简介
想要学会将BL3接入自定义的环境需要做两件事:
第零,你得对自己的任务熟悉,知晓观测空间、动作空间、奖励函数如何设计,根据需求决定要用的模型,再开始写代码。
第一,明确Gym的环境配置,了解需要自己手写哪些函数?配置哪些参数?
第二,套用训练模板,根据你预先决定使用的模型抄模板就行,官方是提供了这些常用模型的示例代码

第零步,我们这次教程使用之前编写的Predator环境,动作空间是离散的,状态空间也是离散的,可以使用A2C模型(也可以用DQN等)。
我们先完成第一步,明确Gym的环境配置,写出需要自定义的函数。【这部分内容之前讲过了】
Gymnasium 环境简介
https://gymnasium.farama.org/api/env/
Gymnasium 环境(Env)的核心标准 API 非常简洁,主要由 4 个核心函数 和 2 个核心属性 组成。这是所有强化学习任务交互的基础。
🧠 1. 核心交互函数
这些是你在训练循环(Training Loop)中必须调用的函数。
| 函数名 | 参数/说明 | 返回值 (Tuple) |
|---|---|---|
.reset() (重置环境) |
作用 :在每个回合(Episode)开始前调用,将环境恢复到初始状态。 参数 :seed (可选,用于复现实验结果), options (特定环境的额外参数)。 |
1. observation :初始环境状态(符合 observation_space 定义)。 2. info:辅助诊断信息(字典)。 |
.step(action) (执行动作) |
作用 :这是强化学习的核心。将 Agent 的动作(Action)传入环境,环境反馈下一步的状态和奖励。 参数 :action (Agent 选择的动作)。 |
1. observation :执行动作后的新环境状态。 2. reward :该动作获得的奖励(浮点数)。 3. terminated :布尔值。True 表示回合正常结束(如到达目标/坠毁)。 4. truncated :布尔值。True 表示回合被强制截断(如超时/出界)。 5. info:辅助诊断信息。 |
.render() (渲染画面) |
作用 :将环境的当前状态可视化。 注意 :在 gymnasium.make() 时需指定 render_mode(如 "human", "rgb_array")。 |
根据 render_mode 不同而不同: * "human":通常返回 None (直接在窗口显示)。 * "rgb_array":返回图像帧 np.ndarray。 * "ansi":返回文本字符串。 |
.close() (关闭环境) |
作用 :释放环境占用的资源(如关闭 Pygame 窗口、数据库连接等)。 建议:在脚本结束或训练完成后调用。 | None |
📏 2. 核心属性 (Spaces)
在编写代码前,你需要通过这两个属性来了解环境的输入输出规格:
-
.action_space- 含义:定义了 Agent 可以采取的所有合法动作的范围。
- 用途 :用于构建 Agent 的输出层。例如,如果是
Discrete(4),说明有 4 个离散动作(如 Lunar Lander 的 0, 1, 2, 3)。 - 常用方法 :
sample()(随机采样一个动作)。
-
.observation_space- 含义:定义了环境状态(观测值)的数据结构和范围。
- 用途 :用于构建 Agent 的输入层。例如,
Box(4,)表示一个包含 4 个浮点数的数组。 - 常用方法 :
sample()(随机采样一个观测值,常用于测试)。
🛠️ 3. 辅助属性与函数
.metadata:包含环境的元信息,比如支持的渲染模式 (render_modes) 和帧率 (render_fps)。.spec:环境的配置规格,通常在通过gymnasium.make()创建时生成。.np_random:环境内部的随机数生成器,用于保证实验的可复现性 (Reproducibility)。
📝 总结代码模板
一个标准的 自定义环境类 模板长这样:
https://stable-baselines3.readthedocs.io/en/master/guide/custom_env.html
python
import gymnasium as gym
import numpy as np
from gymnasium import spaces
class CustomEnv(gym.Env):
"""Custom Environment that follows gym interface."""
metadata = {"render_modes": ["human"], "render_fps": 30}
def __init__(self, arg1, arg2, ...):
super().__init__()
# Define action and observation space
# They must be gym.spaces objects
# Example when using discrete actions:
self.action_space = spaces.Discrete(N_DISCRETE_ACTIONS)
# Example for using image as input (channel-first; channel-last also works):
self.observation_space = spaces.Box(low=0, high=255,
shape=(N_CHANNELS, HEIGHT, WIDTH), dtype=np.uint8)
def step(self, action):
...
return observation, reward, terminated, truncated, info
def reset(self, seed=None, options=None):
...
return observation, info
def render(self):
...
def close(self):
...我们要按要求修改我们的envCube类。
首先,可以看出,自定义环境要继承gym.Env。
其次需要指定action_space和observation_space。
python
self.action_space = gym.spaces.Discrete(ACTION_SPACE_VALUES)
self.observation_space = gym.spaces.Box(low=-SIZE+1, high=SIZE-1,
shape=(4,), dtype=int)注意,动作空间是9个,是离散的,因此使用Discrete。而观察空间其实也是离散的,但是这里还是使用了连续的Box,Box有四个参数,分别是连续区间的最小最大值,状态向量的维度,以及单个数据类型。我们设定的是SIZE*SIZE的棋盘,状态用(x1,y1,x2,y2)这个(4,)tuple表示。
(注意一下,更新后spaces.Discrete、spaces_Box都无法直接用,要加前缀gym)
写出来应该如下:
python
def __init__(self,SIZE=10,
ACTION_SPACE_VALUES = 9,
RETURN_IMAGE = True,
MAX_STEP=200,
FOOD_REWARD = 25,
ENEMY_PENALITY = -300,
MOVE_PENALITY = -1):
super(envCube,self).__init__()
self.SIZE=SIZE
#self.OBSERVATION_SPACE_VALUES=(SIZE,SIZE,3)
self.OBSERVATION_SPACE_VALUES=(4,)
#self.ACTION_SPACE_VALUES=ACTION_SPACE_VALUES
self.RETURN_IMAGE = RETURN_IMAGE # 考虑返回值是否图像
self.MAX_STEP=MAX_STEP
self.FOOD_REWARD = FOOD_REWARD # agent获得食物的奖励
self.ENEMY_PENALITY = ENEMY_PENALITY # 遇上对手的惩罚
self.MOVE_PENALITY = MOVE_PENALITY # 每移动一步的惩罚
self.action_space = gym.spaces.Discrete(ACTION_SPACE_VALUES)
self.observation_space = gym.spaces.Box(low=-SIZE+1, high=SIZE-1,
shape=(4,), dtype=int)然后我们验证一下
为了检测我们的环境是否符合gym的要求,可以使用这个函数验证
肯定会遇到不少报错,但都很好解决,基本就是把observation改为np.array的形式,而不是tuple。以及返回需要添加info的问题。
下面这个是能跑通的:
python
class envCube(gym.Env):
# 设定三个部分的颜色分别是蓝、绿、红
d = {1: (255, 0, 0), # blue
2: (0, 255, 0), # green
3: (0, 0, 255)} # red
PLAYER_N = 1
FOOD_N = 2
ENEMY_N = 3
metadata = {"render_modes": ["human"], "render_fps": 30}
def __init__(self,SIZE=10,
ACTION_SPACE_VALUES = 9,
RETURN_IMAGE = False,
MAX_STEP=200,
FOOD_REWARD = 25,
ENEMY_PENALITY = -300,
MOVE_PENALITY = -1):
super(envCube,self).__init__()
self.SIZE=SIZE
#self.OBSERVATION_SPACE_VALUES=(SIZE,SIZE,3)
self.OBSERVATION_SPACE_VALUES=(4,)
#self.ACTION_SPACE_VALUES=ACTION_SPACE_VALUES
self.RETURN_IMAGE = RETURN_IMAGE # 考虑返回值是否图像
self.MAX_STEP=MAX_STEP
self.FOOD_REWARD = FOOD_REWARD # agent获得食物的奖励
self.ENEMY_PENALITY = ENEMY_PENALITY # 遇上对手的惩罚
self.MOVE_PENALITY = MOVE_PENALITY # 每移动一步的惩罚
self.action_space = gym.spaces.Discrete(ACTION_SPACE_VALUES)
self.observation_space = gym.spaces.Box(low=-SIZE+1, high=SIZE-1,
shape=(4,), dtype=int)
# 环境重置
def reset(self,seed=None, options=None):
self.player = Cube(self.SIZE)
self.food = Cube(self.SIZE)
self.enemy = Cube(self.SIZE)
# 如果玩家和食物初始位置相同,重置食物的位置,直到位置不同
while self.player == self.food:
self.food = Cube(self.SIZE)
# 如果敌人和玩家或食物的初始位置相同,重置敌人的位置,直到位置不同
while self.player == self.enemy or self.food == self.enemy:
self.enemy = Cube(self.SIZE)
# 判断观测是图像和数字
if self.RETURN_IMAGE:
observation = np.array(self.get_image())
else:
observation = (self.player - self.food)+(self.player - self.enemy)
observation=np.array(observation)
self.episode_step = 0
info={}
return observation,info
def step(self,action):
self.episode_step+=1
self.player.action(action)
self.food.move()
self.enemy.move()
# 分类讨论输出new_obs
if self.RETURN_IMAGE:
new_observation = np.array(self.get_image())
else:
new_observation = (self.player - self.food)+(self.player - self.enemy)
new_observation=np.array(new_observation)
#获取reward值
if self.player == self.food:
reward=self.FOOD_REWARD
elif self.player==self.enemy:
reward=self.ENEMY_PENALITY
else:
reward=self.MOVE_PENALITY
#检测截止情况
terminated = False
truncated = False
# 4. 判断结束条件
if self.player == self.food or self.player == self.enemy:
terminated = True
if self.episode_step >= self.MAX_STEP:
truncated = True
info={}
return new_observation,reward,terminated,truncated,info
def render(self,mode='human'):
img=self.get_image()
img = img.resize((800,800))
cv2.imshow('Predator',np.array(img))
cv2.waitKey(1)
def get_image(self):
# 图像显示
env = np.zeros(self.OBSERVATION_SPACE_VALUES,dtype= np.uint8)
env[self.food.x][self.food.y] = self.d[self.FOOD_N]
env[self.player.x][self.player.y] = self.d[self.PLAYER_N]
env[self.enemy.x][self.enemy.y] = self.d[self.ENEMY_N]
img = Image.fromarray(env,'RGB')
return img第二步,套用官方提供的代码
接下来,我们套用之前写的A2C模型的训练代码,来自这一讲【A2C 再战登月器降落】
这一讲中,官方提供了示例代码:
https://stable-baselines3.readthedocs.io/en/master/modules/a2c.html
python
from stable_baselines3 import A2C
from stable_baselines3.common.env_util import make_vec_env
# Parallel environments
vec_env = make_vec_env("CartPole-v1", n_envs=4)
model = A2C("MlpPolicy", vec_env, verbose=1)
model.learn(total_timesteps=25000)
model.save("a2c_cartpole")
del model # remove to demonstrate saving and loading
model = A2C.load("a2c_cartpole")
obs = vec_env.reset()
while True:
action, _states = model.predict(obs)
obs, rewards, dones, info = vec_env.step(action)
vec_env.render("human")我们参照着这个代码写出了:
python
#A2C版本代码
# Instantiate the agent
model = A2C("MlpPolicy",
env,
verbose=1,
tensorboard_log='./logs',
learning_rate=5e-4,
policy_kwargs={'net_arch':[256, 256]}
)
# Train the agent and display a progress bar
model.learn(total_timesteps=int(2.5e6), progress_bar=True,tb_log_name='A2C_Net256_2M_50')
# Save the agent
model.save("A2C_Net256_2M_50_lunar")
del model # delete trained model to demonstrate loading
python
model = DQN.load("dqn_Net256_lunar", env=env)
model.set_env(env)
mean_reward, std_reward = evaluate_policy(model, model.get_env(),deterministic=True,render=False, n_eval_episodes=10)我们不需要改架构,只需要改参数即可。
这次我们打算训练50万次,那么total_timesteps就要设定为5e6,然后我们把训练的日志记录名称改为"S10_A2C_Net256_50W"。
python
#A2C版本代码
# Instantiate the agent
model = A2C("MlpPolicy",
env,
verbose=1,
tensorboard_log='./logs',
learning_rate=5e-4,
policy_kwargs={'net_arch':[256, 256]}
)
# Train the agent and display a progress bar
model.learn(total_timesteps=int(2.5e6), progress_bar=True,tb_log_name='S10_A2C_Net256_50W')然后保存模型的名称也改一下"A2C_Net256_50_lunar"
python
# Save the agent
model.save("S10_A2C_Net256_50W_lunar")
del model # delete trained model to demonstrate loading打开tensorboard,可以看到,训练出来的效果还是不错的,奖励基本都收敛到0附近了!
而且步数也稳定在10步左右就能吃到食物。
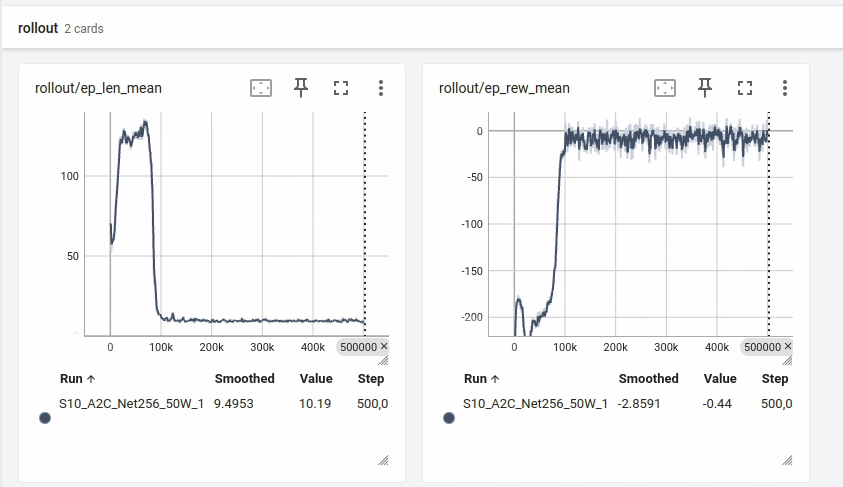
效果不好,考虑修改模型架构
现在我们想扩大一点棋盘,改为SIZE=20,在20*20的情况下,50万次的训练很明显是无法达到预期效果的,仅有-200。
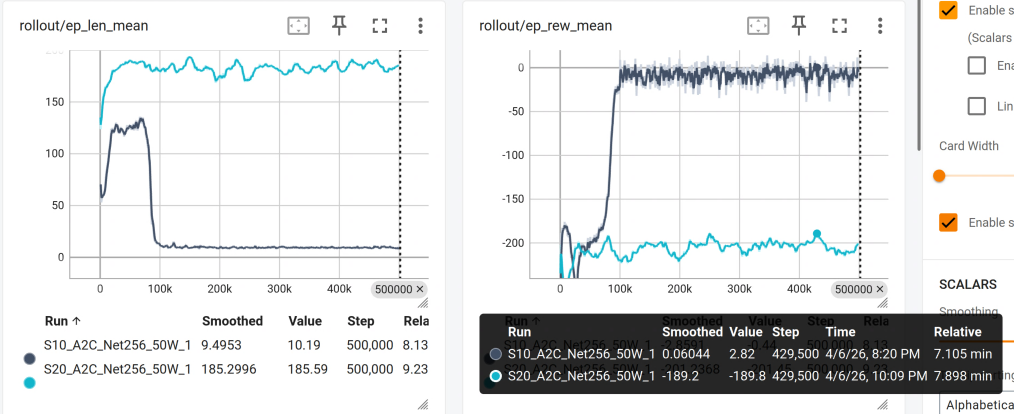
很多时候,训练步数给到50W也无法达到很好的效果,这种情况下,就需要我们修改模型架构了。
python
model = A2C("MlpPolicy",
env,
verbose=1,
tensorboard_log='./logs',
learning_rate=5e-4,
policy_kwargs={'net_arch':[256, 256]}
)核心就是这个policy_kwargs。
如何修改呢?我们可以参考:
https://stable-baselines3.readthedocs.io/en/master/guide/custom_policy.html
架构的修改
policy_kwargs核心参数详解
1. features_extractor_class 和 features_extractor_kwargs
用于指定如何从原始观测(Observation)中提取特征。
用途 :如果你的输入是图像,通常用 CnnPolicy;如果是向量(Vector),通常用 MlpPolicy。
2. net_arch (最常用的参数)
这是设定神经网络层数和每层神经元数量的核心参数。它决定了 Actor(策略网络)和 Critic(价值网络)的隐藏层结构。
设定规则:
net_arch 接受一个列表(List)。列表中的每一个数字代表一个隐藏层的神经元数量。如果需要将策略网络和价值网络的结构分开定义,可以使用字典(Dict)格式。
两种主要设定格式:
格式 A:统一架构
当 Actor 和 Critic 使用相同的网络结构时使用。
-
写法 :
pythonpolicy_kwargs = dict(net_arch=[128, 128]) -
含义:创建两个隐藏层,每层都有 64 个神经元。这个结构将同时用于策略(Policy)和价值函数(Value)。
格式 B:分离架构
当需要为 Actor 和 Critic 分别设定不同结构时使用。这是文档中重点展示的高级用法。
-
写法 :
pythonpolicy_kwargs = dict(net_arch=dict(pi=[32, 32], vf=[64, 64])) -
含义:策略网络使用两层 64 个神经元的结构,而价值网络使用两层 32 个神经元的结构。

激活函数的修改
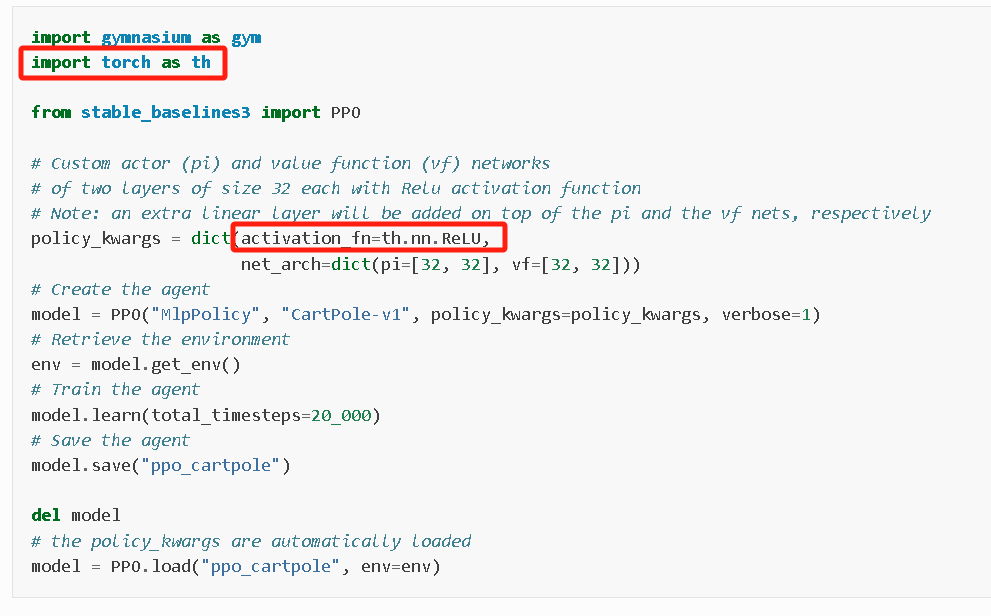
在官方的示例中,如果我们想修改激活函数(默认tanh),可以导入th库,然后在这里设定activation_fn=th.nn.ReLU
我们也参考,先共享一层,再分开
python
model = A2C("MlpPolicy",
env,
verbose=1,
tensorboard_log='./logs',
learning_rate=5e-4,
policy_kwargs={
'net_arch': dict(vf=[32, 32], pi=[32, 16]), # 修正了这里
'activation_fn': th.nn.ReLU
}
)
model.policy
在这个架构下,policynet第一层是32,第二层变成了16;而valuenet第一层是32,第二层也是32;对应了 dict(vf=32, 32, pi=32, 16)
然后我们开始训练。
训练结束,发现红色线形势一片大好,很快就收敛了,只需要15步就能吃到食物,而且奖励也达到了正数!
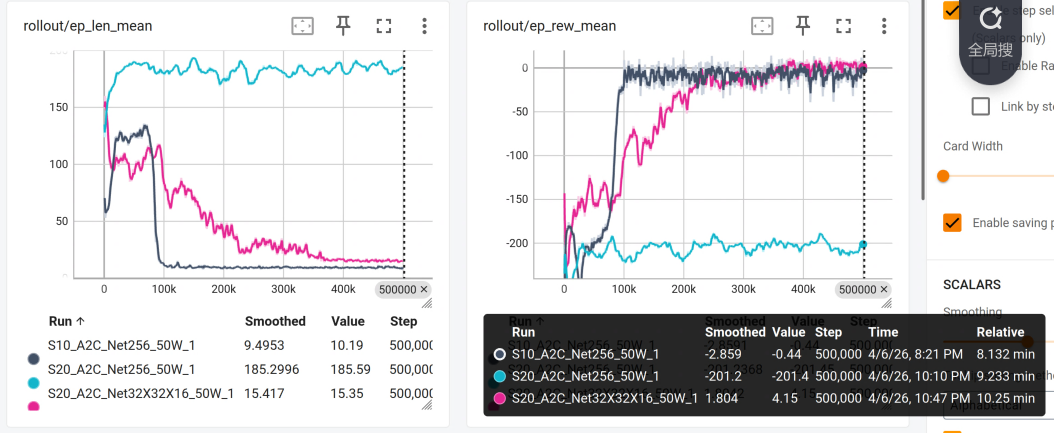
这样我们的模型架构修改是成功的!
总结
这一节,综合了前几节的内容。
包括【强化学习实战4------编写符合Gym的环境】以及【强化学习实战2------A2C 再战登月器降落】
要学会将BL3接入自定义的环境需要做两件事:
第零,你得对自己的任务熟悉,知晓观测空间、动作空间、奖励函数如何设计,根据需求决定要用的模型,再开始写代码。
第一,明确Gym的环境配置,了解需要自己手写哪些函数?配置哪些参数?
第二,套用训练模板,根据你预先决定使用的模型抄模板就行,官方是提供了这些常用模型的示例代码
第三,当增加训练步数也无法达到预期效果时,就要考虑修改模型架构了。
修改有三个地方,
一个是"是否使用分离的AC模型?"
一个是"是否修改不同层级的神经元数量?"
一个是"是否修改激活函数"
实际上,这样的修改往往还不足够,在下一节,我们会讲如何自定义特征提取器。这一节我们仅仅是触及了net_arch的修改,并没有涉及前面的特征提取器的修改。
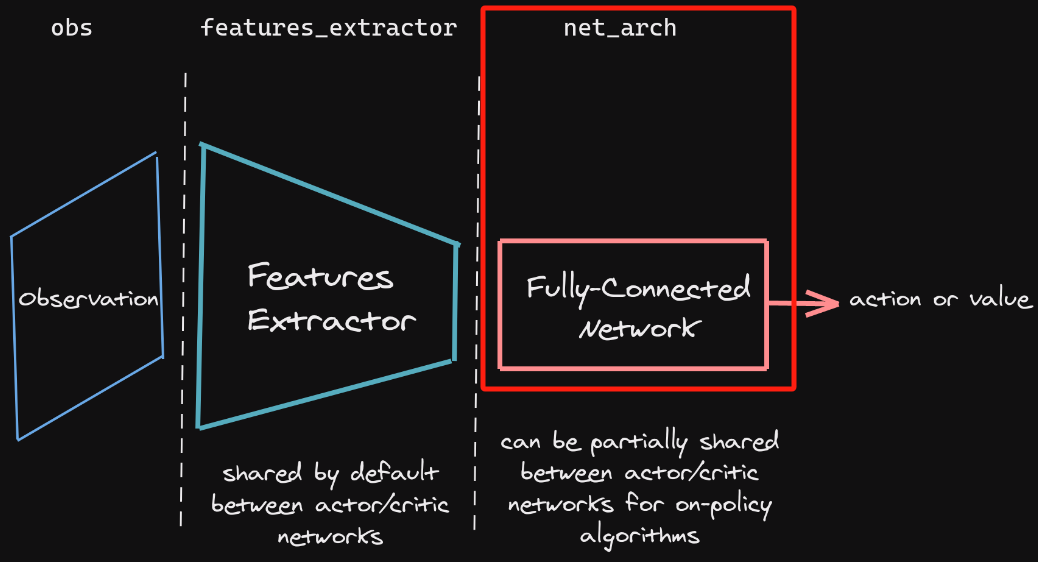
我们最终的目的是要能够自己定义Observation,自定义特征提取器,自定义模型架构。从而实现这张图。
都可以做尝试。
本节代码:
下载依赖库
python
!pip install opencv-python
!pip install pillow
!pip install gymnasium
!pip install matplotlib
!pip install stable-baselines3[extra]
!pip install tensorboard导入依赖库
python
#将学习环境所需要的依赖库导入
import gymnasium as gym
import numpy as np
from gymnasium import spaces
import cv2
from PIL import Image
import time
import torch as th
import pickle #对象到文件的处理
import matplotlib.pyplot as plt
from matplotlib import style
from stable_baselines3.common.env_checker import check_env
style.use('ggplot')设置环境参数
python
#环境参数设定
#SIZE=10 #3个对象在10*10的范围内
EPISODES=30000 #智能体玩的游戏轮数
SHOW_EVERY=3000 #每3000局展示一次游玩过程
#奖励与惩罚
#FOOD_REWARD=25#吃食物的奖励
#ENEMY_PENALITY=300 #被敌人抓住的惩罚
#MOVE_PENALITY=1 #移动惩罚
#环境计算参数
epsilon=0.6 #在强化学习时抽取随机动作的概率 40%使用最大价值期望动作
EPS_DECAY=0.9998 #每玩一局游戏就让随机动作概率乘以这个数,到最后基本就定性了
DISCOUNT=0.95 #折扣回报 未来奖励的折扣
LEARNING_RATE=0.1 #学习率 步长
#q_table_file = "q_table_save.pkl"
#q_table = None
q_table = "qtable_1775227149.pickle"
#d = {1:(255,0,0), #蓝色------玩家
# 2:(0,255,0), #绿色------食物
# 3:(0,0,255)} #红色------敌人
#PLAYER_N=1
#FOOD_N=2
#ENEMY_N=3编写Cube对象类
python
#为三个对象创建类
class Cube:
def __init__(self,size):#初始位置
self.size=size
self.x=np.random.randint(0,self.size-1)
self.y=np.random.randint(0,self.size-1)
def __str__(self): #打印当前位置
return f'{self.x},{self.y}'
def __sub__(self,other):#这个类的另一个实体
return (self.x-other.x,self.y-other.y)
def __eq__(self,other):
return self.x == other.x and self.y == other.y
def action(self,choise):
if choise == 0:
self.move(x=1,y=1)
elif choise == 1:
self.move(x=-1,y=1)
elif choise == 2:
self.move(x=1,y=-1)
elif choise == 3:
self.move(x=-1,y=-1)
elif choise == 4:
self.move(x=0,y=1)
elif choise == 5:
self.move(x=0,y=-1)
elif choise == 6:
self.move(x=1,y=0)
elif choise == 7:
self.move(x=-1,y=0)
elif choise == 8:
self.move(x=0,y=0)
def move(self,x=False,y=False):
if not x:#如果x没有给值
self.x += np.random.randint(-1,2)
else:
self.x += x
if not y:#如果y没有给值
self.y += np.random.randint(-1,2)
else:
self.y += y
#考虑边界
if self.x<0:
self.x=0
elif self.x>=self.size:
self.x=self.size-1
if self.y<0:
self.y=0
elif self.y>=self.size:
self.y=self.size-1编写envCube环境类
python
class envCube(gym.Env):
# 设定三个部分的颜色分别是蓝、绿、红
d = {1: (255, 0, 0), # blue
2: (0, 255, 0), # green
3: (0, 0, 255)} # red
PLAYER_N = 1
FOOD_N = 2
ENEMY_N = 3
metadata = {"render_modes": ["human"], "render_fps": 30}
def __init__(self,SIZE=20,
ACTION_SPACE_VALUES = 9,
RETURN_IMAGE = False,
MAX_STEP=200,
FOOD_REWARD = 25,
ENEMY_PENALITY = -300,
MOVE_PENALITY = -1):
super(envCube,self).__init__()
self.SIZE=SIZE
#self.OBSERVATION_SPACE_VALUES=(SIZE,SIZE,3)
self.OBSERVATION_SPACE_VALUES=(4,)
#self.ACTION_SPACE_VALUES=ACTION_SPACE_VALUES
self.RETURN_IMAGE = RETURN_IMAGE # 考虑返回值是否图像
self.MAX_STEP=MAX_STEP
self.FOOD_REWARD = FOOD_REWARD # agent获得食物的奖励
self.ENEMY_PENALITY = ENEMY_PENALITY # 遇上对手的惩罚
self.MOVE_PENALITY = MOVE_PENALITY # 每移动一步的惩罚
self.action_space = gym.spaces.Discrete(ACTION_SPACE_VALUES)
self.observation_space = gym.spaces.Box(low=-SIZE+1, high=SIZE-1,
shape=(4,), dtype=int)
# 环境重置
def reset(self,seed=None, options=None):
self.player = Cube(self.SIZE)
self.food = Cube(self.SIZE)
self.enemy = Cube(self.SIZE)
# 如果玩家和食物初始位置相同,重置食物的位置,直到位置不同
while self.player == self.food:
self.food = Cube(self.SIZE)
# 如果敌人和玩家或食物的初始位置相同,重置敌人的位置,直到位置不同
while self.player == self.enemy or self.food == self.enemy:
self.enemy = Cube(self.SIZE)
# 判断观测是图像和数字
if self.RETURN_IMAGE:
observation = np.array(self.get_image())
else:
observation = (self.player - self.food)+(self.player - self.enemy)
observation=np.array(observation)
self.episode_step = 0
info={}
return observation,info
def step(self,action):
self.episode_step+=1
self.player.action(action)
self.food.move()
self.enemy.move()
# 分类讨论输出new_obs
if self.RETURN_IMAGE:
new_observation = np.array(self.get_image())
else:
new_observation = (self.player - self.food)+(self.player - self.enemy)
new_observation=np.array(new_observation)
#获取reward值
if self.player == self.food:
reward=self.FOOD_REWARD
elif self.player==self.enemy:
reward=self.ENEMY_PENALITY
else:
reward=self.MOVE_PENALITY
#检测截止情况
terminated = False
truncated = False
# 4. 判断结束条件
if self.player == self.food or self.player == self.enemy:
terminated = True
if self.episode_step >= self.MAX_STEP:
truncated = True
info={}
return new_observation,reward,terminated,truncated,info
def render(self,mode='human'):
img=self.get_image()
img = img.resize((200,200))
cv2.imshow('Predator',np.array(img))
if self.player == self.food or self.player == self.enemy or self.episode_step >= self.MAX_STEP:
cv2.waitKey(1500)
else:
cv2.waitKey(1)
def get_image(self):
# 图像显示
env = np.zeros(self.OBSERVATION_SPACE_VALUES,dtype= np.uint8)
env[self.food.x][self.food.y] = self.d[self.FOOD_N]
env[self.player.x][self.player.y] = self.d[self.PLAYER_N]
env[self.enemy.x][self.enemy.y] = self.d[self.ENEMY_N]
img = Image.fromarray(env,'RGB')
return img创建环境对象
python
env=envCube()检测环境是否符合Gym标准
python
check_env(env)导入主函数依赖库
python
import gymnasium as gym
from stable_baselines3 import DQN,A2C
from stable_baselines3.common.evaluation import evaluate_policy
import os
import stable_baselines3 as sb3
print(sb3.__version__)
os.environ['KMP_DUPLICATE_LIB_OK']='True'构建模型
python
model = A2C("MlpPolicy",
env,
verbose=1,
tensorboard_log='./logs',
learning_rate=5e-4,
policy_kwargs={
'net_arch': dict(vf=[32, 32], pi=[32, 16]), # 修正了这里
'activation_fn': th.nn.ReLU
}
)
model.policy训练模型
python
# Train the agent and display a progress bar
model.learn(total_timesteps=int(500000), progress_bar=True,tb_log_name='S20_A2C_Net32X32X16_50W')保存模型
python
# Save the agent
model.save("S20_A2C_Net32X32X16_50W_lunar")
del model # delete trained model to demonstrate loading加载与评估模型
python
model = DQN.load("S20_A2C_Net32X32X16_50W_lunar", env=env)
model.set_env(env)
mean_reward, std_reward = evaluate_policy(model, model.get_env(),deterministic=True,render=False, n_eval_episodes=10)