论文:Transformer Attractors for Robust and Efficient End-to-End Neural Diarization
简称:EEND-TA
作者:Lahiru Samarakoon, Samuel J. Broughton, Marc Harkonen, Ivan Fung
时间:ASRU2023
任务:Speaker Diarization,回答"谁在什么时候说话"
前言
EEND、SA-EEND、EEND-EDA 这条技术线一直在解决
- 怎样把 diarization 做成一个真正的端到端模型
- 怎样在重叠说话场景下仍然保持较好的建模能力
- 怎样让模型既准,又不要太慢
EEND-EDA 已经把"可变说话人数"这件事往前推了一大步,但它的 attractor 生成器本质上还是 LSTM encoder-decoder。这就带来两个问题:
- 它对输入顺序敏感,甚至需要对 frame-wise embeddings 做 shuffle
- 它是串行生成 attractor 的,推理效率不高
这篇 EEND-TA 把 EEND-EDA 里基于 LSTM 的 attractor 生成模块,换成基于 Transformer 的 attractor 生成模块。
目的是 更自然地从整段对话中抽取 speaker attractor,并且让这个过程既利用全局上下文,又能并行计算。
一、EEND-EDA 的局限
1.1 本质上是顺序模型
LSTM 天生是按顺序读入信息的,所以它对输入顺序敏感。论文也明确提到,EEND-EDA 在实践中通常要把 frame-wise embeddings 在时间维上打乱后再送进 EDA。
1.2 把整段对话压缩得过于激进
LSTM decoder 主要依赖 encoder 最后的 hidden state / cell state 去概括整段对话。这个"压缩后的记忆"未必足够完整,尤其是说话人变多、录音变长时,更容易漏掉前面出现过的人。
1.3 它推理是串行的
LSTM 要一步一步生成 attractor,不能天然并行。speaker 数越多,解码越慢。在长录音、多人场景下,效率较差。
二、EEND-TA
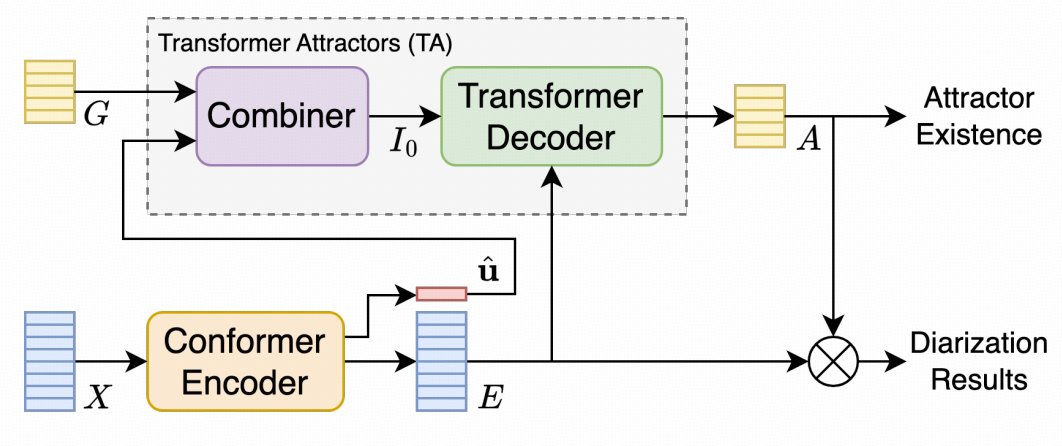
图1 EEND-TA 流程图
2.1 总体结构
作者想用 attention 机制来替换 LSTM 生成 attractor,因为
- attractor 不是语言序列,不一定天然有强顺序性
- 生成 attractor 时,更重要的是"看见整段对话里所有 frame-wise embeddings"
- 如果能直接对整段 embedding 做全局建模,就没必要先把它们压缩进一个 LSTM state 再慢慢解码
如图 1 所示,EEND-TA 的流程可以写成:
text
输入特征 X
-> Conformer Encoder
-> 得到 frame-wise embeddings E 和一个 CSV
-> Combiner 把 CSV 注入全局可学习 speaker queries
-> Transformer Decoder 与 E 做 cross-attention
-> 输出 attractors A 和 existence probabilities q
-> 用 attractor 与 frame embeddings 做匹配,得到逐帧说话概率2.2 u ^ \hat{\mathbf{u}} u^、 G \mathbf{G} G、 I 0 \mathbf{I}_0 I0
Conformer encoder 可以看这里 .
如果没读过 CSV-EEND-EDA,不容易理解这 3 个变量:
X → e n c ( u ^ , E ) , I 0 = ϕ ( u ^ , G ) , ( I 0 , E ) → T A A \mathbf{X} \xrightarrow{\mathrm{enc}} (\hat{\mathbf{u}}, \mathbf{E}), \quad \mathbf{I}_0 = \phi(\hat{\mathbf{u}}, \mathbf{G}), \quad (\mathbf{I}_0, \mathbf{E}) \xrightarrow{\mathrm{TA}} \mathbf{A} Xenc (u^,E),I0=ϕ(u^,G),(I0,E)TA A
即
- 输入语音特征 X \mathbf{X} X
- 编码器输出逐帧 embedding E \mathbf{E} E 和一个全局摘要 u ^ \hat{\mathbf{u}} u^
- 再把全局摘要 u ^ \hat{\mathbf{u}} u^ 注入一组可学习全局 query G \mathbf{G} G
- 得到 decoder 的初始输入 I 0 \mathbf{I}_0 I0
- 最后 Transformer decoder 结合 I 0 \mathbf{I}_0 I0 和 E \mathbf{E} E,输出 attractors A \mathbf{A} A
所以这 3 个变量分别是:
- u ^ \hat{\mathbf{u}} u^:当前这段录音的全局摘要
- G \mathbf{G} G:模型共享的一组全局 speaker-query 原型
- I 0 \mathbf{I}_0 I0:把当前录音信息注入 query 原型后得到的、面向当前录音的初始 speaker queries
如果类比成"检索"过程:
- E \mathbf{E} E 是整段录音的 memory
- u ^ \hat{\mathbf{u}} u^ 是这段录音的摘要卡片
- G \mathbf{G} G 是几张空白查询卡
- I 0 \mathbf{I}_0 I0 是写上了当前录音提示信息的查询卡
2.3 u ^ \hat{\mathbf{u}} u^ 是怎么生成的?
论文沿用了 CSV-EEND-EDA 的思路。编码器不只输出逐帧 embedding E \mathbf{E} E,还额外输出一个全局对话摘要向量 u ^ \hat{\mathbf{u}} u^:
u ^ , E = e n c ( X ) \hat{\mathbf{u}}, \mathbf{E} = \mathrm{enc}(\mathbf{X}) u^,E=enc(X)
其中:
- E ∈ R D × T \mathbf{E} \in \mathbb{R}^{D \times T} E∈RD×T 是逐帧 speaker embeddings
- u ^ ∈ R D × 1 \hat{\mathbf{u}} \in \mathbb{R}^{D \times 1} u^∈RD×1 是整段对话的 summary
论文在输入序列最前面,额外拼接了一个 可学习的 special token。于是输入不再只是普通的帧特征,而是:
X ~ = u 0 , x 1 , x 2 , ... , x T \tilde{\mathbf{X}} = \\mathbf{u}_0, \\mathbf{x}_1, \\mathbf{x}_2, \\ldots, \\mathbf{x}_T X~=u0,x1,x2,...,xT
其中:
- x t \mathbf{x}_t xt 是第 t t t 帧的声学特征
- u 0 \mathbf{u}_0 u0 是一个可学习的 summary token
经过修改后的 Conformer 之后,可以把输出理解成:
u \^ , e 1 , e 2 , ... , e T = C o n f o r m e r ( X ~ ) \\hat{\\mathbf{u}}, \\mathbf{e}_1, \\mathbf{e}_2, \\ldots, \\mathbf{e}_T = \mathrm{Conformer}(\tilde{\mathbf{X}}) u\^,e1,e2,...,eT=Conformer(X~)
于是:
E = e 1 , ... , e T \mathbf{E} = \\mathbf{e}_1, \\ldots, \\mathbf{e}_T E=e1,...,eT
- 第一个位置的输出是全局摘要 u ^ \hat{\mathbf{u}} u^
- 后面各位置的输出仍然是逐帧 embedding
这和 BERT 里的 [CLS]、Vision Transformer 里的 class token 很像。区别只是这里的对象不是文本 token,而是语音帧。在 self-attention 里,这个 token 会和整段语音的所有帧交互。它最后学到的就不再是某一帧的局部信息,而是整段录音在 speaker、对话结构、交互模式上的全局概括。
需要注意的是CSV token 会绕过 Conformer 的 convolution module。 因为 convolution 更偏向局部模式建模,而 CSV token 的目标是保留全局摘要能力。让它跳过卷积模块,本质上是在避免它被当成"普通局部帧"去处理。
2.4 G \mathbf{G} G
Transformer decoder 不能像 LSTM decoder 那样每一步都输入一个零向量慢慢往后解码。它需要一组初始 query。于是论文引入一组可学习的全局 embedding:
G ∈ R D × ( S + 1 ) \mathbf{G} \in \mathbb{R}^{D \times (S+1)} G∈RD×(S+1)
论文中的描述是a learnable global set of embeddings 。它是模型参数的一部分,是一组全局共享、通过训练学出来的 query 原型。 它是一组 speaker-slot queries,或者说一组 attractor 查询模板。这个概念很像目标检测里的 object queries,它们不是某个具体目标本身,而是"拿去当前样本里找目标"的查询槽位。
所以 G \mathbf{G} G 的每一列可以理解成一个待实例化的 speaker query 原型。
2.5 I 0 \mathbf{I}_0 I0
I 0 \mathbf{I}_0 I0 是 Transformer decoder 第一层的输入 queries。它不是独立定义出来的,而是用 combiner 把 u ^ \hat{\mathbf{u}} u^ 和 G \mathbf{G} G 结合后得到的:
I 0 = ϕ ( u ^ , G ) \mathbf{I}_0 = \phi(\hat{\mathbf{u}}, \mathbf{G}) I0=ϕ(u^,G)
可以理解为
- G \mathbf{G} G 本来只是全局共享的"通用 query 模板"
- 但当前录音到底是双人对话、多人会议,还是更复杂的交互,仅靠 G \mathbf{G} G 本身不知道
- 所以要把当前录音的全局摘要 u ^ \hat{\mathbf{u}} u^ 注入 G \mathbf{G} G
- 这样才能得到面向当前录音的初始 queries,也就是 I 0 \mathbf{I}_0 I0
因此, I 0 \mathbf{I}_0 I0 可以理解为带有当前对话条件信息的 speaker 查询向量。
论文尝试了三种 combiner。
2.5.1 加法型
ϕ a d d ( u ^ , G ) = u ^ + G \phi_{\mathrm{add}}(\hat{\mathbf{u}}, \mathbf{G}) = \hat{\mathbf{u}} + \mathbf{G} ϕadd(u^,G)=u^+G
把同一个全局摘要加到每个 query 上。
2.5.2 逐元素乘法型
ϕ m u l t ( u ^ , G ) = u ^ ∗ G \phi_{\mathrm{mult}}(\hat{\mathbf{u}}, \mathbf{G}) = \hat{\mathbf{u}} * \mathbf{G} ϕmult(u^,G)=u^∗G
用 u ^ \hat{\mathbf{u}} u^ 的各维度去缩放 query。
2.5.3 门控放大型
ϕ a m p ( u ^ , G ) = α ⋅ σ ( u ^ ) ∗ G \phi_{\mathrm{amp}}(\hat{\mathbf{u}}, \mathbf{G}) = \alpha \cdot \sigma(\hat{\mathbf{u}}) * \mathbf{G} ϕamp(u^,G)=α⋅σ(u^)∗G
可以理解为:
- σ ( u ^ ) \sigma(\hat{\mathbf{u}}) σ(u^) 先把 CSV 变成门控系数
- 再对 G \mathbf{G} G 的各维度做选择性放大或抑制
让当前对话的全局信息去调制 speaker queries。
实验结果显示这种做法最好。
2.6 Transformer decoder
有了 I 0 \mathbf{I}_0 I0 之后,后面就是标准 Transformer decoder 的思路。
第 i i i 层 decoder block 的计算为:
Z = L N ( M H A ( I i , I i , I i ) + I i ) \mathbf{Z} = \mathrm{LN}(\mathrm{MHA}(\mathbf{I}_i, \mathbf{I}_i, \mathbf{I}_i) + \mathbf{I}_i) Z=LN(MHA(Ii,Ii,Ii)+Ii)
Z ′ = L N ( M H A ( Z , E , E ) + Z ) \mathbf{Z}' = \mathrm{LN}(\mathrm{MHA}(\mathbf{Z}, \mathbf{E}, \mathbf{E}) + \mathbf{Z}) Z′=LN(MHA(Z,E,E)+Z)
I i + 1 = L N ( F F ( Z ′ ) + Z ′ ) \mathbf{I}_{i+1} = \mathrm{LN}(\mathrm{FF}(\mathbf{Z}') + \mathbf{Z}') Ii+1=LN(FF(Z′)+Z′)
- self-attention:先让不同 speaker queries 之间彼此协调,避免它们学成完全重复的槽位
- cross-attention:再让每个 query 去整段 frame-wise embeddings E \mathbf{E} E 里检索与自己最匹配的 speaker 模式
- FFN:做进一步的非线性变换,得到更稳定的 attractor 表示
最后,decoder 输出一组 attractors:
A = a 1 , ... , a S + 1 \mathbf{A} = \\mathbf{a}_1,\\ldots,\\mathbf{a}_{S+1} A=a1,...,aS+1
以及对应的 existence probabilities:
q s = σ ( F F ( a s ) ) q_s = \sigma(\mathrm{FF}(\mathbf{a}_s)) qs=σ(FF(as))
然后再用 attractor 和逐帧 embedding 做匹配,得到第 t t t 帧属于第 s s s 个 speaker 的后验概率:
p t , s = σ ( a s ⊤ e t ) p_{t,s} = \sigma(\mathbf{a}_s^{\top}\mathbf{e}_t) pt,s=σ(as⊤et)
把 speaker 级 attractor 重新落回逐帧 diarization 输出上。
三、实验结果
3.1 数据与训练流程
| 阶段 | 数据 | 说明 |
|---|---|---|
| 预训练阶段 1 | LibriSpeech 模拟混合 | 100,000 条 2-speaker mixture,beta=2 |
| 预训练阶段 2 | LibriSpeech 模拟混合 | 400,000 条 1/2/3/4-speaker mixture,beta=2,2,5,9 |
| 微调 | 真实公开数据 | DIHARD III、VoxConverse、MagicData-RAMC、AMI MIX、AMI SDM1,共 979 个训练文件 |
3.2 模型配置
| 项目 | 配置 |
|---|---|
| Encoder | 4 层 Conformer |
| 隐藏维度 | 256 |
| Attention heads | 4 |
| FFN 维度 | 1024 |
| 输入特征 | 23 维 log Mel filterbank |
| 窗长 / 帧移 | 25 ms / 10 ms |
| 最大说话人数 | 4 |
| 默认训练长度 | 5000 帧 |
论文所有主要实验都是在"最多 4 个 speaker"的设置下做的。
在可训练的多人范围内,Transformer attractor 比 LSTM attractor 更有效。
3.3 TA 明显优于 EDA / EDA+CSV
| Attractor 模块 | NS1-NS4 DER | NS1-NS9 DER |
|---|---|---|
| EDA | 17.45 | 21.68 |
| EDA + CSV | 17.13 | 21.34 |
| TA | 14.77 | 18.78 |
结论
- 相比 EEND-EDA,EEND-TA 在 NS1-NS4 上有 2.68% 绝对 DER 改进
- 相比 EEND-EDA + CSV,EEND-TA 也有 2.36% 绝对 DER 改进
更关键的是,即使 TA 的最大输出 speaker 数固定为 4,在 NS1-NS9 上它依然整体更强。即
EEND-EDA 虽然理论上可以继续往后生成 attractor,但"能继续生成"不等于"生成得好"。
这也说明很多 EEND-EDA 家族方法其实存在经验上的 speaker 数上限。
3.4 Decoder 层数消融
| Transformer decoder 层数 | NS1-NS4 DER |
|---|---|
| 1 | 16.30 |
| 2 | 15.93 |
| 3 | 15.30 |
| 4 | 15.40 |
结论
- decoder 太浅,表达能力不够
- decoder 太深,也没有继续带来收益
- 本文配置下,3 层是最合适的平衡点
3.5 Combiner 消融:门控放大型最好
| Combiner | NS1-NS4 DER |
|---|---|
| None | 15.46 |
| phi_add | 15.30 |
| phi_mult | 15.48 |
| phi_amp, alpha=1.0 | 14.77 |
结论
- 不用 CSV,性能会下降,说明 conversational summary 确实有用
- 简单加法有效,但不是最优
- 最优的是门控放大型 ϕ a m p \phi_{\mathrm{amp}} ϕamp
3.6 分数据集结果
| 数据集 | EDA | TA | 相对改进 |
|---|---|---|---|
| DIHARD III | 14.07 | 12.93 | 8.10% |
| VoxConverse | 15.75 | 9.89 | 37.2% |
| MagicData-RAMC | 14.45 | 13.58 | 6.02% |
| AMI Mix | 19.85 | 17.88 | 9.92% |
| AMI SDM1 | 32.24 | 24.64 | 23.55% |
结论
- 在 VoxConverse 上提升最大,说明面对更复杂、更野外的多人对话时,TA 更有优势
- 在 AMI SDM1 这种远场条件下提升也很明显,说明 TA 更抗远场退化
- 在 MagicData-RAMC 这种只有 2 人对话的数据集上,提升相对较小
3.7 训练长序列时,TA 更能吃到收益
| 模型 | 训练长度 | NS1-NS4 DER |
|---|---|---|
| EEND-EDA | 50 s | 17.45 |
| EEND-EDA | 200 s | 16.37 |
| EEND-TA | 50 s | 14.77 |
| EEND-TA | 200 s | 13.99 |
结论
- 训练片段变长后,EEND-EDA 和 EEND-TA 都会提升
- 但 EEND-TA 受益更明显
- 甚至 50 秒训练的 EEND-TA,就已经优于 200 秒训练的 EEND-EDA
TA 比 LSTM-EDA 更擅长在长上下文中稳定提取 speaker 信息。
3.8 推理效率
| Attractor 模块 | 相对速度 | 参数量(M) |
|---|---|---|
| EDA | 1.00x | 8.1 |
| EDA + CSV | 0.94x | 8.1 |
| TA | 1.28x | 10.2 |
结论
- TA 可以并行地产生 attractor,速度更快
四、总结
EEND-TA 说明 attractor 的生成本质上是在"从整段对话中检索 speaker 原型",那么用 Transformer decoder 来做这件事,会比用 LSTM encoder-decoder 更自然。
收益:
- 更稳:对输入顺序不那么敏感,不再像 LSTM 那样容易"忘掉前面出现过的 speaker"
- 更强:在论文的真实测试集上,相比 EEND-EDA 有明显 DER 改进
- 更快:attractor 可并行生成,推理吞吐高于 EEND-EDA
局限:
- EEND-TA 并没有真正解决"无限说话人数"问题 。论文里的 EEND-TA 依然设置了最大说话人数上限,本实验中是 S = 4 S=4 S=4。