01
文献学习

今天分享的文献是由复旦大学附属肿瘤医院邵志敏教授、肖毅等团队于2025年2月在《Cell Reports Medicine》(中科院1区top,IF=10.6)上发表的研究"Multimodal integration using a machine learning approach facilitates risk stratification in HR+/HER2- breast cancer"即基于机器学习的多模态整合促进HR+/HER2−乳腺癌的风险分层,该研究构建了一个名为CIMPTGV的多模态机器学习模型,整合了临床、免疫组化、代谢组、病理组、转录组、基因组和拷贝数变异7种数据类型,用于预测HR+/HER2−乳腺癌患者的复发风险。模型在训练集和测试集中均表现出较高的预测效能(C-index ≈ 0.87),并进一步开发了一个简化版模型,平衡了预测性能与临床实用性。
创新点:① 首次系统整合七种模态数据构建CIMPTGV模型,实现HR+/HER2-乳腺癌复发风险的精准预测,C指数达0.87。② 揭示多模态间存在正交互补信息,整合后风险人群覆盖所有单模态识别结果,提升模型解释力与稳健性。③提出简化模型S-CIMPTGV,在保持较高预测效能(平均AUC 0.84)的同时降低数据收集成本,促进临床转化。
临床价值:① 模型能准确区分高、低复发风险患者,指导个体化治疗决策,避免过度治疗或治疗不足。② 提供多维度生物学见解(如HRD评分与风险正相关),有助于揭示复发机制与潜在治疗靶点。③简化模型设计降低了临床应用门槛,有望通过试剂盒等形式推广,提升乳腺癌风险分层普适性。
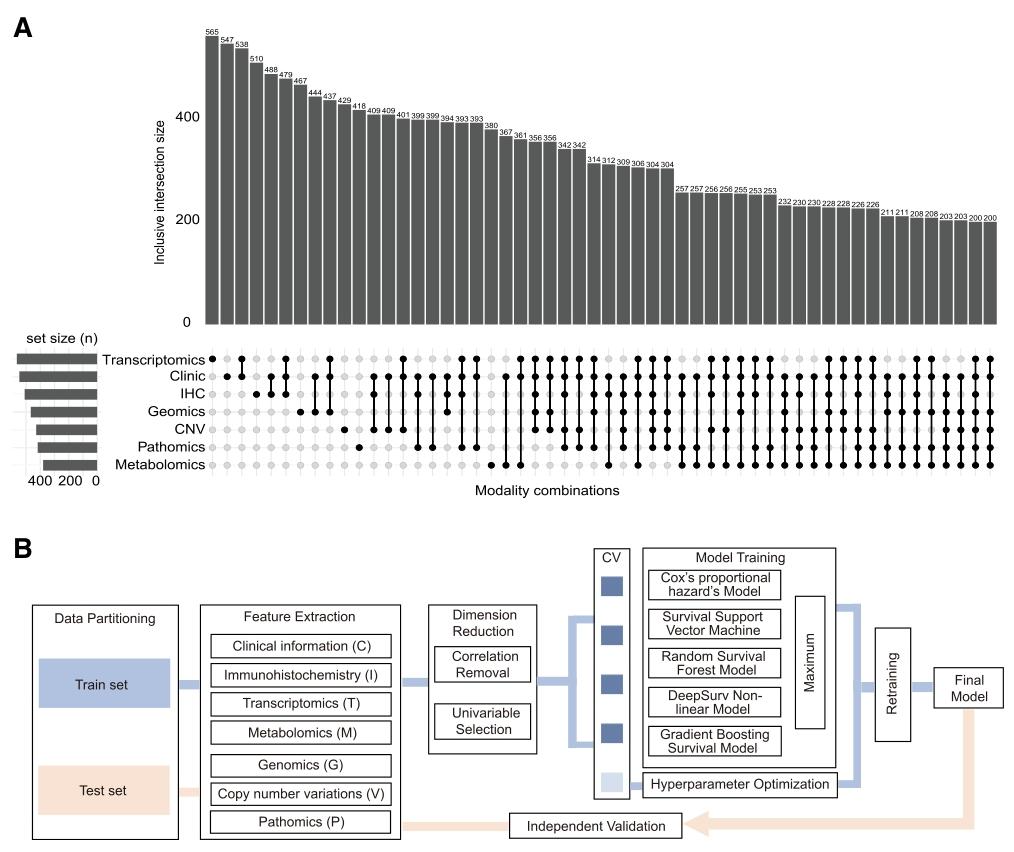
图 1:队列开发与机器学习框架构建
1A:Upset图(模态组合样本量交集图)
1B:机器学习流程图
**数据划分:**按4:1比例进行分层抽样(以"复发状态"为分层因子),分为训练集和测试集,保证两组结局分布一致。
**特征提取:**对7种模态分别提取原始特征(如临床模态6项、IHC模态3项等)。
维度reduction:①去除同一模态内相关性>0.9的冗余特征;②临床/IHC保留全部特征,其他模态筛选单变量Cox风险评分前15的特征;③特征标准化(Z-score)。
**模型训练:**将筛选后的特征矩阵输入5种生存分析模型(Cox比例风险模型、生存支持向量机、随机生存森林、DeepSurv非线性模型、梯度提升生存模型)。
**超参数优化与独立验证:**通过1000步5折交叉验证最大化平均C-index,选择最优模型作为CIMPTGV;在测试集进行独立验证(1000次Bootstrap计算95%置信区间)。
02
研究背景及目的
研究背景
HR阳性/HER2阴性(HR+/HER2-)乳腺癌是最常见的乳腺癌亚型,约占所有病例的65%-70%。尽管内分泌治疗是标准疗法,但肿瘤的持续复发仍是严峻的临床挑战,部分患者因内分泌耐药机制,甚至在治疗5-10年后仍面临高达20%的远期复发风险。因此,精准预测复发风险以指导个体化治疗至关重要 。目前,临床上已有基于基因表达的预测工具(如Oncotype DX和MammaPrint),但它们主要依赖单一的转录组或临床病理数据 ,在预测淋巴结阳性患者复发等方面效能有限(C-index仅为0.56-0.63),难以全面捕捉肿瘤的高度异质性。近年来,随着测序成本降低和人工智能技术的发展,整合多组学数据(包括基因组、转录组、代谢组、病理图像等)的"多模态"研究方法 成为提升预测性能的新方向。然而,由于高质量多模态队列的稀缺、数据整合方法复杂以及临床应用成本高昂,该领域仍处于探索阶段,在乳腺癌中的应用尚未充分开发。本研究正是在此背景下,旨在利用大规模多组学队列和机器学习技术,克服现有模型的局限性。
研究目的
本研究的核心目的是开发并验证一个基于机器学习、整合多维数据的预测模型,以显著提升对HR+/HER2-乳腺癌患者复发风险的预测和分层能力 。具体而言,研究团队旨在利用其建立的包含579名患者的中国人群多组学队列,构建一个名为CIMPTGV的多模态模型 ,该模型将临床信息、免疫组化、转录组学、代谢组学、基因组学、拷贝数变异和病理图像学(病理组学)这七种模态的数据进行系统性整合 。研究希望通过先进的机器学习框架,验证多模态数据融合能否产生协同与互补效应 ,从而在训练集和测试集上获得比现有单模态或传统组合模型(如临床+转录组)更高的预测效能(以C-index衡量) 。此外,为了促进临床转化,本研究还设定了一个关键目标:在保持较高预测性能的前提下,开发一个简化版本的模型(S-CIMPTGV) 。该简化模型通过精选高重要性特征,旨在降低数据收集的复杂性和经济成本,提升其在真实世界临床场景中的可行性与实用性,最终为识别高危患者、制定个性化治疗策略提供有效的决策支持工具。
03
数据和方法
研究数据
队列规模:579例HR+/HER2-单侧浸润性乳腺癌患者(2009-2016年诊断),排除远处转移和预处理患者。
随访数据:547例患者具有完整临床和随访信息,中位随访时间79.1个月(四分位距72.1-93.1个月),结局指标包括无复发生存期(RFS)、总生存期(OS)、无远处转移生存期(DMFS);其中75例病死、150例复发、135例远处转移。
多模态数据覆盖:
临床信息(N=547):年龄、BMI、绝经状态、肿瘤分期等6项特征;
IHC数据(N=510):雌激素受体(ER)、孕激素受体(PR)表达率、Ki-67增殖指数等3项特征;
转录组学(N=565):基因集富集分数、免疫细胞比例等190项特征;
代谢组学(N=380):极性代谢物、脂质等1981项特征;
基因组学(N=467):高频突变基因状态、肿瘤突变负荷(TMB)、同源重组缺陷(HRD)评分等43项特征;
CNV(N=429):Gistic峰值等76项特征;
病理组学(N=418):细胞核形态、拓扑结构等59项特征。
完整多模态数据:200例患者拥有全部7种模态数据,用于模型核心训练。
技术方法
(1)数据处理与划分
分层抽样:按4:1比例划分训练集和测试集,以复发状态为分层因子,保证两组结局分布一致。
特征筛选:①去除同一模态内相关性>0.9的冗余特征;②对临床/IHC保留全部特征,其他模态筛选单变量Cox风险评分前15的特征;③特征标准化(Z-score)。
(2)模型构建与优化
模型框架:输入5种生存分析模型(Cox比例风险模型、生存支持向量机、随机生存森林、DeepSurv非线性模型、梯度提升生存模型)。
超参数优化:通过1000步5折交叉验证,最大化平均交叉验证C-index,选择最优模型作为CIMPTGV。
(3)模型验证
内部验证:100次随机划分训练集/测试集,评估模型稳定性;Bootstrap 1000次计算C-index的95%置信区间。
对比验证:与传统组合模型(CIT、CT、CI)及商业检测(Oncotype DX、MammaPrint)对比预测效能。
亚组分析:在不同肿瘤分期、临床特征(如绝经状态)、IHC表型亚组中验证模型分层能力。
(4)简化模型构建
特征选择:纳入易获取的临床、IHC、病理组学全特征,及其他模态高重要性特征(如代谢组学的2-0-乙酰基岩藻糖、转录组学的VEGF信号通路特征)。
效能验证:评估简化模型(S-CIMPTGV)的时间依赖AUC和生存分层能力。
04
实验结果
(1)模型预测效能优异
- CIMPTGV模型:训练集C-index=0.871,测试集C-index=0.869,显著高于单一模态模型(C-index 0.6-0.75)和传统组合模型(如 CIT模型C-index 0.72)。
- 优于商业检测:在重叠队列中,CIMPTGV的C-index(0.812 vs MammaPrint 的 0.688;0.866 vs Oncotype DX的 0.568)。
- 分层能力强:高/低危组的RFS、OS、DMFS 差异显著(log-rank test p<0.001),能识别74.2%的复发患者,低危组复发率仅14.2%。
(2)模型稳定性良好
- 100次随机划分后,训练集和测试集C-index均波动在0.8-0.9,差异<0.05,无随机误差影响。
- 超参数优化后(最优估计量数量=10),模型无过拟合(增加估计量未提升测试集效能)。
(3)多模态存在协同互补效应
单一模态模型预测分数的Pearson相关系数绝对值≤0.3,提示模态间存在正交信息。
CIMPTGV的高风险人群涵盖所有单一模态模型识别的高风险人群,且复发比例更高。
(4)高风险组特征明确
- 临床特征:肿瘤分期高(pT3/pN3)、Ki-67增殖指数高;
- 分子特征:核酸代谢物(假尿苷、N4-乙酰胞苷)富集、MYC靶通路高表达、脂肪酸代谢通路低表达;
- 病理特征:肿瘤细胞聚集度高、形态异质性(MITH)高;
- 基因组特征:HRD 评分高,11q13.3区域扩增(含 FGF3、FGF4、CTTN 等癌基因)。
(5)简化模型实用高效
- S-CIMPTGV平均AUC=0.840,虽略低于完整版(0.886),但显著优于临床常用模态组合;
- 能有效分层高/低危患者(log-rank test p<0.001),数据收集成本降低60%以上。
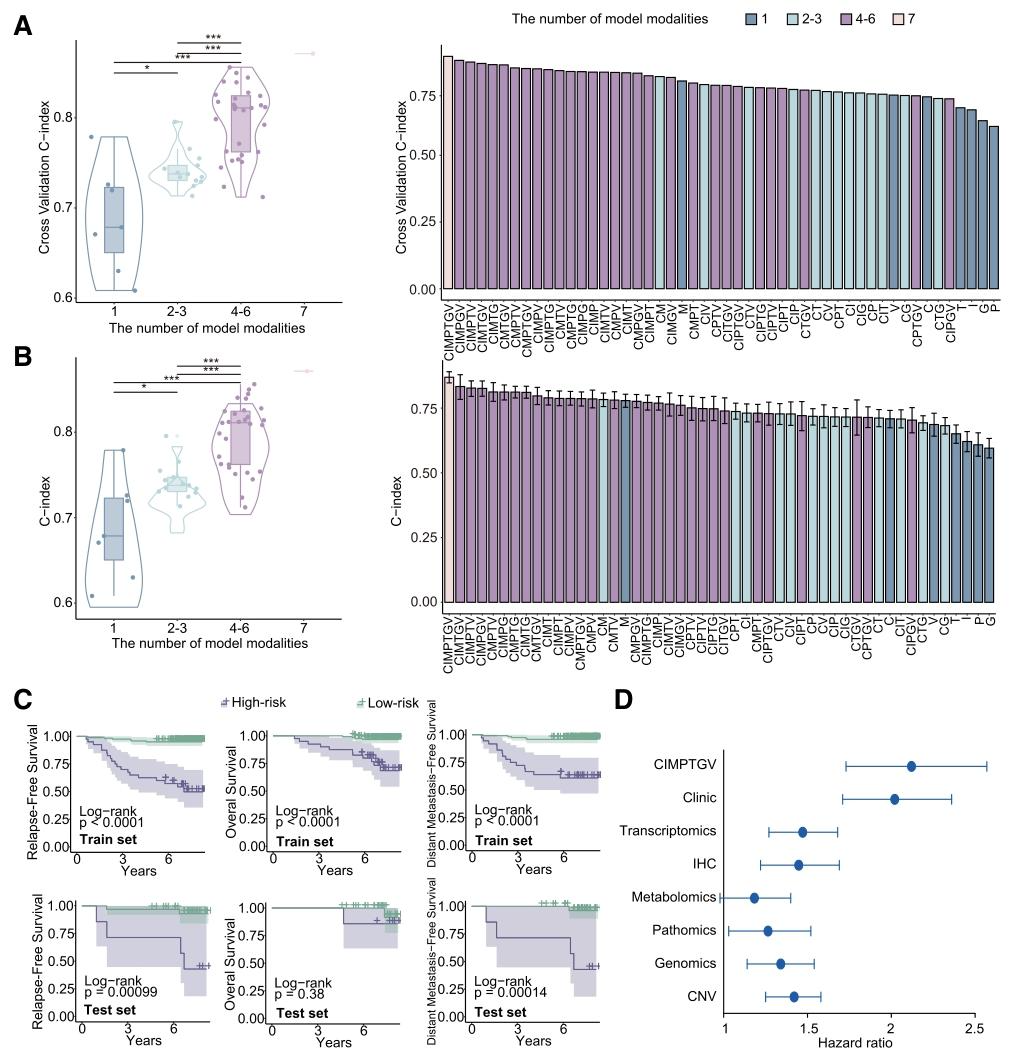
图 2:多模态整合提升预测效能与风险分层
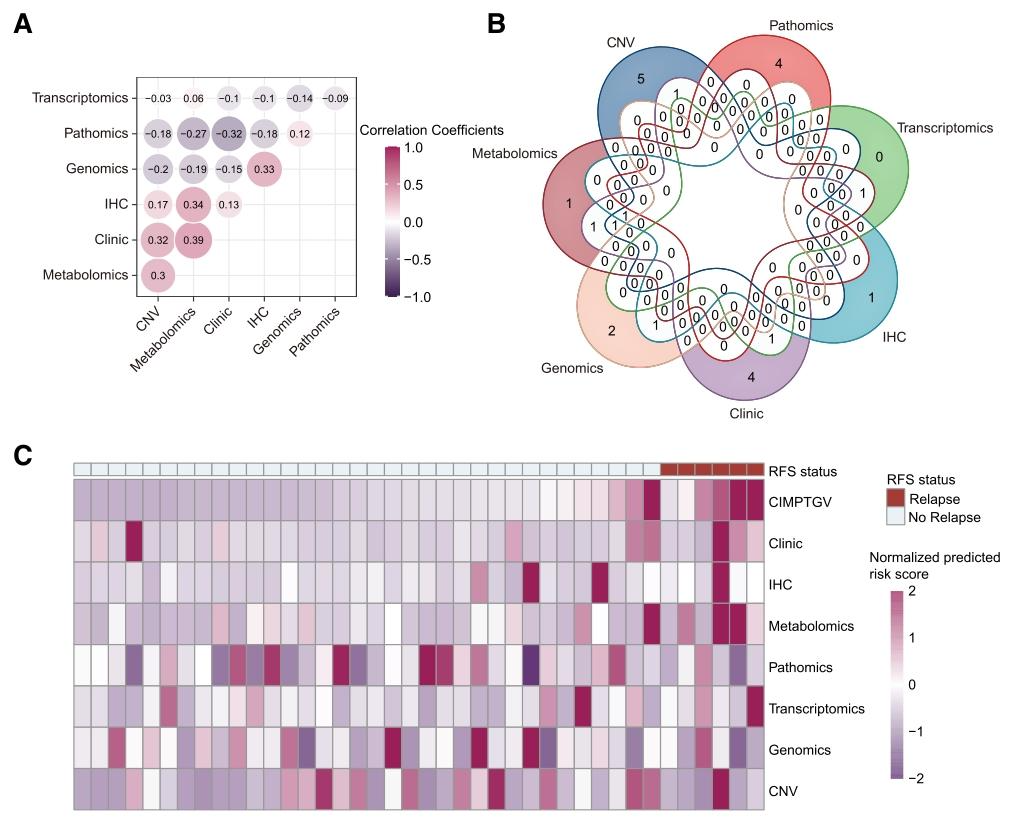
图 3:多模态中的正交数据提升预测效能
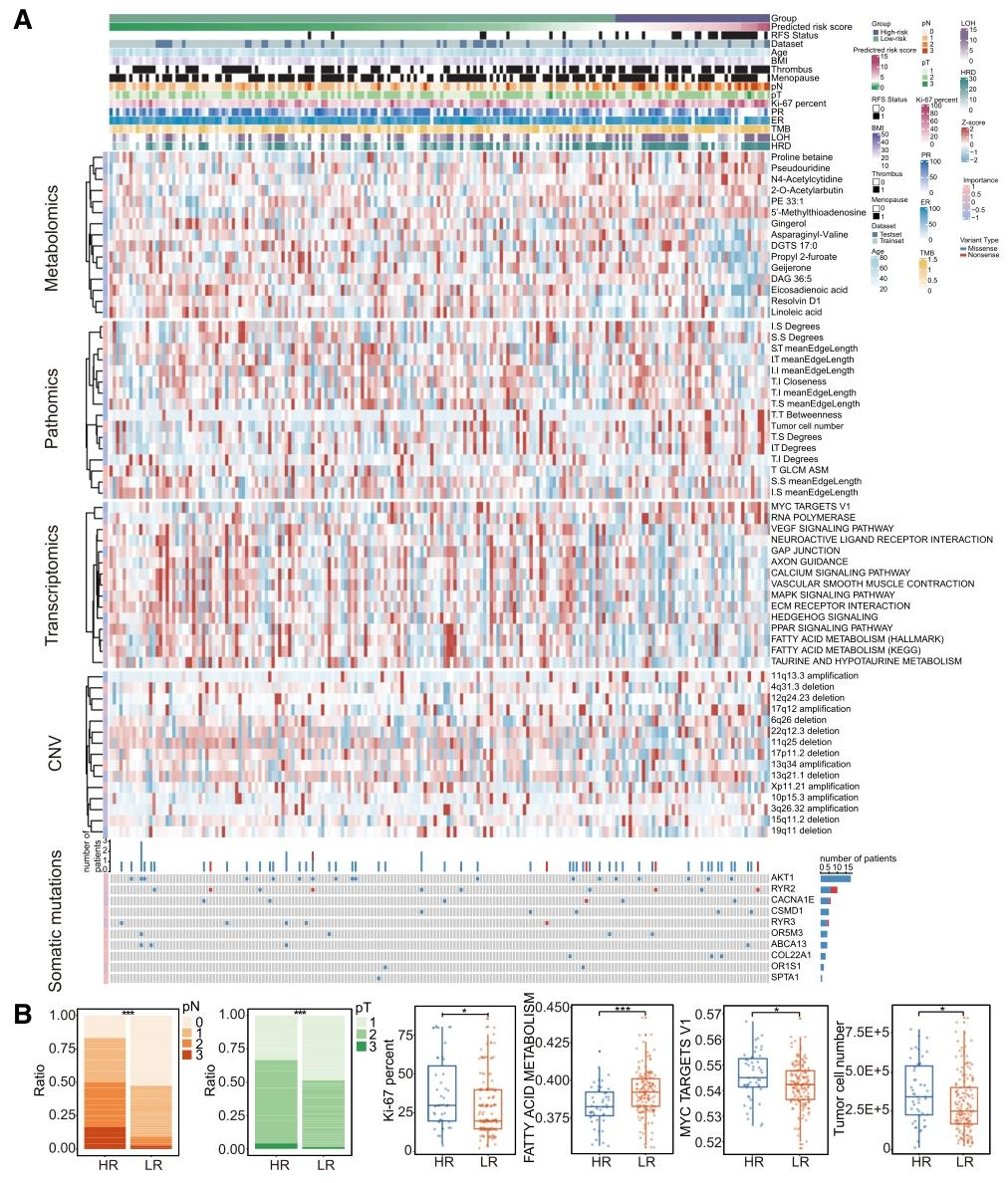
图 4:CIMPTGV模型的模态特征表现
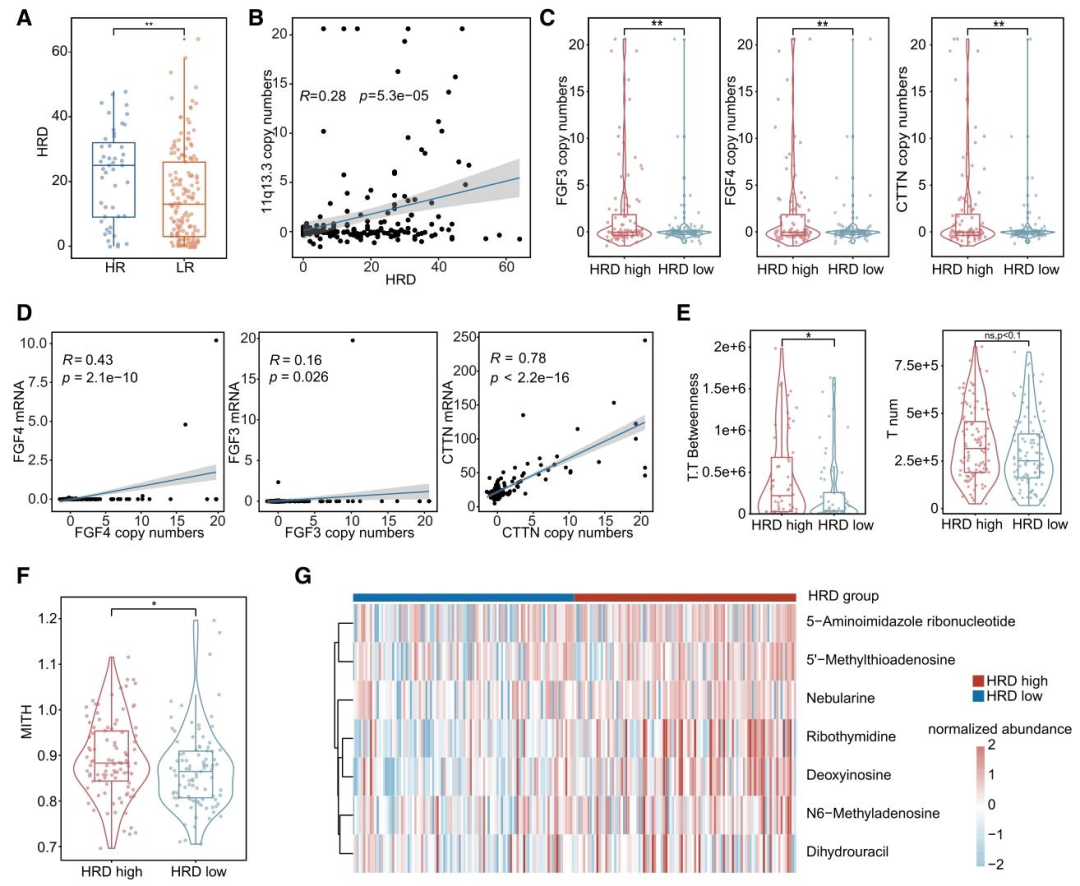
图 5:模态相关性支持互补信息存在
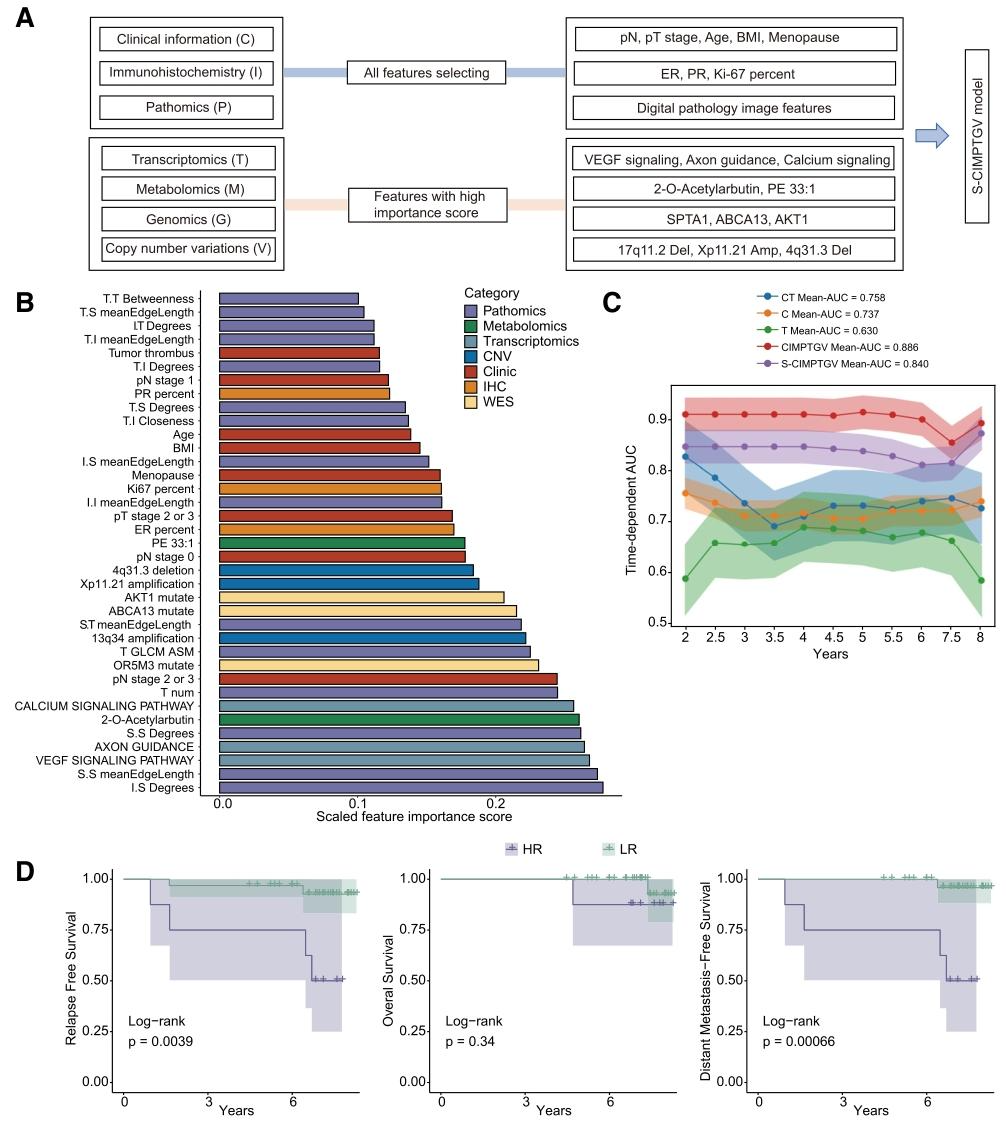
图 6:简化模型(S-CIMPTGV)构建
05
研究结论
本研究通过整合临床、免疫组化、代谢组、病理组、转录组、基因组和拷贝数变异共七种模态数据 ,构建了机器学习模型CIMPTGV,用于预测HR+/HER2-乳腺癌患者的复发风险。该模型在训练集和测试集中分别达到C-index为0.871和0.869 ,显著优于单模态模型及临床常用组合模型,并能够有效区分高风险与低风险患者群体。研究进一步揭示了不同模态数据间存在协同与互补效应 ,整合多源信息可全面捕捉肿瘤生物学特征,提升预测性能。此外,同源重组缺陷评分与模型风险评分呈显著正相关 ,从基因组不稳定角度提供了生物学解释。为推动临床转化,研究团队还开发了简化版模型 ,在保持较高预测效能(平均AUC=0.840)的同时降低了数据收集成本,提升了实用性与可推广性。该研究证明了多模态机器学习在乳腺癌风险分层中的重要作用,为个体化治疗决策提供了有力工具。
参考文献:Zhang H, Yang F, Xu Y, Zhao S, Jiang YZ, Shao ZM, Xiao Y. Multimodal integration using a machine learning approach facilitates risk stratification in HR+/HER2- breast cancer. Cell Rep Med. 2025 Feb 18;6(2):101924. doi: 10.1016/j.xcrm.2024.101924.