上一篇讲到损失函数。
https://blog.csdn.net/i_k_o_x_s/article/details/159929680?spm=1001.2014.3001.5501
如何让损失函数最小呢?
一、正规方程求解
1.求导
2.求偏导
3.矩阵运算
高数内容这篇已大概讲述
https://blog.csdn.net/i_k_o_x_s/article/details/159999903?spm=1001.2014.3001.5502
4.概念
正规方程是一种有效解决小规模线性回归问题的方法,但对于大规模数据集或者特征数量较多的情况,可能会遇到计算效率问题。(矩阵的逆必须存在,否则无法使用正规方程)
第一个公式:假设函数(模型公式 ) -> w(权重)、x(特征)、b(偏置)、h(预测值)
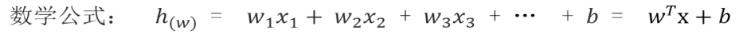
第二个公式:正规方程(求解公式)
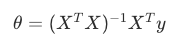
统一符号后的 w, x, b, h 形式
把 θ 直接替换为参数向量 w,公式变为:
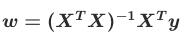
| 原始符号 | 统一后符号 | 含义 |
|---|---|---|
| θ | w | 包含偏置 b 的完整参数向量:w=b,w1,w2,...,wnT |
| X | X | 带全 1 列的特征矩阵(第一列对应 x0=1,用于承载偏置 b) |
| y | y | m×1 的真实标签向量 |
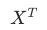 |
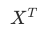 |
矩阵 X 的转置 |
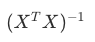 |
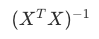 |
矩阵 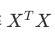 的逆矩阵(不可逆时用伪逆) 的逆矩阵(不可逆时用伪逆) |
步骤 1:定义模型(用 w, x, b, h 写预测公式)
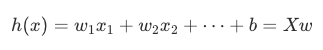
作用:定义模型结构,说明如何用输入特征 x、权重 w、偏置 b 计算预测值 h
步骤 2:求解最优参数(用正规方程求 w,包含 b)
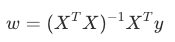
作用:直接计算出最优的 w(包含 b),让预测值 h=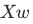 尽可能接近真实值 y(最小化均方误差)
尽可能接近真实值 y(最小化均方误差)
步骤 3:得到最终模型
把求解出的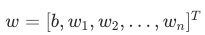 代回步骤 1 的公式,就得到了最终的预测模型:
代回步骤 1 的公式,就得到了最终的预测模型:
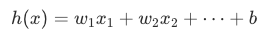
具体例子
假设我们有 3 个样本,1 个特征 x1,真实标签 y 如下:
| 样本 | x1 | y |
|---|---|---|
| 1 | 1 | 2 |
| 2 | 2 | 4 |
| 3 | 3 | 6 |
1. 构造特征矩阵 X(带全 1 列)
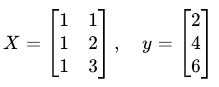
2. 用正规方程求 w(包含 b)
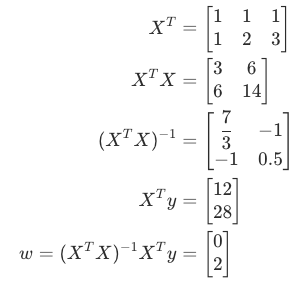
3. 代回假设函数,得到最终模型
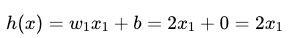
完美拟合数据,验证了两个公式的一致性。
优化:
1.不需要选择学习率
2.直接计算模型参数的方法,而不需要迭代过程。
3.不需要对特征进行缩放处理
基于最小化代价函数来找到最佳拟合直线的参数
缺点:
数据量大的时候,慢。尤其是特征数量很大时候,计算逆矩阵非常慢。
=========================================================================
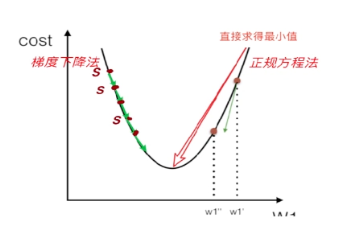
二、梯度下降法
概念
沿着梯度下降的方向 求解极小值
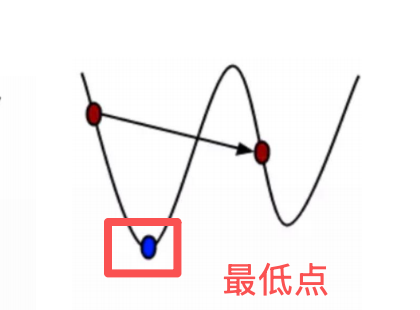
下山过程:连绵不断的山,第一座山的最低点(极小值点)-> 第二座山(极小值)->....
目标逼近山底。
单变量函数中,梯度就是某一点的切线斜率,有方向为函数增长最快的方向
多变量函数中,梯度就是某一点的偏导数,有方向:偏导数分量的向量方向
梯度下降公式(核心)
循环迭代求当前点的梯度,更新当前的权重参数
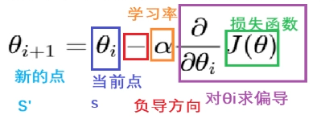

 :学习率(步长) 不能太大,也不能太小。机器学习中: 0.001 ~ 0.01
:学习率(步长) 不能太大,也不能太小。机器学习中: 0.001 ~ 0.01
太大:梯度震旦
太小:太慢
梯度是上升最快的方向,我们需要是下降最快的方向,所以需要加负号
单变量梯度下降 -- 例子
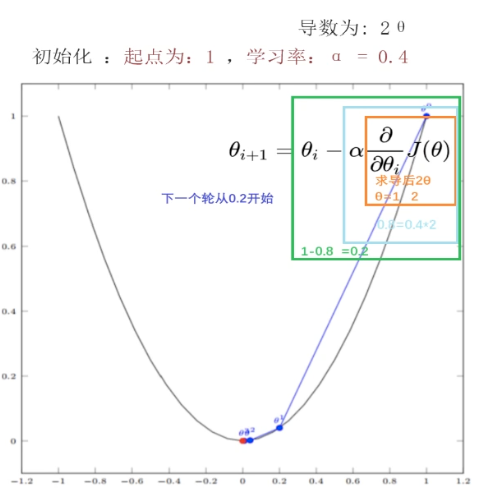

小结:经过四次的运算,即走了四步,基本抵达了函数的最低点
什么时候停止?
满足停止条件:
1.如果设置了具体迭代次数就停止
2.如果满足范围要求 比如: θ (0.001 - 0.003)即停止
梯度下降优化过程
1.给定初始位置、步长(学习率)
2.计算该点当前的梯度步长
3.向该负方向移动步长
4.重复2-3步,直到收敛(设置的满足停止条件)
有关学习率步长(Learning rate)
1.步长决定了在梯度下降迭代的过程中,每一步沿梯度负方向前进的长度
2.学习率太小,下降的速度会慢
3.学习率太大:容易造成错过最低点、产生下降过程中的震荡、甚至梯度爆炸
梯度下降法分类:
1.全梯度下降算法 FGD:
使用全部数据集,训练速度较慢。效果比较好
2.随机梯度下降算法 SGD:
简单,高效,不稳定。SG每次只使用一个样本迭代,容易遇上异常数据写入局部最优解
3.小批量梯度下降算法 mini-bach (用的比较多)
结合SG的大单和FG的心细,正好居于SG和FG二者之间。
证因为它避开了FG运算效率低成本大和SG收敛效果不稳定的缺点。


4.随机平均梯度下降算法SAG
训练初期表现不佳,优化速度较慢。因为常将初始梯度设为0,而SAG每轮梯度更新都结合了上一轮梯度值。
早期数据量小,效率不好。 数据越多效率越好。
三、两个方法的比较
| 梯度下降 | 正规方程 | |
|---|---|---|
| 怎么求 w | 一步步迭代更新 | 直接矩阵求逆 |
| 是否需要学习率 α | 需要,要调参 | 不需要 |
| 特征多 (n 很大) | 跑得动 | 跑不动(求逆太慢) |
| 特征少 (n 很小) | 可以用,但没必要 | 超快、首选 |
| 是否缩放特征 | 需要(否则不收敛) | 不需要 |
| 迭代次数 | 需要很多次 | 0 次,一步到位 |
| 适用模型 | 线性 / 逻辑 / 神经网络都能用 | 只能线性回归 |
| 矩阵不可逆 | 没问题 | 会出问题,要用伪逆 / 正则 |