目录
[(1)稠密模型(Dense Model)](#(1)稠密模型(Dense Model))
[(2)混合专家模型(Mixture of Experts, MoE)](#(2)混合专家模型(Mixture of Experts, MoE))
[(2)Router 对输入打分](#(2)Router 对输入打分)
[(3)被选中的 Expert 处理输入](#(3)被选中的 Expert 处理输入)
[(4)将多个 Expert 的结果聚合](#(4)将多个 Expert 的结果聚合)
参考1: 图文跨模态融合基础 1 :大语言模型(LLM) -CSDN博客
参考2: https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-mixture-of-experts
一、概念
稠密模型(Dense Model)和混合专家模型(MoE,Mixture of Experts)是当前主流大模型(LLM)的常用架构,二者均建立在经典的Transformer架构之上,但在参数分配和Token处理上有一定的差别。
根据我们对大模型的学习可以知道,大模型本质上是一个基于 Transformer 的自回归解码器,其基本流程是:输入 Token 先经过嵌入层映射到高维向量空间,再通过多层注意力机制与前馈网络逐层提取特征,最终输出下一个 Token 的概率分布。在这一过程中,注意力模块主要负责建模上下文依赖关系,而前馈网络(FFN)则承担特征变换与非线性表达的重要作用。
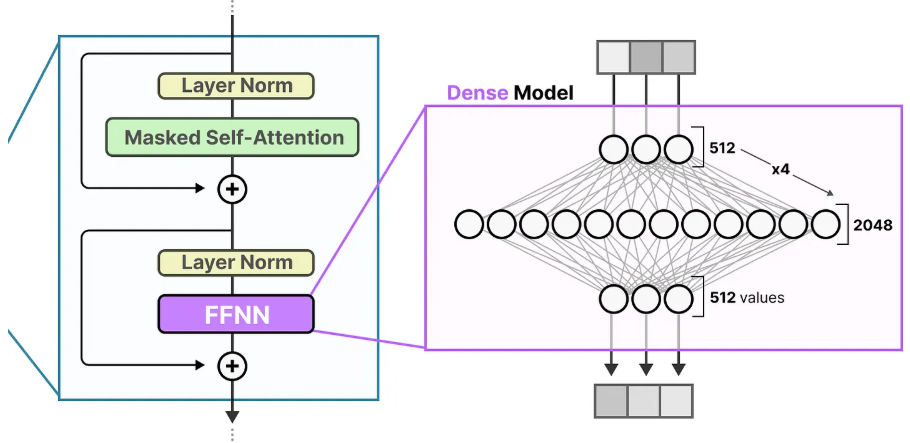
简单来说:稠密模型(Dense)是全员计算,MoE 模型是稀疏激活、专家分工 。核心区别在于:稠密模型每次激活全部参数,MoE 只激活少数专家,从而在保持大容量的同时降低计算成本。
(1)稠密模型(Dense Model)
机制 :全参数激活 。每个输入(token)都经过模型所有参数计算。
结构:标准 Transformer,FFN 是单一、完整的全连接层。
比喻 :全能大厨------ 做任何菜都动用所有厨具。
代表:Llama 1/2、GPT-3、BERT。
(2)混合专家模型(Mixture of Experts, MoE)
机制 :稀疏激活 。每层 FFN 替换为N 个专家(小 FFN)+ 1 个门控(Router) 。门控为每个输入选择 Top-K 个专家 计算(通常 K=1 或 2)。
结构:
- 专家(Experts):多个并行小网络,各司其职。
- 门控(Gate/Router):分配输入到最合适的专家。
比喻 :专家团队 + 分诊台------ 任务分给专科医生。
代表:DeepSeek-V3、Qwen 3-MoE、Switch Transformer。
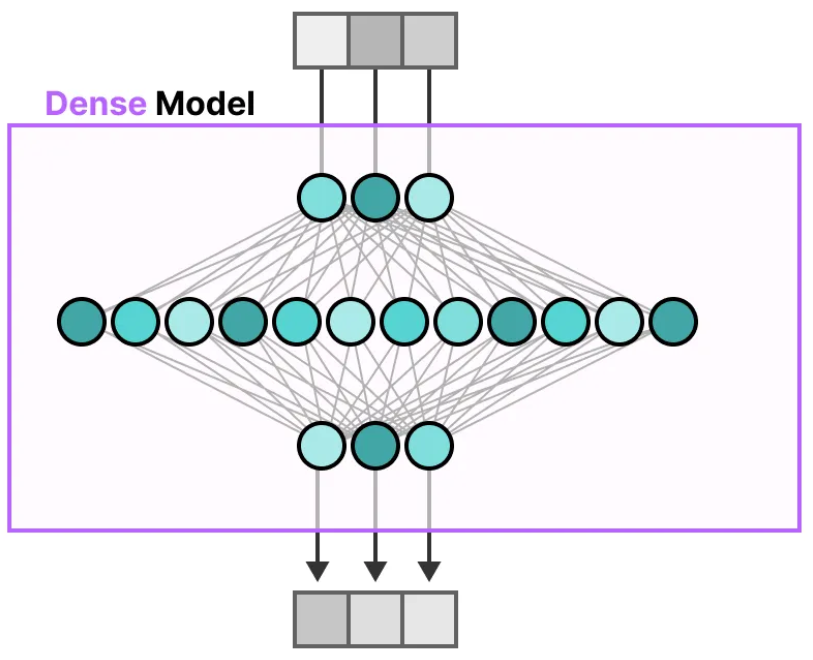
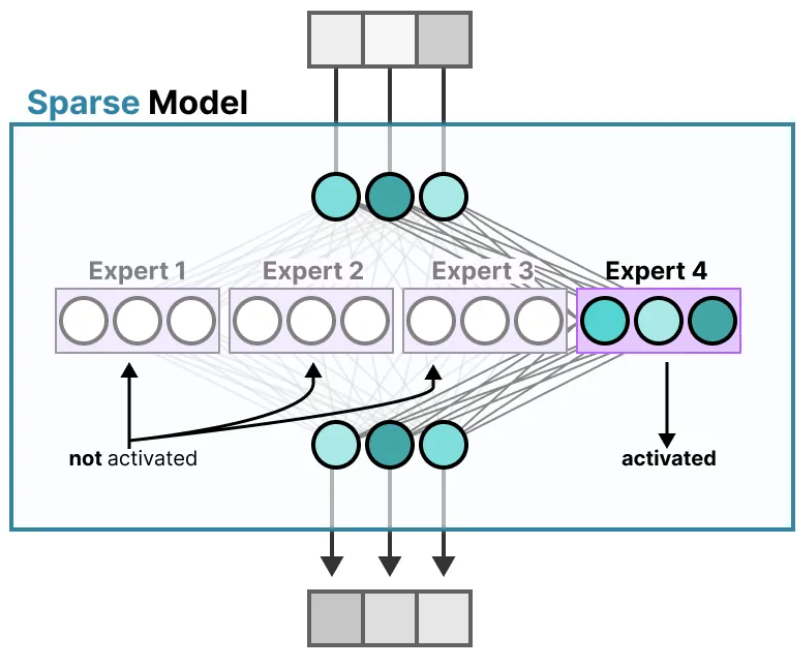
本文主要对MoE做一个笔记,Dense Model主要是传统大模型,无需刻意学习,若要了解见参考1。
二、结构原理
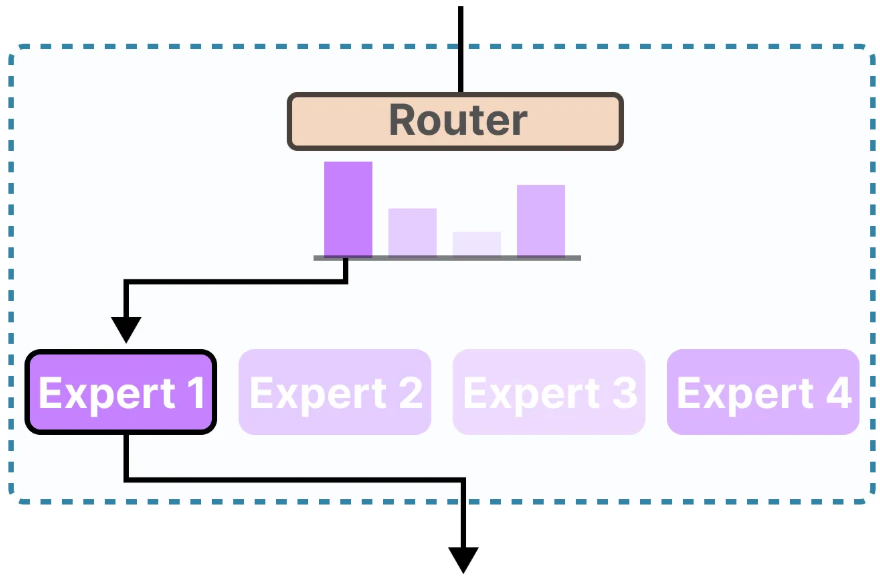
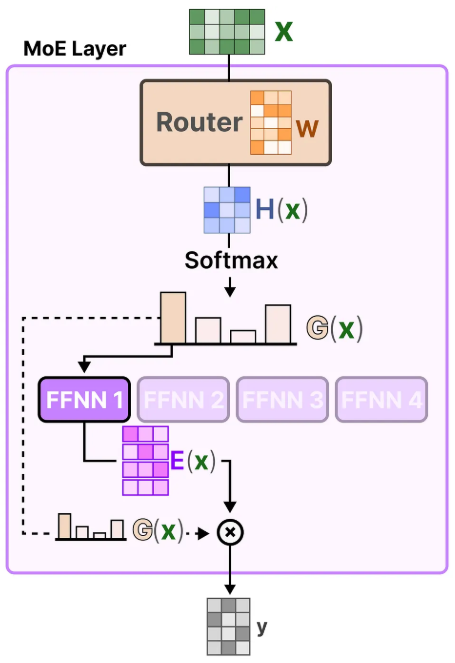
 相比于传统Dense Model,MoE每次的推理不会调用全部的参数 。一般来讲,对于一个MoE模型,会给出总共的参数量和可激活参数量。对于输入,MoE会先经过一个路由(Router) 对输入内容进行打分,对于每一个专家网络(Expert) 都有一个相应的分数,最后会挑选出分数最高的专家进行处理。
相比于传统Dense Model,MoE每次的推理不会调用全部的参数 。一般来讲,对于一个MoE模型,会给出总共的参数量和可激活参数量。对于输入,MoE会先经过一个路由(Router) 对输入内容进行打分,对于每一个专家网络(Expert) 都有一个相应的分数,最后会挑选出分数最高的专家进行处理。
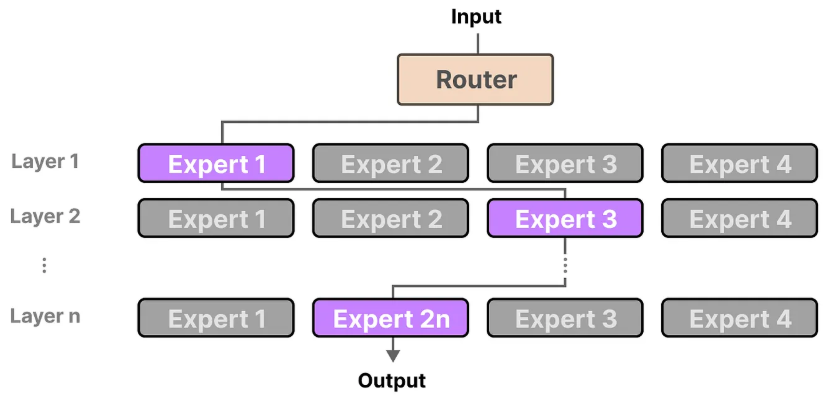
需要注意的是,MoE 中的专家通常是"层内并列、层间独立"的:不同层的专家虽然结构相同,但参数并不共享,Token 也会在每一层重新进行路由选择。另外每个专家的职能无法被具象的描述,如"心理学专家"、"生物学专家"等,而是对于特定token和上下文的一种特定偏好。
对于 Expert,我们可以将其理解为 Transformer 某一层中并列放置的多个前馈子网络(FFN),而不是一个完整的大模型。每个 Expert 都具有独立参数,并在训练过程中逐渐形成不同的功能偏好,因此更擅长处理某一类输入模式。这样一来,MoE 的核心并不是单纯"把大模型拆开",而是通过"路由选择 + 专家分工"的方式,使不同输入能够调用更合适的参数子集。
MoE的专家网络的设定,让其与传统Dense Model相比,MoE能在不显著增加单次推理计算量的前提下,引入更大的总参数规模,从而提升模型容量与表达能力。也就是说,Dense 是"所有参数同时参与计算",而 MoE 是"总参数很多,但每次只激活其中一部分"。前者结构更统一、计算更稳定,后者则更强调按需调用和专家协同。
因此,MoE 可以看作是在 Transformer 框架下,对前馈层进行稀疏化扩展的一种架构设计。它保留了大模型高容量的优势,同时通过稀疏激活降低了实际计算开销,这也是当前许多大规模语言模型采用 MoE 结构的重要原因。
三、基本流程
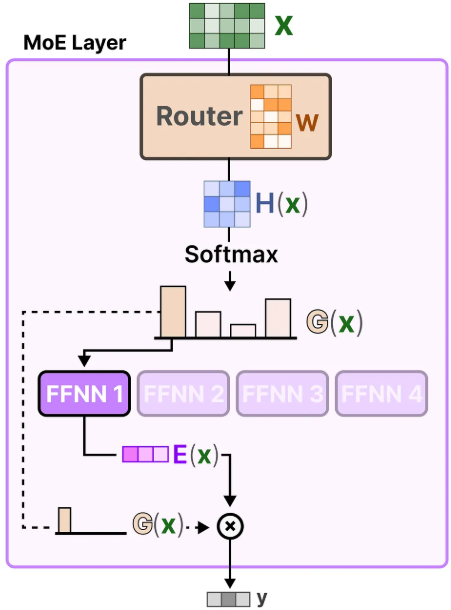
可以把 MoE 的整体流程概括成 "输入---路由---专家计算---聚合---输出" 五步。
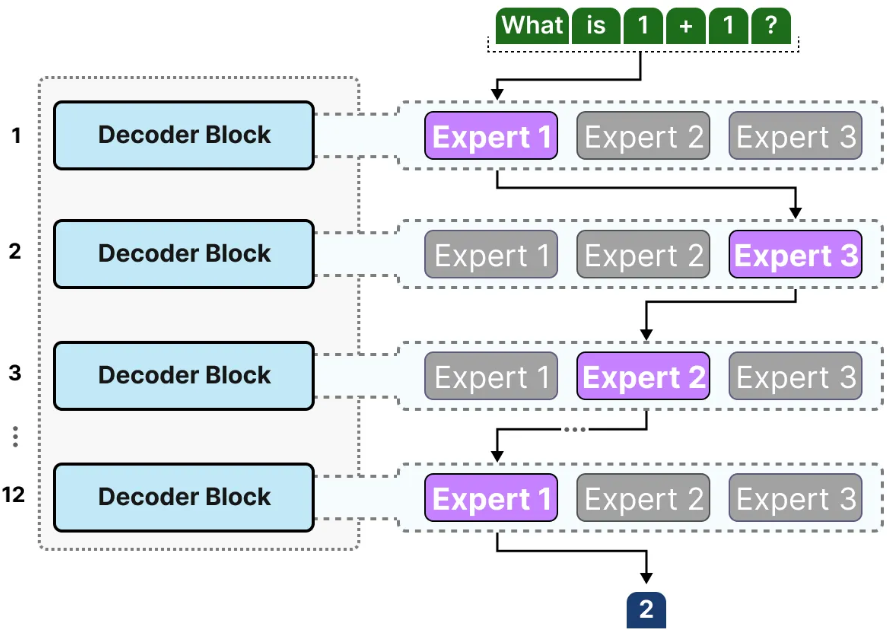
(1)输入进入当前层
在大语言模型里,输入通常不是原始文本本身,而是文本经过分词、嵌入和前面若干层处理后得到的 token 表示向量 。
当这些向量进入某一层的 MoE 模块时,就开始进行专家选择。
(2)Router 对输入打分
MoE 层里会有一个 路由器(Router) 。
它会根据当前 token 的隐藏表示,对这一层的所有专家分别计算一个分数。这个分数表示:
- 当前 token 更适合交给哪个 expert 处理
- 哪些 expert 更可能对这个 token 有用
一般不会让所有 expert 都参与,而是只选分数最高的少数几个,比如 top-1 或 top-2。
(3)被选中的 Expert 处理输入
被选中的 expert 本质上通常是若干个并列的 前馈网络(FFN) 。
每个 expert 都有自己独立的参数,因此即使结构相同,学到的处理方式也可能不同。
于是,当前 token 只会被送到被选中的 expert 中进行计算,而不会经过所有专家。
这就是 MoE 的核心:稀疏激活。
(4)将多个 Expert 的结果聚合
如果只选了一个 expert,那么它的输出就直接作为这一层 MoE 的结果。
如果选了多个 expert,比如 top-2,那么通常会根据 router 给出的权重,对多个 expert 的输出进行 加权求和或聚合,形成该 token 在这一层的最终输出。
也就是说:
- Router 不仅负责"选谁"
- 往往还负责"每个 expert 占多大权重"
(5)输出传给后续网络
聚合后的结果会继续沿着 Transformer 的后续路径往下走,例如:
- 残差连接
- 归一化
- 下一层注意力或下一层 MoE/FFN
如果后面还有别的 MoE 层,那么到了下一层会 重新路由一次 。
同一个 token 在不同层里,可能会被分配给完全不同的 expert。
四、筛选机制
(1)路由机制
Router在本质上,也是一个FNN,用于根据特定输入选择专家。它输出概率值,并用这些概率值来选择最佳匹配的专家。对于MoE,一般存在两种机制即**"稀疏专家,Sparse MoE"** 和"稠密专家,Dense MoE", 两者都使用路由器来选择专家,但稀疏 MoE 只选择少数专家,而密集 MoE 选择所有专家,但分布可能不同。
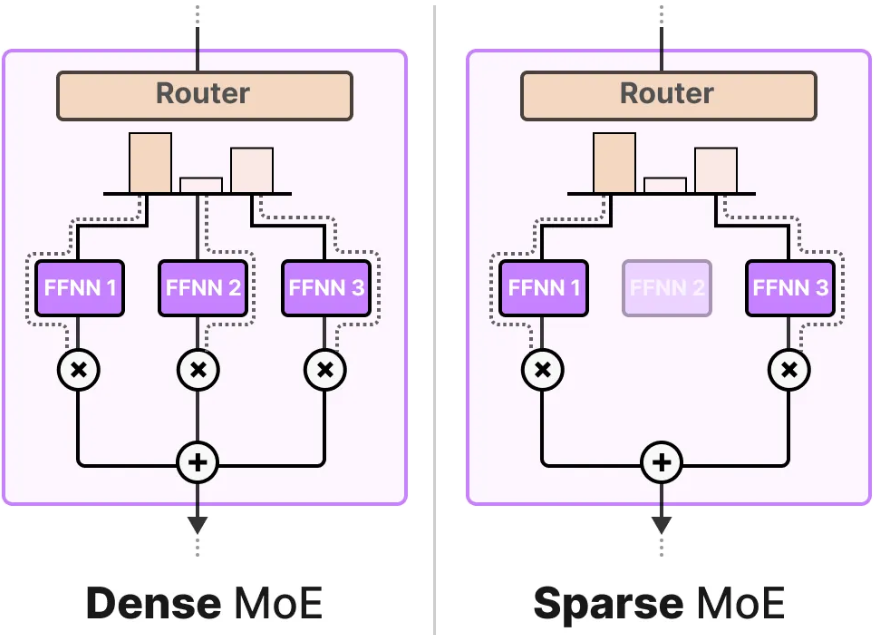
(2)专家筛选
专家遴选的本质,就是先由路由器对输入进行打分,再将分数转为概率分布,据此选出最匹配的专家,并对专家输出加权聚合,形成最终结果。
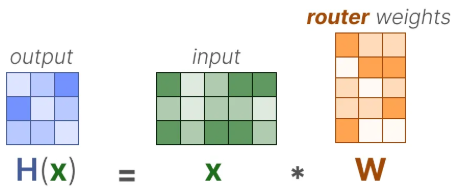
第一步,路由打分。
输入先与路由器权重矩阵
相乘,得到一个打分向量
。这个向量可以理解为:当前输入对各个专家的原始匹配分数。
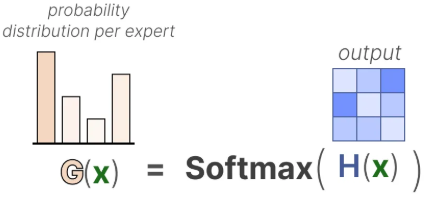
第二步,概率归一化。
再对做
,得到
。此时每个分量都表示当前输入分配给对应专家的概率或权重,也就是各专家对该输入的相对适配程度。
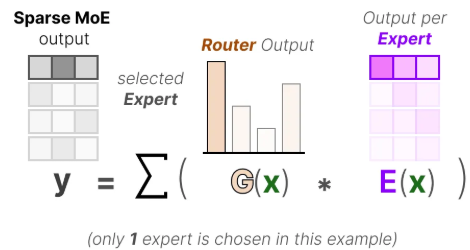
第三步,专家选择与加权输出。
路由器根据选择最合适的专家(或 top-k 个专家),然后将这些被选中专家的输出
按对应权重进行加权求和,得到最终输出
。如果是稀疏MoE,就不会调用全部专家,而只调用得分最高的少数几个专家。
(3)负载均衡
负载均衡是指在 MoE 训练过程中,尽量避免只有少数专家被频繁调用,而其余专家长期闲置的机制。
在理想情况下,不同输入应当被较为合理地分配到不同专家,使各个 expert 都能参与训练并形成分工。但如果路由器总是偏向少数几个专家,就会出现两个问题:
- 专家塌缩:部分专家几乎承担了所有计算,其他专家学不到东西;
- 资源浪费:模型虽然总参数很多,但真正发挥作用的只有少数专家。
因此,MoE 中通常会加入负载均衡损失,对路由结果进行约束,使专家的调用频率和分配权重尽量更均匀。这样做的目的不是让所有专家绝对平均,而是防止路由过度集中,提升专家利用率和训练稳定性。
可以概括成一句话:负载均衡就是通过额外约束,防止 MoE 中路由过于集中到少数专家,从而让更多专家都能被有效使用。
五、思考
假设在某一个范畴,没有更好的专家覆盖,比如打分都低于某个阈值,那效果会不会比稠密差呢?
MoE 可能比稠密差,原因主要有几个:
(1)路由错误
本来这类输入就难分,router 还可能选错 expert。
一旦选错,剩下没被激活的 expert 再强也没用。
(2)专家覆盖不全
训练数据里这类样本少,或者训练过程中没有形成稳定分工,导致没有 expert 专门学到这块。
(3)稀疏激活带来的局部信息损失
稠密模型对每个输入都让同一套 FFN 全量参与;
MoE 只让少数 expert 参与。
如果"少数 expert"覆盖不到这个 corner case,表现就会掉。
因此,在局部难例、长尾分布、覆盖不足的区域,MoE 确实可能比稠密更差。
工程上如何缓解MoE对Expert打分都低的情况?
常见办法有:
- top-2 / top-k 路由:别只选一个 expert,降低押错宝风险
- shared expert / shared FFN:保留一条"所有输入都能过的公共稠密通路"
- load balancing:避免所有数据只训练少数 expert
- 更好的辅助损失或路由正则
- 扩大长尾样本覆盖
其中最该注意的是 shared expert 。
这东西本质上就是在说:
就算专科都不靠谱,至少还有一个"公共医生"兜底。
这能明显缓解你说的"这块输入没人覆盖"的问题。
假如我用的是成品冻结MoE,那么其相对于稠密模型的计算能力,除了算的快的话差距是不是也会很小?
这里要分三种情况:
1. 和"同等激活计算量"的稠密模型比
比如:
- MoE:总参数 100B,但每次只激活 12B
- 稠密:一个 12B dense model
这种比法下,MoE 往往不只是更快 ,而且通常能力还会更强一些,因为:
- 它虽然每次只算 12B 左右
- 但它背后有更大的总参数池
- 不同 token 可以调用不同专家
所以本质上它是在用稀疏路由 换取更大总容量
这也是 MoE 设计最核心的收益:
在接近 12B 的单次计算成本下,得到接近更大模型的一部分容量收益。
所以这时候差距不一定小。
2. 和"同等总参数量"的稠密模型比
比如:
- MoE:总参数 100B
- Dense:也是 100B
那 dense 往往每次都要把 100B 全算一遍,计算代价大很多。
这时 MoE 的主要优势当然是省算力。
但能力上不一定谁绝对更强,因为:
- dense 是全参数协同
- MoE 是分专家稀疏协同
有些任务 dense 更稳,有些任务 MoE 更强。
所以这时不能简单说"冻结后差距很小",因为它们的结构优势根本不同。
3. 和"一个已经很强的中等规模 dense 成品模型"比
如果拿一个冻结成品 MoE ,去和一个同代际、同训练质量、同用途的 dense 模型比,实际体验里常常会出现:
- 整体差距没有想象中那么夸张
- 很多普通任务上,差距确实可能不大
- 但在某些更复杂、分布更杂、知识覆盖更广的场景里,MoE 可能更有上限
也就是说:
MoE 的优势常常不是"每道题都碾压",而是"在相近推理成本下,把能力上限再往上抬一点"。