CLAUDE.md 完整指南------让 Claude 真正理解你的项目
AI Coding 系列第 04 篇 · CLAUDE.md 到底是什么:不是文档,而是 Claude 的规则层
CLAUDE.md 被严重误解
很多人对 CLAUDE.md 的理解有偏差。有人把它当项目文档来写,两百行的架构介绍、API 清单、数据库设计,然后疑惑为什么 Claude 经常无视其中的规则。有人复制了一个通用模板,放在那里从来不改。还有人干脆不知道它到底是干什么的。
这类误解有一个共同点:
把 CLAUDE.md 当成了"给 AI 看的项目说明书"。
但 CLAUDE.md 的本质不是文档,而是规则层。
它不是用来完整介绍项目的,而是用来告诉 Claude:
- 这个项目里哪些边界不能碰
- 哪些行为默认是错的
- 哪些约定会反复影响决策
- 哪些高风险区域必须更保守
如果把它写成"项目背景",Claude 最多只是"看过了";
如果把它写成"行为规则",Claude 的默认工作方式才会真正改变。
所以更准确的定义是:
CLAUDE.md 不是项目文档,而是把稳定偏好、高风险边界和重复纠正,提前变成 Claude 默认上下文的规则层。
一、CLAUDE.md 到底解决什么问题
一个好用的 CLAUDE.md,主要解决四类问题。
1. 把反复提醒的内容沉淀下来
如果你总是在 prompt 里反复说这些话:
- 这个项目不要改
.github/workflows - 错误统一用
AppError - 不要默认新增依赖
- 数据库变更前先讲回滚方案
那这些内容就不该每次重新说,而应该进入 CLAUDE.md。
2. 给 Claude 的默认积极性加边界
Claude 默认会尽量帮你完成任务,但很多项目里真正危险的,不是它不做事,而是它做得太多。
比如:
- 看见旧代码就想顺手重构
- 看见没测试就想补一整套基础设施
- 看见当前实现笨重就建议换栈
这些行为在通用场景里未必错,但在具体项目里可能是噪音,甚至是风险。
CLAUDE.md 的一个重要作用,就是给这种默认积极性划边界。
3. 把"代码里看不出来"的规则显式化
很多项目真正重要的约束,并不直接写在代码里。
例如:
- 某个目录是历史包袱区,轻易别碰
- 某些 migration 一旦上线后绝不能回写修改
- 某个模块表面简单,背后连着外部系统
- 某类接口一改就会影响前端联调和埋点
这些东西人类同事待久了会知道,但 AI 初来乍到不会知道。
CLAUDE.md 的价值,就在于把这些隐性知识提前说透。
4. 降低上下文成本
技术栈、关键路径、错误处理方式、依赖策略、部署边界,这些稳定规则本来就适合长期存在。把它们放进 CLAUDE.md,每次 prompt 就能专注当前任务,而不是重复灌输基础背景。
二、它不只是纠错层,也是预防层
前面说 CLAUDE.md 是纠偏器,这个说法是对的,而且很重要。因为它能一下子把很多人从"项目文档思维"拉回来。
但如果只停在"纠偏器"这一层,对它的理解还是不完整。
更准确地说,CLAUDE.md 既是纠错层 ,也是预防层。
1. 纠错层:把重复犯的错写成规则
比如:
- 你已经说过两次不要直接
throw new Error() - 你已经纠正过几次不要改
.github/workflows - 你已经反复提醒过不要随便
npm install
这些都属于典型的"纠错"。
2. 预防层:提前声明高代价边界
真正好用的 CLAUDE.md,并不只是在事后补锅。它还有一个同样重要的作用:提前声明那些一旦做错,代价就很高的边界。
比如:
- 支付模块改动前先确认幂等逻辑
- migration 文件上线后只能新增,不能回写修改
- 生成目录不要手改,因为下次生成会覆盖
- 新增重大依赖前先说明必要性和替代方案
这些规则不一定是 Claude 已经犯过的错,也可能是你提前告诉它:
"这里不是不能动,而是这里的错误成本很高,你默认要更保守。"
所以从完整定位上说,CLAUDE.md 的作用不是单纯"记录反复犯的错",而是:
把稳定偏好、风险边界和高代价约束,提前变成 Claude 的默认工作上下文。

图:CLAUDE.md 不是项目文档,而是纠偏层 + 预防层 + 长期约束层。
三、文档式写法 vs 纠偏式写法
说一百遍不如直接对比。
markdown
❌ 文档式写法(Claude 读了,但行为不变)
本项目是一个电商平台,使用 Node.js + Express + TypeScript 开发,
数据库采用 PostgreSQL,通过 Prisma 进行 ORM 管理。
项目包含用户模块、订单模块、支付模块和通知模块,
遵循 RESTful API 设计规范......
markdown
✅ 纠偏式写法(Claude 读了,行为立刻改变)
- 禁止 throw new Error(),统一用 AppError 类
- API 响应必须含 success / data / timestamp 三个字段,不能自己发明格式
- 禁止在 controller 层直接写 SQL,必须通过 service 层
- 所有异步函数必须有 try-catch,不靠外层中间件兜底
- 新增依赖前必须问我,不要自行 npm install文档式写法让 Claude "知道"了,但知道不等于行动。
纠偏式写法告诉 Claude:"在这个项目里,你的默认行为哪里不对。" 这才是它真正听进去的语言。
判断一条规则是不是纠偏式,只用问一个问题:
这条规则是在纠正 Claude 的某个具体行为,还是在描述项目背景?
能对应到一个具体行为变化的,是纠偏。
其他的,是文档。
四、它和 Prompt、文档、Memory、Skill 的边界
很多人用不好 CLAUDE.md,不是不会写规则,而是把它和别的东西混在一起了。
最容易混淆的有四个对象:Prompt、项目文档、Memory、Skill。
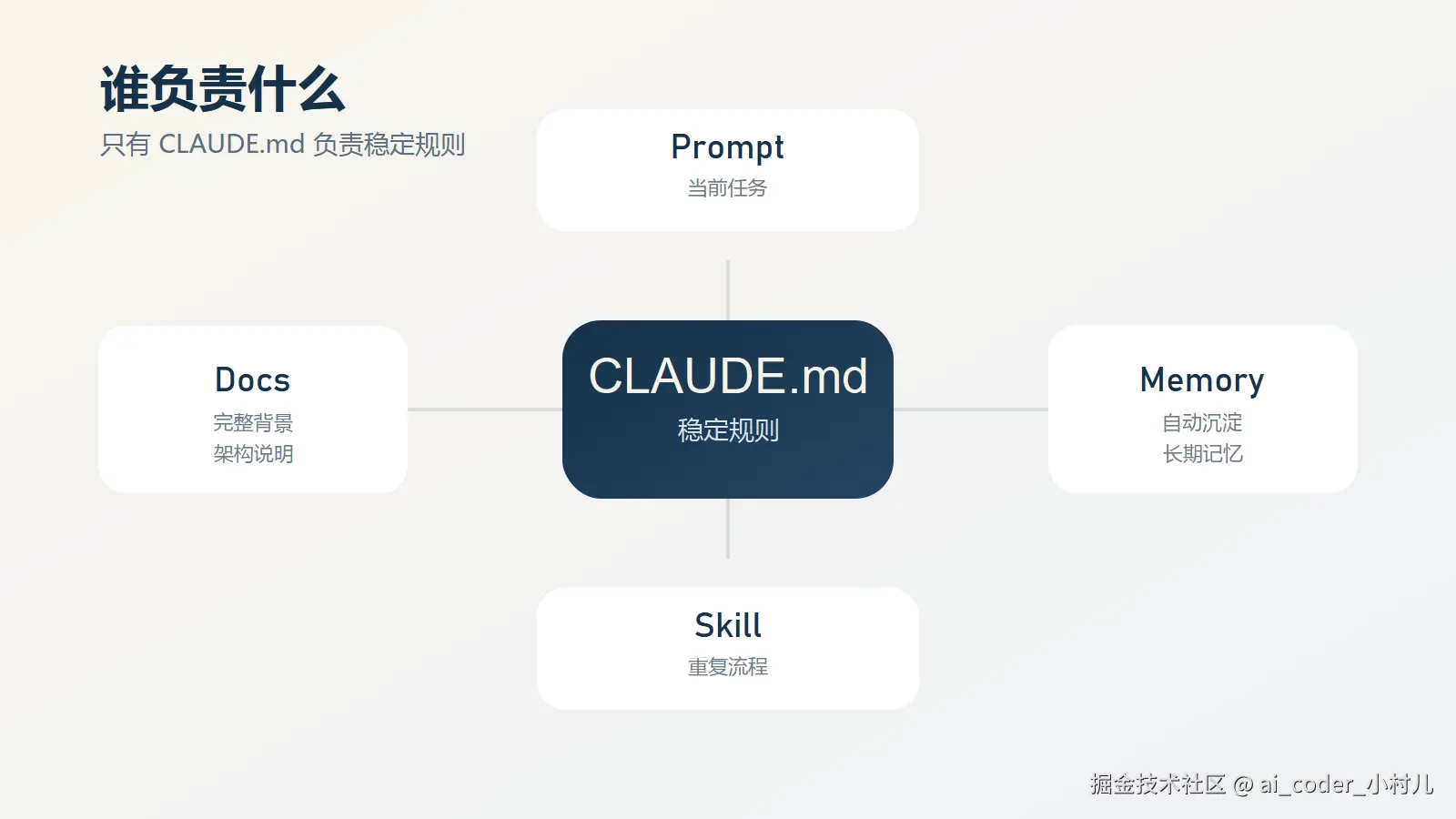
图:Prompt 管当前任务,文档管背景,Memory 管自动沉淀,Skill 管重复流程,CLAUDE.md 管稳定规则。
源码里的分工也很明确
如果去看 Claude Code 的源码,CLAUDE.md 和 Memory 的边界其实分得很清楚。相关实现可以看 src/utils/claudemd.ts。在这部分实现里,CLAUDE.md 被归在一套明确的 instruction loading 顺序里:
- Managed memory:全局托管规则
- User memory:
~/.claude/CLAUDE.md - Project memory:仓库里的
CLAUDE.md、.claude/CLAUDE.md、.claude/rules/*.md - Local memory:
CLAUDE.local.md
这套机制本质上是在加载指令文件。
而同一个文件里又能看到另一套独立机制:当 auto memory 打开时,系统会额外读取 getAutoMemEntrypoint() 返回的 MEMORY.md,其类型是 AutoMem,团队记忆则是 TeamMem。源码里甚至专门写了注释:
AutoMem/TeamMem are intentionally excluded --- they're a separate memory system, not "instructions" in the CLAUDE.md/rules sense.
这句话非常关键。它说明:
CLAUDE.md这一层,本质上是 instructions / rulesMEMORY.md这一层,本质上是 auto memory / persistent memory
它们最后都会进入上下文,但在架构里并不是同一个东西。
所以如果从源码上更严格地说,CLAUDE.md 不是 MEMORY.md 的别名,更不是 auto-memory 的索引。
真正扮演"索引 + 主题文件"角色的,是后面的 MEMORY.md 系统。
1. Prompt 负责当前任务
Prompt 解决的是这一次你到底要 Claude 做什么。
比如:
- 这次只修 bug,不要顺手重构
- 这次只分析原因,先不要改代码
- 这次只改前端,不动后端
这些都是单次任务边界,适合写在 prompt 里,不适合沉淀进 CLAUDE.md。
2. 项目文档负责完整背景
README、设计文档、接口文档、架构说明,负责回答的是:
- 这个项目是什么
- 系统怎么设计
- 模块如何划分
- 业务流程怎么走
这些内容通常信息量大、细节多、更新频繁,它们的职责是"说明项目",不是"约束 Claude 的默认行为"。
3. CLAUDE.md 负责稳定规则
CLAUDE.md 解决的是那些跨多次任务都成立、而且会持续影响 Claude 决策的东西。
比如:
- 高风险文件和目录
- 错误处理规范
- 依赖策略
- migration 边界
- 哪些行为必须先确认
它不负责讲完整背景,只负责把真正影响行为的规则提炼出来。
4. Memory 负责自动沉淀
它更像 Claude 在长期协作里逐步学到的东西,是补充,不是替代。
你可以把它理解成"模型慢慢记住了你们项目里的某些偏好和事实",但这类记忆不适合代替明确规则。因为对于关键边界来说,你明确写下来的东西,永远比它自己学到的更稳。
结合源码看,这个分工会更清楚:
CLAUDE.md通过 instruction loader 进入系统 promptMEMORY.md则是 auto memory 的入口文件- 相关 topic files 会在需要时被检索和召回,而不是把所有细节都塞进一个大文件
因此,更准确的理解是把它们视为"两套协作机制",而不是"一份文件的两种叫法"。
5. Skill 负责重复流程
CLAUDE.md 管的是"长期规则",Skill 更适合管"这类任务应该怎么做"。
比如:
- 需求分析怎么展开
- Code Review 按什么顺序做
- 排查线上 bug 用什么流程
- 新功能开发先看哪些文件、再做哪些验证
这类内容本质上是"做事模板",更像流程,不像规则。
可以概括成一句话:
- 当前任务 进
Prompt - 稳定规则 进
CLAUDE.md - 完整背景进项目文档
- 自动沉淀 交给
Memory - 重复流程 沉淀成
Skill
一旦边界分清楚了,很多人最头疼的那个问题就会自动消失:
为什么我明明写了很多东西,但 Claude 还是不按我想的来?
因为你很可能把应该放在不同位置的信息,全塞进了 CLAUDE.md。
五、三层分层架构
CLAUDE.md 不是一个单一文件,而是一个分层的规则系统。
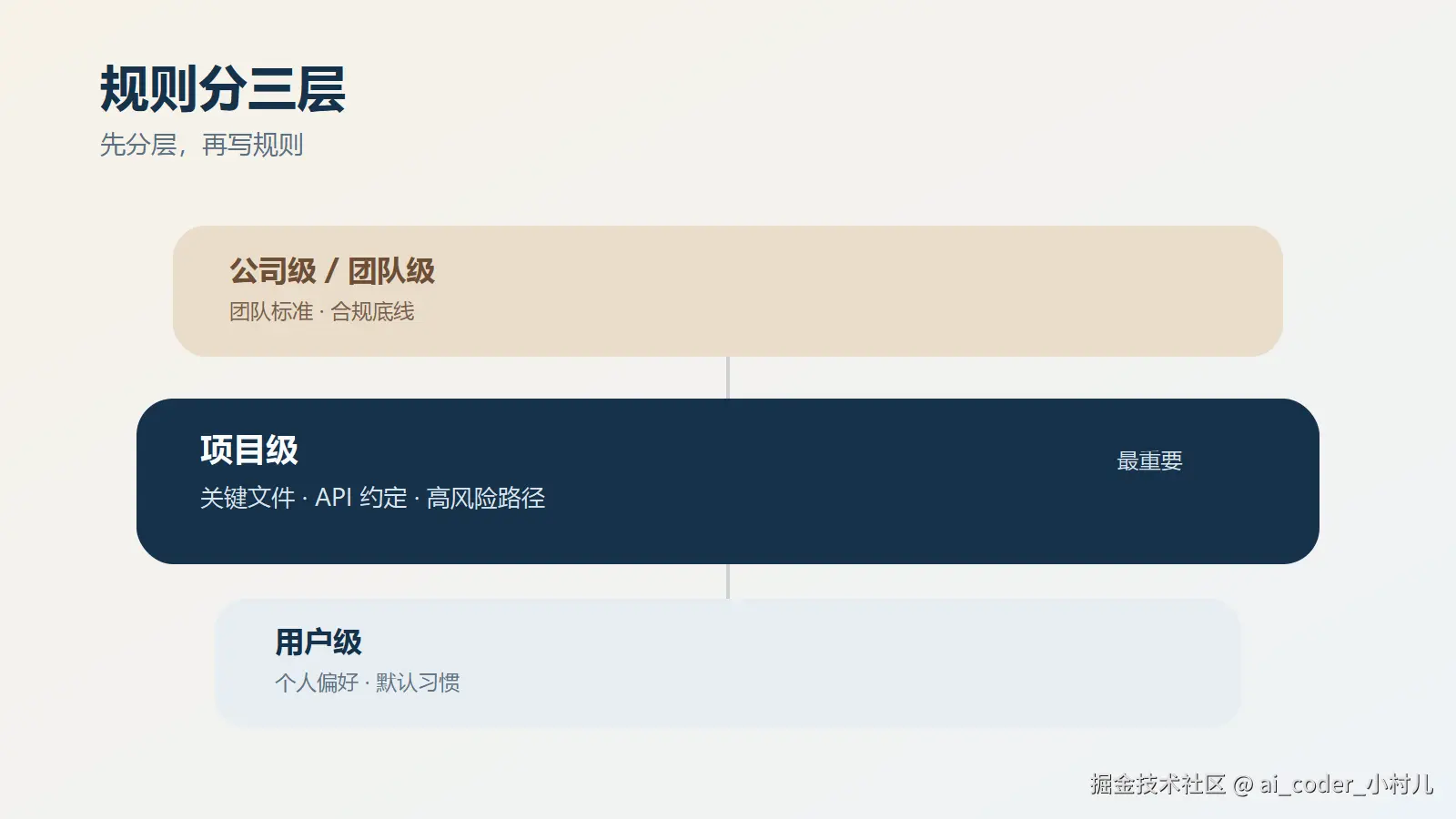
图:先按稳定性分层,再决定规则应该写到用户级、项目级还是公司级。
用户级 :~/.claude/CLAUDE.md
你电脑上所有项目都生效,写个人偏好。
项目级 :仓库根目录的 CLAUDE.md
只在这个项目生效,写项目特有约定,提交进 Git。
公司级 :企业统一管理的配置位置
整个组织生效,写合规要求和架构标准。大型企业才更常用,普通团队通常不需要。
判断一条规则放哪层,只用一个标准:
换个项目还成立吗?
成立放用户级。
比如:"我的变量命名用驼峰。" 换到任何项目都一样。
不成立放项目级。
比如:"这个项目用 Prisma,禁止用 Sequelize。" 换到 MongoDB 项目就不适用了。
这个区分看起来简单,但它直接决定后面的维护成本。
六、用户级:写你的默认行为偏好
用户级规则要少而精,不超过 50 行。这里写的是覆盖 Claude 默认值的个人偏好。
markdown
# 我的个人偏好
## 代码风格
- 缩进:2 个空格
- 变量命名:camelCase,类名 PascalCase
- 单行不超过 100 字符
## 我固定用的库(不要建议替代品)
- 日期处理:date-fns,不用 moment.js
- HTTP 请求:axios,不用 node-fetch
- 测试:Jest,不用 Vitest 或 Mocha
## 从不做的事
- 不要在我没要求时修改测试文件
- 不要建议我换版本控制工具
- 不要在随意讨论时提出架构大改动
## Git 提交格式
feat(模块名): 简短描述
- 改动说明 1
- 改动说明 2注意措辞:写的是"我的偏好",不是"你必须"。前者 Claude 当作信息接收,后者听起来像命令,反而可能在某些场景被跳过。
用户级不该写什么
- 一次性的任务背景
- 大段项目文档
- 经常变动的技术现状
- 只在某个仓库成立的规则
比如:"我现在在做一个电商系统。" 这不是偏好,是当前任务。应该放在 prompt 里。
七、项目级:记录这个项目特有的边界
项目级可以稍长,100 行左右。核心是三类内容:
1. 关键文件保护
markdown
## 禁止修改的文件
- src/config/env.ts --- 改了会影响生产环境变量加载
- .github/workflows/* --- CI/CD 流水线,改动需要 DevOps 审核
- 数据库 migration 文件一旦执行,不得修改,只能新增2. 编码规范,必须具体到代码动作
markdown
## 错误处理
统一使用 AppError 类,禁止 throw new Error():
throw new AppError('用户不存在', 404, 'USER_NOT_FOUND')
## API 响应格式
所有响应必须符合:
{ "success": true, "data": {}, "timestamp": "ISO字符串" }
错误响应:
{ "success": false, "error": "ERROR_CODE", "message": "描述" }3. 高风险路径标注
markdown
## 高风险区域(修改前必须告知我)
- src/modules/auth/* --- 认证核心,任何改动都需要 review
- src/handlers/payment/* --- 对接支付商,出错直接影响收入
- src/database/migrations/* --- 不可逆操作,要有回滚方案项目级真正决定效果的,不是"把整个项目介绍一遍",而是:
把这个仓库里最容易做错、最不能做错的东西写出来。
八、一条好规则到底该怎么写
很多人不是不会列规则,而是写出来之后没有约束力。
比如:
- 代码要整洁
- 数据库迁移要小心
- 不要随便改配置
这些话人类看得懂,但模型不一定知道"到底怎样做才算遵守"。
一条好规则,尽量包含这几个元素:
- 触发场景
- 期望动作
- 禁止动作
- 原因
- 示例

图:好规则最少要把场景、动作、边界和原因交代清楚。
看一个例子就很清楚。
markdown
❌ 只有规则
- 使用 Prisma 生成迁移,不要写原生 SQL
markdown
✅ 规则 + 原因 + 行为边界
- 涉及 schema 变更时,优先走现有 migration 工作流,不要临时手写 SQL 直接改结构。
原因:团队的审查、回滚和环境同步流程都围绕当前 migration 体系建立。
如果必须做破坏性变更,先说明影响范围和回滚方案。再比如:
markdown
❌ 太抽象
- 注意统一错误处理
markdown
✅ 可执行
- 所有业务异常统一使用 AppError,禁止直接 throw new Error()。
原因:前端依赖统一错误码和 message 做提示与埋点归类。关键就在这里:
CLAUDE.md 不是写原则,而是写可执行规则。
九、为什么有时有效,有时又像没生效
这也是很多人真正困惑的地方。
不是所有写进 CLAUDE.md 的内容,效果都一样。有些规则一写进去,Claude 的行为马上变化;有些规则写了之后,几乎没感觉。
通常不是因为它"没读",而是因为规则本身写得不够能执行。
第一,规则写成了背景介绍
例如:
markdown
本项目采用分层架构,强调可维护性和扩展性。这句话是背景,不是约束。Claude 即使看到了,也很难从里面推导出具体行动。
第二,规则太抽象
例如:
markdown
- 代码要整洁
- 注意性能
- 数据库修改要谨慎这些话人类看得懂,但模型不知道"怎样才算遵守"。
第三,规则太多,信噪比下降
不是说长文一定不好,而是低价值内容一多,真正重要的规则就会被埋掉。
如果一份 CLAUDE.md 里面既有项目概述、又有接口说明、又有架构文档、又有零碎提醒,那 Claude 真正应该优先遵守的那些边界,反而不够突出。
第四,规则之间互相冲突
比如你在用户级里写了"我习惯四空格缩进",项目级里又写"这个项目统一两空格",但没有说明项目级覆盖团队标准。
这种情况下,Claude 不是一定做错,而是判断空间会变大。
第五,单次任务 prompt 和长期规则打架
如果你在 CLAUDE.md 里长期写"默认不要大改",但当前 prompt 又说"请你重构这一块并统一风格",那单次任务会临时改变优先级。
这不是 CLAUDE.md 失效,而是上下文优先级在变化。
真正决定它能不能稳定生效的,是三件事:
规则足够具体,边界足够清楚,信噪比足够高。只有这三件事同时成立,CLAUDE.md 才会真正改变行为。
十、它很重要,但不是万能控制器
把这一点想清楚,对 CLAUDE.md 的期待反而会更稳。
CLAUDE.md 很强,但它不是万能控制器。它做不到下面这些事:
- 它不能替代清晰的任务描述
- 它不能替代 README 和设计文档
- 它不能替代你对复杂任务的即时判断
- 它不能保证 Claude 在任何场景下 100% 机械执行
它真正擅长的是:
- 让默认行为更接近你的项目习惯
- 让高风险边界更早暴露
- 让重复提醒沉淀成长期规则
- 让每次 prompt 更聚焦当前任务
所以最好的理解方式不是:
"只要我把 CLAUDE.md 写好了,后面什么都不用管了。"
而是:
"我用 CLAUDE.md 把稳定规则立住,再用 prompt 管当前任务,用文档承载背景,用 Skill 沉淀流程。"
只有在这套分工里,CLAUDE.md 的作用才会既强,又稳定。
十一、连接第 03 篇:为什么它能解决"纠正回退"
第 03 篇讲过一个现象:你在对话里纠正了 Claude,它承认了,但过几轮又犯同样的错。这不是 Claude 不配合,而是对话历史会随时间衰减,纠正效果也会随之消退。
更稳定的纠正方式,就是写进 CLAUDE.md。
写进 CLAUDE.md 的规则,每次对话开始时都会被系统自动注入,不受对话长度影响,也不会像临时纠正那样快速衰减。
判断标准很简单:
同一件事你纠正了两次以上,就应该写进 CLAUDE.md,不要再在对话里重复说。
markdown
# 这条规则在对话里说了三次,该进 CLAUDE.md 了:
- 日志统一用 logger.info/warn/error,禁止 console.log十二、Claude 会主动学习,但它补充不了规则层
CLAUDE.md 不是单向的。你往里写规则,Claude 也会在长期协作中逐步积累知识。
每轮对话结束后,Claude Code 会在后台启动一个独立的子 Agent,分析对话里有没有值得保留的项目知识,自动写入 Memory 文件,下次会话时注入:
text
对话结束 → 后台子 Agent 分析 → 提取项目偏好和技术决策
→ 写入 ~/.claude/projects/[项目]/memory/ → 下次会话自动读取你在某次对话里说了"我们禁止用 moment.js,改用 date-fns",下次打开 Claude Code,它已经记得了。
几个要知道的细节:
它补充 CLAUDE.md,不取代它。
自动记忆是"Claude 学到的",CLAUDE.md 是"你明确要求的",关键约束还是应该写在 CLAUDE.md 里。
明确说出来的比隐含的更容易被记住。
在对话里直接说"我们统一用 date-fns",提取率更高;只是悄悄在代码里换了库,Claude 可能记不到。
你可以检查它记了什么。
/memory 命令可以查看当前记忆内容,发现记错了直接改,它本质上还是普通文本文件。
实际效果是:Claude Code 越用越懂你的项目。头几天需要反复解释背景,用了几周后,很多背景已经自动沉淀,你的 prompt 可以越写越短。
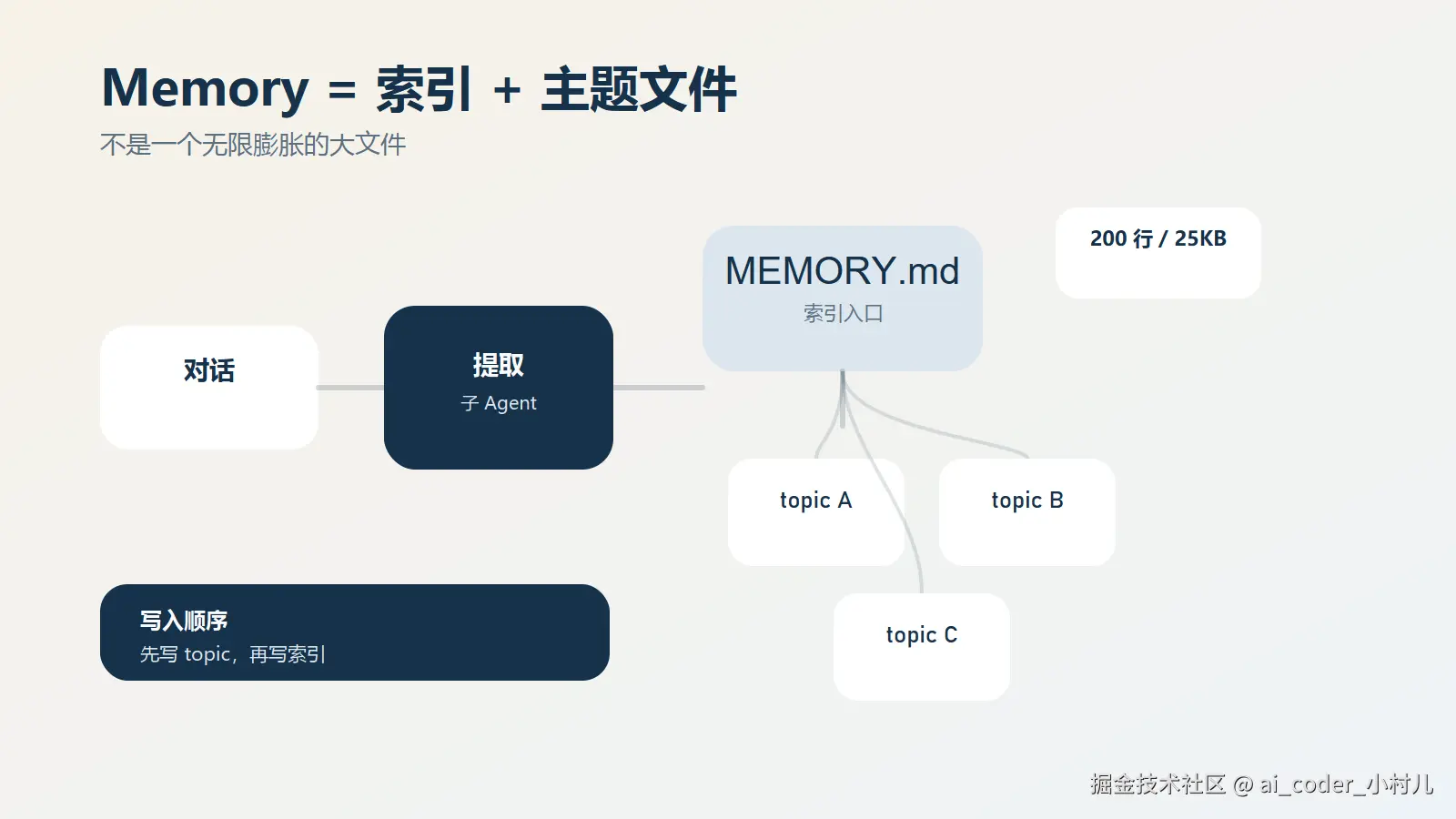
图:从源码看,Memory 更像索引入口 + topic files,而不是一个无限膨胀的大文件。
从源码看,Memory 本质上是一套"索引 + 主题文件"的结构
从实现上看,auto memory 不是把内容都堆在一个文件里。相关实现可以看 src/memdir/memdir.ts。在这部分实现里,入口常量就是:
ts
export const ENTRYPOINT_NAME = 'MEMORY.md'
export const MAX_ENTRYPOINT_LINES = 200
export const MAX_ENTRYPOINT_BYTES = 25_000这三行信息已经说明了很多问题:
第一,真正被当作 memory 入口文件的,是 MEMORY.md,不是 CLAUDE.md。
第二,系统从设计上就不希望这个入口文件无限膨胀。
第三,memory 架构默认就不是"把所有内容堆在一个大文件里"。
同一个文件里,源码把保存流程直接写成了两步:
- 先把记忆写入独立主题文件
- 再在
MEMORY.md里增加一个索引指针
源码注释原话基本就是这个意思:
- Step 1:write the memory to its own file
- Step 2:add a pointer to that file in
MEMORY.md
而且它还专门强调:
MEMORY.mdis an index, not a memory
从实现上看,Claude Code 的 auto memory 更像:
MEMORY.md:目录页 / 索引页- topic files:按主题拆开的详细内容
这也解释了一个很多人会问的问题:
如果记忆越积越多,MEMORY.md 不会越来越大吗?
答案是:源码层面已经考虑了这个问题。
truncateEntrypointContent() 会对 MEMORY.md 做双重限制:
- 超过 200 行会截断
- 超过 25KB 也会截断
截断后甚至还会追加警告,提醒把细节移到 topic files,只把一行短索引留在 MEMORY.md。
换句话说,这套设计本身就在强制你保持:
- 索引足够短
- 细节分散到主题文件
- 入口文件永远尽量装得进上下文
这和 CLAUDE.md 的定位,是什么关系
最容易混在一起的,恰恰是规则系统和记忆系统。
如果站在源码架构的角度看:
CLAUDE.md更像 instruction layerMEMORY.md更像 memory index layer- topic files 更像 memory payload layer
这三层不是互相替代,而是互相配合。
所以把 CLAUDE.md 定义成"规则层"是成立的,而且和源码是对齐的。
放到 Claude Code 的完整架构里看,CLAUDE.md 负责规则,MEMORY.md 负责记忆索引,topic files 负责详细内容。
这样去理解,规则、索引和记忆详情各自负责什么,就不会再混成一团。
从源码看"自愈"和写入一致性
把这套机制类比成一种带"自愈"倾向的写入纪律,可以作为理解辅助,但不宜把类比直接当成源码结论。
从目前能看到的实现和解析文档来看,至少可以确定三件事:
- memory 保存采用"先写主题文件,再更新
MEMORY.md指针"的两步方式 - 这种顺序天然更有利于一致性,因为索引最终指向的是已经成功落盘的内容
- 它的思路更接近"先落数据,再更新索引",和很多数据库 / 存储系统的一致性设计取向相似
更稳妥的理解是,把它当作一种 可以类比理解 的一致性思路,而不是直接把它等同于"源码明确实现了 WAL 逆向"。
因为源码里我能确认的是:
- 两步保存存在
MEMORY.md是索引存在- 入口大小控制存在
- 按需检索 topic files 存在
这些都是可以直接从源码和解析文档里站得住的。
十三、两个最常见的陷阱
陷阱一:写得太多,关键规则被淹没
CLAUDE.md 写得太长时,Claude 往往只会抓住其中最显眼、最强约束的那部分,其他内容会逐渐退化成背景噪音。规则越多,真正稳定生效的比例通常越低。
解决方法:
- 定期删掉已经不再是问题的规则
- 删掉太细节、没有行为约束力的规则
- 删掉重复表达
CLAUDE.md 应该是个活跃的 hotlist,不是越来越臃肿的文档。
陷阱二:规则放错层级
用户级放了项目特有规则,Claude 在其他项目里也按这个来。
项目级放了所有项目通用规则,十几个项目各自维护一份重复内容,改一条要改十几个地方。
解决方法还是那一句:
换个项目还成立吗?
成立放用户级,不成立放项目级,一次定好就别再改。
十四、维护节奏
CLAUDE.md 写好之后不是扔着不管,需要定期维护。
第一个月:初始化
用 /init 生成草稿,花半小时补充:
- 关键文件保护
- 错误处理规范
- API 格式约定
- 高风险路径说明
这是最重要的一次,做好了后面会省很多事。
每两周:维护
回顾最近 Claude 犯过什么错。
- 同一个错出现两次以上,加进
CLAUDE.md - 已经不构成问题的规则,删掉
- 写得太空的规则,改具体一点
每季度:清理
把整个文件读一遍:
- 删冗余
- 合并重复
- 简化过细规则
目标是让文件保持高信噪比,而不是越写越长。
十五、检查清单
提交项目级 CLAUDE.md 前过一遍:
- 规则是纠偏式的,不是文档式的
- 每条规则能对应到 Claude 的一个具体行为变化
- 关键文件有明确的保护声明
- 高风险路径有标注和警告
- 重要规则附上了"为什么"
- 用户级和项目级没有混放
- 文件总长度不超过 200 行
- 对话里纠正过两次以上的规则已经写进来了
本篇实践任务
任务一: 打开你现有的 CLAUDE.md,把里面每条规则过一遍:它是纠偏式,还是文档式?把文档式的删掉或者改成纠偏式。
任务二: 回想最近一周,你在对话里纠正过 Claude 几次同一个问题?把这些问题整理成具体规则,写进 CLAUDE.md,下次对话观察效果。
任务三: 运行 /memory,看看 Claude 已经自动记住了什么。和你的 CLAUDE.md 对比,有没有重复的内容?有没有记错的内容需要修正?
下篇预告
第 05 篇:Skill 提炼------把重复任务沉淀成可复用模板
CLAUDE.md 管的是全局规则,Skill 管的是任务模板。当同一类任务反复出现,把"怎么做这类任务"浓缩成一个 Skill,下次直接触发。下一篇会讲什么时候沉淀 Skill、怎么写一个真正有效的 Skill,以及 Skill 和自定义命令的边界在哪。
AI Coding 系列持续更新。CLAUDE.md 是规则层,不是项目文档。写法不同,效果天壤之别。