博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战8年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈
采用 Python 语言开发,基于 Flask 框架搭建后端服务,使用 MySQL 数据库进行数据存储,通过 requests 爬虫从长江水文网获取水文数据,运用多元线性回归预测算法和 scikit-learn 库进行机器学习预测分析,前端结合 Echarts 可视化库与 Layui 框架实现数据展示与界面开发。
功能模块
· 用户登陆注册模块
· 水文数据管理模块
· 水文数据可视化模块
· 水文数据预测模块
· 公告模块
项目介绍
本系统利用爬虫技术从长江水文网自动获取水文监测数据,经处理后存入 MySQL 数据库。系统提供用户登录注册、水文数据管理与可视化、水文预测分析及公告等功能。通过 Echarts 展示水源地实时流量分布、历史水位与流量变化趋势,并基于多元线性回归算法建立预测模型,对未来水位和流量进行预测。系统采用 Flask 构建数据接口服务层,为水文学研究和水资源管理提供精确的数据支持与决策依据。
2、项目界面
(1)数据概况
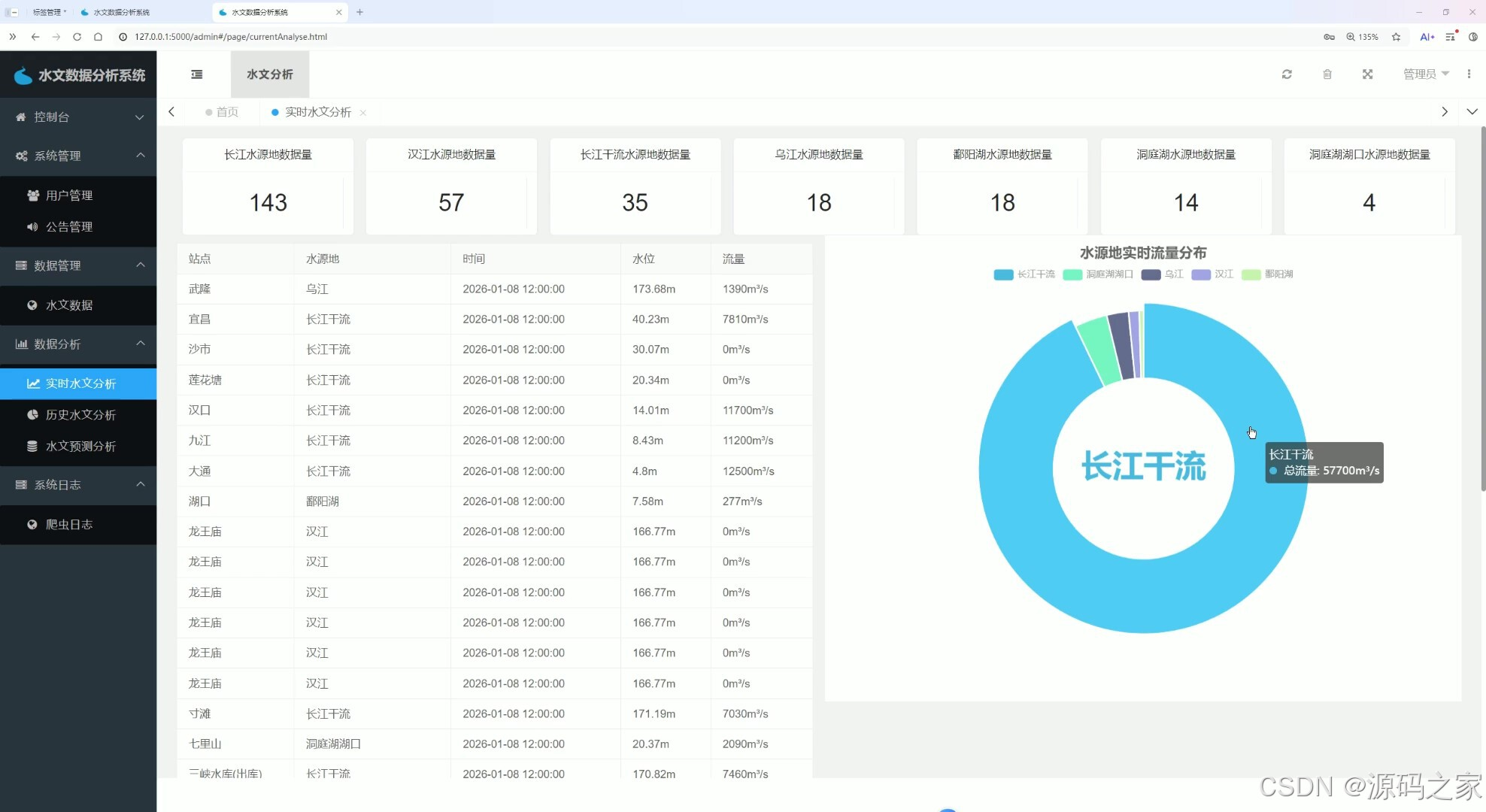
该页面为水文数据分析系统的实时水文分析页,展示各水源地数据量统计卡片、水文监测站点的水位流量数据表格,以及水源地实时流量分布环形图,呈现实时水文监测数据与流量分布情况。
(2)历史水文分析
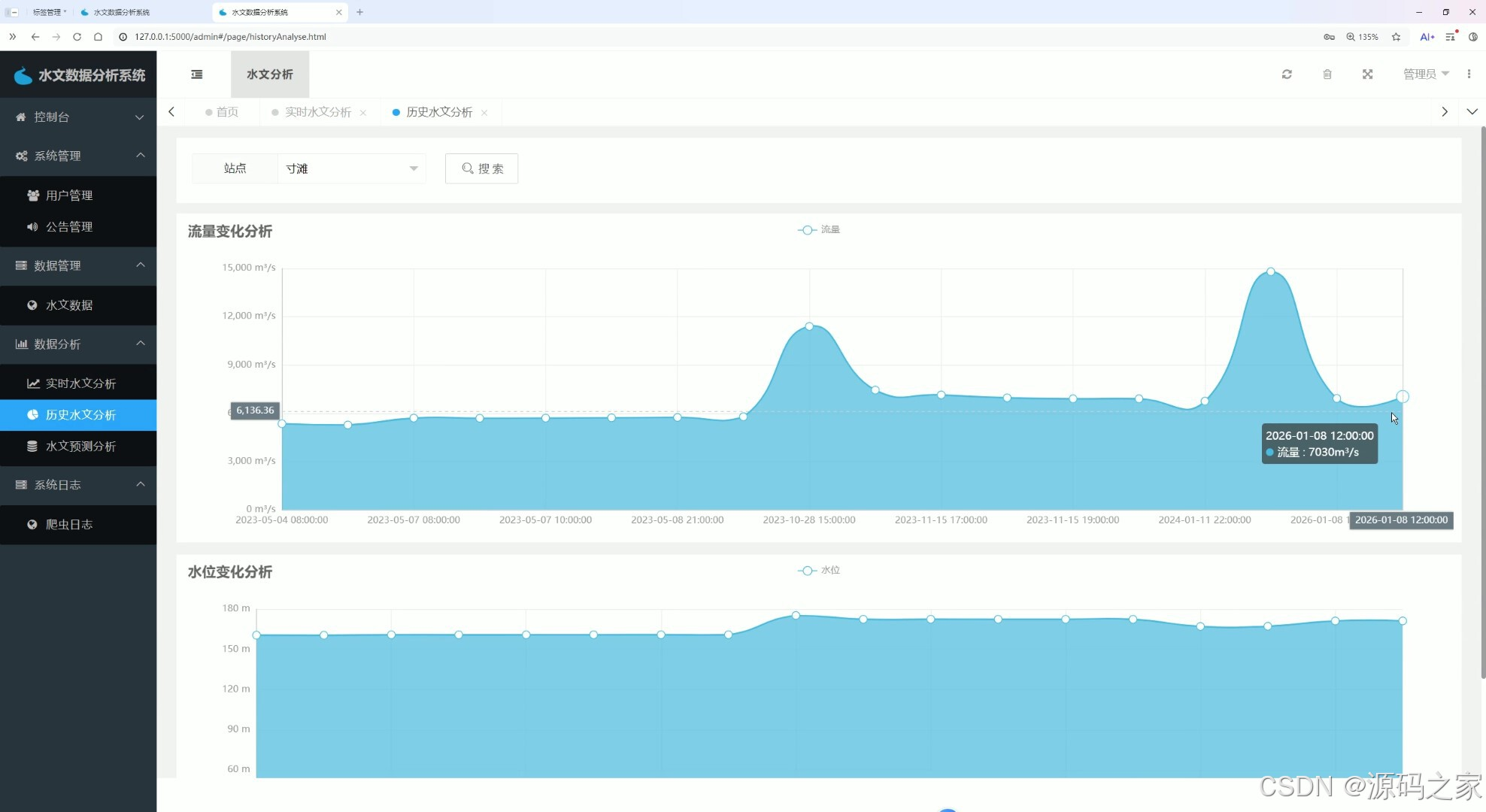
该页面为水文数据分析系统的历史水文分析页,提供站点筛选与搜索功能,通过流量变化分析面积折线图和水位变化分析面积折线图,直观呈现所选站点历史流量与水位的时间变化趋势。
(3)水文预测分析
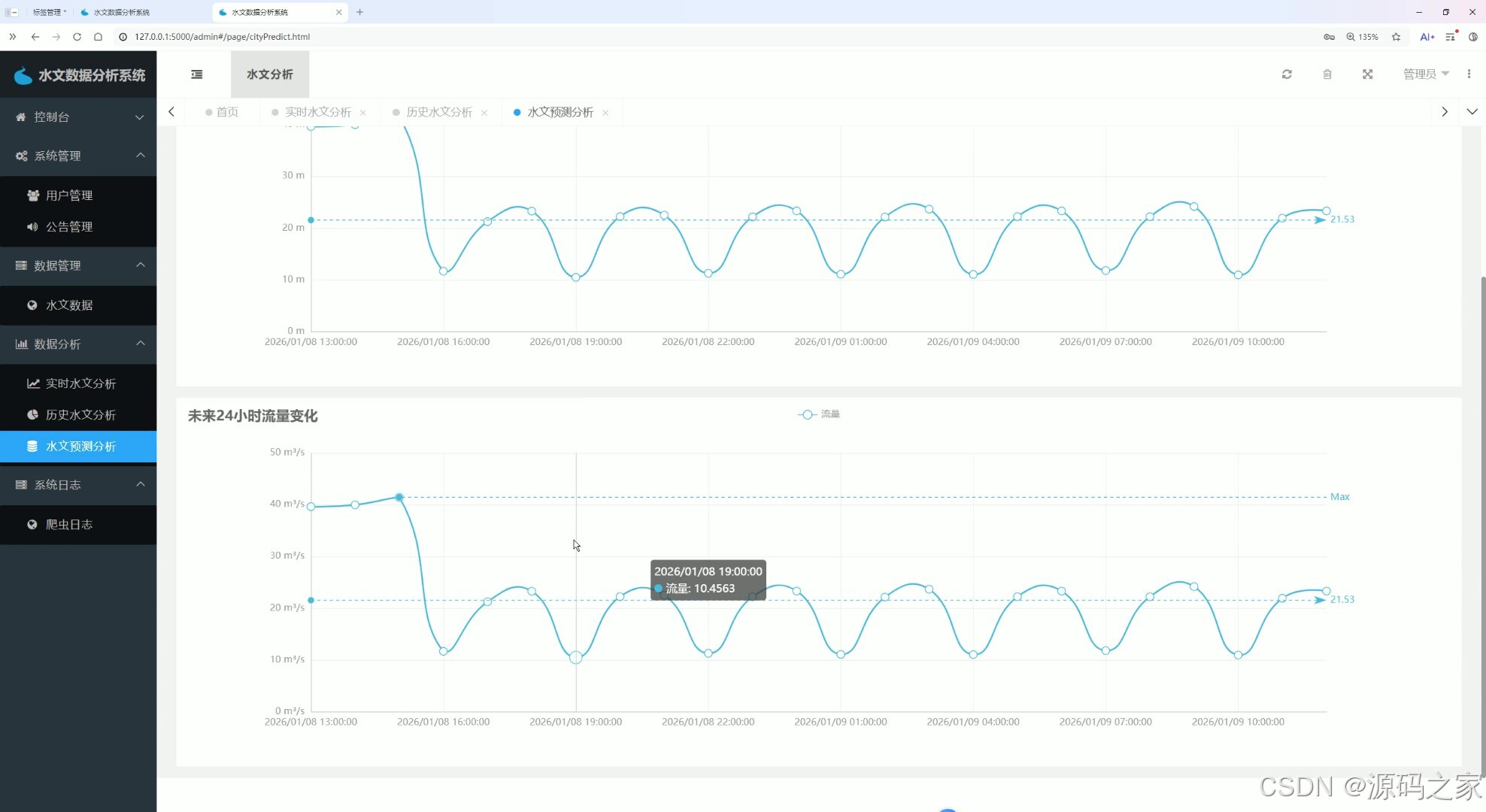
该页面为水文数据分析系统的水文预测分析页,通过水位变化预测折线图和未来24小时流量变化预测折线图,直观呈现水文数据的未来变化趋势,为水文预警与决策提供数据支撑。
(4)水文数据
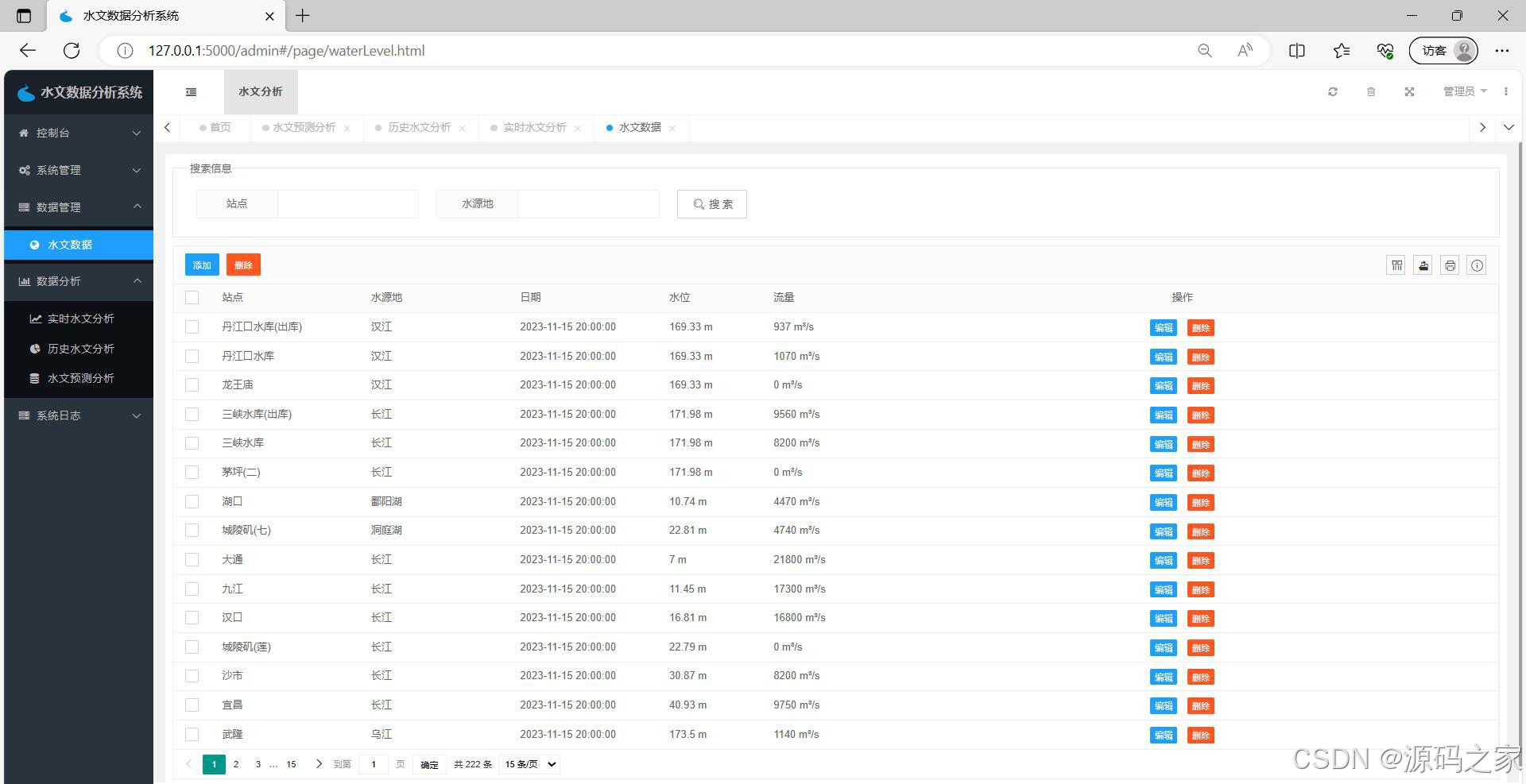
该页面为水文数据分析系统的水文数据页,提供站点和水源地的搜索功能,以表格形式展示各监测站点的水文数据,支持数据的添加、删除、编辑操作,实现水文数据的管理与维护。
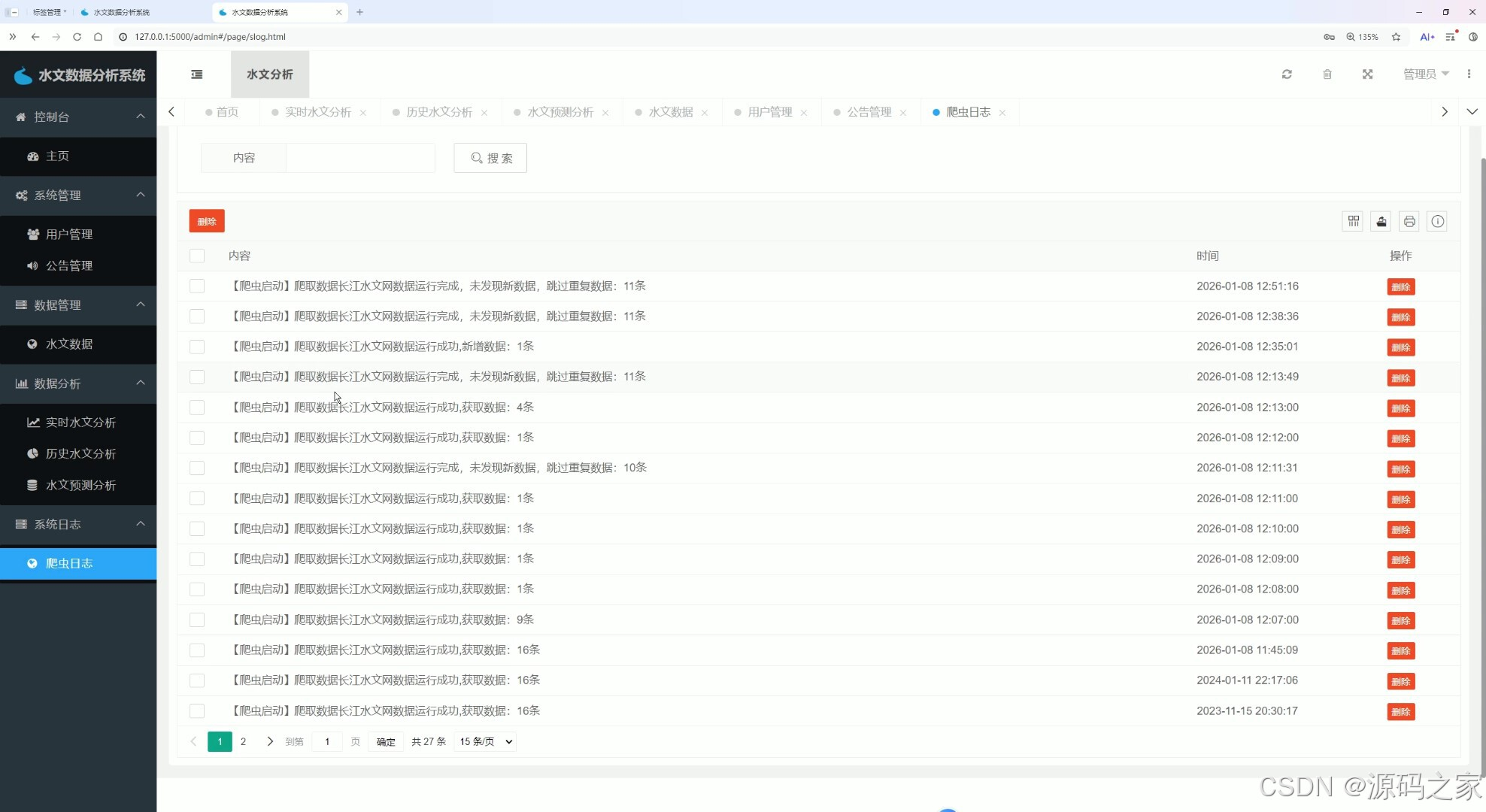
(5)爬虫日志
该页面为水文数据分析系统的爬虫日志页,提供内容搜索功能,以表格形式展示爬虫的运行日志,包含爬虫启动记录、运行结果、执行时间等信息,支持日志的批量删除与单条删除操作,用于监控爬虫运行状态。
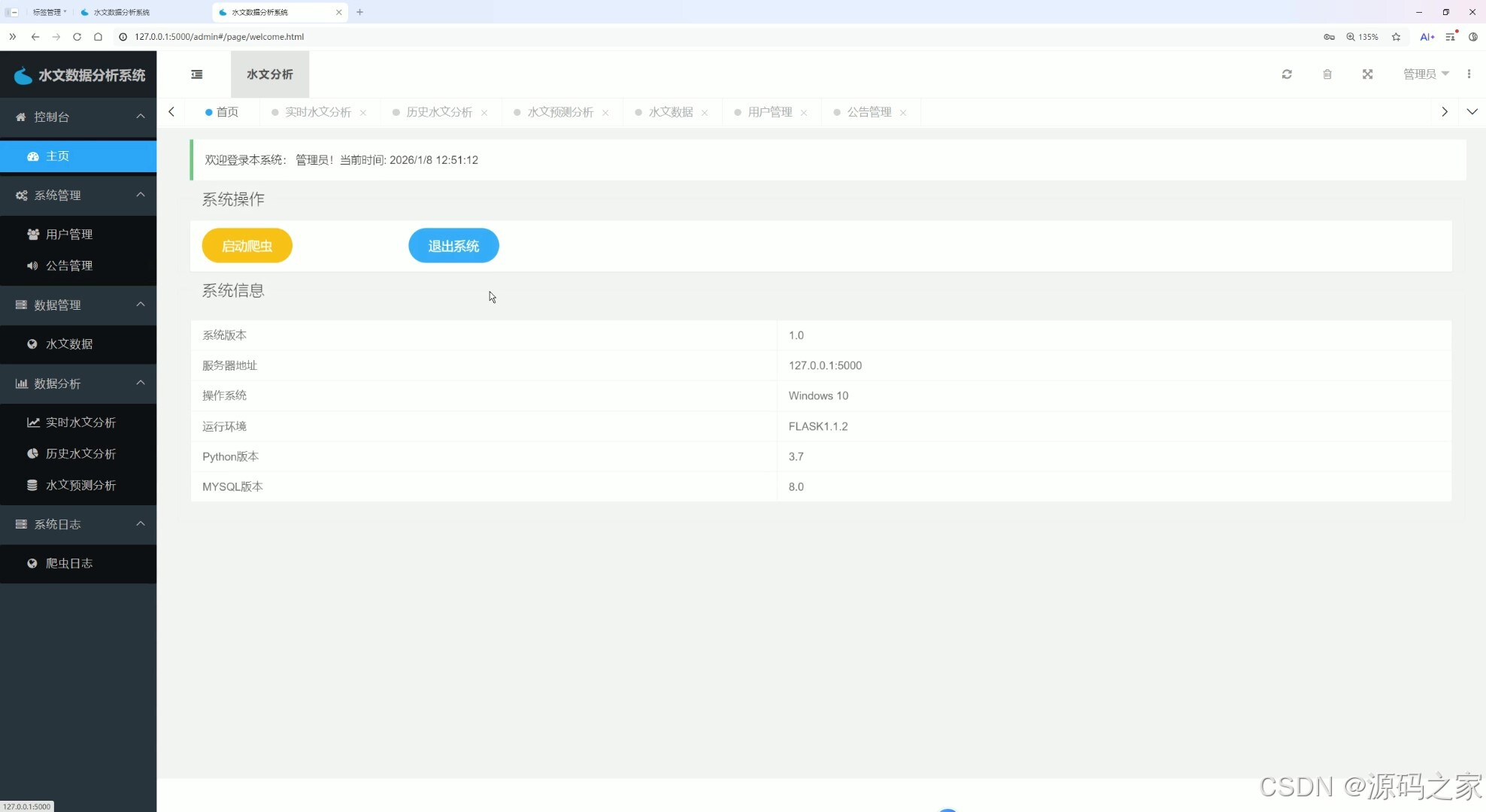
(6)主页
该页面为水文数据分析系统的主页,展示管理员登录欢迎信息与当前时间,提供启动爬虫和退出系统的操作按钮,同时呈现系统版本、服务器地址、运行环境等详细系统信息,方便用户了解系统状态与执行核心操作。
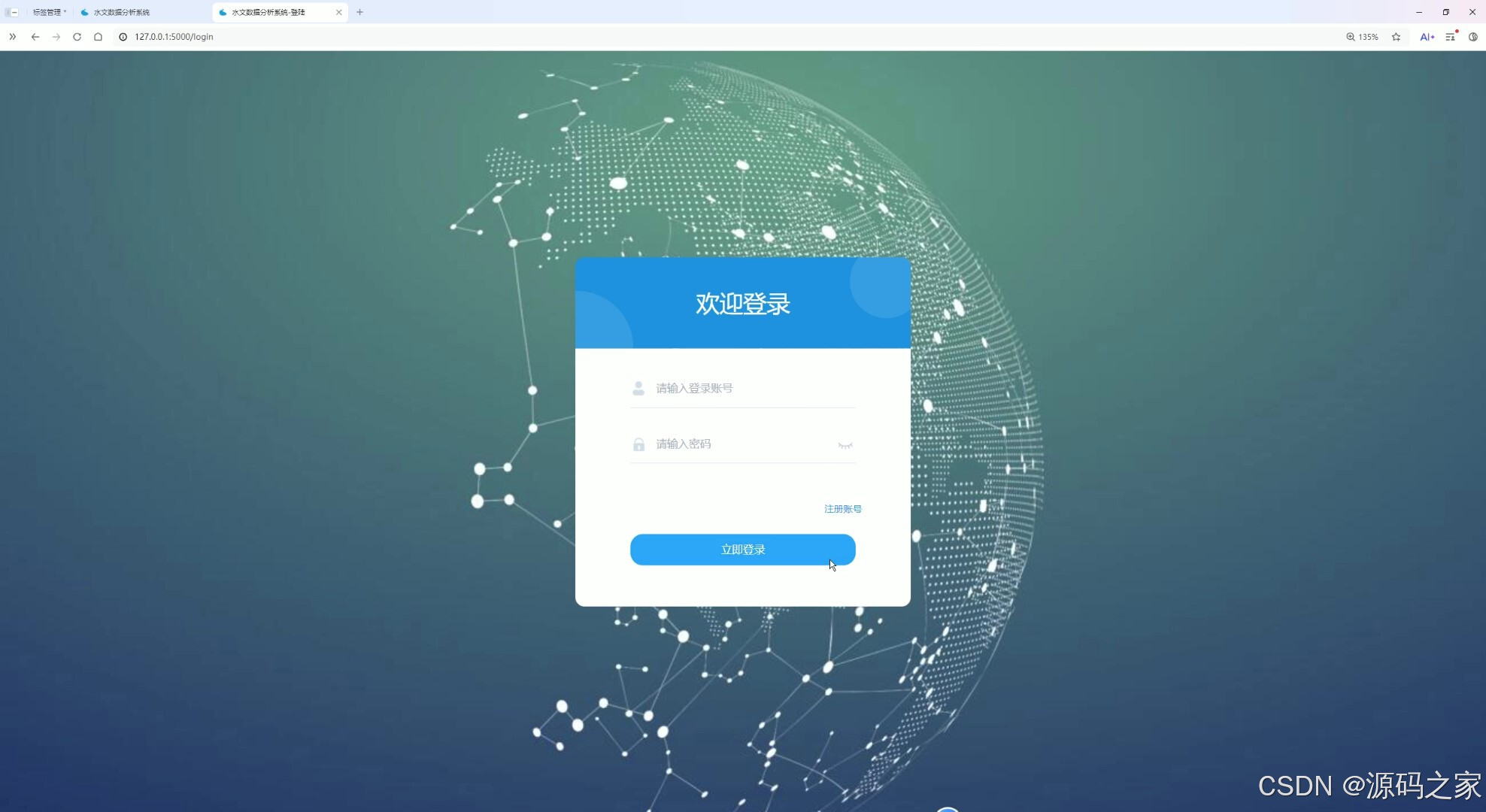
(7)注册登录界面
该页面为水文数据分析系统的登录页,提供账号和密码的输入框,设有立即登录按钮与注册账号入口,用于验证用户身份,是进入系统的权限入口,保障系统访问安全。
3、项目说明
一、技术栈简要说明
本系统采用 Python 语言开发,基于 Flask 框架搭建后端服务,使用 MySQL 数据库进行数据存储,通过 requests 爬虫从长江水文网获取水文数据,运用多元线性回归预测算法和 scikit-learn 库进行机器学习预测分析,前端结合 Echarts 可视化库与 Layui 框架实现数据展示与界面开发。
二、功能模块详细介绍
· 用户登陆注册模块
该模块提供系统的身份验证功能。用户通过注册页面创建账号,注册信息存储到 MySQL 数据库中。登录页面设有账号和密码输入框,配备立即登录按钮与注册账号入口,用于验证用户身份,是进入系统的权限入口,保障系统访问安全。
· 水文数据管理模块
该模块负责水文数据的后台维护与管理。水文数据页面提供站点和水源地的搜索功能,以表格形式展示各监测站点的水文数据,涵盖水位、流量等核心指标,支持数据的添加、删除、编辑操作,实现水文数据的完整管理与维护。爬虫日志页面提供内容搜索功能,以表格形式展示爬虫的运行日志,包含爬虫启动记录、运行结果、执行时间等信息,支持日志的批量删除与单条删除操作,用于监控爬虫运行状态。主页展示管理员登录欢迎信息与当前时间,提供启动爬虫和退出系统的操作按钮,同时呈现系统版本、服务器地址、运行环境等详细系统信息,方便用户了解系统状态与执行核心操作。
· 水文数据可视化模块
该模块通过图表形式直观展示水文数据。数据概况页面为实时水文分析页,展示各水源地数据量统计卡片、水文监测站点的水位流量数据表格,以及水源地实时流量分布环形图,呈现实时水文监测数据与流量分布情况。历史水文分析页面提供站点筛选与搜索功能,通过流量变化分析面积折线图和水位变化分析面积折线图,直观呈现所选站点历史流量与水位的时间变化趋势。
· 水文数据预测模块
该模块基于多元线性回归算法构建预测模型。水文预测分析页面通过水位变化预测折线图和未来24小时流量变化预测折线图,直观呈现水文数据的未来变化趋势。系统利用 scikit-learn 库对历史水文数据进行训练建模,输入时间序列特征后输出未来水位和流量的预测值,为水文预警与决策提供数据支撑。
· 公告模块
该模块用于发布系统相关通知和信息。管理员可通过后台发布水文预警、系统维护、政策法规等公告内容,用户登录后可在系统内查看最新公告,确保重要信息及时传达。
三、项目总结
本系统利用爬虫技术从长江水文网自动获取水文监测数据,经处理后存入 MySQL 数据库。系统提供用户登录注册、水文数据管理与可视化、水文预测分析及公告等功能模块,为用户提供完整的水文数据管理和使用服务。通过 Echarts 展示水源地实时流量分布、历史水位与流量变化趋势,让用户直观了解水文动态。基于多元线性回归算法建立预测模型,对未来水位和流量进行预测,为防洪减灾、水资源调度提供科学依据。系统采用 Flask 构建数据接口服务层,具备良好的可扩展性和可维护性,为水文学研究和水资源管理提供了精确的数据支持与决策依据,在水文监测、预警和调度领域具有重要的应用价值。

4、核心代码
python
from flask import Flask as _Flask, redirect
from flask import request, session
from flask import render_template
from flask.json import JSONEncoder as _JSONEncoder
import decimal
import os
from flask_apscheduler import APScheduler
from service import user_service, spider_service, notice_service, slog_service, data_service, \
predict_service, water_level_service
from utils.JsonUtils import read_json
import datetime
from utils.Result import Result
base = os.path.dirname(__file__)
directory_path = os.path.dirname(__file__)
json_path = directory_path + '/static/api/'
class JSONEncoder(_JSONEncoder):
def default(self, o):
if isinstance(o, decimal.Decimal):
return float(o)
if isinstance(o, datetime.datetime):
return o.strftime("%Y-%m-%d %H:%M:%S")
if isinstance(o, datetime.date):
return o.strftime("%Y-%m-%d")
super(_JSONEncoder, self).default(o)
class Flask(_Flask):
json_encoder = JSONEncoder
import os
app = Flask(__name__)
app.config['SESSION_TYPE'] = 'filesystem'
app.config['SECRET_KEY'] = os.urandom(24)
app.config['PERMANENT_SESSION_LIFETIME'] = datetime.timedelta(days=1)
# ----------------------------------------------页面加载模块开始----------------------------------------------
# 加载系统json文件
@app.route('/api/<string:path>/')
def api_json(path):
if path == 'init.json' and session.get('user') and session.get('user')['type'] == 1:
path = 'custom_init.json'
return read_json(json_path + path)
# 加载page下的静态页面
@app.route('/page/<string:path>')
def api_path(path):
return render_template("page/" + path)
# 系统默认路径后台跳转
@app.route('/admin')
def admin_page():
session['user'] = user_service.get_user(1)
session['site_list'] = water_level_service.get_site_list()
if session.get('user') and session.get('user')['id'] > 0:
return render_template("index.html")
else:
return redirect("/login")
# 系统默认路径前台跳转
@app.route('/')
def main_page():
return render_template("page/login.html")
# 系统登录路径
@app.route('/login')
def login_page():
return render_template("page/login.html")
# 系统退出登录路径
@app.route('/logout')
def logout_page():
session.clear()
return redirect("/login")
# 系统注册用户
@app.route('/register', methods=['get'])
def register_page():
return render_template("page/register.html")
# ----------------------------------------------页面加载模块结束----------------------------------------------
# ----------------------------------------------用户相关模块开始----------------------------------------------
# 用户注册
@app.route('/register', methods=['post'])
def register_user():
form = request.form.to_dict() # 获取值
result = user_service.insert_user(form)
return result.get()
# 用户登录
@app.route('/login', methods=['post'])
def login_user():
form = request.form.to_dict() # 获取值
result = user_service.select_user_by_account_password(form)
session['user'] = result.data
return result.get()
# ----------------------------------------------用户相关模块结束----------------------------------------------
# ----------------------------------------------水文相关模块开始----------------------------------------------
# 水文数据分页
@app.route('/page/water/level/add', methods=['get'])
def page_water_level_add():
site_list = water_level_service.get_site_list()
water_source_list = water_level_service.get_water_source_list()
return render_template("page/waterLevel/add.html", site_list=site_list, water_source_list=water_source_list)
# 添加水文数据
@app.route('/add/water/level', methods=['post'])
def add_water_level():
form = request.form.to_dict()
result = water_level_service.insert_water_level(form)
return result.get()
# 水文数据编辑页面
@app.route('/page/water/level/edit', methods=['get'])
def page_water_level_edit():
id = request.args.get('id')
water_level = water_level_service.select_water_level_by_id(id)
site_list = water_level_service.get_site_list()
water_source_list = water_level_service.get_water_source_list()
return render_template("page/waterLevel/edit.html", site_list=site_list, water_source_list=water_source_list,
water_level=water_level)
# 编辑水文接口
@app.route('/edit/water/level', methods=['post'])
def edit_water_level():
form = request.form.to_dict()
result = water_level_service.edit_water_level(form)
return result.get()
# 单个删除水文接口
@app.route('/del/water/level/<int:id>', methods=['post'])
def del_water_level(id):
result = water_level_service.del_water_level(id)
return result.get()
# 批量删除水文接口
@app.route('/del/water/level', methods=['post'])
def del_water_level_list():
ids = request.args.get('ids')
result = water_level_service.del_water_level_list(ids)
return result.get()
# 水文数据分页
@app.route('/list/water/level', methods=['get'])
def water_level_list():
page = request.args.get('page')
limit = request.args.get('limit')
where = request.args.get('searchParams')
result = water_level_service.select_water_level_list(page, limit, where)
return result.get()
# ----------------------------------------------水文相关模块结束----------------------------------------------
# ----------------------------------------------用户相关模块开始----------------------------------------------
# 用户数据分页
@app.route('/page/user/add', methods=['get'])
def page_user_add():
return render_template("page/user/add.html")
@app.route('/add/user', methods=['post'])
def add_user():
form = request.form.to_dict()
result = user_service.insert_user(form)
return result.get()
# 用户修改密码
@app.route('/user/reset/password', methods=['post'])
def reset_password_user():
form = request.form.to_dict() # 获取值
result = user_service.reset_password(form['old_password'], form['new_password'], form['again_password'])
return result.get()
# 用户编辑页面
@app.route('/page/user/edit', methods=['get'])
def page_user_edit():
id = request.args.get('id')
user = user_service.get_user(id)
return render_template("page/user/edit.html", user=user)
# 编辑用户接口
@app.route('/edit/user', methods=['post'])
def edit_user():
form = request.form.to_dict()
result = user_service.edit_user(form)
return result.get()
# 单个删除用户接口
@app.route('/del/user/<int:id>', methods=['post'])
def del_user(id):
result = user_service.del_user(id)
return result.get()
# 批量删除用户接口
@app.route('/del/user', methods=['post'])
def del_user_list():
ids = request.args.get('ids')
result = user_service.del_user_list(ids)
return result.get()
# 用户数据分页
@app.route('/list/user', methods=['get'])
def user_list():
page = request.args.get('page')
limit = request.args.get('limit')
where = request.args.get('searchParams')
result = user_service.select_user_list(page, limit, where)
return result.get()
# ----------------------------------------------用户相关模块结束----------------------------------------------
# ----------------------------------------------公告相关模块开始----------------------------------------------
# 公告添加页面
@app.route('/page/notice/add', methods=['get'])
def page_notice_add():
return render_template("page/notice/add.html")
@app.route('/add/notice', methods=['post'])
def add_notice():
form = request.form.to_dict()
result = notice_service.insert_notice(form)
return result.get()
# 数据公告编辑页面
@app.route('/page/notice/edit', methods=['get'])
def page_notice_edit():
id = request.args.get('id')
notice = notice_service.get_notice(id)
return render_template("page/notice/edit.html", notice=notice)
# 编辑公告接口
@app.route('/edit/notice', methods=['post'])
def edit_notice():
form = request.form.to_dict()
result = notice_service.edit_notice(form)
return result.get()
# 单个删除公告接口
@app.route('/del/notice/<int:id>', methods=['post'])
def del_notice(id):
result = notice_service.del_notice(id)
return result.get()
# 批量删除公告接口
@app.route('/del/notice', methods=['post'])
def del_notice_list():
ids = request.args.get('ids')
result = notice_service.del_notice_list(ids)
return result.get()
# 公告数据分页
@app.route('/list/notice', methods=['get'])
def notice_list():
page = request.args.get('page')
limit = request.args.get('limit')
where = request.args.get('searchParams')
result = notice_service.select_notice_list(page, limit, where)
return result.get()
# 公告数据分页
@app.route('/get/notice/new', methods=['get'])
def get_new_notice():
result = notice_service.get_notice_by_new()
return result.get()
# ----------------------------------------------公告相关模块结束----------------------------------------------
# ----------------------------------------------日志相关模块开始----------------------------------------------
# 单个删除日志接口
@app.route('/del/slog/<int:id>', methods=['post'])
def del_slog(id):
result = slog_service.del_slog(id)
return result.get()
# 批量删除日志接口
@app.route('/del/slog', methods=['post'])
def del_slog_list():
ids = request.args.get('ids')
result = slog_service.del_slog_list(ids)
return result.get()
# 日志数据分页
@app.route('/list/slog', methods=['get'])
def slog_list():
page = request.args.get('page')
limit = request.args.get('limit')
where = request.args.get('searchParams')
result = slog_service.select_slog_list(page, limit, where)
return result.get()
# ----------------------------------------------日志相关模块结束----------------------------------------------
# ----------------------------------------------分析相关模块开始----------------------------------------------
# 历史水文数据分析
@app.route('/data/history/water', methods=['post', 'get'])
def data_history():
site = request.args.get('site')
flow_data = data_service.flow_data(site)
level_data = data_service.level_data(site)
return {"flow_data": flow_data, "level_data": level_data}
# 实时数据分析
@app.route('/data/current/water', methods=['post', 'get'])
def data_current_water():
return data_service.top_page_data()
# 水文数据预测
@app.route('/data/water/predict', methods=['post', 'get'])
def data_predict():
site = request.args.get('site')
return predict_service.predict(site)
# ----------------------------------------------分析相关模块结束----------------------------------------------
# ----------------------------------------------爬虫相关模块开始----------------------------------------------
from concurrent.futures import ThreadPoolExecutor
# 爬虫自动运行
def job_function():
print("爬虫任务执行开始!")
executor = ThreadPoolExecutor(2)
executor.submit(spider_service.main_spider())
def task():
scheduler = APScheduler()
scheduler.init_app(app)
# 定时任务,每隔600s执行1次
scheduler.add_job(func=job_function, trigger='interval', seconds=3600, id='my_cloud_spider_id')
scheduler.start()
# 后台调用爬虫
@app.route('/spider/start', methods=["POST"])
def run_spider():
executor = ThreadPoolExecutor(2)
executor.submit(spider_service.main_spider())
return Result(True, '指令已发送,静默爬取中,请稍后查看爬虫日志,查看运行情况').get()
# 写在main里面,IIS不会运行
task()
# run_spider()#启动项目就运行一次爬虫
# ----------------------------------------------爬虫相关模块结束----------------------------------------------
if __name__ == '__main__':
# 端口号设置
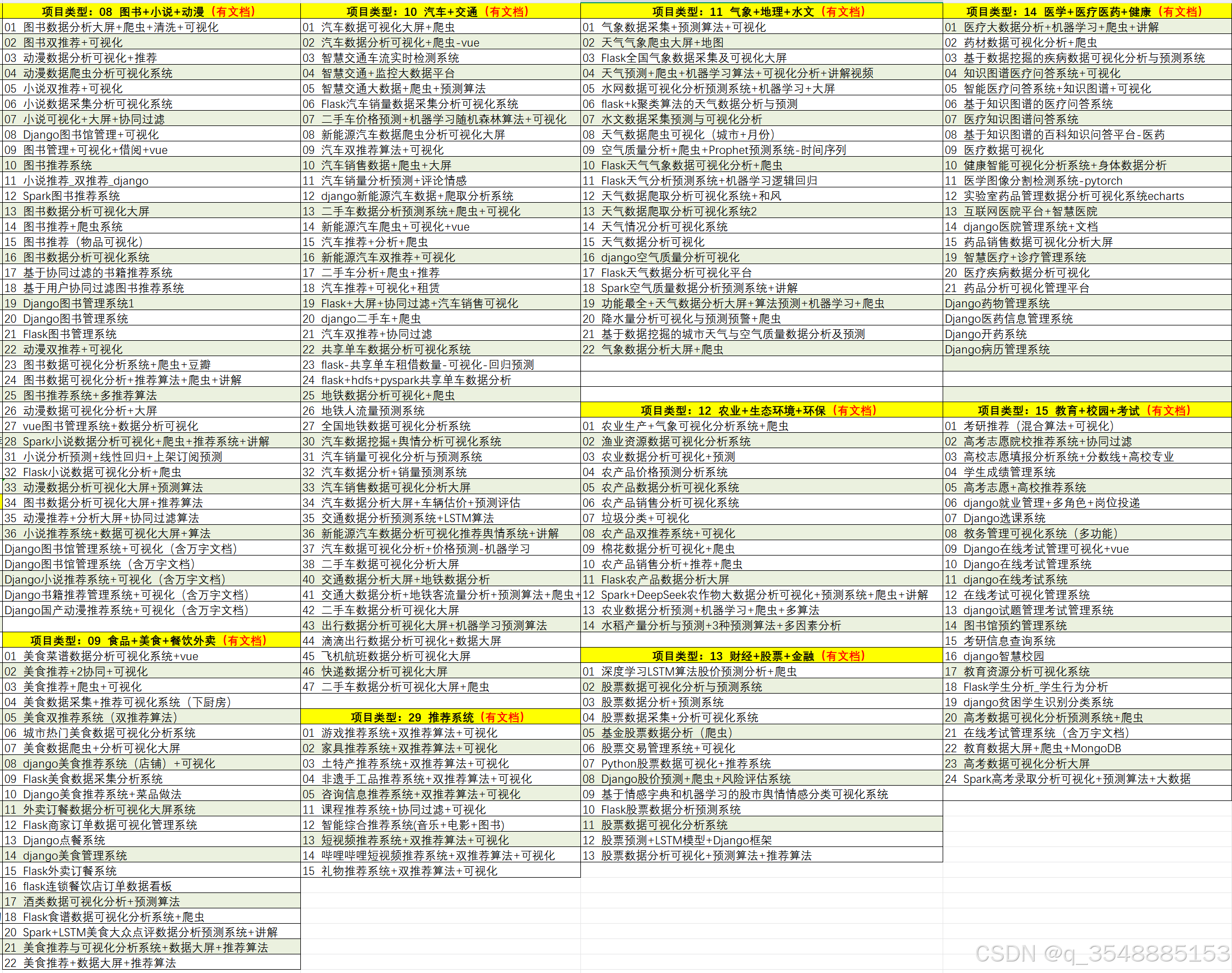
app.run(host="127.0.0.1", port=5000)5、项目列表



6、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看 👇🏻获取联系方式👇🏻