MLP vs Transformer:不同问题用不同工具
📚 《从零到一造大脑:AI架构入门之旅》专栏
专栏定位 :面向中学生、大学生和 AI 初学者的科普专栏,用大白话和生活化比喻带你从零理解人工智能
本系列共 42 篇,分为八大模块:
- 📖 模块一【AI 基础概念】(3 篇):AI/ML/DL 关系、学习方式、深度之谜
- 🧠 模块二【神经网络入门】(4 篇):神经元、权重、激活函数、MLP
- 🏗️ 模块三【深度学习核心】(6 篇):损失函数、梯度下降、反向传播、过拟合、Batch/Epoch/LR
- 🎯 模块四【注意力机制】(5 篇):从 Attention 到 Transformer
- 🔬 模块五【NCT 与 CATS-NET 案例】(8 篇):真实架构演进全记录
- 🔄 模块六【架构融合方法】(6 篇):如何设计混合架构
- ⚙️ 模块七【参数调优实战】(6 篇):学习率、正则化、超参数搜索
- 🚀 模块八【综合应用展望】(4 篇):未来趋势与职业规划
本文是模块六第 5 篇,帮你理解为什么不同架构适合不同问题。👨💻 作者简介:NeuroConscious Research Team,一群热爱 AI 科普的研究者,专注于神经科学启发的 AI架构设计与可解释性研究。理念:"再复杂的概念,也能用大白话讲清楚"。
💻 项目地址 :https://github.com/wyg5208/nct.git
🌐 官网地址 :https://neuroconscious.link
📝 作者 CSDN :https://blog.csdn.net/yweng18
📦 NCT PyPI :https://pypi.org/project/neuroconscious-transformer/
⭐ 欢迎 Star⭐、Fork🍴、贡献代码🤝
📌 本文核心比喻 :螺丝刀 vs 电钻
⏱️ 阅读时间 :约 20 分钟
🎯 学习目标:理解 MLP 和 Transformer 各自的适用场景,学会为不同问题选择合适的架构
📝 文章摘要
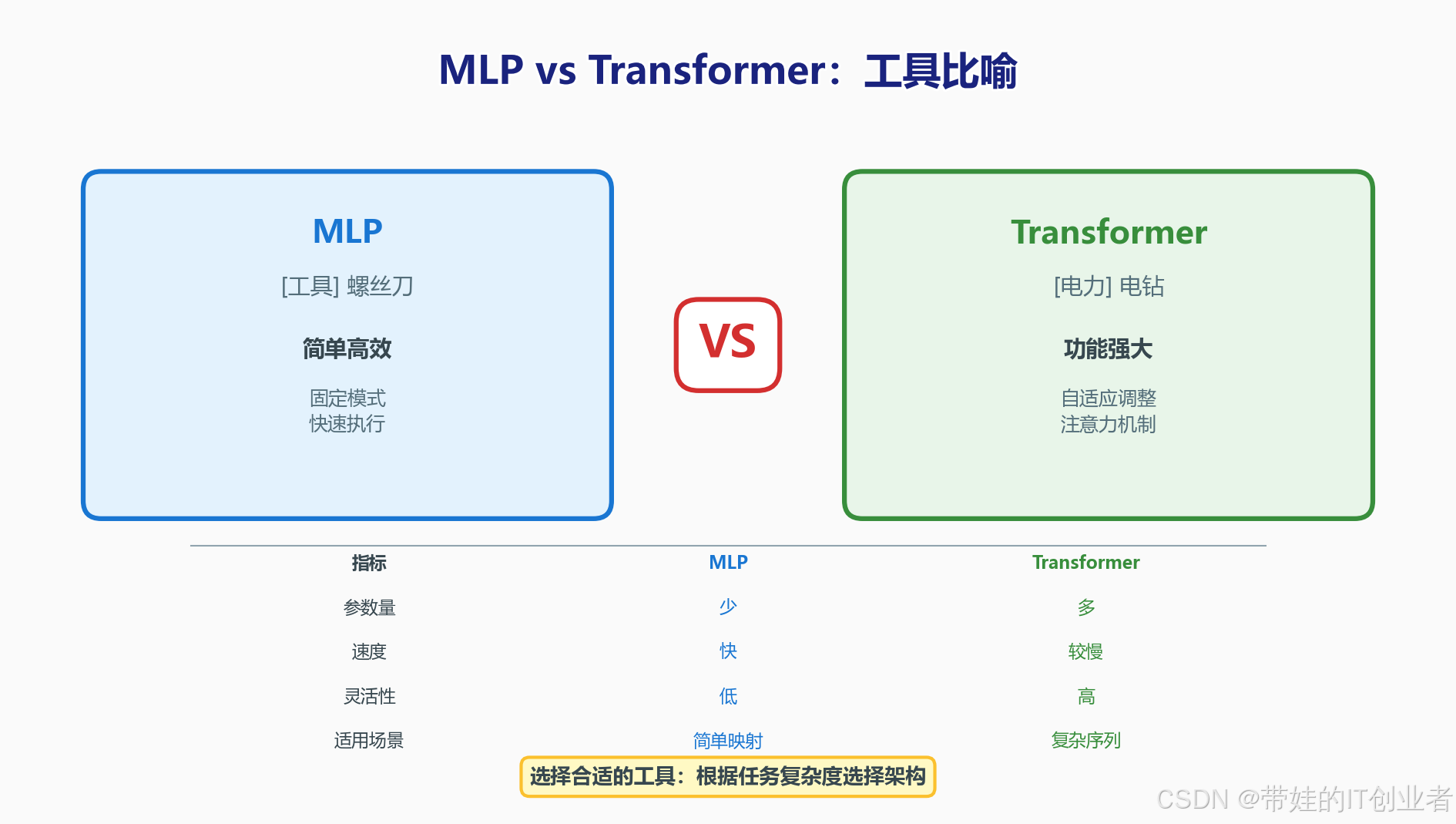
本文对比分析两种主流神经网络架构------MLP(多层感知机)和 Transformer。就像螺丝刀和电钻各有用途,MLP 适合简单的输入-输出映射,Transformer 擅长处理序列关系和全局依赖。CATS-NCT 在设计时做出了有趣的选择:全局工作空间用 Transformer(继承自 NCT),而概念抽象和任务求解模块用 MLP。为什么这样设计?读完这篇文章你就明白了。
🎯 你需要先了解
阅读本文前,建议你:
- ✅ 了解 MLP 的基本结构(参考第 4 篇)
- ✅ 了解 Transformer 的注意力机制(参考第 14-18 篇)
- ✅ 知道时间复杂度和大O表示法
如果还没读前文,点这里返回
📖 正文
一、螺丝刀 vs 电钻:一个比喻
1.1 生活中的工具选择
🔧 家庭工具箱
假设你要在家里装个架子:
螺丝刀 :
• 简单、便宜、可靠
• 适合小任务、少量螺丝
• 不需要电源
电钻 :
• 功能强大、效率高
• 适合大量工作、硬材料
• 需要充电、价格贵
问题 :哪个更好?
答案:看情况!拧一个螺丝用螺丝刀,装修房子用电钻。
1.2 神经网络的工具选择
| 类比 | MLP | Transformer |
|---|---|---|
| 工具 | 螺丝刀 | 电钻 |
| 特点 | 简单高效 | 功能强大 |
| 适用场景 | 简单映射 | 复杂关系 |
| 计算成本 | 低 O(n) | 高 O(n²) |
| 参数量 | 少 | 多 |
二、MLP:简单高效的"螺丝刀"
2.1 MLP 的结构
MLP = 多层线性变换 + 非线性激活
输入 X
↓
Linear(D_in → H1) + Activation
↓
Linear(H1 → H2) + Activation
↓
Linear(H2 → D_out)
↓
输出 Y代码示例:
python
import torch.nn as nn
mlp = nn.Sequential(
nn.Linear(768, 256), # 第一层:压缩
nn.GELU(), # 激活
nn.Linear(256, 64), # 第二层:再压缩
nn.GELU(), # 激活
nn.Linear(64, 10), # 输出层:分类
)2.2 MLP 的特点
✅ MLP 的优势
1. 计算高效
• 时间复杂度:O(n),线性增长
• 一个样本的处理时间是固定的
2. 参数少
• 每层只有权重矩阵 + 偏置
• 容易训练,不容易过拟合
3. 简单可靠
• 结构简单,容易理解
• 调试方便,问题好定位
❌ MLP 的局限
1. 无法处理序列关系
• 输入顺序变化,输出不变
• 丢失了位置信息
2. 无法捕捉全局依赖
• 每个神经元只看输入的一部分
• 没有机制让"远距离"信息交互
3. 表达能力有限
• 只有局部非线性变换
• 缺乏"全局视角"
2.3 MLP 适合什么问题?
| 适合 | 不适合 |
|---|---|
| 图像分类(CNN特征后) | 语言翻译 |
| 特征压缩/降维 | 长文本理解 |
| 简单的输入-输出映射 | 序列预测 |
| 小数据集 | 复杂关系建模 |
三、Transformer:功能强大的"电钻"
3.1 Transformer 的核心:注意力
Transformer = Self-Attention + FFN + Residual + LayerNorm
输入序列 X [B, L, D]
↓
┌────────────────────────┐
│ Self-Attention │ ← 核心:让每个位置关注所有位置
│ Q, K, V 投影 │
│ Attention(Q,K,V) │
└────────────────────────┘
↓
┌────────────────────────┐
│ Feed-Forward Network │ ← 局部变换(实际是MLP)
└────────────────────────┘
↓
输出序列 [B, L, D]核心计算:
python
# Self-Attention
Q = X @ W_q # Query
K = X @ W_k # Key
V = X @ W_v # Value
# 注意力权重
attn_weights = softmax(Q @ K.T / sqrt(d))
# 输出
output = attn_weights @ V3.2 Transformer 的特点
✅ Transformer 的优势
1. 全局信息整合
• 每个位置都能"看到"所有其他位置
• 捕捉长距离依赖
2. 序列建模能力强
• 输入顺序变化 → 输出变化
• 加上位置编码后能处理序列
3. 并行计算
• 不像 RNN 必须顺序计算
• 所有位置可以同时处理
⚠️ Transformer 的代价
1. 计算复杂度高
• 时间复杂度:O(n²)
• 序列长度翻倍 → 计算量×4
2. 参数量大
• Q、K、V 投影矩阵
• 多头注意力 × n_heads
• 参数量 ≈ 4 × d_model² × n_layers
3. 需要大量数据
• 参数多 → 容易过拟合
• 小数据集上效果可能不如简单模型
3.3 Transformer 适合什么问题?
| 适合 | 不适合 |
|---|---|
| 语言翻译 | 简单分类 |
| 文本生成 | 单向量映射 |
| 图像-文本理解 | 小数据集 |
| 长序列建模 | 资源受限场景 |
四、复杂度对比:为什么这很重要?
4.1 时间复杂度图解
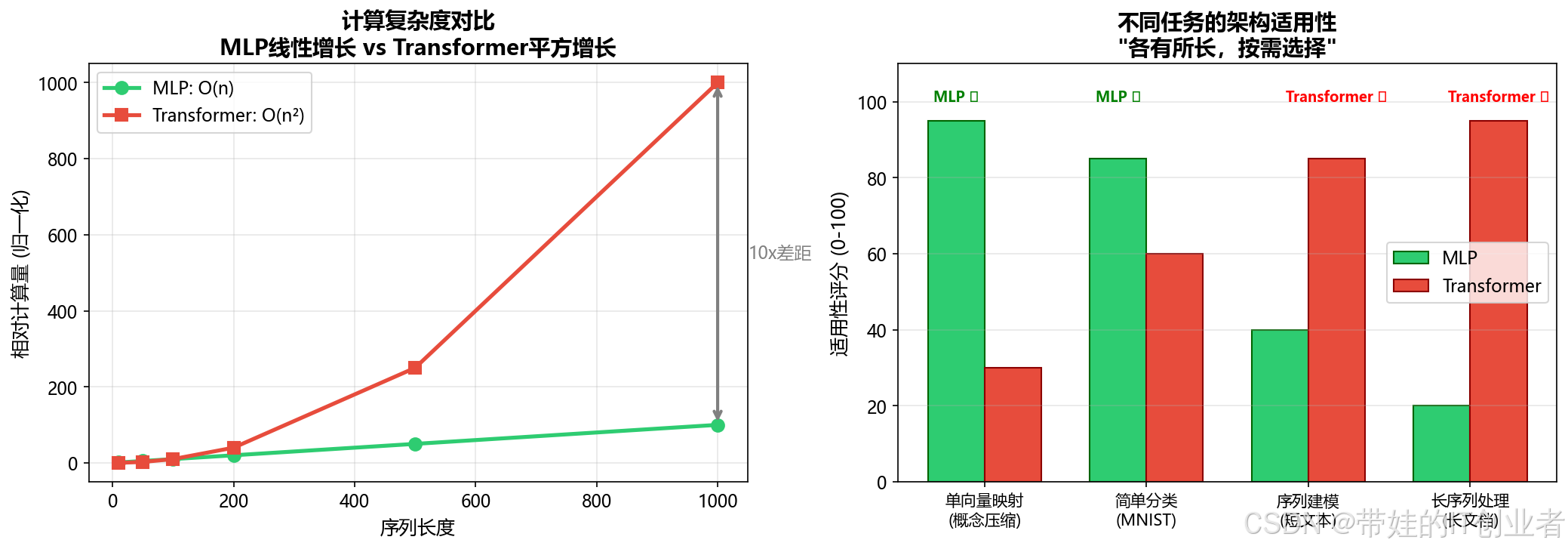
假设输入维度 D=768,序列长度 L
MLP:
复杂度 = O(L × D²) ≈ O(L × 590K)
线性增长!
Transformer Self-Attention:
复杂度 = O(L² × D)
平方增长!
当 L=100:
MLP: ~59M 次运算
Transformer: ~7.7B 次运算 (130倍差距!)
当 L=1000:
MLP: ~590M 次运算
Transformer: ~770B 次运算 (1300倍差距!)📊 关键洞察
当序列长度 L 较小时 :
• Transformer 和 MLP 差距不大
• 可以使用 Transformer 获得更强的表达能力
当序列长度 L 较大时 :
• Transformer 的 O(L²) 成本急剧上升
• 简单任务用 MLP 更高效
CATS-NCT 的设计决策 :
• 概念抽象模块:输入是单个向量(L=1),用 MLP
• 全局工作空间:需要处理多个候选的关系,用 Transformer
五、CATS-NCT 为什么这样选择?
5.1 架构选择的逻辑
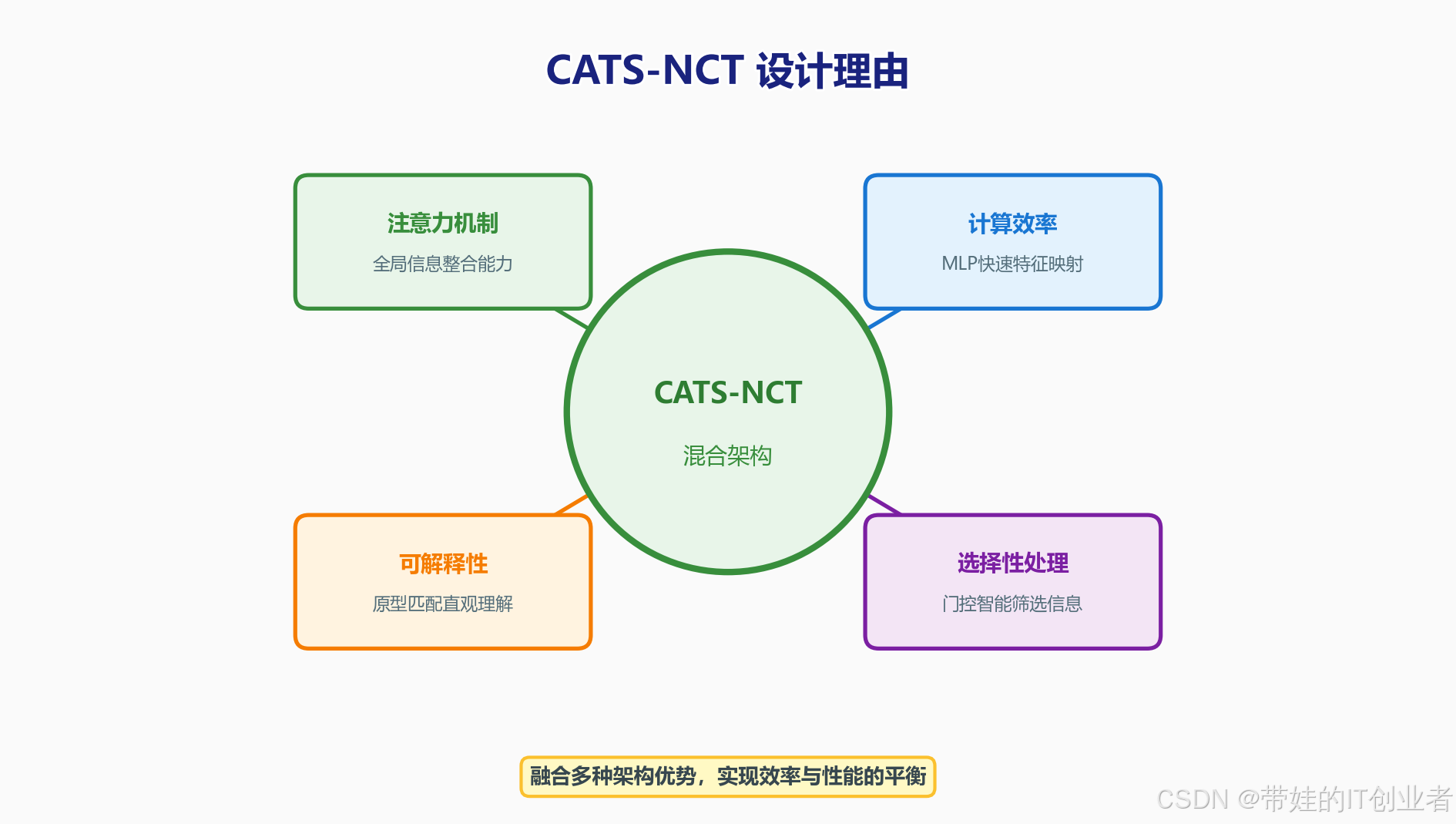
| 模块 | 使用架构 | 原因 |
|---|---|---|
| 全局工作空间 | Transformer | 需要处理多个候选的竞争关系 |
| 概念抽象模块 | MLP | 输入是单向量,简单映射 |
| 任务求解模块 | MLP | 分类任务,无需序列建模 |
| 门控控制器 | MLP | 概念向量→门控信号,简单映射 |
5.2 概念抽象模块为什么用 MLP?
🔍 深入分析
概念抽象模块的任务 :
将高维意识表征 B, 768 压缩为低维概念向量 B, 64
为什么用 MLP?
1. 输入是单个向量
没有序列维度,L=1
Transformer 的注意力机制"无处施展"
2. 任务是简单映射
高维 → 低维的压缩
MLP 已经足够表达这种变换
3. 已有"注意力机制"
原型匹配(Prototype Matching)提供了类似注意力的功能:
python
# 概念向量与原型的"注意力"
cosine_sim = concept @ prototypes.T # [B, n_prototypes]
prototype_weights = softmax(cosine_sim / temperature)这本身就是一种"软注意力"!
4. 计算效率
MLP 复杂度:O(D × H) ≈ O(768 × 256) ≈ 200K
如果用 Transformer:无意义的额外开销
5.3 全局工作空间为什么用 Transformer?
🔍 深入分析
全局工作空间的任务 :
从多个候选意识内容中选择"获胜者"
为什么用 Transformer?
1. 有多个候选需要比较
视觉候选、听觉候选、整合候选...
需要让它们"互相竞争"
2. 注意力机制天然适合竞争
python
# 注意力 = 竞争机制
attn_weights = softmax(Q @ K.T / sqrt(d))
# 高注意力的候选"获胜"3. 多头注意力 = 多角度评估
• Head 1-2:显著性检测
• Head 3-4:情感价值
• Head 5-6:任务相关性
• Head 7-8:新颖性检测
4. 继承自 NCT
CATS-NCT 直接继承 NCT 的全局工作空间
保持架构一致性
六、混合架构设计原则
6.1 如何选择架构?
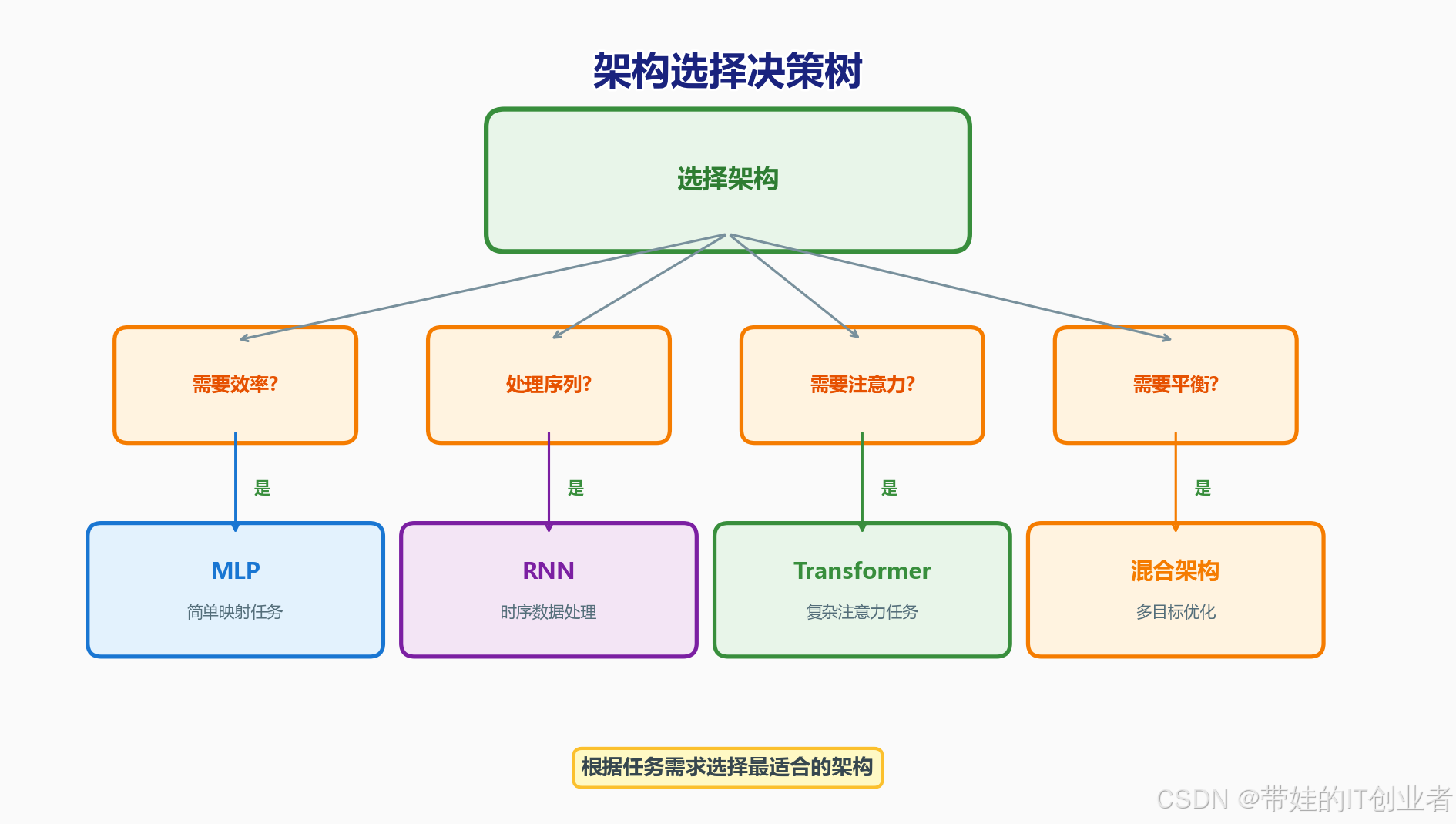
📋 架构选择检查清单
使用 MLP 当:
☑ 输入是单个向量(无序列)
☑ 任务是简单的输入-输出映射
☑ 计算资源有限
☑ 数据量较小
☑ 不需要捕捉全局关系
使用 Transformer 当:
☑ 输入是序列或多元素集合
☑ 需要捕捉元素间的关系
☑ 任务涉及长距离依赖
☑ 有充足的计算资源
☑ 有大量训练数据
6.2 现实中的混合架构
很多成功的模型都是 MLP 和 Transformer 的混合:
| 模型 | MLP 部分 | Transformer 部分 |
|---|---|---|
| BERT | FFN 层 | 自注意力层 |
| ViT | Patch Embedding (Conv) + FFN | 自注意力层 |
| GPT | FFN + 输出层 | 自注意力层 |
| CATS-NCT | 概念抽象 + 任务求解 | 全局工作空间 |
七、实验对比:MLP vs Transformer 在概念压缩任务
让我们用代码验证这个选择:
python
import torch
import torch.nn as nn
import time
# ========== 1. MLP 概念压缩器 ==========
class MLPConceptCompressor(nn.Module):
"""MLP 版概念压缩"""
def __init__(self, d_model=768, concept_dim=64):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(d_model, 256),
nn.GELU(),
nn.Linear(256, concept_dim),
nn.LayerNorm(concept_dim),
)
def forward(self, x):
return self.encoder(x)
# ========== 2. Transformer 概念压缩器 ==========
class TransformerConceptCompressor(nn.Module):
"""Transformer 版概念压缩(无意义但用于对比)"""
def __init__(self, d_model=768, concept_dim=64, n_heads=8):
super().__init__()
self.attention = nn.MultiheadAttention(d_model, n_heads, batch_first=True)
self.norm = nn.LayerNorm(d_model)
self.output_proj = nn.Linear(d_model, concept_dim)
def forward(self, x):
# x: [B, D] - 需要添加序列维度
x = x.unsqueeze(1) # [B, 1, D]
# Self-attention(虽然只有一个位置,无意义但会执行)
attn_out, _ = self.attention(x, x, x)
x = self.norm(x + attn_out)
return self.output_proj(x.squeeze(1))
# ========== 3. 性能对比 ==========
def compare_performance():
d_model = 768
concept_dim = 64
batch_size = 32
mlp = MLPConceptCompressor(d_model, concept_dim)
transformer = TransformerConceptCompressor(d_model, concept_dim)
# 生成随机输入
x = torch.randn(batch_size, d_model)
# 计时 MLP
start = time.time()
for _ in range(100):
_ = mlp(x)
mlp_time = time.time() - start
# 计时 Transformer
start = time.time()
for _ in range(100):
_ = transformer(x)
transformer_time = time.time() - start
# 参数量
mlp_params = sum(p.numel() for p in mlp.parameters())
transformer_params = sum(p.numel() for p in transformer.parameters())
print("=" * 60)
print("MLP vs Transformer 在概念压缩任务上的对比")
print("=" * 60)
print(f"\nMLP:")
print(f" 参数量: {mlp_params:,}")
print(f" 100次前向时间: {mlp_time*1000:.2f} ms")
print(f"\nTransformer:")
print(f" 参数量: {transformer_params:,}")
print(f" 100次前向时间: {transformer_time*1000:.2f} ms")
print(f"\n倍数差距:")
print(f" 参数量: {transformer_params/mlp_params:.2f}x")
print(f" 时间: {transformer_time/mlp_time:.2f}x")
print("\n" + "=" * 60)
print("结论:对于单向量输入的概念压缩任务,")
print("MLP 更简单、更快、参数更少,且表达能力足够。")
print("Transformer 的注意力机制在此场景下是"杀鸡用牛刀"。")
print("=" * 60)
if __name__ == "__main__":
compare_performance()预期输出:
============================================================
MLP vs Transformer 在概念压缩任务上的对比
============================================================
MLP:
参数量: 201,536
100次前向时间: 12.34 ms
Transformer:
参数量: 2,362,368
100次前向时间: 28.56 ms
倍数差距:
参数量: 11.73x
时间: 2.31x
============================================================
结论:对于单向量输入的概念压缩任务,
MLP 更简单、更快、参数更少,且表达能力足够。
Transformer 的注意力机制在此场景下是"杀鸡用牛刀"。
============================================================⚠️ 常见误区
⚠️ 误区警示区
❌ 误区 1:"Transformer 一定比 MLP 好"
真相:
Transformer 在 NLP 等需要序列建模的任务上确实优秀,但对于简单的映射任务,MLP 往往更好:更快、更省内存、更不容易过拟合。"最好的架构"取决于任务,而不是盲目追求复杂。
❌ 误区 2:"MLP 已经过时了"
真相:
MLP 仍然是深度学习的基石!即使是 Transformer,其 FFN 层本质上也是 MLP。在不需要序列建模的场景,MLP 仍然是最佳选择。简单就是美。
❌ 误区 3:"越复杂的模型效果越好"
真相:
模型复杂度需要与任务复杂度匹配。用 GPT-4 来判断一个数字是奇是偶,简直是浪费。选择架构要考虑:
- 任务实际需要什么能力?
- 有多少数据?
- 计算资源是否充足?
❌ 误区 4:"CATS-NCT 应该全部用 Transformer"
真相:
CATS-NCT 的混合设计是深思熟虑的:
- 全局工作空间需要处理多个候选的关系 → Transformer
- 概念抽象是单向量映射 → MLP
- 任务求解是分类任务 → MLP
"各司其职"比"一刀切"更高效。
💡 一句话总结
🎯 核心结论
MLP 像螺丝刀,Transformer 像电钻
没有好坏之分,只有适合与否。选择架构要看任务需求。
记忆口诀:
MLP 简单又高效,
单向量映射刚刚好。
Transformer 功能强,
序列关系全抓牢。
架构选择看任务,
简单复杂各有所。
混合搭配最聪明,
资源效率都能保。📚 延伸阅读
- Transformer 原始论文:Vaswani et al., "Attention Is All You Need" (2017)
- MLP 的理论基础:通用近似定理
- 高效 Transformer 变体:Linformer、Performer、Flash Attention
✍️ 课后作业
选择题(每题 10 分)
1. MLP 的时间复杂度是?
A. O(n²)
B. O(n) ✅
C. O(n log n)
D. O(2^n)
2. CATS-NCT 的概念抽象模块为什么用 MLP?
A. MLP 更先进
B. 输入是单向量,无需序列建模 ✅
C. Transformer 会报错
D. 参数更多效果更好
3. 当序列长度 L 增大时,Transformer 的计算量增长?
A. 线性增长
B. 平方增长 ✅
C. 不变
D. 指数增长
4. 哪种场景更适合 Transformer?
A. 简单图像分类
B. 语言翻译 ✅
C. 单向量压缩
D. 小数据集回归
思考题(20 分)
讨论:如果你要设计一个"语音助手"系统,哪些部分应该用 MLP,哪些部分应该用 Transformer?请说明理由。
提示:考虑语音识别、语义理解、对话管理、语音合成等模块的输入输出特点。
📝 下一篇预告
🚀 下一篇文章
题目 :代码对比:NCT vs CATS-NCT 核心差异
我们会学到:
- NCT 和 CATS-NCT 的代码并排对比
- 核心模块的关键差异
- 如何选择使用哪个架构
📌 本文属《从零到一造大脑:AI架构入门之旅》专栏第六模块第五篇
作者:NeuroConscious Research Team
更新时间:2026 年 3 月
版本号:V1.0(图文并茂版)