模块一:大模型训练概览与核心理念(基石篇)
本章核心知识点: LLM全生命周期(Pre-training -> CPT -> SFT -> RLHF)、模型知识的存储机制、指令微调(SFT)的本质与作用。
在去算显存、看Loss曲线之前,我们必须先在脑海中建立大模型(LLM)的宏观物理学。很多在微调阶段踩的坑(比如模型变傻了、怎么教都教不会),本质上是因为对"模型在不同阶段究竟在学什么"存在误解。
大模型的唯一底层任务就是预测下一个Token。
给定历史序列 ,模型输出词表中所有词作为下一个词
的概率分布。优化的目标是最小化交叉熵损失(Cross-Entropy Loss):
模型权重的更新,完全依赖于这个等式中产生的梯度进行反向传播。
目前业界主流的大模型训练范式,都可以归结为一个从"读书"到"学做人"的过程。整个生命周期包含以下核心阶段:
1. 预训练阶段 (Pre-Training, PT)
-
输入数据: 海量的无监督互联网文本(网页、书籍、代码、论文),通常以万亿 Tokens (Trillions of Tokens) 为单位。
-
训练目标: Next-Token Prediction(预测下一个词)。给定上文,猜测下文是什么。
-
本质: 这是"死记硬背"阶段。模型在这个阶段构建世界观,学习语言的语法,并把海量的世界知识压缩到它的神经网络权重(参数)中。此时的模型是一个极其强大的"文本接龙机器",但它不知道什么是对话。
2. 持续预训练 (Continual Pre-Training, CPT) - (可选,针对垂直领域)
-
输入数据: 垂直领域的高质量无监督文本(如医疗文献、法律卷宗、企业内部知识库)。
-
本质: 如果基座模型在预训练时没看过太多你们行业的书,你就在这里给它"开小灶"补充专业知识。训练方式和预训练完全一样(预测下一个词)。
3. 指令微调 / 监督微调 (Supervised Fine-Tuning, SFT)
-
输入数据: 高质量的"人类指令 - 标准回答"问答对(Prompt-Response pairs),规模通常在几万到几十万条之间。
-
训练目标: 依然是预测下一个词,但只针对 Response 部分计算 Loss(损失)。
-
本质: 这是"应试培训"阶段。著名的 LIMA (Less Is More for Alignment) 论文证明了一个核心观点:大模型的知识和能力几乎都是在预训练阶段获得的,SFT 的作用仅仅是教会模型"如何与人类交互"。SFT 是一把钥匙,用来解锁预训练阶段积累的知识,让模型从"文本接龙器"变成"听话的AI助手"。
4. 人类反馈强化学习 (RLHF / DPO) - (可选,用于对齐)
- 本质: 进一步规范模型的输出,让它符合人类的价值观(不输出有害内容、不骂人、态度好),也就是著名的 3H 原则(Helpful, Honest, Harmless)。
PT(预训练)与 SFT(指令微调)的数据结构差异:
PT 数据结构(无监督纯文本): 输入:{"text": "Apple was founded by Steve Jobs and Steve Wozniak in 1976."} 机制:模型会对这句话中的每一个字计算 Loss。比如它会根据 "Apple was founded by" 预测 "Steve",计算一次 Loss;再根据 "Apple was founded by Steve" 预测 "Jobs",再计算一次 Loss。
SFT 数据结构(监督对话对): 输入:{"instruction": "Who founded Apple?", "output": "Steve Jobs and Steve Wozniak."} 机制:通过 Attention Mask 和 Label Mask 机制,模型绝对不会对 "Who founded Apple?" 这部分计算 Loss(在 PyTorch 中,这部分标签会被设为 -100 以忽略梯度计算)。模型仅对 output 部分计算 Loss并更新权重。
知识是如何编码进权重的?
知识在模型中体现为神经元之间的"共现概率"和"连接强度"。当 "Aspirin" 和 "Headache" 在海量文本中反复作为上下文出现时,前向传播会不断激活特定的多层感知机(MLP)神经元。反向传播会增大这些神经元之间的权重(Weight Matrices)。知识不是以关系型数据库(如 SQL)的形式存在,而是以高维向量空间的统计分布形式存在于参数矩阵中。
QA:
1.预训练和微调哪个阶段注入知识的?
解答: 绝大部分事实类、常识类和专业领域知识,都是在预训练(Pre-training, PT)或继续预训练(Continue Pre-training, CPT)阶段注入的。
- 实例: 假设你要让模型知道"某公司2024年发布了产品X,特点是Y"。如果这条知识只在 SFT 阶段以 10 条问答对的形式出现,模型极难将"公司"、"产品X"和"特点Y"的隐性关联写入到底层 MLP 权重中。相反,如果这段文本在 PT 阶段以无格式的新闻稿、技术白皮书形式出现并训练数百次迭代,模型底层向量空间就会建立起强关联。
2.想让模型学习某个领域或行业的知识,是应该预训练还是应该微调?
解答: 应该采用 Continue Pre-training (CPT) 注入知识,然后用 SFT 规范输出格式。
-
实例流程:
-
目标: 构建法律大模型。
-
第一步(CPT阶段): 收集几百 GB 的《民法典》、法院判决书、法律学术论文。按 PT 的方式,去除格式,只保留连续文本,让模型进行 Next-Token Prediction 训练。此时模型记住了法律条文和术语分布。
-
第二步(SFT阶段): 准备 1-2 万条高质量问答对(例如
{"prompt": "张三偷了李四的牛,犯了什么罪?", "response": "根据《刑法》第XX条,构成盗窃罪..."})。这一步不为了让模型背诵《刑法》,而是教会它当用户以提问形式输入时,以"法律顾问"的严谨口吻输出。
-
3.预训练和SFT操作有什么不同?
解答: 除了上文提到的数据格式(纯文本 vs 指令对)差异外,核心不同体现在Loss计算范围和优化目标上:
-
预训练(PT): 对全序列计算 Loss。目标是拟合训练语料的数据分布,学习自然语言的语法、逻辑和海量事实。
-
指令微调(SFT): 仅对 Response 部分计算 Loss。目标是行为对齐(Alignment) ,即学习如何与人类交互、何时停止输出(生成
<EOS>Token),以及特定任务的输出模版。
4.大模型LLM进行SFT操作的时候在学习什么?
解答: SFT 阶段模型学习的是格式约束、任务模式和拒绝策略。
-
实例 1(格式约束): 训练集中大量存在
{"instruction": "提取实体", "output": "{\"name\": \"张三\", \"age\": 18}"}。模型学习到的不是张三18岁这个事实,而是"当遇到实体提取指令时,必须输出合法的 JSON 格式"。 -
实例 2(任务模式): 针对 ReAct 智能体框架,SFT 让模型学习按严格的
[Thought] -> [Action] -> [Observation]序列输出,否则工具调用解析器会报错。 -
实例 3(激活内置知识): 用户提问"量子力学是什么?"。模型在 PT 阶段已经看过大量物理论文,拥有这些知识,SFT 教会模型从高维空间中定向提取这些知识,并组织成适合阅读的段落。
5.领域模型Continue PreTrain,如何让模型在预训练过程中就学习到更多的知识?
解答: 在 CPT 阶段提高知识吸收率,完全依赖于数据工程的密度与策略,主要有以下三种硬核实例操作:
-
数据去重与清洗(Data Deduplication):
- 实例: 抓取的网页数据包含大量 "Accept Cookies", "Copyright 2023" 等无意义长尾重复词汇。如果不剔除,模型的容量(Capacity)会被这些垃圾分布挤占。使用 MinHash 或 LSH 算法进行文档级和段落级去重。
-
Document Packing(文档拼接技术):
-
机制: 如果
max_seq_length设为 4096,而你的单篇法律文档只有 500 Tokens,如果不拼接,剩余的 3596 个位置只能用<PAD>填充,这些位置不仅不参与学习,还会白白消耗算力。 -
实例: 将多篇短文档用
<EOS>(End of Sentence) 符号连接起来,拼满 4096 Tokens,如[Doc 1] <EOS> [Doc 2] <EOS> [Doc 3]。这样每一次前向传播的矩阵计算都是满载且高效的。
-
-
动态数据混合比例(Data Mixing Rules):
-
机制: 纯喂领域数据极易导致灾难性遗忘(表现为模型不会说正常人话了)。
-
实例: 即使是训练纯医疗大模型,CPT 数据集也必须硬性规定混合比例:80% 医疗数据 + 15% 通用高质量百科数据(如 Wikipedia) + 5% 数学/代码数据(用于保持模型的逻辑推理能力,这在工程上已被证明能显著维持 Attention 机制的清晰度)。
-
模块二:算力底座与显存消耗剖析(硬件篇)
在实际操作中,显存不足(OOM, Out of Memory)是阻碍训练的第一道门槛。要解决这个问题,必须量化每一比特显存的去向。
核心知识点:显存占用量化分析
大模型训练时的显存占用主要由静态显存 和动态显存 两部分组成。以 FP16(半精度) 训练、使用 AdamW 优化器为例:
1. 静态显存:模型参数与优化器状态
这部分显存与输入序列长度无关,只要模型加载,显存就会被固定占据。
-
模型参数 (Weights): 每个参数在 FP16 下占 2 Bytes。
-
梯度 (Gradients): 每个参数对应的梯度在 FP16 下占 2 Bytes。
-
优化器状态 (Optimizer States): 这是"显存杀手"。AdamW 优化器需要为每个参数维护:
-
一份 FP32 的参数备份(Master Weights):4 Bytes
-
一阶动量 (Momentum):4 Bytes
-
二阶动量 (Variance):4 Bytes
-
合计:12 Bytes
-
结论: 在全参数微调(Full Fine-tuning)中,每 1B(10亿)参数大约需要 2 + 2 + 12 = 16 GB 的显存。
2. 动态显存:激活值 (Activations)
假设模型中某一层的计算是简单的线性变换:
-
是这一层的权重(参数)。
-
-
在微调时,我们需要更新权重。根据微积分的链式法则,损失函数
对权重
的梯度为:
因为 ,所以
。
这意味着:要计算权重 的梯度,你必须知道当时的输入
。 在深层网络中,前向传播是一层层算下去的,而反向传播是从最后一层往回算的。因此,第一层计算出的
,必须一直保存在显存里,直到反向传播"走回"第一层并用完它为止。层数越深,需要囤积的激活值就越多。
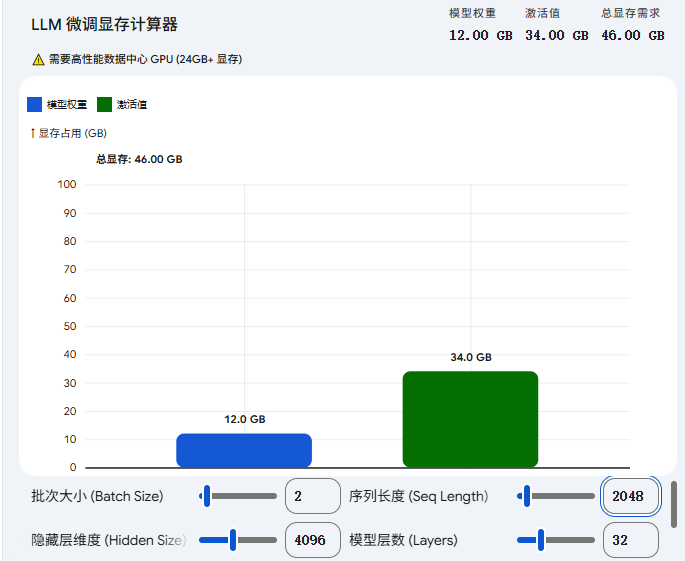
模型权重(Parameters)占用的显存是固定的。比如一个 7B(70亿参数)的模型,用半精度(FP16,每个参数2字节)加载,固定占用约 14GB 显存。
但激活值占用的显存是动态的,并且与你的训练数据大小呈正比。在标准的 Transformer 模型中,激活值的显存占用主要由以下四个维度决定:
-
批次大小 (Batch Size, b): 并行处理的样本数。
-
序列长度 (Sequence Length, s): 文本的长度(Token 数量)。
-
隐藏层维度 (Hidden Size, h): 模型内部特征的宽度。
-
层数 (Number of Layers, L): 模型的深度。
一个经验公式是:在没有优化的情况下,单次前向传播产生的激活值大小大约为 字节。
关键结论: 当你微调长文本(序列长度 s很大)或加大 Batch Size 时,激活值占用的显存会呈线性增长,甚至呈二次方增长(因为注意力机制中的注意力矩阵大小是 ),很容易远超模型权重本身占用的显存。
当单张显卡装不下这"四大刺客"时,底层工程师发明了以下方法:
-
Gradient Checkpointing(梯度检查点 / 激活重计算): 核心思想是"用时间换空间"。在前向传播时,不保存所有的激活值,只保存关键节点的。在反向传播需要用到时,再临时重新计算一次。这能大幅降低激活值显存占用,代价是训练速度变慢约20%。
-
ZeRO (Zero Redundancy Optimizer): DeepSpeed框架的核心。既然单卡装不下,就把"优化器状态、梯度、权重"切成多份,分摊到多张显卡上。
-
PEFT (如 LoRA): 冻结原来的大模型参数,只在旁边外挂极少量的"小参数矩阵"进行训练。这样优化器状态和梯度就只作用于这极小部分的参数,显存需求断崖式下跌。
QA:
1. 如果想要在某个模型基础上做全参数微调,究竟需要多少显存?
解答:
如果你进行的是全参数微调(Full Fine-Tuning),且使用标准的混合精度(BF16/FP16权重 + AdamW优化器),我们可以推导出一个经典的底层公式:
设模型参数量为(如7B模型,
):
-
模型权重(FP16):
-
梯度(FP16):
-
AdamW状态(FP32):
-
静态显存总计:
这意味着,对于每一个参数,全参数微调至少需要 16 Bytes 的显存(纯静态模型占用,不含输入数据)。
-
实例计算(以7B模型为例):
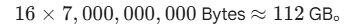
这仅仅是静态显存!如果再加上数据输入带来的激活值(Activations),一个7B模型的全参数微调,通常需要 至少 4 张 80GB 的 A100 显卡(通过ZeRO-3并行拆分)才能稳定跑起来。
2.微调模型需要多大显存?
解答: 这个问题是对"问题1"的延伸。微调分为"全参数微调"和"参数高效微调(PEFT/LoRA)",两者的显存需求天差地别:
-
全参数微调: 极其昂贵。正如问题1计算的,7B模型约需要 120GB+ 显存。13B模型需要约 240GB+。
-
LoRA微调(主流选择): 在LoRA机制下,原始模型的权重被冻结(不需要计算它的梯度,也不需要为它分配AdamW状态)。我们只训练外挂的几百万到上千万参数(通常只占总参数的0.1%到1%)。 此时的显存约等于:原始模型权重显存 (FP16) + 一点点微调参数的开销 + 激活值。
-
7B模型 LoRA: 基础权重占 14GB,加上激活值,通常 一张 24GB 显存的消费级显卡(如 RTX 3090 / 4090)就能搞定。
-
如果使用 QLoRA (把底座模型量化到 INT4 即占用 4GB),显存甚至可以压缩到 8GB - 12GB 左右。
-
3.哪些因素会影响内存(显存)使用?
解答:
根据底层的"四大刺客",影响显存使用的核心因素可以归纳为四个维度:
-
模型本身的固有属性:
-
参数量: 参数越多,权重本身占据的物理空间越大。
-
词表大小(Vocabulary Size): 经常被忽视的因素。如果你扩充了大量中文词表,模型的Embedding层和输出层矩阵会急剧膨胀,带来额外的显存开销。
-
-
训练数据的维度(极其关键):
-
Batch Size(批次大小): 一次送入多少条数据。Batch Size越大,激活值成倍增加。
-
Sequence Length(序列长度): 一条数据的Token数量。因为Self-Attention的计算量是
-
-
微调策略与精度:
-
全参数 vs LoRA: 决定了优化器状态的大小。
-
计算精度: FP32、BF16 还是 INT8/INT4。
-
-
工程加速与优化组件:
-
是否开启 Gradient Checkpointing(开启可省大量显存)。
-
是否使用显存优化版的算子,比如 FlashAttention(能大幅避免Attention矩阵计算时的显存峰值)。
-
4.当数据规模增大时OOM(Out of Memory)的原因?
发生OOM的原因,是因为单次输入模型的数据规模(Batch Size 或 序列长度)超过了显卡的单次计算极限,导致前向传播产生的"激活值矩阵"尺寸过大,直接挤爆了显存。
遇到这种情况,底层的解决办法如下(按推荐优先级排序):
-
引入时间换空间的机制: 立即开启
gradient_checkpointing=True。这通常能将激活值的显存占用降低50%以上,是防OOM的第一把交椅。 -
降低 Batch Size,补偿梯度累加: 把
per_device_train_batch_size设小(比如从 8 降到 2 甚至 1)。为了保证训练效果(模型更新的步长一致),你可以同步增大gradient_accumulation_steps(梯度累加步数)。 -
开启 FlashAttention: 如果你的卡(Ampere架构以上,如A100/A800/RTX3090/4090)支持,一定要开启 FlashAttention-2。它通过在SRAM级别的切块计算(Tiling),彻底消除了
-
截断超长样本: 检查你的数据集中是否有极个别非常长的文本。大语言模型的输入必须 padding 或 truncate 到统一长度。如果一条数据长达10000个Token,它会把整个Batch的显存拉爆。设置合理的
max_seq_length(如 2048 或 4096)进行截断。
模块三:数据工程与词表构建的底层逻辑
核心知识点剖析:数据结构、分词器(Tokenizer)与掩码(Mask)机制
1. Tokenizer 的底层编码机制(BPE 算法)
模型不认识文字,它只认识数字(Token IDs)。目前主流大模型(如 LLaMA, Qwen, ChatGLM)主要采用 BPE (Byte-Pair Encoding) 算法进行分词。
-
物理机制: BPE 是一种数据压缩算法,通过统计语料中相邻字符组合的频率,将高频组合合并为一个全新的 Token。
-
实例: 在通用中文模型中,"微处理器"这个词,如果词频不够高,可能会被切分为
[微, 处理, 器]4 个 Token;但在大量的计算机领域语料中如果它频繁出现,扩增词表后,它可能会被合并为 1 个独有 Token[微处理器]。
2. 词表扩增带来的矩阵维度突变
模型的词表大小(Vocabulary Size,记为 V)直接决定了模型首尾两层的参数矩阵大小(假设隐藏层维度为 H):
-
输入层 Embedding Matrix: 维度为
-
输出层 LM Head: 维度为
如果在原有模型基础上增加 10,000 个领域专业词汇,V 变为 V + 10000。这两个巨大矩阵的维度会发生物理改变。新增加的那部分矩阵权重是随机初始化的,如果不经过大量的 CPT(继续预训练)来更新这些随机权重,直接进行 SFT 会导致模型输出乱码或严重破坏原有能力。
3. SFT 中 Attention Mask 与 Label Mask 的物理实现
在 PyTorch 等框架中,实现"只对回答计算 Loss,不对提问计算 Loss"是依靠 labels 数组的屏蔽机制。
- CrossEntropyLoss 的底层特性: 默认配置下,当目标标签的值为
-100时,损失函数会直接忽略该位置,不对其计算梯度。
QA:
1.领域模型词表扩增是不是有必要的?
解答: 并非必须,且成本极高。通常建议不扩充,除非满足特定条件。
-
扩增词表的收益:
- 提升编解码效率: 比如医疗领域的"聚四氟乙烯",不扩词表可能会被切成 5 个 Token,扩增后切成 1 个。输入同样的文本,扩词表后占用的 Context Window(上下文长度)更少,推理速度更快。
-
扩增词表的代价(为何不建议):
-
如核心知识点所述,新增词汇的 Embedding 是随机向量。如果此时直接做 SFT,这些随机向量会导致梯度爆炸,破坏原有词表空间的分布。
-
强制前置条件: 如果你扩充了词表,必须先进行大规模的 CPT(Continue PreTraining),通常需要数百 GB 甚至上 TB 的领域文本,让模型通过 Next-Token Prediction 把这些随机初始化的新词向量拉到正确的语义空间中。
-
2. 领域模型Continue PreTrain数据选取? & 进行领域大模型预训练应用哪些数据集比较好?
解答: CPT 数据选取的底层原则是高信息密度 与分布多样性。数据集应按比例混合构建。
实例:构建一个金融领域模型的 CPT 数据集配比方案
-
核心领域数据 (60%): 上市公司招股说明书、财报文本、金融行业研报、宏观经济分析文章。要求剥离排版格式,转换为纯 Markdown 或纯文本。
-
领域术语与词典 (10%): 金融专业词典、百科的金融词条。
-
通用高质量能力保持数据 (30%):
-
代码 (Code): Python, SQL 脚本等(这被学术界和工业界证明是维持模型逻辑推理能力的最有效数据,即使是金融模型也必须喂代码)。
-
中英文维基百科 (Wikipedia): 维持通用常识。
-
数学数据: 维持严谨的计算逻辑。
-
3. SFT指令微调数据如何构建? & 用于大模型微调的数据集如何构建?
解答: SFT 数据构建从"量大"转向"质精"。构建流程依赖数据合成流水线。
-
构建方式(实例):
-
Self-Instruct (自我指令生成) / 知识蒸馏: 借助能力更强的模型(如 GPT-4)。提供几条种子指令(Seed Prompts),让 GPT-4 自动扩写出数万条不同场景、不同提问方式的指令数据。
-
人工改写(Human-in-the-loop): 针对 GPT-4 产出的数据,人工抽样检查,修正不符合特定领域逻辑的幻觉(Hallucinations)。
-
数据分布控制: 保证指令类型的多样性。例如一个医疗 SFT 库必须包含:
-
单轮问答(占 40%)
-
多轮追问(占 30%)
-
摘要生成(占 10%)
-
结构化信息提取(如抽取电子病历,占 20%)
-
-
1. 单轮问答(占 40%)
-
意思是: 用户提一个问题,模型直接给出一个完整的回答。这是最基础的知识调用能力。
-
医疗场景示例:
-
用户指令: "阿莫西林胶囊的常见不良反应有哪些?"
-
模型回复: "阿莫西林常见的不良反应包括:1. 胃肠道反应(恶心、呕吐、腹泻);2. 过敏反应(皮疹)......"
-
2. 多轮追问(占 30%)
-
意思是: 模拟真实的对话场景,模型必须能够记住上下文,并根据之前的对话内容进行连续回复。这对于AI问诊至关重要。
-
医疗场景示例:
-
第一轮: 用户:"我今天早上开始肚子痛。" 模型:"请问是哪个部位痛?有拉肚子吗?"
-
第二轮: 用户:"右下腹,没有拉肚子,但是有点发烧。" 模型:(记住前面的"肚子痛"和现在的症状)"右下腹疼痛伴随发热,需要警惕急性阑尾炎的可能,建议您......"
-
3. 摘要生成(占 10%)
-
意思是: 给模型输入一段冗长、复杂的文本,要求它提炼出核心要点。考验的是模型的理解和长文本压缩能力。
-
医疗场景示例:
-
用户指令: "请帮我总结以下这篇关于'2型糖尿病最新治疗指南'的 3000 字论文的核心观点。"
-
模型回复: 输出一段 200 字以内的精简摘要,列出最新的用药建议和饮食干预重点。
-
4. 结构化信息提取(占 20%)
-
意思是: 让模型像一个不知疲倦的助理,从杂乱无章的自然语言文本中,精准找出特定的信息,并按照规定的格式(如表格、JSON)输出。
-
医疗场景示例:
-
用户指令: "请从以下这段医生手写的出院小结中,提取出关键信息并填入系统:'患者王大爷,65岁,因头晕伴随呕吐3天入院,既往有高血压病史10年,一直吃硝苯地平,这次查出来是轻微脑梗......'"
-
模型回复:
-
姓名:王大爷
-
年龄:65岁
-
主诉:头晕伴呕吐3天
-
既往史:高血压(10年)
-
用药史:硝苯地平
-
初步诊断:脑梗死(轻微)
-
-
总结来说: 这段话是在设计一份"AI 医生的培训大纲"。40% 的精力用来背基础知识,30% 的精力练习和病人沟通,10% 的精力练习写报告摘要,20% 的精力练习整理病历档案。只有这样按比例组合构建 SFT 数据集,微调出来的医疗大模型才是真正好用、全能的。
4.领域模型微调指令&数据输入格式要求?
解答: SFT 数据必须遵循底座模型在预训练或其原版 SFT 时使用的特定模版(Prompt Template),通常包含系统提示词(System Prompt)、用户(User)和助手(Assistant)的标识符。
实例(以 ChatML 格式为例): 在进入 Tokenizer 前,一条 JSON 格式的数据: {"instruction": "解释量化宽松", "output": "量化宽松是一种货币政策..."} 必须被格式化拼接为以下字符串字面量:
<|im_start|>system
你是一个金融助手。<|im_end|>
<|im_start|>user
解释量化宽松<|im_end|>
<|im_start|>assistant
量化宽松是一种货币政策...<|im_end|>如果不使用底座模型认识的特殊字符(如 <|im_start|> 和 <|im_end|>),模型会将其视为普通乱码文本,导致微调失败,丧失对话能力。
5多轮对话任务如何微调模型?
解答: 多轮对话微调的核心在于数据拼接方式 和Loss 掩码(Label Masking)矩阵的构建。
-
物理计算机制实例: 假设有两轮对话:用户问 (U1) -> 助手答 (A1) -> 用户追问 (U2) -> 助手追答 (A2)。
-
序列拼接: 这四个部分会被拼成一个单一的长一维数组(Sequence)送入模型:
[U1, A1, U2, A2]。 -
Labels 数组构建: 我们要构建一个与输入维度完全一致的
labels数组。-
提问部分(U1, U2)不需要模型学,将其对应的 label 设为
-100。 -
回答部分(A1, A2)需要计算 Loss,保持其原本的 Token IDs。
-
-
底层数据阵列对照图:
-
Input_IDs:[ ID(U1), ID(A1), ID(U2), ID(A2) ] -
Labels:[ -100, ID(A1), -100, ID(A2) ]
-
-
通过这种底层的 Mask 设置,模型在一次前向反向传播中,就能同时学习到基于上下文回答第一轮和第二轮的能力,且不会因为"预测用户会问什么"而产生错误的梯度更新。
模块四:SFT核心策略与灾难性遗忘对抗
1. Base 模型与 Chat 模型在高维空间的特征分布差异
-
Base 模型(基座模型): 经历了海量无监督预训练(PT),其参数矩阵编码了庞大的客观世界知识。它的唯一目标是"续写文本",输入一个问题,它可能会续写另一个问题,而不是回答。它的特征分布是发散的、无约束的。
-
Chat 模型(对话/对齐模型): 在 Base 模型基础上,经过了 SFT 甚至是 RLHF(基于人类反馈的强化学习)。它的特征空间已经被"强行塑形",引入了严格的格式约束(如
system,user,assistant标签)和安全拒答机制。
2. 灾难性遗忘(Catastrophic Forgetting)的物理底层机制
在神经网络的损失地形(Loss Landscape)中,预训练得到的模型权重处于一个"通用知识的局部最优解"盆地。 当输入大量单一领域的微调数据时,反向传播产生的梯度向量会强行将权重矩阵朝着"领域任务最优解"的方向拉扯。这种物理层面上的权重漂移(Weight Drift),会直接覆盖或破坏原本编码在 MLP(多层感知机)层中的通用知识连接,导致模型"记住"了新格式,却"遗忘"了旧知识。
3. 指令微调的数据质量定律(LIMA 定律)
学术界和工业界的共识是:在 SFT 阶段,"Less is More"(少即是多)。SFT 的主要目的不是注入新知识(这是预训练的任务),而是激活模型原有的知识库并规范其输出格式。1,000 条高质量、多样化的 SFT 数据,产生的对齐效果远好于 100,000 条低质量、重复的数据。
QA:
1.指令微调的好处?
解答: 指令微调(SFT)将一个纯粹的"文本概率续写器"转变为一个"可交互的指令执行器"。
-
实例: 输入提示词"写一首关于秋天的诗"。
-
未微调的 Base 模型可能会输出:"写一首关于秋天的诗,写一首关于冬天的诗,小学三年级作文题目..." (它只是在做概率续写)。
-
经过 SFT 的模型,由于在训练数据中见过大量的
{"instruction": "...", "output": "..."}映射对,它会立即停止续写指令,转而生成符合格式的诗歌正文,并在结尾输出<EOS>停止符。
-
2.进行SFT操作的时候,基座模型选用Chat还是Base?
解答: 具体选择取决于你的任务目标和数据量,底层逻辑如下:
-
选择 Base 模型(推荐用于构建全新垂直领域模型):
-
原理: Base 模型像一张白纸(就指令格式而言),没有预设的 Prompt Template 约束。
-
适用场景: 当你有特定且复杂的指令格式要求,或者构建医疗、法律等极其专业的问答系统时。它的可塑性最强,但通常需要数万条高质量 SFT 数据才能将其完全拉平到对话模式。
-
-
选择 Chat 模型(推荐用于通用能力的快速微调或轻量级外挂):
-
原理: Chat 模型已经具备了优秀的对话能力和自我认知。
-
适用场景: 资源有限,或者只是想让模型学习某种特定语气(如"扮演某个角色")时。只需少量数据(几百条)即可。
-
风险: 必须严格使用该 Chat 模型原有的 Prompt Template 格式,否则你输入的新格式会与其底层已固化的特征分布发生冲突,导致模型输出混乱。
-
3.为什么SFT之后感觉LLM傻了?
解答: 这通常是因为过拟合(Overfitting)和数据多样性崩塌导致的。
-
实例剖析: 假设你的 SFT 数据集中有 10,000 条数据,且输出长度全部在 50 个 Token 以内,句式全部是"好的,结果如下:XXX"。
-
经过这样微调后,权重矩阵被极度窄化。即便你问它"请详细论述相对论的原理",它也只会生成几十个字的干瘪回答。模型失去了生成长文本和深度逻辑推理的"意图",因为它在 SFT 阶段被训练成了一个"只输出短句的机器人"。表现出来就是变"傻"了。
4.微调后的模型出现能力劣化,灾难性遗忘是怎么回事?
解答:
灾难性遗忘是神经网络更新机制的天然缺陷。
-
实例剖析: 原本的 LLaMA 模型在预训练阶段看过了海量的数学推导代码,具备解一元二次方程的能力。如果你用 50,000 条"纯中医问诊记录"对其进行全参数微调。
-
由于每一轮的反向传播都在强烈更新权重以降低"中医术语预测"的 Loss,那些原本负责存储"数学逻辑"的神经元连接权重(Weights)被中医数据的梯度无情改写。微调结束后,模型中医水平大增,但连 1+1=2的逻辑推理能力都被破坏了。
5. 领域数据训练后,通用能力往往会有所下降,如何缓解模型遗忘通用能力?
解答: 在工程实践中,缓解遗忘主要依靠以下两种底层干预手段:
-
数据混合重放(Data Mix-in / Replay):
-
在构建领域 SFT 数据集时,绝对不能只用领域数据。必须强制混入一定比例(通常是 10% 到 20%)的通用高质量对齐数据(如通用闲聊、数学推理、代码生成)。
-
物理意义: 这样在每一个 Batch 的反向传播中,梯度更新不仅有拉向领域方向的力,也有维持原有通用能力方向的力,从而将模型权重锚定在一个多任务平衡的区域。
-
-
采用参数隔离的微调技术(如 LoRA):
-
正如第一章所述,使用 LoRA 微调时,底座模型(Base Model)的权重被设为
requires_grad=False(完全冻结)。 -
物理意义: 既然通用知识矩阵的参数根本不发生改变,通用能力自然得到了最大程度的保留。领域能力则完全由外挂的 LoRA 旁路矩阵提供。
-
6.大模型LLM进行SFT如何对样本进行优化?
解答: 样本优化的核心是"降噪"与"提升信息熵"。具体优化操作如下:
-
消除格式污染: 剔除数据集中包含 HTML 标签、多余的空格、无法解析的转义字符的样本。这些噪音会消耗模型的参数容量去学习毫无意义的模式。
-
截断与填充控制: 尽量将长度相似的数据放在同一个 Batch 中(在 PyTorch 中通过自定义
collate_fn实现)。减少<PAD>占位符的数量,提高矩阵计算的有效信息密度。 -
复杂指令提升(Instruction Evolution): 如果全是"提取苹果的颜色"这种简单单轮指令,模型能力会劣化。必须人工或利用大模型扩写出复杂的、需要多步推理的指令(例如:"分析苹果在不同光照下的颜色变化规律,并以 JSON 格式输出"),以提高样本的训练难度(即提高梯度的信息量)。
模块五:超参调优、优化器与训练稳定性追踪
1. 优化器(Optimizer)的底层物理机制
神经网络的训练本质上是在一个极其复杂的高维空间中寻找最低点(Loss最低点)。
-
梯度(Gradient): 告诉我们当前位置最陡峭的下坡方向。
-
学习率(Learning Rate, LR): 决定我们在下坡方向上迈出多大的步子。 如果步子太大(LR过高),会直接跨过最低点甚至飞到更高的山上;步子太小(LR过低),则会在平缓区域停滞不前。
2. Global Batch Size(全局批次大小)的数学意义
在一次权重更新中,模型不是看一条数据就算一次梯度,而是看一批数据(Batch)。 这批数据产生的梯度会被平均,形成一个"综合下坡方向"。
-
Global Batch Size 越大,这个"综合方向"就越接近整个数据集的真实数据分布,梯度估算越准确。
-
真实工程中,受限于单卡显存,Global Batch Size 通常由三个物理量相乘得到:
Global_Batch_Size = 显卡数量 × 单卡批次大小(per_device_batch_size) × 梯度累加步数(gradient_accumulation_steps)
3. 混合精度训练中的数值溢出(Overflow)
如第一章所述,为了省显存我们常用 FP16(半精度浮点数)。但是,FP16 能表示的最大数值只有 65504 。 在反向传播时,如果某个梯度的计算结果超过了 65504,在底层计算中就会变成 NaN(Not a Number)或 Inf(无穷大)。这个错误的数值一旦参与权重更新,整个模型矩阵就会瞬间崩溃。
QA:
1.微调大模型时,优化器如何选择?
解答: 目前大模型训练的绝对工业标准是 AdamW(Adam with Weight Decay)。
-
底层机制: 传统的 SGD(随机梯度下降)每次只看当前的梯度。而 AdamW 内部维护了两个状态(一阶矩估计和二阶矩估计,即动量和方差)。它不仅看当前步的方向,还记住了过去的下坡惯性,并且能为每个单独的参数自适应地调整学习率。
-
为什么是 AdamW 而不是 Adam? AdamW 改进了权重衰减(Weight Decay)的计算方式,将其与梯度更新解耦,有效防止了模型权重矩阵中的数值变得过大,从而提升了模型的泛化能力。
-
显存极度受限时的平替方案: 如果显存严重不足,可以使用 8-bit Adam(通过 bitsandbytes 库调用)。它将 FP32 的优化器状态量化为 INT8,能直接省出大量的优化器显存,而对收敛精度的影响微乎其微。
2.微调大模型时,如果batch size设置太小会出现什么问题?
解答:
-
收敛困难(梯度噪音过大): 如果 Batch Size 只有 1 或 2,模型每次看到的样本极其片面。第一步的数据让它向左走,第二步的数据让它向右走,优化轨迹会像"醉汉走路"一样剧烈震荡,Loss 曲线极度不平滑,很难收敛到全局最优解。
-
算力严重闲置: GPU(尤其是其内部的 Tensor Cores)是为大规模并行矩阵乘法设计的。如果 Batch Size 太小,矩阵维度过低,无法填满 GPU 的计算单元,导致运算速度极慢(表现为 GPU 显存占满了,但 GPU 利用率 Volatile GPU-Util 只有 20-30%)。
3.微调大模型时,如果batch size设置太大会出现什么问题?
解答:
-
显存直接 OOM: 最直观的物理结果,激增的激活值会直接撑爆显存。
-
泛化能力下降(陷入尖锐局部最优): 纯数学层面的现象。过大的 Batch Size 会导致梯度方向过于精确。在极其平滑的优化轨迹下,模型很容易掉进损失地形中的"尖锐局部极小值"(Sharp Local Minima)。这种模型在训练集上 Loss 极低,但在遇到未见过的测试数据时,由于地形尖锐,稍有扰动 Loss 就会剧增(表现为泛化能力差)。
4.微调大模型时,batch size如何设置问题?
解答: 核心原则:在不 OOM 的前提下,通过梯度累加(Gradient Accumulation)维持一个合理的 Global Batch Size。
-
实例参考:
-
对于 7B - 13B 级别的模型进行 SFT,Global Batch Size 通常设置在 64 到 256 之间。
-
具体操作: 假设你有 4 张卡。每张卡受限于显存,
per_device_train_batch_size只能设为 2。此时物理吞吐量是 4 * 2 = 8。 -
为了达到 Global Batch Size = 64,你需要将
gradient_accumulation_steps设为 8(即:每做 8 次前向传播,才进行 1 次真正的权重更新)。
-
5.模型参数迭代实验(如何调超参?)
解答: 由于大模型训练成本极高,我们无法像传统机器学习那样进行暴力网格搜索(Grid Search)。超参迭代遵循以下优先级:
-
确定 Batch Size: 按照上个问题的方法,将其固定为一个合理值。
-
重点搜寻学习率(Learning Rate, LR): 这是影响最大的参数。SFT 阶段的 LR 通常比预训练阶段小 10 到 100 倍。
- 实例基准: 全参数微调通常在 1e-5 到 5e-5 之间测试;LoRA 微调由于只更新少量参数,LR 可以大一些,通常在 1e-4 到 3e-4 之间。
-
设置学习率调度器(LR Scheduler): 必须使用 Cosine with Warmup(余弦退火与预热)。
-
预热(Warmup): 训练前期的几十到几百步,让学习率从 0 慢慢增长到设定值,防止初始随机梯度过大炸毁模型。
-
余弦衰减: 随后让学习率按余弦曲线平滑下降,帮助模型在训练末期精准收敛到局部最低点。
-
6.大模型训练 loss 突刺原因和解决办法
什么是大模型训练 Loss 突刺?
- 现象: 观察 TensorBoard 中的 Loss 曲线,原本稳定下降的 Loss(比如一直在 1.2 左右徘徊),在某一个 Step 突然毫无征兆地飙升到 5.0 甚至 10.0 以上。模型之前建立的特征分布被瞬间破坏,哪怕后续 Loss 降回来,模型的能力也往往会发生不可逆的劣化。
为什么会出现 Loss 突刺?
-
原因一:脏数据攻击。 Batch 中突然混入了一条由乱码、连续的特殊符号组成的异常长文本。模型无法从历史分布中预测这些符号,导致预测概率接近 0,Cross-Entropy Loss 计算出极大的值。
-
原因二:数值溢出(FP16 的原罪)。 梯度的二阶范数在累加过程中超过了 FP16 的极限(65504),出现了
NaN梯度,毒化了优化器状态。 -
原因三:学习率或梯度过大。 遇到复杂样本时,反向传播计算出的梯度陡增,带着极大的步伐跨出了平稳区。
Loss 突刺如何解决?
底层干预手段如下(按优先级排序):
-
更换底层精度类型(极其有效): 如果你的显卡支持(Ampere 架构及以上,如 A100, RTX 30/40 系),立刻将 FP16 切换为 BF16(Bfloat16)。BF16 牺牲了一点点小数精度,但其指数位与 FP32 一致,其能表示的最大数值达到了 3.4 \\times 10\^{38},从物理层面上彻底杜绝了因精度导致的溢出突刺。
-
开启梯度裁剪(Gradient Clipping): 设置
max_grad_norm = 1.0。这是强制物理限速。在反向传播更新权重前,强制检查所有梯度的范数,如果超过 1.0,就按比例将其缩放回 1.0。这就保证了单次更新的步伐永远在一个安全范围内。 -
跳过坏数据与回滚: 如果突刺已经发生且无法挽回,必须从 Checkpoint(检查点)读取突刺发生前几个 Step 的模型权重和优化器状态。同时排查那个时间点送入模型的 Batch 数据,手动清洗掉导致崩溃的脏数据。
模块六:从零到一的全流程实战与评测
1. 大模型落地的 MLOps 标准流水线
-
数据工程 (Data Engineering):
-
数据采集与清洗:去重、去隐私(PII过滤)、质量打分。
-
指令微调(SFT)数据构建:Prompt 设计、多轮对话构造、数据增强。
-
-
模型训练与微调 (Training & Tuning):
-
算力调度与分布式训练(Megatron-LM, DeepSpeed)。
-
高效微调技术(PEFT):如 LoRA, QLoRA, P-Tuning,降低企业落地成本。
-
-
模型部署与推理优化 (Deployment & Inference):
-
模型量化(Quantization):INT8, INT4 (AWQ, GPTQ) 以降低显存占用。
-
推理加速框架:vLLM (PagedAttention 优化显存), TensorRT-LLM。
-
-
监控与反馈闭环 (Monitoring & Feedback):
-
性能监控:Token 生成速度(Tokens/sec)、首字延迟(TTFT)。
-
质量监控:监控模型是否出现"幻觉"或数据偏移。
-
数据飞轮: 收集用户的真实输入与反馈,将其清洗后重新加入训练集,实现模型的持续迭代。
-
2、 中文大模型训练的特殊考量
训练一个优秀的中文大模型,不能简单地照搬英文模型的经验,需要解决两个痛点:
-
痛点一:高质量中文语料稀缺性
-
现状: 互联网上高质量的中文学术、代码、逻辑推理数据远少于英文。
-
对策:
-
精细化清洗: 对中文网页数据进行极高标准的清洗,去除大量水军内容和低质广告。
-
机器翻译与跨语言对齐: 将高质量的英文指令集翻译成中文,或者通过双语语料让模型具备"英文理解,中文输出"的跨语言能力。
-
合成数据(Synthetic Data): 使用更强的模型(如 GPT-4)自动生成高质量的中文垂类对话和逻辑链(CoT)数据。
-
-
-
痛点二:分词效率优化 (Tokenization)
-
现状: 原生的英文大模型(如 LLaMA)词表对中文支持极差,通常将一个汉字切分为多个 Byte,导致中文字符的 Token 数量暴增。这会极大消耗上下文窗口(Context Window),并严重拖慢推理速度。
-
对策(扩表机制):
-
在原有的 BPE(Byte-Pair Encoding)或 SentencePiece 词表基础上,加入几万个常见的高频中文词汇或字。
-
在中文语料上重新训练 Tokenizer 的 embedding 层,使得模型在编码中文时,一个词甚至一个短语只占用一个 Token,大幅提升编解码效率。
-
-
3、 领域评测集构建原则与评估方法
"没有准确的评测,就没有进步的方向。" 针对特定垂直领域(如医疗、法律、金融),构建评测集是落地的第一步。
-
客观题与主观题的构建:
-
客观题(选择/判断/填空): 便于自动化评估,计算 Accuracy(准确率)或 F1 Score。常用于考察模型的硬知识(如 C-Eval, CMMLU 的模式)。
-
主观题(生成/总结/翻译): 考察模型的逻辑连贯性、语气和长文本生成能力。传统 NLP 的指标(如 BLEU, ROUGE)对大模型已基本失效,因为它们只看重字面重合度,无法评估语义的准确性。
-
-
核心评估指标:
-
困惑度 (Perplexity, PPL): 评估基础模型(Base Model)的核心指标。PPL 越低,说明模型对该领域语言的规律掌握得越好,预测下一个词的准确度越高。但 PPL 低不代表它是一个好的对话助手。
-
人类对齐评估:
-
Reward Model (奖励模型): 使用 RLHF 阶段训练出的奖励模型,对当前模型生成的回答进行打分。
-
LLM-as-a-Judge (大模型作为裁判): 目前最主流的高效主观评测方法。使用 GPT-4 或 Claude 3 等顶级模型作为"裁判",给定详细的评分Prompt(包含相关性、准确性、安全性等维度),让其对被测模型的回答进行 1-5 分的打分或胜率比对(Win Rate)。这极大降低了人工标注成本。
-
-
总结:
第一步:准备底座与数据
在工业界,我们极少从头写代码训练模型,都是站在巨人的肩膀上。
-
选模型(解决中文问题): 你打开 HuggingFace 网站,准备下载一个开源模型作为底座。此时你面临选 LLaMA-3(纯英文底座)还是 Qwen-2.5(通义千问,中文底座)。 底层物理差异实例: 同样输入"《中华人民共和国民法典》"这11个汉字。 LLaMA-3 的词表里没有这些汉字,它会在底层把这11个字强制拆解成几十个无意义的 UTF-8 字节(Tokens)来计算。这不仅极度浪费显存,还会导致模型算不出这几个字的关联。 而 Qwen 的词表扩充过中文,它可能只需要 4 个 Token 就能精确表示这句话。 实战结论: 做中文大模型,直接下载 Qwen、GLM 或 DeepSeek 这类原生支持中文的基座。
-
造数据(核心建议:数据质量远大于参数量): 你手里有 100 万条网上乱爬的法律帖子,和 5000 条顶级律师手写的问答。 实战操作: 直接扔掉那 100 万条垃圾数据。把那 5000 条律师问答,严格按照底座模型认识的格式拼装好。微调前,必须打印出第一条数据看一眼:如果你看到数据里混进了
<html>标签或者乱码,立刻停止训练,回去写 Python 脚本洗数据。
第二步:防爆雷的试训练
数据搞定后,绝不能直接投入几万块钱的算力去跑全量数据。
-
永远先跑 LoRA: 冻结刚刚下载的 Qwen 模型原参数,只外挂一个极小的 LoRA 矩阵。
-
跑一个极小批次: 先只抽取 200 条数据,跑 10 分钟。
-
观察 Loss 曲线(防骗局): 你盯着屏幕上的 Loss 数值。 如果训练集 Loss 一路降到了 0.01,但验证集(Validation Set,你预留的没参与训练的50条数据)的 Loss 却在往上飙升。 实战结论: 你的模型"死记硬背"了那 200 条数据,但失去了举一反三的能力(过拟合)。你必须立刻停止训练,回去增加数据的多样性,或者调大 Dropout 参数。
第三步:怎么判断模型练成了?
模型训练完后,你怎么向老板或自己证明它变强了?传统计算字面重合度的指标已经没用了,你必须上"双轨制"评测:
-
客观题直接闭卷考试(自动化评估): 你收集 1000 道真实的国家司法考试单选题。用脚本把题目输入给你的微调模型。 评测代码逻辑: 只要模型输出的第一个字母不是 A、B、C 或 D 中的正确答案,直接判 0 分。统计最后的精确匹配率(Exact Match)。这能测试模型有没有把基本法律条文背错。
-
主观题请外援当裁判(LLM-as-a-Judge): 你输入一个极其复杂的案例:"张三借了李四的钱,担保人是王五,现在张三跑了,李四怎么要钱?" 你的模型给出了一大段回答。你怎么打分? 实战操作: 写一个 Python 脚本,调用顶级模型(比如 GPT-4)的 API。把你模型的回答,连同标准答案一起发给 GPT-4,并附上指令:"你是一个资深法官,请根据法律准确性、逻辑清晰度,给下面这段回答打分,满分 5 分。"用 GPT-4 的打分作为你模型的最终能力得分。
QA:
1.如何训练自己的大模型?
从零开始(From Scratch)预训练一个大模型对绝大多数团队是不现实的(动辄数千万人民币算力)。这里的"训练自己的大模型"在工程上通常指基于开源底座的垂直领域全流程开发。具体实例步骤如下:
-
算力与基座盘点: 确认手头有几张卡。如果是单卡 24G/40G,锁定 7B-8B 规模的模型(如 Llama-3-8B, Qwen-2.5-7B),采用 LoRA 微调;如果有 8 张 A100 80G,可以考虑 14B-32B 规模的全参数微调。
-
构建数据飞轮: 不要一开始就急于训练。花 80% 的时间写 Python 脚本处理数据。制定严格的去重、清洗、格式化流水线。
-
跑通微小规模 Baseline: 先抽样 1000 条数据,用上述跑通一次完整的 SFT。测试模型是否学会了基本格式,是否能正常推理,Loss 是否正常下降。
-
全量训练与 Checkpoint 保存: 将全量数据输入,训练过程中每隔几百个 Step 保存一次 Checkpoint。
-
模型合并与推理: 如果是 LoRA 微调,训练产出的只是一层极小的参数权重(几十 MB)。需要使用脚本将这层 LoRA 权重与原始 Base 模型权重进行矩阵相加(合并),得到最终的独立模型。
2.训练中文大模型有啥经验?
解答: 中文大模型的底层痛点主要集中在分词效率(Tokenization Efficiency)和语料污染上。
-
Tokenizer 编码压缩率问题:
-
底层逻辑: 原生 LLaMA 等英文模型,其词表中中文词汇极少。遇到中文时,底层通常会退化为
Byte-fallback机制,将一个汉字拆分成 3 个 UTF-8 字节进行编码(即 1 个汉字 = 3 个 Token)。 -
物理后果: 这会导致显存消耗剧增(Sequence Length 变长 3 倍),且模型很难学到中文词汇的整体语义。
-
经验: 必须选择原生对中文支持极好的基座模型(如 Qwen, GLM, DeepSeek,它们 1 个 Token 平均能表示 1.5 到 2 个汉字)。如果非要用纯英文底座,必须进行词表扩增(参考第三章第 10 题)。
-
-
中文数据的"脏数据清洗":
-
中文互联网语料含有大量的 SEO 垃圾、繁简混杂、特殊全角字符。
-
经验: 必须在数据处理流中加入严格的启发式规则(Heuristic Rules)。例如:如果一段文本中出现连续的 5 个以上特殊符号,直接丢弃;使用
OpenCC库统一进行繁转简处理,减少同一概念在特征空间中的分裂。
-
3.领域模型微调领域评测集构建?
解答: 评测集必须在微调开始前 就构建好,且绝对不能与训练集有任何重合。一个严谨的领域评测集构建实例如下(以医疗领域为例):
-
客观知识评测集(2000 题):
-
来源: 收集历年国家执业医师资格考试的单选题。
-
格式构建:
{"prompt": "患者心梗,首选药物是? A... B... C... D...", "target": "B"} -
评测方法: 计算模型输出文本的第一个字符是否精准命中 target。这用于评估 CPT/SFT 过程中是否发生了知识遗忘。
-
-
主观业务评测集(300 - 500 题):
-
来源: 由真实医生撰写的典型病历或高频医患对话记录。
-
类目分布: 涵盖"症状分析"、"用药建议"、"禁忌症警告"等不同维度。
-
评测方法: 部署一个自动化裁判脚本,调用 GPT-4 API,将微调模型的回答输入,要求 GPT-4 按照"安全性(是否有致死用药建议)"、"专业性"、"通俗性"三个维度给出 1-5 分的打分。
-
微调大模型的一些建议
最后,总结几条经过无数经费燃烧换来的建议:
-
格式即正义: SFT 训练失败,90% 的原因是因为你输入的数据格式,和底座模型预期的系统特殊符(如
<|user|>、<bos>、<eos>)不一致。微调前,一定要手写脚本,把 Tokenizer 编码后的数据再decode(解码)回文本看一眼,确保拼接严丝合缝。 -
警惕 Loss 骗局: 训练集 Loss 降到极低(比如 0.1 以下)不一定是好事,很可能是严重过拟合。必须同时观察验证集(Validation Set)的 Loss 曲线。如果验证集 Loss 开始拐头向上,立刻停止训练(Early Stopping),此时模型已经开始死记硬背,泛化能力正在崩溃。
-
永远先做 LoRA: 无论你有多少算力,接触新任务时,永远先用 LoRA 跑一个 Baseline。LoRA 的训练速度快、容错率高。当确定数据质量没问题、超参大致摸清后,再去尝试代价高昂的全参数微调。
-
数据质量 大于 模型参数量: 一个用 10,000 条极高质量人工精调数据微调出来的 7B 模型,在特定领域的表现,大概率会物理碾压一个用 1,000,000 条粗糙爬虫数据微调出来的 32B 模型。把精力花在数据上,永远是收益最高的投资。