位置编码(Positional Encoding, PE) 是自然语言处理(NLP)中,特别是 Transformer 模型架构里的一个核心概念。
它的作用是给序列中的每个词(Token)注入"顺序"或"位置"信息。
一、WHY:为什么需要位置编码
1. 核心原因:Self-Attention 机制缺乏"顺序感"
Transformer 的核心组件是 Self-Attention(自注意力机制),它的计算方式是并行的,且具有排列不变性(Permutation Invariance)。
-
并行计算:模型一次性看到所有词,而不是像 RNN 那样一个一个按顺序处理。
-
排列不变性:在数学上,如果你打乱输入句子中词的顺序,Self-Attention 输出的向量集合内容是一样的(只是顺序变了)。
- 例如:输入
"I love AI"和"AI love I",如果没有位置信息,模型计算出的注意力权重集合是完全相同的。
- 例如:输入
2. 语言数据的本质:顺序决定语义
自然语言(NLP)是序列数据,词的顺序直接决定含义。
-
例子 1(主谓宾关系):
-
"
猫抓老鼠" vs "老鼠抓猫" -
词完全一样,但顺序不同,语义截然相反。
-
-
例子 2(否定词位置):
-
"
我喜欢这个产品" vs "我不喜欢这个产品" -
否定词的位置决定了情感极性。
-
如果没有位置编码,模型无法区分上述差异,导致无法理解语言逻辑。
3. 与 RNN/CNN 的对比
|-------------|----------|-----------------------------|
| 模型架构 | 是否有天然顺序感 | 是否需要 Position Embedding |
| RNN / LSTM | ✅ 有 | ❌ 不需要(按时间步 sequentially 处理) |
| CNN | ✅ 有 | ❌ 不需要(卷积核按顺序滑动) |
| Transformer | ❌ 无 | ✅ 必须需要 |
4. Position Embedding 的作用
它的作用是显式地将"位置信息"注入到输入向量中,弥补 Transformer 的缺陷。
-
实现方式:将一个代表位置的向量(Position Vector)加到词嵌入向量(Word Embedding)上。 Input=Token Embedding+Position Embedding
-
效果:即使词相同,只要位置不同,最终输入模型的向量就不同。模型因此能够学习到"词 A 在词 B 前面"这样的顺序依赖关系。
5. 结论
-
弥补架构缺陷:Transformer 的 Self-Attention 机制本身无法感知词序。
-
保留语义逻辑:确保模型能区分"谁对谁做了什么"(主谓宾关系)。
-
实现并行计算:为了让 Transformer 能并行处理序列(比 RNN 快),必须牺牲天然的顺序感,并通过 PE 显式补回位置信息。
二、HOW:如何实现位置编码
1. 用整型值标记位置
核心思想:直接使用 1, 2, 3, ..., N 作为位置 ID,通过 Embedding 层查找向量。
这种方法带来的问题是:
-
泛化性差(外推能力弱):模型训练时最大长度可能是 512。如果推理时遇到长度为 1024 的句子,模型会遇到从未见过的位置 ID(如 513),导致 Embedding 查找失败或随机初始化,性能急剧下降。
-
数值无界:位置值无限增大,导致 Embedding 向量的分布难以稳定,可能影响梯度更新。
2. 用0,1范围标记位置
2.1 核心思想:位置归一化(Position Normalization)
这种方法的核心思想是将绝对的索引值转化为相对的比例值。它不再关心一个 token 具体是第几个(如第 1 个、第 100 个),而是关心它在整个序列中所处的相对进度。
2.2 设计逻辑
-
边界固定:无论序列多长,起始位置永远标记为
0,结束位置永远标记为1。 -
均匀分布:中间的 token 根据序列总长度,均匀地分布在 0 到 1 之间。
-
序列长度 = 3:位置为
[0, 0.5, 1]。每个间隔为0.5。 -
序列长度 = 4:位置为
[0, 0.33, 0.69, 1]。每个间隔约为0.33。
-
-
目的:试图解决整型值标记带来的"数值无界"问题,将位置信息压缩到一个固定的浮点数范围内,避免位置值随序列长度无限增大。
2.3 核心缺陷:相对距离的语义不一致性
这种方法虽然解决了数值范围问题,但引入了一个更严重的语义问题:Token 间的相对距离随序列长度变化而变化。
2.3.1 缺陷详解
在自然语言处理中,距离往往代表着语法或语义的关联强度。
-
短序列(长度 3):相邻 token 的数值距离是
0.5。 -
长序列(长度 4):相邻 token 的数值距离变成了
0.33。 -
更长序列:这个距离会变得更小(如长度 10 时,距离为 0.11)。
2.3.2 为什么这是致命问题?
模型在学习语言规律时,会建立"数值距离"与"语义关系"之间的映射。
-
假设模型学习到:当两个词的position距离为
0.5时,它们通常是"主谓关系"(紧密关联)。 -
冲突发生:
-
在一个短句中,相邻词的距离是
0.5,模型能正确识别为主谓关系。 -
在一个长句中,相邻词的距离变成了
0.1,模型可能会认为这两个词"距离很远",从而忽略它们之间的语法关联。
-
-
后果:模型无法形成稳定的位置感知。它学到的位置规律无法在不同长度的句子之间迁移。同样的语法结构,仅仅因为句子变长了,在模型眼里的"位置距离"就变了,导致理解能力下降。
2.4 理想的位置表示方式
2.4.1. 能表示 Token 的绝对位置
-
含义:模型需要知道某个词具体在句子的哪个位置(例如是开头、中间还是结尾)。
-
必要性:某些语义依赖于绝对位置。例如,句首的词通常是主语,句尾的词可能是结论。如果只告诉模型"你在 50% 的位置",模型可能无法区分这是一个短句的中间,还是长句的中间。
2.4.2. 不同序列长度下,相对位置/距离保持一致
-
含义:无论句子长短,相邻两个词之间的"位置编码距离"应该是固定的(或者遵循某种固定规律),而不是随长度缩放。
-
必要性:这是为了解决上述核心缺陷。确保模型学到的"近距离依赖"规则,在短句和长句中都能通用。
2.4.3. 能表示训练过程中从未看到过的句子长度(外推性)
-
含义:模型训练时可能只见过长度为 512 的句子,但在实际使用时,需要处理长度为 1024 或 2048 的句子。位置编码方法必须支持这种泛化。
-
必要性:实际应用场景中,输入长度是不可控的。如果位置编码只能处理训练过的长度,模型的实用性将大打折扣。
3. 二进制数字位置编码
-
核心定义:将 token 在序列中的位置索引(Index)直接转换为二进制向量,作为位置编码加到 token 的词向量上。
-
假设条件:
-
每个 token 的表征维度为 d (例如 d=4)。
-
位置索引 p 从 0 开始。
-
使用 d 位二进制数来表示位置 p。
-
-
编码规则:以4维二进制编码为例,前9个token的位置编码如下:
|---------|-----|----------------|
| Token位置 | 十进制 | 二进制向量 (dim=4) |
| Pos 0 | 0 | 0, 0, 0, 0 |
| Pos 1 | 1 | 0, 0, 0, 1 |
| Pos 2 | 2 | 0, 0, 1, 0 |
| Pos 3 | 3 | 0, 0, 1, 1 |
| Pos 4 | 4 | 0, 1, 0, 0 |
| Pos 5 | 5 | 0, 1, 0, 1 |
| Pos 6 | 6 | 0, 1, 1, 0 |
| Pos 7 | 7 | 0, 1, 1, 1 |
观察规律:
-
最低位(最右边,dim 3):每个token都变化(0→1→0→1...),变化最快
-
次低位(dim 2):每2个token变化一次(00→11→00→11...)
-
次高位(dim 1):每4个token变化一次
-
最高位(最左边,dim 0):每8个token才变化一次,变化最慢
二进制低位 → 高频(变化快)
二进制高位 → 低频(变化慢)
- 二进制编码缺陷:
离散的二进制数字编码会出现跳变,而处于两个跳变区间的值全部相同(要么全为0,要么全为1)。这种情况下,模型很难感知到这些维度上的位置变化
4. Sinusoidal位置编码
4.1 sinusoidal连续性
参数说明
|------|---------------|-------------------------|
| 符号 | 含义 | 示例 |
| pos | Token 在序列中的位置 | 0,1,2,3... |
| i | 维度索引的一半 | i = 0, 1, 2, ..., d/2-1 |
| d | 位置编码向量的总维度 | 如 d=512 |
| 2i | 偶数维度(使用sin) | 0, 2, 4, ... |
| 2i+1 | 奇数维度(使用cos) | 1, 3, 5, ... |
示例分析:
当i=0时(第0维和第1维)
周期分析:
sin函数的完整周期是2π ≈ 6.283,意味着每 6.2 个 token,第 0 维的编码值就"绕完"一圈
pos=0: sin(0) = 0.00
pos=1: sin(1) = 0.84
pos=2: sin(2) = 0.91
pos=3: sin(3) = 0.14
pos=4: sin(4) = -0.76
pos=5: sin(5) = -0.96
pos=6: sin(6) = -0.28
pos=7: sin(7) = 0.66 ← 开始新周期当i=1时(第二维和第三维):
假设d=512,代入公式:
其中,
所以:
周期分析:
新周期=1.029×2π≈6.468
频率分布规律 (不同维度的波长对比(d=512))
|-------|-------------|---------------------------------------------------------|--------|-----|
| 维度 i | 对应维度 | 波长计算 | 波长值 | 频率 |
| i=0 | dim 0,1 | | 6.28 | 最高频 |
| i=1 | dim 2,3 | | 6.47 | 高频 |
| i=2 | dim 4,5 | | 6.66 | 中高频 |
| ... | ... | ... | ... | ... |
| i=255 | dim 510,511 | | 63,662 | 最低频 |
总结:低维度高频编,高维度低频编
Sinusoidal位置编码优势:
-
✅ 每个位置的编码都不同
-
✅ 相邻位置的编码差异平滑
-
✅ 模型可以轻松感知任意位置变化
4.2 Sinusoidal的线性表示
sin(A +B )=sinA cosB +cosA sinB
cos(A +B )=cosA cosB −sinA sinB
- 这两个公式将角度相加的三角函数,分解为单独角度的线性组合
位置关系推导:
原始公式:
代入pos+k:
令:
所以:
其中,
所以:
公式结构分析:
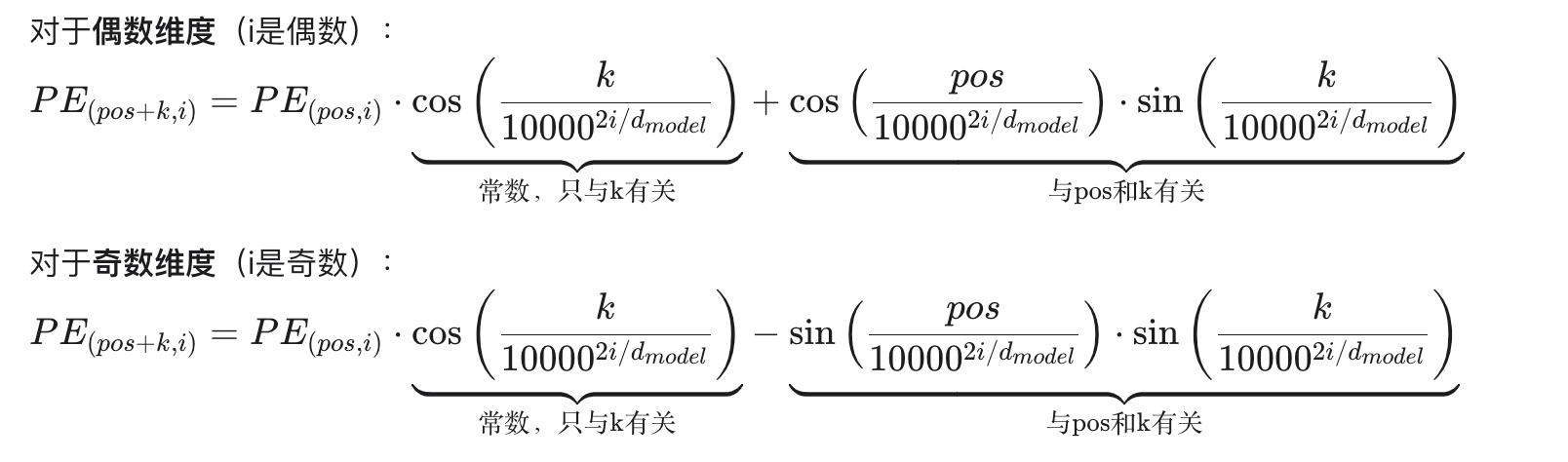
根据以上公式:
可以表示为
的线性组合
形式为:ax+b,其中:
-
-
-
b = ±cos/sin(pos /⋯)⋅sin(k/⋯)
|------|------------------------------------------------------------------------------------------|--------|
| 特性 | 说明 | 优势 |
| 线性关系 | 相对位置编码可以用线性函数表示 | 模型容易学习 |
| 相对位置 | 与
的关系只依赖于k | 捕捉相对距离 |
| 参数固定 | 系数只与k 和维度 i有关,与 无关 | 泛化能力强 |
4.3 Sinusoidal的相对位置信息
在Self-Attention机制中,模型能够感知两个不同token位置信息的关键时刻是Query和Key的计算过程。
公式如下:
将上式展开可得:
其中,第一项为token信息交互,第二项为key的位置信息,第三项为query的位置信息,第四项为key和query的位置信息交互。
因为Query和Key的位置编码同时出现在第四项,所以这一项可能与相对位置有关。但原式子中,原始的位置编码 和
都经过了线性映射,这让分析变得困难。为了简化,我们先把这两个线性映射当作恒等映射
。那么相对位置这一项就可以简化成了
。
,
其中 2ℎ 表示维度索引; d是总维度大小。上式中,向量的两个维度分别对应维度 2ℎ 和维度 2ℎ+1 的位置编码。为进一步简化符号,记:
那么,
,
利用上式计算向量内积:
利用三角函数性质:
所以:
根据以上公式,按照Sinusoidal位置编码的定义,如果我们不给两个位置编码引入额外的线性变化,那么 就能实现相对位置编码