📖 点击展开/收起 文章目录
文章目录
- <本节内容简介>
- 快排(交换排序)
- 快排的优化
-
- 控制key位置
-
- [1. 三数选中](#1. 三数选中)
- [2. 随机数取keyi(key)](#2. 随机数取keyi(key))
- 大量重复数据存在
- 希望读者们多多三连支持
- 小编会继续更新
- 你们的鼓励就是我前进的动力!
<本节内容简介>
任务<>:重点讲述快排的多种方法实现,带你从零基础,到工业级快排的实现 |
快排(交换排序)
冒泡排序也是选择排序比较简单,大家下来就可以去实践,这里篇幅原因,就不过多介绍
这里就只给演示动画不单独做实现
hoare版本
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法
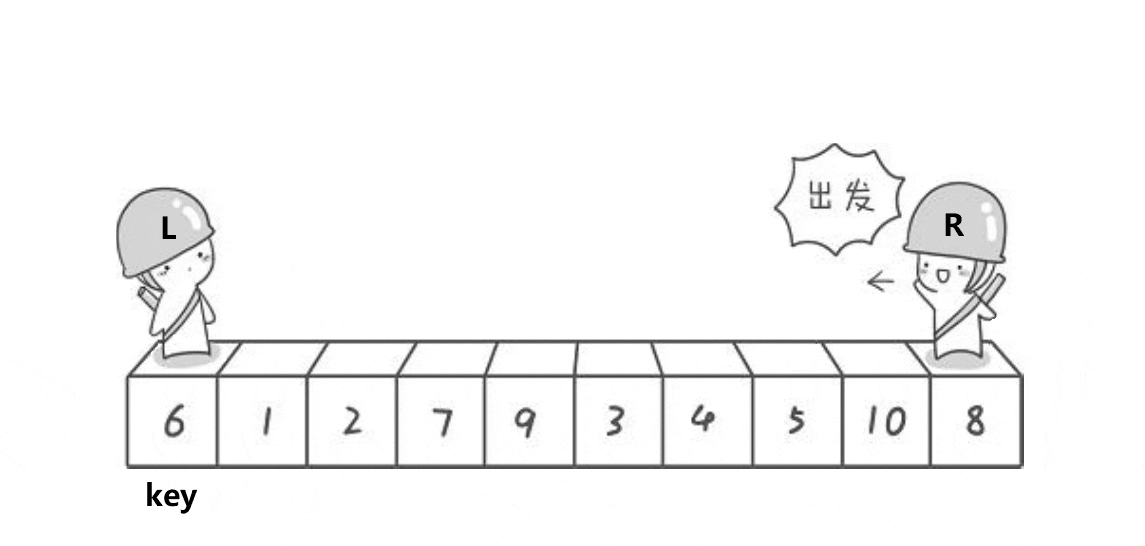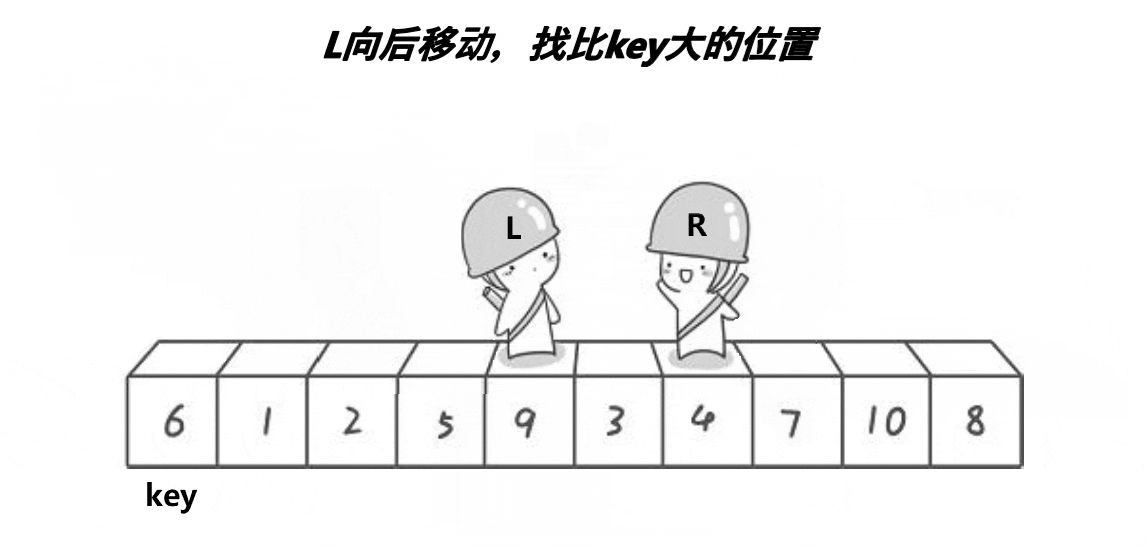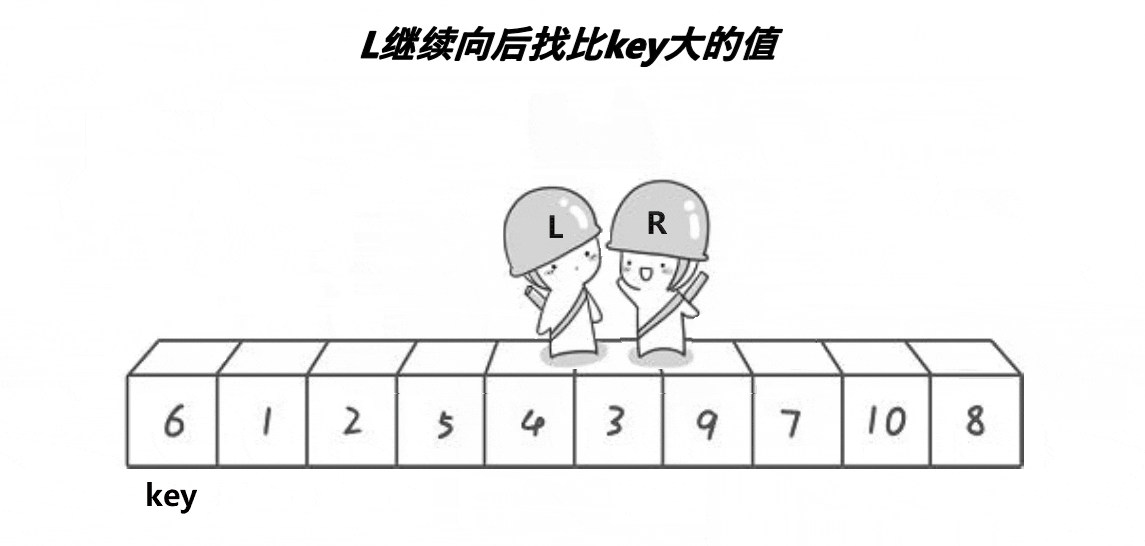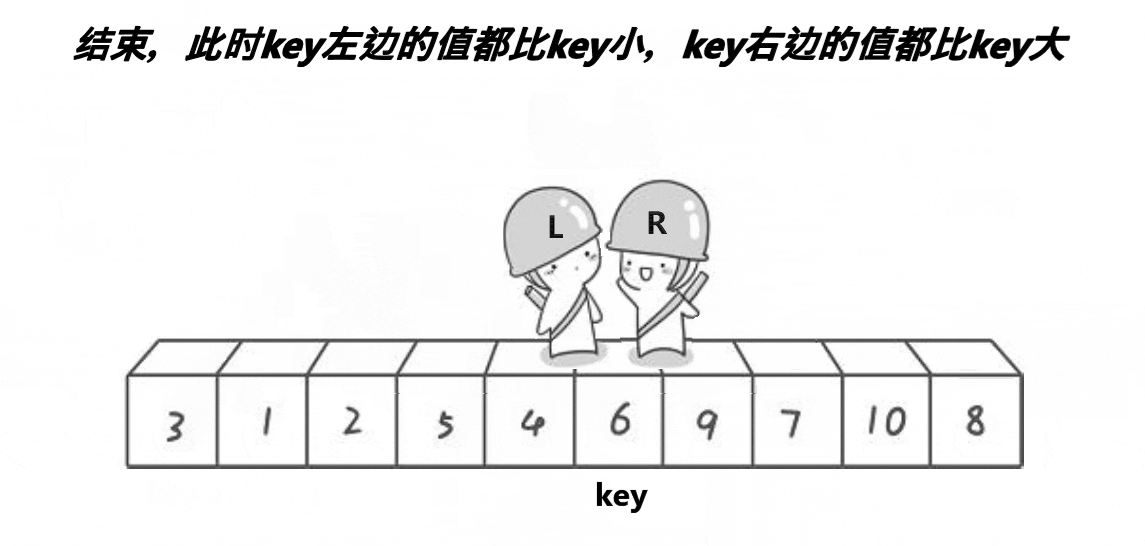
由图中我们可知,hoare版本下快排的基本逻辑是,右边一定先走 左边选大右边选小选取最左边的值为key最后与相遇位置交换下面我来讲解一下基本原理
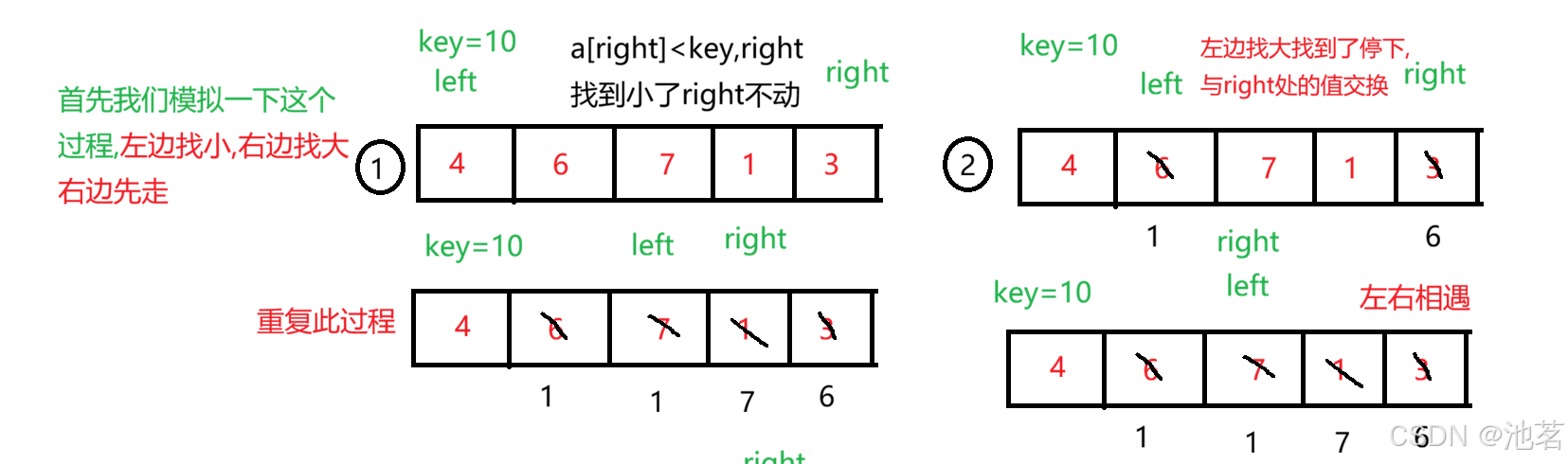
这里传参 会传begin end来记录传入区间的首尾,不做移动,移动由right和left完成
分割是靠相遇位置在这里a[keyi]=key,
这里做好赋值来分割区间
keyi = left;
hoare(a, begin, keyi - 1);
hoare(a, keyi + 1,end);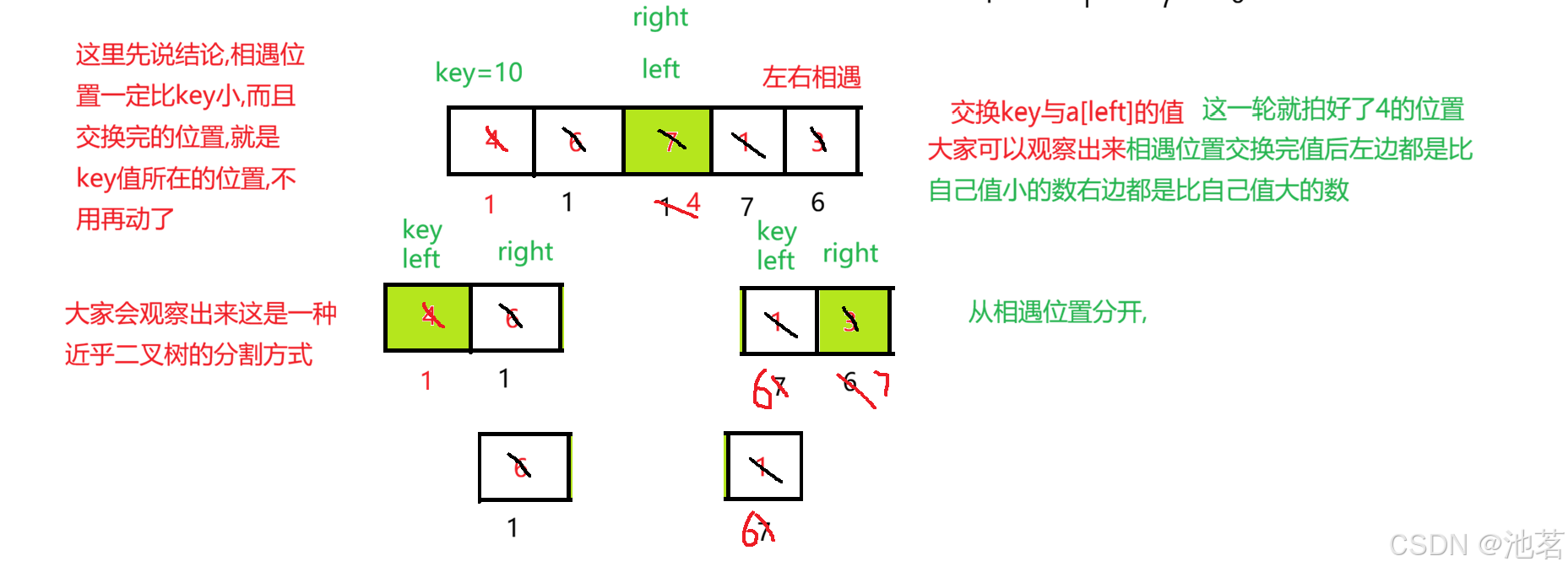
递归终止条件 就是 if (left >= right) { return; };
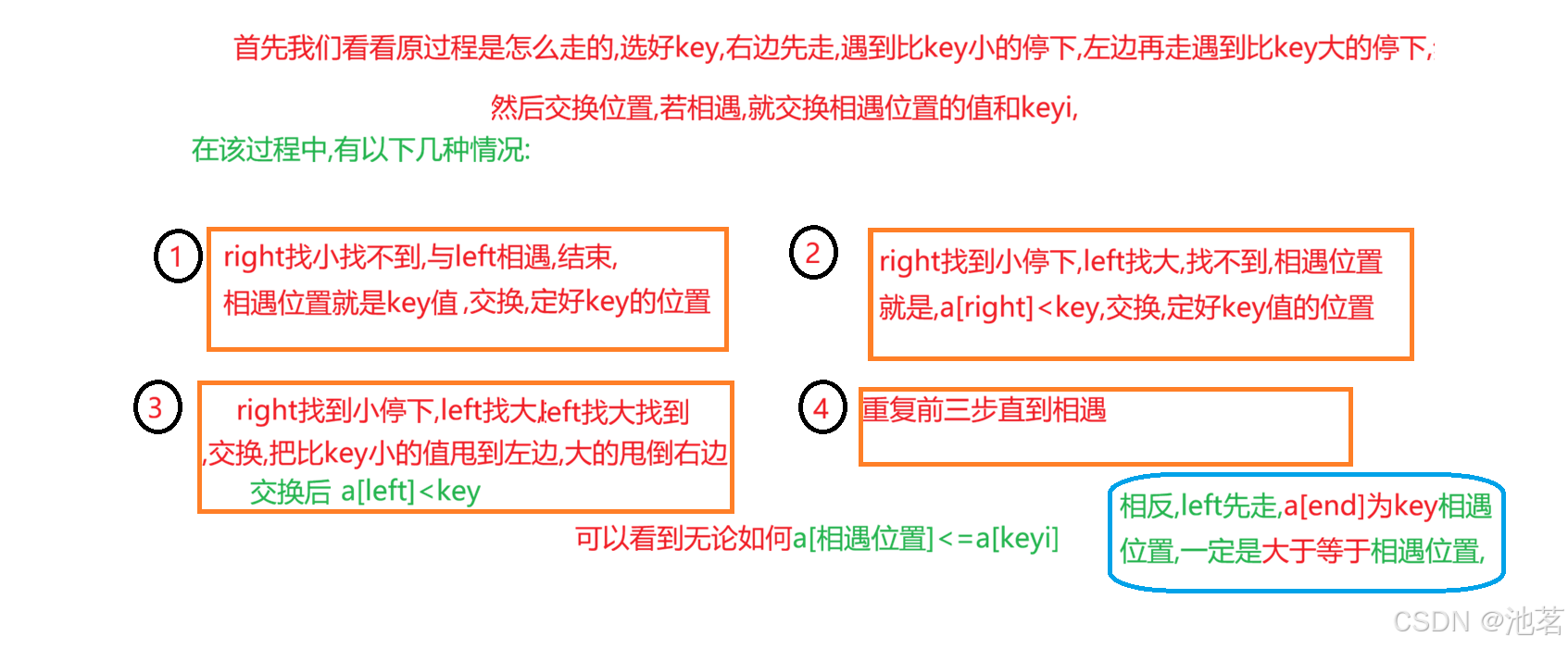
其实经过上面的讲解,大家还会有很多疑惑,
最经典的就是,为什么要从右先走,从左先走行不行?
为什么相遇位置就是一定比key的值小?
下面我来一一解答:
c
void hoare(int* a, int begin, int end)
{
int left = begin; int right = end;
if (left >= right) { return; };
int keyi = left;
while(left<right)
{
//右边找小
while (a[right] >= a[keyi] && left < right)
{
--right;
}
//左边找大
while (a[left] <= a[keyi] && left < right)
{
++left;
}
//交换大于key的值往左甩,小于key的值往右甩
swap(&a[left], &a[right]);
}
//交换相遇位置值与key的值
swap(&a[keyi], &a[left]);
//记得赋值
keyi = left;
hoare(a, begin, keyi - 1);
hoare(a, keyi + 1,end);
}lomuto版本(前后指针法)
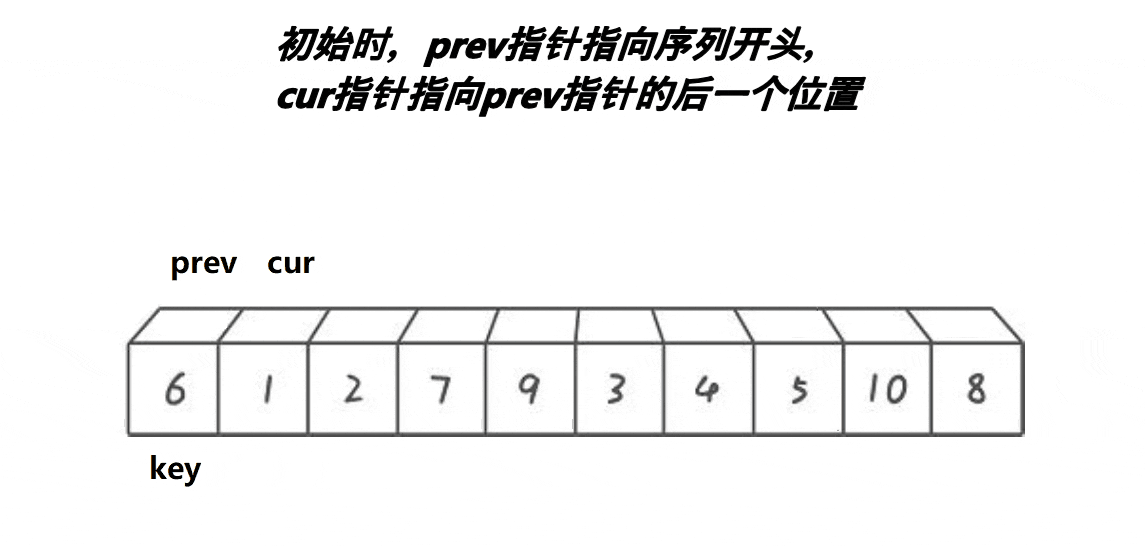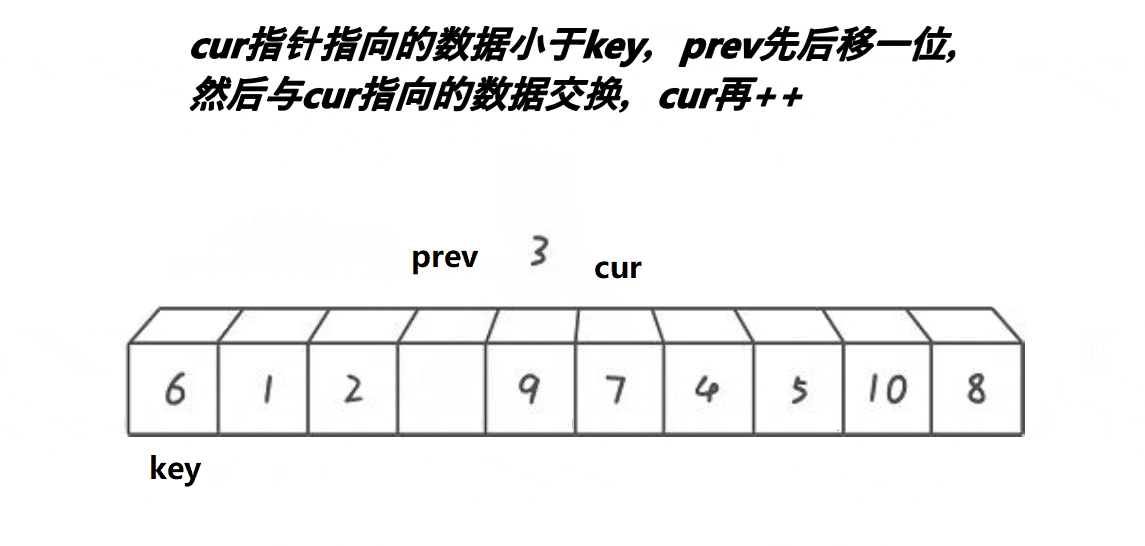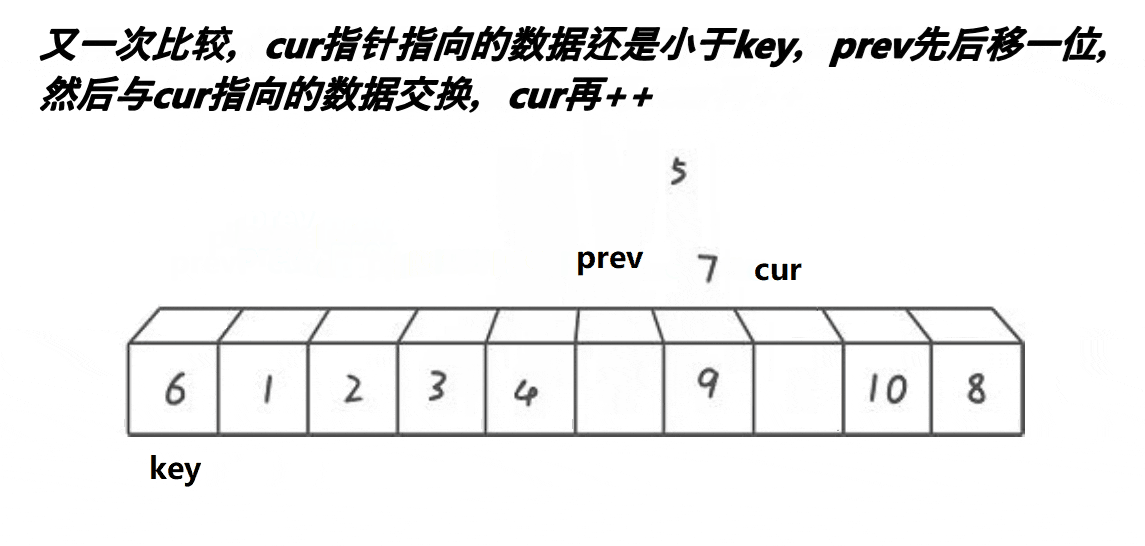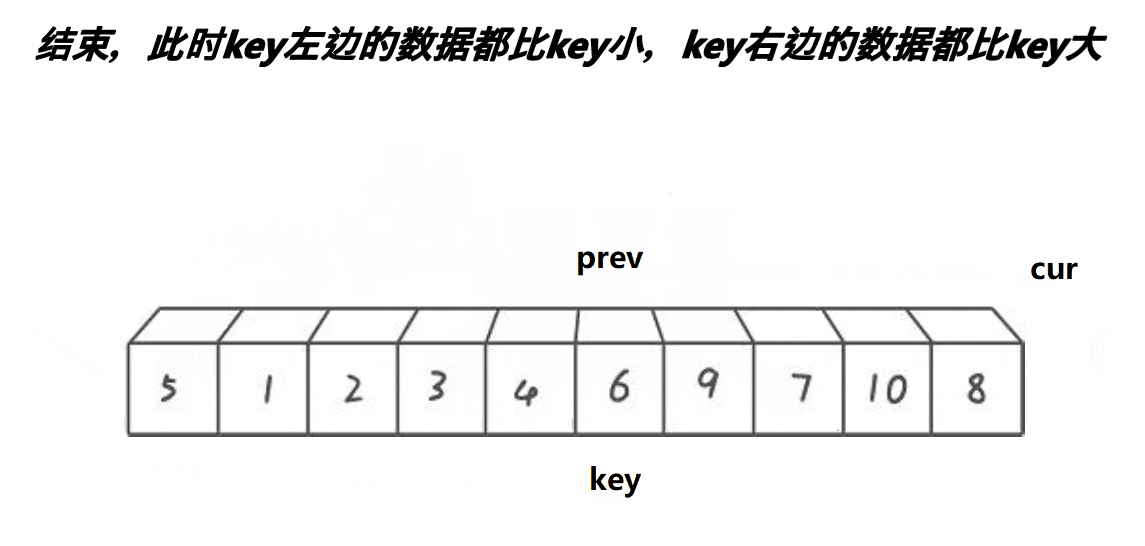
lomuto快排(前后指针)法思考起来很简单,效率与hoare
keyi还是和hoare版本的是一样的包括最后的分割,但这里结束,不是相遇,而是cur>end
下面简单讲解思路:
开始还是选key,定义prev=begin,cur=begin+1
逻辑是怎么走的呢?
cur每一轮循环都走一步,只是遇到小于key值的时候,prev++,prev跟着一起走,swap(&a[prev], &a[cur]);
最后结束,cur>end, swap(&a[keyi], &a[prev]);
那为什么这种方式可以做到和hoare版本做到分割呢
因为cur遇到比key大的值他自己走,遇到小于key值的时候,prev++,prev跟着一起走
这就会产生两种情况
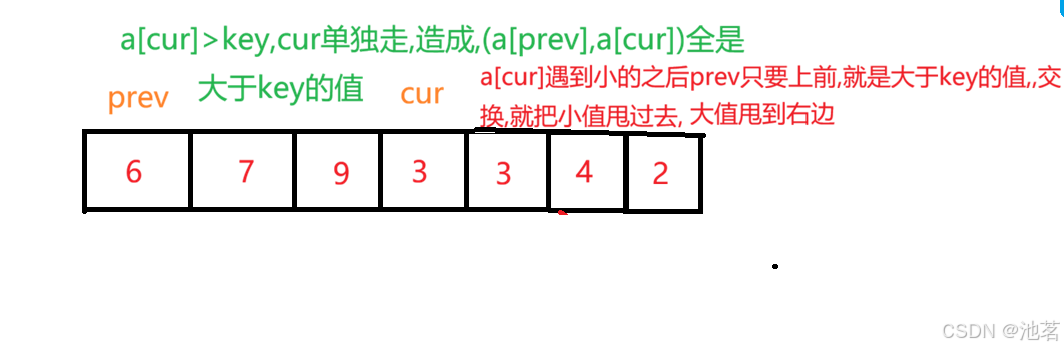
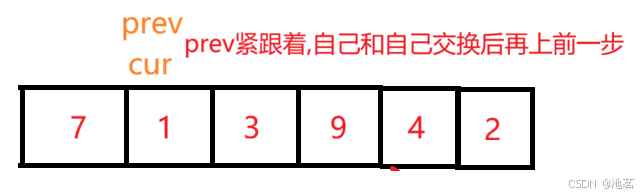
递归结束条件与hoare版本一致
c
void lomuto(int* a, int begin, int end)
{
if (begin >= end) { return; };
int prev, cur,keyi;
prev = keyi = begin;
cur = begin + 1;
while (cur <= end)
{
if (a[cur] < a[keyi])
{
++prev;
swap(&a[prev], &a[cur]);
}
++cur;
}
swap(&a[keyi], &a[prev]);
keyi = prev;
lomuto(a, begin, keyi-1);
lomuto(a, keyi+1, end);
}挖坑法
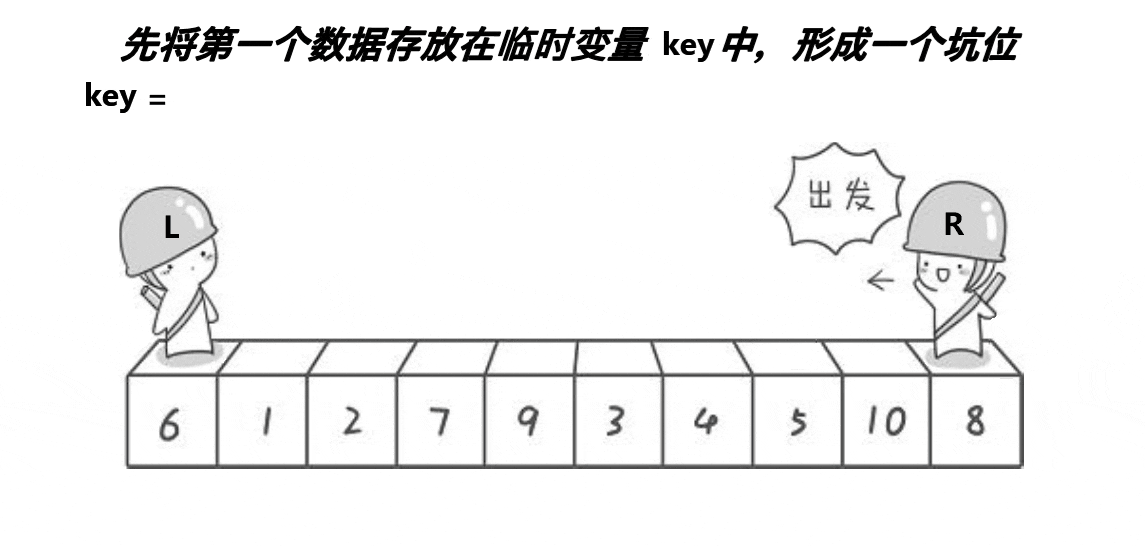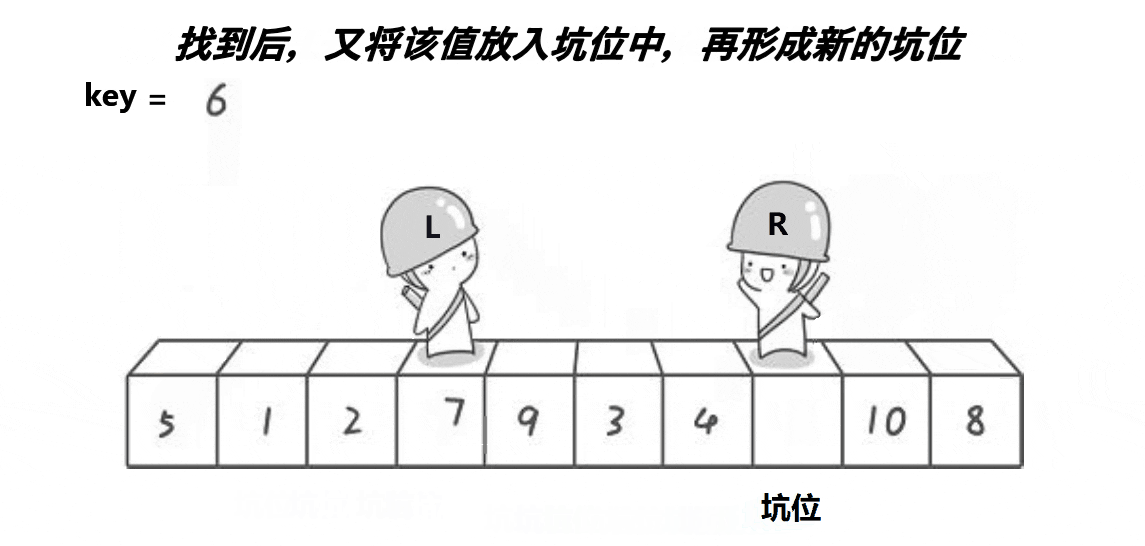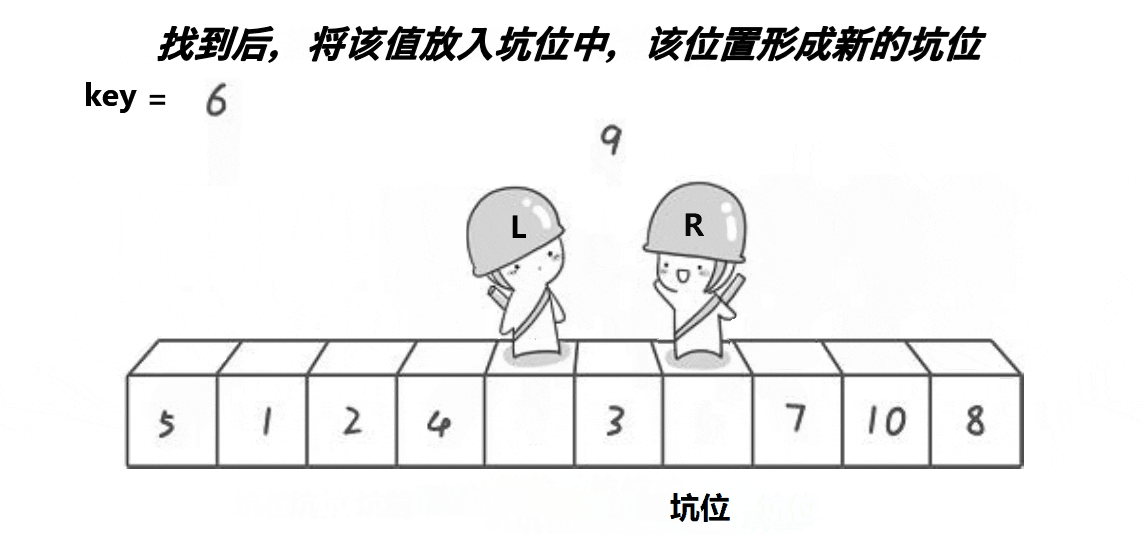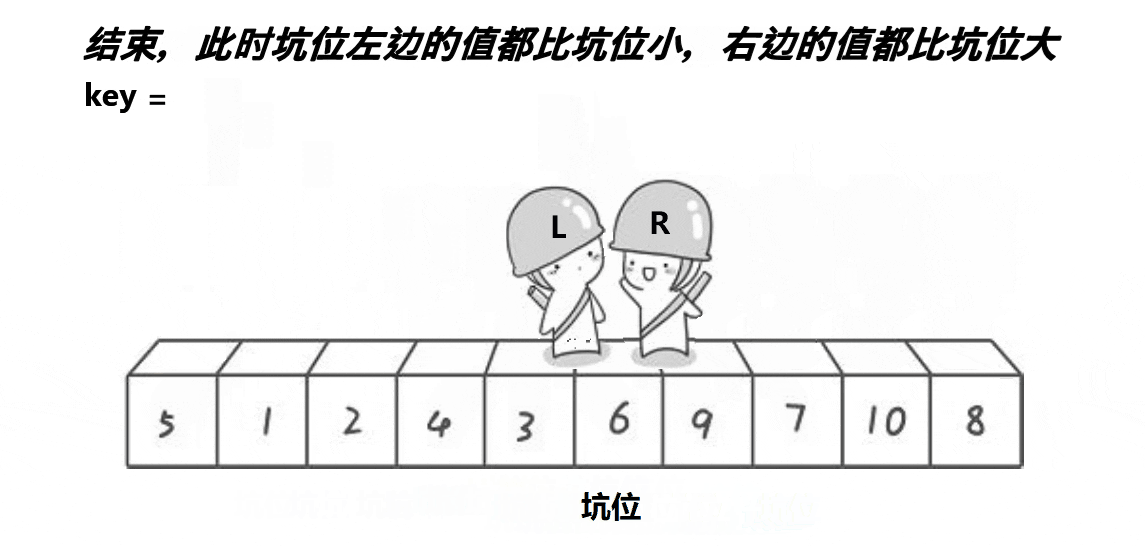
逻辑大体上还是与hoare一致
还是以最左值key,左边找小,右边找大,右边先走
区别: 右边找到小,就给a[left],左边再找大,找到了直接赋值给a[right]
key记录了第一个a[left],所以不怕赋值时候会丢值
结束条件,left与right相遇
递归结束条件与hoare相同
c
void QuickSort2(int* a, int left,int right)
{
if (left >= right)
return;
int begin, keyi, end;
//我框起来的两部分是优化我会在下面进行讲解
/////////////////////////////////////////
//if (right - left < 10) //
//{ //
// InsertSort(a + left, right - left + 1); //
//} //
////////////////////////////////////////
else
{
///////////////////////////////////////////
// keyi = GetMid(a, left, right); //
// Swap(&a[keyi], &a[left]); //
// keyi = left; //
///////////////////////////////////////////
begin = left;
end = right;
int key = a[keyi];
while (begin < end)
{
//注意这里a[keyi]在变化不能用a[keyi]
while (a[end] >= key && begin < end)
{
end--;
}
a[begin] = a[end];
while (a[begin] <= key && begin < end)
{
begin++;
}
a[end] = a[begin];
}
a[begin] = key;
keyi = begin;
QuickSort2(a, left, keyi - 1);
QuickSort2(a, keyi + 1, right);
}
}非递归实现
我框起来的两部分是优化,大家可以先跳过不看,我会在下面进行详细讲解
利用栈和队列实现快速排序的非递归版本,其核心逻辑是相似的,主要区别在于使用时需要根据栈(后进先出)和队列(先进先出)各自的数据结构特性来调整区间处理的顺序性,在这里
我把两种方法代码都拿出来了,自取,但是这里只对栈模拟实现非递归做讲解
有需要栈和队列的可以在下面自取
栈的代码
队列的代码
利用栈
我们要知道,栈的作用,在这里就是帮我们模拟递归分割区间的
1. 首先你要把最初传入的左右区间给入栈
2. 在循环中用begin,end来取左右区间,取完就pop
3. 在进行排序核心逻辑找到对应key的位置之后分割左右区间
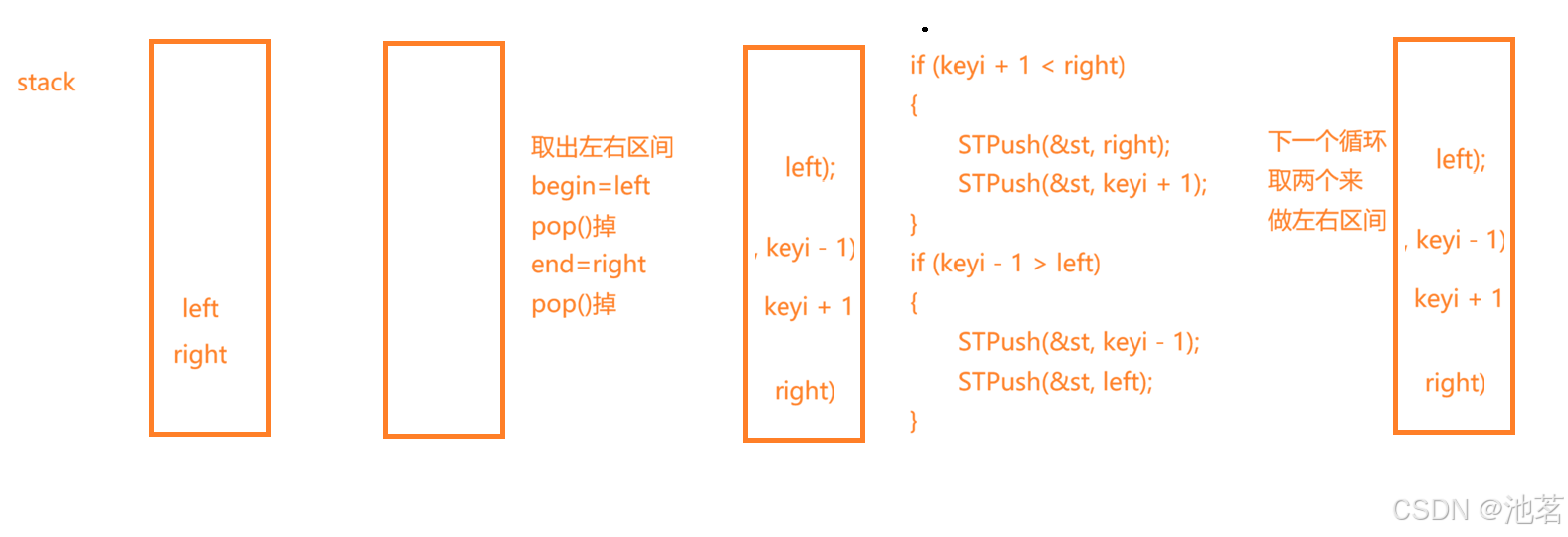
c
void QuickSort4(int* a, int left, int right)
{
Stack st;
//初始化栈
STInit(&st);
//插入左右区间
STPush(&st, right);
STPush(&st, left);
int begin,end,keyi;
while (!STEmpty(&st))
{
//取出左右区间
left = STTop(&st);
STPop(&st);
right = STTop(&st);
STPop(&st);
/////////////////////////////////////////
//if (right - left < 10) //
//{ //
// InsertSort(a + left, right - left + 1); //
//} //
////////////////////////////////////////
else
{
begin = left;
end = right;
///////////////////////////////////////////
// keyi = GetMid(a, left, right); //
// Swap(&a[keyi], &a[left]); //
// keyi = left; //
///////////////////////////////////////////
//快排核心逻辑
while (begin < end)
{
while (a[end] >= a[keyi] && begin < end)
{
end--;
}
while (a[begin] <= a[keyi] && begin < end)
{
begin++;
}
Swap(&a[begin], &a[end]);
}
Swap(&a[keyi], &a[begin]);
keyi = begin;
//模拟递归分割区间
if (keyi + 1 < right)
{
STPush(&st, right);
STPush(&st, keyi + 1);
}
if (keyi - 1 > left)
{
STPush(&st, keyi - 1);
STPush(&st, left);
}
}
}
STDestory(&st);
}利用队列
c
void QuickSort5(int* a, int left, int right)
{
Queue q;
QueueInit(&q);
QueuePush(&q, left);
QueuePush(&q, right);
int begin, end, keyi;
while (!QueueEmpty(&q))
{
//取出左右区间
left = QueueFront(&q);
QueuePop(&q);
right = QueueFront(&q);
QueuePop(&q);
/////////////////////////////////////////
//if (right - left < 10) //
//{ //
// InsertSort(a + left, right - left + 1); //
//} //
////////////////////////////////////////
else
{
begin = left;
end = right;
///////////////////////////////////////////
// keyi = GetMid(a, left, right); //
// Swap(&a[keyi], &a[left]); //
// keyi = left; //
///////////////////////////////////////////
//快排核心逻辑
while (begin < end)
{
while (a[end] >= a[keyi] && begin < end)
{
end--;
}
while (a[begin] <= a[keyi] && begin < end)
{
begin++;
}
Swap(&a[begin], &a[end]);
}
Swap(&a[keyi], &a[begin]);
keyi = begin;
//模拟递归分割区间
if (keyi - 1 > left)
{
QueuePush(&q, left);
QueuePush(&q, keyi - 1);
}
if (keyi + 1 < right)
{
QueuePush(&q, keyi + 1);
QueuePush(&q, right);
}
}
}
QueueDestory(&q);
}
快排的优化
控制key位置
我们知道快排是Nlog(N)的排序算法,之所以是N log(N),核心还是选key,
如果选key不佳快排就会退化到O(N^2)所以说选key还是个技术活
如果不做处理按最坏情况,给你一个升序让你排降序,right每次要走到最右边与left相遇
算法就退化到O(N^2`)了

正常我们希望看到的是最是这种比较,均分的值它的高度就是log(N)排序就很快

因此我们就要找靠中间位置的数,下面介绍两种方法:
三数取中,随机数取keyI并不能保证选出的 key 是真正的中位数,左右区间仍然可能很不平衡。 那为什么说它"优化"了呢?原因在于它极大地降低了最坏情况出现的概率,而不是完全消除不平衡。
1. 三数选中
找到数组中间位置的数,返回(中间位置,左,右)这三个数的中位数
逻辑和简单如下:
c
int GetMid(int*a,int left,int right)
{
int mid = (left + right) / 2;
if (a[mid] > a[left])
{
if (a[mid] > a[right])
{
if (a[left] > a[right])
{
return left;
}
else
{
return right;
}
}
else
{
return mid;
}
}
else if(a[mid]>a[right])
{
return mid;
}
else
{
if(a[left]>a[right])
return right;
return left;
}
}2. 随机数取keyi(key)
这个逻辑更简单,就是在(left,right)中间随机选择一个数,来作为keyi
c
int RandomPivot(int*a,int left,int right)
{
return rand() % (right - left + 1) + left;
}大量重复数据存在
有前面两种优化,这里有有个问题,加入这里有大量重复数据出现,我们选到重复数据, 的概率很大,排序就又退化了,因此我们就又要解决问题,这也刚好回应解释了
三数取中,随机数取keyI并不能保证选出的 key 是真正的中位数,左右区间仍然可能很不平衡
三路划分
三路划分与hoare版本代码的区别就是他多了一个分支,遇到等于key值的时候就直接跳过

c
void KeyWayIndex(int* a, int begin, int end)
{
if (begin >= end) { return; };
int left = begin; int right = end; int cur = begin + 1;
int key = a[left];
while (cur <= right)
{
if (a[cur] < key)
{
swap(&a[left], &a[cur]);
++left;
}
else if (a[cur] > key)
{
swap(&a[right], &a[cur]);
--right;
}
else
++cur;
}
KeyWayIndex(a, begin, left - 1);
KeyWayIndex(a, right + 1, end);
}自省快排(工业实现)
自省快排,就比较智能,他不管你那么多,只要递归深度深了,我就切换算法,属于是快刀斩乱麻
需要的堆排序和直接插入排序放在下面自取
堆排序
直接插入排序具体是怎么切换的呢
当
递归深度大于2倍logN,这里N是数据量,如果begin,end数量小于16就切换直接插入排序
这是工业及代码的思想,了解各种排序,取长补短
注意:这里有个大坑
这里排序排的是[begin,end],不是[0,end],要对a+begin来排序
c
if (end - begin + 1 < 16)
{
InsertSort(a+begin, end - begin + 1);
}
if (depth >= 2 * defaultDepth)
{
HeapSort(a + begin , end - begin + 1);
}
c
void introsort(int* a, int begin, int end , int depth, int defaultDepth)
{
if (begin >= end) { return; };
//大家注意这里要从begin位置开始写,从0开始逻辑就错误了
//只是走的逻辑不是我们的自省排序而是插入或者堆排,会排很多,并不是我们想让他排的地方
//会打乱排序递归分割
if (end - begin + 1 < 16)
{
InsertSort(a+begin, end - begin + 1);
}
if (depth >= 2 * defaultDepth)
{
HeapSort(a + begin , end - begin + 1);
}
else
{
int left = begin; int right = end;
int keyi = left;
while (left < right)
{
//右边找小
while (a[right] >= a[keyi] && left < right)
{
--right;
}
//左边找大
while (a[left] <= a[keyi] && left < right)
{
++left;
}
swap(&a[left], &a[right]);
}
swap(&a[keyi], &a[left]);
keyi = left;
depth++;
introsort(a, begin, keyi - 1, depth, defaultDepth);
introsort(a, keyi + 1, end, depth, defaultDepth);
}
}下面是力扣上的排序,在这里你就必须考虑大量重复数据的情况,他卡的很严格因此官方排序也没过
力扣排序OJ