- 自 ChatGPT 发布以来,LLM 应用的工程形态经历了快速演进,其产品形态也逐步从以 Chat 为主扩展到更复杂的 Agent 系统 。本文对近年来 LLM 技术范式的关键演进节点进行梳理,可以将其抽象为如下路径: Prompt Engineering → RAG → Function Calling → MCP → Skill → Harness \text{Prompt Engineering → RAG → Function Calling → MCP → Skill → Harness} Prompt Engineering → RAG → Function Calling → MCP → Skill → Harness
- 在这一演进过程中,我个人认为 Skill 是一个非常关键的分水岭,利用它可以创建小而美的 LLM-based Agent 工作闭环 ,并且这一层已经开始沉淀出相对稳定的实践范式,因此具有较高的学习与工程价值
- 在 Skill 之前,各阶段的核心仍然是为模型能力打基础:通过不断探索与固化"如何指导 LLM 工作"的方法,提升模型的指令遵循能力与工具使用能力。这一时期整体仍停留在 "增强 Chat 能力" 的范式,即围绕单次任务不断优化输入与执行方式
- Skill 的引入带来了一个关键跃迁,即实现了 "Agent 工作指南" 的抽象。它将任务所需的流程、规则、工具使用方式与上下文组织方式封装为一个整体,使其可以被重复调用与复用。其本质是从 "单次任务优化" 转向 "可复用的工作方法 / 流程",可以视作 LLM-based Agent 走向工程化与规模化的标志
- Skill 之后,当下的研究热点是 Harness。这一阶段的重点不再是定义单个任务能力,而是提升 Agent 在复杂环境中的长任务稳健性与系统级运行能力,引入了基于文件的记忆管理、上下文管理、子任务拆解与委派、多组件协同与执行控制等技术要点,其目标是构建一个 "Agent 稳定工作框架"。不过,目前这一方向仍处于快速演进阶段,尚未形成统一且成熟的最佳实践
- 本文将对以上技术里程碑进行简要介绍,并对 Skill 展开讨论
文章目录
- [0. 概述](#0. 概述)
-
- [0.1 阶段一:能力增强(Prompt / RAG / Tool)](#0.1 阶段一:能力增强(Prompt / RAG / Tool))
- [0.2 阶段二:流程沉淀(Skill)](#0.2 阶段二:流程沉淀(Skill))
- [0.3 阶段三:系统编排(Harness)](#0.3 阶段三:系统编排(Harness))
- [0.4 小结](#0.4 小结)
- [2. Skill for LLM-based Agent](#2. Skill for LLM-based Agent)
0. 概述
- 回顾近两年 LLM 应用的发展,可以发现一个非常清晰的趋势:LLM 的能力提升固然重要,但真正推动应用形态变化的,是围绕 LLM 构建的工程范式演进。如果从工程视角来看,这一演进大致可以分为三个阶段: 能力增强 → 能力封装 → 系统编排 \text{能力增强 → 能力封装 → 系统编排} 能力增强 → 能力封装 → 系统编排 关键里程碑中,我把 Prompt Engineering、RAG、Function Calling、MCP 划为第一阶段,Skill 划为第二阶段,Harness 划为第三阶段,如下图所示
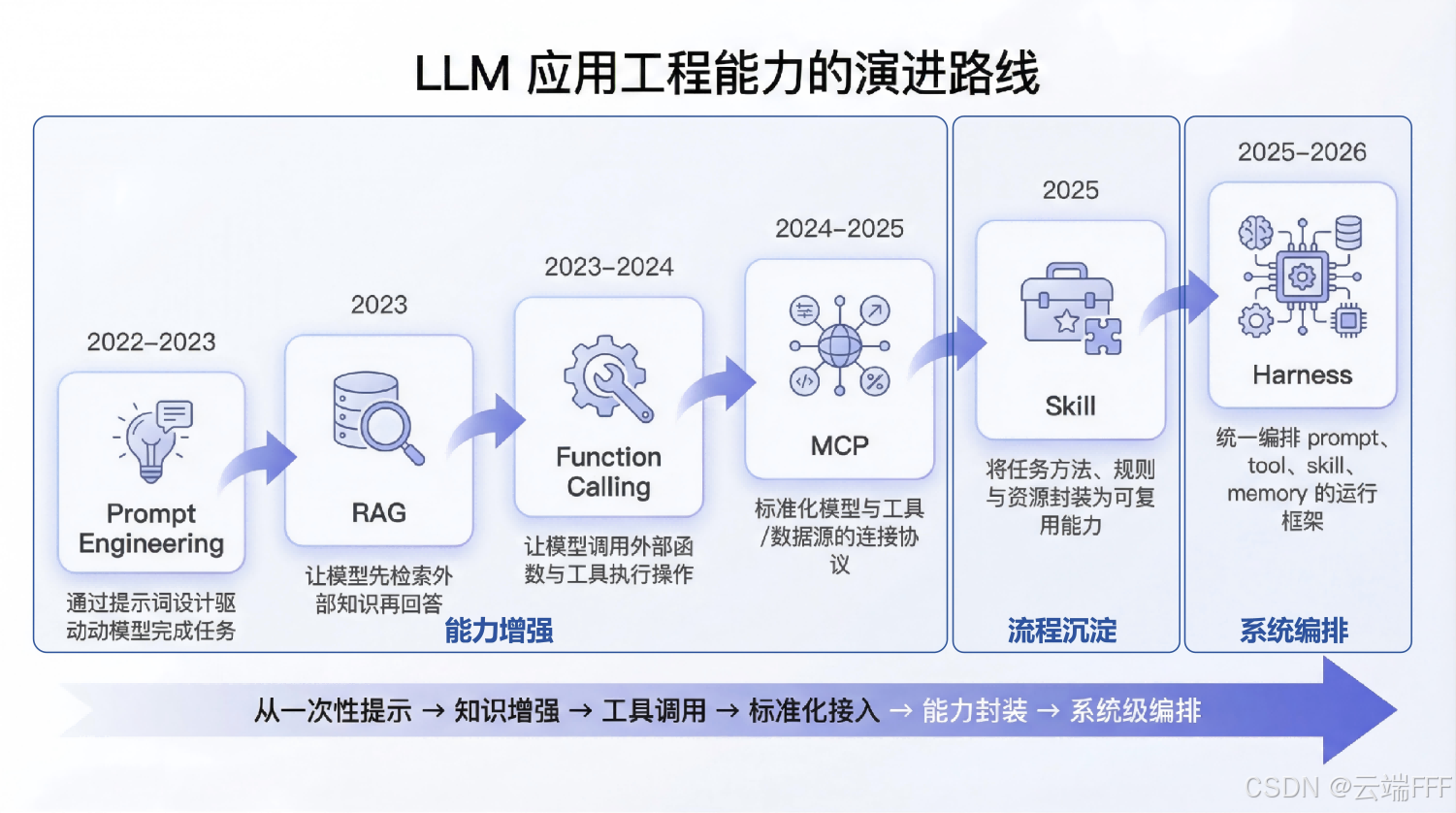
- 这条演进路线可以概括如下:
- Prompt Engineering 教会模型听懂需求
- RAG 教会模型先查资料
- Function Calling 教会模型调用工具
- MCP 让工具接入开始标准化
- Skill 把工作经验沉淀为可复用能力
- Harness 把以上所有能力真正组织成一个可持续运行的 Agent 系统
0.1 阶段一:能力增强(Prompt / RAG / Tool)
- 该阶段 LLM 应用的核心问题是 "如何让模型更好地完成一次任务" ,业界围绕该目标进行了如下进行探索:
- 提示工程,让模型更好地理解人类需求 :最早的时候,LLM 主要被当做 "超强文本接口" 来用:通过不断修改 system prompt、few-shot 示例和输出格式约束,尽量把任务描述清楚,让模型在一次对话里给出更稳定的结果。这一阶段的核心思想很直接------如果模型表现不好,那就继续改 prompt。提示工程直到今天依然重要,因为它决定了模型如何理解角色、目标和约束,但其局限也很明显:很多复杂能力并不能只靠几段提示词稳定获得,prompt 既难复用,也难维护,更难沉淀成团队级资产
- RAG,补充领域知识,减弱生成幻觉 :由于 LLM 上下文窗口有限,仅靠提示工程无法良好地引入私有知识。RAG 的目标就是在模型回答之前,先从文档库、知识库、产品手册、代码仓库等外部相关信息检索出来,再作为上下文喂给模型。这样一来,模型回答问题时不再只依赖参数记忆,而是能够结合最新、最相关的外部材料生成答案。RAG 极大提升了企业场景中的可用性,因为它把问题从"训练一个知道一切的模型"转换成"让模型在回答前先查资料"。RAG 主要解决的是 "知道什么" 的问题,而不是 "该怎么做"的问题:它擅长补知识,却不天然擅长执行复杂流程
- Function Calling / Tool Use,与外部能力交互 :这里的关键变化是模型不再只是生成文本,而是可以根据需要去调用外部函数或工具,例如搜索网页、查询数据库、执行代码、发送邮件、读取日历等。这一步非常关键,它第一次让模型具备了 "行动能力",LLM-based agent 的雏形也开始出现。不过,function calling 本质上仍然偏原子化:模型会不会调用工具、调用哪个工具、调用后如何衔接下一步,很多时候仍依赖开发者手工设计。也就是说,这一阶段解决的是 "模型可以做事了",但还没有彻底解决 "模型如何系统地完成一整类事"
- MCP,外部能力标准化 :Tool Using 带来了重要问题:如果每个平台、每个数据源、每个工具系统都要单独适配,那 Agent 工程会迅速碎片化。针对该问题,Anthropic 在 2024 年 11 月 25 日正式发布 MCP,将其定义为一种开放标准,用来把 AI 应用和外部数据源、工具、安全授权机制连接起来;官方文档也把它形容为 AI 应用的 "USB-C 接口"。MCP 的意义不在于"又多了一个工具",而在于它试图统一 "模型如何接入世界" 的方式:工具、资源、工作流不再需要针对每个 Agent 框架各写一套接入逻辑,而可以通过统一协议暴露出来
- 在这一阶段,所有方法都围绕 "增强单次调用能力" 展开,从本质上看,这一阶段仍然属于 Chat 范式的延伸与强化
- 每一次调用都是"临时构建"的
- 能力依赖当前上下文(prompt + retrieved context)
- 缺乏结构化的能力沉淀
0.2 阶段二:流程沉淀(Skill)
- 随着 MCP 和工具接入逐渐成熟,LLM 已经不再只是一个 "会聊天、会回答问题" 的模型,而开始具备调用外部资源和执行操作的能力
- 第二阶段 LLM 应用的核心问题是 "如何围绕模型基础能力和外部工具能力组织出一套可复用的工作流程" :
- Skill,把零散能力沉淀成可复用工作方法 :一个真正可用的 Agent,不仅要知道什么时候调用 Excel、什么时候读 PDF、什么时候执行脚本,还要知道某类任务通常应遵循什么流程、遵守哪些规则、参考哪些模板、输出成什么结构。在这种背景下,Anthropic 在 2025 年 10 月 16 日 正式发布 Agent Skills,把 Skill 描述为一种可由文件、文件夹、说明文档和执行逻辑组成的模块化能力,并在 2025 年明显走向主流。Skill 的关键变化在于:它不再只是给模型补一句说明、补一段知识,或者补一个可调用函数,而是把某一类任务所需的程序性知识、领域约束、参考模板、工具使用方法与输出规范一起封装起来,形成一个可以重复调用的工作单元
0.3 阶段三:系统编排(Harness)
- 随着 Skill 逐渐成熟,LLM-based agent 已可以通过组合复用 Skill 稳定完成各类多步任务,但在面对复杂任务时,一个 Agent 往往需要具备多轮推理、长程运行、多能力协同、状态记忆、动态决策等能力,仅仅依靠 Skill,已经不足以完成上下文管理、记忆管理、任务拆解与委派、多组件编排、执行控制等挑战。
- 第三阶段 LLM 应用的核心问题是 "如何让 Agent 在真实环境中稳定、长期、可控地工作" :
- Harness,围绕各种能力构造可持续运行的 Agent 系统:如果说 Skill 是 "能力模块",那么 Harness 更像是"Agent 的运行时系统或外部控制框架"。这个词在 2025--2026 年的 Agent 工程讨论里开始越来越常见。Anthropic 把 Agent SDK 直接称为一种 general-purpose agent harness,强调它负责上下文压缩、工具调用、计划执行和长时运行;LangChain 也把 harness 描述为连接 LLM 与其环境的那一层,其中包含系统提示、工具、middleware、skills、子代理委派和记忆系统等部件。也就是说,Harness 不是某一个具体能力,而是把 prompt、memory、tools、MCP connectors、skills、guardrails、evaluation hooks 统一编排起来的整套执行框架
0.4 小结
-
以上各里程碑可以整理如下
阶段 时间 目标 典型工作流 主要局限 Prompt Engineering 2022 年底---2023 年 开始爆发 通过提示词让模型更好理解任务 写 system prompt、few-shot、格式约束,让模型一次性输出结果 强依赖手工调 prompt,难复用、难维护、稳定性有限。ChatGPT 于 2022-11-30 发布后迅速流行 (OpenAI) RAG 2023 年 在应用侧迅速普及(概念源头可追溯到 2020 年) 让模型在回答前先检索外部知识 向量检索/关键词检索 → 取回文档片段 → 拼进上下文 → 再生成答案 主要解决"知道什么",不直接解决"怎么做";检索质量决定上限。RAG 的经典论文发表于 2020-05-22 (arXiv) Function Calling / Tool Use 2023 年中 让模型不仅会说,还会调用外部工具执行操作 模型判断是否调用函数 → 输出结构化参数 → 系统执行函数 → 结果回填模型继续推理 工具通常是原子能力,多步流程仍需开发者手工编排。OpenAI 于 2023-06-13 公布 function calling (OpenAI) MCP 2024 年底 发布,2025 年 快速扩散 标准化模型与外部工具/数据源的连接方式 通过 MCP server 暴露工具、资源、上下文;Agent 统一接入 解决的是"怎么接",不自动解决"怎么用得好"。Anthropic 于 2024-11-25 发布 MCP,并在 2025 年称其快速成为事实标准 (Anthropic) Skill 2025 年 走向主流 把某类任务的方法、规则、脚本、资源封装成可复用能力 模型按需动态加载某个 skill,调用其中的说明、脚本和资源完成任务 比 tool 更高层,但仍需要宿主系统决定调度、记忆、上下文管理。Anthropic 于 2025-10-16 发布 Agent Skills (Claude API Docs) Harness 2025 年下半年---2026 年 成为更明确的工程概念 为 Agent 提供长任务运行的"外骨骼"与执行环境 把 prompt、tools、skills、memory、planning、delegation、context management 统一编排 复杂度更高,重点从"模型能力"转向"系统设计能力"。LangChain 将 harness 定义为包含 planning、文件系统、delegation、context/token management 等能力的组合 (Anthropic) -
综合来看,这条演进路径可以用一句话总结:LLM 应用正在从"优化单次调用",走向"构建可复用能力",再走向"设计完整运行系统"
阶段 核心问题 抽象层 Prompt / RAG / Tool 如何让模型更好完成一次任务? 调用层(Call-level) Skill 如何沉淀可复用的工作方法? 能力层(Capability-level) Harness 如何让 Agent 稳定运行? 系统层(System-level) -
在这一框架下,Skill 之所以关键,是因为它恰好位于 "能力" 与 "系统" 之间的桥梁位置
2. Skill for LLM-based Agent
- Skills 本质上就是教 AI 按固定流程做事的操作说明书,一旦写好,就能像函数一样反复调用,可以看作是把
某类事情应该怎么专业做这件事封装成一个可复用、可自动触发的能力模块
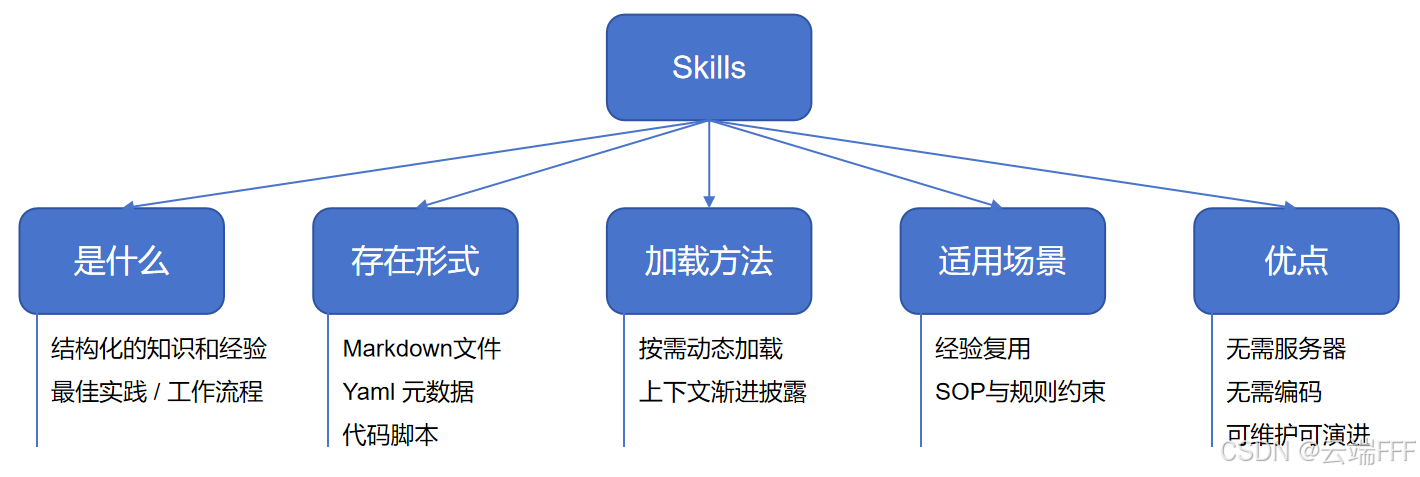
- 和之前的关键节点对比
-
与 Prompt 相比:Skill 天然本地固化,支持按需加载 + 渐进式披露,包含资源脚本
对比项 普通 Prompt Skills 机制 使用方式 每次重新发送 读取本地固化文件 维护方式 重新描述发送 修改本地固化文件,全局/项目生效 上下文 每次全量输入 渐进披露 LLM 行为一致性 低(依赖每次 prompt 质量) 高(固定 SOP + 模板) 复用性 手动复制粘贴 自动匹配 / 项目共享 / 跨平台(OpenClaw、Claude、Cursor) -
与 MCP 相比:Skill 用于知识复用,MCP 用于能力扩展

-
2.1 Skill 的核心结构
-
本文以 OpenClaw 的组织方式对 Skill 进行介绍。它采用的是 AgentSkills-compatible 的文件夹结构,每个 skill 就是一个独立目录,目录里至少要有一个 SKILL.md,这个文件既是技能说明书,也是元数据入口,如下
bashskill-name/ ├── SKILL.md # 必需,包含工作流说明和元数据 │ ├── YAML frontmatter # 必需元数据 │ │ ├── name │ │ └── description │ └── Markdown instructions # 技能说明/工作流程 └── bundled resources/ # 可选 ├── scripts/ # 可执行脚本,如 Python / Bash ├── references/ # 需要按需加载进上下文的参考资料 └── assets/ # 模板、图标、字体等输出资源OpenClaw 默认把一个 Skill 看成 说明文档 + 元数据 + 可选资源文件 的组合,用一个文件夹来承载 "这类任务该怎么做"。这种组织方式使 Skill 天然适合承载"可复用工作流",而不仅仅是一次性的提示词
-
其中
SKILL.md是中心文件,它包含两层内容:前面的 YAML frontmatter 负责描述这个 skill 是什么,后面的 Markdown instructions 负责告诉 agent 什么时候该用它、怎么用它

2.2 Skill 执行流程
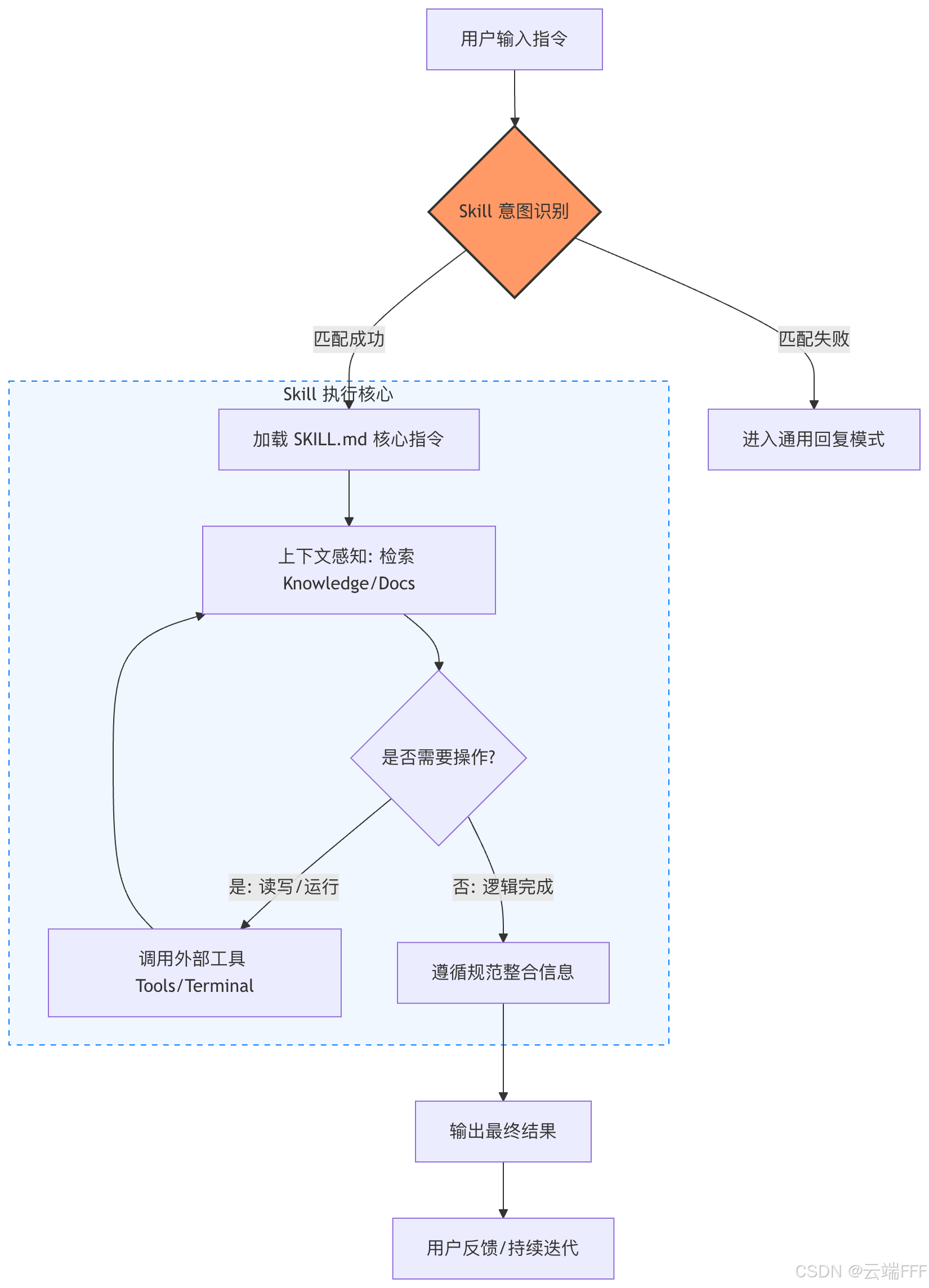
- 以 OpenClaw 的 Skill 执行流程为例:
- 注入基础上下文与 Skill 摘要 :在 OpenClaw 中,新会话开始时首先加载
AGENTS.md、SOUL.md、TOOLS.md等工作区中基础文件 。如果当前环境中存在可用 Skill,系统还会额外提供一份精简的可用 Skill 列表,其中通常只包含 Skill 的名称、描述和位置,用于后续匹配与选择 - 模型根据当前任务判断是否需要进入某个 Skill:模型会结合用户输入和 Skill 摘要进行推理,判断当前任务是否适合调用某个 Skill。这里的关键不是简单关键词匹配,而是根据任务目标、上下文和可用工作流,决定是否进入某个受控执行路径
- 命中后加载 SKILL.md,按既定流程展开执行 :一旦模型判断某个 Skill 相关,就会进一步读取对应的
SKILL.md,模型随后按照这份工作指南展开任务执行。系统提示会明确要求模型在需要时去读取对应位置的SKILL.md - 在 Skill 约束下按需调用工具,并输出结果:进入 Skill 后,模型会在既定规则和权限边界内决定是否调用外部工具;如果当前问题可以直接在上下文中完成,就不必额外调工具。任务完成后输出结果,用户的下一次输入再触发新一轮相同机制的判断与执行
- 注入基础上下文与 Skill 摘要 :在 OpenClaw 中,新会话开始时首先加载
- 示意图如下所示
2.3 渐进披露加载
- 渐进披露加载是 Skill 的核心特点。理想情况下 LLM 骨干会组织复用大量 Skill 开展工作,如果把所有 Skill 的完整内容都提前注入 LLM 上下文,会立刻遇到几个问题
- 提示过于臃肿,占用上下文窗口
- 与当前任务无关的 Skill 会干扰模型决策
- 很多信息其实只有执行时才需要,在 "是否调用" 阶段,模型只需要知道这个 Skill 是干什么的;在 "真正执行" 阶段才需要看到具体流程细节
- 渐进披露加载是一种按需注入上下文的机制 :模型先看到技能的简要描述,用于判断是否相关;只有在确定需要时,才进一步加载详细流程、规则和配套资源。具体分三层加载:
- 层级 1:技能发现 -- AI 先读取所有技能的元数据(
name和description),判断任务是否相关,这些元数据始终在系统提示中 - 层级 2:加载核心指令 -- 如果判定相关,AI 自动读取 SKILL.md 的正文内容,获取详细指导
- 层级 3:加载资源文件 -- 只在需要时读取额外文件(如脚本、示例),或通过工具执行脚本
- 层级 1:技能发现 -- AI 先读取所有技能的元数据(
- 当用户消息触发时,上下文窗口变化如下所示

2.4 Skill.md 编写方法
2.4.1 基本模板
-
Skill.md 的基本模板如下
bash--- name: your-skill-name description: What it does and when Claude should use it --- # Skill Title ## Instructions Clear, concrete, actionable rules. ## Examples - Example usage 1 - Example usage 2 ## Guidelines - Guideline 1 - Guideline 2 -
元数据字段如下(for Claude ):
字段 必填 说明 name 是 Skill 显示名称,默认使用目录名,仅支持小写字母、数字和短横线(最长 64 字符) description 是 技能用途及使用场景,Claude 根据它判断是否自动应用 argument-hint 否 自动补全时显示的参数提示,如 issue-number、filename format disable-model-invocation 否 设为 true 禁止 Claude 自动触发,仅能手动 /name 调用(默认 false) user-invocable 否 设为 false 从 / 菜单隐藏,作为后台增强能力使用(默认 true) allowed-tools 否 Skill 激活时 Claude 可无授权使用的工具 model 否 Skill 激活时使用的模型 context 否 设为 fork 时在子代理上下文中运行 agent 否 子代理类型(配合 context: fork 使用) hooks 否 技能生命周期钩子配置 -
Skills 支持在内容中插入动态变量(for Claude ):
变量 说明 $ARGUMENTS 调用 Skill 时传入的所有参数 $ARGUMENTSN 按索引访问参数,如 $ARGUMENTS0 $N 简写方式,如 $0 表示第一个参数 ${CLAUDE_SESSION_ID} 当前会话 ID,用于日志、临时文件、关联输出 插入动态变量示例如下
bash--- name: session-logger description: 记录当前会话活动 --- 请将以下内容写入日志文件: logs/${CLAUDE_SESSION_ID}.log $ARGUMENTSOpenClaw 与 Claude Skills 在参数传递机制上存在相似性,至少可以确认 OpenClaw 技能生态中实际使用了 ARGUMENTS 和 argument-hint;但对于 ARGUMENTSN、0 以及 {CLAUDE_SESSION_ID} 等变量,目前没有足够证据表明 OpenClaw 3.28 与 Claude 保持完全一致,因此不宜直接视为同等支持。
2.4.2 长技能文件结构
-
当技能超过 500--800 行,或需要模板/脚本/参考资料时,推荐以下组织方式:
bash~/.claude/skills/react-component-review/ ├── SKILL.md # 核心指令 + 元数据(建议控制在 400 行内) │ ├── templates/ # 常用模板(Claude 按需读取) │ ├── functional.tsx.md │ └── class-component.md │ ├── examples/ # 优秀/反例(给 Claude 看标准) │ ├── good.md │ └── anti-pattern.md │ ├── references/ # 规范、规则、禁用词表 │ ├── hooks-rules.md │ └── naming-convention.md │ └── scripts/ # 可执行脚本(需开启 code execution) ├── validate-props.py └── check-cycle-deps.sh -
在 SKILL.md 中引用方式示例:
bashMarkdown需要给出标准函数组件时,参考 templates/functional.tsx.md 的结构。 如果违反 Hooks 规则,对照 references/hooks-rules.md 第 3--5 条说明。 如需校验 propTypes,可执行 scripts/validate-props.py "{代码片段}"。