1.逻辑回归分类器

根据是否给模型提供标签,机器学习可分为监督学习(带标签)、无监督学习(无标签)、半监督学习(用一部分标签)、以及强化学习(目前还不太熟悉)。

然后根据任务来分,又可分为回归和分类,另外对于监督学习还包含集成学习(随机森林就算一种集成学习的方式 )、自监督学习(不给标签),请见本人另一篇文《结构特征提取的附录12》https://blog.csdn.net/m0_59777389/article/details/158431130?spm=1011.2415.3001.5331

ok,我们来看啥是逻辑回归。
逻辑回归是数据科学中的一种监督式 机器学习算法。它是一种分类算法,用于预测离散或类别的结果。
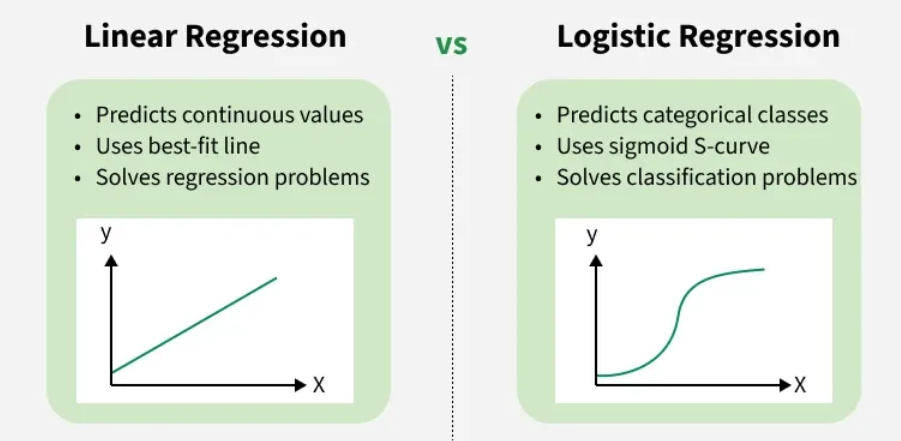
逻辑回归与线性回归一样,是一种线性模型 ,用于研究预测变量(自变量)与输出变量(响应变量、目标变量或因变量)之间的关系。关键区别在于线性回归适用于输出为连续值的情况------例如预测某人的信用评分。而逻辑回归则用于输出为分类值的情况,例如贷款是否获批。
在逻辑回归中,模型预测特定结果发生的概 率。模型的输出值介于 0 和 1 之间,基于一个阈值------通常为 0.5。 与线性回归中我们通过数据画一条直线不同,逻辑回归拟合一个 S 形曲线来将输入值映射到概率。
线性回归和逻辑回归都使用统计检验来评估哪些预测变量对输出有显著影响。t 检验和方差分析(ANOVA)(或逻辑回归中的似然比检验)等技术为每个系数生成 p 值,帮助我们判断关系是否具有统计学意义。低 p 值(通常低于 0.05)表明该变量对模型有显著贡献。
逻辑回归通常用于预测和分类问题。其中一些应用场景包括:
- 欺诈检测:逻辑回归模型可以帮助团队识别数据异常,这些异常可以预测欺诈行为。某些行为或特征可能与欺诈活动有更高的关联性,这对银行和其他金融机构在保护客户方面特别有帮助。基于 SaaS 的公司也开始采用这些做法,在分析业务表现时从数据集中消除虚假用户账户。
- 疾病预测:在医学领域,这种分析方法可用于预测特定人群患疾病或疾病的可能性。医疗组织可以为表现出更高倾向性特定疾病的个体建立预防性护理。
- 客户流失预测:特定行为可能在不同组织职能中预示着客户流失。例如,人力资源和管理团队可能想知道公司内是否有表现优异但面临离职风险的员工。这类洞察可以促使团队探讨公司内部存在的问题,如企业文化或薪酬制度。另一方面,销售团队可能希望了解哪些客户有流失到竞争对手的风险。这可以促使团队制定客户保留策略,以避免收入损失。
逻辑回归是一种用于分类问题的监督机器学习算法。与线性回归不同,它预测的是输入属于特定类的概率,而不是预测连续值。
- 它用于二元分类(但不仅限于二元分类任务,也可以实现多分类),其中输出可以是两种可能类别中的一种,例如是/否、真/假或 0/1。
- 它使用 Sigmoid 函数将输入转换为 0 和 1 之间的概率值。
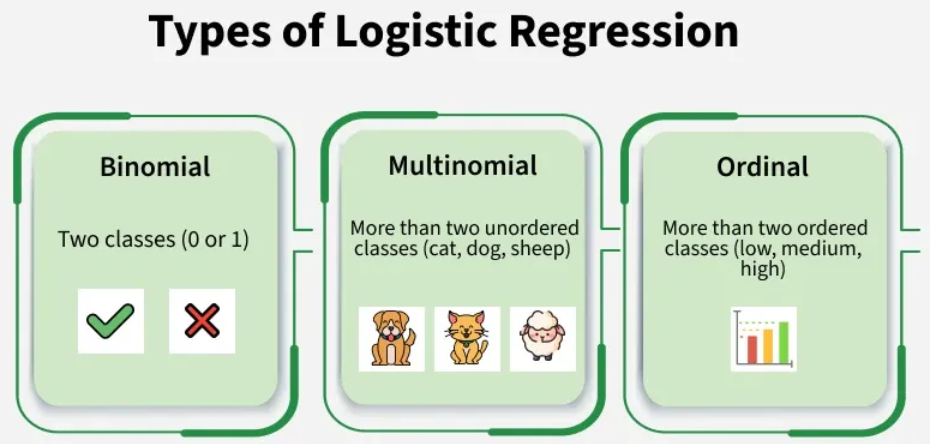
逻辑回归可以根据因变量的性质分为三种主要类型:
- 二元逻辑回归:当因变量只有两个可能的类别时使用这种类型。例如 Yes/No、Pass/Fail 或 0/1。这是最常见的逻辑回归形式,用于二元分类问题。
- 多项式逻辑回归:当因变量有三种或更多种可能的类别且这些类别无序时使用。例如,将动物分类为"猫"、"狗"或"羊"等类别。它将二项式逻辑回归扩展到处理多个类别。
- 序数逻辑回归:当因变量有三种或更多种具有自然顺序或等级的类别时使用。例如,评分如"低"、"中"和"高"。在建模时,它考虑了类别的顺序。
逻辑回归和线性回归在应用和输出上有所不同。以下是对比:
| Aspect 方面 | Linear Regression 线性回归 | Logistic Regression 逻辑回归 |
| Definition 定义 | Linear regression is used to predict the continuous dependent variable using a given set of independent variables. 线性回归用于使用一组给定的自变量来预测连续的因变量。 | Logistic regression is used to predict the categorical dependent variable using a given set of independent variables. 逻辑回归用于使用一组给定的自变量来预测分类的因变量。 |
| Problem Type 问题类型 | It is used for solving regression problem. 它用于解决回归问题。 | It is used for solving classification problems. 它用于解决分类问题。 |
| Output Type 输出类型 | In this we predict the value of continuous variables. 在此我们预测连续变量的值。 | In this we predict values of categorical variables. 在此我们预测分类变量的值。 |
| Curve/Model Fitting 曲线/模型拟合 | In this we find best fit line. 在此我们找到最佳拟合线。 | In this we find S-Curve. 在此我们找到 S 曲线。 |
| Estimation Method 估计方法 | Least square estimation method is used for estimation of accuracy. 最小二乘估计方法用于估计准确性。 | Maximum likelihood estimation method is used for estimation of accuracy. 最大似然估计方法用于估计准确性。 |
| Output Example 输出示例 | The output must be continuous value such as price, age etc. 输出必须是连续值,如价格、年龄等。 | Output must be categorical value such as 0 or 1, Yes or No, etc. 输出必须是分类值,如 0 或 1、是或否等。 |
| Relationship Requirement 关系要求 | It required linear relationship between dependent and independent variables. 它需要自变量和因变量之间存在线性关系。 | It not required linear relationship. 它不需要线性关系。 |
| Collinearity 共线性 | There may be collinearity between the independent variables. 自变量之间可能存在共线性。 | There should be little to no collinearity between independent variables. 自变量之间应该几乎没有或完全没有共线性。 |
|---|
参考文章
1.一个系统学习机器学习的地方:(偏重数学原理)
https://www.ibm.com/think/topics/logistic-regression#684929715
2.我很喜欢的一个学习网站geeksforgeeks,(理论+实战)
https://www.geeksforgeeks.org/machine-learning/understanding-logistic-regression/
3.scikit-learn官网API
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
4.《静态融合特征做分类任务(监督)》我的另一篇文章的附录7讲的也很棒
https://mp.csdn.net/mp_blog/creation/editor/158923553
2.SVM支持向量机

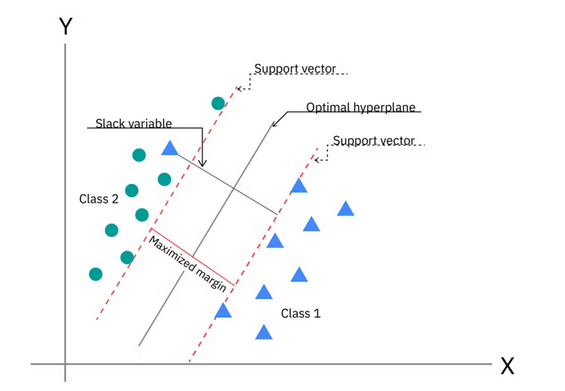
支持向量机是一种监督学习算法 ,主要用于分类 (也可用于回归,即 SVR)。其核心思想是:在特征空间中找到一个超平面,将不同类别的样本分开,并且使得离超平面最近的样本点(即支持向量)到超平面的距离(间隔)尽可能大。
直观理解:
想象二维平面上有两类点(用圆圈和叉表示),我们希望画一条直线将它们分开。SVM 的目标不是随便一条能分开的线,而是找到一条线,使得它离两侧最近的点都尽可能远。这条线就是最大间隔超平面 。那些离超平面最近的点(决定了间隔宽度)就是支持向量。
参考文章
1.《静态融合特征做分类任务(监督)》我的另一篇文章的附录10(推荐先看)
https://mp.csdn.net/mp_blog/creation/editor/158923553
2.还是那个系统学习机器学习的网站
https://www.ibm.com/think/topics/support-vector-machine#684929714
3.理解 Scikit-Learn 的 SVC:决策函数和预测(理论+实战)
4.scikit-learn官网API
https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html
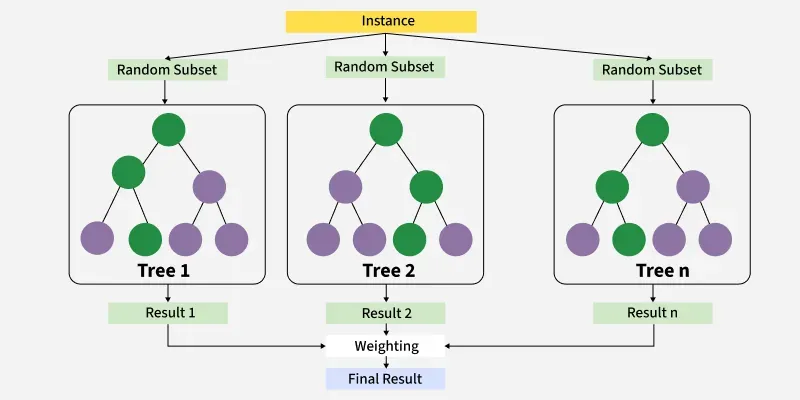
3.随机森林分类器
随机森林是一种集成机器学习算法,它构建多个决策树并将它们的预测结果结合起来以提高准确性和减少过拟合。在 Scikit-learn 中,随机森林分类器因其能够处理大型数据集且擅长处理非线性关系,而被广泛用于分类任务。
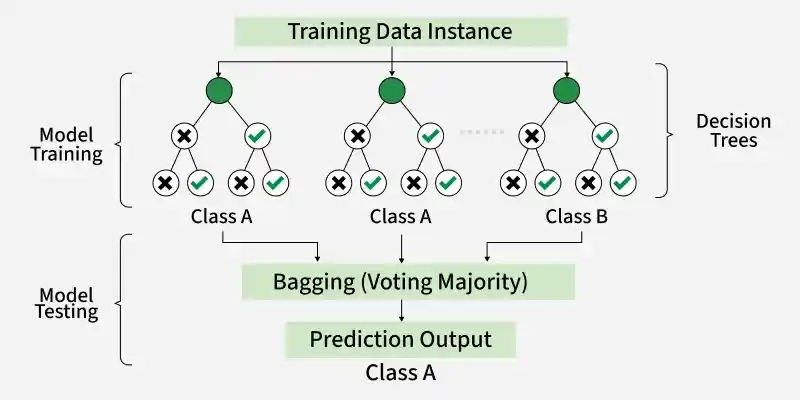
随机森林分类器的工作原理
- 自助采样:随机选取(允许重复)行来训练每棵树。
- 随机特征选择:每棵树使用一组随机特征(不是所有特征)。
- 构建决策树:树使用其随机特征集中的最佳特征来分割数据。分割持续进行直到满足停止规则(如最大深度)。
- 做出预测:每棵树给出自己的预测。
- 多数投票:最终预测是多数树同意的结果。
随机森林分类的优点:
- 随机森林可以处理大型数据集和高维数据。
- 通过结合多个决策树的预测,与单个决策树相比,它减少了过拟合的风险。
- 它对噪声数据具有鲁棒性,并且适用于分类数据。
在 Python 中实现随机森林分类
在Python 中实现随机森林分类器之前,让我们先了解它的参数。
- n_estimators: 森林中的树的数量。
- max_depth: 每棵树的最大深度。
- max_features: 每个节点用于分裂的特征数量。
- criterion: 用于衡量分裂质量的函数('gini' 或 'entropy')。
- min_samples_split: 分裂节点所需的最小样本数。
- min_samples_leaf: 叶节点所需的最小样本数。
- bootstrap: 构建树时是否使用自助采样(True 或 False)。
何时使用随机森林(以及何时不用)
当你需要一个开箱即用的强大基线模型时,随机森林是一个很好的选择。它们可以处理数值和分类特征,优雅地处理缺失值,并且比单个决策树更不容易过拟合。
使用随机森林的情况:
- 你拥有包含混合特征类型的表格数据
- 你希望得到一个稳健的模型,且不需要进行复杂的特征缩放或预处理
- 对于你的应用来说,可解释性(通过特征重要性)很重要
然而,当以下情况发生时,随机森林可能不是理想的选择:
- 你需要实时预测;它们可能比单个模型慢
- 你正在处理非常高维度的数据(例如文本或图像)
- 你希望在结构化数据上获得最先进的准确度,而梯度提升方法如 XGBoost 或 LightGBM 通常表现更优
参考文章
1.使用 Scikit-learn 的随机森林分类器(理论+实战)
https://www.geeksforgeeks.org/random-forest-classifier-using-scikit-learn/
2.随机森林分类的工作原理(理论+实战),讲到了使用Scikit-Learn 的RandomizedSearchCV
来调整模型的超参数,它将针对每个超参数在指定范围内随机搜索参数。
https://www.datacamp.com/tutorial/random-forests-classifier-python
3.scikit-learn官网API
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
4.《静态融合特征做分类任务(监督)》我的另一篇文章的附录11(推荐先看)
https://mp.csdn.net/mp_blog/creation/editor/158923553
4.xgboost分类器
XGBClassifier 是由 XGBoost 库提供的一种高效的机器学习算法,全称为 Extreme Gradient Boosting。它被广泛用于解决分类问题,例如预测一封邮件是否为垃圾邮件、客户是否会流失或交易是否为欺诈行为。XGBoost 是一种梯度提升决策树的实现,专为速度和性能而设计。
Key Features 关键特性
- 极端梯度提升:依次构建树,每个新树纠正前一个树的错误(残差)。
- 速度和性能:设计用于高计算速度和性能,具有并行树构建和优化的内部数据结构(
DMatrix)。 - 正则化:包含 L1(Lasso)和 L2(Ridge)正则化,以防止过拟合,这是复杂模型中常见的问题。
- 灵活性:支持多种数据类型和缺失值处理。
- 应用场景:广泛应用于欺诈检测、信用评分、客户流失预测和医学诊断等领域。
XGBClassifier 的用例
- 信用评分和风险预测:银行和金融机构使用 XGBClassifier 来预测贷款申请人是否可能违约。其高准确性和处理不平衡数据的能力使其成为信用风险建模的理想选择。
- 欺诈检测:在银行和电子商务等领域,它通过识别大型复杂数据集中的细微模式来帮助检测欺诈交易。
- 客户流失预测:电信、SaaS 和订阅型业务使用它来识别可能取消服务的客户,从而实现主动的保留策略。
- 医疗诊断:在医疗保健领域用于疾病分类,通过分析患者数据。它可以处理医疗记录中常见的缺失值和不平衡数据集。
- 垃圾邮件检测:使用标记的电子邮件数据进行训练,以分类传入的邮件是否为垃圾邮件,通常比传统模型的准确率更高。
Advantages 优点
- 梯度提升框架:XGBClassifier 基于梯度提升,其中树是按顺序构建的,使用梯度下降来最小化损失函数。
- 决策树集成:该模型结合了许多弱学习器(决策树)的预测,形成一个强分类器。
- 增量训练:新树被添加以纠正先前树所犯的错误,逐渐提高模型的准确性。
- 正则化:使用 L1(Lasso)和 L2(Ridge)正则化来控制模型复杂度并防止过拟合。
Disadvantages 缺点
- 复杂的超参数调优:XGBClassifier 具有许多超参数,如 max_depth、learning_rate、subsample、colsample_bytree、gamma 和正则化项。为特定问题找到合适的组合可能既耗时又计算成本高。
- 过拟合风险:尽管 XGBoost 包含正则化来防止过拟合,但如果未正确调优,它仍然容易过拟合。过拟合会导致训练精度很高,但在未见过的测试数据上泛化能力差。
- 更难解释:XGBClassifier 本质上是一个黑盒模型。虽然像 SHAP 和 LIME 这样的工具可以帮助解释预测,但它们又增加了另一层复杂性。与决策树或逻辑回归等更简单的模型相比,理解模型为何做出特定预测变得更加困难,这在可解释性重要的领域可能是一个问题。
Key Methods 关键方法
| 方法 | 描述 |
|---|---|
fit(X, y) |
在提供的数据和标签上训练分类器。 |
predict(X) |
预测新数据的类别标签。 |
predict_proba(X) |
预测新数据中每个类别的概率。 |
score(X, y) |
返回模型在给定数据和标签上的准确率。 |
set_params(...) |
设置估计器的参数。 |
get_params() |
获取估计器的参数。 |
save_model(fname) |
将模型保存到文件。 |
XGBClassifier 的参数
- n_estimators:定义提升轮次的数量。更多的树可以增加准确性,但也增加了过拟合的风险和训练时间。
- learning_rate:控制每棵树对最终预测的贡献程度。较低值使模型更稳健,但需要更多的树。
- max_depth:限制每个决策树的最大深度。更深的树可以捕捉更多模式,但可能会过拟合数据。
- subsample: 指定用于构建每棵树时使用的训练实例的比例。有助于防止过拟合。
- colsample_bytree: 构建每棵树时使用的特征比例。减少树之间的相关性,防止过拟合。
- gamma: 使叶节点进一步划分所需的最小损失减少量。作为正则化项,用于控制树的复杂度。
- reg_alpha(L1 正则化)和 reg_lambda (L2 正则化): 这些通过为较大的权重(系数)添加惩罚来帮助防止过拟合。L1 可能导致稀疏性(特征选择),而 L2 减小权重大小。
- objective:指定学习任务和相应的损失函数。
- scale_pos_weight:通过给予少数类更多的重要性,帮助处理不平衡分类任务。通常设置为负样本与正样本的比例。
- early_stopping_rounds:在带验证数据训练时使用,一旦评估指标停止提升,就停止训练过程。
参考文章
1.geeksforgeeks平台上的XGBClassifier教程(理论+实战)
https://www.geeksforgeeks.org/machine-learning/xgbclassifier/
2.《静态融合特征做分类任务(监督)》我的另一篇文章的附录12(推荐先看)
https://mp.csdn.net/mp_blog/creation/editor/158923553
3.xgboost官网API
https://xgboost.readthedocs.io/en/latest/python/python_api.html
4.更详细的实战还得看kaggle平台(有特征相关性分析+重要性分析)
https://www.kaggle.com/code/palanjali007/xgbclassifier
5.LightGBM分类器
LGBMClassifier 指的是 Light Gradient Boosting Machine Classifier(轻量级梯度提升机分类器)。它使用决策树算法进行排序、分类和其他机器学习任务。LGBMClassifier 采用了一种新颖的基于梯度的单边采样(GOSS)和排他性特征捆绑(EFB)技术,以高精度处理大规模数据,有效提高速度并减少内存使用。
参考文章
1.《静态融合特征做分类任务(监督)》我的另一篇文章的附录13(推荐先看)
https://mp.csdn.net/mp_blog/creation/editor/158923553
2.geeksforgeeks平台:使用 LightGBM 进行二分类(理论+实战)有特征之间的相关性分析+可视化单个特征的分布+使用计数图可视化分类特征与目标变量的关系
https://www.geeksforgeeks.org/machine-learning/binary-classification-using-lightgbm/
3.kaggle平台:Python 中的 LightGBM 分类器
https://www.kaggle.com/code/prashant111/lightgbm-classifier-in-python
4.lightgbm官网API
https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.LGBMClassifier.html
5.使用泰坦尼克号数据集,其中包含有关泰坦尼克号乘客的信息,目标变量表示他们是否幸存。的一个实战案例:
https://www.kdnuggets.com/2023/07/lgbmclassifier-gettingstarted-guide.html