
这里写目录标题
- 摘要
- 一、预备知识:4DGS
-
- [1. 动态位置偏移 (Dynamic Position)](#1. 动态位置偏移 (Dynamic Position))
- [2. 时间透明度衰减 (Temporal Opacity)](#2. 时间透明度衰减 (Temporal Opacity))
- [3. 4D 球谐函数颜色建模 (4D Spherical Harmonics)](#3. 4D 球谐函数颜色建模 (4D Spherical Harmonics))
- 二、神经衰减函数
- 三、基于可见性的衰减策略(区分不同区域做衰减)
- 实验
标题:4C4D: 4 Camera 4D Gaussian Splatting
来源:清华大学软件学院;快手科技
链接:https://junshengzhou.github.io/4C4D
摘要
本文致力于解决仅需四台便携式相机拍摄视频即可重建四维动态场景的技术难题。在计算机图形学领域,学习场景动态建模以实现时间一致性新视角渲染是基础性任务,传统方法通常需要通过数十甚至数百个视角的相机阵列获取密集多视角数据。我们提出4C4D框架,该创新方案能够从极稀疏相机拍摄的视频中实现高保真四维高斯贴片重建。
核心发现在于:稀疏场景下的几何建模难度远超外观建模 。基于此认知,我们 引入高斯不透明度的神经衰减函数,显著提升4DGS的几何建模能力 。该设计通过引导4DGS梯度更聚焦几何学习,有效缓解了模型中几何建模与外观建模的固有失衡。在不同相机重叠率的稀疏视角数据集上开展的大量实验表明,4C4D方案相较现有技术展现出更优的性能表现。
一、预备知识:4DGS
1. 动态位置偏移 (Dynamic Position)
σ ( t ~ ) = σ + ∑ 1 : 3 , 4 ∑ 4 , 4 − 1 ( t ~ − μ t ) --- (1) \sigma(\tilde{t}) = \sigma + \sum\nolimits_{1:3,4} \sum\nolimits_{4,4}^{-1}(\tilde{t} - \mu_t) \quad \text{--- (1)} σ(t~)=σ+∑1:3,4∑4,4−1(t~−μt)--- (1)
其描述了高斯中心点 σ \sigma σ 随时间 t ~ \tilde{t} t~ 的平移轨迹 。 它利用 4D 协方差矩阵的逆矩阵(分块矩阵形式)来建立空间与时间的线性耦合。这意味着位置的变化不仅仅是随机的,而是由高斯的时空关联属性决定的,从而实现了平滑的运动轨迹。
2. 时间透明度衰减 (Temporal Opacity)
o ( t ~ ) = ω ( t ~ ) ∗ o --- (2) o(\tilde{t}) = \omega(\tilde{t}) * o \quad \text{--- (2)} o(t~)=ω(t~)∗o--- (2) ω ( t ~ ) = exp ( − 1 2 ( t ~ − μ t ) 2 Σ 4 , 4 ) --- (3) \omega(\tilde{t}) = \exp(-\frac{1}{2} \frac{(\tilde{t} - \mu_t)^2}{\Sigma_{4,4}}) \quad \text{--- (3)} ω(t~)=exp(−21Σ4,4(t~−μt)2)--- (3)
上式定义了高斯的生命周期。其中 ω ( t ~ ) \omega(\tilde{t}) ω(t~) 是一个随时间变化的权重因子 。 4DGS 给每个高斯增加了一个时间上的"高斯窗"。 μ t \mu_t μt 是该高斯影响最强的时刻。 Σ 4 , 4 \Sigma_{4,4} Σ4,4 控制了该高斯在时间轴上的持续时长(Duration)。直观理解: 一个高斯会在特定时间点逐渐"显现",达到峰值后再逐渐"消失",这为处理物体的出现、消失和剧烈形变提供了极大的灵活性。
3. 4D 球谐函数颜色建模 (4D Spherical Harmonics)
c ( t , θ , ϕ ) = cos ( 2 π n T t ) Y l m ( θ , ϕ ) --- (4) c(t, \theta, \phi) = \cos(\frac{2\pi n}{T}t) Y_{lm}(\theta, \phi) \quad \text{--- (4)} c(t,θ,ϕ)=cos(T2πnt)Ylm(θ,ϕ)--- (4)
描述了颜色 c c c 如何受时间 t t t、观察角度 ( θ , ϕ ) (\theta, \phi) (θ,ϕ) 的共同影响 。 传统的 3DGS 使用球谐函数(SH)来表现视角相关的颜色(外观)。4DGS 在此基础上引入了傅里叶级数(由 cos \cos cos 项体现),将时间周期性融入外观模型 。这使得模型能够捕捉随时间变化的光影效果(如物体的金属光泽随运动改变,或动态的光源照射)。例如对于 K = 2 K=2 K=2(越高的越能拟合高频闪烁):给定当前帧的时间 t t t,计算傅里叶基函数的值向量,计算得出 1 , cos ( 2 π T t ) , cos ( 4 π T t ) 1, \\cos(\\frac{2\\pi}{T}t), \\cos(\\frac{4\\pi}{T}t) 1,cos(T2πt),cos(T4πt) 。系数融合(核心): 将这些标量值与存储的张量 W n , l , m W_{n,l,m} Wn,l,m 沿着时间维度 n n n 进行加权求和。
二、神经衰减函数
核心痛点:稀疏视角下的优化偏差 (Biased Optimization)
-
外观过拟合 (Appearance Overfitting): 模型单纯通过调整高斯的颜色(RGB)来完美拟合训练视角的图像。
-
几何崩塌 (Geometry Neglect): 由于缺乏足够的空间几何监督,模型构建的底层深度(Depth)和几何结构是混乱的。
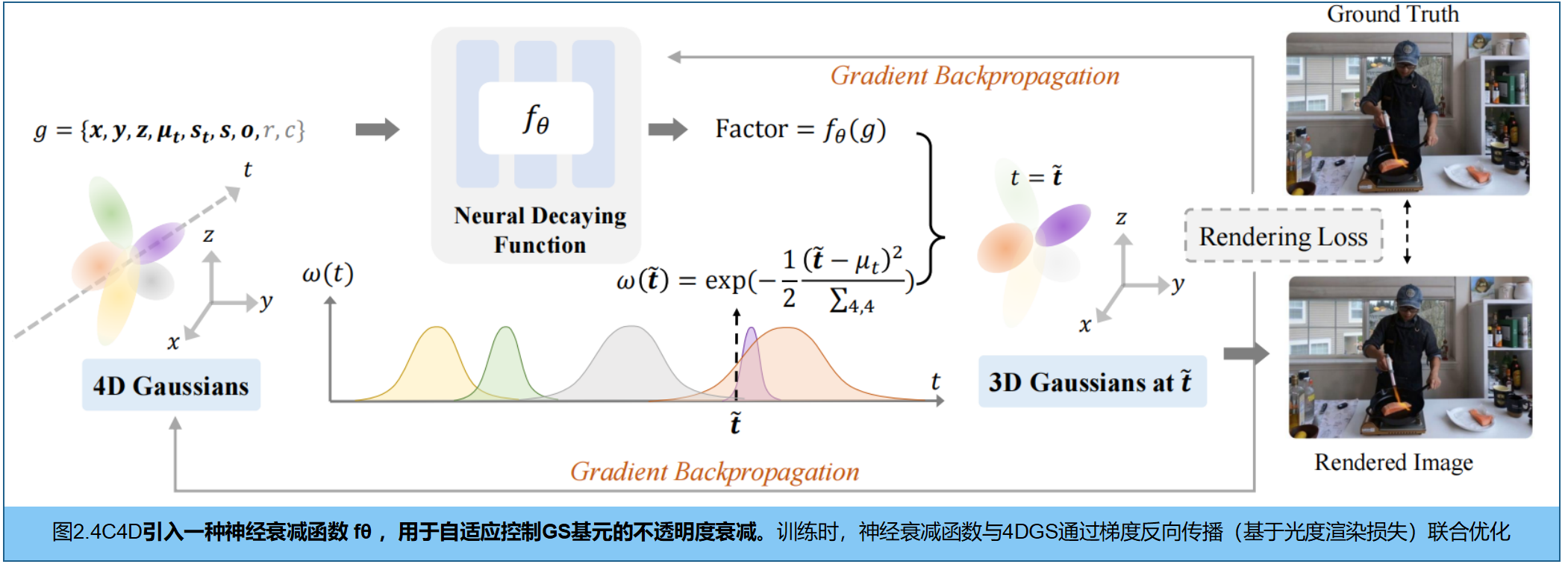
为纠正这种偏差,作者引入一个由简单神经网络实现的神经衰减函数 f θ f_\theta fθ,旨在将优化的注意力"强制拉回"到几何结构的构建上:
τ = f θ ( x , y , z , o , r ) ( 5 ) \tau = f_\theta(x, y, z, o, r)(5) τ=fθ(x,y,z,o,r)(5)
其将每个 4D 高斯基元的关键空间几何属性------中心位置 ( x , y , z ) (x, y, z) (x,y,z)、初始不透明度 o o o 和旋转参数 r r r 作为输入,送入神经网络 f θ f_\theta fθ,预测衰减因子 τ \tau τ 。模型根据gs姿态和位置,动态决定是否抑制。最终的不透明度加入预测的衰减因子 τ \tau τ :
o ( t ~ ) = τ ∗ exp ( − 1 2 ( t ~ − μ t ) 2 Σ 4 , 4 ) ∗ o ( 6 ) o(\tilde{t}) = \tau * \exp(-\frac{1}{2} \frac{(\tilde{t} - \mu_t)^2}{\Sigma_{4,4}}) * o(6) o(t~)=τ∗exp(−21Σ4,4(t~−μt)2)∗o(6)
4D 高斯在 t ~ \tilde{t} t~ 时刻的最终不透明度,不仅受原本的时间高斯窗(指数衰减部分)控制,还受神经网络基于空间几何特征输出的 τ \tau τ 的神经调制 (Neural Modulation)。这改变了反向传播时梯度的流动分布:削弱了模型单纯依靠改变颜色来降低 Loss 的倾向,迫使优化过程将更多的梯度分配给几何参数(如位置、缩放),从而在"外观拟合"和"几何保真度"之间实现了平衡。最终在不丢失渲染质量的前提下,获得了干净、一致的深度结构。
延申 :只靠渲染损失,在没有任何正则化的情况下,改变高斯的颜色(RGB/SH系数)或直接提高错误位置高斯的不透明度(Opacity) 是阻力最小、见效最快的途径。此时,模型会生成大量漂浮在半空中的"Floaters(伪影)"。衰减因子网络 f θ ( x , y , z , o , r ) f_\theta(x,y,z,o,r) fθ(x,y,z,o,r)相当于对不合理的空间位置的gs一个惩罚因子 τ \tau τ。效果见图3:
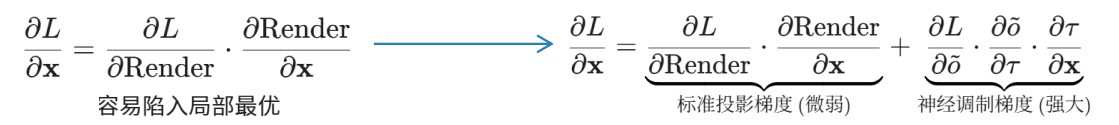

三、基于可见性的衰减策略(区分不同区域做衰减)
在可微渲染中,只有那些被当前相机视角"看到"的高斯才会参与渲染并获得梯度 ;对其他遮挡gs施加神经衰减 f θ f_\theta fθ,由于缺乏渲染梯度,它们的参数会被错误地扭曲,导致整个优化过程失去平衡(性能下降)。判断依据(从两个维度) :只有在空间和时间上都双重可见的高斯才会被标记为 G m G_m Gm。 G m = Z V ( v ~ , σ , Z T ( t ~ , s t , G ) ) ( 7 ) G_m = Z_V(\tilde{v}, \sigma, Z_T(\tilde{t}, s_t, G))(7) Gm=ZV(v~,σ,ZT(t~,st,G))(7)
-
空间维度 Z V Z_V ZV: 检查高斯中心 σ \sigma σ 是否在当前相机视角 v ~ \tilde{v} v~ 的视锥体内。
-
时间维度 Z T Z_T ZT: 检查当前时间点 t ~ \tilde{t} t~ 是否落在该高斯的持续时长(Duration) s t s_t st 之内。
分离衰减策略 (Separate Decay Strategy) :基于可见性,作者定义了最终的衰减因子 τ ( g ) \tau(g) τ(g):
τ ( g ) = { f θ ( x , y , z , o , r ) if g ∈ G m β if g ∈ G m ∗ ( 8 ) \tau(g) = \begin{cases} f_\theta(x, y, z, o, r) & \text{if } g \in G_m \\ \beta & \text{if } g \in G_m^* \end{cases}(8) τ(g)={fθ(x,y,z,o,r)βif g∈Gmif g∈Gm∗(8)
-
对于可见高斯 ( g ∈ G m g \in G_m g∈Gm): 使用神经网络 f θ f_\theta fθ 预测衰减值。这是为了利用前面提到的"梯度重分配"来精细地优化几何结构。
-
对于不可见高斯 ( g ∈ G m ∗ g \in G_m^* g∈Gm∗): 直接给一个接近 1 的常数 β \beta β(文中设定为 0.999)。
实验
数据集。针对四个数据集:
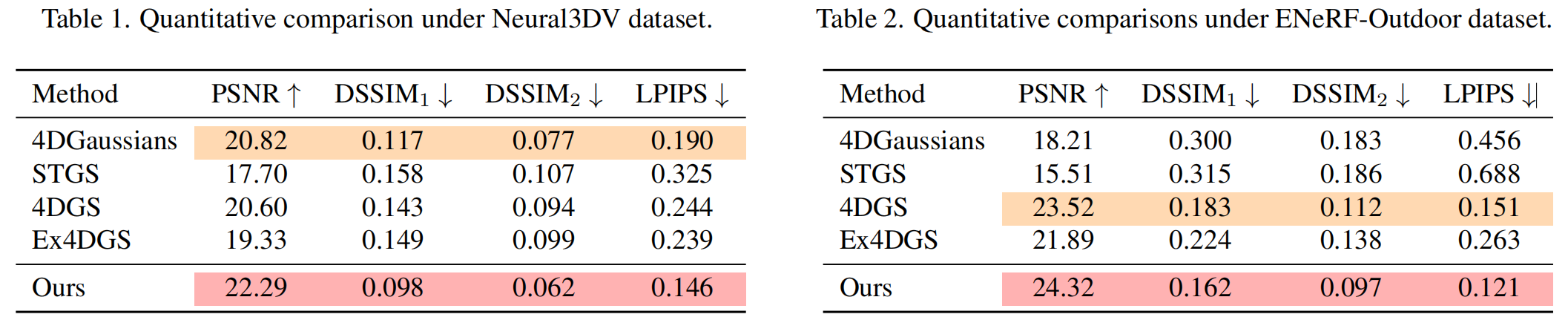
- Neural3DV19是广泛使用的多视角视频数据集,包含六个动态场景。每个场景通过18-21个摄像头以2704×2028分辨率和30帧/秒的帧率录制。沿用既往研究方法,我们在训练前对图像进行0.5倍下采样,并采用每个场景的前300帧用于训练和评估。在稀疏视角设置中,选取最远位置的四个摄像头作为训练视角,其余摄像头视频作为测试视角。
- ENeRF-Outdoor22包含由18个摄像头阵列拍摄的三个户外动态场景,视频以1920×1080分辨率和60帧/秒的帧率录制。我们沿用Neural3DV中四摄像头的训练/测试分割策略。
- Mobile-Stage数据集由4K4D45发布,包含高度动态多人舞蹈表演的复杂场景,采用24个摄像头以1920×1080分辨率录制。训练时选取四个大范围重叠视角,其余视角作为测试数据。
- 最后,鉴于现有数据集均采用约20台设备的密集阵列拍摄,我们额外收集了仅使用四台便携式GoPro风格相机采集的Dyn4Cam数据集。视频以60帧/秒的帧率录制,分辨率为1920×1080,每个场景包含300帧。由于Dyn4Cam未包含保留测试视图,我们仅针对该数据集提供定性比较结果。


#pic_center =40%x80%
d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ D ^ \hat{D} D^ I ~ \tilde{I} I~ ϵ \epsilon ϵ
ϕ \phi ϕ ∏ \prod ∏ a b c \sqrt{abc} abc ∑ a b c \sum{abc} ∑abc
/ $$ E \mathcal{E} E