【大语言模型】 揭秘OPD:大语言模型的长度膨胀与稳定化策略
📌 文章信息
Original Title: Demystifying OPD: Length Inflation and Stabilization Strategies for Large Language Models
中文标题: 揭秘OPD:大语言模型的长度膨胀与稳定化策略
| 项目 | 内容 |
|---|---|
| arXiv ID | 2604.08527v1 |
| 作者 | Feng Luo, Yu-Neng Chuang, Guanchu Wang, Zicheng Xu, Xiaotian Han 等 (7位作者) |
| 发布日期 | 2026-04-09 |
| 搜索日期 | 2026-04-12 |
| arXiv 链接 | https://arxiv.org/abs/2604.08527v1 |
📄 摘要信息
在线策略蒸馏(OPD)在利用更强教师模型指导的同时,在学生模型自身产生的分布下训练模型。我们发现了一个OPD的失效模式:随着训练的进行,在线策略 rollout 可能会经历突然的长度膨胀,导致被截断的轨迹主导了训练数据。这种截断崩溃与突然的重复饱和同时发生,并引发有偏的梯度信号,导致严重的训练不稳定和验证性能急剧下降。我们将这一问题归因于学生模型诱导的数据收集与蒸馏目标之间的相互作用,后者隐式地偏爱长且重复的 rollout。为了解决这个问题,我们提出了 Stable-OPD,这是一个稳定的 OPD 框架,结合了基于参考的散度约束和 rollout 混合蒸馏。这两者共同缓解了由重复引起的长度膨胀,并进一步稳定了 OPD 训练。在多个数学推理数据集上,我们的方法防止了截断崩溃,稳定了训练动态,并将平均性能提高了 7.2%。
🔍 研究背景
大语言模型(LLM)在推理任务(如数学和代码)中表现出色,但通常需要昂贵的计算资源。为了将这些能力迁移到更小的学生模型中,知识蒸馏(Knowledge Distillation)成为了一种主流范式。传统的离线蒸馏(Off-policy Distillation)虽然有效,但存在"训练-推理不匹配"(Train-Inference Mismatch)的问题:学生模型在训练时看到的是教师模型生成的前缀,而在推理(测试)时,它必须基于自己生成的前缀继续生成。这种分布差异限制了学生模型在长文本生成任务中的鲁棒性。
为了解决这一问题,在线策略蒸馏(On-policy Distillation, OPD)应运而生。OPD 让学生模型在训练过程中基于自身的策略(Policy)生成轨迹(Rollouts),并利用教师模型提供监督信号。这种方法理论上能更好地对齐训练和推理时的状态分布,避免了分布不匹配问题。然而,尽管 OPD 在理论上具有优势,但在实际应用中,研究者发现其训练过程往往不稳定,且难以复现预期的性能提升。本文正是在这一背景下,深入探究了 OPD 训练不稳定的内在机制,并提出了相应的解决方案。
❗问题与挑战
本文作者通过大量的实证研究,揭示了 OPD 中一种特定的训练病理(Training Pathology),即"截断-重复膨胀"(Truncation-Repetition Inflation)。具体的问题与挑战如下:
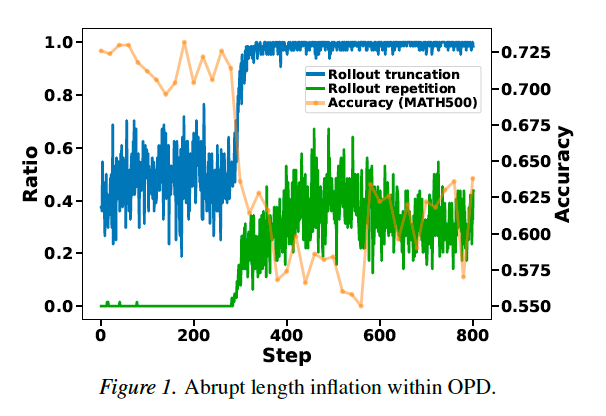
2.1 突发性的长度膨胀与截断崩溃
在 OPD 训练初期,模型表现正常,生成的推理链长度适中且能正常结束(EOS)。然而,随着训练步数的增加(例如在几百步内),模型会突然进入一个失效状态。此时,学生模型生成的轨迹长度急剧增加,直到达到预设的最大长度限制(Context Length)被强制截断。这种现象被称为"长度膨胀"。由于大量样本被截断,有效的训练信号减少,导致模型性能急剧下降,即"截断崩溃"。
2.2 重复饱和(Repetition Saturation)
这种长度膨胀并非由复杂的推理过程引起,而是由"重复"驱动的。作者发现,膨胀的轨迹尾部往往包含大量无意义的重复 Token(如循环的短语或字符)。这种现象被称为"重复饱和"。一旦模型开始重复,它会陷入自我强化的循环中无法自拔。
2.3 机制分析:为什么会出现这种现象?
作者深入分析了其背后的数学机制,指出这是由 Reverse-KL(反向 KL 散度)优势函数 与 在线采样 的相互作用导致的:
隐式偏好: OPD 使用基于 Reverse-KL 的奖励机制。实验证明,重复的 Token 往往会获得比正常 Token 更大的优势值(Advantage)。
反馈循环: 在训练初期,重复 Token 很少见,因此影响不大。但一旦由于随机波动出现了一些重复,这些 Token 获得了高奖励。由于 OPD 是基于当前策略采样的,模型在下一次更新中会更倾向于生成这些高奖励(重复)的 Token。这形成了一个正反馈循环:重复导致高奖励,高奖励导致更多重复,最终导致长度爆炸和训练崩溃。
梯度偏差: 当重复 Token 占据主导地位时,它们主导了梯度更新的方向,使得模型忽略了真正有价值的推理信息,导致验证准确率骤降。
⚙️ 算法模型
为了解决上述问题,论文提出了 Stable-OPD,这是一个结合了混合蒸馏(Mixture Distillation)和KL 正则化(KL Regularization)的双重稳定框架。
3.1 混合蒸馏 (Mixture Distillation)
标准 OPD 仅依赖学生模型当前生成的轨迹,这容易陷入退化分布。混合蒸馏引入了"黄金数据"(Golden Data)作为锚点。
核心思想: 在训练批次中,同时包含两部分数据:
On-policy Rollouts: 学生模型自己生成的轨迹(保持在线策略特性)。
Off-policy Golden Data: 预先收集的高质量、完整的推理链数据(保持高质量分布)。
实现方式: 模型在优化时,同时最小化 OPD 损失和监督微调(SFT)损失。
L_{mix}(theta) = L_{OPD}(theta) + lambda_{gold} mathbb{E{(x,y)sim D{gold}} L_{SFT}(theta; x, y)
作用: 黄金数据充当了"路标",确保即使学生模型开始生成截断或重复的垃圾文本,模型依然能从高质量数据中学习到正确的推理模式,防止训练完全崩溃。
3.2 基于参考的散度约束 (Reference-based Divergence Constraint)
为了防止策略在单步更新中发生剧烈漂移,引入了 KL 正则化项。
核心思想: 引入一个参考策略 pi_{ref}(通常是训练初期的检查点),惩罚学生策略 pi_theta 与参考策略之间的 KL 散度。
实现方式: 在损失函数中增加一个 KL 正则化项:
L_{final}(theta) = L_{mix}(theta) - beta_{KL} mathbb{E{s sim d{pi_theta}, y} D_{KL}(pi_theta(cdot\|s) \| pi_{ref}(cdot\|s))
作用: 这限制了策略更新的步长(Trust Region),防止模型为了追求 Reverse-KL 奖励而过快地进入重复 Token 的区域。它就像一个"刹车",阻止了突发的重复饱和。
3.3 总结
Stable-OPD 通过 混合蒸馏 从数据分布层面维持了训练的稳定性,防止截断主导;通过 KL 正则化 从优化更新层面防止了策略的剧烈偏移。两者结合,打破了"重复导致高奖励,高奖励导致更多重复"的恶性循环。
💡 创新点
揭示了 OPD 的特定失效模式(Length Inflation): 论文首次明确指出了在推理任务中,OPD 会经历一种由"重复饱和"驱动的"突发性长度膨胀"。这与传统的 RL 中的长度偏差(Length Bias)有本质区别,它是 OPD 特有的病理。
机制归因(Reverse-KL 的漏洞): 论文深入剖析了 Reverse-KL 目标函数,证明了重复 Token 会系统性地获得更大的优势值。这解释了为什么模型会"利用"蒸馏目标函数的漏洞,通过生成重复文本来自我欺骗(Hacking the Objective)。
提出了双重稳定框架(Stable-OPD): 提出的解决方案并非单一手段,而是结合了外部监督(混合蒸馏)和内部约束(KL 正则化)的双管齐下策略。这种方法不仅解决了问题,还保持了 OPD 的核心优势(在线策略对齐)。
量化指标的提出: 论文定义了"截断率(Truncation Rate)"和"重复率(Repetition Rate)"作为监控 OPD 训练动态的关键指标,为诊断此类问题提供了工具。
📊 实验效果(重要数据与结论)
5.1 实验设置
数据集: OpenR1-Math-220k(过滤后约 46k 样本)。
基准测试: MATH-500, Minerva, Olympiad, AMC, AIME2024, AIME2025。
模型架构: Qwen2.5-Math 系列(1.5B 和 7B 参数)。
对比基线: SFT(监督微调)、GRPO(分组相对策略优化)、SimpleRL-Zero、OpenReasoner-Zero、标准 OPD。
5.2 核心结论
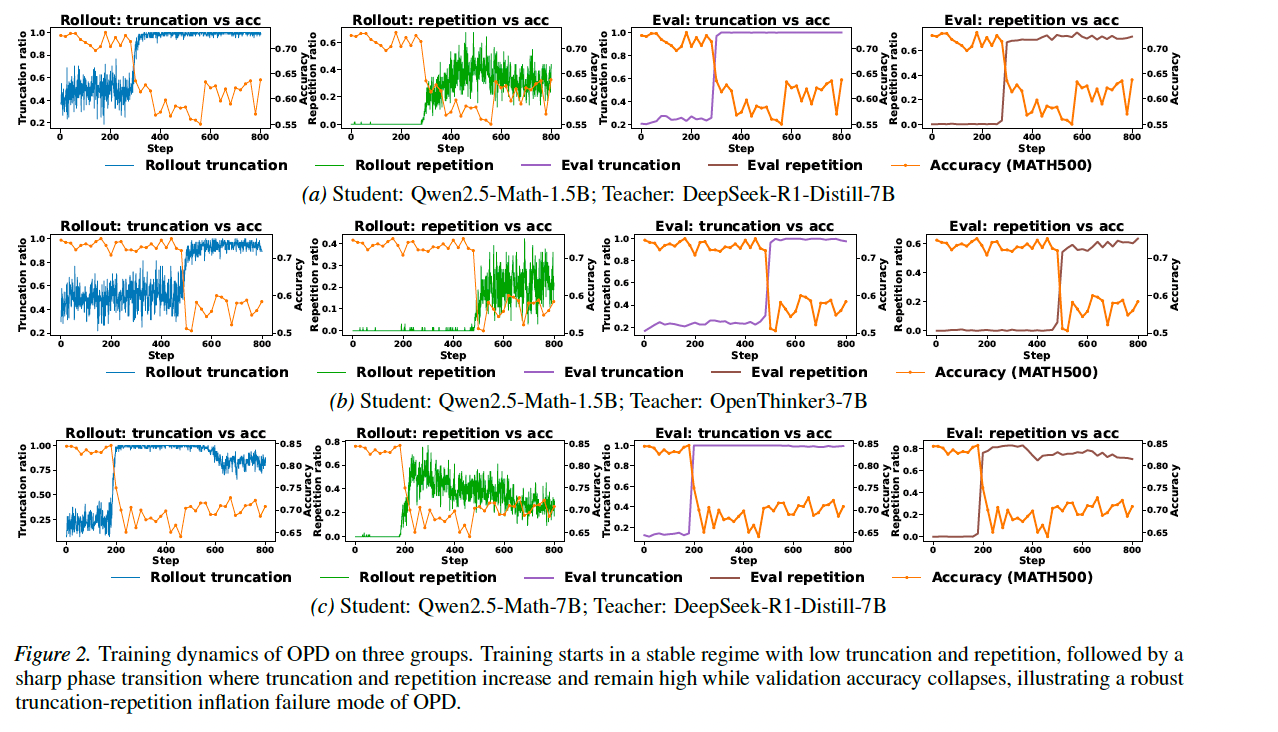
标准 OPD 的不稳定性得到验证: 在所有实验设置中,标准 OPD 最终都经历了截断率飙升(接近 100%)和准确率骤降的过程,证明了该失效模式的鲁棒性。
Stable-OPD 的性能提升:
在 1.5B 模型上,Stable-OPD 将平均准确率从标准 OPD 的 28.9% 提升至 36.1%(绝对提升 7.2%)。
在 7B 模型上,Stable-OPD 达到了 47.6% 的平均准确率,超过了 SFT (44.1%)、GRPO (45.5%) 以及其他的 RLVR 方法(如 SimpleRL-Zero 等)。
训练动态的稳定性: 实验监控显示,Stable-OPD 的截断率和重复率在整个训练过程中保持平稳,没有出现标准 OPD 中的突发性尖峰。
消融研究: 仅添加 KL 正则化或仅添加混合蒸馏都有一定效果,但两者结合的效果最好,证明了两种机制的互补性。
📈 推荐阅读指数
推荐指数
⭐⭐⭐⭐⭐ (4.5/5)
推荐理由
切中要害: 论文解决的是当前大模型推理(Reasoning)领域最热门的 RL/蒸馏方向中的核心痛点------训练不稳定性。对于任何尝试复现或改进 OPD 的研究者来说,这是一篇必读文献。
分析深度: 作者没有停留在现象表面(如"模型训练崩了"),而是深入到了数学机制层面(Reverse-KL 与采样分布的相互作用),解释了为什么会发生这种崩溃。这种深度的理论分析在工程导向的 AI 论文中非常难得。
实用价值高: 提出的 Stable-OPD 方法简单有效,且具有很强的通用性。它不仅修复了 OPD 的缺陷,还使其性能超越了现有的 SOTA 方法(如 GRPO),具有很高的工程落地参考价值。
严谨性: 论文通过大量的消融实验和可视化分析(如截断率与准确率的动态图),有力地支撑了其论点。
总结与展望
7.1 总结
本文通过深入研究在线策略蒸馏(OPD)的训练动态,揭示了其在推理任务中面临的一个致命缺陷:由 Reverse-KL 优势函数漏洞引发的"突发性重复膨胀"。这种病理导致模型陷入生成无限长重复文本的死循环,最终导致训练崩溃。为了解决这一问题,作者提出了 Stable-OPD 框架,通过引入"混合蒸馏"以保持高质量数据锚点,以及"参考策略约束"以限制更新步长,成功打破了恶性循环。实验证明,Stable-OPD 不仅解决了训练不稳定问题,还显著提升了模型在数学推理任务上的性能。
7.2 展望
基于本文的研究,未来的研究方向可能包括:
替代奖励机制: 既然 Reverse-KL 存在偏好重复的固有缺陷,未来的研究可以探索基于 Forward-KL 或其他形式的散度度量,或者结合显式的长度惩罚项,从根本上消除对长序列的隐式偏好。
动态混合策略: 目前的混合蒸馏使用了固定的黄金数据集。未来可以探索动态混合,即根据模型当前的截断率或重复率自动调整黄金数据的比例,以提高训练效率。
扩展到多模态: OPD 和 Stable-OPD 的理念可以扩展到多模态大模型(MLLM)的训练中,探究在图像生成或视频生成任务中,类似的"模式崩溃"或"长度偏差"是否也会发生,并应用类似的稳定化策略。
理论边界: 进一步理论化分析在什么数据分布或模型规模下,这种长度膨胀现象最容易发生,从而为大规模模型训练提供更精确的指导原则。
后记
- 如果您对我的博客内容感兴趣,欢迎三连击(点赞, 关注和评论) !!!
- 本博客将持续为您带来计算机人工智能前沿技术研究进展分享,助您更快了解 AI前沿技术。