最近我正在学习 MySQL 的面试相关八股,打算单独开一个 MySQL 专栏来记录自己每天的学习,内容主要来自小林coding和 JavaGuide。今天了解到了 MySQL 的架构和执行流程,没想到一条简单的 sql 语句居然在 MySQL 中经历了这么多的流程。
二、MySQL 执行流程
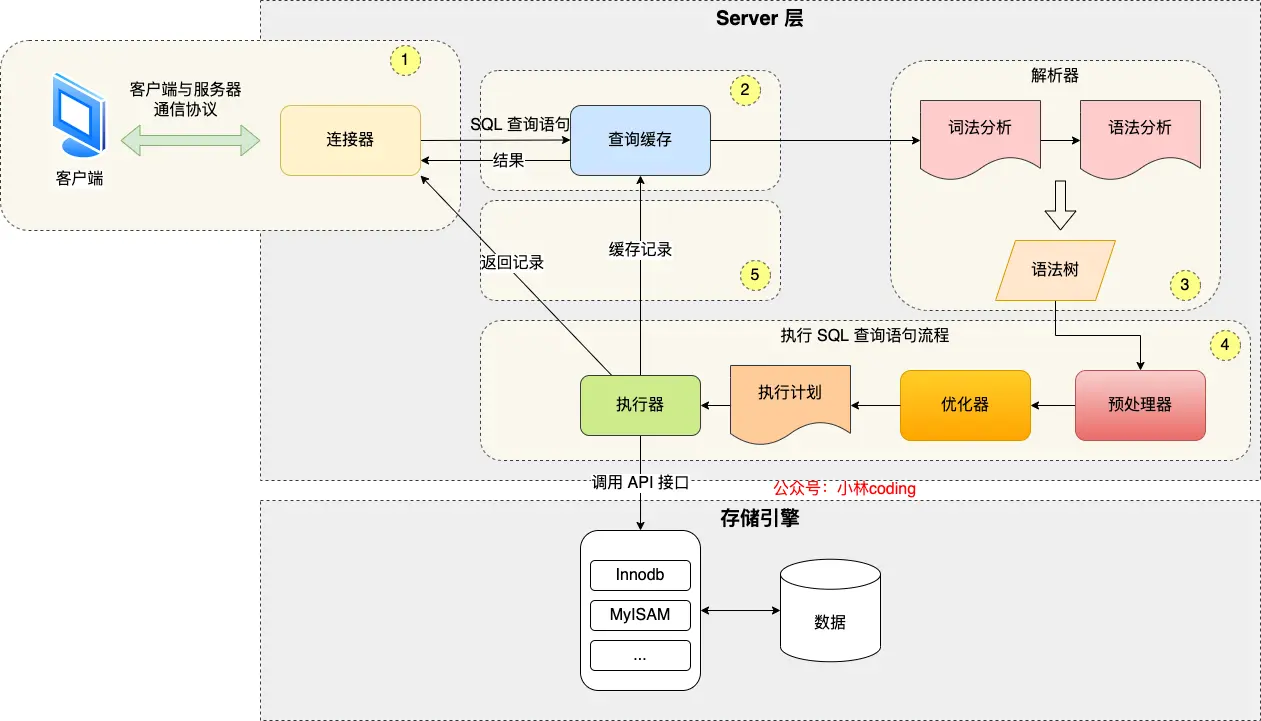
MySQL 执行流程大概分为服务层和存储引擎层两部分,服务层中主要涉及到建立连接、查询缓存、SQL语句解析、预处理、优化、执行几个阶段,存储引擎层则是把执行结果拿到的数据返回。
1.服务层
(1)连接器
连接器这一环主要是让客户端(如 Java 程序、TablePlus等)基于 TCP 连接到 MySQL 的服务端。第一步肯定是先启动 MySQL 服务,然后基于 TCP 协议完成三次握手,连接层要做的事情第一个就是校验你的用户名和密码是否正确,只有你输入正确时,才会建立连接,同时记录你这个账号的权限,并在此后该连接的过程中都会基于刚连接时保存的权限一直执行该权限的逻辑。
在 MySQL 中也有长连接和短连接的概念,所谓的短连接就是每建立一次 MySQL 客户端连接,只能执行一条 SQL 语句,然后就立马断开连接。而长连接就是一次客户端连接中可以执行多条 SQL 语句。
长连接与短连接的性能差异极大,在 MySQL 中频繁地创建销毁连接都是极其消耗资源的,原因主要出在了巨大的"握手"开销上,如网络层面的 TCP 三次握手、MySQL 协议握手、TLS/SSL握手以及每次创建连接 MySQL 都要去系统表查询用户权限并加载到内存中。
与此同时 MySQL 的连接与内存是密切相关的。默认情况下,连接器每建立一次新的连接,MySQL 都会对应创建一个新的工作线程,即便这个线程是 Sleep 状态,也会占用相应的内存。为避免大量线程创建导致内存溢出以及 CPU 频繁切换线程,MySQL 还提供了线程池功能,让少量线程服务于大量连接,进而减小内存损耗。
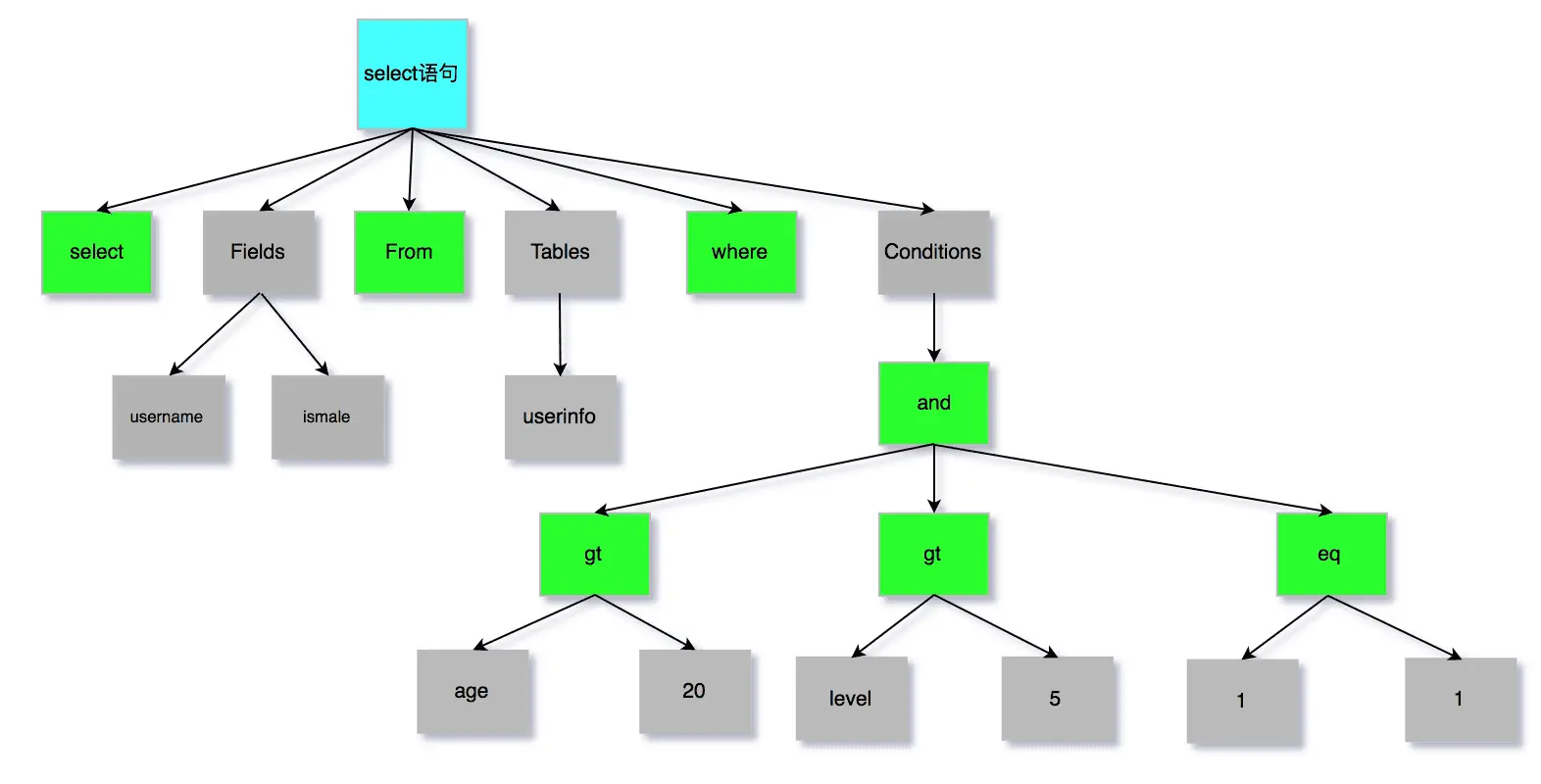
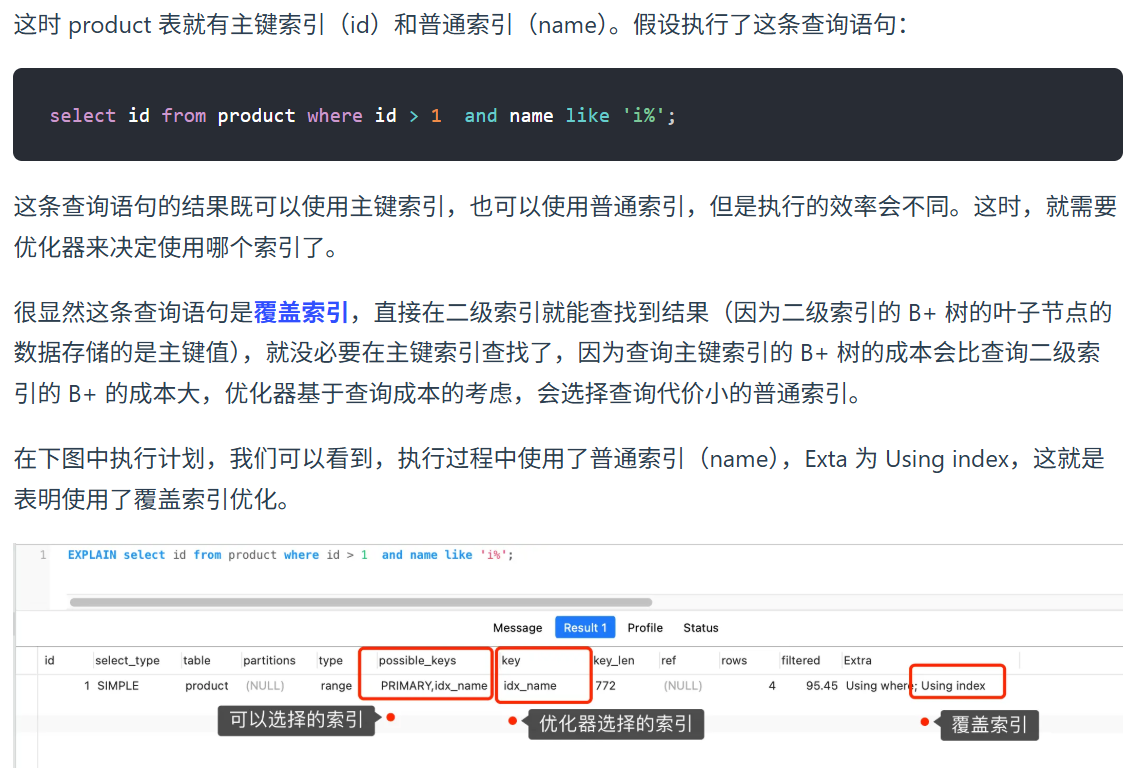
查询语句:SELECT id FROM product WHERE id > 1 AND name LIKE 'i%';
查询需要的字段 :id(在 SELECT 里)和 name(在 WHERE 里)。
二级索引 name 的内容 :它本身是按 name 排序的,且它的叶子节点里存的就是 id。
结论 :这个 name 索引已经包含了你查询所需要的全部信息(name 和 id)。
此时:
MySQL 引擎只需要扫描 name 这棵 B+ 树,就能过滤出满足 i% 条件的记录,并且直接从这棵树里把 id 拿出来返回。它根本不需要去翻主键索引那棵树。 这就叫"覆盖索引"。
复习了上述概念我们也就能明白为什么优化器最后帮我们决定使用普通索引,做覆盖索引优化。而不是说直接查主键索引。一来是主键索引的叶子节点存储的信息过多,查询主键索引导致的磁盘 I/O 也就更多,自然更耗时间,相较之下二级索引的叶子节点里面只存了主键和索引字段。另一个原因就是我们查的是主键ID,它已经存在于二级索引的叶子节点了,因此没必要回表,节省了大笔开销。
常见指令:
sql复制代码
explain + 查询 SQL 语句 // 输出这条 SQL 语句的执行计划
(6)执行器
开始执行 SQL。
权限校验:在执行前,再次确认用户对该表是否有执行权限。
调用接口:根据优化器生成的执行计划,循环调用存储引擎提供的 API 接口。
索引下堆:索引下堆是一种查询优化策略,它能够减少二级索引查询过程中的回表操作,其本质在于把应该由 Server 层做的判断交给了存储引擎层。在小林coding中案例如下:
使用索引下堆前后的关键我用红线标注了起来,主要就是 reward 是否等于 1000000 这个判断由 Server 层转交给了存储引擎层,它的好处在于不用为了让 Server 层判断这一条件而特意回表,可以看到如果该条件不成立完全可以在存储引擎层就直接跳过该二级索引,进而节省了一部分的回表操作开销。