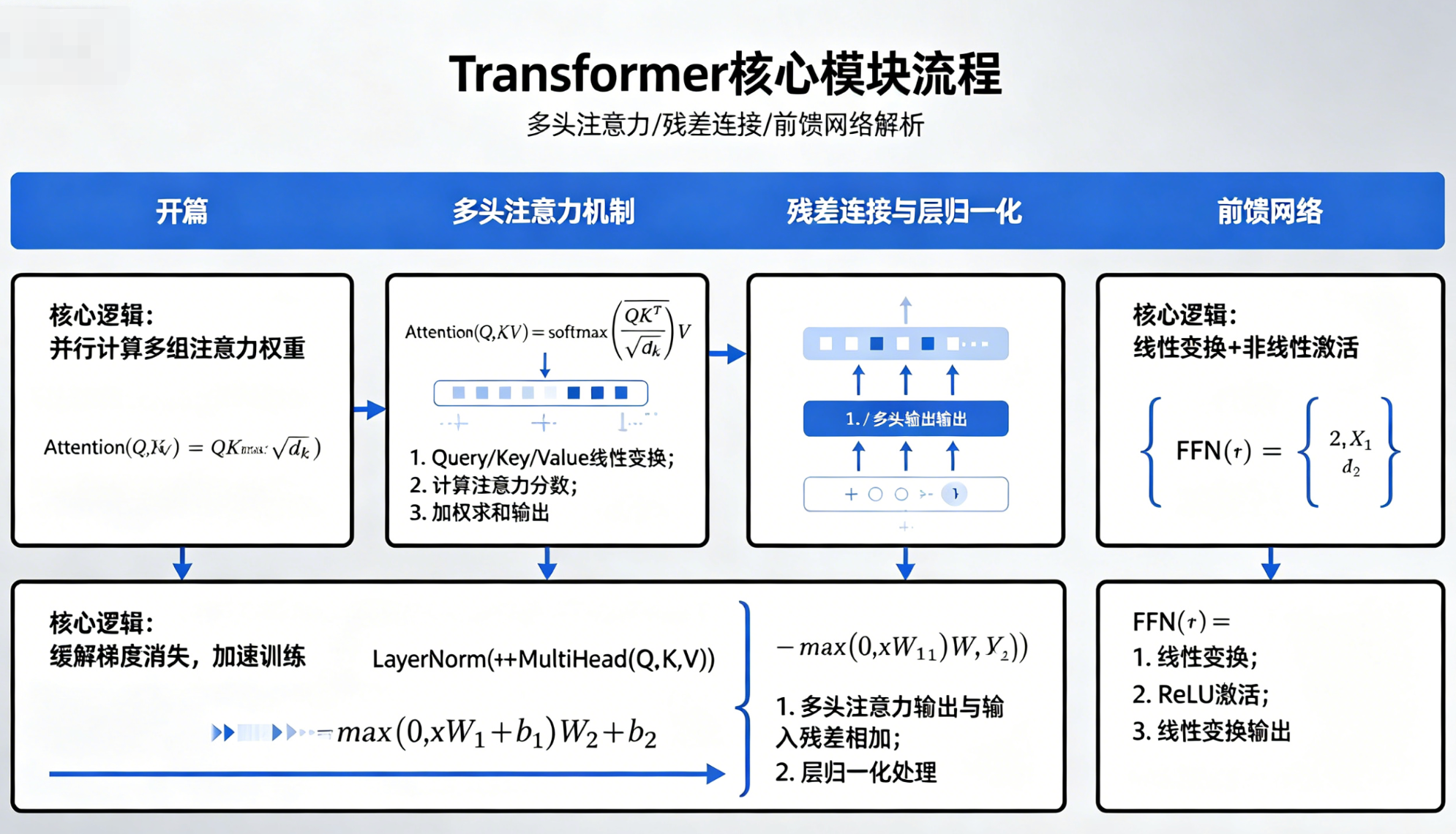
在学习大模型相关知识时,Transformer绝对是绕不开的核心架构,而其中的多头注意力机制、残差连接、层归一化以及前馈网络,更是让很多新手望而却步的"拦路虎"。不少人第一次接触这些概念时,都会被复杂的公式、抽象的矩阵维度和专业术语搞得晕头转向,甚至越看越困惑。其实这些看似高深的技术,本质上都是为了解决"让模型更好地理解语言"这一核心问题,只要用通俗的类比、清晰的步骤拆解,就能彻底搞懂它们的原理和作用。
本文将以最接地气的大白话,结合生活化的例子,一步步拆解Transformer中最核心的三大模块,多头注意力机制、残差连接(含层归一化)、前馈网络,把每一个细节、每一步计算、每一个公式都翻译成普通人能听懂的语言,同时补充知识点之间的关联,帮你构建完整的知识体系,彻底摆脱"看不懂、记不住、不会用"的困境。不管你是零基础的新手,还是已经接触过相关知识但仍有困惑的学习者,读完这篇文章,都能对Transformer的核心架构有清晰且深入的理解。
开篇:为什么Transformer能成为大模型的"核心骨架"?
在了解具体模块之前,我们先搞清楚一个核心问题:为什么Transformer能取代传统的循环神经网络(RNN),成为ChatGPT、BERT等大模型的核心架构?答案很简单:传统RNN是"串行处理",只能一个词一个词地分析,处理长句子时不仅速度慢,还容易丢失前面的信息;而Transformer采用"并行处理",能同时分析一句话中所有词的关系,既高效又能更好地捕捉上下文关联。
如果把语言理解比作"侦探破案",传统RNN就像一个侦探,只能按顺序逐个排查线索,很容易遗漏关键信息;而Transformer就像一个侦探团队,每个人负责不同的排查方向,最后汇总线索得出结论,效率更高、结论更全面。而这个"侦探团队"的核心成员,就是我们接下来要重点讲解的多头注意力、残差连接和前馈网络,它们分工明确、配合默契,共同完成对语言的深度理解。
接下来,我们就逐个拆解这些核心模块,从"是什么、为什么、怎么做"三个角度,把每一个知识点讲透、讲细,让你彻底摆脱困惑。
第一部分:多头注意力机制,让模型"看清"词与词的关系
多头注意力机制是Transformer的"灵魂",也是最容易让人困惑的模块。很多人看到"注意力""多头""矩阵计算"这些词就头疼,但其实它的核心逻辑非常简单:让模型同时从多个角度,关注一句话中每个词和其他词的关联,从而更全面地理解句子的含义。
我们不用一上来就纠结公式和维度,先从一个生活化的类比入手,轻松搞懂它的核心作用。
一、先搞懂:为什么需要"多头"注意力?
我们先区分两个概念:单头注意力和多头注意力。
假设你需要翻译一句话"人工智能正在改变世界",如果只找一个翻译员(单头注意力),他只能从自己的专业角度出发,比如有的翻译员擅长语法,有的擅长语义,有的擅长情感表达,单独一个人翻译,很容易遗漏一些关键信息,翻译结果也不够全面。
但如果你找8个翻译员(多头注意力),每个人负责一个角度:第一个关注语法结构,第二个关注语义关联,第三个关注情感色彩,第四个关注专业术语,第五个关注上下文逻辑,第六个关注用词搭配,第七个关注句式特点,第八个关注整体语气。最后把这8个翻译员的结果汇总整合,得到的翻译结果一定会更全面、更准确。
Transformer中的多头注意力机制,干的就是这个事。它设置了8个独立的"小注意力头",每个头都从不同的维度提取句子中的信息,最后把8个头部的输出结果拼接起来,让模型能同时关注到句子里的多种关联,比如语法关联、语义关联、情感关联等,从而更深入地理解句子的含义。
这里有一个关键前提:为什么是8个头部?后面我们会详细讲解,这里先记住一个结论:8个头部是Transformer原论文经过大量实验验证的最优选择,既能保证信息的全面性,又不会让计算量过大。
二、核心公式拆解:把复杂公式翻译成"大白话"
讲到多头注意力,就绕不开它的核心公式。很多人看到公式就望而却步,但其实只要把公式拆解开,逐句翻译,就会发现它一点都不复杂。我们先看最核心的两组公式,再逐个拆解每一步的含义。
1. 多头注意力总公式
公式如下:
{MultiHead(Q,K,V)=Concat(head1,head2,...,headh)WOwhere headi=Attention(QWiQ,KWiK,VWiV)\begin{cases} \text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_1,\text{head}_2,\dots,\text{head}_h)W^O \\ \text{where } \text{head}_i = \text{Attention}(QW_i^Q,KW_i^K,VW_i^V) \end{cases}{MultiHead(Q,K,V)=Concat(head1,head2,...,headh)WOwhere headi=Attention(QWiQ,KWiK,VWiV)
很多人看到这个公式就懵了,其实我们可以把它翻译成四步"大白话",每一步都对应一个简单的操作:
第一步:准备"原材料"。输入的句子经过词嵌入和位置编码后,会得到三个矩阵:Q(查询矩阵)、K(键矩阵)、V(值矩阵)。简单理解:Q是"我要查询的内容",K是"所有可供查询的键",V是"每个键对应的具体内容"。比如我们要理解"它"这个词,Q就是"它",K就是句子中所有的词,V就是每个词的具体含义。
第二步:给每个头分配"专属工具"。我们有8个头部,所以需要给每个头部配备一套独立的"小权重矩阵",分别是 WiQW_i^QWiQ (Q的权重矩阵)、 WiKW_i^KWiK (K的权重矩阵)、 WiVW_i^VWiV (V的权重矩阵)。用输入的Q、K、V分别乘上这8组小权重矩阵,就能得到8组"小Q、小K、小V",每组对应一个头部,相当于给每个翻译员配备了一套专属的"翻译工具"。
第三步:每个头单独"工作"。用8组小Q、小K、小V,分别跑8次"单头注意力计算",得到8个输出结果,也就是公式中的 head1\text{head}_1head1 到 head8\text{head}_8head8 ,每个头部的输出都代表了它从自己的角度提取到的句子信息。
第四步:汇总整合"结果"。把8个头部的输出结果"拼接"(Concat)起来,形成一个大矩阵,再乘上一个输出权重矩阵 WOW^OWO ,做一次最终的整合,就得到了多头注意力的最终输出。这一步相当于把8个翻译员的结果汇总起来,再由一个"总审核"进行整理,得到最终的翻译结果。
2. 单头注意力公式(每个头部的具体计算)
每个头部的计算,都遵循单头注意力公式:
headi=Attention(Qi,Ki,Vi)=Softmax(QiKiTdk)Vi\text{head}_i = \text{Attention}(Q_i,K_i,V_i) = \text{Softmax}\left(\frac{Q_iK_i^T}{\sqrt{d_k}}\right)V_iheadi=Attention(Qi,Ki,Vi)=Softmax(dk QiKiT)Vi
这个公式看似复杂,其实只有四步操作,每一步都有明确的作用,我们逐个拆解:
第一步:计算"相似度"。用每个头部的小Q( QiQ_iQi )和小K( KiK_iKi )做矩阵乘法( QiKiTQ_iK_i^TQiKiT ),得到一个相似度矩阵。这个矩阵的作用是:计算每个词和句子中其他所有词的关联程度,数值越大,说明两个词的关系越近。比如"人工智能"和"技术"的相似度数值会很高,和"苹果"的相似度数值会很低。
第二步:"缩放"操作。用第一步得到的相似度矩阵,除以 dk\sqrt{d_k}dk ( dkd_kdk 是每个头部Q、K的维度,后面会讲)。这一步的作用很简单:防止相似度矩阵的数值太大,导致后面的Softmax函数失效。举个例子,如果数值太大,Softmax会把大部分权重都集中在少数几个词上,导致模型只关注少数词,忽略其他重要信息,缩放后就能避免这种情况。
第三步:归一化处理。用Softmax函数把缩放后的相似度矩阵,归一化到0-1之间,得到注意力权重矩阵。归一化的意思是,每个词对应的所有权重加起来等于1,这样就能清晰地看出"每个词应该重点关注哪些词"。比如"它"这个词的权重矩阵中,"猫"的权重是0.8,其他词的权重加起来是0.2,说明模型认为"它"主要指代"猫"。
第四步:加权求和。用归一化后的注意力权重矩阵,乘上每个头部的小V( ViV_iVi ),得到这个头部的最终输出。这一步的作用是:根据权重的大小,给每个词的内容赋予不同的重要性,权重越大,对应的内容越重要,从而让模型聚焦于关键信息。
3. 维度公式:为什么每个头部的维度是64?
在Transformer原论文中,有一个固定的维度设置:
dk=dv=dmodelh=64d_k = d_v = \frac{d_{\text{model}}}{h} = 64dk=dv=hdmodel=64
我们还是用大白话翻译:
首先, dmodeld_{\text{model}}dmodel 是模型的总维度,固定为512(这也是原论文的经典设置);h是头部的数量,固定为8。用总维度512除以头部数量8,得到每个头部的Q、K、V维度都是64。
为什么要这样设置?核心原因是"维度匹配"。每个头部的输出维度是64,8个头部拼接起来,64×8=512,刚好回到模型的总维度512,这样就能保证多头注意力的输出维度和输入维度一致,方便后面的模块继续处理。如果维度不匹配,后面的计算就会出错,整个模型的架构就会崩塌。
简单总结:512维的总输入,拆成8个64维的小输入,每个头部处理一个小输入,最后再拼回512维,既保证了信息的全面性,又不破坏模型的整体结构。
三、一步步拆解:多头注意力到底怎么计算?(结合实例,一看就懂)
前面我们讲了公式和核心逻辑,接下来我们结合一个具体的例子,一步步拆解多头注意力的计算过程,让你彻底明白每一步到底在做什么。我们用原文中的例子:输入句子是"人工智能"4个汉字,经过词嵌入和位置编码后,得到一个4行512列的输入矩阵X(4个词,每个词用512个数字表示),并且Q=K=V=X(这是自注意力的情况,也是Transformer中最常用的情况)。
第1步:给每个头生成"专属Q/K/V"
我们有8个头部,所以需要准备8组独立的权重矩阵,每组权重矩阵都有三个:Q的权重矩阵、K的权重矩阵、V的权重矩阵,每个权重矩阵的维度都是512, 64(512是输入维度,64是每个头部的输出维度)。
具体操作:用输入的Q矩阵(维度4,512),分别乘上8组Q的权重矩阵( Wq0W_{q_0}Wq0 到 Wq7W_{q_7}Wq7 ),就能得到8个小Q矩阵,每个小Q矩阵的维度都是4,64(4个词,每个词64维)。
同理,用输入的K矩阵乘上8组K的权重矩阵,得到8个小K矩阵(每个4,64);用输入的V矩阵乘上8组V的权重矩阵,得到8个小V矩阵(每个4,64)。
这里可以用一个比喻:每个头部就像一个"分析师",8组权重矩阵就像8套不同的"分析模板",每个分析师拿到一套模板,把原始的512维数据,加工成64维的"分析报告",每个报告都从自己的角度提取了关键信息,互不干扰。比如头1的模板擅长提取语法信息,头2的模板擅长提取语义信息,头3的模板擅长提取情感信息,以此类推。
第2步:每个头单独跑"注意力计算"
这一步是每个头部独立工作的过程,我们以其中一个头部(比如头1)为例,讲解具体计算过程,其他7个头部的计算过程完全一样。
头1的输入是自己的小Q(4,64)、小K(4,64)、小V(4,64),计算过程如下:
-
计算相似度:用小Q(4,64)乘上小K的转置(64,4),得到一个4,4的相似度矩阵。这个矩阵的每一行,都代表一个词和其他4个词的相似度。比如第一行是"人"这个词和"人、工、智、能"四个词的相似度,数值越大,说明关系越近。
-
缩放:用相似度矩阵除以 64\sqrt{64}64 (也就是8),对数值进行缩放,避免数值过大导致Softmax失效。
-
Softmax归一化:把缩放后的相似度矩阵,通过Softmax函数归一化,得到4,4的注意力权重矩阵。比如"人"这个词的权重矩阵中,"工"的权重是0.3,"智"的权重是0.2,"能"的权重是0.1,"人"自身的权重是0.4,加起来等于1,说明"人"这个词重点关注自己和"工"。
-
加权求和:用注意力权重矩阵(4,4)乘上小V(4,64),得到头1的输出Z1(4,64)。这个输出矩阵,就是头1从自己的角度,对"人工智能"这句话的理解和编码。
我们把这个过程重复8次,就得到了8个头部的输出:Z1到Z8,每个输出的维度都是4,64。这就相当于8个分析师,各自完成了自己的"分析报告",每个报告都包含了从一个角度提取的关键信息。
第3步:拼接8个头的输出,进行最终整合
这一步是把8个头部的"分析报告"汇总整合,得到最终的多头注意力输出,分为两个小步骤:
-
拼接(Concat):把8个头部的输出Z1到Z8,沿着"列"的方向拼接起来。每个头部的输出是4,64,8个拼接起来,列数就是64×8=512,所以拼接后的矩阵维度是4,512,和输入矩阵X的维度完全一致。这一步就相当于把8个分析师的报告,整理成一份完整的"汇总报告",包含了所有角度的信息。
-
最终线性变换:用一个维度为512,512的输出权重矩阵 WOW^OWO ,乘上拼接后的大矩阵,得到多头注意力的最终输出,维度还是4,512。这一步的作用是:对8个头部的信息进行进一步整合,消除不同头部之间的"信息偏差",让汇总后的信息更连贯、更准确,方便后面的模块继续处理。
到这里,多头注意力的整个计算过程就完成了。我们可以用一个简单的生活流程,帮你彻底记住这个过程:
老板(输入Q/K/V)给了一份"人工智能"的材料(4个词,512维)→ 老板找了8个专员(8个头部),给每个专员配了一套"专属分析模板"(8组权重矩阵)→ 每个专员用自己的模板,把材料加工成了一份64维的分析报告(每个头部的输出Zi)→ 秘书把8份报告拼在一起,做成了一份512维的总报告(拼接操作)→ 总监(输出权重矩阵 WOW^OWO )对总报告做了一次整合,最终输出一份和原始材料维度一致、但信息更丰富的成品(多头注意力最终输出)。
四、多头注意力的核心优势与关键细节补充
- 核心优势:为什么多头注意力比单头注意力更好?
单头注意力就像只有一个分析师,只能从一个角度分析问题,很容易遗漏信息、产生偏见;而多头注意力有8个分析师,每个分析师从不同角度分析,汇总后的结果更全面、更准确。具体来说,多头注意力能捕捉到句子中更多样的关联,比如语法关联、语义关联、情感关联、长距离依赖等,让模型对句子的理解更深入、更全面。
- 关键细节:为什么是8个头部?64维?
这是Transformer原论文经过大量实验验证的最优设计,核心是"平衡信息全面性和计算量":
-
头部数量太少(比如2个、4个):信息不够全面,模型无法捕捉到足够多的关联,理解能力会下降;
-
头部数量太多(比如16个、32个):计算量会急剧增加,模型训练起来更困难,而且会出现"参数冗余",也就是很多头部的作用重复,反而降低模型效率;
-
每个头部64维:既保证了每个头部有足够的表达能力,能提取到有效的信息,又能让8个头部拼接后刚好回到512维,保证维度匹配,不破坏模型结构。
- 维度变化总结(帮你快速记忆)
为了方便你记忆,我们用一张简单的表格,总结整个多头注意力过程中的维度变化,对应我们前面讲的例子(输入是"人工智能"4个词,维度4,512):
| 步骤 | 操作 | 输入维度 | 权重维度 | 输出维度 |
|---|---|---|---|---|
| 1 | 生成每个头的Q/K/V | Q/K/V: 4,512 | Wq/Wk/WvW_q/W_k/W_vWq/Wk/Wv : 512,64 | Qi/Ki/ViQ_i/K_i/V_iQi/Ki/Vi : 4,64(8组) |
| 2 | 单头注意力计算 | Qi/Ki/ViQ_i/K_i/V_iQi/Ki/Vi : 4,64 | 无(公式内计算) | ZiZ_iZi : 4,64(8个) |
| 3 | 拼接8个头 | 8个4,64 | 无 | Z: 4,512 |
| 4 | 最终线性变换 | Z: 4,512 | WoW_oWo : 512,512 | 最终输出: 4,512 |
第二部分:残差连接与层归一化,让模型"稳得住",不"学崩"
理解了多头注意力机制后,我们接下来讲解Transformer中的另一个核心模块:残差连接(Add)和层归一化(Norm)。这两个模块通常一起出现,组成"Add & Norm"模块,它们的核心作用是:让模型训练更稳定,避免出现"梯度消失""梯度爆炸"的问题,同时保留原始信息,让模型能更好地学习。
很多人在学习这两个概念时,会被"残差""归一化"这些术语搞得困惑,甚至不知道它们到底在做什么。其实我们还是用生活化的类比,结合具体的作用,就能轻松搞懂。
一、残差连接(Add):给模型留一条"后路"
我们先看书上对残差连接的定义:"Add表示残差连接,即将输出矩阵Z与输入矩阵X进行加法运算。" 这句话看似简单,但背后的逻辑非常关键,我们用一个生活化的类比,帮你理解它的作用。
1. 传统神经网络的"致命问题"
在Transformer出现之前,传统的神经网络(比如CNN、RNN)有一个很大的问题:当网络层数很深时,模型会出现"梯度消失"或"梯度爆炸"的情况,导致模型无法正常训练。
我们可以把神经网络想象成"多层筛子":输入的原始数据,就像一堆沙子,每一层筛子都会对沙子进行一次加工(筛选出有用的特征)。传统网络中,沙子只能一层一层往下传,没有回头路。如果网络层数太多,经过多层筛选后,原始的沙子(原始信息)会彻底丢失,而且筛选后的沙子(加工后的特征)会越来越少,最后导致模型"学不到东西"(梯度消失);或者筛选后的沙子越来越多,超出模型的处理能力,导致模型"崩溃"(梯度爆炸)。
举个例子:你写一篇论文,传统网络就像你写完初稿后,给导师改,改完给二审,改完给三审,每一轮修改都只传递修改后的版本,不保留原始初稿。最后拿到的稿子,可能和你最开始的想法完全不一样,甚至偏离了主题(原始信息丢失);或者每一轮修改都增加大量内容,最后稿子变得杂乱无章,无法使用(梯度爆炸)。
2. 残差连接:给模型加一条"高速公路"
残差连接的核心,就是给模型加一条"高速公路",让原始输入数据能"抄近路"直接传到下一层,和加工后的结果相加,而不是只传递加工后的结果。
我们用公式来理解:
传统网络的输出: H(x)=f(x)H(x) = f(x)H(x)=f(x) ,其中x是输入,f(x)是加工后的结果。也就是说,下一层只能拿到加工后的结果,原始输入x彻底丢失。
残差网络的输出: H(x)=f(x)+xH(x) = f(x) + xH(x)=f(x)+x ,其中x是原始输入,f(x)是加工后的结果。也就是说,下一层拿到的是"原始输入 + 加工后的结果",原始信息被完整保留了。
回到论文的例子:残差连接就像你写完初稿后,每一轮审稿都把"审稿修改版 + 原始初稿"一起传给下一轮。这样不管改多少轮,你的原始想法(原始输入)永远都在,不会被丢失;而且如果某一轮修改得不好(加工后的结果f(x)很差),原始初稿(x)可以起到"兜底"的作用,不会让整个稿子彻底废掉。
3. Transformer中的残差连接:Add操作
在Transformer中,残差连接就是"Add"操作,它的使用非常简单:每经过一个功能模块(比如多头注意力、前馈网络),都会把这个模块的输入和输出相加,得到新的输出,再传给下一个模块。
比如,多头注意力的输入是X(4,512),输出是Z(4,512),Add操作就是把X和Z相加,得到X+Z(维度还是4,512),然后再把X+Z传给层归一化模块。
这里有一个关键细节:加法不会改变矩阵的维度,所以残差连接的输入和输出维度永远一致,这就保证了模型的整体结构不会被破坏,后面的模块能正常处理数据。
4. 残差连接的3大核心优势
残差连接看似简单,但它解决了深层网络训练的核心问题,主要有3大优势:
(1)解决梯度消失/爆炸:在模型训练时,梯度需要从最后一层反向传播到最底层。如果没有残差连接,梯度会经过多层乘法,越乘越小(梯度消失)或越乘越大(梯度爆炸);而有了残差连接,梯度可以顺着"原始输入x"这条"高速公路"直接传回最底层,不会被层层削弱或放大,让深层网络也能正常训练。
(2)保留原始信息:原始输入x会一直跟着数据流传下去,不会在多层加工中丢失。模型在学习加工特征的同时,还能保留原始信息,这样学到的特征会更完整、更准确。
(3)增强模型表达能力:把"原始特征(x)"和"加工后的特征(f(x))"融合在一起,模型能学到更复杂的规律,拟合能力更强。比如,原始特征是词的基本含义,加工后的特征是词的上下文关联,两者融合后,模型能更全面地理解词的含义。
二、层归一化(Norm):给模型"校准"数据,避免"跑偏"
残差连接之后,紧接着就是层归一化(Norm)。很多人会把层归一化和批归一化(Batch Norm)搞混,其实它们的作用类似,但适用场景完全不同。我们先搞懂归一化的核心作用,再区分两者的区别。
1. 归一化的核心作用:让数据"标准化",稳定训练
简单来说,归一化就是把模型中的数据,强行调整成"标准正态分布"(均值为0,方差为1)。为什么要这么做?
在模型训练过程中,随着数据的层层加工,数据的数值会变得越来越大或越来越小,导致模型的参数更新不稳定,甚至出现"梯度爆炸"的情况。归一化就像给数据"校准",把所有数据都拉到同一个"标准范围"内,让模型能更稳定地学习,避免数据"跑偏"。
举个例子:如果模型中有的数据数值是1000,有的数据数值是0.001,两者差距太大,模型在更新参数时,会偏向于数值大的数据,忽略数值小的数据,导致训练不稳定;归一化后,所有数据都在0附近波动,差距变小,模型就能更公平地学习所有数据的特征。
2. 层归一化(Layer Norm)vs 批归一化(Batch Norm):关键区别
Transformer中只用层归一化,而不用批归一化,这是一个非常关键的知识点。我们用通俗的类比,结合具体的操作,帮你区分两者的区别。
首先,我们明确两个基本概念:
-
Batch Size(批量大小):一次同时喂给模型的句子数量,比如书上的例子中,批量大小是6,也就是一次喂给模型6个句子。
-
特征维度(Hidden Size):每个词用多少个数字表示,也就是我们前面讲的 dmodel=512d_{\text{model}}=512dmodel=512 ,每个词用512个数字表示。
(1)批归一化(Batch Norm):"横向对比",管"全班同学"
批归一化的操作方向是"横向切",也就是"同一位置的词对比"。具体来说:
假设我们有6个句子(批量大小=6),每个句子有4个词,每个词有512维特征。批归一化会把6个句子中"同一位置的词"拿出来,计算它们的均值和方差,然后进行归一化。
用生活化的类比:全班有6个学生(6个句子),每个学生都考了语文、数学、英语等512门科目(512维特征)。批归一化就相当于:统计所有学生的"语文成绩"分布,把大家的语文分拉到统一标准;再统计所有学生的"数学成绩"分布,把数学分拉到统一标准;以此类推,直到所有科目都完成归一化。
为什么Transformer不用批归一化?核心原因是:Transformer的注意力机制是关注"同一个句子内部"的词与词关系,而批归一化会把不同句子的同位置词混在一起统计,破坏了句子的独立性。比如,句子A的"人工智能"和句子B的"人工智能",虽然词一样,但上下文不同,含义也可能不同,批归一化把它们混在一起统计,会让模型无法区分它们的上下文,导致理解出错。
(2)层归一化(Layer Norm):"纵向对比",管"单个学生"
层归一化的操作方向是"纵向切",也就是"单个句子内部的词对比"。具体来说:
还是以6个句子为例,层归一化会单独拿出其中一个句子,把这个句子中所有词的512维特征,计算均值和方差,然后进行归一化,完全不管其他5个句子。
用生活化的类比:还是全班6个学生,层归一化不关注其他学生,只关注其中一个学生,把这个学生的"语文、数学、英语"等所有科目成绩,拉到一个统一标准(比如总分变成平均分,方差标准化)。
为什么Transformer最爱层归一化?核心原因有两个:
第一,层归一化只处理单个句子,不会破坏句子的独立性,能完美保留句子内部的词与词关系,适配Transformer的注意力机制;
第二,层归一化的计算更简单,不需要等待所有句子都输入后再统计,单个句子就能完成计算,适合并行处理,提高模型的训练效率。
3. 层归一化的公式与大白话翻译
层归一化的公式如下:
y=γ⋅x−μσ2+ε+βy = \gamma \cdot \frac{x - \mu}{\sqrt{\sigma^2 + \varepsilon}} + \betay=γ⋅σ2+ε x−μ+β
我们把这个公式翻译成大白话,每一步都很简单:
-
x:需要归一化的数据(比如残差连接后的X+Z矩阵);
-
μ\muμ :数据的均值(比如单个句子中所有词的512维特征的平均值);
-
σ2\sigma^2σ2 :数据的方差(衡量数据的离散程度);
-
ε\varepsilonε :一个很小的数(比如1e-5),防止分母为0;
-
γ\gammaγ 和 β\betaβ :可学习的参数,用来调整归一化后的结果,让模型能根据实际情况优化,避免归一化过于"死板";
-
y:归一化后的输出数据,维度和输入x一致。
简单总结:层归一化就是先计算数据的均值和方差,然后用数据减去均值、除以标准差(方差的平方根),把数据拉到均值为0、方差为1的标准分布,最后再通过两个可学习参数调整,得到最终的输出。
三、Add & Norm 模块:残差连接与层归一化的"完美配合"
在Transformer中,残差连接(Add)和层归一化(Norm)从来都不是单独使用的,它们总是组成"Add & Norm"模块,而且在编码器的每一层中会出现两次:一次在多头注意力之后,一次在前馈网络之后。
我们用具体的流程,讲解Add & Norm模块的工作过程(以多头注意力之后的Add & Norm为例):
-
输入:多头注意力的输入X(4,512)和输出Z(4,512);
-
Add(残差连接):把X和Z相加,得到X+Z(4,512),保留原始输入信息;
-
Norm(层归一化):对X+Z进行层归一化,得到归一化后的输出(4,512),稳定数据分布;
-
输出:把归一化后的结果,传给下一个模块(前馈网络)。
前馈网络之后的Add & Norm模块,工作过程完全一样:前馈网络的输入和输出相加,再进行层归一化,然后传给下一层或输出。
为什么要这样设计?核心目的是"双重保护":
-
残差连接负责"保留原始信息",给模型留后路,避免梯度消失;
-
层归一化负责"稳定数据分布",避免数据跑偏,让模型训练更稳定。
两者配合,让模型既能学到有用的特征,又能稳定训练,不会出现"学崩"的情况。
第三部分:前馈网络(FFN),让模型"读懂"每个词的深层含义
在前文的讲解中,我们多次提到前馈网络,它是Transformer中不可或缺的核心模块,和多头注意力机制分工明确:多头注意力负责"找关系",前馈网络负责"深加工"。很多人对前馈网络的理解比较模糊,甚至觉得它"多余",但其实它的作用非常关键,让模型能深入理解每个词的深层含义,而不只是停留在"词与词的关系"层面。
接下来,我们用最通俗的语言,结合具体的步骤和类比,把前馈网络讲透,彻底解决你的困惑。
一、先记住一句话:多头注意力找关系,前馈网络深加工
这是理解前馈网络最核心的一句话,我们再用生活化的类比,把这句话讲明白:
假设句子是"小明今天上课睡觉",我们把句子比作一个班级,每个词比作一个学生:
-
多头注意力:就像一个"观察者",负责观察班级里每个学生和其他学生的关系,比如"睡觉"和"上课"关系近,"小明"是主语,"今天"是时间状语。它关注的是"关系",是"全局视角";
-
前馈网络:就像一个"体检医生",不管学生之间的关系,只盯着每个学生单独看,给每个学生做一次"深度体检",比如这个学生的性格是什么样的、学习成绩怎么样、有没有隐藏的问题。它关注的是"单个个体",是"局部视角、深度加工"。
简单来说,多头注意力帮模型搞懂"词和词之间的关系",前馈网络帮模型搞懂"每个词本身的深层含义"。两者结合,模型才能真正理解一句话的含义,而不是只停留在表面的关系层面。
二、前馈网络的核心结构:两层线性变换 + 一个激活函数
前馈网络的结构非常简单,本质上就是一个两层的全连接网络,核心是"两次线性变换 + 一次激活函数"。我们先看它的核心公式,再逐个拆解每一步的作用。
1. 核心公式大白话翻译
书上的前馈网络公式:
FFN(x)=max(0,xW1+b1)W2+b2FFN(x) = max(0, xW_1 + b_1)W_2 + b_2FFN(x)=max(0,xW1+b1)W2+b2
这个公式看似复杂,其实只有三步操作,我们逐个拆解,每一步都翻译成大白话:
第1步:第一次线性变换( xW1+b1xW_1 + b_1xW1+b1 ), 把词的特征"放大"
-
输入x:前馈网络的输入,也就是Add & Norm模块的输出,维度是4,512(4个词,每个词512维);
-
权重 W1W_1W1 :维度是512,2048,作用是把512维的特征,放大到2048维;
-
偏置 b1b_1b1 :一个常数,用来调整数据的偏移,让模型能更好地学习;
-
输出:经过第一次线性变换后,数据的维度从4,512变成4,2048。
大白话解释:这一步就像把一张小照片放大成高清图。512维的特征就像一张小照片,里面的细节不够清晰;放大到2048维,就相当于把照片放大,让模型能看到更多的细节,把词的隐含信息充分展开,方便后续的深度加工。
比如,"人工智能"这个词,512维的特征只能表达它的基本含义,而放大到2048维后,就能展开它的更多细节,比如它的应用场景、技术原理、发展趋势等,让模型能更深入地理解这个词。
第2步:ReLU激活函数( max(0,⋅)max(0, ·)max(0,⋅) ),过滤无效信息
这一步的操作非常简单:把第一次线性变换后的所有数据,进行"筛选",把负数变成0,正数保留不变。
大白话解释:模型在放大词的特征时,会不可避免地引入一些"无效信息"(比如一些无关的特征、噪声),这些无效信息会干扰模型的判断。ReLU激活函数就像一个"过滤器",把这些无效信息(负数)直接扔掉,只保留有用的特征(正数),让模型能聚焦于关键信息。
这里有一个关键细节:ReLU激活函数不会改变数据的维度,所以经过这一步后,数据的维度还是4,2048。
举个例子:第一次线性变换后,某个词的特征中,有一些数值是-0.5、-0.3(无效信息),还有一些数值是0.8、1.2(有用信息)。经过ReLU激活后,-0.5和-0.3变成0,0.8和1.2保留不变,这样就过滤掉了无效信息,保留了有用信息。
第3步:第二次线性变换( ⋅W2+b2·W_2 + b_2⋅W2+b2 ),把特征"压缩"回去
-
输入:ReLU激活后的输出,维度是4,2048;
-
权重 W2W_2W2 :维度是2048,512,作用是把2048维的特征,压缩回512维;
-
偏置 b2b_2b2 :和 b1b_1b1 一样,用来调整数据的偏移;
-
输出:经过第二次线性变换后,数据的维度从4,2048变回4,512,和输入x的维度完全一致。
大白话解释:这一步就像把修好的高清图,重新压缩成适合传输的大小。我们把词的特征放大、过滤无效信息后,需要再把它压缩回512维,保证前馈网络的输出维度和输入维度一致,方便后面的Add & Norm模块继续处理,不破坏模型的整体结构。
比如,我们把"人工智能"的特征放大到2048维,过滤掉无效信息后,再压缩回512维,此时的512维特征,比原始的512维特征更丰富、更精准,包含了更多的深层含义。
三、关键疑问解答:为什么要"先放大再缩小"?
这是很多人学习前馈网络时,最容易提出的疑问:既然最后还要压缩回512维,为什么还要先放大到2048维?直接用512维加工不行吗?
答案很简单:512维的空间太"窄",装不下词的复杂语义,模型无法进行深度推理;而2048维的空间足够"宽敞",能给模型足够的空间,展开词的隐含信息,进行复杂的逻辑推理,然后再压缩回512维,既保证了信息的丰富性,又不破坏模型结构。
我们用一个生活化的例子,帮你理解:
假设你要修改一张模糊的小照片,直接在小照片上修改,很难看清细节,修改效果不好;你可以先把小照片放大成高清图,在高清图上仔细修改、修复细节,修改完成后,再把高清图压缩回原来的大小,这样既修复了照片,又保留了照片的原始尺寸。
前馈网络的"先放大再缩小",和这个道理完全一样:先放大到2048维,给模型足够的空间,深入挖掘词的深层含义、进行复杂推理;再压缩回512维,保证模型结构的连贯性,方便后续处理。
另外,这里有一个固定的设计:2048维是512维的4倍,也就是 dff=4×dmodeld_{ff} = 4 \times d_{\text{model}}dff=4×dmodel 。这是Transformer原论文经过大量实验验证的最优选择,既能保证模型有足够的推理空间,又不会让计算量过大。
四、前馈网络的核心作用与细节补充
- 核心作用:增强模型的非线性表达能力
多头注意力和线性变换,都是"线性操作",只能捕捉线性关系;而前馈网络中的ReLU激活函数,是"非线性操作",能让模型捕捉到更复杂的非线性关系,比如词的语义歧义、情感变化、隐含含义等。
举个例子:"它"这个词,在不同的语境中,含义完全不同------"它是一只猫"中,"它"指代动物;"它是一台电脑"中,"它"指代物品;"它是一个好主意"中,"它"指代想法。多头注意力能发现"它"和后面的词有关系,但无法区分这些不同的含义;而前馈网络能通过非线性推理,区分"它"在不同语境中的不同含义,让模型的理解更精准。
- 关键细节:每个词单独处理,互不干扰
前馈网络的一个重要特点是:对每个词进行单独处理,不考虑其他词的影响。也就是说,"小明"这个词的加工过程,和"今天""上课""睡觉"这三个词的加工过程完全独立,互不干扰。
这和多头注意力形成了鲜明的对比:多头注意力关注的是词与词之间的关系,是"全局视角";前馈网络关注的是单个词的深层含义,是"局部视角"。两者结合,模型既能理解词与词的关系,又能理解每个词的深层含义,从而更全面、更深入地理解句子。