LLM-Aided Compilation for Tensor Accelerators 【伯克利24年报告】
一、研究什么
这篇论文关注的是一个比"自动优化"更早一步的问题:
能不能先让 LLM 帮我们把普通代码翻译成张量加速器能执行的低层代码,然后再在此基础上做性能优化?
如果把它和上一篇 Autocomp 放在一个发展脉络里看,这篇更像:
一个探索性、原型性的早期工作
一个在问"LLM 进入加速器编译这件事到底行不行"的 feasibility study
一个把很多后来更成熟的思路先搭出轮廓的工作
二、为什么这个问题重要
这篇论文的背景非常现实:
张量加速器越来越多
它们不只可以跑深度学习,还可能服务机器人控制、图算法、科学计算等
但没有合适的软件栈,很多硬件能力根本用不上
作者强调一个"鸡生蛋、蛋生鸡"困境:
没有编译器,应用难迁移到新加速器
没有应用,厂商又不愿意为新加速器投入大量编译器工程
因此,若能用 LLM 减少编译器开发和迁移成本,就可能加快加速器探索速度。
这里的思路其实不是"让 LLM 取代编译原理",而是想让 LLM 充当一种低成本的、可快速适配的代码翻译和优化助手。
背景知识
1. 什么是 Gemmini
Gemmini 是加州伯克利那边很常见的一个开源 systolic array accelerator generator。它不是一颗固定芯片,而更像一个可参数化生成的加速器平台。
这篇论文拿它来做实验很合理,因为:
-
学术界使用广
-
ISA 和软件接口可见
-
易于做实验和对比
2. 什么是"把代码翻译到 Gemmini"
不是简单把矩阵乘法函数改个名字,而是把普通 C++ 中的矩阵运算拆成:
-
配置加速器
-
把矩阵 tile 搬进 scratchpad
-
调 compute/preload/mvout 等低层接口
-
小心处理 stride、地址、转置、bias、维度约束
这件事麻烦的地方是:
-
语义不能错
-
参数不能越界
-
地址不能算错
-
还要尽量快
3. 什么是 in-context learning
作者大量使用 one-shot / two-shot example。这里的意思不是重新训练模型,而是在 prompt 里先给一个"像样的例子",让模型学这个任务的风格和结构。
对低资源 DSL,这往往比空讲规则更有效。
如果没有这篇文章 正常的思路:
没有这篇文章时,正常路线就是"传统编译器/库驱动"的做法 ,不是让模型直接翻译代码,而是靠人工定义中间表示、pattern matching、调度优化、代码生成,一步步把高层程序映射到 Gemmini 这类加速器上。
具体内容:
- 最传统的做法:手写库 / API
- 不做"自动翻译"。
- 直接让程序员调用 Gemmini 提供的 intrinsic、宏、driver API。
- 例如:手动写
mvin / compute / mvout这类序列,自己管 tile 大小、buffer 地址、数据搬运。- 更正规的做法:走编译器 lowering
- 先把高层代码变成某种 IR(中间表示)。
- 再识别其中的矩阵乘、卷积、归约等 pattern。
- 把这些 pattern lower 成 Gemmini 对应的指令序列或 DSL。
- 核心优化靠编译器 passes,不靠模型生成
- 包括:
- loop tiling
- loop interchange
- buffer allocation
- data layout transformation
- DMA / scratchpad orchestration
- instruction scheduling
- 本质上是:把算法拆成"算什么"和"怎么在这个硬件上跑"两层。
一、INTRO
引言先从 AI/ML 加速器切入,再把范围扩展到更一般的 tensor-related applications,包括 robotics、graph algorithms、financial modeling 等。
作者想强调的是:
这些加速器的潜力不该被局限在深度学习框架里。
但要做到这点,就得把应用代码编译到加速器专用 DSL 或 ISA,而这件事目前高度依赖人工。
引言中的"ideal compiler framework"这个概念值得注意。作者想要的是一种对上下层变化都敏感的框架:
-
上层应用变了,也能快速适配
-
下层硬件变了,也不用重写大量工具链
LLM 被引入的理由就在这里:它可能提供一种比手工规则更灵活的中间层。
这篇论文把自己放在哪个位置
作者把已有工作分成两大类:
- 代码翻译相关工作
包括 pattern matching、search-based lifting、神经方法
- 张量加速器设计空间探索相关工作
包括各种 cost model、schedule search、硬件/软件 co-design
这篇论文的定位是把两者接起来:
不是单纯做 code generation,也不是单纯做 tensor schedule,而是探索 LLM 作为编译流程一部分的可能性。
二、方法
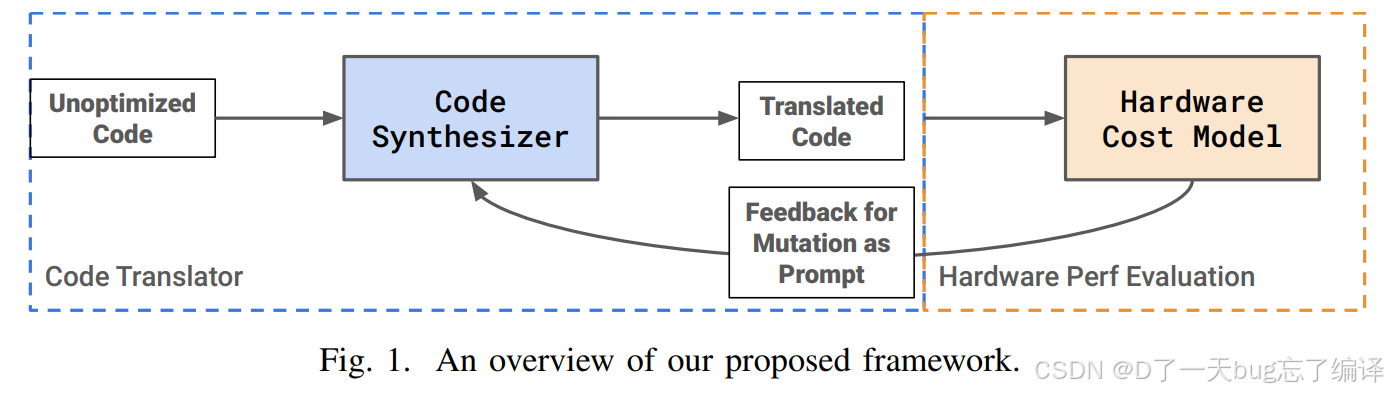
图 1 画的是:
-
输入是未优化代码
-
中间有 code translator / synthesizer
-
再由硬件 cost model 或性能评估给出反馈
-
反馈回到 synthesizer,继续改
这张图最大的意义在于,它明确告诉你作者并不信任 LLM 的一次性输出。
作者真正想做的是:
生成 -> 验证 -> 再生成
这在系统研究里是更可信的路子。
Code Template Generation with LLMs
这是这篇论文最扎实的部分。
作者先说传统方法,比如 pattern-matching compiler 或 verified lifting,有几个问题:
- 规则要人工写,维护成本高;
- 常依赖枚举搜索或约束求解;
- 一旦搜索空间大,必须加很多启发式;
- 需要大量领域知识去缩小空间。
尤其对 accelerator DSL,这个问题更严重,因为每个硬件后端都不太一样。
作者接着提出:LLM 是一种有潜力的替代方案。理由有两个:
- 它见过大量代码和文档,可能学到了通用的程序语法和语义;
- 它擅长上下文推理,可以把复杂问题拆成多个半结构化步骤来处理。
但作者也明确承认一个挑战:
TA(tensor accelerator)和 DSA 的低层语言,在 LLM 训练语料里几乎没什么存在感。
也就是说,模型不太可能"靠背答案"直接会写 Gemmini ISA。
所以他们的办法不是盲信预训练知识,而是:
通过 prompt 把目标语言规范补给模型。
作者提出结构化 prompt,由三部分组成:
- instructions
任务说明,告诉模型要把源程序翻译成目标语言。
- target language specification
告诉模型 Gemmini 有哪些操作、每个操作怎么用、约束是什么。
- source program
给出待翻译的高层代码。
这三项看起来简单,但其实已经包含了一个很重要的方法论:
对冷门 DSL,目标语言说明不能省。
你不能指望模型自己"猜出"加速器指令含义。
为什么作者特别强调 example
因为单有 ISA 描述还不够。
论文实验表明,zero-shot 几乎不可用;但一旦给一个 one-shot example,正确率会暴涨。
模型在这里不是"真的理解了整个 Gemmini 编程体系",而是:
-
通过例子学到了输出风格
-
通过例子学到了 low-level code 的结构模板
-
降低了语法和组织错误
也就是说,example 在这里既是知识提示,也是格式约束。
Cost Model-Driven Code Translation
作者进一步提出,不应该停留在"翻对",而应继续做"翻快"。
作者提到已有一些工作,比如 Ansor,已经证明了基于 cost model 的优化 是有效的。
但这些方法通常有两个问题:
- 搜索空间是人工设计的;
- 每个新硬件目标都要重新做大量调参/训练。
作者想做的则不同:
- 不把搜索空间完全手工写死;
- 借助 LLM 对程序优化的"潜在知识";
- 让优化空间更灵活、更非结构化一些。
这其实是在说:
传统 auto-scheduler 擅长在明确定义的空间 里找最优点;
而 LLM 的价值可能在于,它能帮助提出一些不那么规则化的变换候选。
这一部分的方法还比较概念化,但大致思路是:
-
给模型一个优化集合
-
让模型优化每个计算块
-
再让模型决定块的顺序
-
结合 cost model 或硬件反馈做迭代修正
这里已经能看到后来 Autocomp 的雏形:
先给模型一组可能的优化动作
作者会先提示模型一些候选优化方向,比如:
- 合并指令;
- 改变数据移动模式。
也就是说,不是让 LLM 毫无约束地"自由发挥优化",而是先给它一个操作空间。
再让模型逐个 block 优化
模型会针对每个计算 block 做局部优化。
这是"hierarchical"的含义之一:先局部,再全局。
作者试了两种做法
作者明确说做了两种实验:
- LLM 直接生成优化后的代码
- LLM 生成 Halide-style scheduling operations
这两种思路的差别很重要:
- 第一种更直接,但风险是语义容易错;
- 第二种更像"生成调度策略",再由系统应用这些 scheduling 操作,理论上更可控。
这其实已经隐含了一个很重要的编译思想:
把"算什么"和"怎么调度"分开。
最后再决定 block 的整体顺序
在局部优化之后,再让模型去安排这些 block 在最终程序中的次序。
这个顺序为什么重要?因为它会影响:
- 数据局部性;
- 并行性;
- 同步/依赖关系;
- memory traffic。
所以作者希望模型不只是改每一小段,而是理解全局执行效果。
但在这篇论文里,这部分还没有被做成一个很完整的、系统化的大规模框架。
三、实验
把 Robotics Kernels 翻译到 Gemmini ISA
作者选的不是随便一个教材矩阵乘法,而是机器人控制里的 kernels,包括:
-
matrix-vector operations
-
matrix-matrix operations
这类任务有代表性,因为:
-
矩阵运算多
-
尺寸不总是规则的大方阵
-
真正有 edge acceleration 需求
Matrix-Vector 实验在测什么
作者从 TinyMPC 的 backward pass 中抽出几类矩阵-向量乘法,测试不同 prompting 方式对 pass rate 的影响。
表 1 的结果:
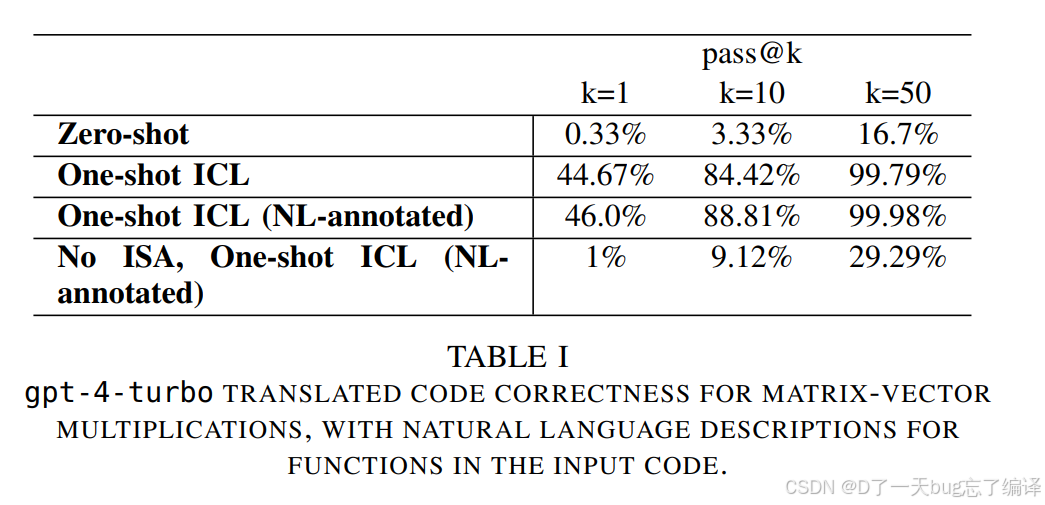
-
Zero-shot 几乎不可用,pass@1 只有 0.33%
-
One-shot ICL 直接大幅跃升,pass@1 到 44.67%
-
One-shot + NL annotation 再小幅提升到 46.0%
-
去掉 ISA 后,正确率暴跌
这几个结果说明了三件事:
第一,Gemmini 这种低资源 DSL 无法靠模型常识直接搞定。
第二,样例极其重要,甚至比空讲规则更重要。
第三,ISA 说明不是可有可无的附件,而是任务成功的基础条件。
为什么"语义实现"比"自然语言描述"更有效
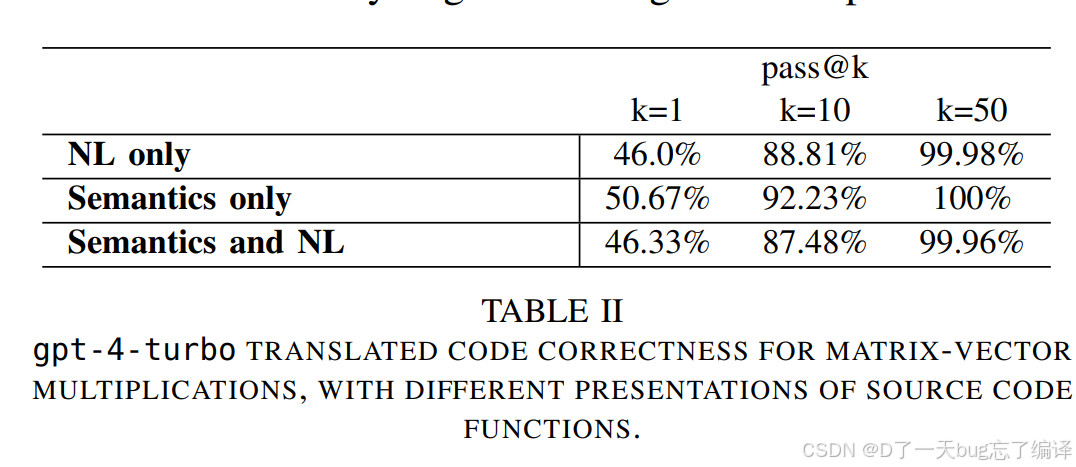
作者比较了三种给源程序函数语义的方法:
-
NL only
-
Semantics only
-
Semantics and NL
结果最好的是 semantics only。
这很有意思,因为很多人会直觉觉得"代码 + 自然语言一起给,信息更多,应该更好"。但论文结果说明:
prompt 不是信息越多越好,而是冗余越多越容易扰乱模型。
换句话说,对这种任务来说,直接给结构化、精确的函数实现或语义,往往比额外给一段解释性文字更有效。
Matrix-Matrix 翻译实验
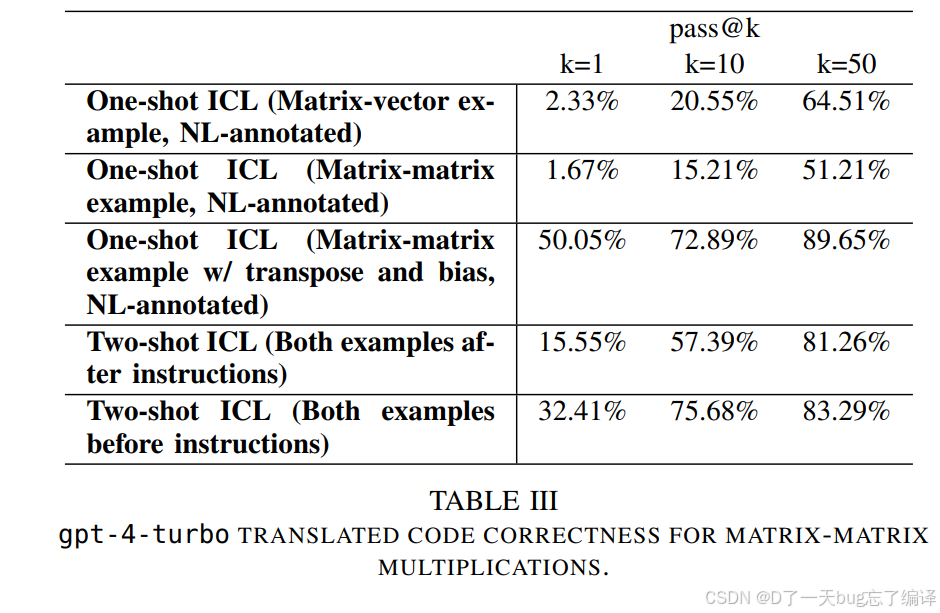
相比 matrix-vector,matrix-matrix 更复杂,因为:
-
尺寸更大
-
变体更多
-
可能涉及转置、bias 加减等情况
Table III 中能看到:
-
如果只给不匹配的 matrix-vector 例子,效果很差
-
如果给更接近目标任务的 matrix-matrix 例子,正确率明显提高
-
例子放在 instructions 前面,比放在后面更好
这一组实验说明:
-
in-context example 必须"像"
-
prompt 顺序会影响结果
这不是小技巧,而是对 LLM 编译任务很核心的结论:任务结构比文字多少更重要。
Repairing Translated Code
这一节虽然篇幅不大,但我认为价值很高。
作者发现有个 kernel 总是"差一点就对",主要错在:
-
addressing
-
stride
-
constants
这非常符合 LLM 的典型弱点:大结构能搭对,但细碎算术和索引容易翻车。
于是作者不是让模型"重写",而是做多步修复:
-
从接近正确的 candidate 出发
-
让模型先定位不确定位置
-
再让模型对这些 hole 进行替换和常数修正
这个思路很成熟,因为真实工程里经常不是从 0 到 1,而是从 0.8 修到 1。
Code Optimization
这里作者开始做初步优化实验,主要有两种方向:
- Structured LLM-Driven Code Rewrites
让模型先优化各个 block,再决定 block 顺序。
- LLM-driven Autoscheduling
让模型不是直接写最终代码,而是选 schedule operations。
第二条尤其值得注意,因为它已经显露出后续研究的更优方向:
与其让 LLM 直接改低层代码,不如让它在一个语义安全的 schedule DSL 里操作。
作者拿 Exo 做实验,就是出于这个考虑。因为 Exo 的 rewrite 成功后默认是语义保持的,这能显著降低 hallucination 带来的 correctness 风险。
个人看法
- 它的价值在哪里
第一,它证明了一个此前并不显然的事情:
LLM 在低资源加速器代码翻译任务上,不是完全没法用;只要给足结构化信息和例子,它能达到相当不错的正确率。
第二,它说明了 prompt 设计中的几个硬结论:
-
ISA 说明不能省
-
one-shot 非常重要
-
示例必须和目标任务相似
-
prompt 顺序会影响效果
-
冗余信息会拖后腿
这些结论对后续很多工作都是直接可复用的。
第三,它很诚实地暴露了 LLM 的弱点:
-
zero-shot 很差
-
算术细节容易错
-
block 级优化和 autoscheduling 还不稳定
这比那种只报最好结果、不讲失败模式的论文可信得多。
- 它的问题在哪里
第一,这篇论文更像"概念验证",而不是成熟系统。
翻译实验较完整,但优化部分明显还是原型状态,缺乏更系统、更大规模的性能验证。
第二,很多结果是 pass@k,而不是单样本稳定性。
这意味着它更像"采样足够多次,总有一些能对",而不是"给一次就稳对"。对于真实编译器场景,这两者差别很大。
第三,它对端到端工程成本的讨论不够。
比如:
-
prompt 设计成本多少
-
candidate 采样成本多少
-
如果任务更复杂,pass@k 会不会快速恶化
这些问题在文中没有被充分展开。
这篇论文不该被读成"LLM 已经能胜任张量加速器编译器",而应该被读成:
LLM 可以进入这个流程,但前提是你必须把任务拆小、把目标语言说清、把样例给对、把验证闭环接上。
它真正有价值的是提出问题、验证可行性、暴露边界,而不是给出一个已经工业级成熟的解决方案。