一、Kafka 基础概述
1.1 什么是 Kafka
Apache Kafka 是一个开源的分布式流处理平台 。Kafka 提供了一套统一的高吞吐、低延迟平台,用于处理实时数据流,本质上是一个分布式的、分区的、多副本的提交日志服务(distributed, partitioned, replicated commit log service)。
Kafka 具备三大核心能力:
-
发布与订阅:以消息队列的方式发布和订阅流式数据
-
存储:以容错的持久化方式存储数据流,消息保留时间可配置
-
处理:在数据流产生时进行实时处理(通过 Kafka Streams)
1.2 应用场景
| 场景 | 说明 |
|---|---|
| 异步处理 | 将耗时操作通过消息队列异步化,如发送短信验证码、邮件通知 |
| 系统解耦 | 通过消息队列替代直接的 HTTP 接口调用,降低微服务间的耦合度 |
| 流量削峰 | 利用消息队列的高吞吐和缓冲能力应对突发高并发流量 |
| 日志收集 | 集中收集分布式系统的日志数据,统一处理和分析 |
| 流处理 | 结合 Kafka Streams 实现实时数据流处理和分析 |
| 事件溯源 | 将系统状态变化记录为不可变的事件序列,支持回放和重建 |
| 变更数据捕获(CDC) | 捕获数据库变更日志并同步到其他系统 |
1.3 消息队列两种模型
-
点对点模型(Queue) :每个消息只有一个消费者,消费后消息从队列中删除。Kafka 4.0 通过 KIP-932(共享组/Share Groups) 原生支持了这一模型。
-
发布订阅模型(Topic) :每个消息可以有多个订阅者,订阅者需提前订阅并保持在线,Kafka 通过消费者组机制实现。
1.4 Kafka 消息语义
Kafka 提供了三种消息传递语义(Delivery Semantics):
| 语义 | 含义 | 实现方式 |
|---|---|---|
| At most once | 最多一次,消息可能丢失但不会重复 | acks=0,不重试 |
| At least once | 至少一次,消息不丢失但可能重复 | acks=all + 重试 |
| Exactly once | 精确一次(实际是"有效一次") | 幂等生产者 + 事务 |
"精确一次"实际上是在网络层"至少一次"语义之上构建的应用层保证,通过幂等性 (Producer ID + 序列号)和原子事务来消除重复消息的可见影响。
二、Kafka 核心架构
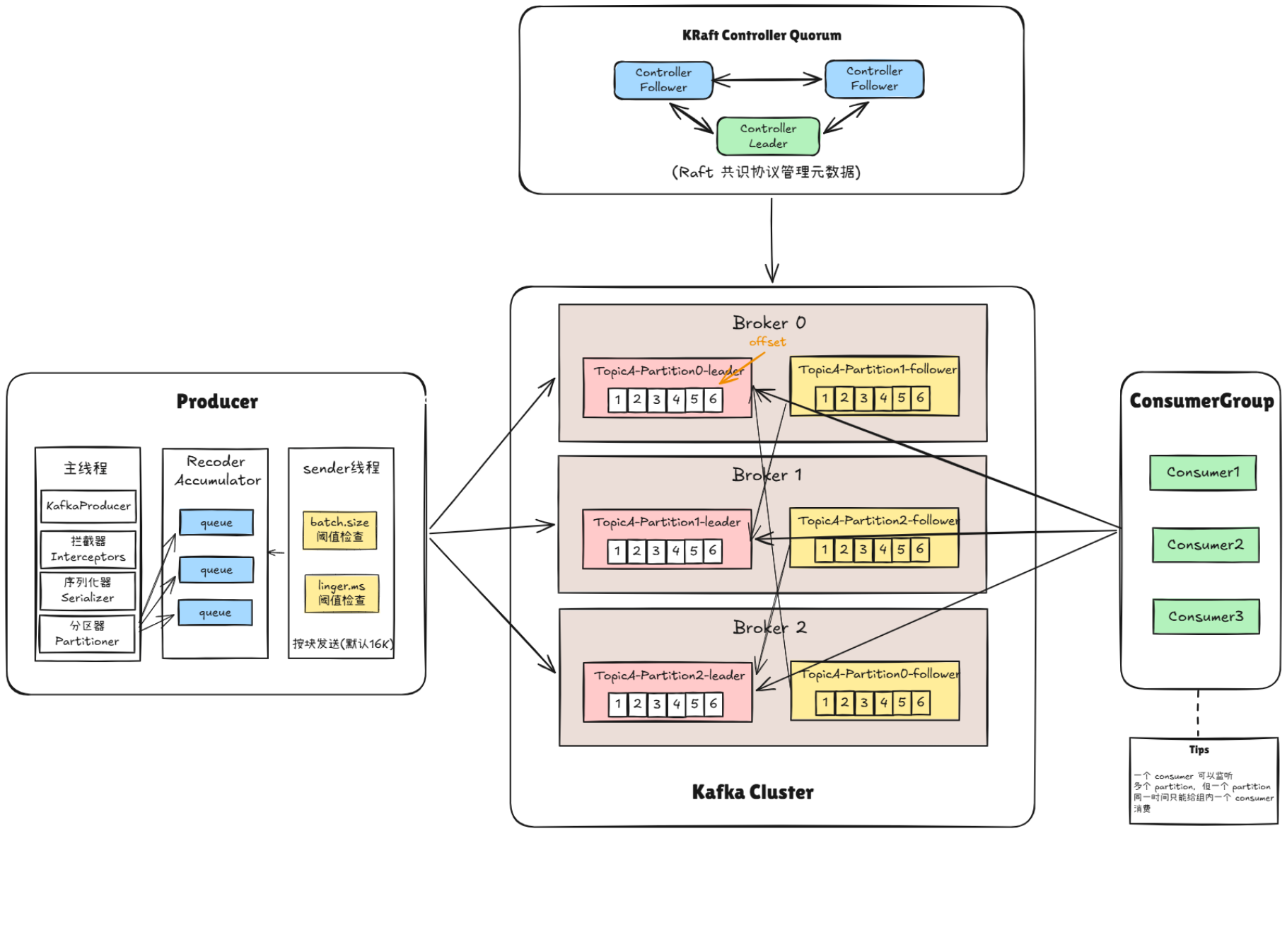
2.1 核心组件
Kafka 集群由以下核心组件构成:
| 组件 | 说明 |
|---|---|
| Broker | Kafka 服务实例,负责消息存储和传递,是集群中的核心节点 |
| Producer | 消息生产者,负责将消息发布到指定 Topic |
| Consumer | 消息消费者,订阅 Topic 并消费消息,通过 Pull 模式拉取消息 |
| Topic | 消息的逻辑分类,生产者发布到 Topic,消费者从 Topic 订阅 |
| Partition | Topic 的物理分区,是并行处理和扩展的基本单元 |
| Controller | 集群控制器,负责分区 Leader 选举、Broker 上下线管理等(KRaft 模式下由 Controller Quorum 承担) |
| Consumer Group | 消费者组,同一组内的消费者共同消费一个 Topic,实现负载均衡 |
| Group Coordinator | 消费者组协调器,管理组内消费者的分区分配和 Rebalance |
2.2 Broker 详解
Broker 是 Kafka 集群中的基本服务单元,每个 Broker 使用 TCP 协议与客户端通信,协议是语言无关的高性能二进制协议。Broker 水平扩展性极强,节点数量越多,集群吞吐率越高。单个 Broker 可以处理数千个客户端连接,同时管理多个分区。
2.3 Topic 与 Partition
Topic 代表逻辑上的消息流,是一个只追加(append-only)的日志:
-
Append-only:记录始终添加到日志末尾
-
Immutable:一旦写入,记录不可修改
-
Retention-based:基于时间或大小保留,而非消费状态
-
Multi-subscriber:多个消费者组可独立读取同一 Topic
Partition 是 Kafka 可扩展性的核心机制。每个 Topic 被划分为一个或多个 Partition,每个 Partition 是一个有序、不可变的消息序列 。每个分区中的消息被分配一个唯一的偏移量(Offset),用于标识消息在分区内的位置。Partition 的数量决定了:
-
并行度(更多消费者可同时读取)
-
吞吐量分布
-
扩展粒度
注意 :Kafka 4.0 之后的版本中,引入了 KIP-1114(分区分块/Chunk) 的概念,允许一个分区的数据分散存储在多个 Broker 上,进一步解耦了分区和存储节点之间的绑定关系。
分区策略:生产者发送消息时的路由方式
| 策略 | 触发条件 | 核心算法 | 典型应用场景 |
|---|---|---|---|
| 指定分区 | 显式调用 ProducerRecord 构造函数传入 partition |
直接使用指定值 | 需要绝对控制分区路由的场景 |
| 基于 Key 哈希 | 指定了 Key,未指定 Partition | murmur2(key) % partition_count |
需要相同 Key 消息有序的场景(如用户操作日志) |
| 粘性分区(Sticky) | 未指定 Key 和 Partition(Kafka ≥2.4 默认) | 随机选分区 → 填满批次 → 切换分区 | 高吞吐量、低延迟的通用场景 |
| 轮询(Round Robin) | 未指定 Key 和 Partition(旧版默认,现已不推荐) | 逐条消息轮换分区 | 已被粘性分区取代 |
| 自定义分区器 | 实现 Partitioner 接口并配置 |
完全自定义逻辑 | 特殊业务需求(如按地域路由、权重分配) |
分区数量建议:
-
常见起步配置为 6-12 个分区
-
单分区吞吐量通常为 10-50 MB/s(取决于硬件)
-
分区数 = 所需总吞吐量 ÷ 单分区吞吐量
-
同一消费者组内消费者数量 ≤ 分区数(超出部分闲置)
2.4 消费者组(Consumer Group)
消费者组机制实现负载均衡和容错:
-
任何 Consumer 必须属于一个 Group
-
同一 Group 中的 Consumer 不同时消费同一个 Partition
-
不同 Group 可同时消费同一条消息
-
Partition 数量决定了同一 Group 内消费者的最大并发数
-
消费者组的位移(Offset)可以存储到 Kafka 内部 Topic
__consumer_offsets或外部系统中
2.5 传统架构 vs KRaft 架构
Kafka 4.0 最重要的架构变革是彻底移除了对 ZooKeeper 的依赖,KRaft 成为默认且唯一的元数据管理方式。
| 对比维度 | ZooKeeper 模式 | KRaft 模式 |
|---|---|---|
| 元数据存储 | ZooKeeper 外部集群 | Kafka 内部 __cluster_metadata 主题 |
| 运维复杂度 | 需独立维护 ZK 集群 | 单一系统,部署管理简单 |
| 分区扩展上限 | 约 10 万+ | 百万级分区 |
| Controller 切换 | 秒级到分钟级 | 毫秒级到秒级 |
| 故障恢复时间 | 分钟级 | 秒级 |
| 适用版本 | Kafka 3.x 及更早 | Kafka 3.3+(实验性),4.0+(默认) |
KRaft 模式的技术实现 :KRaft(Kafka Raft)基于 Raft 共识算法,将元数据存储于内置的 __cluster_metadata 主题中,由 Controller 节点(通过选举产生)统一管理。所有 Broker 作为 Raft 协议的 Follower,实时复制 Controller 的元数据日志,确保强一致性。整个通信协调机制本质上是事件驱动模型(Metadata as an Event Log),Leader 通过 KRaft 生产权威事件,Follower 和 Broker 通过监听 KRaft 来获得这些事件并顺序处理,达到集群状态的最终一致。
迁移提醒 :从 ZooKeeper 模式迁移到 Kafka 4.0 的 KRaft 模式并非简单的版本升级,而是一次完整的架构迁移 。不存在从旧版 ZooKeeper 模式直接升级到 Kafka 4.0 KRaft 模式的支持路径。通常需要先升级到 Kafka 3.9(作为桥接版本),完成元数据迁移后再升级到 4.0。
三、消息存储机制
3.1 存储架构
Kafka 的存储架构以分区(Partition)为基本单位,每个分区在物理上对应一个日志(Log),而日志又由多个日志段(LogSegment)组成。这种分段存储设计便于数据滚动清理和压缩,同时显著提高了并发读写能力。
Kafka 的设计大量依赖文件系统来存储和缓存消息,充分利用了操作系统提供的读写优化。
3.2 日志段(LogSegment)
每个 LogSegment 包含多个核心文件:
| 文件类型 | 后缀 | 说明 |
|---|---|---|
| 日志文件 | .log |
存储实际的消息数据,包括消息体、偏移量、时间戳、Key 等 |
| 偏移量索引文件 | .index |
存储消息偏移量与物理位置的映射(稀疏索引) |
| 时间戳索引文件 | .timeindex |
存储消息时间戳与偏移量的映射 |
| 快照文件 | .snapshot |
幂等生产者的事务状态快照(Kafka 0.11+) |
日志文件命名基于基础偏移量(Base Offset),例如 00000000000000000000.log。
3.3 索引文件详解
Kafka 的索引是稀疏索引,并非每条消息都建立索引。这大幅减少了索引文件的大小,同时保持了高效的查找能力。
偏移量索引文件(.index) :每个条目为 <relativeOffset, position>,relativeOffset 是相对于 Base Offset 的差值,position 是消息在 .log 文件中的物理位置。
时间戳索引文件(.timeindex) :每个条目为 <timestamp, relativeOffset>,用于按时间戳快速定位消息。
查找过程:
-
根据目标 Offset,二分查找定位到对应的 Segment 文件
-
在该 Segment 的
.index文件中二分查找小于等于目标 Offset 的最大索引条目 -
从索引指定的物理位置开始顺序扫描
.log文件,直到找到目标消息
通过索引文件,Kafka 能够将随机读取转化为近似顺序的磁盘访问,极大降低延迟。
3.4 存储特点
-
顺序写入:消息以追加方式写入当前活跃的日志段,充分利用磁盘顺序写性能优势(顺序写可达 600MB/s,而随机写仅约 100KB/s,差距超过 6000 倍)
-
分段滚动 :默认每个 Segment 大小 1GB(
log.segment.bytes),达到后滚动创建新 Segment -
高效删除 :基于时间(
log.retention.hours)或大小(log.retention.bytes)删除过期 Segment,而非逐条删除消息 -
消息保留:Kafka 保留所有已发布消息一定时间(可配置),无论是否已被消费
3.5 日志清理策略
Kafka 支持两种日志清理策略:
| 策略 | 配置值 | 说明 | 适用场景 |
|---|---|---|---|
| 删除(Delete) | delete |
超时后直接删除 Segment | 日志收集、事件流 |
| 压缩(Compact) | compact |
保留每个 Key 的最新值 | 状态存储、CDC |
3.6 日志压缩原理(Log Compaction)
当日志清理策略设置为 compact 时:
-
后台清理线程扫描日志,识别具有相同 Key 的消息
-
仅保留每个 Key 的最新消息,删除旧版本
-
保证每个 Key 至少有一条消息
-
用于实现 Key-Value 存储语义、KTable 状态存储等
四、高可用与副本机制
4.1 副本机制
Kafka 通过多副本冗余存储实现数据高可用性,每个 Partition 有一个 Leader 副本和多个 Follower 副本。Leader 处理所有读写请求,Follower 仅被动地从 Leader 拉取消息进行同步。每个 Broker 同时作为某些分区的 Leader 和另一些分区的 Follower,实现负载均衡。
4.2 核心概念:AR / ISR / OSR
-
AR(Assigned Replicas) :为分区分配的所有副本的集合
-
ISR(In-Sync Replicas) :与 Leader 副本保持同步的副本集合,ISR 中的成员才有资格参与 Leader 选举
-
OSR(Out-of-Sync Replicas) :落后较多或长时间未响应的副本
4.3 ISR 动态维护机制
Kafka 通过配置参数 replica.lag.time.max.ms(默认 30 秒)动态维护 ISR:
-
Follower 在指定时间内未发送 fetch 请求或延迟过高 → 移出 ISR
-
延迟恢复后 → 重新加入 ISR
4.4 HW(High Watermark)与 LEO(Log End Offset)
| 概念 | 说明 |
|---|---|
| LEO | 日志末端位移,记录每个副本日志的最新位置 |
| HW | 高水位线,标识所有 ISR 副本均已持久化的最新消息位移 |
-
消费者只能读取 HW 之前的消息(已提交消息)
-
HW 之后的消息虽已写入 Leader 但未被所有 ISR 确认,处于"未提交"状态
-
HW 的更新遵循木桶原理------由 ISR 中进度最慢的副本决定
HW 与 LEO 的更新流程:
-
Producer 发送消息到 Leader
-
Leader 写入本地日志,更新 LEO
-
Follower 从 Leader 拉取消息,更新本地 LEO
-
Leader 收到 Follower 的 fetch 请求后,根据所有副本的 LEO 计算并更新 HW
-
Follower 下次 fetch 时获取最新的 HW 并更新本地 HW
4.5 Leader 选举
当 Leader 故障时,Kafka 从 ISR 中选择新的 Leader,确保数据一致性。选举过程由 Controller 负责协调。
选举策略:
-
首选副本选举(Preferred Replica Election):优先选择 AR 列表中第一个副本作为新 Leader
-
ISR 优先选举:优先选择 ISR 中的副本作为新 Leader
-
禁止脏选举 :
unclean.leader.election.enable控制是否允许 OSR 中的副本成为 Leader。设为false可防止数据丢失,但可能牺牲可用性
数学原理:假设共有 2f + 1 个 Replica,commit 之前必须保证有 f + 1 个 Replica 复制完消息。为了保证能正确选出新 Leader,fail 的 Replica 不能超过 f 个。
4.6 ACK 机制
生产者通过 acks 参数控制消息确认策略:
| acks 值 | 含义 | 吞吐量 | 可靠性 |
|---|---|---|---|
0 |
不等待确认,立即返回 | 最高 | 可能丢消息 |
1 |
Leader 写入成功即确认 | 中 | 可能丢消息(Leader 宕机且未同步到 Follower) |
all 或 -1 |
等待所有 ISR 确认 | 较低 | 最高 |
4.7 可靠性配置黄金组合
推荐生产环境配置:
replication.factor = 3 # 副本总数
min.insync.replicas = 2 # 最小同步副本数
acks = all # 确认级别
unclean.leader.election.enable = false # 禁止脏选举推荐关系:replication.factor = min.insync.replicas + 1,保证在单副本故障时仍满足最小同步副本数。
五、高性能设计原理
5.1 顺序读写
Kafka 将消息追加到日志文件末尾,不做随机写。顺序读写充分发挥现代硬盘的优势,机械硬盘顺序写可达 600MB/s,而随机写仅有约 100KB/s。现代操作系统的预读(read-ahead)和后写(write-behind)技术进一步优化了顺序读写性能。
5.2 Page Cache(页缓存)
Page Cache 是操作系统提供的内存管理机制,Kafka 充分利用了这一特性:
-
写消息:消息先写入 Page Cache,由操作系统异步刷盘。这种设计使得 Kafka 能访问所有空闲内存作为缓存(32GB 机器上可达 28-30GB 可用缓存),且比在 JVM 堆内维护缓存更高效。
-
读消息:消息直接从 Page Cache 转入 Socket 发送。当消费者基本跟上了生产速度时,所有数据都可以直接从 Page Cache 提供服务,磁盘上完全看不到读 I/O 活动。
-
性能优势:大幅减少对磁盘的直接读写,使 Kafka 能够在高并发场景下保持低延迟和高吞吐量。
5.3 零拷贝(Zero-Copy)
Kafka 使用 sendfile 系统调用实现零拷贝,将数据直接从 Page Cache 发送到网络:
-
传统方式(4 次拷贝,2 次 CPU 拷贝) :
-
磁盘 → 内核缓冲区(DMA 拷贝)
-
内核缓冲区 → 用户空间(CPU 拷贝)
-
用户空间 → 内核 Socket 缓冲区(CPU 拷贝)
-
Socket 缓冲区 → 网络(DMA 拷贝)
-
-
零拷贝方式(2 次拷贝,0 次 CPU 拷贝) :
-
磁盘 → 内核缓冲区(DMA 拷贝)
-
内核缓冲区 → 网络(DMA 拷贝)
-
多消费者场景的优势:如果有 5 个消费者,传统方式需要 4×5=20 次复制,零拷贝方式只需 1+5=6 次(1 次磁盘到 Page Cache,5 次消费者各自读取 Page Cache)。
零拷贝避免了数据在用户空间和内核空间之间的冗余拷贝,显著降低 CPU 开销和传输延迟。
5.4 批量处理
Kafka 支持端到端批量处理:
-
生产端 :
batch.size和linger.ms控制批量发送。Kafka 4.0 将linger.ms默认值从 0ms 调整为 5ms,通过引入微小的"人工延迟"换取更高的批处理效率,实际延迟不升反降。 -
消费端 :
fetch.min.bytes和fetch.max.wait.ms控制批量拉取 -
压缩:支持 GZIP、Snappy、LZ4、Zstandard 等压缩算法。批处理 + 压缩可大幅减少网络传输量
5.5 分区并行
Topic 分为多个 Partition,分布在多个 Broker 上,实现并行处理和水平扩展。每个分区在 Broker 层面实现文件顺序写,多个分区可同时写入不同磁盘目录,充分发挥多磁盘的 I/O 性能。
注意 :Kafka 在消息写入时的 I/O 性能会随着 Topic 和分区数量的增长先上升后下降,需要警惕过度的分区数量。
5.6 压缩算法对比
| 算法 | 吞吐量 | 压缩比 | CPU 占用 | 适用场景 |
|---|---|---|---|---|
| LZ4 | 最高 | 中等 | 中等 | 高 TPS,推荐首选 |
| Snappy | 高 | 低 | 高 | 低延迟场景 |
| Zstd | 中 | 最高 | 低 | 低带宽,追求高压缩比 |
| GZIP | 低 | 中等 | 高 | 一般不建议使用 |
六、Kafka 4.0 / 4.1 关键新特性
6.1 版本演进概览
| 版本 | 关键变化 |
|---|---|
| Kafka 3.0 | 引入 KRaft 实验模式、默认开启幂等性、弃用 Java 8 |
| Kafka 3.3 | KRaft 生产就绪 |
| Kafka 3.9 | 桥接版本,提供 ZooKeeper → KRaft 迁移工具 |
| Kafka 4.0 | KRaft 成为默认且唯一模式、KIP-848 消费者重平衡协议、KIP-932 队列预览 |
| Kafka 4.1 | 18 个 KIP 落地,KIP-1071 Streams 重平衡协议(EA)、强化 KIP-848 |
6.2 KRaft 模式(KIP-500)
Kafka 4.0 默认启用 KRaft 模式,完全摒弃 ZooKeeper 依赖:
-
元数据存储于 Kafka 内部
__cluster_metadata主题 -
基于 Raft 共识算法进行元数据复制和 Leader 选举
-
简化部署架构,无需维护 ZooKeeper 集群
-
支持百万级分区数量
-
Controller 切换时间从分钟级优化至秒级
6.3 新一代消费者重平衡协议(KIP-848)
KIP-848 是 Kafka 4.0 的又一重大革新:
传统协议痛点:
-
依赖"胖客户端",协议 Bug 修复需要客户端升级
-
全局同步屏障(Stop-the-World),单个问题消费者可拖垮整个组
-
Rebalance 期间消费暂停,消息积压
新协议特点:
-
完全增量式/异步协议:不再依赖全局同步屏障
-
协调逻辑从客户端移至 Broker:服务端驱动的协调机制
-
Rebalance 时间显著缩短,消费者组扩展性大幅提升
-
服务端默认启用,消费者端需设置
group.protocol=consumer -
新协议组称为 Consumer groups ,旧协议组称为 Classic groups
-
支持平滑在线升级和降级
KIP-848 的核心机制:消费者通过心跳机制声明订阅并确认分区分配,由 Broker 侧的 Group Coordinator 作为中央智能体,维护组成员关系、监控主题元数据、计算目标分配方案。
6.4 Kafka 队列(KIP-932)
KIP-932 引入 Share Groups(共享组) ,为 Kafka 原生添加了队列语义:
核心特点:
-
允许消费者数量 超过 分区数量
-
基于消息可用性进行"协作消费",不受分区-消费者 1:1 映射的限制
-
支持单条消息确认(per-message acknowledgment)和重试
典型使用场景:
-
峰值流量扩展:在高峰期临时增加消费者数量(消费者数 > 分区数)
-
慢消费者加速:使用消费者池并行处理每条消息,降低端到端延迟
队列模型对比:
-
传统消费者组:多个队列(每个分区一个),每个队列一个专用消费者处理,保证分区内有序
-
共享组:单一队列,多个消费者池化处理,不保证顺序,适用于事件可并行处理的场景
6.5 Java 版本要求
Kafka 4.0 更新了 Java 最低要求:
-
Kafka Clients / Kafka Streams:Java 11
-
Kafka Brokers / Connect / Tools:Java 17
6.6 其他重要 KIP
-
KIP-1071(Streams Rebalance Protocol) :基于 KIP-848 的创新,专门为 Kafka Streams 应用设计的 Broker 驱动重平衡系统,与传统的消费者组协议分离
-
KIP-1114(Partition Chunk) :引入分区数据分块存储能力,允许一个分区的数据分散存储在多个 Broker 上
七、集群搭建与配置
7.1 环境准备
-
操作系统:Linux(CentOS 7+、Ubuntu 等),推荐 64 位
-
JDK:Kafka 4.0 要求 Java 17(Broker 端),Clients 需要 Java 11
-
硬件建议 :优先使用 SSD,推荐多块 SSD 组成 RAID 0 或配置多个
log.dirs
7.2 核心配置文件
server.properties 核心配置(ZooKeeper 模式,Kafka 3.x) :
properties
broker.id=0 # 集群内唯一 ID
listeners=PLAINTEXT://0.0.0.0:9092 # 监听地址和端口
advertised.listeners=PLAINTEXT://public-ip:9092 # 对外公布地址
log.dirs=/data/kafka1,/data/kafka2 # 多磁盘提升 I/O 性能
num.partitions=3 # 默认分区数
default.replication.factor=3 # 默认副本因子
num.network.threads=3 # 网络线程数,建议设为 CPU 核数
num.io.threads=8 # I/O 线程数,默认 8
log.segment.bytes=1073741824 # Segment 大小(1GB)
log.retention.hours=168 # 数据保留 7 天
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181 # ZooKeeper 地址server.properties 核心配置(KRaft 模式,Kafka 4.0+) :
properties
process.roles=broker,controller # 节点角色(broker / controller / broker,controller)
node.id=1 # 集群内唯一节点 ID
controller.quorum.voters=1@node1:9093,2@node2:9093,3@node3:9093 # 法定人数投票者
controller.listener.names=CONTROLLER # Controller 监听器名称
listeners=PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093
advertised.listeners=PLAINTEXT://public-ip:9092
log.dirs=/data/kafka7.3 常用运维命令
bash
# ========== KRaft 模式:格式化存储目录 ==========
kafka-storage.sh format -t <uuid> -c config/server.properties
# ========== Topic 管理 ==========
# 创建 Topic
kafka-topics.sh --bootstrap-server localhost:9092 \
--create --topic my-topic --partitions 10 --replication-factor 3
# 查看 Topic 详情
kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic my-topic
# 修改分区数(只能增加,不能减少)
kafka-topics.sh --bootstrap-server localhost:9092 \
--alter --topic my-topic --partitions 20
# 删除 Topic
kafka-topics.sh --bootstrap-server localhost:9092 \
--delete --topic my-topic
# 查看所有 Topic 列表
kafka-topics.sh --bootstrap-server localhost:9092 --list
# ========== 生产者测试 ==========
kafka-console-producer.sh --bootstrap-server localhost:9092 \
--topic my-topic \
--property "parse.key=true" \
--property "key.separator=:"
# ========== 消费者测试 ==========
kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic my-topic --from-beginning \
--group my-group \
--property print.key=true \
--property key.separator="-"
# ========== 消费者组管理 ==========
# 查看所有消费者组
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
# 查看消费者组详情(Lag 监控)
kafka-consumer-groups.sh --bootstrap-server localhost:9092 \
--group my-group --describe
# 重置消费者组 Offset
kafka-consumer-groups.sh --bootstrap-server localhost:9092 \
--group my-group --reset-offsets --to-earliest \
--topic my-topic --execute
# ========== 分区重分配 ==========
kafka-reassign-partitions.sh --bootstrap-server localhost:9092 \
--reassignment-json-file reassign.json --execute
# ========== 性能压测 ==========
# 生产者压测
kafka-producer-perf-test.sh \
--topic test --num-records 10000000 \
--record-size 100 --throughput -1 \
--producer-props bootstrap.servers=localhost:9092 acks=all
# 消费者压测
kafka-consumer-perf-test.sh \
--bootstrap-server localhost:9092 \
--topic test --messages 10000000八、生产者与消费者编程
8.1 生产者核心配置
| 参数 | 说明 | 默认值 | 建议值 |
|---|---|---|---|
acks |
确认机制 | 1(3.0+默认 all) | all(高可靠) |
batch.size |
批量发送大小(字节) | 16384 | 32768-131072 |
linger.ms |
批量等待时间 | 0(4.0 改为 5) | 5-100 |
compression.type |
压缩算法 | none | lz4 |
max.in.flight.requests.per.connection |
在途请求数 | 5 | 5(幂等时),1(严格保序) |
enable.idempotence |
幂等性 | false(3.0+ true) | true |
retries |
重试次数 | 2147483647(4.0) | Integer.MAX_VALUE |
buffer.memory |
缓冲区大小 | 33554432(32MB) | 64-128MB |
max.request.size |
单次请求最大大小 | 1MB | 根据业务调整,需 ≤ Broker 的 message.max.bytes |
delivery.timeout.ms |
发送超时总时间 | 120000(2 分钟) | 根据网络调整 |
8.2 消费者核心配置
| 参数 | 说明 | 默认值 | 建议值 |
|---|---|---|---|
group.id |
消费者组 ID | null | 必填 |
enable.auto.commit |
自动提交 Offset | true | false(推荐手动) |
auto.offset.reset |
无 Offset 时行为 | latest | earliest / latest |
max.poll.records |
单次拉取最大消息数 | 500 | 根据处理速度调整 |
max.poll.interval.ms |
两次 poll 最大间隔 | 300000(5 分钟) | 根据最长处理时间调整 |
session.timeout.ms |
会话超时 | 45000 | 45000-60000 |
heartbeat.interval.ms |
心跳间隔 | 3000 | session.timeout.ms/3 |
fetch.min.bytes |
最小拉取字节数 | 1 | 1024-10240 |
fetch.max.wait.ms |
最大拉取等待时间 | 500 | 500-1000 |
isolation.level |
事务隔离级别 | read_uncommitted | read_committed(使用事务时) |
partition.assignment.strategy |
分区分配策略 | RangeAssignor | CooperativeStickyAssignor |
group.protocol |
组协议(4.0+) | classic | consumer(启用 KIP-848) |
8.3 幂等生产者原理
Kafka 的幂等生产者(Idempotent Producer)通过以下机制防止消息重复:
-
每个生产者实例被分配一个唯一的 Producer ID(PID)
-
生产者对发送到每个分区的每条消息分配一个单调递增的序列号(Sequence Number)
-
Broker 维护每个 PID 对每个分区最后接受的序列号
-
如果收到序列号已写入过的消息,Broker 丢弃该消息并返回成功响应
配置:
properties
enable.idempotence=true
acks=all # 幂等性必须配合 acks=all
max.in.flight.requests.per.connection=5 # 最大 5
retries=2147483647 # 无限重试8.4 Kafka 事务
事务使"读取-处理-写入"模式中的消息消费和生产成为原子操作,实现端到端的精确一次语义。
关键概念:
-
Transactional Producer :带有
transactional.id的生产者 -
Transaction Coordinator:管理事务状态的 Broker 组件
-
Control Batch:包含事务提交或中止标记的特殊消息
配置:
properties
transactional.id=my-transactional-id # 唯一事务 ID
enable.idempotence=true
acks=all使用流程:
-
producer.initTransactions() -
producer.beginTransaction() -
发送消息
-
producer.commitTransaction()或producer.abortTransaction()
消费者端配置:
properties
isolation.level=read_committed # 只读已提交的事务消息8.5 生产者代码示例(Java,含幂等和事务)
java
// ========== 幂等生产者 ==========
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("acks", "all");
props.put("enable.idempotence", true);
props.put("max.in.flight.requests.per.connection", 5);
props.put("retries", Integer.MAX_VALUE);
props.put("compression.type", "lz4");
props.put("batch.size", 32768);
props.put("linger.ms", 5);
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("my-topic", "key", "value");
producer.send(record, (metadata, exception) -> {
if (exception != null) {
// 发送失败,记录日志或写入补偿队列
System.err.println("Send failed: " + exception.getMessage());
} else {
System.out.printf("Sent to partition %d, offset %d%n",
metadata.partition(), metadata.offset());
}
});
producer.close();
// ========== 事务生产者 ==========
Properties txProps = new Properties();
txProps.put("bootstrap.servers", "localhost:9092");
txProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
txProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
txProps.put("transactional.id", "my-transactional-id");
txProps.put("enable.idempotence", true);
txProps.put("acks", "all");
KafkaProducer<String, String> txProducer = new KafkaProducer<>(txProps);
txProducer.initTransactions();
try {
txProducer.beginTransaction();
txProducer.send(new ProducerRecord<>("topic-A", "key", "value"));
txProducer.send(new ProducerRecord<>("topic-B", "key", "value"));
txProducer.commitTransaction();
} catch (Exception e) {
txProducer.abortTransaction();
e.printStackTrace();
}
txProducer.close();8.6 消费者代码示例(Java,含手动提交)
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "my-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("enable.auto.commit", "false"); // 手动提交
props.put("auto.offset.reset", "earliest");
props.put("max.poll.records", 500);
props.put("max.poll.interval.ms", 300000);
props.put("isolation.level", "read_committed"); // 读取已提交的事务消息
// Kafka 4.0+ 启用新一代重平衡协议
props.put("group.protocol", "consumer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n",
record.offset(), record.key(), record.value());
// 业务处理逻辑
}
// 同步提交(确保提交成功)
consumer.commitSync();
// 或异步提交(更高性能)
// consumer.commitAsync((offsets, exception) -> {
// if (exception != null) {
// System.err.println("Commit failed: " + exception.getMessage());
// }
// });
}
} catch (WakeupException e) {
// 优雅关闭
} finally {
// 关闭前最后提交一次
consumer.commitSync();
consumer.close();
}九、性能调优最佳实践
9.1 性能优化总览
Kafka 集群配置本质上是在吞吐量、延迟、容错和可扩展性之间做有意的权衡。每个配置选择都会影响系统的稳定性和效率。
9.2 生产者调优
| 优化方向 | 参数 | 调优建议 |
|---|---|---|
| 批量发送 | batch.size |
增大至 32KB-128KB,减少网络请求次数 |
| 批量等待 | linger.ms |
5-100ms,Kafka 4.0 默认为 5ms,用微小延迟换取更高批处理效率 |
| 压缩 | compression.type |
启用 LZ4 压缩,平衡吞吐和压缩比 |
| 缓冲区 | buffer.memory |
增大至 64-128MB,应对突发流量 |
| 幂等性 | enable.idempotence |
开启,防止重试导致的重复 |
| 重试 | retries |
设为最大值,配合幂等性使用 |
| 连接复用 | connections.max.idle.ms |
适当增大,避免频繁建立连接 |
生产者触发发送的"Whichever happens first"原则 :当累积数据量达到 batch.size 时立即发送;如果数据量不足,则等待 linger.ms 时间后再发送。
9.3 Broker 调优
| 优化方向 | 参数 | 调优建议 |
|---|---|---|
| 网络线程 | num.network.threads |
建议设为 CPU 核数,默认 3 |
| I/O 线程 | num.io.threads |
根据 CPU 核数和磁盘带宽调整,默认 8 |
| 多磁盘 | log.dirs |
配置多个磁盘路径提升 I/O 并行度 |
| 日志刷新 | log.flush.interval.messages |
默认依赖 Page Cache 异步刷盘,追求高可靠可调小 |
| Socket 缓冲区 | socket.send.buffer.bytes |
增大至 1MB 以上 |
| 副本拉取 | replica.fetch.max.bytes |
适当增大,加快副本同步 |
| 日志段 | log.segment.bytes |
1GB(默认),根据磁盘情况调整 |
9.4 消费者调优
| 优化方向 | 参数 | 调优建议 |
|---|---|---|
| 批量拉取 | max.poll.records |
处理慢时调小,处理快时调大 |
| 批量大小 | fetch.min.bytes |
增加最小拉取字节数减少网络请求 |
| 等待时间 | fetch.max.wait.ms |
500-1000ms |
| 手动提交 | enable.auto.commit |
设为 false,精确控制 Offset 提交 |
| 超时配置 | max.poll.interval.ms |
确保大于最长消息处理时间 |
| 分配策略 | partition.assignment.strategy |
使用 CooperativeStickyAssignor |
9.5 操作系统调优
| 优化方向 | 调优建议 |
|---|---|
| Page Cache | 预留 70% 以上内存给 Page Cache,避免频繁磁盘 I/O |
| 文件系统 | 推荐 XFS 或 ext4,支持大文件和高并发 |
| 挂载选项 | 使用 noatime 挂载选项,减少元数据更新开销 |
| 磁盘 | SSD 优于 HDD,多块磁盘做 RAID 0 或配置多个 log.dirs |
| 网络 | 万兆网卡,调整 TCP 缓冲区大小(net.core.rmem_max、net.core.wmem_max) |
| 文件描述符 | 增大 ulimit -n,建议 100000+ |
| JVM 调优 | 使用 G1GC,堆大小 4-8GB,减少 GC 暂停影响 |
9.6 压缩算法选择
| 算法 | 吞吐量 | 压缩比 | CPU 占用 | 网络占用 | 推荐场景 |
|---|---|---|---|---|---|
| LZ4 | 最高 | 中 | 中 | 中 | 高 TPS,推荐首选 |
| Snappy | 高 | 低 | 高 | 高 | 对 CPU 不敏感的场景 |
| Zstd | 中 | 高 | 低 | 低 | 低带宽,追求高压缩比 |
| GZIP | 低 | 中 | 高 | 低 | 不推荐 |
十、常见问题与故障排查
10.1 消息积压
原因分析:
-
消费者处理能力不足
-
Rebalance 导致消费暂停
-
分区数少于消费者数(部分消费者闲置)
-
下游依赖服务响应慢
解决方案:
-
增加消费者数量(不超过分区数)
-
优化消费者业务处理逻辑(异步化、批量化)
-
增加分区数(需评估 Topic 和分区数量对 I/O 的影响)
-
调优 Rebalance 相关超时参数
-
使用 Kafka 4.0 的 Share Groups 突破消费者 ≤ 分区数的限制
10.2 消息丢失
生产端可能原因:
-
acks=0或acks=1时 Leader 故障 -
发送时未处理异常(发后即忘)
-
max.request.size超过 Broker 的message.max.bytes被拒绝
Broker 端可能原因:
-
replication.factor=1时单点故障 -
min.insync.replicas=1时副本不足 -
unclean.leader.election.enable=true导致脏选举时数据截断 -
异步刷盘 + 断电
消费端可能原因:
-
自动提交 Offset,处理失败时已提交导致无法重放
-
先提交后处理,处理失败时消息丢失
解决方案汇总:
properties
# 生产端
acks=all
enable.idempotence=true
retries=Integer.MAX_VALUE
delivery.timeout.ms=120000
# Broker 端
replication.factor=3
min.insync.replicas=2
unclean.leader.election.enable=false
# 消费端
enable.auto.commit=false # 手动提交
# 处理完成后调用 consumer.commitSync()10.3 消息重复消费
原因分析:
-
消费者处理完消息但 Offset 提交失败
-
Rebalance 导致分区重新分配,未提交的 Offset 被重复消费
-
生产者重试机制(未开启幂等性时)
解决方案:
-
消费端实现幂等处理:使用唯一 ID(如数据库主键、Redis Set)去重
-
使用 Kafka 事务:实现精确一次语义
-
生产者开启幂等性 :
enable.idempotence=true -
合理配置重平衡参数:使用 CooperativeStickyAssignor 减少重平衡影响
10.4 分区倾斜(Partition Skew)
原因分析:
-
消息 Key 分布不均(热点 Key)
-
自定义分区策略不合理
-
扩容后新增 Broker 未分配分区
解决方案:
-
优化分区 Key 设计,避免使用单一热点 Key
-
增加分区数量,分散负载
-
使用
kafka-reassign-partitions.sh重新分配分区 -
监控分区级别的生产和消费速率
-
考虑无 Key 消息 + 轮询策略
10.5 Rebalance 问题
Rebalance 是消费者组内分区与消费者的重新分配过程,触发条件包括:
| 触发场景 | 说明 |
|---|---|
| 消费者数量变化 | 扩容、下线、宕机、网络断连 |
| Topic 分区数增加 | 消费者组需感知新分区 |
| 订阅的 Topic 变化 | 修改订阅列表 |
| 心跳超时 | 超过 session.timeout.ms 未发送心跳 |
| 消费超时 | 处理单批消息超过 max.poll.interval.ms |
Rebalance 的危害:
-
消费暂停,消息积压
-
消息重复或丢失(Offset 未及时提交)
-
下游服务响应中断
优化方案:
properties
# 经典协议优化
session.timeout.ms=45000
max.poll.interval.ms=300000
heartbeat.interval.ms=3000
partition.assignment.strategy=org.apache.kafka.clients.consumer.CooperativeStickyAssignor
enable.auto.commit=false
# Kafka 4.0+ 启用新一代协议
group.protocol=consumer新一代协议优势:
-
无全局同步屏障(No stop-the-world)
-
Rebalance 期间消费者可继续 fetch 和 commit
-
协调逻辑从客户端移至服务端
10.6 排查清单
| 问题 | 排查命令/指标 |
|---|---|
| 消息积压 | kafka-consumer-groups.sh --describe 查看 LAG |
| 副本不同步 | 监控 UnderReplicatedPartitions 指标 |
| ISR 收缩 | 检查 replica.lag.time.max.ms 和网络延迟 |
| 磁盘 I/O | iostat、iotop |
| 网络延迟 | netstat、ping |
| JVM GC | jstat、GC 日志 |
十一、监控与运维工具
11.1 常用监控工具
| 工具 | 类型 | 特点 |
|---|---|---|
| CMAK(Kafka Manager) | 开源 | 集群健康检查、配置管理、分区重分配 |
| Burrow | 开源 | 专注消费者 Lag 监控,无需设置阈值,支持 HTTP 告警 |
| Kafdrop | 开源 | 轻量级 Web 界面,查看 Topic 详情、消息内容 |
| Cruise Control | 开源 | 自动化分区再平衡、资源监控 |
| Confluent Control Center | 商业 | 集中化监控、告警、性能优化 |
| Prometheus + Grafana | 开源 | 通过 JMX Exporter 采集指标,自定义仪表盘 |
| Kafka Lag Exporter | 开源 | 将 Lag 指标导出到 Prometheus |
11.2 关键监控指标
Broker 指标:
| 指标 | 说明 | 告警阈值建议 |
|---|---|---|
BytesInPerSec / BytesOutPerSec |
网络吞吐量 | 根据带宽设定 |
MessagesInPerSec |
消息写入速率 | 趋势监控 |
RequestHandlerAvgIdlePercent |
请求处理线程空闲率 | < 0.3 需关注 |
UnderReplicatedPartitions |
副本不足的分区数 | > 0 告警 |
ActiveControllerCount |
活跃 Controller 数量 | 必须为 1 |
OfflinePartitionsCount |
离线分区数 | > 0 严重告警 |
UncleanLeaderElectionsPerSec |
脏选举速率 | > 0 告警 |
消费者指标:
| 指标 | 说明 |
|---|---|
records-lag-max |
最大消费延迟 |
records-consumed-rate |
消费速率 |
records-lead |
领先量(已生产未消费) |
commit-latency-avg |
提交延迟平均值 |
操作系统指标:
| 指标 | 说明 |
|---|---|
| CPU 使用率 | broker_cpu_usage |
| 内存使用率 | broker_memory_usage |
| 磁盘使用率 | broker_disk_usage |
| 磁盘 I/O 等待 | iowait |
11.3 JMX 监控配置
bash
# 启用 JMX
export JMX_PORT=9999
export KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote \
-Dcom.sun.management.jmxremote.port=9999 \
-Dcom.sun.management.jmxremote.authenticate=false \
-Dcom.sun.management.jmxremote.ssl=false"
# 启动 Kafka 时指定 JMX
./kafka-server-start.sh -daemon ../config/server.properties11.4 压测工具
bash
# 生产者压测
kafka-producer-perf-test.sh \
--topic test \
--num-records 10000000 \
--record-size 100 \
--throughput -1 \
--producer-props bootstrap.servers=localhost:9092 \
acks=all batch.size=32768 linger.ms=5 compression.type=lz4
# 输出示例:
# 10000000 records sent, 125000.123456 records/sec (11.92 MB/sec)
# 消费者压测
kafka-consumer-perf-test.sh \
--bootstrap-server localhost:9092 \
--topic test \
--messages 10000000 \
--threads 10 \
--group perf-test-group
# 端到端压测(生产 + 消费)
kafka-verifiable-producer.sh --bootstrap-server localhost:9092 \
--topic test --max-messages 10000000
kafka-verifiable-consumer.sh --bootstrap-server localhost:9092 \
--topic test --group-id test-group --max-messages 10000000十二、总结与推荐学习路径
12.1 核心要点回顾
| 维度 | 核心设计 | 关键技术 |
|---|---|---|
| 架构 | Topic → Partition → Segment 分层存储 | 水平扩展,百万级分区 |
| 高性能 | 顺序读写 + Page Cache + 零拷贝 + 批量处理 | sendfile,LZ4 压缩 |
| 高可用 | 副本机制 + ISR + HW + Leader 选举 | 3 副本 + min.insync.replicas=2 |
| 可靠性 | ACK 机制 + 幂等生产者 + 事务 | acks=all + 事务实现精确一次 |
| 演进方向 | KRaft 替代 ZooKeeper | Kafka 4.0 默认 KRaft,移除 ZK |
| 新特性 | KIP-848 + KIP-932 + KIP-1114 | 新一代重平衡协议、共享组、分区分块 |
12.2 可靠性配置黄金清单
properties
# 生产端
acks=all
enable.idempotence=true
retries=Integer.MAX_VALUE
compression.type=lz4
# Broker 端
replication.factor=3
min.insync.replicas=2
unclean.leader.election.enable=false
# 消费端
enable.auto.commit=false
isolation.level=read_committed # 使用事务时
group.protocol=consumer # Kafka 4.0+12.3 学习建议
-
入门(1-2 周) :掌握核心概念(Topic、Partition、Broker、Consumer Group),动手搭建单机集群
-
进阶(1-2 月) :深入理解存储机制(Segment、索引)、副本同步(ISR、HW、LEO)、性能优化原理(零拷贝、Page Cache)
-
实践(1-2 月) :搭建生产级集群、编写生产者消费者代码、进行压测和调优
-
深入(持续) :阅读源码,理解底层实现(LogSegment、ReplicaManager、GroupCoordinator);关注 KIP 提案了解演进方向
-
生产(持续) :掌握监控运维、故障排查、容量规划、版本升级策略
面试题
Kafka 中的消息由哪些部分组成?
ProducerRecord(生产者发送的消息)
生产者构造一条待发送的消息时,使用 ProducerRecord 对象,包含以下字段:
| 字段 | 是否必填 | 说明 |
|---|---|---|
| Topic | ✅ 必填 | 消息要发往的主题名称 |
| Value | 可选 | 消息的实际业务数据(字节数组),可为 null |
| Key | 可选 | 消息的键,用于分区路由(相同 Key 进入同一分区),可为 null |
| Partition | 可选 | 显式指定目标分区号,不填则由分区器决定 |
| Timestamp | 可选 | 消息的时间戳,不填则使用生产者当前时间 |
| Headers | 可选 | 消息头部,一组键值对,用于传递附加元数据 |
ConsumerRecord(消费者读取的消息)
消费者从 Kafka 拉取消息时,返回的是 ConsumerRecord 对象,它包含了比生产者发送时更多的信息------这些额外信息是 Broker 在处理过程中添加的。
| 字段 | 说明 |
|---|---|
| topic | 消息所属的主题 |
| partition | 消息所在的分区编号 |
| offset | 消息在分区内的唯一偏移量(由 Broker 分配) |
| timestamp | 消息的时间戳 |
| timestampType | 时间戳类型:CreateTime(生产者指定)或 LogAppendTime(Broker 写入时) |
| key | 消息的键 |
| value | 消息的值 |
| headers | 消息头部信息 |
什么是Kafka的主题(Topic)?它的作用是什么?
Topic(主题)是 Kafka 中消息的逻辑分类和命名容器。Topic 本身不存储任何数据,它是一个逻辑概念,数据实际存储在 Partition 中。生产者向指定Topic发送消息,消费者订阅Topic消费消息,实现消息的分类隔离。
Topic的分区(Partition)是什么?为什么要分区?
分区的定义:
Partition(分区)是 Kafka 中物理存储和并行处理的基本单元。
从不同视角理解分区:
| 视角 | 理解 |
|---|---|
| 逻辑视角 | Topic 的一个有序子集,是一个只追加(append-only)的、不可变的消息序列。 |
| 物理视角 | Broker 磁盘上的一个独立目录 ,包含多个日志段文件(.log、.index、.timeindex)。 |
| 并发视角 | 消费者组内最小的并行消费单元,同一分区同一时刻只能被组内一个消费者消费。 |
| 容错视角 | 副本机制的基本粒度,每个分区可以独立配置多个副本(Leader + Follower)。 |
一个 Topic 由多个 Partition 组成:
Topic: order-events
│
├── Partition 0: [msg0, msg1, msg2, msg3, ...] (Leader: Broker 1)
├── Partition 1: [msg0, msg1, msg2, msg3, ...] (Leader: Broker 2)
└── Partition 2: [msg0, msg1, msg2, msg3, ...] (Leader: Broker 3)每个分区内的消息从 0 开始被分配一个单调递增的 Offset,Offset 唯一标识该消息在分区内的位置。
为什么要分区?------ 分区的四大核心价值
Kafka 引入分区的根本目的是突破单机物理极限,实现水平扩展。
2.1 水平扩展写入吞吐量
单台 Broker 的写入能力受限于:
-
磁盘顺序写带宽(HDD 约 50~100 MB/s,SSD 更高)
-
网络带宽
分区如何解决?
-
多个分区可以分布在不同的 Broker 上。
-
生产者可以并发向不同分区的 Leader 写入。
-
集群总吞吐量 ≈
分区数 × 单分区吞吐量上限。
举例:
业务需要 500 MB/s 的写入吞吐量,单 Broker 顺序写上限 100 MB/s。
只需设置 ≥ 5 个分区,并分布到 5 台 Broker 上,即可满足需求。
2.2 水平扩展消费并行度
消费者组内,每个分区同一时刻只能被一个消费者线程处理。因此:
-
消费者组的最大并行度 = 订阅的 Topic 的分区总数。
-
若分区数小于消费者实例数,多余的消费者会处于空闲状态。
举例:
订单 Topic 有 6 个分区 ,消费者组部署 10 个实例 。
实际只有 6 个实例在工作,另外 4 个闲置。
结论: 分区数是消费者并行度的硬上限。
2.3 负载均衡与故障隔离
-
负载均衡:多个分区的 Leader 会均匀分布到不同 Broker 上,读写流量自然分散。
-
故障隔离:单个分区 Leader 所在的 Broker 宕机,只会影响该分区的读写,其他分区不受影响。Controller 会迅速将该分区的 Leader 切换到其他 Broker。
2.4 突破单机存储容量
-
单台 Broker 的磁盘容量有限。
-
分区可以分布到多台 Broker 的磁盘上,使 Topic 的总存储容量 =
所有 Broker 可用容量之和。
分区副本(Replica)的作用是什么?
分区副本(Replica)是Kafka实现高可用性、数据可靠性和读写可扩展性的核心机制。简单来说,它就是为每个数据分区(Partition)保留多份相同的"备份",以防止因服务器故障导致数据丢失或服务中断。
副本是如何工作的?三种关键角色
在Kafka中,每个分区可以有多个副本,但它们扮演的角色各不相同:
-
Leader Replica(领导者副本) :每个分区只有一个Leader副本。它负责处理该分区所有的读写请求,生产者将消息发往Leader,消费者也从Leader拉取消息。
-
Follower Replica(追随者副本) :其余副本均为Follower。它们不直接为客户端提供服务,唯一的任务就是不断从Leader副本拉取新消息来保持数据同步,以便随时待命。
-
In-Sync Replica - ISR(同步副本集合) :这是一个由Leader动态维护的、与自身数据保持同步的Follower副本集合。当生产者设置
acks=all时,只有ISR集合中的所有副本都确认收到消息,消息才算发送成功。
副本机制带来的核心优势
引入副本机制为Kafka带来了三大核心优势:
-
实现高可用与故障转移:当Leader副本所在的Broker宕机时,Kafka的Controller组件会立即从ISR集合中选举出一个新的Leader,快速接管服务,整个过程对客户端几乎无感知。
-
保障数据高可靠 :通过多副本冗余存储,Kafka可避免因单点磁盘损坏导致的数据丢失。配合
min.insync.replicas等配置,可精细控制数据可靠性与可用性的平衡。 -
提升系统吞吐量:虽然写操作集中在Leader,但消费者可以被允许从Follower副本读取数据,从而分担Leader的读负载,实现读写分离,提升系统整体吞吐量。
副本的关键机制与配置
为了精确控制副本的行为,Kafka提供了几个关键机制和配置:
-
ISR的动态维护 :ISR是一个动态集合。Leader副本会实时追踪所有Follower的状态,如果Follower因网络延迟、负载过高等原因落后,它会被暂时踢出ISR;待其追上进度后,又会被重新加入。这个判断标准由参数
replica.lag.time.max.ms控制,默认为10秒。 -
控制数据可靠性的ACK机制 :生产者端的
acks参数决定了消息在何种情况下被视为发送成功,它与副本机制紧密相关。-
acks=0:不等待确认,性能最高,可靠性最低,可能丢失消息。 -
acks=1:等待Leader确认,性能中等,若Leader在同步给Follower前宕机,可能丢失消息。 -
acks=all(或-1):等待ISR中所有副本确认,可靠性最高,但延迟相对较高。
-
-
平衡可靠性与可用性的min.insync.replicas:该参数指定了ISR中至少要有多少个副本(包括Leader),分区才能继续接受写入。当ISR数量小于该值时,Broker会拒绝写入请求。这虽会牺牲部分可用性,但能在极端情况下保证数据一致性。
-
预防"脏选举"的unclean.leader.election.enable :当ISR为空(即所有同步副本都不可用)时,是否允许从OSR(Out-of-Sync Replicas,非同步副本集合)中选举新Leader。该操作被称为"Unclean选举",虽然能快速恢复服务,但必然导致数据丢失 。在生产环境中,强烈建议将其设置为
false,优先保证数据一致性。
总结:一个比喻
可以把Kafka的副本机制想象成一个专业的抢修团队:
-
Leader:是正在主舞台表演的明星演员,负责所有演出(处理读写请求)。
-
Follower:是在后台时刻准备着的替身演员,他们密切观察、模仿主演的一举一动(同步数据),但不上台。
-
ISR:是状态良好、能随时顶上(同步进度达标)的替身名单。
-
ACK机制 :是导演的要求。
acks=0是导演让主演"不用管,演完就走";acks=1是"只要主演准备好了就行";acks=all则是"必须等所有替身也准备好了,这条才算过",虽然慢,但最保险。
如果主演(Leader)突然无法表演,导演(Controller)就会立刻从ISR名单里挑一个最好的替身(Follower)顶上去,保证演出不中断。
Leader副本和Follower副本的职责分别是什么?
在 Kafka 的副本机制中,Leader 副本 和 Follower 副本是同一个分区数据在不同 Broker 上的冗余拷贝,但它们在集群中扮演的角色和承担的职责截然不同。
一、核心职责对比
| 职责维度 | Leader 副本 | Follower 副本 |
|---|---|---|
| 处理生产者写入 | ✅ 唯一负责。所有 Produce 请求必须发往 Leader。 | ❌ 不接收写入请求。若误发,会返回 NOT_LEADER_FOR_PARTITION 错误。 |
| 处理消费者拉取 | ✅ 默认负责。消费者默认从 Leader 拉取消息。 | ❌ 默认不服务消费者(Kafka 2.4+ 支持配置机架感知后可从 Follower 读)。 |
| 数据同步方向 | 被动提供。响应 Follower 的 Fetch 请求,推送新数据。 | 主动拉取。像特殊消费者一样,持续向 Leader 发送 Fetch 请求,复制数据。 |
| 维护 ISR | ✅ 负责跟踪所有 Follower 的同步进度,动态维护 ISR 集合。 | ❌ 不参与 ISR 管理,仅被动上报自己的 LEO。 |
| 推进 HW | ✅ 根据 ISR 中最慢副本的 LEO 计算并推进 HW(高水位)。 | ❌ 从 Leader 的 Fetch 响应中获取 HW,更新本地 HW。 |
| 故障转移 | 宕机后由 Controller 从 ISR 中选举新 Leader。 | ✅ 候选者。ISR 中的 Follower 随时准备被选举为新 Leader。 |
| 参与 Leader 选举 | 不再参与(已是 Leader)。 | ✅ ISR 中的 Follower 有资格成为新 Leader。 |
二、Leader 副本的详细职责
2.1 处理所有读写请求
Leader 是分区的唯一入口,承担全部读写流量:
Producer ──── 写入 ────► Leader ──── 持久化到本地磁盘
Consumer ─── 拉取 ────► Leader ──── 从 Page Cache 或磁盘读取返回为什么必须是 Leader?
-
数据一致性:只有 Leader 拥有最新的日志序列,Follower 可能存在滞后。若允许向 Follower 写入,会导致数据冲突和顺序混乱。
-
写入路径最短化:Leader 单写 + 异步复制,避免了 Quorum 写带来的额外网络延迟。
2.2 管理 ISR(同步副本集合)
Leader 维护一个动态的 ISR 列表,记录了当前与自己保持同步的 Follower 副本。
ISR 动态维护规则:
-
Follower 必须在
replica.lag.time.max.ms(默认 30 秒)内向 Leader 发送过 Fetch 请求。 -
超时的 Follower 被暂时踢出 ISR,待追上进度后重新加入。
Leader 跟踪每个 Follower 的同步状态:
2.3 推进 HW(高水位线)
HW 是已提交消息的边界,消费者只能读取 HW 以下的消息。
HW 的推进条件:
-
Leader 必须等到 ISR 中所有副本的 LEO 都大于等于某个 Offset,才能将 HW 推进到该位置。
初始状态:Leader LEO=100, Follower1 LEO=98, Follower2 LEO=99
→ HW = min(100, 98, 99) = 98Follower1 追到 100,Follower2 追到 100
→ HW = min(100, 100, 100) = 100
HW 的作用:
-
消费可见性:消费者只能读取 Offset ≤ HW 的消息,确保不会读到未提交的数据。
-
故障恢复:新 Leader 选举后,只需截断 HW 之后的消息,保证数据一致性。
2.4 响应 Follower 的 Fetch 请求
Leader 不主动推送数据给 Follower,而是被动响应 Follower 的拉取请求。这种 Pull 模式 的优势:
-
Follower 可根据自身处理能力控制拉取速率,避免被 Leader 压垮。
-
简化 Leader 逻辑,只需维护 Follower 的拉取状态即可。
三、Follower 副本的详细职责
3.1 主动从 Leader 拉取数据
Follower 的唯一数据来源是 Leader。它不断向 Leader 发送 Fetch 请求,拉取自己缺失的消息。
拉取流程:
Follower ── Fetch 请求(携带当前 LEO)──► Leader
◄── 返回从该 LEO 开始的新消息 ──
Follower ── 追加到本地日志,更新 LEO关键特点:
-
Follower 的 Fetch 请求与消费者的 Fetch 请求使用相同的协议 ,但 Follower 被标记为
replica,享有更高的拉取优先级。 -
Follower 只拉取已提交到 Leader 本地日志的消息,即使该消息尚未被所有 ISR 确认(即 HW 尚未推进),Follower 也会拉取。
3.2 保持数据同步,随时准备接管
Follower 的本质是 热备(Hot Standby)。它持续与 Leader 保持同步,确保自己处于 ISR 中,以便在 Leader 宕机时能被 Controller 选举为新 Leader。
被踢出 ISR 的后果:
-
若 Follower 同步滞后,被 Leader 踢出 ISR,它将失去被选举为新 Leader 的资格。
-
即使它物理上拥有该分区的数据,Controller 也不会选它(除非配置了
unclean.leader.election.enable=true,但这会导致数据丢失)。
3.3 协助 Leader 推进 HW
Follower 在 Fetch 请求的响应中,会将自己的 LEO 告知 Leader。Leader 收集所有 ISR 副本的 LEO,计算出新的 HW,并在下一次 Fetch 响应中带回给 Follower。
Follower 本地 HW 的更新:
- Follower 不独立计算 HW,而是完全信任 Leader 返回的 HW 值,直接更新本地 HW。
3.4 (可选)服务消费者的读取请求
从 Kafka 2.4.0 开始,消费者可以配置为从 同机架的 Follower 读取消息(Rack-Aware Replica Selection)。
适用场景: 多可用区部署,消费者希望从本地机房的 Follower 读取,以减少跨机房流量成本。
限制:
-
Follower 可能存在滞后,读取到的消息可能略晚于 Leader。
-
需要 Broker 配置
broker.rack,消费者配置client.rack,并启用RackAwareReplicaSelector。 -
生产者写入依然只能发往 Leader。
四、Leader 与 Follower 的协作流程
以一条消息从写入到被消费的完整流程为例:
| 步骤 | Leader 的动作 | Follower 的动作 |
|---|---|---|
| 1. 生产者写入 | 收到 Produce 请求,追加消息到本地日志,更新 LEO。 | 无动作。 |
| 2. 数据复制 | 响应 Follower 的 Fetch 请求,返回新消息。 | 发送 Fetch 请求,拉取新消息,追加到本地日志,更新 LEO。 |
| 3. HW 推进 | 收集所有 ISR 副本的 LEO,计算新 HW,推进本地 HW。 | 在 Fetch 响应中收到新 HW,更新本地 HW。 |
| 4. 返回 ACK | 若配置 acks=all,等待所有 ISR 副本确认后,向生产者返回成功。 |
无动作。 |
| 5. 消费者拉取 | 收到 Fetch 请求,返回 HW 以下的消息(使用零拷贝)。 | 默认不参与。若启用机架感知,可响应同机架消费者的 Fetch 请求。 |
| 6. Leader 宕机 | 无法继续服务。 | ISR 中的 Follower 被 Controller 选举为新 Leader,开始对外服务。 |
五、常见问题澄清
Q1:Follower 会主动推送数据给其他副本吗?
不会。 Follower 之间不直接通信。所有数据流向都是:
Producer → Leader → Follower(s)Follower 只与 Leader 交互,形成一个星型复制拓扑。
Q2:Follower 的数据一定和 Leader 完全一致吗?
不一定,可能存在短暂滞后。 Follower 通过持续拉取来追赶 Leader,但受网络延迟和磁盘 I/O 影响,Follower 的 LEO 可能略低于 Leader。这种滞后是 Kafka 选择最终一致性 而非强一致性的体现。
Q3:如果所有 Follower 都落后,Leader 会等吗?
取决于 acks 配置。
-
acks=all:Leader 必须等待 ISR 中的所有副本确认,如果 Follower 落后被踢出 ISR,则不再等待它。 -
acks=1:Leader 只等待自己写入成功,不等待任何 Follower。
Q4:Follower 可以成为 Leader 吗?
可以,这是 Kafka 高可用的核心机制。 当 Leader 宕机时,Controller 会从 ISR 中选举一个 Follower 晋升为新 Leader。整个过程对客户端透明,客户端只需刷新元数据后连接到新 Leader。
六、总结
| 角色 | 一句话职责 |
|---|---|
| Leader 副本 | 分区的唯一对外服务窗口,处理所有读写,管理 ISR,推进 HW。 |
| Follower 副本 | 分区的热备冗余,持续从 Leader 同步数据,随时准备接管服务。 |
这种 Leader-Follower 单写多备 的架构,使 Kafka 在保证数据一致性和高可用的同时,实现了极致的读写吞吐量。
什么是ISR集合?它的作用是什么?
一、ISR 的定义
ISR(In-Sync Replicas,同步副本集合) 是指与 Leader 副本保持同步的副本集合。它是 Kafka 副本机制的核心概念,直接决定了数据的可靠性、一致性以及集群的容错能力。
简单理解:
-
一个分区有多个副本(Replica),其中一个为 Leader,其余为 Follower。
-
ISR = { Leader } + { 所有追赶上进度的 Follower }
-
只有 ISR 中的副本才有资格被选举为新 Leader。
二、ISR 的组成
| 组成元素 | 说明 |
|---|---|
| Leader 副本 | 永远在 ISR 中,是集合的基准。 |
| 同步中的 Follower 副本 | 满足同步条件的 Follower,与 Leader 数据差距在阈值内。 |
示例:
假设分区 P0 配置了 3 个副本(分布在 Broker 1、2、3),当前 Leader 在 Broker 1。
-
如果 Broker 2 与 Leader 保持紧密同步,Broker 3 因网络延迟落后较多。
-
则 ISR = Broker 1 (Leader), Broker 2 (Follower)。
-
Broker 3 被暂时踢出 ISR,称为 OSR(Out-of-Sync Replica)。
三、ISR 的动态维护机制
ISR 不是固定不变的,而是由 Leader 副本动态维护,根据 Follower 的同步状态实时调整。
3.1 加入 ISR 的条件
Follower 必须同时满足以下条件才能留在 ISR 中:
-
时间维度 :在过去
replica.lag.time.max.ms(默认 30 秒)内向 Leader 发送过 Fetch 请求。 -
数据维度(历史版本) :在 Kafka 早期版本中,还要求 Follower 落后的消息条数不超过
replica.lag.max.messages(已废弃)。现在 仅以时间维度作为判断标准,更加科学。
3.2 踢出 ISR 的场景
| 场景 | 说明 |
|---|---|
| Follower 宕机或网络分区 | 超过 30 秒未向 Leader 发送 Fetch 请求。 |
| Follower 处理能力不足 | 持续拉取但速度跟不上 Leader 写入速度(例如磁盘 I/O 慢、CPU 负载高),导致拉取间隔超过 30 秒。 |
| Follower 被管理员停机维护 | Broker 正常关闭时,Controller 会主动将其从所有分区的 ISR 中移除。 |
3.3 重新加入 ISR
当被踢出的 Follower 恢复同步,追上 Leader 的进度后,Leader 会检测到其拉取请求的间隔恢复到阈值内,便会将其重新加入 ISR。
判断逻辑伪代码:
java
// Leader 每次收到 Follower 的 Fetch 请求时
if (now - follower.lastFetchTime <= replica.lag.time.max.ms) {
isr.add(follower);
} else {
isr.remove(follower);
}四、ISR 的核心作用
4.1 决定消息的可靠性与 ACK 行为
生产者配置 acks=all(或 -1)时,消息必须被 ISR 中所有副本确认 后才算写入成功。
生产者 ── 写入 ──► Leader
│
├─ Leader 写入本地日志
├─ 等待 ISR 中所有 Follower 拉取并确认
└─ 全部确认后,返回 ACKISR 缩小的影响:
-
假设 ISR 原本有 3 个副本,因 Follower 故障缩减为 2 个。
-
只要
min.insync.replicas设置为 2,写入仍可成功。 -
若 ISR 进一步缩减至 1(只剩 Leader),且
min.insync.replicas=2,则 写入会被拒绝 (NOT_ENOUGH_REPLICAS异常),从而牺牲可用性来保证数据一致性。
4.2 约束 Leader 选举范围,防止数据丢失
当 Leader 宕机时,Controller 需要从该分区的副本中选举出新 Leader。
选举规则:
-
默认行为 (
unclean.leader.election.enable = false):只能从 ISR 中的副本选举。 -
原因 :ISR 中的副本与旧 Leader 数据同步,选举它们可以保证 数据零丢失。
-
如果允许从 OSR 选举 (Unclean 选举):虽然能快速恢复服务,但因 OSR 副本数据落后,会永久丢失一部分已提交的消息。
旧 Leader (Broker 1) ── 宕机前已写入 Offset 100~150
ISR 副本 (Broker 2) ── 同步到 Offset 150
OSR 副本 (Broker 3) ── 只同步到 Offset 120若从 Broker 2 选举:数据完整,Offset 100~150 全部保留。
若从 Broker 3 选举:Offset 121~150 的消息永久丢失(Unclean 选举)。
4.3 决定 HW(高水位线)的推进
HW = ISR 中所有副本 LEO 的最小值。
java
Leader LEO = 200
ISR 包含:Follower1 LEO = 198, Follower2 LEO = 195
→ HW = min(200, 198, 195) = 195HW 的作用:
-
消费者可见性边界:消费者只能读取 Offset ≤ HW 的消息,确保不会读到未被多数副本确认的"脏数据"。
-
故障恢复截断点:新 Leader 选举后,会将本地日志截断到 HW,保证副本间数据一致性。
ISR 变化对 HW 的影响:
-
若 Follower2 被踢出 ISR,HW 可能上升(因为不再受其低 LEO 拖累)。
-
若 Follower2 追上来重新加入 ISR,HW 可能暂时被压低(需要等它继续追)。
4.4 监控集群健康度
ISR 的收缩和扩张是 Kafka 集群健康状态的重要指标。
| 监控指标 | 含义 | 告警阈值 |
|---|---|---|
| UnderReplicatedPartitions | ISR 副本数 < 配置的副本数的分区数量 | > 0 即告警 |
| UnderMinIsrPartitions | ISR 副本数 < min.insync.replicas 的分区数量 |
> 0 严重告警 |
| IsrShrinksPerSec | ISR 收缩速率 | 突然升高说明集群不稳定 |
| IsrExpandsPerSec | ISR 扩张速率 | 恢复过程监控 |
五、ISR 与相关配置的联动
| 配置参数 | 作用域 | 默认值 | 与 ISR 的关系 |
|---|---|---|---|
replica.lag.time.max.ms |
Broker | 30000 (30s) | 唯一决定 Follower 是否在 ISR 中的时间阈值。 |
min.insync.replicas |
Topic/Broker | 1 | 要求 ISR 中至少有多少副本,写入才能成功。配合 acks=all 使用。 |
unclean.leader.election.enable |
Broker | false | 决定 ISR 为空时是否允许从 OSR 选举(生产环境必须 false)。 |
acks |
Producer | all (3.0+) | acks=all 时,必须等待 ISR 中所有副本确认。 |
生产环境黄金组合:
properties
java
# Broker 配置
replication.factor = 3
min.insync.replicas = 2
unclean.leader.election.enable = false
# Producer 配置
acks = all
enable.idempotence = true该配置可实现:容忍 1 个副本故障,同时保证已确认消息绝不丢失。
六、ISR 与 Raft Quorum 的区别
Kafka 的 ISR 模型与 Raft 的多数派(Quorum)模型是两种不同的数据一致性方案:
| 维度 | ISR 模型(Kafka) | Quorum 模型(Raft) |
|---|---|---|
| 写入确认 | 等待 ISR 中所有副本 (可配置 min.insync.replicas) |
等待 多数派(> N/2) |
| 3 副本容错能力 | 可容忍 1 个故障(ISR 保持 3 个时),或 2 个故障(若 min.insync=1,但不推荐) |
只能容忍 1 个故障 |
| 读性能 | 极高(只需读 Leader) | 需要读多数派防止脏读,或依赖强 Leader 读 |
| 写性能 | 高(Follower 异步拉取,不影响写延迟) | 较高(需等待多数派确认) |
ISR 模型的优势:
-
用 更少的副本 实现了 相同甚至更高的容错能力 (若配置
min.insync=2,3 副本可容忍 1 个故障;Raft 3 副本也只能容忍 1 个故障)。 -
读取只需访问 Leader,延迟极低。
七、ISR 收缩的典型案例
场景: 3 副本分区,Leader 写入流量突增,Follower 所在 Broker 磁盘 I/O 繁忙。
| 时间点 | 事件 | ISR 状态 |
|---|---|---|
| T0 | 正常运行,所有副本同步 | [Broker1(L), Broker2, Broker3] |
| T1 | Broker2 磁盘 I/O 阻塞,Fetch 请求延迟 | 仍在线,但拉取间隔逼近 30 秒 |
| T2 | 30 秒后,Broker2 被踢出 ISR | [Broker1(L), Broker3] |
| T3 | 生产者 acks=all,min.insync=2,仍可写入 |
写入成功,但冗余度降低 |
| T4 | Broker2 I/O 恢复,追上进度 | 重新加入 ISR,[Broker1(L), Broker2, Broker3] |
影响:
-
T2 期间,若 Broker1 宕机,Controller 只能选 Broker3 为新 Leader(Broker2 不在 ISR,无资格)。
-
集群冗余度暂时下降,但数据一致性得以保证。
八、总结
| 核心要点 | 说明 |
|---|---|
| ISR 是什么 | 与 Leader 保持同步的副本集合,包含 Leader 自身。 |
| 如何维护 | Leader 根据 Follower 最后一次 Fetch 时间动态调整(阈值 30 秒)。 |
| 作用 1 | 决定 acks=all 时消息何时确认(必须等 ISR 全确认)。 |
| 作用 2 | 约束 Leader 选举范围(只从 ISR 选,防止数据丢失)。 |
| 作用 3 | 决定 HW 推进(HW = min(ISR 中所有副本的 LEO))。 |
| 作用 4 | 集群健康的核心监控指标。 |
| 生产配置 | replication.factor=3 + min.insync.replicas=2 + unclean.leader.election=false。 |
一句话总结:ISR 是 Kafka 在数据可靠性与高可用之间做出的精巧权衡------它保证了已确认消息不会丢失,同时允许集群在部分副本故障时继续安全地对外提供服务。
Kafka中的偏移量(Offset)是什么?
一、什么是 Offset
Offset(偏移量)是 Kafka 分区内每条消息的唯一、单调递增的 64 位整数标识符。 它表示消息在分区日志中的物理位置,类似于数组的下标。
每个分区独立维护自己的 Offset 序列,不同分区之间的 Offset 没有关联性。
Partition 0: [msg0] [msg1] [msg2] [msg3] [msg4] ...
Offset: 0 1 2 3 4 ...
Partition 1: [msg0] [msg1] [msg2] ...
Offset: 0 1 2 ...二、Offset 的核心作用
| 作用 | 说明 |
|---|---|
| 唯一标识消息 | 在分区内通过 Offset 精确定位任意一条消息。 |
| 消费者进度管理 | 消费者通过记录已消费的 Offset,实现断点续传和故障恢复。 |
| 消息重复消费控制 | 消费者可重置 Offset 到任意位置,实现消息重放或跳过。 |
| 副本同步的基准 | Leader 和 Follower 通过 Offset 比较同步进度,维护 ISR 和 HW。 |
| 顺序保证 | Offset 的单调递增性保证了分区内消息的严格顺序。 |
三、三种重要的 Offset 类型
在 Kafka 的运作过程中,存在三种容易混淆的 Offset 概念:
| 类型 | 全称 | 维护方 | 含义 |
|---|---|---|---|
| Consumer Offset | 消费者偏移量 | 消费者 / __consumer_offsets |
消费者已处理到的消息位置,用于恢复消费。 |
| LEO | Log End Offset | Broker | 分区日志当前最后一条消息的下一个 Offset,即下一条写入消息将获得的 Offset。 |
| HW | High Watermark | Broker | 已提交(所有 ISR 副本已确认)的消息边界,消费者最多只能读到 HW 位置。 |
3.1 消费者 Offset(Consumer Offset)
消费者在处理完一批消息后,会将当前处理到的 Offset 提交给 Kafka,存储在内部 Topic __consumer_offsets 中。
// 消费者提交 Offset
consumer.commitSync(); // 同步提交当前拉取到的最大 Offset作用:
-
消费者重启或发生 Rebalance 后,从上次提交的 Offset 处继续消费。
-
若未提交,则根据
auto.offset.reset策略从最早(earliest)或最新(latest)位置开始。
3.2 日志末端偏移量(LEO)
LEO 是分区日志的物理末尾位置,表示下一条写入消息将被分配的 Offset。
分区日志:
[msg0] [msg1] [msg2] [msg3] [msg4] (待写入)
0 1 2 3 4
↑
LEO = 5-
Leader LEO:Leader 副本的日志末端位置。
-
Follower LEO:Follower 副本的日志末端位置。
Leader 通过收集各 Follower 的 LEO 来推进 HW。
3.3 高水位偏移量(HW)
HW 是已提交(Committed) 的消息边界,即 ISR 中所有副本都已确认持久化的最大 Offset。
Leader LEO = 200
ISR = [Broker1(Leader), Broker2(Follower), Broker3(Follower)]
Broker2 LEO = 198
Broker3 LEO = 195
→ HW = min(200, 198, 195) = 195HW 的关键作用:
-
消费者可见性边界 :消费者只能读取
Offset < HW的消息,防止读到未完全提交的数据。 -
故障恢复截断点:Leader 切换时,新 Leader 会将本地日志截断到 HW,确保副本间数据一致。
四、Offset 的生命周期
以一条消息从生产到消费的完整流程为例:
| 阶段 | Offset 行为 |
|---|---|
| 1. 生产者写入 | 消息追加到 Leader 本地日志末尾,被分配一个新的 Offset(即当前 Leader LEO)。 |
| 2. 副本同步 | Follower 通过 Fetch 请求拉取消息,更新各自的 LEO。 |
| 3. HW 推进 | 当 ISR 中所有副本的 LEO 都大于该 Offset 时,Leader 推进 HW。 |
| 4. 消费者拉取 | 消费者发起 Fetch 请求,从上次提交的 Consumer Offset 开始拉取,最多拉到 HW 位置。 |
| 5. 消费者提交 | 消费者处理完消息后,将当前 Offset 提交至 __consumer_offsets。 |
| 6. 消费者重启 | 从 __consumer_offsets 读取上次提交的 Offset,从此处继续消费。 |
五、Offset 存储机制
5.1 消费者 Offset 的存储位置
| Kafka 版本 | 存储位置 | 说明 |
|---|---|---|
| 0.9 之前 | ZooKeeper | 已废弃,存在性能瓶颈。 |
| 0.9 及之后 | 内部 Topic __consumer_offsets |
将 Offset 作为普通消息写入 Kafka,享受高吞吐和持久化。 |
__consumer_offsets 是一个压缩 Topic(cleanup.policy=compact),每个消费者组的每个分区只保留最新的 Offset 记录。
Offset 提交的消息格式:
Key: (Group, Topic, Partition)
Value: (Offset, Metadata, Timestamp)5.2 分区内 Offset 的物理存储
Offset 并不显式存储在 .log 文件的每条消息中,而是通过消息在文件中的物理位置和索引文件推算得出。
-
.log文件中,每条消息的 Offset 通过baseOffset + offsetDelta计算。 -
.index文件存储了Offset → 物理位置的稀疏映射,用于快速定位。
六、Offset 相关配置参数
| 配置项 | 作用域 | 说明 |
|---|---|---|
auto.offset.reset |
Consumer | 无初始 Offset 或 Offset 无效时的行为:earliest(从最早开始)、latest(从最新开始)、none(抛异常)。 |
enable.auto.commit |
Consumer | 是否自动提交 Offset。推荐设为 false,手动控制提交时机。 |
auto.commit.interval.ms |
Consumer | 自动提交间隔,默认 5000ms。 |
offsets.retention.minutes |
Broker | __consumer_offsets 中 Offset 记录的保留时长,默认 7 天。 |
log.retention.hours |
Broker | 消息数据的保留时长,与 Offset 无关。 |
七、Offset 常见问题与陷阱
Q1:消费者提交 Offset 失败会怎样?
-
下次拉取时会从上次成功提交的 Offset 处重新消费,可能导致消息重复。
-
解决方案 :消费端实现幂等处理,或使用事务实现精确一次语义。
Q2:Offset 越界(Out of Range)是什么原因?
-
消费者请求的 Offset 小于分区最小可用 Offset(数据已过期被删除)。
-
消费者请求的 Offset 大于分区当前 LEO(尚未写入)。
-
处理策略 :根据
auto.offset.reset配置决定行为。
Q3:Offset 和分区扩容的关系?
-
分区数增加时,已有消息的 Offset 不会改变,但新消息会被路由到新分区。
-
分区数减少不被允许,因为 Offset 归属会错乱。
Q4:如何重置消费者 Offset?
使用 kafka-consumer-groups.sh 工具:
# 将消费者组 offset 重置到最早位置
kafka-consumer-groups.sh --bootstrap-server localhost:9092 \
--group my-group --reset-offsets --to-earliest \
--topic my-topic --execute
# 重置到指定时间戳
kafka-consumer-groups.sh --bootstrap-server localhost:9092 \
--group my-group --reset-offsets --to-datetime 2024-01-01T00:00:00.000 \
--topic my-topic --execute八、总结
| 核心要点 | 说明 |
|---|---|
| 定义 | Offset 是分区内消息的唯一、递增编号。 |
| 消费者 Offset | 记录消费者进度,存储在 __consumer_offsets 中。 |
| LEO | 分区日志末端位置,下一条消息将获得的 Offset。 |
| HW | ISR 全确认的消息边界,消费者只能读到 HW 之前。 |
| 重要性 | Offset 是 Kafka 实现顺序保证、断点续传、故障恢复、副本同步的基石。 |
一句话总结:Offset 是 Kafka 分区内消息的"门牌号",消费者通过它记住自己读到了哪里,Broker 通过它管理副本同步和数据一致性。
什么是消费者组(Consumer Group)?
一、什么是消费者组
消费者组(Consumer Group)是 Kafka 实现消息消费的负载均衡和容错机制的核心抽象。 它由一组消费者实例组成,这些实例共同订阅一个或多个 Topic,并协作消费这些 Topic 的分区消息。
核心原则:
同一个消费者组内,一个分区最多只能被一个消费者实例消费。
Consumer Group "order-processor"
│
├─ Consumer 1 ── 消费 Partition 0, Partition 1
├─ Consumer 2 ── 消费 Partition 2, Partition 3
└─ Consumer 3 ── 消费 Partition 4, Partition 5二、消费者组的核心作用
| 作用 | 说明 |
|---|---|
| 水平扩展消费能力 | 增加消费者实例即可线性提升消费吞吐量(上限为分区总数)。 |
| 故障转移与高可用 | 组内某个消费者宕机时,其负责的分区会被自动重新分配给其他健康的消费者。 |
| 实现发布-订阅模型 | 不同消费者组独立订阅同一 Topic,每组都能收到全量消息,互不影响。 |
| 消费进度隔离 | 每个消费者组独立维护自己的 Offset,组间消费进度互不干扰。 |
三、消费者组的两种消费模式
3.1 点对点模式(Queue / Load Balancing)
当所有消费者属于同一个消费者组 时,Topic 中的每条消息只会被组内的某一个消费者处理。
Topic: order-events (6 Partitions)
│
Consumer Group "order-service"
│
┌────┼────┬────┬────┬────┐
▼ ▼ ▼ ▼ ▼ ▼
C1 C1 C2 C2 C3 C3适用场景:
- 订单处理、邮件发送等需要分摊负载 、单次处理的任务。
3.2 发布-订阅模式(Pub/Sub)
当每个消费者属于不同的消费者组 时,Topic 中的每条消息会被所有组各自消费一次。
Topic: user-events
│
┌────────────────┼────────────────┐
▼ ▼ ▼
Group "实时推荐" Group "数据仓库" Group "风控引擎"
(收到全量消息) (收到全量消息) (收到全量消息)适用场景:
- 同一份数据需要被多个独立的业务系统消费(如用户行为日志同时用于实时推荐、离线分析和风控告警)。
四、消费者组与分区的关系
4.1 分区分配原则
-
消费者实例数 ≤ 分区数:每个消费者负责一个或多个分区,所有消费者均在工作。
-
消费者实例数 > 分区数:多余的消费者实例会处于空闲状态,不消费任何分区。
结论:消费者组的并行度上限 = Topic 的分区总数。
4.2 分区分配策略
当消费者加入或离开组时,Kafka 会根据配置的分配策略重新分配分区。Kafka 4.0 支持的策略:
| 策略 | 特点 |
|---|---|
| RangeAssignor | 按 Topic 逐个分配,每个 Topic 的分区按范围均分。可能导致分配不均。 |
| RoundRobinAssignor | 将所有 Topic 的分区统一轮询分配,分配更均匀。 |
| StickyAssignor | 在均匀分配的基础上,尽量保持现有分配不变,减少 Rebalance 迁移量。 |
| CooperativeStickyAssignor | Kafka 4.0 默认策略,实现渐进式 Rebalance,只迁移需要变更的分区。 |
五、消费者组重平衡(Rebalance)
Rebalance 是指消费者组内分区所有权发生变更的过程。
5.1 触发条件
| 触发场景 | 说明 |
|---|---|
| 消费者数量变化 | 新消费者加入或现有消费者离开(主动退出或宕机)。 |
| Topic 分区数增加 | 消费者组需要感知新分区并分配给成员。 |
| 订阅的 Topic 变化 | 通过正则匹配新增了匹配的 Topic。 |
| 心跳超时 | 消费者超过 session.timeout.ms 未发送心跳。 |
| 消费超时 | 消费者处理单批消息超过 max.poll.interval.ms。 |
5.2 Rebalance 的影响与优化
| 协议 | 特点 | 消费中断 |
|---|---|---|
| 经典协议(Eager) | 触发时所有消费者停止消费,释放全部分区,重新分配。 | Stop-The-World,消费完全中断。 |
| 新一代协议(Cooperative,KIP-848) | 增量调整,仅迁移需要变更的分区,其余分区持续消费。 | 几乎无感知,消费持续进行。 |
优化建议:
# 使用渐进式重平衡
partition.assignment.strategy=org.apache.kafka.clients.consumer.CooperativeStickyAssignor
# 合理设置超时
session.timeout.ms=45000
max.poll.interval.ms=300000
# 在 Kafka 4.0+ 中启用新一代组协议
group.protocol=consumer六、消费者组的 Offset 管理
每个消费者组独立维护自己消费到的位置(Offset),存储在内部 Topic __consumer_offsets 中。
__consumer_offsets 中存储的记录:
Key: (Group="order-processor", Topic="order-events", Partition=0)
Value: (Offset=1500, Metadata="", Timestamp=1712908800000)关键特性:
-
组间隔离:Group A 消费到 Offset 1000,Group B 可能才消费到 Offset 500,互不影响。
-
故障恢复:消费者重启后,从上次提交的 Offset 继续消费,实现断点续传。
-
重置能力:可通过工具将组的 Offset 重置到最早、最新或指定时间点。
七、消费者组的常见配置
| 配置项 | 说明 | 推荐值 |
|---|---|---|
group.id |
消费者组唯一标识 | 必填,同一组的消费者必须相同 |
session.timeout.ms |
心跳会话超时,用于检测消费者故障 | 45000(45s) |
max.poll.interval.ms |
两次 poll 最大间隔,超时触发 Rebalance | 300000(5min) |
heartbeat.interval.ms |
心跳发送间隔 | session.timeout.ms / 3 |
enable.auto.commit |
是否自动提交 Offset | false(推荐手动提交) |
auto.offset.reset |
无初始 Offset 时的行为 | earliest / latest |
partition.assignment.strategy |
分区分配策略 | CooperativeStickyAssignor |
group.protocol |
组协议(Kafka 4.0+) | consumer(启用 KIP-848) |
八、消费者组的管理命令
# 查看所有消费者组
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
# 查看指定组的消费详情(包含 LAG)
kafka-consumer-groups.sh --bootstrap-server localhost:9092 \
--group my-group --describe
# 输出示例:
# GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG
# my-group order-events 0 1500 1505 5
# my-group order-events 1 2300 2300 0
# 重置消费者组 Offset 到最早
kafka-consumer-groups.sh --bootstrap-server localhost:9092 \
--group my-group --reset-offsets --to-earliest \
--topic order-events --execute
# 删除消费者组(需确保组内无活跃消费者)
kafka-consumer-groups.sh --bootstrap-server localhost:9092 \
--group my-group --delete九、常见问题与最佳实践
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 消费积压(LAG 过高) | 生产速度 > 消费速度 | 增加消费者实例(不超过分区数);优化消费逻辑;增加分区数。 |
| 频繁 Rebalance | 心跳超时或 poll 间隔超时 | 调大 session.timeout.ms 和 max.poll.interval.ms;确保消费逻辑无长时间阻塞。 |
| 消息重复消费 | 消费完未提交 Offset 即发生 Rebalance | 手动提交 Offset;消费端实现幂等处理。 |
| 消费者空闲 | 消费者实例数 > 分区数 | 减少消费者实例或增加 Topic 分区数。 |
| 组 ID 冲突 | 不同业务共用同一 group.id | 为每个独立业务配置唯一的 group.id。 |
十、总结
| 核心要点 | 说明 |
|---|---|
| 定义 | 一组消费者协作消费 Topic 分区的集合。 |
| 核心约束 | 同一组内,一个分区只能被一个消费者消费。 |
| 并行度上限 | 消费者实例数超过分区数时,多余实例空闲。 |
| 负载均衡 | 分区在组内动态分配,实现水平扩展。 |
| 故障转移 | 消费者宕机后,分区自动分配给其他成员。 |
| 进度隔离 | 每个组独立维护 Offset,组间互不影响。 |
| Rebalance | 分区所有权变更过程,新协议实现无感迁移。 |
一句话总结:消费者组是 Kafka 实现消息消费的"弹性伸缩小组",它通过动态分配分区来实现负载均衡和故障转移,同时保证每个组独立管理自己的消费进度。
Kafka的生产者和消费者分别是如何与Broker交互的?
Kafka 生产者和消费者都是通过与 Broker 建立 TCP 长连接 ,并使用一套自定义的二进制协议 来完成交互的。它们之间的交互是异步 且解耦的:生产者与消费者彼此不知道对方的存在,各自独立地与 Broker 通信。
生产者与Broker的交互
生产者的主要任务是可靠、高效地将消息发送到 Broker。整个发送流程由主线程 和Sender 线程协同完成,核心步骤如下:
-
发现与连接 :生产者启动时,会根据
bootstrap.servers配置连接到任意一台 Broker,并发送一个MetadataRequest。Broker 会返回集群的元数据,生产者据此知道应该为每个 Topic 分区向哪台 Leader Broker 建立连接。 -
消息处理与路由 :当
producer.send()被调用后,消息在主线程中依次经过拦截器、序列化器(将键值转为字节数组),最后通过分区器决定其要发往的Topic-Partition。 -
批量缓冲 :处理后的消息会被放入
RecordAccumulator中,为每个目标分区维护一个队列。生产者会等待batch.size或linger.ms配置的条件满足,将多条消息组成一个批次(Batch)来减少网络请求。 -
异步发送 :独立的 Sender 线程 会从
RecordAccumulator中取出已准备好的批次,通过 TCP 连接以异步方式将其发送给目标 Leader Broker。 -
Broker响应与确认 :Broker 成功将消息写入分区日志后,会向生产者返回一个包含元数据的响应。
acks参数决定了消息的持久性级别:-
acks=0:不等待确认,吞吐量最高,但可能丢失消息。 -
acks=1:等待 Leader 写入成功后确认,若 Leader 在同步前宕机可能丢失数据。 -
acks=all(或-1):等待所有同步副本(ISR)都写入后确认,可靠性最高。
-
消费者与Broker的交互
消费者的交互模式更为复杂,主要是向 Broker 主动拉取(Pull) 消息,并处理消费组内的协调问题。
-
连接与加入消费组 :消费者启动时同样通过
bootstrap.servers建立连接,向 Broker 发送ConsumerMetadataRequest,定位到负责其消费者组的 Group Coordinator (组协调器)。之后,消费者会发送JoinGroupRequest请求加入消费组。 -
分区分配 (Rebalance):Group Coordinator 根据指定的分区分配策略(如Range、RoundRobin),为组内消费者分配其应消费的分区,并将分配方案返回给所有消费者。
-
心跳保活 :消费者会通过独立的心跳线程定期向 Group Coordinator 发送心跳。若在
session.timeout.ms内未收到心跳,该消费者会被踢出消费组,并触发一次 Rebalance。 -
拉取消息 :分配完成后,消费者通过
poll()方法向分区 Leader 所在的 Broker 发起拉取请求,并指定消费的起始 Offset。poll循环会不断从服务端拉取新消息。 -
处理与提交位移 :消费者处理完消息后,需要提交(Commit)位移 ,将当前消费位置记录在 Kafka 内部 Topic
__consumer_offsets中。-
自动提交:由客户端在后台定期自动提交,实现简单,但可能造成消息丢失或重复。
-
手动提交:由开发者控制提交时机,可确保"至少一次"或通过业务幂等实现"精确一次"的消费语义,是生产环境中的推荐做法。
-
Kafka支持哪些消息投递语义?
Kafka 在生产者到 Broker、Broker 到消费者两个环节中,共定义了三种消息投递语义(Delivery Semantics),用于描述消息在传递过程中可能出现的丢失或重复情况。
一、三种投递语义概览
| 语义 | 含义 | 实现方式 | 可靠性 |
|---|---|---|---|
| At most once(最多一次) | 消息可能丢失,但绝不会重复。 | acks=0,不重试。 |
低 |
| At least once(至少一次) | 消息绝不丢失,但可能重复。 | acks=all + 失败重试。 |
中 |
| Exactly once(精确一次) | 消息既不丢失也不重复(有效一次)。 | 幂等生产者 + 事务。 | 高 |
注意: "Exactly once" 在 Kafka 中是 "有效一次" (Effectively Once)的语义。在底层网络传输中,消息可能被重试发送多次,但通过 幂等去重 和 事务原子性,最终在业务侧表现为只被成功处理一次。
二、At most once(最多一次)
2.1 实现方式
| 组件 | 配置 | 说明 |
|---|---|---|
| 生产者 | acks=0 |
生产者发送消息后不等待任何确认,直接视为成功。 |
| 生产者 | retries=0 |
发送失败不重试。 |
| 消费者 | 先提交 Offset,后处理消息 | 若处理消息前消费者崩溃,该 Offset 已被提交,消息实际未被处理。 |
2.2 消息丢失场景
生产者 ── 发送消息 ──► Broker (Leader)
│
└─ 不等 ACK,直接返回成功
(若 Broker 宕机,消息丢失)2.3 适用场景
-
对数据一致性要求极低、允许丢失的监控指标或日志(不推荐生产核心业务)。
-
追求极致吞吐量、容忍偶尔丢失的场景。
三、At least once(至少一次)
这是 Kafka 默认且最常见 的投递语义。
3.1 实现方式
| 组件 | 配置 | 说明 |
|---|---|---|
| 生产者 | acks=all |
等待 ISR 中所有副本确认后才返回成功。 |
| 生产者 | retries > 0 |
发送失败时自动重试(可能造成消息重复)。 |
| 消费者 | 先处理消息,后提交 Offset | 若处理完成后、提交 Offset 前消费者崩溃,重启后会重新消费该消息。 |
3.2 消息重复场景
消费者 poll 到消息 Offset=100
│
├─ 处理消息(写入数据库)
│
├─ 提交 Offset 前,消费者崩溃 ❌
│
└─ 消费者重启,从 Offset=100 重新消费 → 消息重复处理3.3 应对重复的策略
-
消费端实现幂等:例如使用数据库唯一键、Redis Setnx 等保证重复处理的结果相同。
-
使用事务:配合 Kafka 事务实现端到端的精确一次(见下文)。
3.4 适用场景
-
绝大多数业务场景,配合幂等处理即可满足要求。
-
对数据丢失零容忍,但可接受偶尔重复的场景。
四、Exactly once(精确一次 / 有效一次)
Kafka 通过 幂等生产者 和 事务 两个机制,分别在单分区和跨分区场景下实现精确一次语义。
4.1 幂等生产者(单分区 / 单会话内的精确一次)
原理: Broker 为每个生产者分配一个唯一的 Producer ID(PID),生产者发送每条消息时附带一个单调递增的 Sequence Number。Broker 会记录每个 (PID, Topic, Partition) 对应的最近已提交的序列号,若收到重复序列号的消息,则直接丢弃并返回成功,从而消除生产者重试导致的重复。
配置:
enable.idempotence=true
acks=all # 幂等性要求 acks=all
max.in.flight.requests.per.connection=5 # 幂等性下最大为 5局限性:
-
仅保证单分区内 的精确一次,且只在单个生产者会话内有效(生产者重启会分配新 PID,无法跨会话去重)。
-
无法保证"消费-转换-生产"场景的端到端精确一次。
4.2 事务(跨分区 / 跨会话的精确一次)
事务允许生产者将一组跨分区、跨 Topic 的消息发送 作为一个原子操作,同时也支持 消费-转换-生产 模式的原子性。
关键概念:
-
Transactional ID:用户指定的唯一事务标识,跨生产者会话保持不变,用于关联 PID 实现跨会话去重。
-
事务协调器(Transaction Coordinator) :负责管理事务状态,写入内部 Topic
__transaction_state。
生产者配置与使用:
Properties props = new Properties();
props.put("transactional.id", "my-transactional-id");
props.put("enable.idempotence", true); // 事务依赖幂等性
props.put("acks", "all");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(new ProducerRecord<>("topic-A", "key1", "value1"));
producer.send(new ProducerRecord<>("topic-B", "key2", "value2"));
producer.commitTransaction();
} catch (Exception e) {
producer.abortTransaction();
}消费者配置:
isolation.level=read_committed # 只读取已提交的事务消息(过滤掉未提交或已中止的事务消息)4.3 端到端精确一次(消费-转换-生产)
通过事务,可将消息的消费和后续生产包装在同一事务中,实现 "消费 Kafka → 处理 → 生产到 Kafka" 的精确一次。
// 消费者配置
props.put("isolation.level", "read_committed");
props.put("enable.auto.commit", "false"); // 必须手动提交,由事务管理 Offset
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
KafkaProducer<String, String> producer = new KafkaProducer<>(txProps);
producer.initTransactions();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
try {
producer.beginTransaction();
for (ConsumerRecord<String, String> record : records) {
// 处理并生产到下游 Topic
producer.send(new ProducerRecord<>("output-topic", record.key(), process(record.value())));
}
// 将消费者 Offset 的提交纳入同一事务
producer.sendOffsetsToTransaction(offsets, "consumer-group-id");
producer.commitTransaction();
} catch (Exception e) {
producer.abortTransaction();
}
}原理: sendOffsetsToTransaction 会将消费者 Offset 的提交操作作为事务的一部分。只有当整个事务(包括下游生产和 Offset 提交)成功提交后,消费进度才会被持久化,从而保证 "消费-处理-生产" 的原子性。
五、三种语义的对比与选型建议
| 语义 | 实现复杂度 | 吞吐量 | 可靠性 | 适用场景 |
|---|---|---|---|---|
| At most once | 极低 | 最高 | 可能丢消息 | 可丢失的监控数据、非关键日志 |
| At least once | 低(需幂等) | 高 | 不丢,可能重复 | 绝大多数业务场景(配合幂等) |
| Exactly once | 高(需事务) | 略低 | 不丢不重复 | 金融交易、订单状态、跨系统数据一致性要求高的场景 |
生产环境推荐配置(At least once + 幂等):
# 生产者
acks=all
enable.idempotence=true
retries=2147483647
max.in.flight.requests.per.connection=5
# 消费者
enable.auto.commit=false # 手动提交 Offset
isolation.level=read_committed # 若使用事务生产者,读取已提交消息六、总结
| 语义 | 一句话概括 |
|---|---|
| At most once | "发出去就不管了,丢了拉倒。" |
| At least once | "必须送到,多送几次也无妨,你自己处理重复。" |
| Exactly once | "无论网络怎么折腾,最终效果就像只发了一次。" |
Kafka 的精确一次语义并非魔法,它是在 "至少一次" 的网络重试基础上,通过 幂等性去重 和 事务原子提交 构建的应用层保证。理解这三种语义及其实现机制,是设计可靠数据管道的基础。
什么是Kafka的日志压缩(Log Compaction)?适用场景是什么?
Kafka的日志压缩(Log Compaction)是一种基于消息键(Key)的细粒度数据保留机制。它的核心作用是确保在日志中,每个Key对应的最新Value总能被保留,而相同Key的旧Value则会在后台被清理。
这与Kafka默认基于时间或大小的"删除"(Delete)策略截然不同,后者会在数据过期后直接丢弃,不关心消息内容。日志压缩则将Kafka从一个简单的消息流,转变为一个持久的、可恢复的键值状态存储。
核心机制与原理
日志压缩的目的是保留每个Key的最新状态,同时清理旧值以释放存储空间。其后台处理流程如下:
-
选择待压缩日志段 :Kafka的后台
Log Cleaner线程会定期扫描分区日志。当一个日志段(Log Segment)中"脏数据"(即可被清理的旧记录)的比例达到min.cleanable.dirty.ratio(默认为0.5)时,该段会被选中。 -
构建Key的偏移量映射 :Cleaner会读取整个待压缩的日志段,在内存中为每个唯一的消息Key建立一个映射,记录该Key在日志段中出现的最新偏移量(Offset)。
-
重写并替换日志段 :Cleaner会创建一个新的、清理过的日志段,只保留映射表中每个Key的最新记录。完成后,用新段原子性地替换旧段,整个过程对生产者和消费者是透明的。
请注意 :日志压缩仅保留每个Key的最新值,并不会保证全局消息的顺序,也不会在消费时自动去重。消费者看到的仍是一个消息流,只是不再包含已被压缩掉的历史记录。
关键概念:"墓碑"消息
如果要删除某个Key,而非更新它,生产者可以发送一个Value为null 、Key为待删除键 的消息,这被称为墓碑(Tombstone) 消息。
-
作用:墓碑消息会像普通更新一样参与压缩,作为该Key的"最新状态"被保留,并向消费者明确传达"此Key已删除"的语义。
-
保留时间 :墓碑消息不会永久存在。Kafka会在保留一段时间(由
delete.retention.ms配置,默认为24小时)后,将其也清理掉,以彻底释放空间。
✅ 典型适用场景
日志压缩的核心价值在于将消息流转化为一个可以恢复最新状态的快照,它天然适用于以下场景:
-
变更数据捕获 (CDC):这是最经典的场景。当使用Debezium等工具将数据库的变更(INSERT, UPDATE, DELETE)同步到Kafka时,CDC主题会为每一行数据保留完整的变更历史。启用日志压缩后,Kafka只需保留每行数据的最新状态,节省大量空间。
-
Kafka Streams中的KTable :在Kafka Streams流处理中,
KTable代表一个不断更新的状态。其底层的状态存储正是依赖于一个启用了日志压缩的"变更日志(Changelog)"主题。该主题记录了KTable的所有状态变更,通过日志压缩,可以快速重建最新的全局状态。 -
事件溯源(Event Sourcing)中的快照:在事件溯源架构中,应用状态由一系列不可变的事件序列构成。为避免每次重启都从头重放所有事件,可以定期创建一个包含当前状态的"快照"主题,并开启日志压缩,始终保留最新的快照。
-
分布式缓存或配置中心 :当系统需要在内存中维护一份全量数据(如用户信息、系统配置)时,可以将Kafka的压缩主题作为数据源。消费者在启动时读取整个压缩主题,即可快速在本地重建缓存。
__consumer_offsets主题正是基于此原理来存储所有消费者组的位移。
对比:压缩 vs. 删除
| 策略 | 日志压缩 (Compact) | 日志删除 (Delete) |
|---|---|---|
| 保留依据 | 按消息Key,保留最新值 | 按时间或大小,到期/超限即删除 |
| 最终结果 | 一个包含每个Key最新状态的"键值"快照 | 一个保留最近一段时间的消息流 |
| 适用场景 | CDC、KTable、状态恢复 | 应用日志、监控指标、用户行为埋点等时序数据 |
🔧 关键配置速览
启用和调优日志压缩主要涉及以下配置:
| 配置参数 | 作用 | 默认值 |
|---|---|---|
cleanup.policy |
核心开关 ,设置为compact以启用压缩 |
delete |
min.cleanable.dirty.ratio |
控制压缩触发时机的阈值,值越小触发越频繁 | 0.5 |
delete.retention.ms |
墓碑消息(Value为null)的保留时间 |
86400000 (24小时) |
log.cleaner.threads |
执行压缩操作的后台线程数 | 1 |
重要注意事项
-
消息必须有Key :日志压缩完全依赖消息Key来识别和去重,因此所有发送到压缩主题的消息都必须包含非空的Key。
-
压缩是异步后台操作:压缩过程在后台运行,不会阻塞生产者写入或消费者读取,但它并非实时。
-
不保证全局顺序 :压缩会删除旧记录,因此不能保证消费者会按原始写入顺序看到所有消息。如果业务依赖严格的顺序,则不适合使用压缩主题。
-
不会无限压缩:活跃的日志段(正在写入的)不会被压缩。压缩只在已关闭的旧日志段上执行。
-
对消费者Lag监控的影响:压缩会物理删除消息,导致基于offset计算的消费Lag值失真。例如,一个消费者实际上落后了很多数据,但由于其应消费的offset已被压缩清理,Kafka会返回下一个可用的offset,导致计算出的Lag比实际值小。
-
何时使用
compact,delete混合策略:该混合策略会先执行基于时间的删除,再对剩余数据进行压缩。适用于需要保留每个Key的最新状态,但同时也希望自动淘汰那些长期未更新的"僵尸"数据的场景。
总结
日志压缩 (Log Compaction) 是Kafka的一种关键机制,它能基于消息Key高效地保留最新状态并清理历史数据。这使得Kafka从一个纯粹的消息流平台,转变为兼具持久化状态存储能力的强大系统,尤其适用于CDC、流处理状态管理和配置同步等场景。