数据结构
数据结构在学什么?
- 如何用程序代码把现实世界的问题信息化
- 如何用计算机高效地处理这些信息从而创造价值
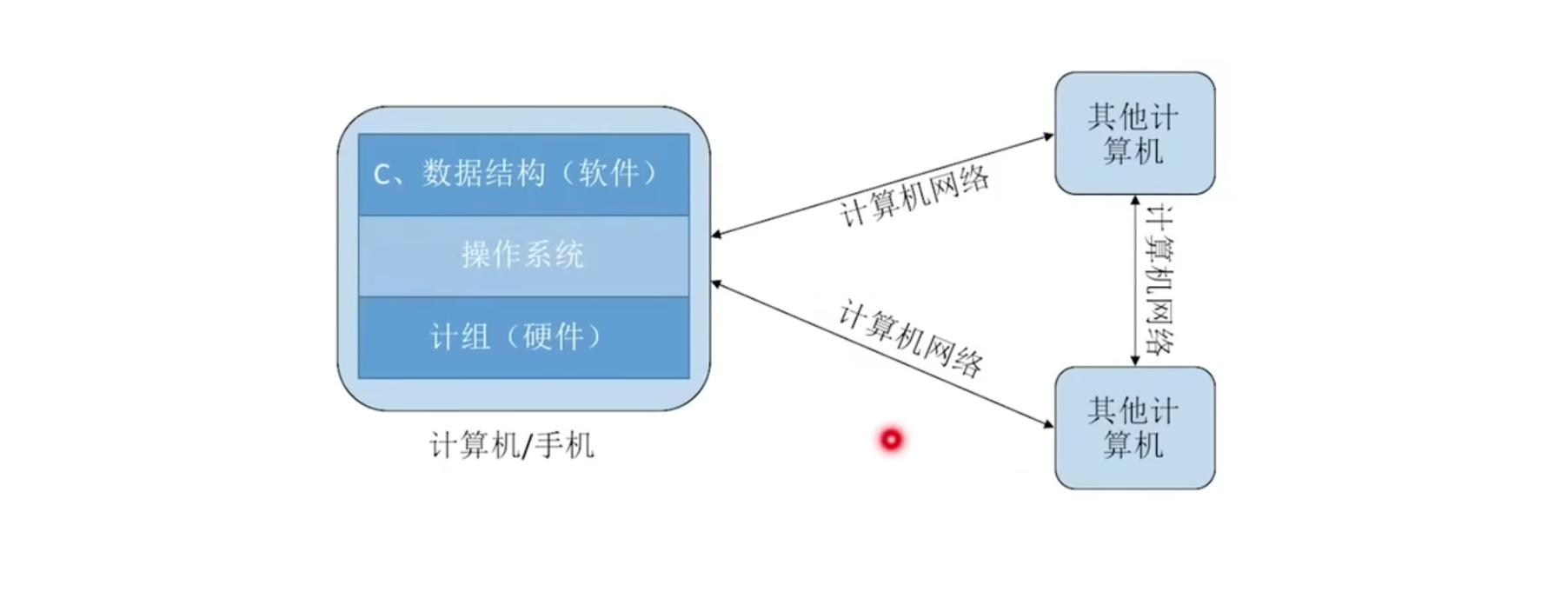
计算机组成原理:硬件,CPU,内存,主板,计算机底层的这些硬件的工作原理是什么
操作系统:研究ios、安卓等系统是怎么工作的,怎么管理你的手机管理你的电脑
数据结构:软件,应用软件的开发处理现实世界的问题
计算机网络:实现了各个计算机之间的互联互通,相互之间是怎么传递信息的
例图:
1 数据结构的基本概念
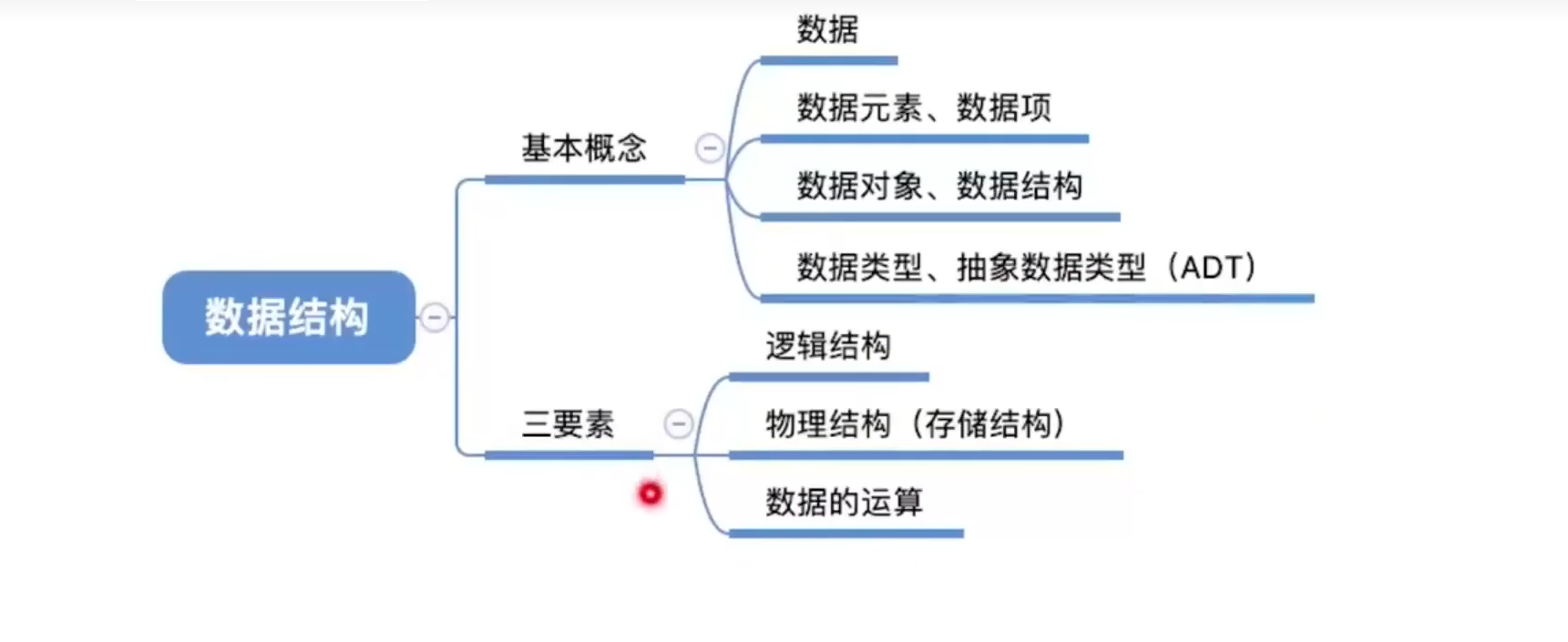
- 数据:
数据是信息的载体,是描述客观事物属性的数、字符以及所有能输入到计算机中并被计算机程序识别和处理的符号的集合,数据是计算机程序加工的原料。
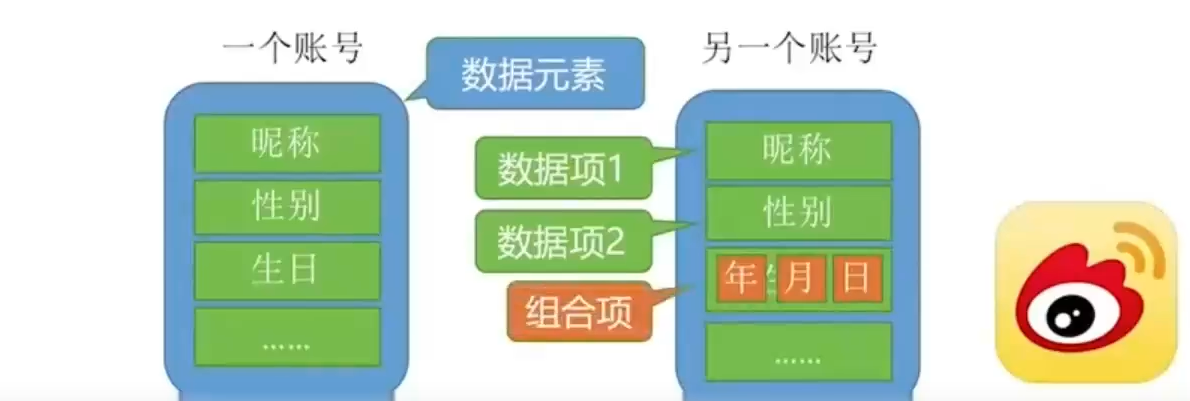
- 数据元素、数据项:
数据元素是数据的基本单位,通常作为一个整体进行考虑和处理。
一个数据元素由若干数据项组成,数据项是构成数据元素不可分割的最小单位。
- 结构
各个元素之间的关系。
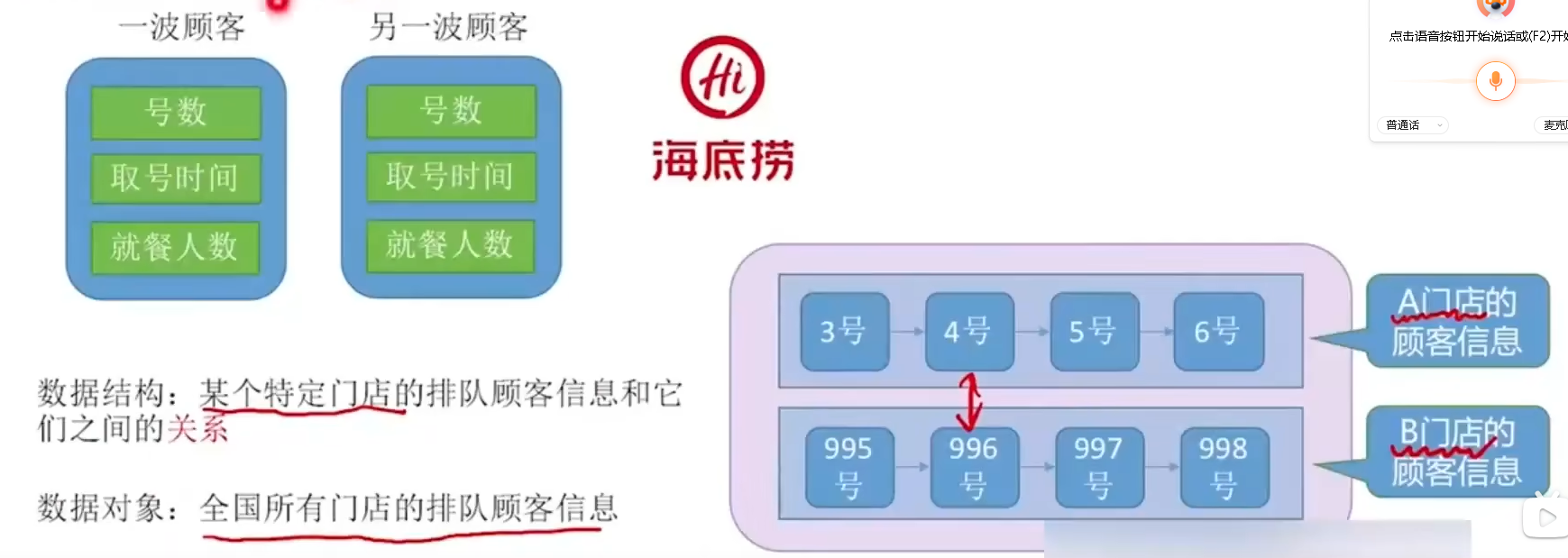
- 数据结构、数据对象
数据结构是相互之间存在一种或多种特定关系的数据元素的集合(数据元素之间的关系)。
数据对象是具有相同性质的数据元素的集合,是数据的一个子集(只强调性质,与元素之间无关)。
2 数据结构的三要素
2.1 数据的逻辑结构
探讨数据元素之间的逻辑关系是什么?
数据的逻辑结构分为:集合、线性结构、树形结构、图状结构(网状结构)
-
集合:各个数据元素同属一个集合,别无其他关系。
-
线性结构:数据元素之间是一对一的关系,除了第一个元素,所有元素都有唯一前驱,除了最后一个元素,所有元素都有唯一后继。
-
树形结构:数据元素之间是一对多的关系。
-
图状结构:数据元素之间是多对多的关系。
2.2 数据的物理结构(存储结构)
探讨如何用计算机表示数据元素的逻辑关系?
- 顺序存储:把逻辑上相邻的元素存储在物理位置上也相邻的存储单元中,元素之间的关系由存储单元的邻接关系来体现。
- 链式存储:逻辑上相邻的元素在物理位置上可以不相邻,借助指示元素存储地址的指针来表示元素之间的逻辑关系。
- 索引存储:在存储元素信息的同时,还建立附加的索引表,索引表中的每项称为索引项,索引项的一般形式是(关键字、地址)。
- 散列存储:根据元素的关键字直接计算出该元素的存储地址,又称为哈希存储。
注意:
- 如果采用顺序存储,则各个数据元素在物理上必须是连续的,若采用非顺序存储,则各个数据元素在物理上是可以离散的。
- 数据的存储结构会影响存储空间分配的方便程度。eg:顺序存储插队不方便。
- 数据的存储结构会影响对数据运算的速度。
2.3 数据的运算
施加在数据上的运算包括运算的定义和实现,运算的定义是针对逻辑结构的,指出预算的功能 ;运算的实现是针对存储结构的,指出运算的具体操作步骤。
2.4数据类型、抽象数据类型
- 数据类型是一个值的集合和定义在此集合上一组操作的总称。
- 原子类型。其值不可再分的数据类型,例如布尔类型,int类型。
- 结构类型,其值可以再分解成若干成分(分量)的数据类型。
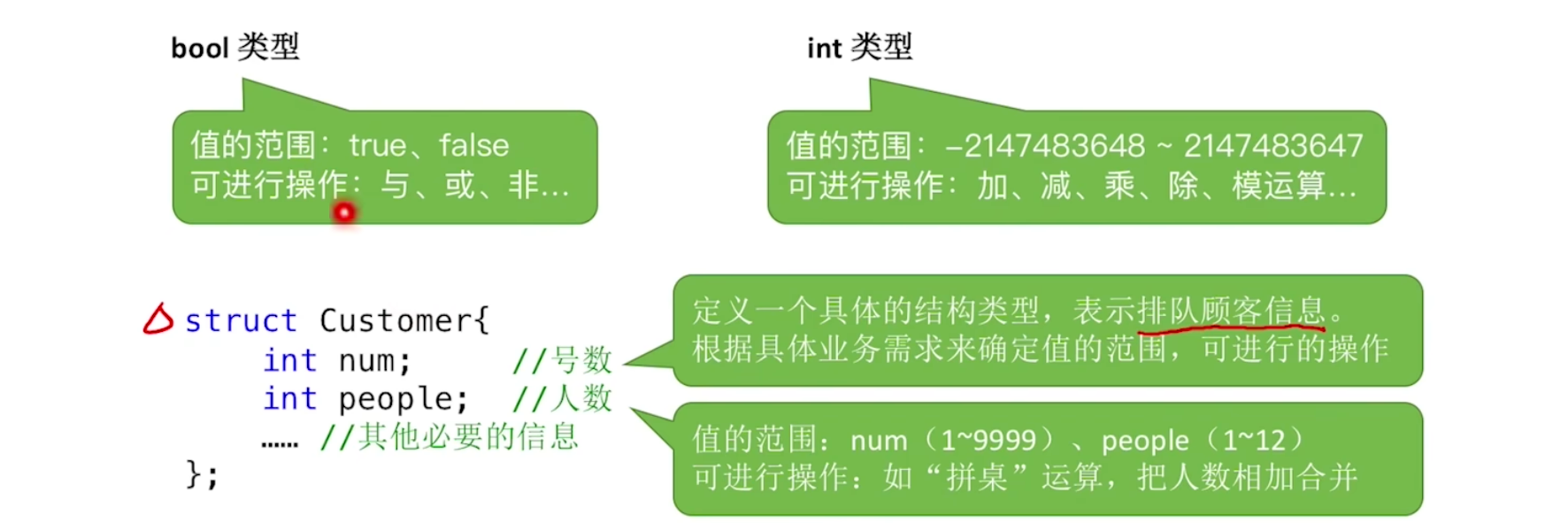
- 抽象数据类型是抽象数据组织及与之相关的操作。
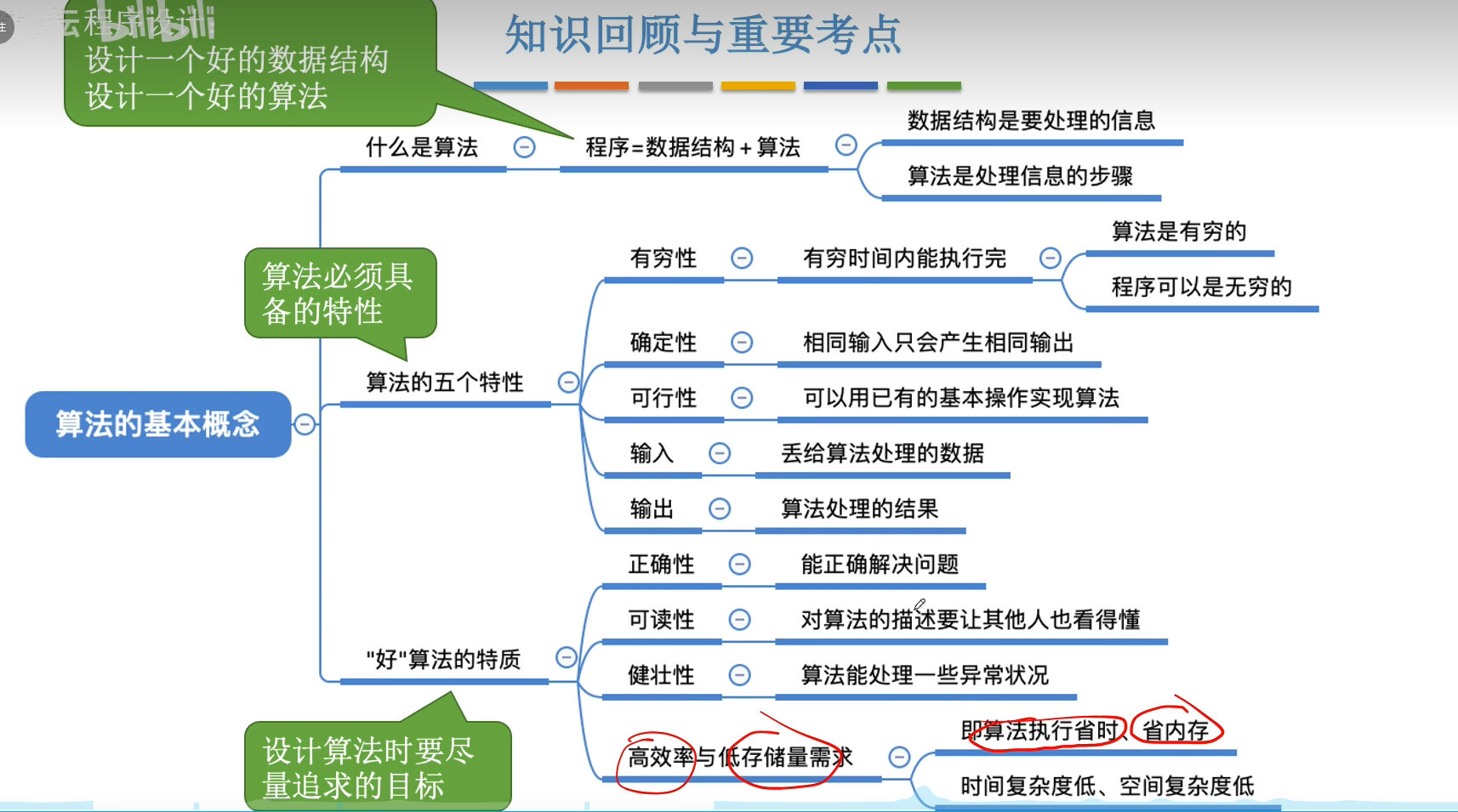
3 算法的基本概念
程序=数据结构+算法
算法:是对特定问题求解步骤的一种描述,它是指令的有限序列,其中每条指令表示一个或多个操作。目的是为了高效的处理这些数据,以解决实际问题。
3.1 算法的特性:
-
有穷性:一个算法必须总在执行有穷步之后结束,且每一步都可在有穷时间内完成,注意算法必须是有穷的,而程序可以是无穷的。
-
确定性:算法中每条指令必须有确切的含义,对于相同的输入只能得到相同的输出。
-
可行性:算法中描述的操作都可以通过已经实现的基本运算执行有限次来实现。
-
输入:一个算法有零个或多个输入,这些输入取自于某个特定对象的集合。
-
输出:一个算法有一个或多个输出,这些输出是与输入有着某种特定关系的量。
3.2 算法效率的度量
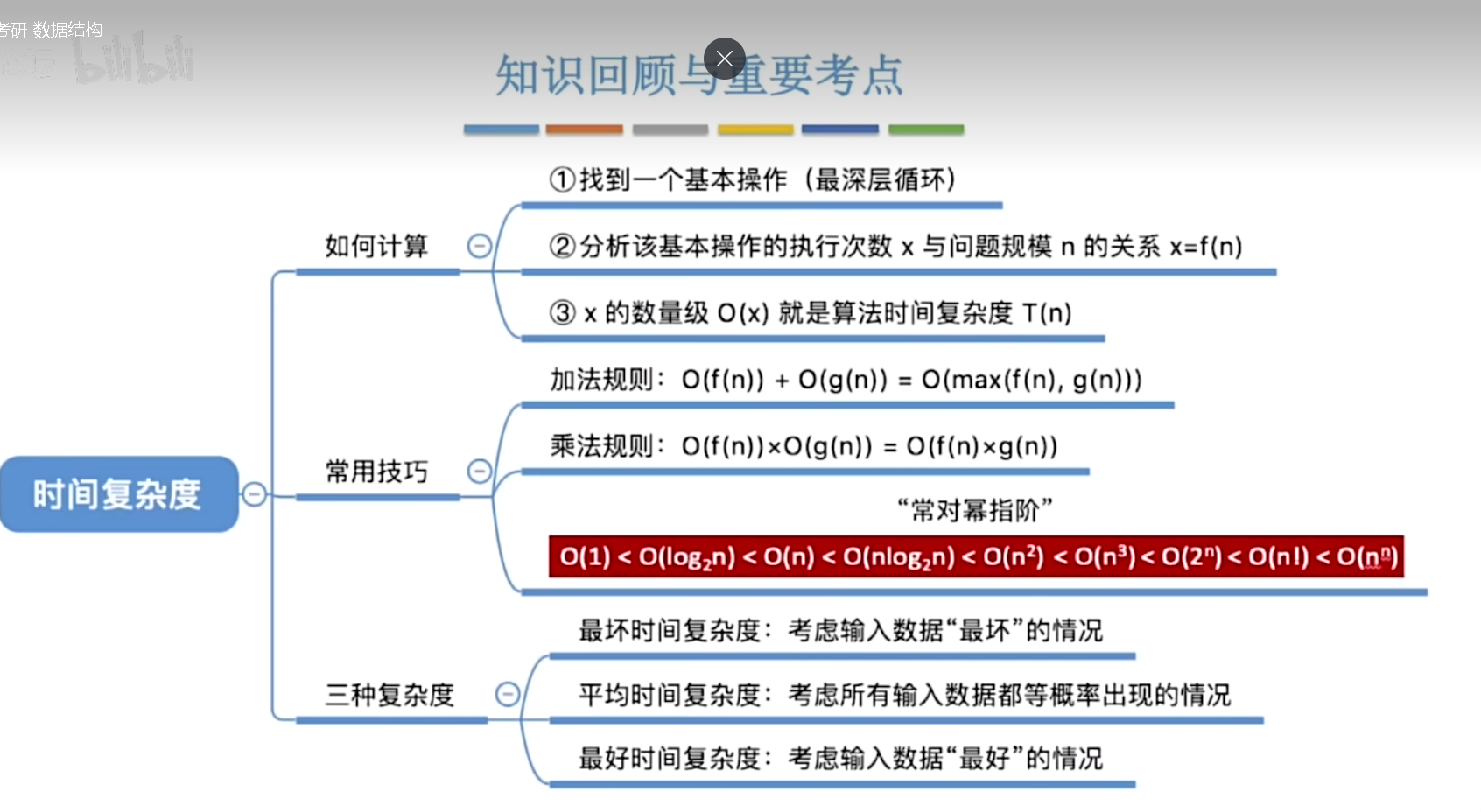
3.2.1 时间复杂度
用于评价一个算法的时间开销等指标:花的时间少,时间复杂度越低
事前预估算法时间开销T(n)和问题规模n的关系(T表示时间time)
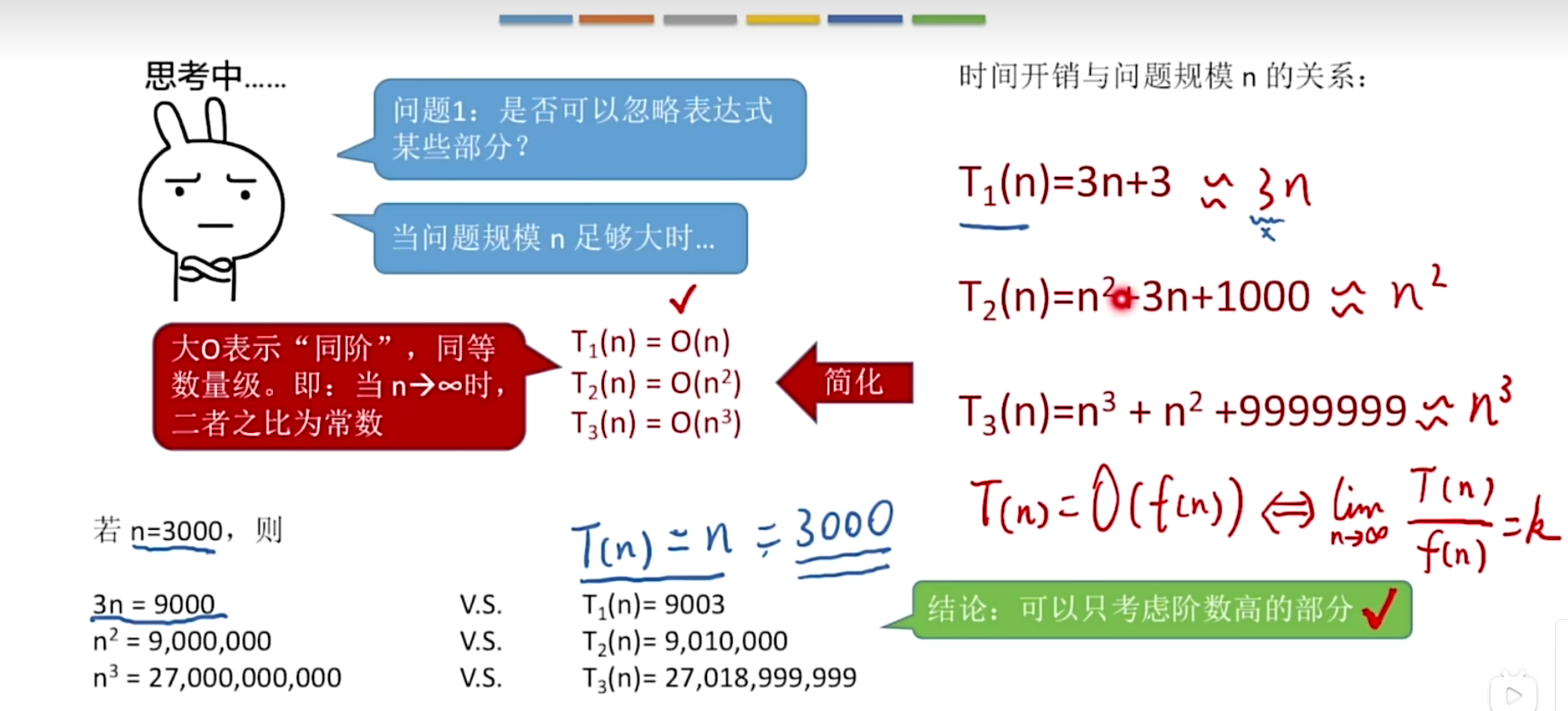
- 当描述一个算法的时间复杂度的时候,一般来说只需要关注它的时间复杂度是什么样的数量级,不看常数和低阶项
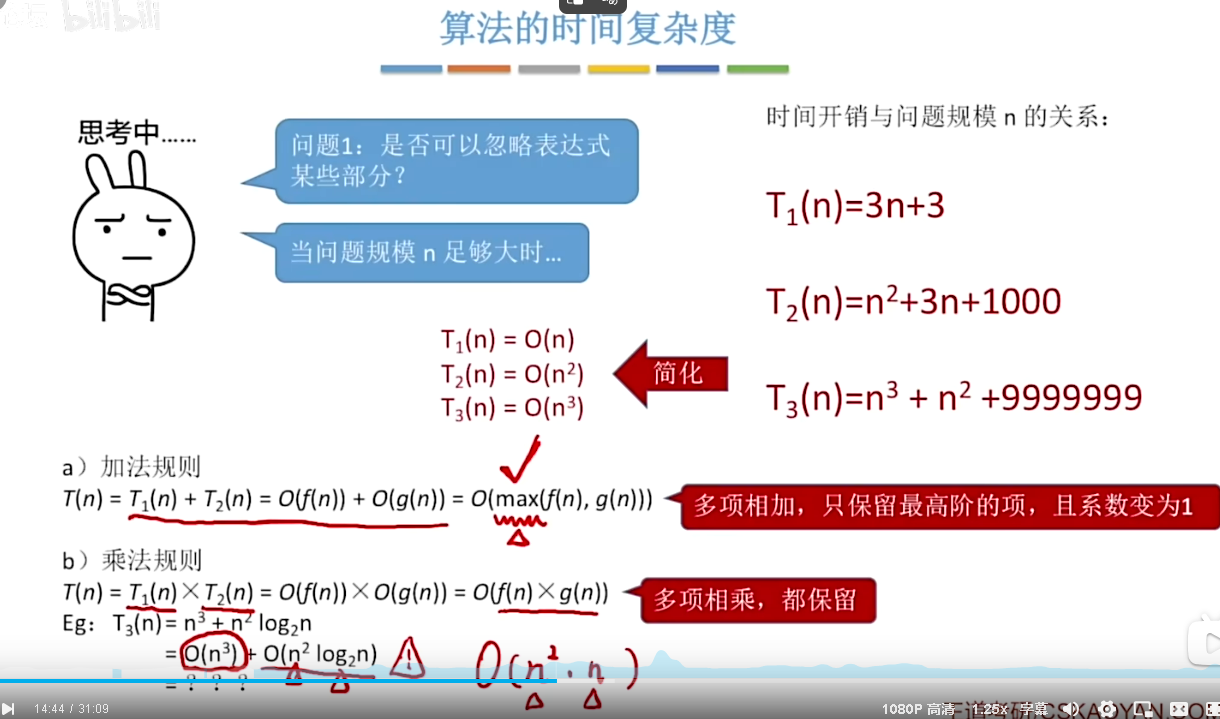
- 加法规则(多项相加)
公式:T(n) = T_1(n)+T_2(n) = O(f(n))+O(g(n)) = O(max(f(n),g(n)))
大白话解释:
如果一个算法分成两段时间去跑,第一段时间复杂度是O(f(n)),第二段是O(g(n)),那总时间复杂度就取增长最快(量级最大)的那个,小的那个可以直接丢掉,系数也忽略。
举个简单例子:
T(n) = 3n + 100log_2n
-
3n的量级是O(n)
-
100log_2n的量级是O(log_2n)
-
因为O(n) > O(log_2n),所以总时间复杂度是O(n)
-
乘法规则(多项相乘)
公式:T(n) = T_1(n)*T_2(n) = O(f(n)) * O(g(n)) = O(f(n) * g(n))
大白话解释:
如果一个算法是嵌套结构(比如外层循环跑f(n)次,内层循环每次跑g(n)次),那总时间复杂度就是两个量级相乘,之后再取最高阶。
举个简单例子:
外层循环O(n)次,内层循环每次O(n)次
总时间复杂度 = O(n) * O(n) = O(n* n) = O(n^2)
- 拆解例题:T_3(n) = n^3 + n^2 log_2 n
第一步:拆分时间开销
这个式子是加法关系,可以拆成两部分:
- 第一部分:n^3 → 时间复杂度O(n^3)
- 第二部分:n^2 log_2 n → 时间复杂度O(n^2 log_2 n)
所以:
T_3(n) = O(n^3) + O(n^2 log_2 n)
第二步:比较两个量级的大小
比较两个量级:n^3 vs n^2 log_2n
因为n > log_2n(当n足够大时),所以n^3 = n*n^2 > n^2 log_2 n,最高阶是n^3。
所以最终:
T_3(n) = O(n^3)
最终结论
- 加法规则:取最大的那个量级,小的直接丢,系数不管
- 乘法规则:两个量级相乘后再取最大
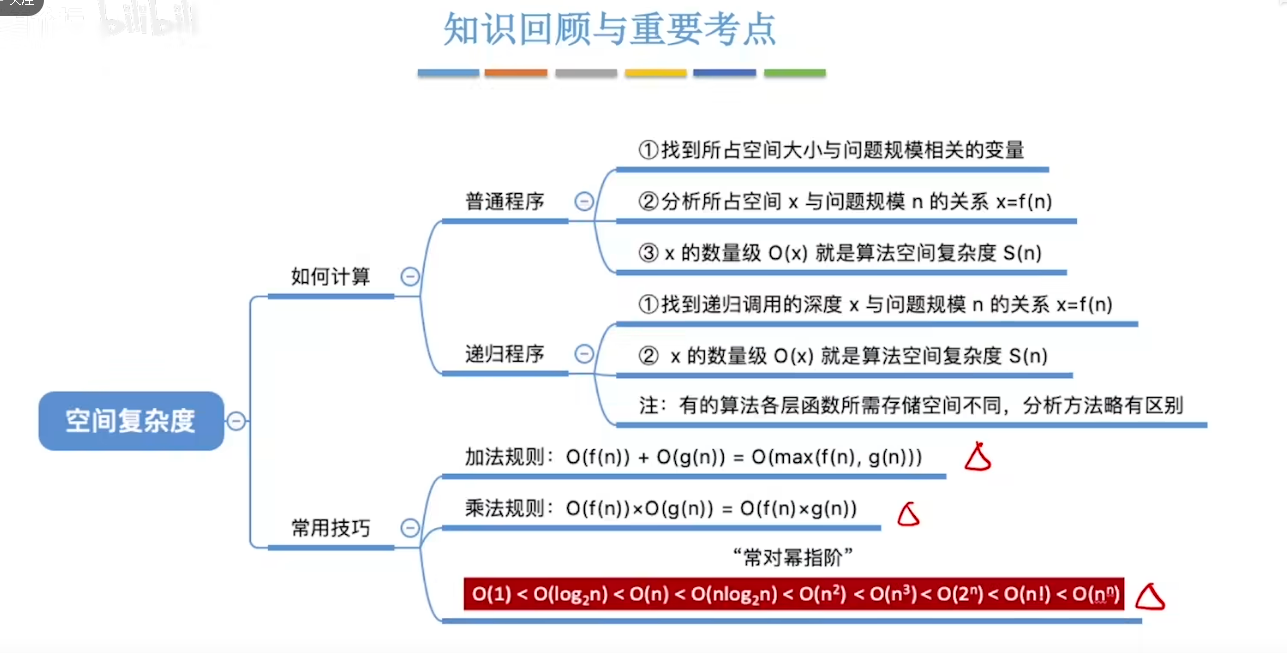
- 时间复杂度的阶数比较,越低花的时间越少,算法越好:
O(1) < O(log_2n) < O(n) < O(nlog_2n) < O(n^2) < O(n^3) < O(2^n) < O(n!) < O(n^n)
示例图: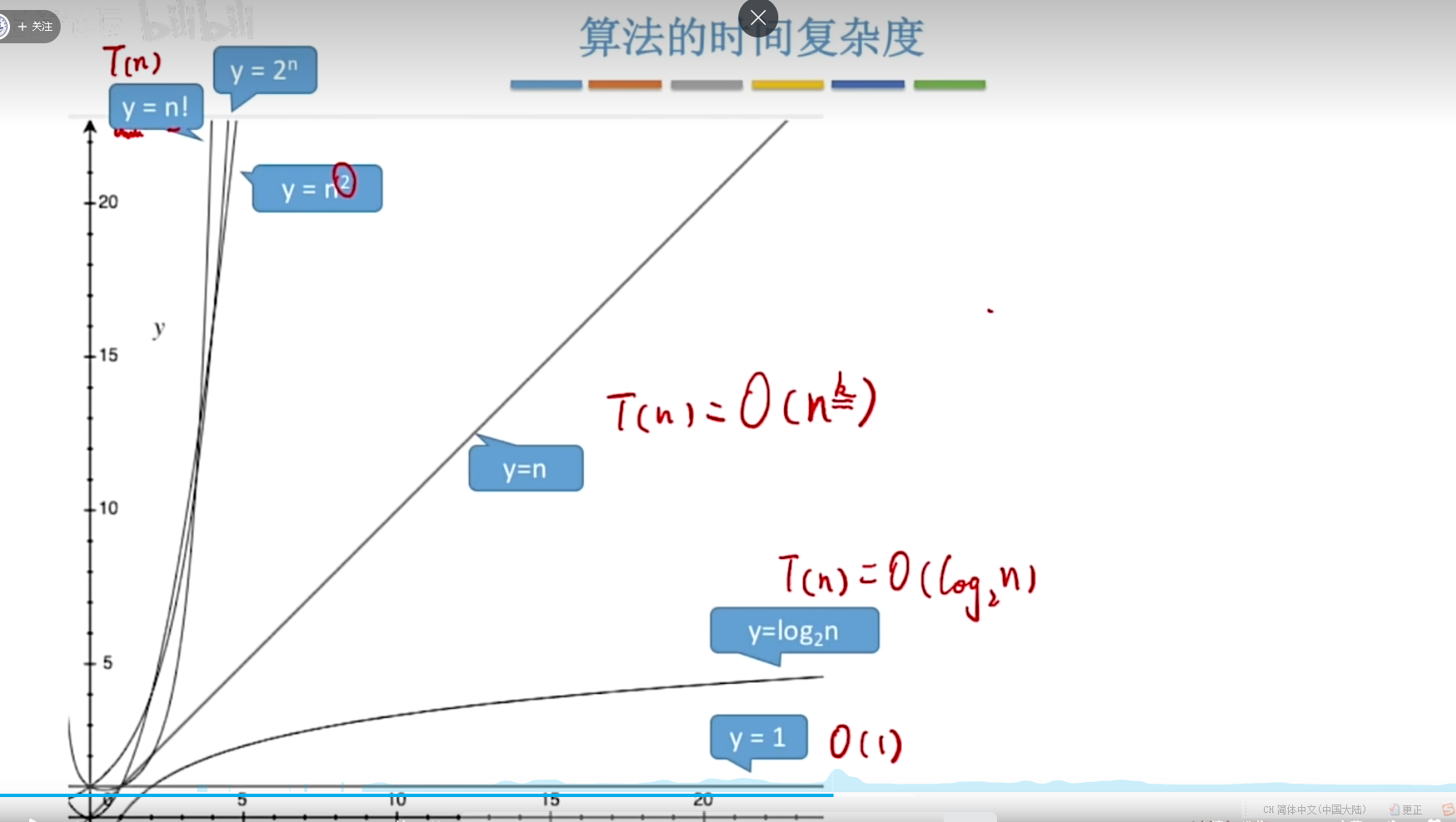
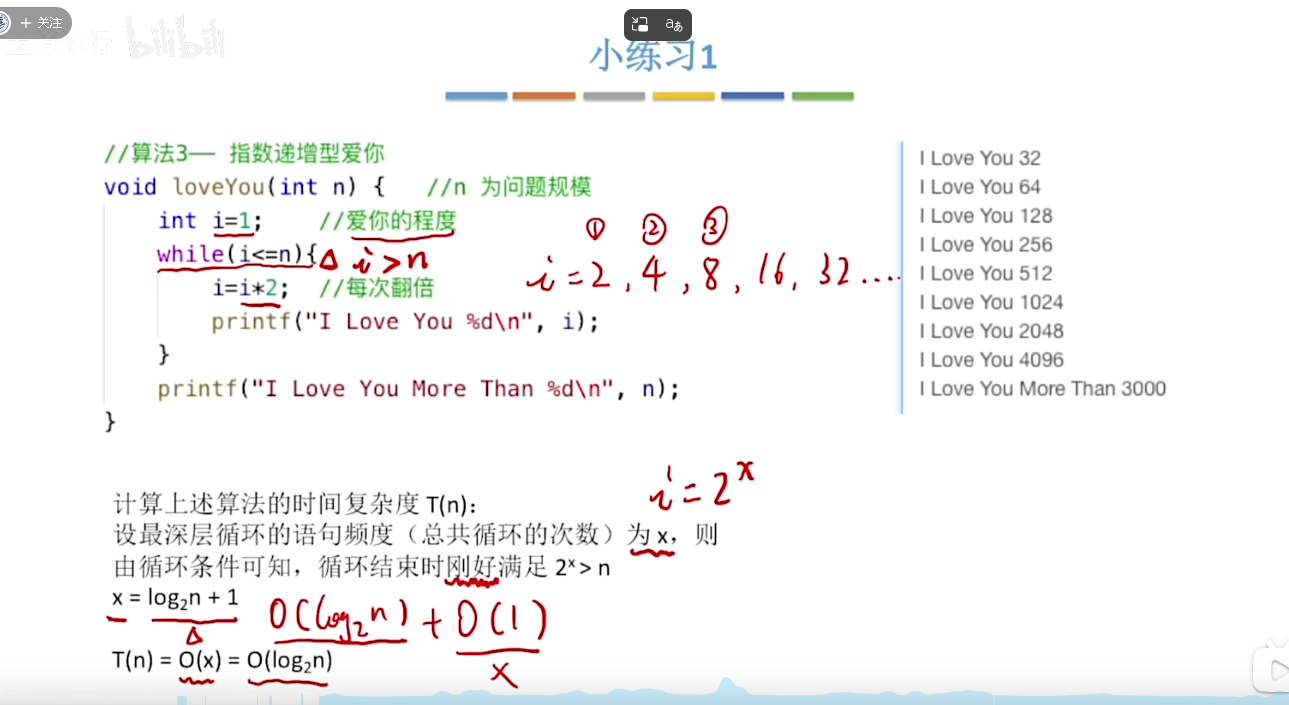
练习1:
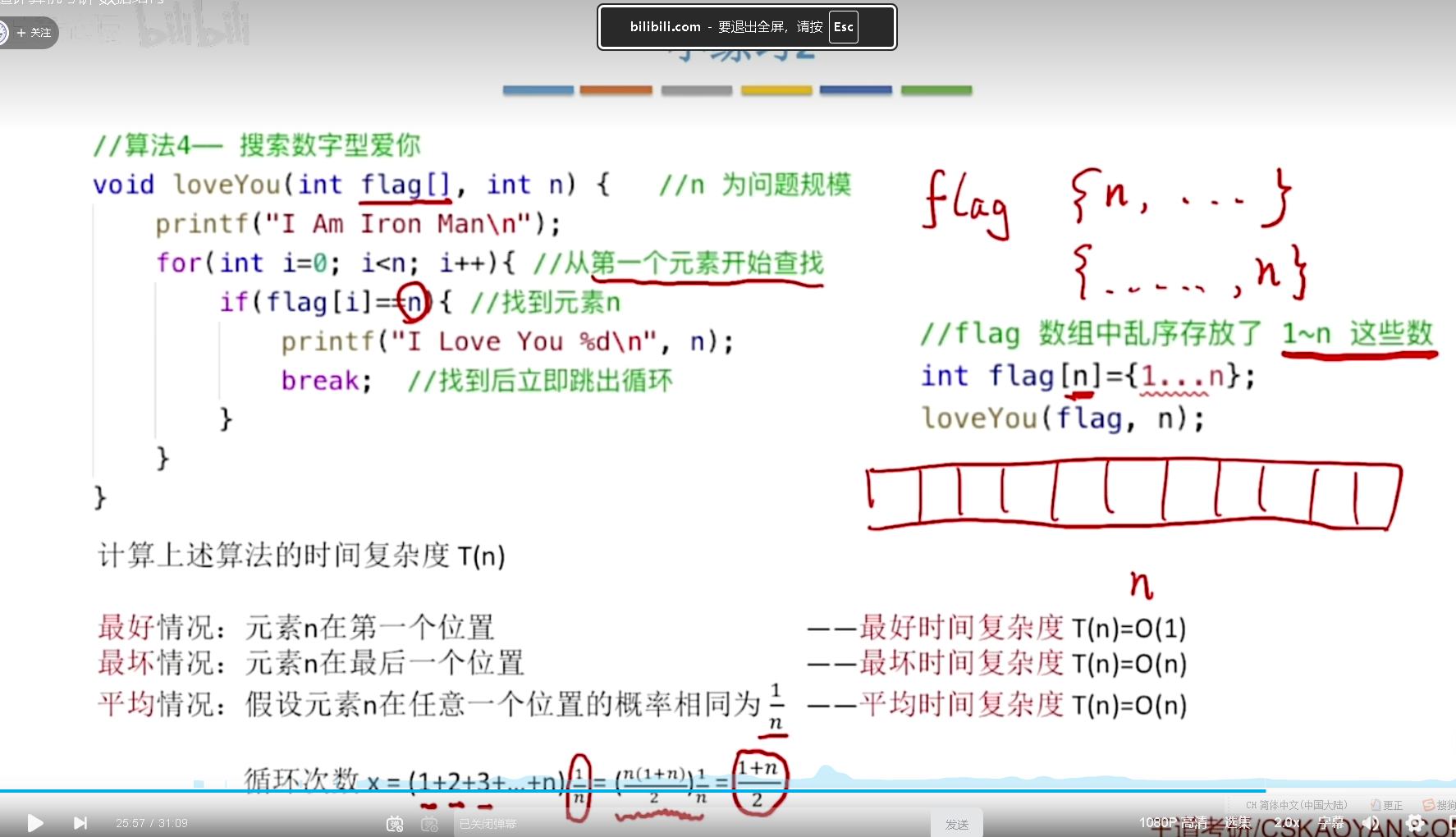
练习二:
总结:
3.2.2 空间复杂度
-
不费内存,空间复杂度越低,主要探讨空间开销(内存开销)与问题规模n之间的关系。
-
导致算法的空间复杂度变化的主要原因是这个算法当中定义的某些变量,存储这些变量需要一些内存空间的开销
-
还有一种情况就是函数调用的时候也会导致内存开销的增加。
-
递归就是函数自己调用自己,将复杂问题拆解为结构相同、规模更小的子问题来求解的技巧。
练习:

函数执行过程
main 函数调用 loveYou(5) ,函数逻辑是:
- 当 n>1 时,先递归调用 loveYou(n-1) ,不会执行打印"I Love You ",而是先暂停,把自己的状态压入栈
- 当 n=1 时,直接打印"I Love You 1"
- loveYou(1)执行结束了,loveYou(2) 从暂停的地方继续往下走,执行 printf ,打印 I Love You 2 。
所以递归调用顺序是:
loveYou(5) → loveYou(4) → loveYou(3) → loveYou(2) → loveYou(1)
到达递归边界 n=1 后,开始回溯执行打印,输出顺序就是 1~5 。
- 由于每一层函数里都声明了一个和问题规模相关的数组,总空间是每一层空间的累加,「带动态空间的递归」:空间复杂度 ≠ 递归深度
- 普通递归每一层函数里没有额外的动态空间开销,只有函数调用栈的开销,空间复杂度就等于递归的深度。
总结: