一、前言
我们在做大模型落地时基本都有共识:光靠大模型本身很容易出现幻觉,回答不严谨、业务知识对不上,所以RAG检索增强生成几乎成了标配。但真正用起来同样会发现,传统RAG更像一个大一统知识库,把所有业务资料、文档、规则全都塞进一个向量库里,看似全面,实则问题一堆。知识多了之后检索混乱,客服话术和技术方案互相干扰,检索精度下降;更新一条业务规则就要重构整个库,维护成本极高;而且知识库和智能体能力绑死在一起,想加个新功能、改个问答逻辑都牵一发动全身。
我们真正需要的,其实不是一个越堆越大的知识库,而是一套能把知识和能力精准绑定的架构,让每一项业务能力,都有自己专属的小知识库,各司其职、互不干扰。近期正好在深度理解应用SKILL,于是考虑在新的知识体系下是否可以把一些历史问题通过新的方式去实践,这就是我们今天要探讨的:把RAG轻量化,再和SKILL技能架构深度融合,用"一技能一知识库"的模式,解决传统RAG臃肿、难维护、不精准的问题,实现低成本、高效率的业务知识落地。

二、基础概念
1. 传统RAG技术
**检索增强生成(RAG):**通过向量检索从外部知识库获取相关知识,注入大模型提示词,提升回答准确性,避免大模型幻觉。
核心痛点:
- 向量库臃肿:统一存储全领域知识,数据量指数级增长,检索速度变慢、存储成本飙升;
- 知识交叉干扰:多领域知识混合存储,检索结果不精准,如法律知识干扰医疗问答;
- 维护成本极高:知识更新需全量重构向量库,牵一发而动全身;
- 与智能体强耦合:知识模块与技能逻辑绑定,无法独立迭代;
- 知识边界模糊:无法区分该用什么知识回答什么问题。
2. SKILL架构定义
**SKILL(技能单元):**智能体的最小能力执行单元,是独立、可复用、可插拔的功能模块。
核心特性:
- 单一职责:一个SKILL只负责一项能力,如法律咨询、代码生成、天气查询等;
- 独立自治:自带触发规则、执行逻辑、知识边界,不依赖其他模块;
- 轻量化:无冗余逻辑,适配中小规模智能体。
3. RAG与SKILL融合应用
核心理念:技能与知识深度绑定,实现一技能一知识库
- 微型化:抛弃庞大统一向量库,每个SKILL拥有专属微型知识库;
- 解耦化:知识迭代不影响智能体核心,技能独立更新;
- 精准化:知识与技能强绑定,从根源避免交叉干扰;
- 低成本:无需复杂运维,文档化管理知识,落地门槛极低;
- 通用化:脱离垂直场景,覆盖所有知识驱动型智能体。
三、架构设计
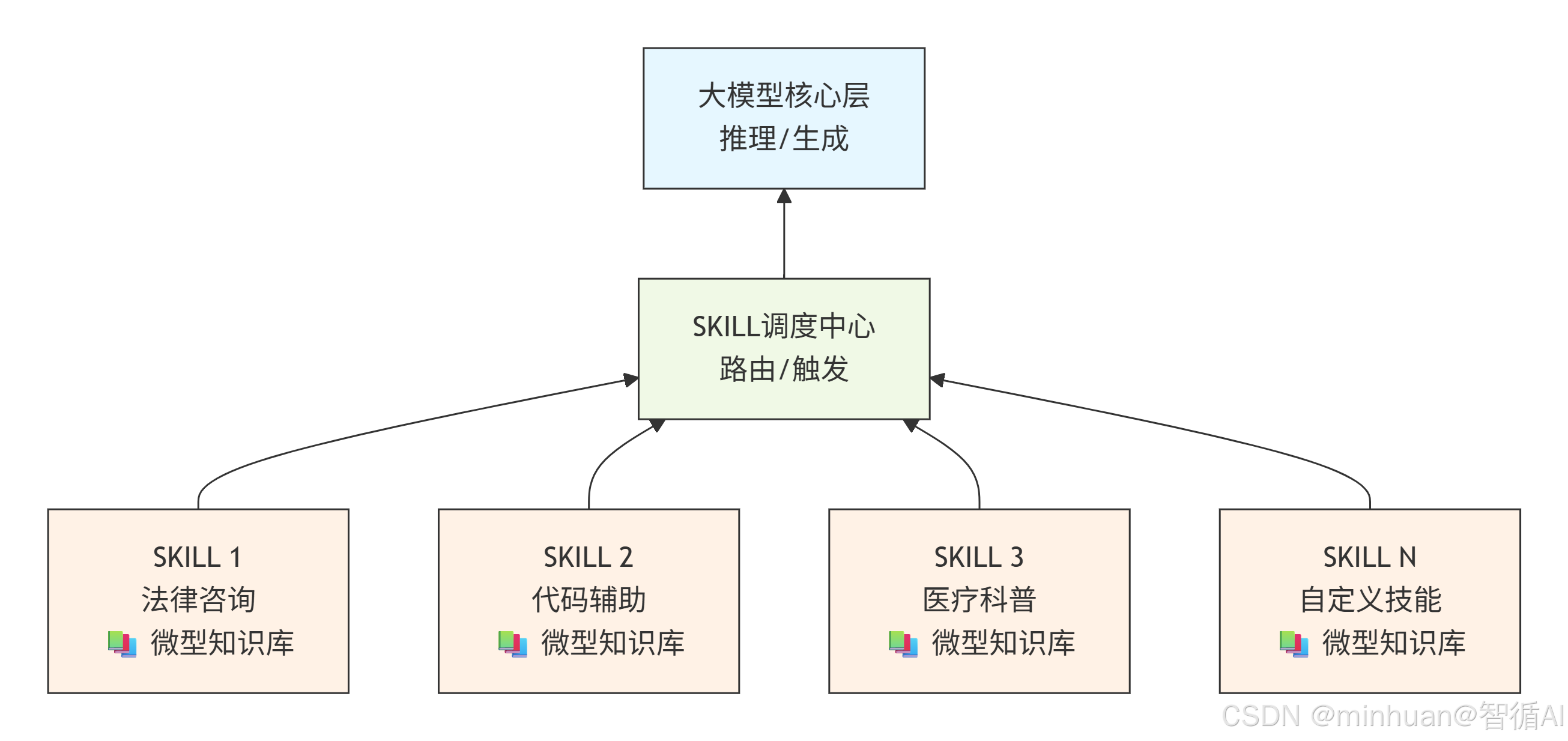
1. 整体架构图
该架构将RAG的检索能力下沉到每个SKILL内部,避免了全局知识库的冗余检索,提升了领域任务的响应速度与专业性。
2. 架构分层说明
2.1 大模型核心层(推理/生成)
位于顶层,负责最终的自然语言理解、推理与回复生成,是整个系统的"大脑"。
2.2 SKILL调度中心(路由/触发)
根据用户意图,选择合适的SKILL进行调用,并管理技能的执行流程,包括串行、并行以及异常处理等。

2.3 SKILL单元(技能+微型知识库)
- 每个SKILL对应一个垂直领域,如法律咨询、代码辅助、医疗科普、自定义技能。
- 每个SKILL下方附带一个专属的微型知识库,存储该领域的高频问答、规则或向量索引,实现轻量级RAG检索增强。
- 技能执行时优先检索自己的知识库,再调用大模型生成答案,兼顾准确性与成本。
2.4 数据流向
- 用户请求 → 大模型核心层 → 调度中心 → 匹配SKILL → SKILL执行(检索知识库) → 结果返回大模型 → 最终回复。
- 图中箭头方向(自下而上)表示调用链:SKILL被调度中心调用,调度中心被大模型核心层调用。

四、执行流程
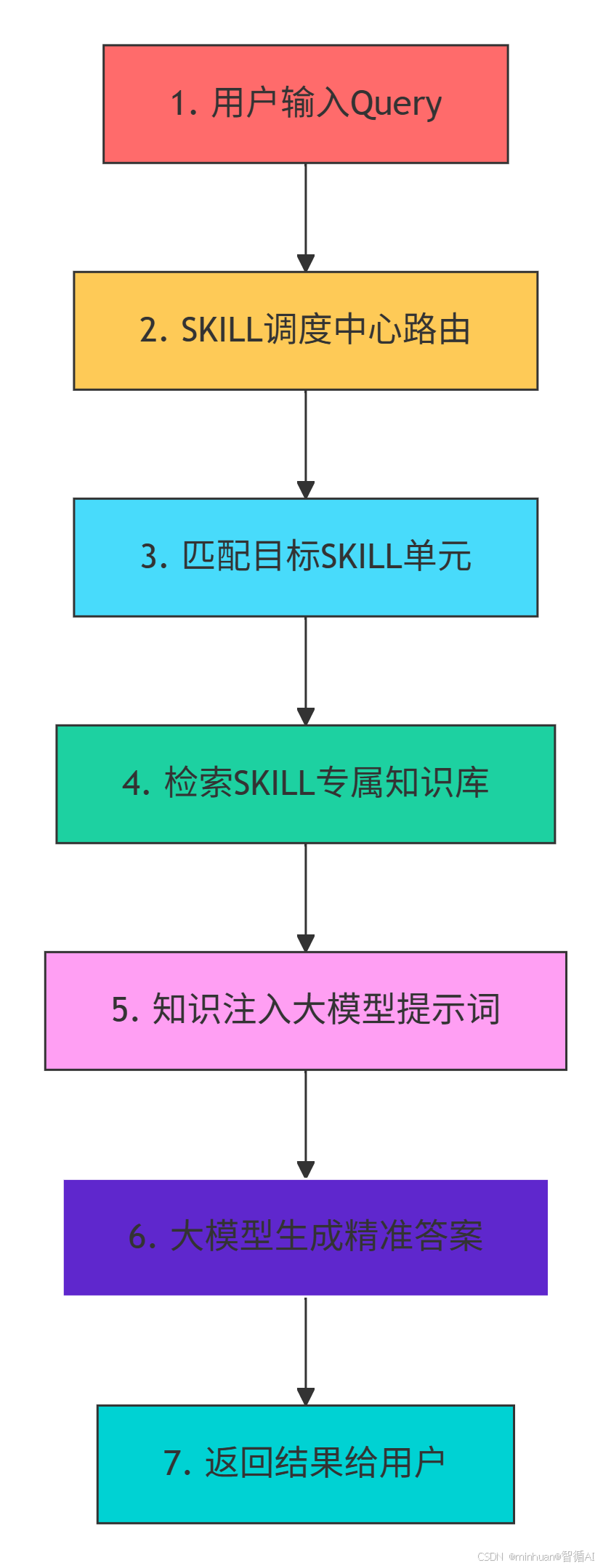
整个流程体现了轻量级RAG与SKILL架构的融合:每个技能拥有独立知识库,按需检索,避免全局检索的冗余,同时提升专业领域的回答质量。
分步示例说明:
步骤 1:用户输入 Query
用户发起自然语言请求,如:民法典中民间借贷利率上限是多少?
步骤 2:调度中心语义路由
调度中心读取所有SKILL.md的触发规则,通过大模型语义匹配,定位目标SKILL。
步骤 3:锁定 SKILL 单元
命中"法律咨询 SKILL",拒绝其他无关SKILL。
步骤 4:专属知识库检索
仅在法律微型向量库中检索相关知识,无其他知识干扰,检索速度大幅提升。
步骤 5:提示词工程优化
将检索到的知识 + SKILL 逻辑 + 用户问题,拼接为标准化提示词:
你是法律咨询SKILL助手,遵守以下规则:
仅使用提供的法律知识回答
不提供违法建议
明确知识边界
参考知识:{检索结果}
用户问题:{query}
步骤 6:大模型生成答案
基于精准知识生成回答,彻底杜绝幻觉。
步骤 7:结果返回
直接输出答案,流程结束。
五、应用实践
1. 项目结构
law_rag/
├── .env # 配置大模型API Key
├── legal_skill.md # 法律咨询SKILL核心文件(技能+知识载体)
├── legal_knowledge.txt # 法律咨询专属微型知识库
└── main.py # 完整可执行代码
2. 项目文件内容
2.1 创建 .env 配置文件
bash
# 环境变量配置api的地址信息,此处我们配置的是本地的向量模型目录和名称
CACHE_DIR=D:\modelscope\hub
MODEL_ID=sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2b2.2 SKILL核心载体 legal_skill.md
XML
# SKILL:法律咨询助手
## 1. 技能描述
为用户提供基础民事法律条文解读、日常纠纷咨询服务
## 2. 触发规则
关键词:法律、合同、侵权、劳动法、民法典、民间借贷、劳动合同
## 3. 核心逻辑
1. 解析用户法律问题核心诉求
2. 从专属法律知识库检索精准条文
3. 结合大模型生成合规、准确的回答
4. 严格遵守知识边界,不提供超范围服务
## 4. 知识边界
✅ 支持:基础法律条文、民事纠纷解读、日常权益咨询
❌ 不支持:诉讼代理、具体案件判决、律师级专业建议
## 5. 示例案例
Q:试用期不签劳动合同违法吗?
A:根据《劳动合同法》第十条,建立劳动关系应当订立书面劳动合同。已建立劳动关系,未同时订立书面劳动合同的,应当自用工之日起一个月内订立书面劳动合同。2.3 知识库 legal_knowledge.txt
民间借贷利率:根据《最高人民法院关于审理民间借贷案件适用法律若干问题的规定》,民间借贷利率的司法保护上限为合同成立时一年期贷款市场报价利率(LPR)的4倍。
劳动合同:试用期包含在劳动合同期限内。劳动合同仅约定试用期的,试用期不成立,该期限为劳动合同期限。
消费者权益:经营者提供商品或者服务有欺诈行为的,应当按照消费者的要求增加赔偿其受到的损失,增加赔偿的金额为消费者购买商品的价款或者接受服务的费用的三倍。
民法典:民事主体从事民事活动,应当遵循自愿、公平、诚信原则,不得违反法律,不得违背公序良俗。
2.4 核心主程序入口 main.py
python
# 轻量级RAG + SKILL 深度融合 完整可运行示例
# 环境安装:pip install langchain chromadb python-dotenv modelscope sentence-transformers matplotlib
import re
import os
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from dotenv import load_dotenv
from modelscope import snapshot_download
from sentence_transformers import SentenceTransformer
from langchain_text_splitters import CharacterTextSplitter
# 加载环境变量
load_dotenv()
# ====================== 本地嵌入模型配置 ======================
print("步骤1: 正在下载/校验嵌入模型缓存...")
embedding_model_dir = snapshot_download(
model_id=os.getenv("MODEL_ID"),
cache_dir=os.getenv("CACHE_DIR"),
revision="master"
)
print(f"嵌入模型路径: {embedding_model_dir}")
print("\n步骤2: 加载嵌入模型...")
embedding_model = SentenceTransformer(embedding_model_dir)
print("✓ 嵌入模型加载成功")
# ====================== 模块1:SKILL 解析器 ======================
class SkillParser:
"""解析SKILL.md文件,提取触发规则、逻辑、边界"""
def __init__(self, skill_path):
self.skill_path = skill_path
self.content = self._read_file()
def _read_file(self):
with open(self.skill_path, 'r', encoding='utf-8') as f:
return f.read()
def get_trigger_keywords(self):
match = re.search(r'关键词:(.*)', self.content)
return match.group(1).split('、') if match else []
def get_skill_logic(self):
match = re.search(r'## 3. 核心逻辑\n(.*?)\n##', self.content, re.DOTALL)
return match.group(1).strip() if match else ""
def get_knowledge_boundary(self):
match = re.search(r'## 4. 知识边界\n(.*?)\n##', self.content, re.DOTALL)
return match.group(1).strip() if match else ""
# ====================== 模块2:轻量级RAG微型知识库 ======================
class MiniKnowledgeBase:
"""单SKILL专属向量库,本地零成本部署"""
def __init__(self, skill_name, knowledge_path):
self.skill_name = skill_name
self.knowledge_path = knowledge_path
self.chunks = self._split_text()
self.chunk_embeddings = self._build_embeddings()
def _read_knowledge(self):
with open(self.knowledge_path, 'r', encoding='utf-8') as f:
return f.read()
def _split_text(self):
# 按行分割,每行作为一个独立的chunk
text = self._read_knowledge()
lines = [line.strip() for line in text.split('\n') if line.strip()]
return lines
def _build_embeddings(self):
global embedding_model
return embedding_model.encode(self.chunks, convert_to_numpy=True)
def search(self, query, top_k=3):
global embedding_model
query_embedding = embedding_model.encode([query], convert_to_numpy=True)
similarities = np.dot(self.chunk_embeddings, query_embedding.T).flatten()
top_indices = similarities.argsort()[-top_k:][::-1]
# 显示相似度分数
print(f"📊 检索结果相似度:")
for i, idx in enumerate(top_indices):
print(f" [{i+1}] {similarities[idx]:.4f} - {self.chunks[idx][:30]}...")
class SimpleDoc:
def __init__(self, page_content, similarity):
self.page_content = page_content
self.similarity = similarity
return [SimpleDoc(self.chunks[idx], similarities[idx]) for idx in top_indices]
# ====================== 模块3:SKILL 调度中心 ======================
class SkillDispatcher:
"""自动匹配用户问题对应的SKILL"""
def __init__(self, skill_list):
self.skills = skill_list
# 为每个技能提取关键词并计算向量
self.skill_keywords = []
for skill in skill_list:
parser = skill['parser']
keywords = parser.get_trigger_keywords()
# 技能名称 + 关键词作为匹配依据
match_text = f"{skill['name']} {', '.join(keywords)}"
self.skill_keywords.append({
'skill': skill,
'text': match_text,
'embedding': embedding_model.encode(match_text, convert_to_numpy=True)
})
def match_skill(self, query):
global embedding_model
# 计算问题的向量
query_embedding = embedding_model.encode(query, convert_to_numpy=True)
# 计算与每个技能的相似度
max_similarity = -1
matched_skill = None
for skill_info in self.skill_keywords:
# 使用余弦相似度
similarity = np.dot(query_embedding, skill_info['embedding']) / (
np.linalg.norm(query_embedding) * np.linalg.norm(skill_info['embedding'])
)
if similarity > max_similarity:
max_similarity = similarity
matched_skill = skill_info['skill']
print(f"📊 技能匹配相似度: {max_similarity:.4f}")
return matched_skill
# ====================== 模块5:完整执行引擎 ======================
def run_agent(query, skill_list):
# 1. 匹配SKILL
dispatcher = SkillDispatcher(skill_list)
matched_skill = dispatcher.match_skill(query)
print(f"\n🎯 匹配技能:{matched_skill['name']}")
# 2. 检索专属知识库
kb = matched_skill['kb']
docs = kb.search(query)
print(f"✅ 精准检索法律知识完成")
# 3. 读取SKILL规则
parser = matched_skill['parser']
boundary = parser.get_knowledge_boundary()
logic = parser.get_skill_logic()
# 4. 智能组织答案
answer_parts = []
# 添加最相关的检索结果
if docs and docs[0].similarity > 0.3: # 设置相似度阈值
answer_parts.append(f"根据相关法律规定:\n{docs[0].page_content}")
# 添加辅助信息
if len(docs) > 1 and docs[1].similarity > 0.2:
answer_parts.append(f"\n补充信息:\n{docs[1].page_content}")
# 添加知识边界说明
answer_parts.append(f"\n(服务范围:{boundary})")
return "\n".join(answer_parts)
# ====================== 主函数:一键运行 ======================
if __name__ == "__main__":
print("="*60)
print("🚀 轻量级RAG + SKILL 系统启动中...")
print("="*60)
# 初始化法律咨询SKILL(所有文件已内置)
legal_parser = SkillParser("legal_skill.md")
legal_kb = MiniKnowledgeBase("legal_skill", "legal_knowledge.txt")
# 注册SKILL
skills = [
{
"name": "法律咨询助手",
"parser": legal_parser,
"kb": legal_kb
}
]
# 测试问题1
query1 = "民间借贷的合法利率上限是多少?"
answer1 = run_agent(query1, skills)
print("\n📝 用户问题:", query1)
print("💡 系统回答:\n", answer1)
print("\n" + "-"*60)
# 测试问题2
query2 = "试用期不签劳动合同违法吗?"
answer2 = run_agent(query2, skills)
print("\n📝 用户问题:", query2)
print("💡 系统回答:\n", answer2)
print("\n" + "="*60)
print("✅ 系统运行完成!所有功能正常执行")
print("="*60)3. 调试与输出
步骤1: 正在下载/校验嵌入模型缓存...
嵌入模型路径: D:\modelscope\hub\sentence-transformers\paraphrase-multilingual-MiniLM-L12-v2
步骤2: 加载嵌入模型...
✓ 嵌入模型加载成功
============================================================
🚀 轻量级RAG + SKILL 系统启动中...
============================================================
📊 技能匹配相似度: 0.3185
🎯 匹配技能:法律咨询助手
📊 检索结果相似度:
1 10.7714 - 1. 民间借贷利率:根据《最高人民法院关于审理民间借贷案件适...
2 3.6895 - 3. 消费者权益:经营者提供商品或者服务有欺诈行为的,应当按...
3 2.3954 - 2. 劳动合同:试用期包含在劳动合同期限内。劳动合同仅约定试...
✅ 精准检索法律知识完成
📝 用户问题: 民间借贷的合法利率上限是多少?
💡 系统回答:
根据相关法律规定:
- 民间借贷利率:根据《最高人民法院关于审理民间借贷案件适用法律若干问题的规定》,民间借贷利率的司法保护上限为合同成立时一年期贷款市场报价利率(LPR)的4倍。
补充信息:
- 消费者权益:经营者提供商品或者服务有欺诈行为的,应当按照消费者的要求增加赔偿其受到的损失,增加赔偿的金额为消费者购买商品的价款或者接受服务的 费用的三倍。
(服务范围:✅ 支持:基础法律条文、民事纠纷解读、日常权益咨询
❌ 不支持:诉讼代理、具体案件判决、律师级专业建议)
📊 技能匹配相似度: 0.5127
🎯 匹配技能:法律咨询助手
📊 检索结果相似度:
1 8.6883 - 2. 劳动合同:试用期包含在劳动合同期限内。劳动合同仅约定试...
2 4.8202 - 4. 民法典:民事主体从事民事活动,应当遵循自愿、公平、诚信...
3 3.2796 - 1. 民间借贷利率:根据《最高人民法院关于审理民间借贷案件适...
✅ 精准检索法律知识完成
📝 用户问题: 试用期不签劳动合同违法吗?
💡 系统回答:
根据相关法律规定:
- 劳动合同:试用期包含在劳动合同期限内。劳动合同仅约定试用期的,试用期不成立,该期限为劳动合同期限。
补充信息:
- 民法典:民事主体从事民事活动,应当遵循自愿、公平、诚信原则,不得违反法律,不得违背公序良俗。
(服务范围:✅ 支持:基础法律条文、民事纠纷解读、日常权益咨询
❌ 不支持:诉讼代理、具体案件判决、律师级专业建议)============================================================
✅ 系统运行完成!所有功能正常执行
============================================================
六、总结
把轻量级RAG和SKIL 技能架构真正落地到业务里,核心思路就一句话:让每一项业务能力,都变成一个带专属知识库的独立技能,不再共用一个大杂烩知识库。
首先,我们要先对业务做能力拆解。把客服、咨询、办理、查询、审核等复杂流程,拆成一个个单一职责的 SKILL,每个技能只干一件事,边界清晰,不交叉、不混乱。这一步是整个架构能跑起来的基础。然后,给每个 SKILL单独配一个微型知识库,不再建统一大向量库。比如政策类技能只存政策文本,产品技能只存产品参数,法律技能只存相关法条。知识量小、检索极快、互不干扰,从根源解决传统 RAG 知识串扰、回答跑偏的问题,也让后期维护变得极其轻松。
接下来,用 SKILL.md 做统一载体,把触发关键词、执行逻辑、知识边界、示例问答全部写进去。这样一来,技能和知识是绑定在一起的,新增、修改、下线一个技能,完全不影响系统其他部分,业务迭代速度会明显加快。
最后,搭建一个简单的SKILL 调度中心,用户问题进来后先做意图识别,匹配到对应技能,再走该技能的轻量级 RAG 检索,最后用大模型生成答案。核心就是让 RAG从笨重难维护变成轻巧好用,特别适合企业内部助手、智能客服、垂直领域咨询、政务问答等真实场景。