一、前言
本文是我对 Canal 的一次系统性学习整理,主要记录它的核心原理、常用能力和实际落地中的关键问题。
这篇文章不仅会讲清楚 Canal 如何接入 ,也会关注 接入之后如何把数据链路跑稳,包括异常处理、幂等、补偿和治理思路。
本文主要覆盖:
- Canal 是什么
- Canal 能做什么
- Canal 的核心原理
- Canal 的核心概念
- Canal 支持的传输模式
- Canal 常用 API
- 如何搭建并使用 Canal
- 使用 Canal 时需要注意什么
学习 Canal 的过程中,我的体会是:
如果你已经了解 MySQL binlog 和主从同步,Canal 的入门并不复杂。
真正需要持续打磨的,是变更消费之后的业务处理与链路治理能力。Canal 更像是数据链路的起点,稳定性建设仍然在业务侧。
所以,Canal 的难点不只是"跑起来",而是"稳定、可观测、可恢复地长期运行"。
二、Canal 是什么
2.1 官方定义
Canal 是一个基于 MySQL binlog 增量日志解析 ,提供数据订阅与消费能力的组件。
2.2 三层理解
很多人对 Canal 的理解停留在"工具使用层",其实可以从三个层面去看它。
第一层:业务视角
数据库发生变化,其他系统能够感知到。
例如:
- 商品价格变化 → ES 索引更新
- 用户信息变化 → Redis 缓存刷新
- 订单状态变化 → 触发后续业务流程
本质上是"数据驱动系统"。
第二层:技术视角
Canal 监听的不是 SQL,而是 MySQL 的 binlog。
它不依赖业务代码:
- 不侵入业务逻辑
- 不拦截 JDBC
- 不做 AOP
而是直接从数据库日志层获取变化。
第三层:本质视角(建议记住)
Canal = MySQL 主从复制机制 + 数据消费能力
这是理解 Canal 的关键。
2.3 一个更形象的理解
可以把 Canal 看成一条"数据水渠":
MySQL 数据变更 → binlog → Canal → 下游系统稍微工程一点:
业务写MySQL → MySQL记录binlog → Canal解析 → 业务消费 → ES/Redis更新它解决的核心问题是:
如何把 MySQL 的增量变化,以低侵入的方式传递到其他系统。
三、Canal 能做什么
3.1 常见应用场景
| 场景 | 说明 |
|---|---|
| 搜索索引同步 | MySQL → Elasticsearch |
| 缓存刷新 | MySQL → Redis |
| 异构数据同步 | MySQL → 其他存储或服务 |
| 宽表构建 | 多表变化驱动统一索引或报表 |
| 实时业务处理 | 基于数据变化触发业务逻辑 |
| 增量备份/镜像 | 基于 binlog 的数据订阅处理 |
3.2 Canal 的优点
| 优点 | 说明 |
|---|---|
| 低侵入 | 不需要在业务代码里显式双写 |
| 准实时 | 相比定时任务,时效性更高 |
| 解耦 | MySQL 写入和下游同步分离 |
| 通用性强 | 可同步到 ES、Redis、MQ、其他系统 |
| 天然增量 | 基于 binlog,只关注变化部分 |
一句话概括:
Canal 把"数据同步"从业务代码中抽离出来。
3.3 Canal 的不足
| 不足 | 说明 |
|---|---|
| 非强一致 | 更适合最终一致性场景 |
| 要处理幂等 | rollback 后可能重复消费 |
| 会有异常数据问题 | 一条脏数据可能卡住整条链路 |
| 需要补偿机制 | 仅靠实时链路通常不够 |
| 工程复杂度在业务侧 | 难点不在接入,而在后续治理 |
一个很实际的结论是:
Canal 的复杂度不在接入,而在后续治理。
四、Canal 核心原理
4.1 工作流程

4.2 核心机制
Canal 的核心流程可以按下面几步理解:
- MySQL 写入 binlog: 当发生
INSERT / UPDATE / DELETE时,MySQL 会把这些变化写到 binlog 中。 - Canal 伪装成 MySQL slave: Canal 会模拟从库,与 MySQL 建立复制连接。
- Canal 向 MySQL 发送 dump 请求: 本质上是在说: "我作为从库,要开始拉你的 binlog 了。"
- MySQL 按主从复制协议推送 binlog: 这一点和真正的 MySQL 主从复制原理非常接近。
- Canal 解析 binlog: 把原始日志转换成结构化对象,区分出
INSERT / UPDATE / DELETE类型。 - 客户端消费数据(TCP模式 || MQ模式): 业务程序通过 TCP 模式连接 Canal,拉取这些解析后的数据,再做自己的处理。
本质上:
Canal 复用了 MySQL 主从复制协议。
4.3 为什么容易理解
因为它的原理并不难。
如果已经理解这两件事:
- binlog 是什么
- MySQL 主从同步是怎么回事
那么 Canal 的理解成本会低很多。
换句话说,Canal 并不是另起炉灶发明了一套很新的东西,而是站在 MySQL 主从复制的能力之上,把日志消费这件事做成了一个组件。
4.4 数据结构
Canal 拉到的数据并不是"原始 SQL 字符串",而是结构化后的对象。
erlang
Message
└── Entry
└── RowChange
└── RowData
├── beforeColumns
└── afterColumns各层含义
| 层级 | 作用 |
|---|---|
Message |
一次拉取回来的一批数据 |
Entry |
单条变更记录 |
RowChange |
行级变化信息 |
RowData |
一行数据的 before / after |
Column |
某个字段的值 |
4.5 UPDATE 示例
ini
UPDATE product
SET price = 4999,
stock = 20
WHERE id = 1;解析后:
| 字段 | before | after |
|---|---|---|
| id | 1 | 1 |
| price | 5999 | 4999 |
| stock | 50 | 20 |
这也是为什么 Canal 很适合做索引同步、缓存刷新和宽表更新: 它不是只告诉你"有变化",还告诉你"具体哪一列从什么变成了什么"。
五、核心概念
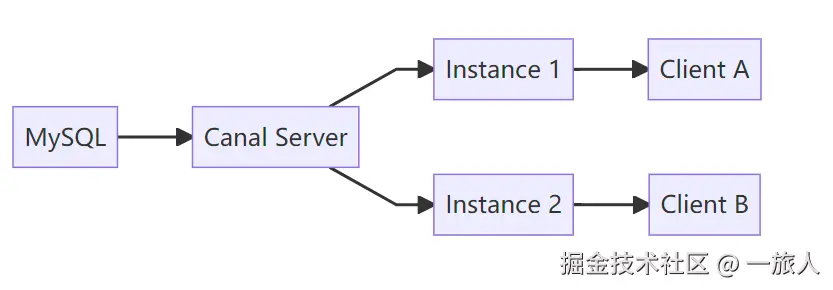
5.1 Canal Server
Canal 的服务端,负责:
- 连接 MySQL
- 拉取 binlog
- 解析 binlog
- 对外提供消费能力
5.2 Instance
Instance 是 Canal Server 中的一个订阅单元。
通常可以这样理解:
- Server 是容器
- Instance 是任务
一个 Server 可以包含多个 Instance。 一个 Instance 通常对应一个 MySQL 数据源,并配置监听哪些库表。
5.3 Client
Client 就是业务系统,例如 Spring Boot 应用。
它负责:
- 连接 Canal Server
- 拉取消息
- 处理自己的业务逻辑
5.4 关系结构图
六、Canal 支持的传输模式
6.1 TCP 模式
这是最直接的模式,也是本文重点。
特点:
- 业务程序直接连接 Canal Server
- 主动拉取数据
- 自己控制消费和确认逻辑
数据流
arduino
MySQL → Canal Server → instance → 单一消费者优点
- 简单直接
- 灵活可控
- 便于理解底层消费流程
缺点
- 客户端自己承担消费与异常处理
- 扩展性不如 MQ 模式
6.2 MQ 模式
Canal 也支持把数据投递到消息中间件,例如:
- Kafka
- RocketMQ
- RabbitMQ
数据流
arduino
MySQL → Canal Server → instance → MQ → 单一/多个消费者优点
- 解耦更强
- 多消费方更方便
- 更适合大规模场景
缺点
- 架构更复杂
- 运维成本更高
6.3 模式对比
| 模式 | 数据流 | 优点 | 适用场景 |
|---|---|---|---|
| TCP | Canal → Client | 简单、灵活、直观 | 学习、轻量项目、单消费方 |
| MQ | Canal → MQ → Consumer | 扩展性强、解耦好 | 大规模、多个消费方 |
七、Canal 常用 API
7.1 核心类
| 类 | 作用 |
|---|---|
CanalConnector |
核心连接器 |
CanalConnectors |
Connector 工厂类 |
Message |
一批数据 |
Entry |
单条变更 |
RowChange |
行变更对象 |
RowData |
before / after 数据 |
Column |
字段对象 |
7.2 核心 API 说明
1)connect()
ini
connector.connect();作用:建立客户端与 Canal Server 的连接
2)subscribe()
arduino
connector.subscribe("db\.table");作用:订阅指定的库表规则
示例:
arduino
connector.subscribe(".*\..*");表示订阅所有库表。
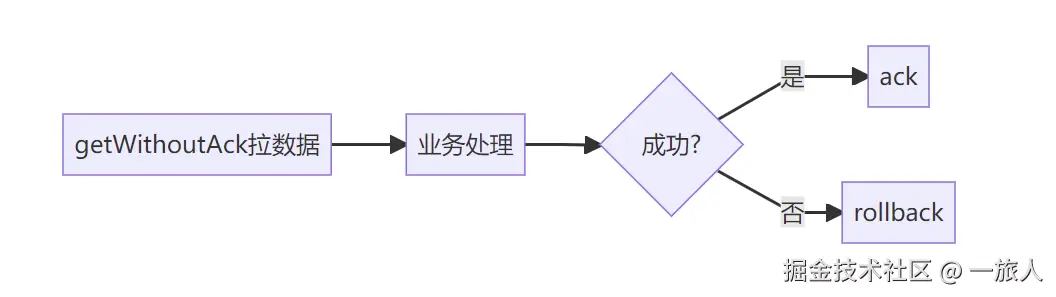
3)getWithoutAck()
ini
Message message = connector.getWithoutAck(100);作用:拉取一批数据,但不自动确认
这里的"100"表示每次最多拉取 100 条。
4)ack()
ini
connector.ack(batchId);作用:确认这一批数据已经成功处理
一旦 ack,消费位点就会往前推进。
5)rollback()
ini
connector.rollback(batchId);作用:表示这一批处理失败,需要重新消费
如果 rollback,这批消息后续还会再次被拉取。
6)disconnect()
ini
connector.disconnect();作用:断开连接
7.3 消费模型图
八、如何搭建 Canal
8.1 MySQL 配置
MySQL 需要开启 binlog,并使用 ROW 模式。
补充说明:在 MySQL 8 中,binary logging 默认已开启且默认是 ROW;显式写出配置依然是推荐做法,便于跨环境统一。
ini
[mysqld]
log-bin=mysql-bin
binlog-format=ROW
server_id=18.2 创建 Canal 账号
sql
create user 'canal'@'%' identified by 'canal';
grant SELECT, REPLICATION SLAVE, REPLICATION CLIENT on *.* to 'canal'@'%';
flush privileges;8.3 配置 Instance
核心配置示例:
ini
canal.instance.master.address=127.0.0.1:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.filter.regex=.*\..*如果只想监听某张表,也可以配置更精确的正则。
8.4 启动 Canal
一般就是启动 deployer:
startup.shWindows 下对应 startup.bat。
可以直接把这一段替换成下面这个"合并精简版":
九、TCP 模式代码示例
9.1 一个可运行的消费示例(拉取 + 解析 + ack/rollback)
java
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import java.net.InetSocketAddress;
import java.util.List;
public class CanalTcpConsumer {
private final CanalConnector connector = CanalConnectors.newSingleConnector(
new InetSocketAddress("127.0.0.1", 11111), "example", "", "");
public void start() throws Exception {
connector.connect();
connector.subscribe(".*\\..*"); // 订阅全部库表
connector.rollback(); // 从未 ack 位点开始消费
try {
while (true) {
Message msg = connector.getWithoutAck(100); // 每批最多 100 条
long batchId = msg.getId();
if (batchId == -1 || msg.getEntries().isEmpty()) {
Thread.sleep(1000); // 无数据时短暂休眠,避免空转
continue;
}
try {
consume(msg.getEntries()); // 业务处理
connector.ack(batchId); // 成功:推进位点
} catch (Exception e) {
connector.rollback(batchId); // 失败:回滚该批次,后续重试
}
}
} finally {
connector.disconnect();
}
}
private void consume(List<Entry> entries) throws Exception {
for (Entry entry : entries) {
// 忽略事务边界消息,只处理行变更
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN
|| entry.getEntryType() == EntryType.TRANSACTIONEND) continue;
RowChange change = RowChange.parseFrom(entry.getStoreValue());
EventType type = change.getEventType();
for (RowData row : change.getRowDatasList()) {
List<Column> before = row.getBeforeColumnsList();
List<Column> after = row.getAfterColumnsList();
switch (type) {
case INSERT -> printColumns("INSERT after", after);
case UPDATE -> {
printColumns("UPDATE before", before);
printColumns("UPDATE after", after);
}
case DELETE -> printColumns("DELETE before", before);
default -> { /* 忽略其他事件 */ }
}
}
}
}
private void printColumns(String tag, List<Column> cols) {
System.out.println("---- " + tag + " ----");
cols.forEach(c -> System.out.println(c.getName() + "=" + c.getValue()));
}
}9.2 关键点速记
getWithoutAck:拉取数据但不自动确认ack(batchId):处理成功后确认,位点前进rollback(batchId):处理失败回滚,后续会重拉- 行数据读取规则:
INSERT看afterColumnsUPDATE看beforeColumns + afterColumnsDELETE看beforeColumns
十、一条 SQL 是如何流转的
假设有一条 SQL:
sql
UPDATE product
SET price = 4999,
stock = 20
WHERE id = 1;它的处理链路如下:
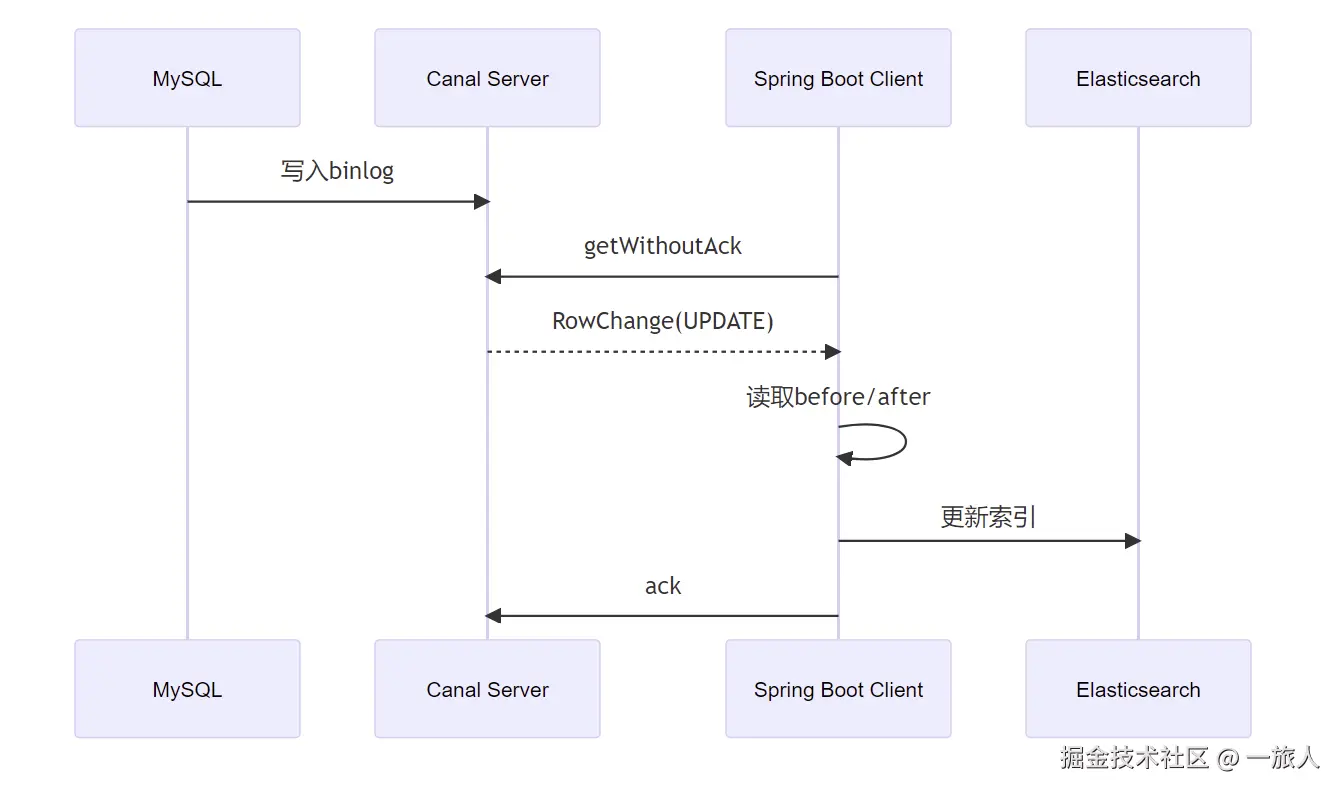
十一、ack 与 rollback 的核心理解
11.1 行为对比
| 操作 | 含义 | 结果 |
|---|---|---|
ack(batchId) |
这批处理成功 | 位点前进,不再重复消费 |
rollback(batchId) |
这批处理失败 | 位点回退,后续重新消费 |
11.2 顺序消费模型
css
A → B → C如果 A 失败,那么:
- B 、C不会继续推进
这点非常重要。Canal 的消费是顺序位点推进,不是随便跳过某一批继续往后。
十二、使用 Canal 时的注意事项
12.1 顺序消费
Canal 本质上是顺序消费模型,所以:
- 前面失败,后面会卡住
- 不适合"随便跳过失败消息"的思路
12.2 毒数据问题
最典型的风险就是:
一条数据一直失败,导致整条链路被卡死
表现通常是:
- 不断重试
- 延迟不断变大
- 后续消息无法推进
常见解决思路:
| 问题 | 处理方式 |
|---|---|
| 单条数据一直失败 | 设置重试上限 |
| 重试后仍失败 | 异常落库 |
| 需要后续修复 | 人工补偿 / 手工回放 |
12.3 幂等问题
因为 rollback 后会重复消费,所以业务处理必须考虑幂等:
- 重复执行不会造成错误结果
- 重复更新 ES 不会出脏数据
- 重复刷新缓存不会造成不可恢复的问题
12.4 数据一致性问题
Canal 适合的是:
- 准实时
- 最终一致
它并不天然保证强一致。 所以一般都需要配套:
- 补偿任务
- 回放能力
- 数据校验
12.5 真正难的不是接入,而是治理
这部分往往最容易被低估。
Canal 最开始接起来很快,甚至打印几条日志就能看到效果。 但真正进入项目后,复杂度往往来自这些地方:
- 哪些字段需要同步
- 哪些更新应该忽略
- 失败后怎么补偿
- 一条异常数据如何隔离
- 整条链路怎么监控和告警
当然可以,这里给你一个更有"作者感"和温度的结尾版本,你可以直接替换:
十三、总结
13.1 总览
| 维度 | 结论 |
|---|---|
| Canal 是什么 | 基于 MySQL binlog 的增量订阅与消费组件 |
| 核心原理 | MySQL 主从复制机制 + 日志解析 |
| 核心数据源 | binlog |
| 常见模式 | TCP / MQ |
| TCP 特点 | 简单、灵活、客户端主动拉取 |
| 关键 API | connect / subscribe / getWithoutAck / ack / rollback |
| 最大优点 | 低侵入、准实时、解耦 |
| 主要难点 | 幂等、异常、补偿、毒数据治理 |
13.2 关键认识
| 认识 | 说明 |
|---|---|
| Canal 不难理解 | 前提是理解 binlog 和主从同步 |
| Canal 不是监听 SQL | 它监听的是 binlog |
| Canal 不是最终答案 | 它只是把数据变化拿出来 |
| 真正难的是业务落地 | 怎么处理、怎么补偿、怎么兜底 |
13.3 我自己的一点体会
写这篇过程中,我越来越确定一件事:
Canal 解决的是"把变化拿出来",而工程要解决的是"把变化处理好"。
真正到线上之后,大家面对的往往不是"连不上 Canal",而是这些更现实的问题:
- 某条消息反复失败,整条链路怎么不被拖垮?
- 同一批数据重复消费,业务如何保证结果不乱?
- 下游系统短暂不可用时,如何补偿、如何回放?
- 问题发生后,怎么快速定位是采集、消费还是业务处理阶段出了问题?
这些问题没有一个能靠"会调 API"彻底解决,它们依赖的是完整的工程设计:
幂等策略、失败隔离、补偿机制、监控告警和可观测性。
所以,如果只把 Canal 当成"同步工具",它的价值会被低估;
把它放进一条可治理的数据链路里,它才会真正成为基础设施能力。