
cout << txhash.ToString() << endl;
//BitcoinMiner();
}输出:
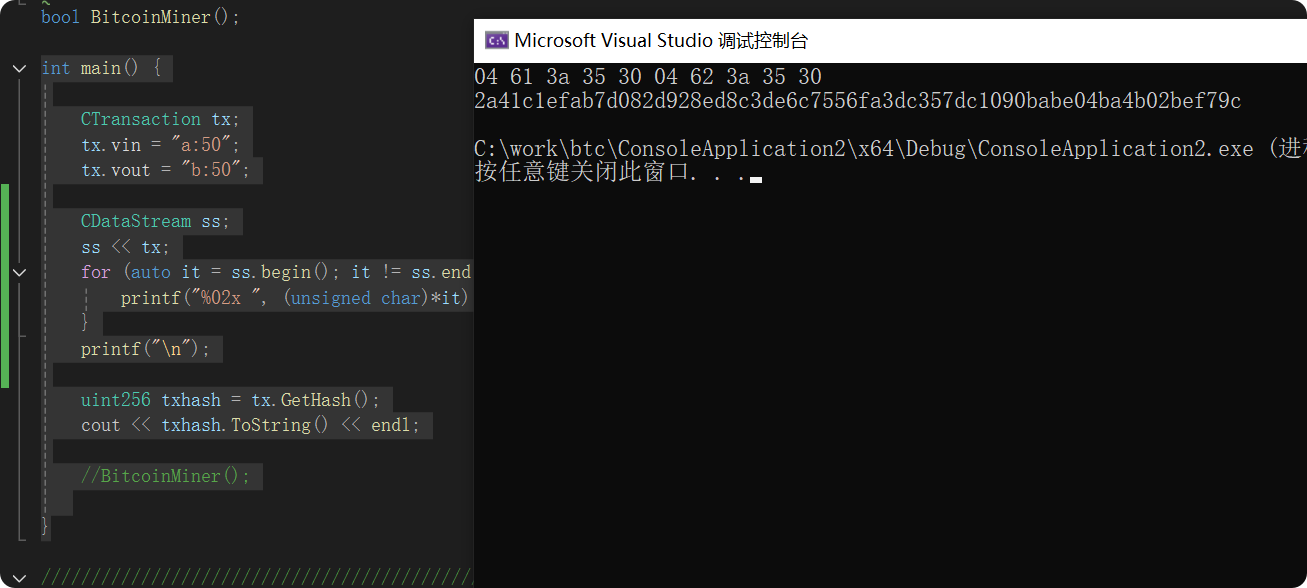
可以看到,再将tx序列化后,ss获得的值和我们计算出来的是一致的。
对象序列化后得到是这样一串数据,接着,就是将这串数据进行两次哈希。
6.手动验证结果
我们用在线工具来测试一下,注意要选择支持hex输入数据的,否则它会把0461...每个数字当成一一个字符,比如0,4,当成两个字符,但其实这是十六进制表达,04,只是一个ascii码,表达的是一个字符。如果你不选择hex模式,那么应该是a:10b:10之类的,当然前面还要加上04这个ascii对应的字符,这里仅举例,就不去查04实际对应那个字符了。
好,开始第一次哈希:
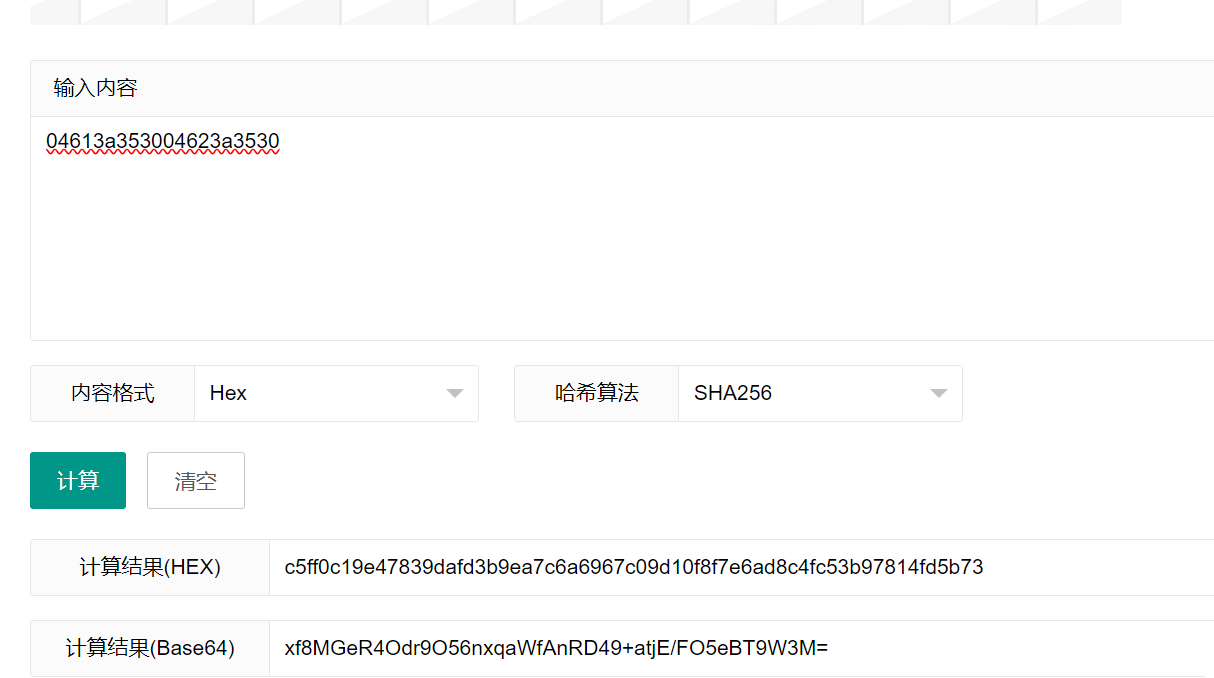
得到哈希值:
c5ff0c19e47839dafd3b9ea7c6a6967c09d10f8f7e6ad8c4fc53b97814fd5b73
接着将这个哈希值再哈希一次:
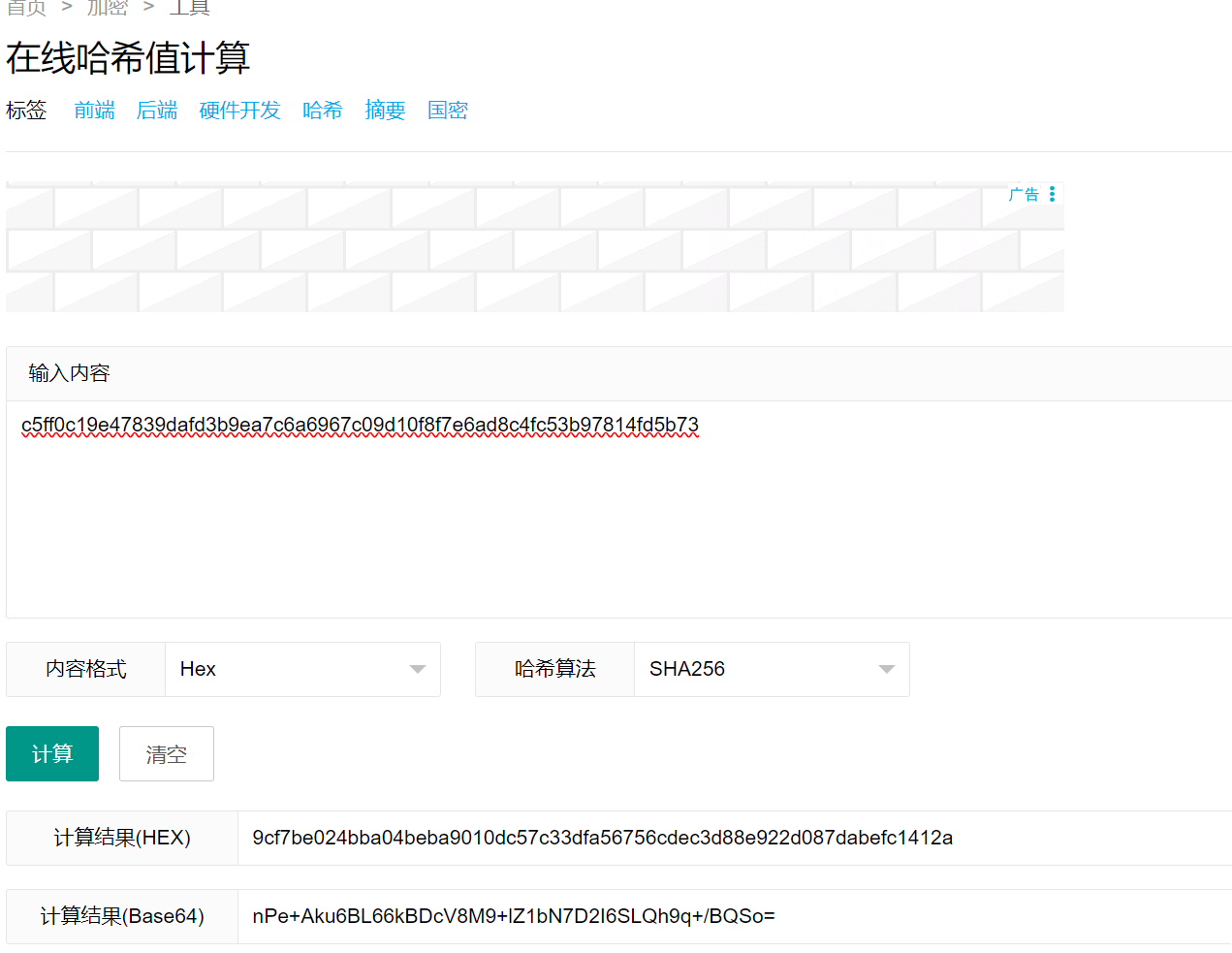
可以看到是9c开头?结果不对?结果是对的,哈希值已经正确储存,uint256的值也是一致的,只是大小端序的问题。需要反着展示,即从后往前看,不是a2141这样啊,两位代表一个字节。
所以是2a41c1.....9c,从后面两位一反转的看。所以这样结果就是对上了。