****论文题目:****UWDET: IoT-Enabled Training Enhancement for Resource-Limited Underwater Object Detection(UWDET:基于物联网的资源有限水下目标探测训练增强)
期刊:IOTJ
****摘要:****在支持物联网(IoT)的海洋传感器网络中,由于资源限制,水下物体检测(UWDET)面临挑战,例如小目标识别和规模变化。这些挑战导致样本不平衡和标签分配的模糊性。虽然像你只看一次(YOLO)系列这样的框架是有效的,但由于这些问题,它们的水下性能往往不足。本文介绍了为物联网环境中的UWDET量身定制的训练增强策略,旨在减少推理资源消耗,同时保持高检测准确性。重要的是,我们的方法保留了现有的网络架构,并且不会延长推理时间。该方法包括三个主要元素:高斯重叠损失(GOL),它通过二维高斯分布解释边界盒(BBoxes),从而增强定位并解决资源有限环境下小物体的尺度不平衡问题。动态任务联合分配(DTJA)基于分类置信度和回归质量修改正样本分配,从而最大限度地减少训练过程中的假阳性率。规范焦点损失(NFL)采用归一化的联合分配度量作为连续标签,有效地解决了样本不平衡问题。水下检测基准的实验评估表明,我们的方法显著提高了精度和召回率,稳定了梯度信号,提高了训练效率。我们还报告了训练端GPU内存/时间/能量和边缘端内存和延迟,证实了不变的推理成本和减少的训练资源使用。我们的训练增强策略将精心设计的轻量级通用物体检测模型应用于水下领域。在不需要对网络架构进行复杂修改的情况下,它可以在资源受限的物联网水下设备中快速训练并促进高精度模型的部署和推理。
UWDET:让水下目标检测在IoT边缘设备上更精准------不改结构,只改训练
1. 背景:水下IoT检测为什么这么难?
随着IoT技术的快速发展,水下传感网络被广泛部署用于环境监测、海洋安全和资源探测。这些系统的核心能力是水下目标检测(UWDET),需要在算力受限的边缘设备上完成实时推理。
然而,水下场景对检测算法而言极为苛刻:光线在水中发生衰减、散射和吸收,导致图像出现色彩失真、运动模糊和不均匀光照。叠加上边缘设备的算力与能耗约束,研究者面临一个两难困境:
- 高精度模型(如大型Transformer):推理开销过大,边缘设备无法承受;
- 轻量化模型(如YOLO系列):面对水下复杂光学畸变,精度严重下滑。
具体而言,水下检测存在三个核心技术挑战:
- 样本不平衡:前景目标与复杂背景之间存在严重的正负样本比例失衡;
- 标签分配模糊:传统IoU指标在特定几何关系下(如预测框与GT框中心重合但宽高比不同时)判别力完全失效;
- 小目标性能退化:水下场景中小目标占比极高,而现有检测器对小目标极不友好。
现有解决思路主要有两类:一是模型压缩 (量化、剪枝、知识蒸馏),能降低计算量但无法解决水下域特有问题;二是图像/特征增强,能提升精度但引入额外推理开销------实时增强流水线通常增加15%--30%的处理时间,特征增强模块往往扩大20%--40%的参数量,与资源受限的水下IoT需求背道而驰。
2. 核心思路:只动训练,不动网络
本文作者提出了一个关键洞察:优质的通用目标检测模型(如YOLO系列)已经在精度和速度之间取得了很好的平衡,若能在训练阶段直接引导模型学习正确的水下目标特征,就无需对推理架构做任何修改。
基于此,论文提出了UWDET训练增强框架,包含三个模块:
- GOL(Gaussian Overlap Loss,高斯重叠损失):重新定义BBox的相似度度量;
- DTJA(Dynamic Task Joint Assignment,动态任务联合标签分配):动态、高质量地分配正样本;
- NFL(Normative Focal Loss,归一化Focal损失):将损失函数扩展至连续标签并解决样本不平衡。
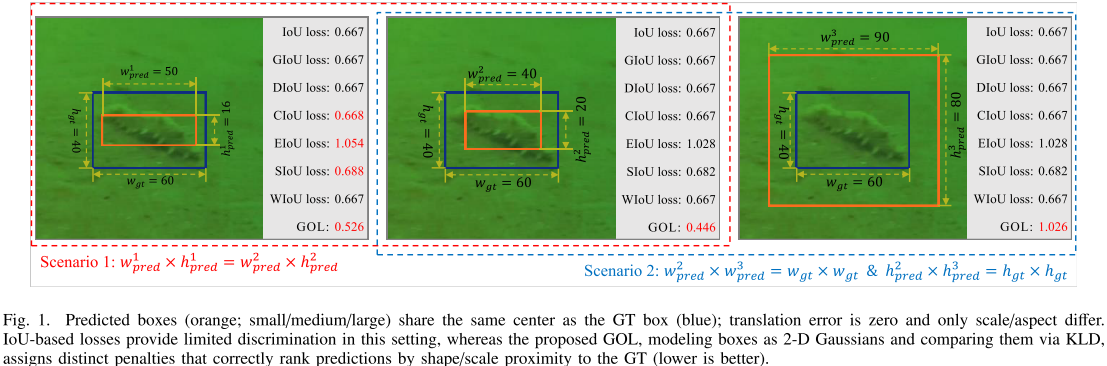
【配图:论文 Figure 1】IoU变体与GOL的对比示意图。图中展示了当预测框与GT框中心对齐、仅形状/尺度不同时,IoU/GIoU/DIoU/WIoU等损失值完全相同无法区分优劣,而GOL能给出有差异的惩罚值,正确排列预测质量。
3. 方法详解
3.1 GOL:把BBox"看作"高斯分布
为什么IoU不够用?
传统IoU及其变体(GIoU、DIoU、CIoU、EIoU、SIoU、WIoU)在某些情况下完全丧失判别力。如Figure 1所示,当预测框的中心与GT框完全重合时,无论预测框的宽高比如何变化,IoU、GIoU、DIoU、WIoU的损失值均保持不变(均为0.667)。即便是表现相对较好的CIoU/EIoU,在宽高比按比例缩放的场景下仍然不足。
GOL的核心思想
GOL将预测BBox和GT BBox都建模为二维高斯分布的外包围框:对于中心坐标(x,y)、宽w、高h的BBox,均值向量和协方差矩阵分别为中心坐标和以宽高为对角元素的矩阵(标准化因子σ=3,覆盖99.73%的数据点)。两个BBox之间的差异通过KL散度来衡量,最终的GOL损失引入对数缩放:
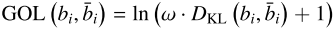
对数缩放有两个关键作用:在KL散度较大时压缩其影响(防止训练初期梯度爆炸),在KL散度较小时增强区分度(促进精细定位收敛)。
梯度分析的两个重要性质
通过对KL散度求偏导,论文揭示了两个对水下检测极为有利的特性:
- 尺度感知:中心坐标梯度与GT框尺寸成反比------GT框越小,梯度越大,模型对小目标施加更强的优化驱动;
- 紧凑倾向:KL散度天然倾向于优化出比GT框略小的预测框,与水下场景中标注者对模糊目标采取保守标注(框略大于实际目标)的实践完全吻合。
3.2 DTJA:动态联合正样本分配
传统标签分配的问题
常见的固定top-k策略单纯依赖IoU选取正样本,在水下低对比度、密集遮挡场景中极易选到劣质正样本,导致训练噪声和假阳性增多。
DTJA的三步流程
第一步,构建联合度量矩阵M,将回归质量(基于GOL归一化到0,1)与分类置信度通过幂次加权相结合:
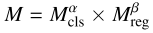
其中α和β控制两者的相对权重,回归度量归一化公式为 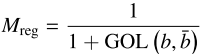
第二步,动态确定正样本数量。不同于固定top-k的静态策略,DTJA根据每个GT框的度量分布动态计算正样本数量:
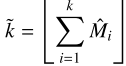
其中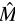 为降序排列后的度量值。其直觉是:容易检测的目标(高分数候选框多)分配更多正样本;难以检测的目标(分数普遍偏低)分配更少但更精准的正样本,避免噪声正样本污染训练。
为降序排列后的度量值。其直觉是:容易检测的目标(高分数候选框多)分配更多正样本;难以检测的目标(分数普遍偏低)分配更少但更精准的正样本,避免噪声正样本污染训练。
第三步,冲突消歧。当同一预测框被多个GT框竞争时,优先分配给回归质量最高的GT框,并从其余GT的候选列表中移除。
3.3 NFL:连续标签下的归一化Focal Loss
为什么需要NFL?
DTJA的联合度量矩阵M本质上是一个连续值(0到1之间),适合作为反映"定位质量"的软标签。然而标准FL仅支持0/1二值标签;而QFL(Quality Focal Loss)虽扩展到连续标签,但当正样本标签不等于1时,负样本惩罚项始终存在并与正样本惩罚项相互竞争,干扰优化收敛。
NFL的设计
NFL通过引入二值辅助标签 ti(仅区分"是否为正样本")来分离正负样本的惩罚计算:
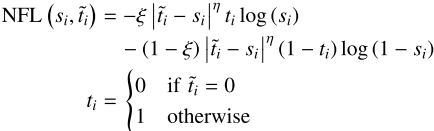
正负样本的惩罚计算彻底解耦,消除了QFL中的竞争梯度问题。NFL是FL的超集------当标签退化为0/1时,NFL与FL完全等价。
3.4 总损失函数
分类损失以DTJA的联合度量之和作为归一化分母,回归损失以联合度量加权GOL以抑制低质量BBox的负面影响,总损失为三部分的加权和:
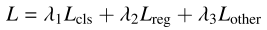
4. 实验设置
数据集
论文在五个水下数据集上进行了全面评估:
- URPC2022-optic:中国水下机器人大赛光学数据,4类目标(海参、海胆、扇贝、海星),低对比度、不均匀光照,训练/测试按8:2划分;
- URPC2022-sonar:同竞赛的声呐数据,10类目标;
- RUOD:14,000张图像,74,903个标注目标,10类,目标尺度较均衡(小:中:大 ≈ 21%:47%:32%),训练/测试按7:3划分;
- TrashCan:7,212张水下垃圾检测图像,含海洋碎片、ROV等;
- RUIE-UHTS:约300张图像,按图像质量分A--E五个等级。
评估指标
精度指标包括mAP、AP₅₀、AP₇₅(重点关注,反映严格定位精度)、APS/APM/APL、AR和ARS(小目标召回)。效率指标包括参数量、FLOPs、模型内存和FPS(在Jetson Orin NX上,FP16,batch=1)。训练资源指标包括GPU显存、训练时长和训练能耗。
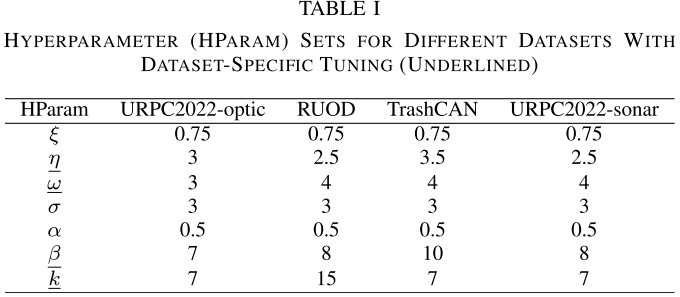
【配表:论文 Table I】不同数据集的超参数设置。
5. 实验结果
5.1 URPC2022-optic:核心基准
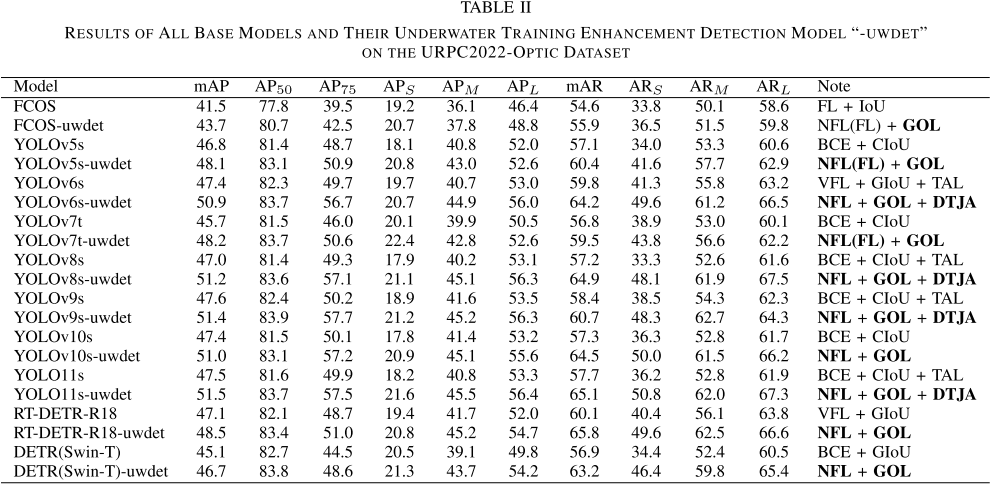
【配表:论文 Table II】所有基础模型与对应-uwdet增强版在URPC2022-optic上的完整对比结果。
Table II展示了最关键的结果。以YOLOv8s为例,mAP从47.0%提升至51.2%(+4.2%),AP₇₅从49.3提升至56.3(+7.0%),小目标召回ARS从32.6大幅跃升至48.1,提升高达14.8个百分点。
增益在所有架构上均一致出现,涵盖FCOS(+2.2%)、YOLOv5s(+1.3%)、YOLOv6s(+3.5%)、YOLOv7t(+2.5%),以及Transformer类模型DETR(Swin-T)(+1.3%)和RT-DETR-R18(+2.5%),充分说明方法对架构无偏好性。AP₇₅的显著提升表明增强方法在严格IoU条件下对定位精度的改善最为突出。
5.2 RUOD:均衡数据集上的验证
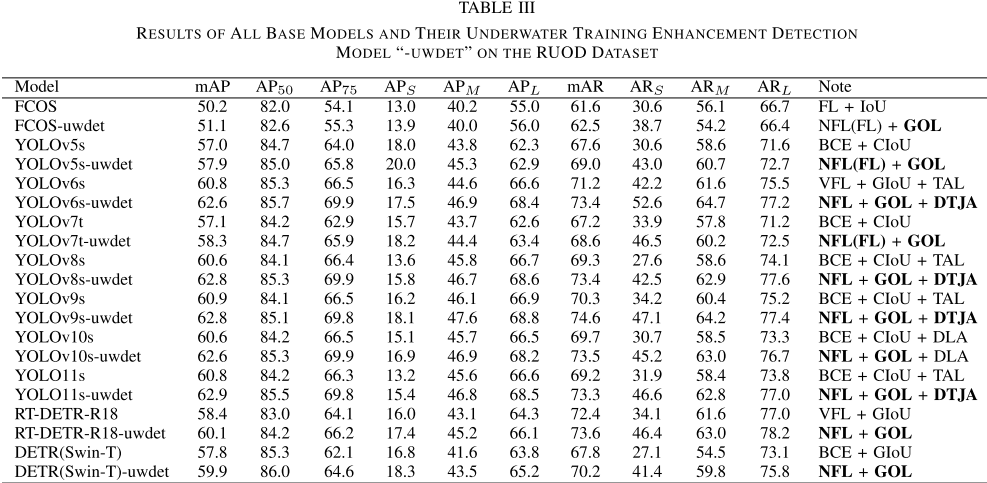
【配表:论文 Table III】所有基础模型与对应-uwdet增强版在RUOD上的完整对比结果。
RUOD数据集目标尺度较均衡,改进幅度相对温和,mAP提升约1--2个百分点,但AP₇₅仍有接近3.5%的提升(YOLOv6s-uwdet和YOLOv8s-uwdet)。
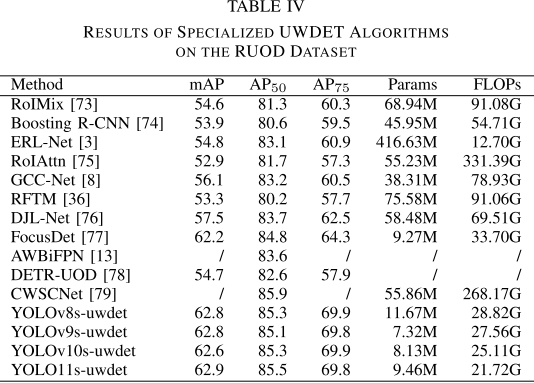
【配表:论文 Table IV】与专用水下检测算法在RUOD上的对比结果。
Table IV中,ERL-Net、FocusDet等专用方法虽然AP值有竞争力,但参数量和FLOPs均远高于本文方法。以YOLOv8s-uwdet为例(mAP 62.8%,参数11.67M,FLOPs 28.82G),对比FocusDet(mAP 62.2%,参数9.27M),本文方法以极低的计算代价达到SOTA级别的精度。
5.3 TrashCan与RUIE-UHTS:泛化能力验证
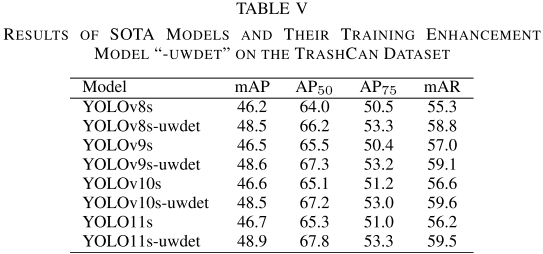
【配表:论文 Table V】在TrashCan数据集上的结果。
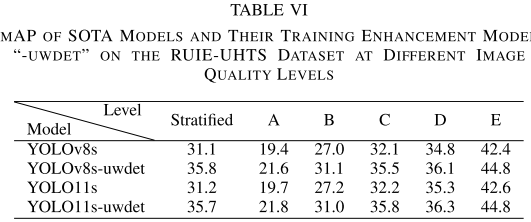
【配表:论文 Table VI】在RUIE-UHTS不同图像质量等级上的mAP结果。
TrashCan实验中,四个"-uwdet"增强版模型平均mAP提升约+2.13%,mAR提升更显著(+2.1%至+3.5%)。
RUIE-UHTS的结果揭示了一个重要规律:增益在图像质量较差的A--C等级最为明显,在高质量D--E等级增益较小,这与"高质量样本的提升空间有限"的直觉完全吻合。YOLOv8s-uwdet和YOLO11s-uwdet分别在分层随机划分上取得+4.7%和+4.5%的mAP提升。
5.4 URPC2022-Sonar:跨模态迁移
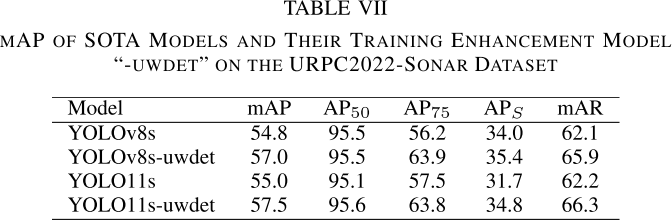
【配表:论文 Table VII】在URPC2022-Sonar数据集上的结果。
GOL/DTJA/NFL完全作用于监督信号和样本分配层面,与成像物理解耦。在声呐数据上,mAP提升2.2%--2.5%,AP₇₅提升高达6.3%--7.7%,证明方法可迁移至非光学模态,也暗示了在热红外、低光等场景的应用潜力。
6. 训练分析
6.1 收敛行为
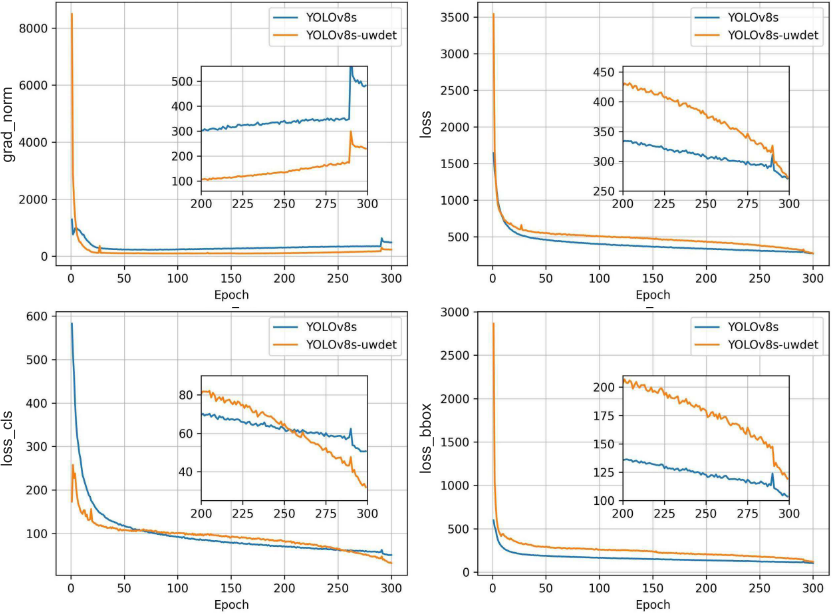
【配图:论文 Figure 4】梯度范数、总损失、分类损失、回归损失的训练曲线对比。
Figure 4对比了YOLOv8s与YOLOv8s-uwdet的训练动态。增强版模型呈现出更高的初始梯度范数(得益于GOL对小目标施加更强的梯度信号),以及更快、更平滑的损失下降,各损失曲线均更快收敛到更低值。
6.2 样本平衡分析
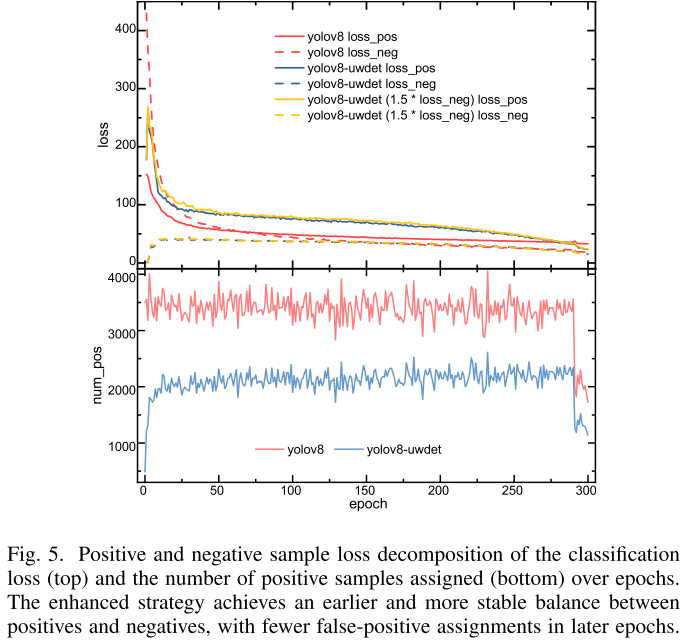
【配图:论文 Figure 5】分类损失的正负样本分解(上图)与正样本分配数量(下图)的训练曲线。
Figure 5的正负样本分解分析显示:原始YOLOv8s训练需要约150个epoch才能让负样本损失稳定,而YOLOv8s-uwdet在约50个epoch即实现稳定平衡。下图还直观展示了一个问题:原始方法在训练后期(mosaic增强关闭后)正样本分配数量反而增多,存在大量假阳性;而DTJA从一开始就以较少但更精准的正样本引导优化,始终维持更干净的分配质量。
7. 效率分析:训练更省,推理不变
这是本文最重要的特性之一:增强模型在推理时与基线完全等同。
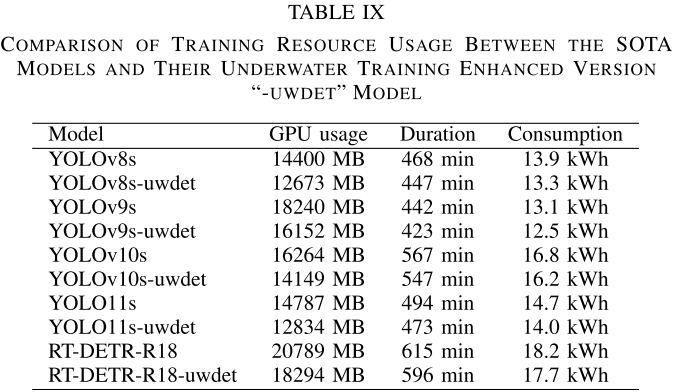
【配表:论文 Table IX】训练资源对比(GPU显存、训练时长、能耗)。
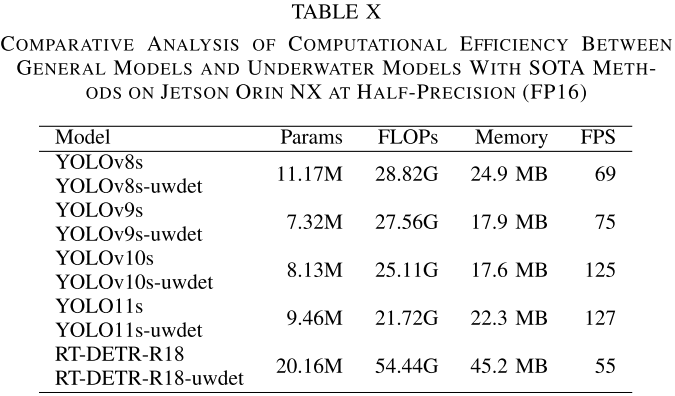
【配表:论文 Table X】在Jetson Orin NX上的边缘部署对比(参数量、FLOPs、内存、FPS)。
Table IX数据清晰呈现了训练资源的节省:在五对模型的平均统计中,GPU显存降低约2.1 GB(12.3%),训练时长缩短约20分钟(3.9%),设备级训练能耗降低约0.6 kWh(4.0%)。
Table X则证明了所有"-uwdet"版本与对应基线的参数量、FLOPs、内存占用和FPS完全一致。以YOLOv8s为例,参数量11.17M,FLOPs 28.82G,内存24.9MB,FPS 69,与YOLOv8s-uwdet完全相同,而检测精度则显著更高。
训练资源反而下降的原因在于:NFL将正负样本损失解耦降低了计算复杂度;DTJA减少了正样本总数,使每个epoch的有效计算量更少。
8. 消融实验与可视化
8.1 消融实验
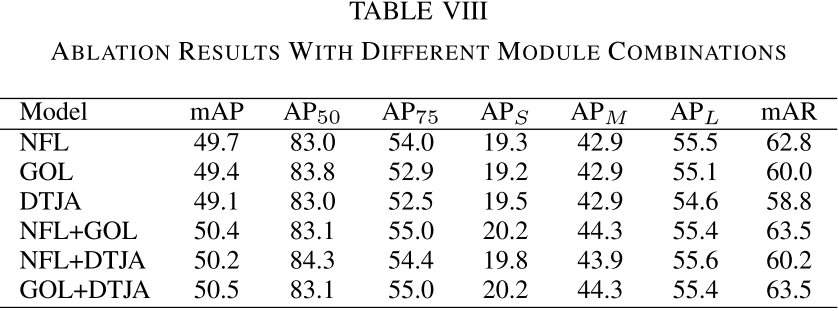
【配表:论文 Table VIII】各模块组合的消融实验结果。
Table VIII给出了各模块的独立和组合贡献,三个模块各自均有提升,且组合使用效果最优:
- NFL单独使用:mAP 49.7%,主要提升整体检测精度;
- GOL单独使用:mAP 49.4%,主要改善高IoU阈值下的性能,AP₇₅从39.5提升至52.5;
- DTJA单独使用:mAP 49.1%,单独增益较小,但与其他模块结合后显著提升小目标检测;
- 三者全部使用:mAP 51.2%,各项指标全面最优。
8.2 定性可视化

【配图:论文 Figure 2】通用检测器与-uwdet增强版的检测结果对比图。黑框为GT,绿框为正确检测,蓝框为漏检,红框为误检。
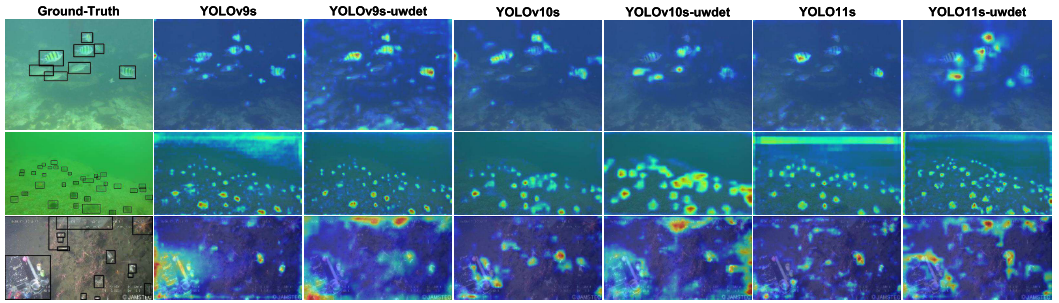
【配图:论文 Figure 3】激活热力图对比。
Figure 2的定性结果显示,增强模型在多种复杂场景下均显著减少了漏检和误检。YOLO11s-uwdet在复杂场景下漏检率较原始YOLO11s降低50%。Figure 3的类激活可视化揭示了机制层面的变化:"-uwdet"版本的热力图在目标区域更为集中和清晰,背景噪声和水中伪影的响应明显受到抑制。
8.3 错误分析
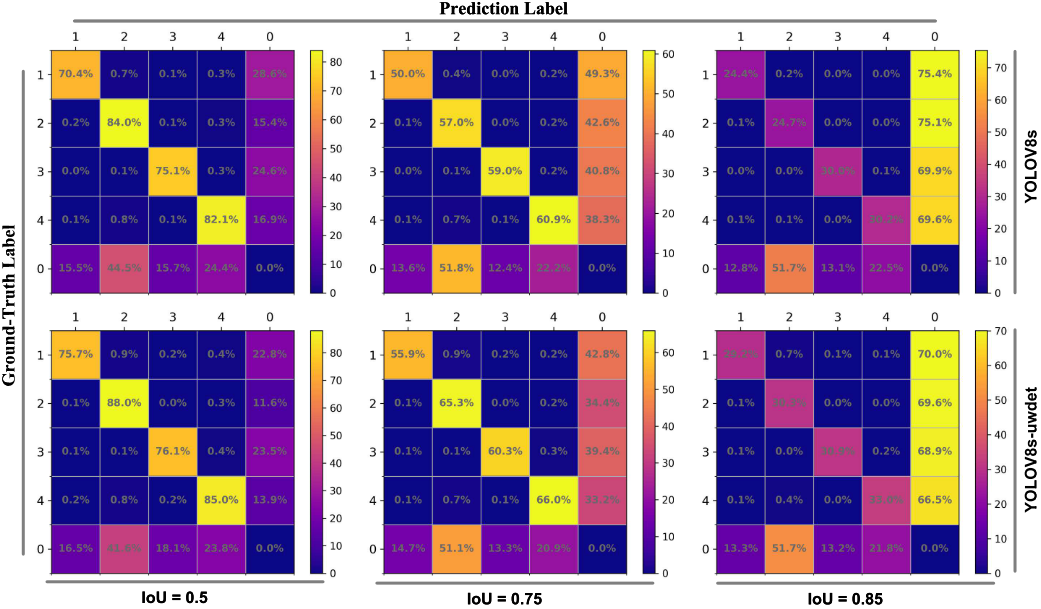
【配图:论文 Figure 6】YOLOv8s与YOLOv8s-uwdet在RUOD数据集上不同IoU阈值下的混淆矩阵对比。
Figure 6从错误类型角度进一步验证了增强效果。在IoU=0.50时,YOLOv8s-uwdet将各类平均漏检率(FNR)降低了3.3个百分点,并将背景误报率(FPR)从85.5%大幅压缩至71.8%(-13.7个百分点)。在更严格的IoU=0.75条件下,FNR平均降低5.2个百分点,背景FPR降低21.2个百分点,体现出更强的定位鲁棒性。
9. 局限性与未来方向
论文作者坦诚地指出了现有方法的局限:
- 标注质量依赖:精度仍受限于标注质量,尤其对小目标和遮挡目标;
- 轴对齐假设:当前的高斯分布假设采用对角协方差矩阵,对高度细长或旋转的目标可能拟合不足;
- 超参数敏感性:在极度杂乱的场景中,部分超参数可能需要微调;对于非常深的Transformer,GOL中的对数阻尼系数ω可能需要增大。
未来工作方向包括:旋转感知或全协方差GOL(椭圆Σ)、自适应超参数调整,以及向热红外、低光等其他复杂检测任务的扩展。
10. 总结
UWDET提供了一个优雅的解决范式:不在推理端增加负担,而是在训练端精心设计监督信号。GOL解决了IoU指标的几何盲区,DTJA让正样本分配更智能,NFL让分类损失能够感知定位质量。三者共同作用,在不触碰网络结构的前提下,让轻量化检测模型在水下这一极端场景中焕发新的活力。
对于在资源受限的IoT边缘设备上部署水下视觉系统的工程师和研究者而言,这一"只改训练、不改推理"的思路提供了极具价值的参考------让模型学得更好,有时比让模型变得更大更聪明。