1. 引言
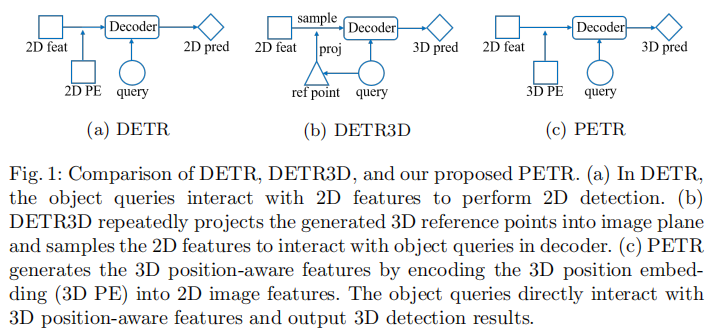
在自动驾驶系统中,基于多视图图像的 3D 目标检测因成本优势成为研究热点。传统方法多从单目目标检测视角切入,而近年来 DETR 框架凭借端到端检测的创新性受到广泛关注。DETR3D 作为 DETR 在 3D 领域的延伸,通过将 3D 参考点投影回图像空间采样 2D 特征实现检测,但这种 2D-to-3D 变换存在参考点定位不准、缺乏全局特征学习、特征采样流程复杂等问题,限制了其实际应用。
为此,MEGVII Technology 的研究团队提出了 PETR(Position Embedding Transformation for Multi-View 3D Object Detection)框架,创新性地将 3D 位置信息编码到 2D 图像特征中,生成 3D 位置感知特征,使目标查询能直接在 3D 环境中更新,无需在线 2D-to-3D 投影和特征采样。该方法在 nuScenes 数据集上取得了 50.4% NDS 和 44.1% mAP 的 SOTA 性能,位居基准测试榜首,为后续研究提供了简洁且强大的基线模型。
原文链接:https://arxiv.org/pdf/2203.05625
代码链接:https://github.com/megvii-research/PETR
沐小含持续分享前沿算法论文,欢迎关注...
2. 相关工作回顾
2.1 Transformer-based 目标检测
Transformer 凭借自注意力机制能有效建模长距离依赖关系,在目标检测领域得到广泛应用。其核心是通过位置嵌入(Position Embedding)为特征注入位置信息,适用于图像、序列、视频等多种数据类型。
- Transformer-XL 采用相对位置嵌入编码 token 间的相对距离;
- ViT 将学习到的位置嵌入添加到图像块表示中;
- MViT 分解相对位置嵌入的距离计算,建模时空结构。
DETR 首次将 Transformer 引入 2D 目标检测,通过目标查询与 2D 特征的交互实现端到端检测,但存在收敛速度慢的问题。后续改进方法如 Encoder-only DETR、SMAC、Deformable DETR 等通过优化注意力机制或引入位置先验加速收敛。SOLQ 则在 DETR 基础上实现了分类、边界框回归和实例分割的多任务统一。
2.2 基于视觉的 3D 目标检测
基于视觉的 3D 目标检测可分为图像视图检测和 3D 世界空间检测两类:
- 图像视图检测方法(如 M3D-RPN、FCOS3D、PGD)直接在 2D 图像上学习 3D 相关特征,但面临深度估计不准确的问题。例如 PGD 通过概率表示缓解深度不确定性,但增加了计算开销和推理延迟;DD3D 通过大规模深度数据集预训练提升性能。
- 3D 世界空间检测方法(如 OFT、CaDDN、ImVoxelNet、BEVDet)将 2D 特征映射到鸟瞰图(BEV)或 3D 体素空间进行检测。DETR3D 则延续 DETR 的查询机制,通过 3D 参考点投影采样 2D 特征,但存在投影误差和局部特征依赖问题。
BEV-based 方法易产生 Z 轴误差,而 DETR-based 方法能从端到端建模和数据增强中获益更多。PETR 作为 DETR-based 方法,通过编码 3D 位置信息解决了投影误差问题,实现更高效的 3D 目标检测。
2.3 隐式神经表示(INR)
隐式神经表示通过多层感知机(MLP)将坐标映射到视觉信号,是建模 3D 物体、场景和 2D 图像的高效方式。NeRF 利用全连接网络表示场景,通过 5D 坐标输入生成体密度和辐射度;MetaSR 和 LIFF 将高分辨率坐标编码到低分辨率特征中,实现任意尺寸的高分辨率图像生成。
PETR 借鉴 INR 的思想,将 2D 图像特征与 3D 坐标结合,生成 3D 位置感知特征,可视为 INR 在 3D 目标检测领域的延伸。
3. PETR 核心方法详解
3.1 整体架构
PETR 的整体架构如图 2 所示,主要包含四个核心模块:骨干网络(Backbone)、3D 坐标生成器(3D Coordinates Generator)、3D 位置编码器(3D Position Encoder)、查询生成器与解码器(Query Generator & Decoder)。
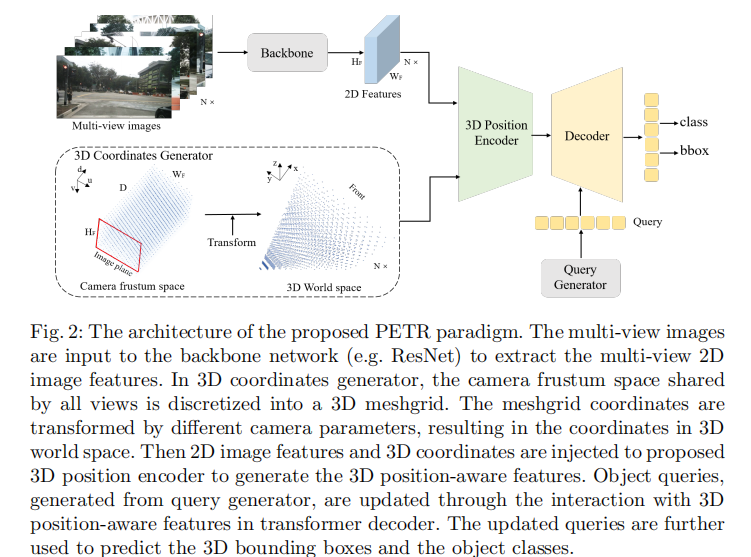
其核心流程为:
- 多视图图像经骨干网络提取 2D 特征;
- 3D 坐标生成器将相机视锥空间离散化为 3D 网格,并通过相机参数转换为 3D 世界空间坐标;
- 3D 位置编码器将 2D 特征与 3D 坐标融合,生成 3D 位置感知特征;
- 查询生成器生成初始目标查询,解码器中查询与 3D 位置感知特征交互更新,最终预测目标类别和 3D 边界框。
3.2 3D 坐标生成器
为建立 2D 图像与 3D 空间的关联,PETR 利用相机视锥空间与 3D 空间的一一对应关系,通过以下步骤生成 3D 坐标:
-
视锥空间离散化 :参考 DGSN 的方法,将所有视图共享的相机视锥空间离散化为尺寸为
的 3D 网格。网格中每个点表示为
-
3D 世界空间转换:通过相机参数将视锥空间网格坐标逆投影到 3D 世界空间,公式如下:
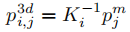
其中
-
坐标归一化:为统一尺度,对 3D 世界空间坐标进行归一化处理,将坐标值映射到 0,1 区间:
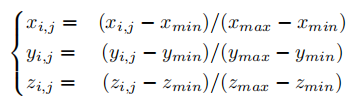
其中是3D世界空间的感兴趣区域(RoI)。最终归一化后的坐标被重塑为
,作为后续编码的输入。
3.3 3D位置编码器
3D位置编码器的核心是将2D图像特征与3D位置信息融合,生成3D位置感知特征。其数学表达为:
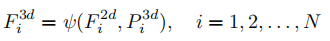
其中为位置编码函数,具体实现流程如图3所示:
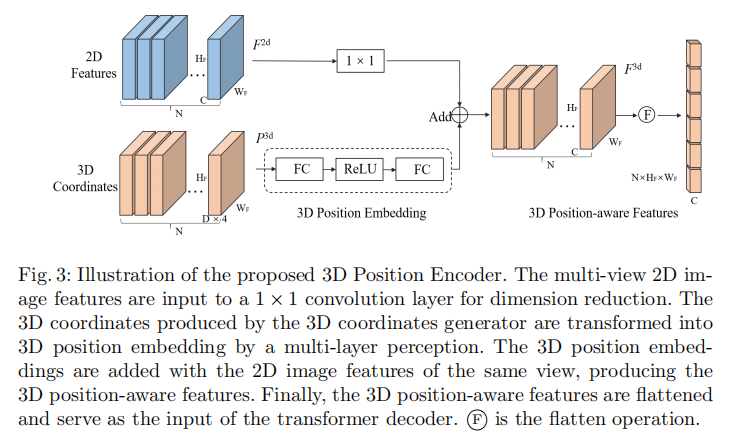
-
2D特征降维 :将骨干网络提取的2D多视图特征
-
3D位置嵌入生成 :将3D坐标
-
特征融合:将降维后的2D特征与对应的3D位置嵌入相加,生成3D位置感知特征。
-
特征展平:将3D位置感知特征展平后,作为Transformer解码器的输入(键和值)。
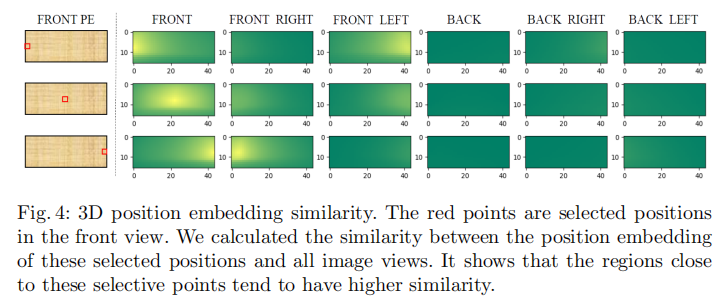
3D位置嵌入的有效性验证:为验证3D PE的作用,实验中随机选择前视图的三个点,计算其与所有多视图PE的相似度。如图4所示,靠近所选点的区域具有更高的相似度,例如选择前视图左侧点时,前左视图的右侧区域响应更强。这表明3D PE能隐式建立不同视图在3D空间中的位置关联,为跨视图特征融合提供基础。
3.4 查询生成器与解码器
3.4.1 查询生成器
DETR直接使用可学习参数作为初始目标查询,DETR3D基于初始查询预测参考点。为缓解3D场景下的收敛难题,PETR借鉴Anchor-DETR的思想,采用以下方式生成初始查询:
- 在3D世界空间中初始化一组均匀分布(0~1)的可学习锚点(Anchor Points);
- 将3D锚点坐标输入包含两个线性层的小型MLP,生成初始目标查询
实验表明,3D空间锚点能保证模型收敛,而BEV空间锚点或无锚点设置均无法达到满意性能。
3.4.2 解码器
解码器采用DETR的标准Transformer解码器结构,包含L层解码层。每层解码过程可表示为:
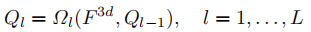
其中为第l层解码器,
为更新后的目标查询(M为查询数量,C为特征通道数)。
在每层解码中,目标查询通过多头注意力机制与3D位置感知特征交互,并经前馈网络优化,逐步学习到高维语义特征,为后续检测任务提供支持。
3.5 检测头与损失函数
检测头包含分类和回归两个分支,接收解码器输出的更新后查询,分别预测目标类别概率和3D边界框参数。其中回归分支预测相对于锚点坐标的偏移量。
为与DETR3D公平对比,PETR采用以下损失函数设置:
- 分类损失:Focal Loss,解决类别不平衡问题;
- 回归损失:L1 Loss,用于3D边界框参数回归;
- 标签分配:匈牙利算法(Hungarian Algorithm),实现预测与真实标签的最优匹配。
总损失函数定义为:
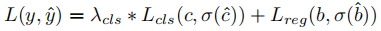
其中 和
分别表示真实标签和预测结果,
为最优分配函数,
为平衡分类损失和回归损失的超参数。
4. 实验结果与分析
4.1 实验设置
4.1.1 数据集
实验基于nuScenes数据集,该数据集包含1000个场景,由6台相机、1个激光雷达和5个雷达采集数据,分为700/150/150的训练/验证/测试集划分。每个场景包含20秒视频帧,每0.5秒标注一次3D边界框。
4.1.2 评估指标
采用nuScenes官方评估指标,包括:
- 核心指标:nuScenes检测分数(NDS)、平均精度(mAP);
- 辅助指标:平均平移误差(mATE)、平均尺度误差(mASE)、平均方向误差(mAOE)、平均速度误差(mAVE)、平均属性误差(mAAE)。
4.1.3 实现细节
- 骨干网络:支持ResNet、Swin-Transformer、VoVNetV2,采用C4与C5特征融合生成P4特征(1/16输入分辨率);
- 3D坐标生成:沿深度轴采用线性递增离散化(LID)采样64个点,RoI设置为X/Y轴-61.2m, 61.2m,Z轴-10m, 10m;
- 训练配置:AdamW优化器(权重衰减0.01),初始学习率\(2.0×10^{-4}\),余弦退火调度;多尺度训练(短边640~900,长边≤1600);3D随机旋转增强(-22.5°~22.5°);训练24个epoch,8卡Tesla V100,批次大小8;
- 推理配置:无测试时增强(TTA)。
4.2 基线对比实验
4.2.1 nuScenes验证集结果
表1展示了PETR与当前SOTA方法在nuScenes验证集的对比结果。可以看出:
- 与单目3D检测方法(CenterNet、FCOS3D、PGD)相比,PETR(ResNet-101)的NDS分别提升11.4%、2.7%、1.4%,mAP分别提升6.4%、1.4%、0.1%;
- 与多视图3D检测方法(BEVDet、DETR3D)相比,PETR的NDS分别提升1.4%、0.8%,展现出更优的全局特征学习能力;
- 当采用Swin-T骨干网络和1408×512输入尺寸时,PETR的NDS达到0.431,mAP达到0.361,优于多数对比方法。
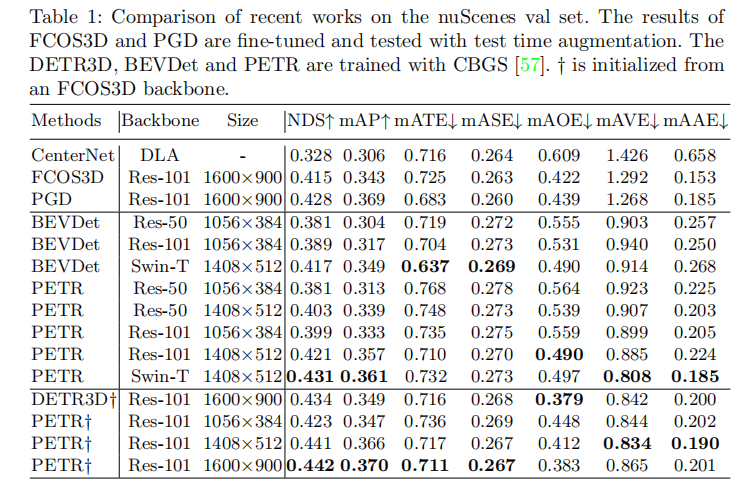
注:†表示基于FCOS3D骨干网络初始化;-表示未报告数据。
4.2.2 nuScenes测试集结果
表2展示了nuScenes测试集的对比结果,PETR依然保持SOTA性能:
- 采用Swin-S骨干网络时,PETR的NDS为0.481,mAP为0.434,分别比BEVDet高1.8%和3.6%;
- 采用Swin-B骨干网络时,PETR的mAP达到0.445,接近使用外部数据的方法;
- 结合外部数据和VoVNetV2骨干网络时,PETR实现50.4% NDS和44.1% mAP,成为首个NDS突破50%的视觉基3D目标检测方法。
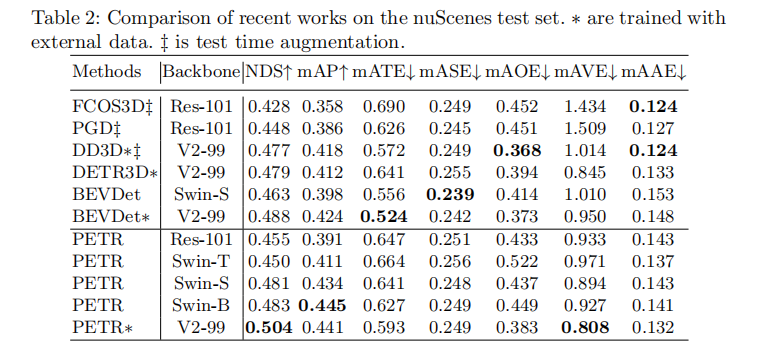
注:∗表示使用外部数据;‡表示使用测试时增强。
4.3 收敛性与速度分析
4.3.1 收敛性对比
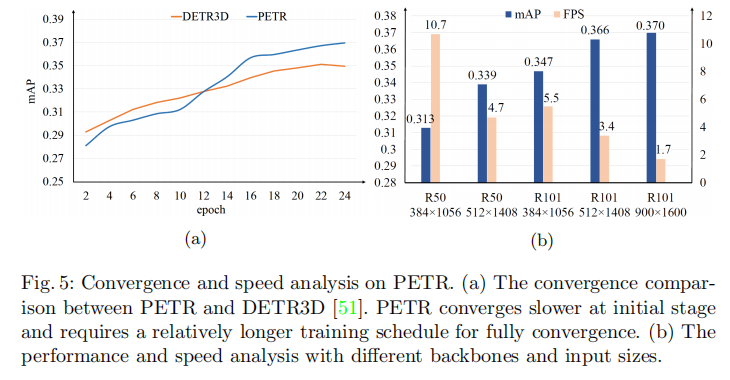
图5(a)展示了PETR与DETR3D的收敛曲线对比。可以看出:
- 前12个epoch内,PETR的收敛速度慢于DETR3D;
- 随着训练轮次增加,PETR逐渐追上并超越DETR3D,最终实现更优性能。
这一现象的原因是PETR通过全局注意力学习3D关联,而DETR3D仅在局部区域感知3D场景,全局特征学习需要更长的训练周期。
4.3.2 推理速度分析
图5(b)展示了不同输入尺寸和骨干网络下PETR的推理速度(FPS)和性能权衡。关键结论如下:
- 相同输入尺寸(1056×384)下,PETR在Tesla V100上的推理速度为10.7 FPS,远超BEVDet在更强的NVIDIA 3090上的4.2 FPS;
- 随着输入尺寸增大(如1408×512、1600×900),性能逐步提升,但推理速度略有下降;
- 骨干网络复杂度对速度影响显著,ResNet-50比ResNet-101、Swin-T更高效,适合实时场景。
4.4 消融实验
为验证各核心组件的有效性,PETR进行了全面的消融实验,所有实验基于ResNet-50骨干网络的C5特征,未使用CBGS策略。
4.4.1 3D位置嵌入的影响
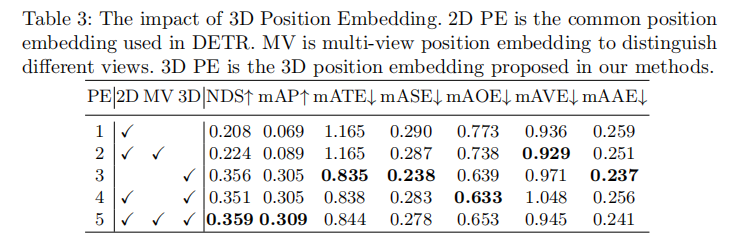
表3分析了不同位置嵌入(PE)的作用:
- 仅使用2D PE时,模型性能极差(mAP仅6.9%),无法有效学习3D特征;
- 添加多视图PE(区分不同视图)后,性能略有提升(mAP 8.9%);
- 仅使用3D PE时,mAP直接提升至30.5%,表明3D PE能提供强大的3D位置先验;
- 3D PE与2D PE、多视图PE结合后,性能进一步优化(NDS 0.359,mAP 0.309),但核心增益来自3D PE。
4.4.2 3D坐标生成器的影响
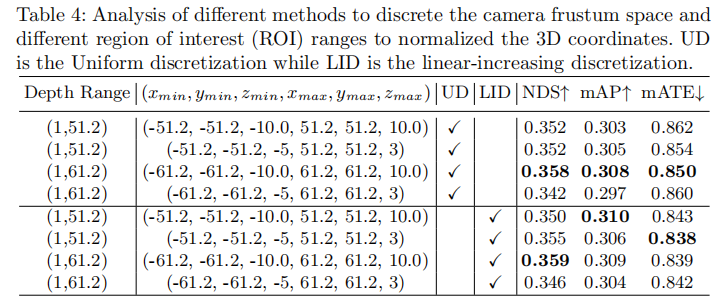
表4分析了不同离散化方法和RoI范围的影响:
- 均匀离散化(UD)与线性递增离散化(LID)性能相近,说明离散化方式对结果影响较小;
- RoI范围为(-61.2m, -61.2m, -10.0m, 61.2m, 61.2m, 10.0m)时性能最优(NDS 0.359,mAP 0.309),过窄或过宽的RoI会导致性能下降。
4.4.3 3D位置编码器的影响
表5(a)和(b)分别分析了3D PE生成网络和特征融合方式的影响:
- 3D PE生成网络:使用"1×1-ReLU-1×1"的简单MLP时性能最优(NDS 0.359,mAP 0.309);直接使用归一化坐标作为3D PE时性能较差(NDS 0.311,mAP 0.256);3×3卷积会破坏2D特征与3D位置的对应关系,导致模型无法收敛;
- 特征融合方式:加法融合与拼接融合性能相近(NDS均为0.359/0.358),优于乘法融合,且加法融合计算更高效。
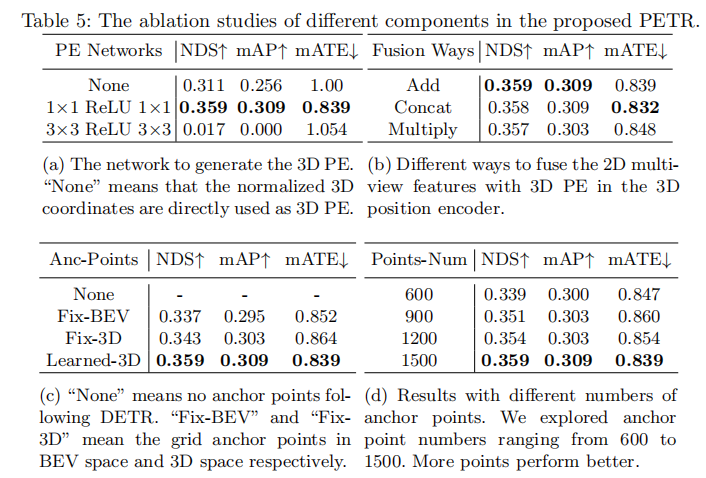
4.4.4 查询生成器的影响
表5(c)和(d)分析了锚点设置和锚点数量的影响:
- 锚点设置:3D可学习锚点(Learned-3D)性能最优(NDS 0.359,mAP 0.309);BEV空间锚点(Fix-BEV)和3D固定锚点(Fix-3D)性能较差;无锚点设置(DETR方式)无法收敛;
- 锚点数量:锚点数量从600增加到1500时,性能逐步提升,1500个锚点达到最优性能,考虑计算成本,最终选择1500个锚点。
4.5 可视化分析
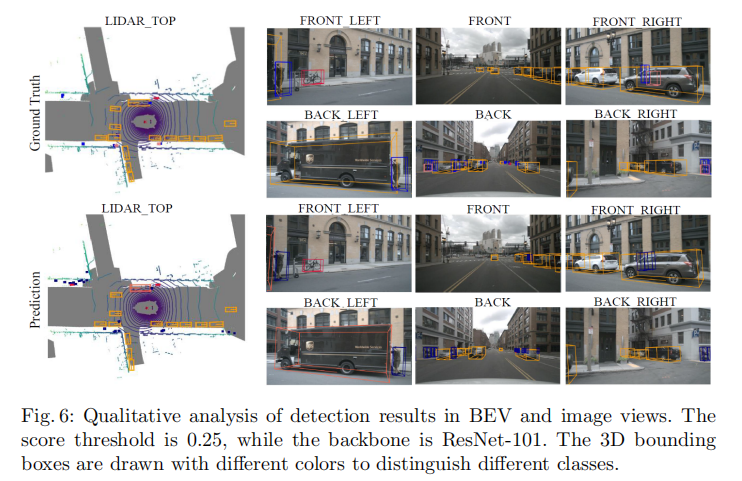
4.5.1 检测结果可视化
图6展示了PETR在BEV视图和图像视图的检测结果。可以看出:
- BEV视图中,预测的3D边界框与真实标签高度吻合,准确捕捉了目标的位置、尺度和方向;
- 图像视图中,3D边界框投影到多视图图像上,与目标区域对齐良好,验证了跨视图特征融合的有效性。
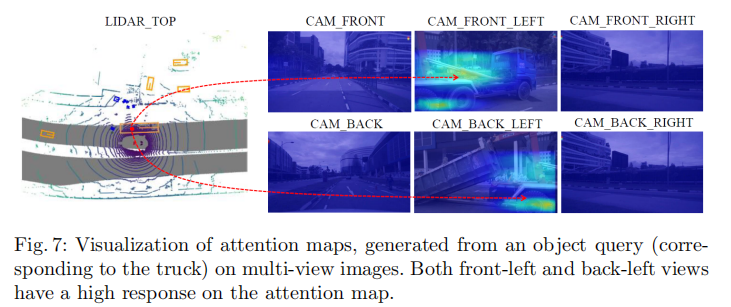
4.5.2 注意力图可视化
图7展示了单个目标查询在多视图图像上的注意力分布。可以看出,目标查询能同时关注不同视图中的同一目标(如卡车),前左视图和后左视图的目标区域注意力响应较高。这表明3D位置嵌入成功建立了不同视图间的位置关联,使目标查询能全局感知3D空间中的目标。
4.5.3 失败案例分析
图8展示了PETR的典型失败案例:
- 红色圆圈:小型目标(如行人、自行车)未被检测,主要原因是小型目标的特征表达较弱,且3D位置信息编码不够充分;
- 绿色圆圈:目标分类错误,多发生在外观相似的车辆之间(如轿车与SUV),表明类别特征的区分能力有待提升。

5. 结论与展望
5.1 核心贡献
- 提出了PETR框架,通过编码3D坐标将多视图2D特征转换为3D位置感知特征,实现端到端3D目标检测,避免了复杂的2D-to-3D投影和特征采样;
- 引入了新的3D位置感知表示,通过简单的隐式函数将3D位置信息注入2D特征,建立跨视图位置关联;
- 在nuScenes数据集上取得SOTA性能(50.4% NDS、44.1% mAP),成为首个NDS突破50%的视觉基3D目标检测方法,为后续研究提供强基线。
5.2 未来方向
- 优化小型目标检测性能,可通过增强小型目标的特征表达或设计针对性的位置编码策略;
- 提升模型收敛速度,探索更高效的注意力机制或初始化方法;
- 扩展到更复杂的场景(如恶劣天气、遮挡场景),增强模型的鲁棒性;
- 结合多模态数据(如激光雷达、雷达),进一步提升检测精度。
PETR的创新之处在于将3D位置信息与2D特征的深度融合,简化了多视图3D目标检测的流程,同时保证了检测性能。其简洁的架构和优异的结果,为3D目标检测领域的研究提供了新的思路,有望推动自动驾驶等相关应用的发展。