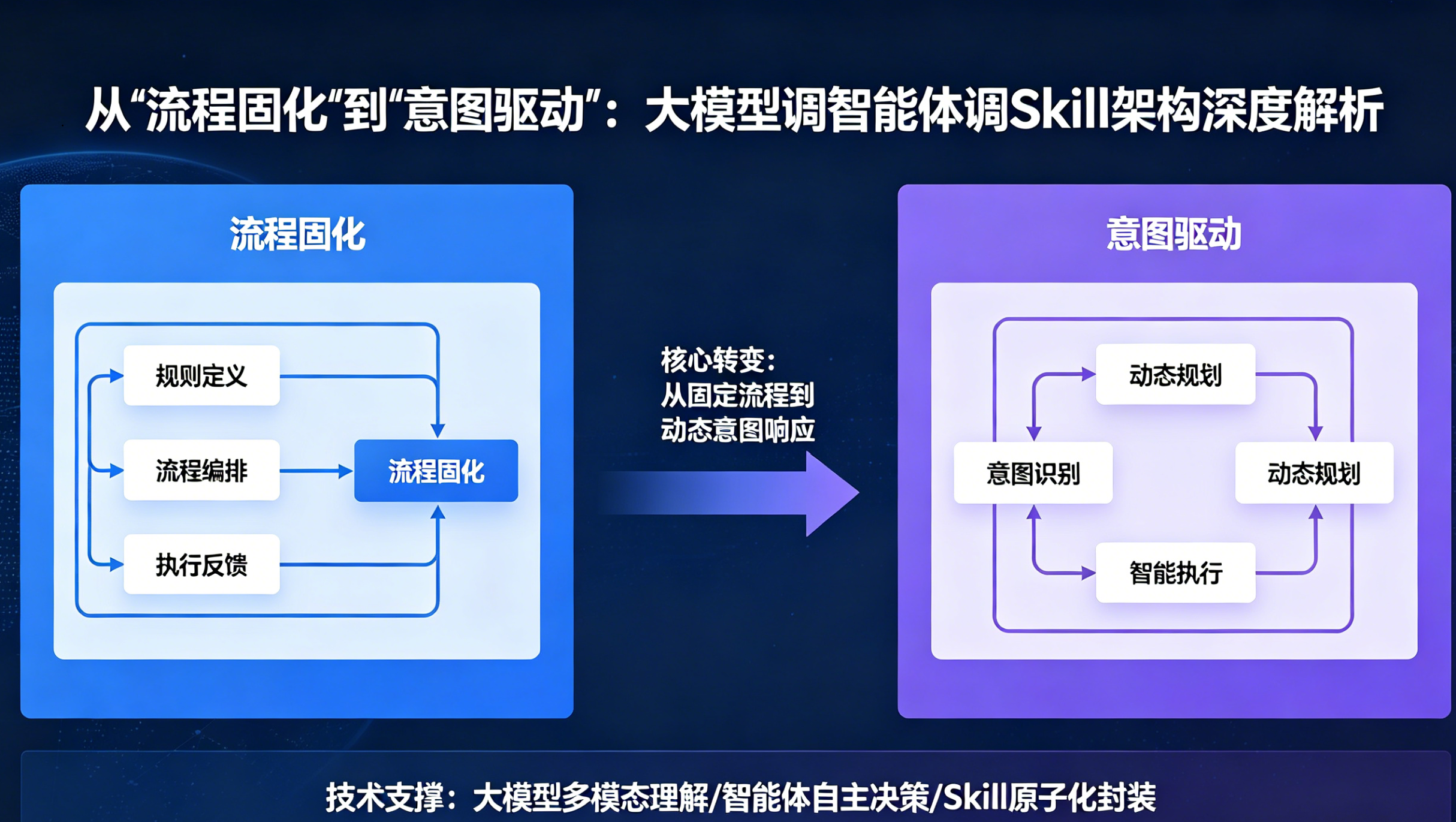
传统业务系统基于确定性逻辑构建:if-else分支、状态机、工作流引擎。业务进化意味着修改这些逻辑------提需求、排期、上线,周期以周或月为单位。大语言模型(LLM)的出现带来了新的可能性:让模型理解业务目标,动态编排已有能力,在执行中自我优化。这就是"大模型调智能体调Skill"的核心思想。
本文将深度拆解这套架构的三个层次、调用协议、设计原则以及如何形成业务进化的闭环。面向具备一定AI工程经验的读者,我们不仅讲概念,更讲落地的细节与权衡。
一、重新定义三层能力模型
1.1 为什么不是单一"大模型调API"?
许多人尝试过直接让LLM调用函数(Function Calling)。这在简单场景下有效,但业务系统面临三个挑战:
- 长期任务:一个业务目标可能需要多步推理、条件分支、甚至等待外部事件。
- 错误恢复:某个API失败后,需要重试、降级或切换策略。
- 状态管理:跨轮对话或异步执行需要记忆上下文。
因此需要引入**智能体(Agent)作为中间层,它具备环境感知、规划、记忆和执行能力。而技能(Skill)**则是Agent可调用的最小能力单元,对应一个确定性的业务操作。
1.2 三层定义与职责
| 层次 | 角色 | 输入 | 输出 | 典型技术载体 |
|---|---|---|---|---|
| 大模型 | 决策核心、任务规划器 | 用户自然语言意图 + 历史记忆 | 任务序列(Plan) | GPT-4、Claude、LLaMA 3,带结构化输出 |
| 智能体 | 任务执行器、状态管理者 | 高层任务计划 | 低阶技能调用序列 + 中间结果 | LangGraph、AutoGen、CrewAI、自研状态机 |
| 技能 | 原子业务操作 | 结构化参数(JSON Schema) | 结构化结果 + 执行元数据 | 云函数、API、SQL、REST endpoint |
调用关系并非简单的链式调用,而是一个递归的、带反馈的控制回路:
用户意图 → LLM规划 → Agent分解 → 调用Skill1 → 结果返回Agent →
Agent决策(成功/需修正)→ 调用Skill2 → ... → 最终结果 → LLM总结1.3 一个具体例子
用户说:"帮我查一下上周订单量最大的品类,然后给该品类的VIP用户发送一张8折优惠券。"
- LLM规划:输出JSON任务列表
json
[
{"action": "query_top_category", "params": {"time_range": "last_week"}},
{"action": "send_coupon", "params": {"category": "{{前一步.result}}", "user_segment": "VIP", "discount": 0.2}}
]- Agent执行 :维护变量上下文,先调用
query_top_categorySkill,拿到结果"运动鞋",再调用send_couponSkill。 - Skill实现 :
query_top_category执行SQL查询,返回{"category":"运动鞋","order_count":1230};send_coupon调用促销引擎API。
二、Skill设计:原子化与可观测性
业务进化的最小单元是Skill。如果Skill设计得粗糙,Agent无论怎么调度都无法产生高质量结果。
2.1 原子化原则
一个Skill只做一件明确的事,且不依赖外部上下文(所有参数显式传入)。
反面例子 :process_order 混合了库存检查、支付、发货通知。
正确拆分:
check_inventory(sku, quantity) → {available: bool, estimated_restock_date: date}
create_payment_intent(user_id, amount, currency) → {payment_id, status}
schedule_shipment(order_id, address) → {tracking_number, carrier}原子化带来三个好处:
- 可复用:不同Agent可以组合相同Skill。
- 可测试:每个Skill可单独单元测试。
- 可观测:失败时可以精确定位到最小环节。
2.2 标准化接口
每个Skill必须提供OpenAPI风格的定义,包含:
- 输入参数的JSON Schema(含类型、枚举、范围)
- 输出结果的JSON Schema
- 预期副作用(如"修改数据库"、"发送消息")
示例(YAML格式):
yaml
name: send_coupon
description: 向指定用户发送一张优惠券
input:
type: object
properties:
user_id:
type: string
pattern: '^USR-\d+$'
coupon_template_id:
type: string
expiry_days:
type: integer
minimum: 1
maximum: 365
required: [user_id, coupon_template_id]
output:
type: object
properties:
success: boolean
coupon_code: {type: string}
sent_at: {type: string, format: date-time}
side_effects: ['insert into coupon_issue_log']2.3 可观测性元数据
Skill的每次执行都应该返回或上报以下元数据,供Agent和LLM做后续决策:
| 字段 | 说明 |
|---|---|
duration_ms |
执行耗时 |
confidence |
结果置信度(如预测类Skill) |
retry_count |
重试次数 |
error_type |
失败时分类(network / business / permission / rate_limit) |
这些数据会进入执行轨迹(Trace),成为业务进化的燃料。
三、Agent实现模式:从ReAct到Plan-and-Execute
Agent负责将LLM的计划转化为对Skill的调用序列,并处理异常。这里介绍两种主流模式。
3.1 ReAct模式(Reason + Act)
LLM在每一步思考:"当前状态是什么?下一步应该调用哪个Skill?调用后预期得到什么?" 适合交互式、步骤数少的场景。
伪代码流程:
while not goal_achieved:
prompt = build_prompt(history, available_skills, current_state)
response = llm.generate(prompt) # 输出 Thought + Action + Action Input
if response.action == "finish":
break
result = call_skill(response.action, response.action_input)
history.append((response.action, result))- 优点:灵活性高,LLM可以动态纠错。
- 缺点:Token消耗大,容易陷入循环。
3.2 Plan-and-Execute模式
LLM首先生成完整计划(一系列Skill调用),然后由Agent执行引擎按顺序执行,支持条件跳转和并行。
关键组件:
- Planner:输出有向无环图(DAG)或线性步骤列表。
- Executor:解释计划,调用Skill,管理变量上下文,处理跳转。
- Checker:验证计划可行性(例如检查Skill输入输出类型是否匹配)。
LangGraph示例结构(Python风格):
python
from langgraph.graph import StateGraph, MessageGraph
class AgentState(TypedDict):
plan: List[Dict]
current_step: int
variables: Dict
final_answer: str
graph = StateGraph(AgentState)
graph.add_node("planner", llm_plan_node)
graph.add_node("executor", skill_executor_node)
graph.add_node("reflector", llm_reflect_node) # 可选的反思节点
graph.add_edge("planner", "executor")
graph.add_conditional_edges("executor", should_continue)3.3 多Agent协作
对于复杂业务,可以使用多个专职Agent(如"数据分析Agent"、"客服Agent"、"交易Agent"),由主控Agent进行任务分发。每个Agent内部有自己的Skill集合。这种模式更适合大型业务系统,因为职责隔离、易于调试。
四、业务进化闭环:数据驱动的自我优化
"Agent驱动业务进化"不是一句口号,而是通过以下三个机制实现的工程化设计。
4.1 反馈回路:执行轨迹 → 微调与优化
每次Agent完成一个任务,系统记录完整轨迹(Trace),包括:
- 用户原始意图
- LLM生成的计划
- 每个Skill的输入输出及元数据
- 最终结果是否成功
这些轨迹可以用于:
| 用途 | 说明 |
|---|---|
| 离线评估 | 计算计划执行成功率、平均Skill调用次数、耗时分布 |
| 错误分析 | 哪些Skill组合经常失败?是因为参数错误,还是Skill本身不稳定? |
| LLM微调 | 将成功的轨迹作为正样本,失败的轨迹作为负样本,微调Planner模型 |
| 动态Skill路由 | 如果某个Skill在特定条件下失败率超过阈值,Agent学习先调用"预处理Skill"(如数据清洗) |
4.2 策略学习:从固定流程到动态组合
传统工作流是人工预定义的路径。在Agent架构中,路径由LLM根据当前上下文动态生成。这意味着系统能够发现从未被程序员写过的成功模式。
例如,一个电商售后Agent遇到"用户要求换货但目标SKU无货"时,标准流程是告知无货。但通过实验,LLM可能生成新路径:
1. check_inventory(target_sku) → 无货
2. get_similar_skus(original_sku) → 返回3个推荐
3. ask_user_accept_similar() → 用户同意
4. create_exchange_order(new_sku)这个路径如果成功率高,可以被缓存为"模式",后续类似场景直接复用,降低LLM调用成本。
4.3 主动进化:Agent发现业务盲区
Agent不仅可以被动响应,还可以主动扫描系统状态。例如:
- 监控Skill调用频率的变化,发现某个入口功能使用量下降,推测产品流程有问题,自动在团队协作工具中创建工单:"检查XX功能是否被新UI隐藏"。
- 分析用户重复询问的问题,发现缺少一个"批量退款"Skill,自动提议新增该能力。
这种主动进化需要Agent具备元认知能力,通常通过定时运行一个"审计Agent"来实现。
五、实战案例:电商售后智能体
为了展示完整的技术实现,我们以电商售后场景为例,使用Plan-and-Execute模式构建一个Agent。
5.1 定义Skill集合
| Skill名称 | 输入 | 输出 | 实现方式 |
|---|---|---|---|
get_order_detail |
order_id | order_items, status, user_id | 订单中心API |
check_refund_eligibility |
order_id, user_id | eligible: bool, reason: string | 规则引擎 |
create_refund |
order_id, amount, reason | refund_id, status | 支付网关API |
send_notification |
user_id, message_template | sent: bool | 消息中心 |
get_inventory |
sku | available_qty | 库存服务 |
create_exchange |
order_id, old_sku, new_sku | exchange_id | 售后系统 |
5.2 Agent规划提示词设计
Planner的Prompt需要明确约束:
你是售后Agent规划器。根据用户需求生成一个JSON任务列表。
每个任务包含:skill_name, parameters (可以是常量或变量引用,变量用{{变量名}}表示)
可用Skill列表:
- get_order_detail: 需要order_id
- check_refund_eligibility: 需要order_id, user_id
- create_refund: 需要order_id, amount, reason
- send_notification: 需要user_id, message_template
- get_inventory: 需要sku
- create_exchange: 需要order_id, old_sku, new_sku
规则:
1. 如果用户要求退款,必须先检查资格。
2. 如果用户要求换货,必须先检查新SKU库存,无库存则不能创建换货。
3. 任何操作后都必须通知用户。
4. 变量使用双花括号,例如{{get_order_detail.user_id}}。
用户输入:{{user_input}}5.3 执行器核心逻辑(伪代码)
python
class Executor:
def __init__(self, skills_registry):
self.skills = skills_registry
self.variables = {}
def execute_plan(self, plan: List[Dict]) -> Dict:
for step in plan:
# 解析参数中的变量引用
resolved_params = self._resolve_variables(step["parameters"])
# 调用Skill
skill = self.skills[step["skill_name"]]
result = skill(**resolved_params)
# 存储结果到变量上下文,key为 skill_name_output
self.variables[f"{step['skill_name']}_output"] = result
# 检查业务异常(例如资格检查不通过)
if step.get("on_failure") == "abort" and not result.get("success"):
return {"status": "failed", "reason": result.get("error")}
return {"status": "success", "final_variables": self.variables}5.4 进化闭环:从一次换货请求看数据收集
用户输入:"我要把订单ORD-123中的蓝色M码T恤换成黑色L码,但我后天要出差。"
Agent生成的计划:
get_order_detail(order_id="ORD-123")get_inventory(sku="BLK-TS-L")- 条件判断:库存>0 → 执行
create_exchange;否则执行替代方案 send_notification
假设库存为0,Agent动态生成替代计划:
get_similar_skus(category="T恤", size="L", color="black")(假设有推荐Skill)- 向用户询问是否接受替代品
该轨迹被记录后,数据分析发现:"换货时原始SKU无货"的占比为23%。产品团队因此决定增加"相似商品推荐"功能作为标准流程,并开发了专门的 get_similar_skus Skill。这就是业务进化。
六、工程落地要点与最佳实践
6.1 安全围栏:防止失控
Agent再强大,也不能拥有无限权限。需要设置:
| 机制 | 说明 |
|---|---|
| 操作白名单 | 每个Agent只能调用其授权范围内的Skill |
| 频次限制 | 同一Skill单位时间内调用上限(如退款接口每分钟不超过10次) |
| 金额/数量上限 | 在参数层面钳制(如优惠券面额不超过50元) |
| 人工审批点 | 对于高风险操作(如批量退款、修改核心配置),Agent必须暂停并等待人工确认 |
实现方式:在Skill调用前增加一个Guard层,检查当前Agent会话的权限和配额。
6.2 人机协同:Human-in-the-loop
不是所有场景都适合全自动。推荐的成熟度模型:
| 等级 | 描述 | 适用场景 |
|---|---|---|
| L1 | 完全人工 | 新业务,无历史数据 |
| L2 | Agent推荐,人工确认 | 中等风险操作 |
| L3 | Agent执行,人工抽查 | 低风险、高频操作 |
| L4 | 全自动,事后审计 | 已验证的稳定路径 |
实现时,可以在Executor中插入 human_approval 节点:当计划中包含高风险Skill时,通过消息通道(如飞书、Slack)发送审批卡片。
6.3 可观测性:三大支柱
- Logs:每个Agent决策、Skill调用的结构化日志。
- Metrics:成功率、平均耗时、Token消耗、计划长度分布。
- Traces:完整的分布式追踪(从用户输入到最终输出)。
推荐使用OpenTelemetry协议,将数据导出到Jaeger或阿里云ARMS。
6.4 成本控制
LLM调用(尤其是Plan阶段)是主要成本来源。优化手段:
- 缓存常用计划:对于重复性高的请求(如"查询订单状态"),不经过LLM,直接映射到预定义计划。
- 小模型做路由:使用BERT等小模型判断用户意图,分流到不同Agent,减少LLM调用。
- 流式输出与早停:如果Agent已经收集到足够信息回答用户,可以中断后续Skill调用。
七、总结与展望
"大模型调智能体调Skill"不是简单地把LLM当作API网关,而是一种新的业务系统编程范式。它要求我们:
- 重新设计Skill:原子、可观测、结构化。
- 精心构建Agent:规划、执行、记忆、安全。
- 建立进化闭环:通过数据反馈持续优化策略。
目前,这一范式已经在客服自动化、智能运维、数据分析等场景展现出显著效果。未来,随着LLM推理能力的提升和成本的下降,Agent将从"辅助人类"走向"自主驱动业务",但核心原则不会变:让模型理解业务目标,让代码保障确定性,让数据驱动进化。
实践建议 :如果你正准备在自己的系统中落地这套架构,建议从一个低风险、高频的业务场景(如内部知识问答、工单分类)开始,先封装3-5个Skill,搭建一个简单的ReAct Agent,积累执行轨迹数据,再逐步扩展。
愿你在这条路上,不仅收获技术成长,更能看到业务因智能而进化的力量。