
🎬 渡水无言 :个人主页渡水无言
❄专栏传送门 : 《linux专栏》《嵌入式linux驱动开发》《linux系统移植专栏》
❄专栏传送门 : 《freertos专栏》 《STM32 HAL库专栏》《linux裸机开发专栏》
❄专栏传送门 :《产品测评专栏》
⭐️流水不争先,争的是滔滔不绝
📚博主简介:第二十届中国研究生电子设计竞赛全国二等奖 |国家奖学金 | 省级三好学生
| 省级优秀毕业生获得者 | csdn新星杯TOP18 | 半导纵横专栏博主 | 211在读研究生
在这里主要分享自己学习的linux嵌入式领域知识;有分享错误或者不足的地方欢迎大佬指导,也欢迎各位大佬互相三连

目录
[五、CRC16 校验原理与实现](#五、CRC16 校验原理与实现)
[5.2、CRC 计算范围](#5.2、CRC 计算范围)
[5.3、CRC 计算步骤](#5.3、CRC 计算步骤)
[5.5、为什么选择边收边算 CRC?](#5.5、为什么选择边收边算 CRC?)
前言
在嵌入式机器人、物联网等项目中,上位机与下位机的稳定通信 是核心基础功能。本文以 STM32+FreeRTOS 平台为基础,完整讲解一套工业级串口通信方案:从CommunicationTask通信任务设计、自定义协议帧格式、大小端处理,到 CRC16 校验的原理与代码实现,全流程覆盖。
一、CommunicationTask通信任务整体设计
CommunicationTask是系统负责通信数据接收与解析的核心任务,核心作用是:
接收上位机 / 外部设备的串口原始字节流
完成数据缓存、拆包、校验
解析有效指令后,通知ControlTask等业务任务执行
支持后续通信功能扩展

UART 接收方案:STM32 DMA 环形模式 + 空闲中断,实现无阻塞串口数据接收,空闲中断触发后及时处理数据,避免丢包。
流缓冲区:FreeRTOS StreamBuffer实现中断与任务间的数据解耦,CommTask阻塞读取,不占用 CPU 资源
状态机解析:逐字节匹配协议帧格式,支持变长数据,适配流式数据接收
线程安全:全局命令更新使用taskENTER_CRITICAL/EXIT_CRITICAL临界区保护,避免多任务数据竞争
任务通知:通过 FreeRTOS 任务通知唤醒ControlTask,替代队列实现高效任务间通信
二、自定义协议帧格式设计
上位机与下位机通信需遵循统一协议格式,本方案自定义协议帧结构如下:
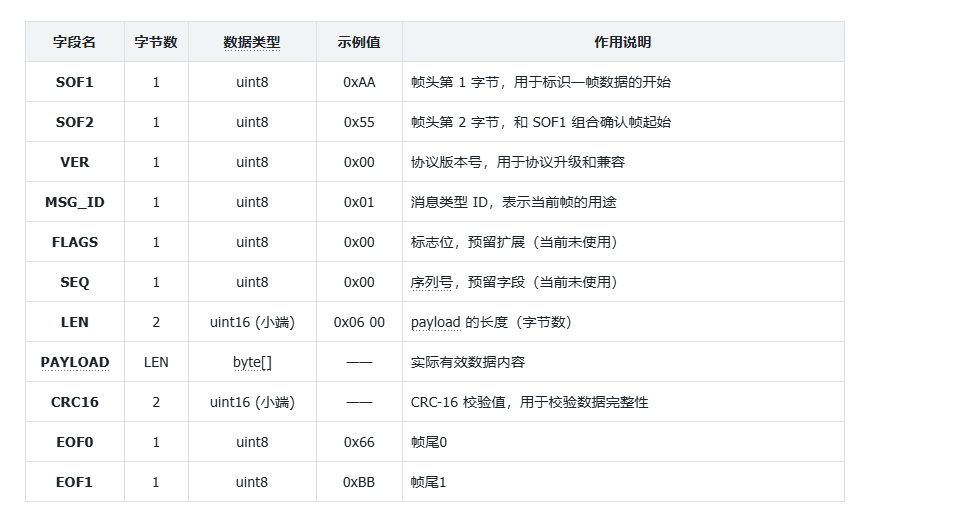
一帧数据完整结构:帧头 → 描述信息 → 实际数据 → 校验码 → 帧尾,各字段作用详解:

(1)SOF1/SOF2(帧头)
SOF1和SOF2是帧头标识,用于告诉接收端"一帧数据从这里开始"。
双字节固定帧头(0xAA 0x55),解决单字节帧头的误判问题:避免payload(实际数据)中出现相同字节导致的帧同步错误,同时处理帧头重叠场景(如AA AA 55),解析器会把第二个AA作为下一帧帧头,保证数据同步。
(2)VER(协议版本号)
用于协议版本兼容,接收端校验版本号,若版本不匹配直接丢弃帧,不进入业务处理,避免协议升级导致的解析错误。
(3)MSG_ID(消息类型)
标识帧的业务类型,决定payload(实际数据)应该如何解释。不同MSG_ID对应不同解析逻辑:本方案中0x01对应速度控制指令CMD_VEL,后续可扩展其他指令(如状态查询、配置设置等),实现协议灵活扩展。
(4)FLAGS(标志位)
FLAGS预留字段,用于后续功能扩展(如FLAGS标识应答 / 广播、SEQ用于丢包重传),当前固定为0x00,解析时严格校验。
(5)SEQ(序列号)
SEQ为序列号字段,通常用于检测丢包、乱序或实现请求等功能。本次不使用该字段,直接固定为0x00。
(6)LEN(payload 长度)
LEN表示payload的长度 2字节,采用小端存储格式(低字节在前,高字节在后),该字段的作用是支持变长payload,支持变长数据,接收端根据长度读取有效数据,避免缓冲区越界。
(7)PAYLOAD(有效载荷)
PAYLOAD是协议承载的实际业务数据。
本方案中CMD_VEL指令对应 6 字节数据,包含 3 个int16(小端)字段:
vx:X 方向线速度(单位:mm/s)
vy:Y 方向线速度(单位:mm/s)
wz:角速度(单位:mrad/s)
(8)CRC16(校验字段)
CRC16用于检测整帧数据在传输过程中是否发生错误。用于校验数据传输完整性,
校验范围为:VER到PAYLOAD的所有字节,不包含帧头、帧尾和 CRC 字段本身。
2 字节小端 CRC-16 校验值,
(9)EOF1/EOF2(帧尾)
帧尾。
三、协议帧示例
示例指令
上位机发送指令:
AA 55 00 01 00 00 06 00 64 00 00 00 CE FF B2 4F 66 BB
逐字段解析:
| 字节段 | 字段名 | 解析说明 |
|---|---|---|
AA 55 |
SOF | 帧头,标识帧起始 |
00 |
VER | 协议版本 0x00,校验通过 |
01 |
MSG_ID | 速度控制指令CMD_VEL |
00 |
FLAGS | 预留位,校验通过 |
00 |
SEQ | 预留位,校验通过 |
06 00 |
LEN | 小端转换为 0x0006,payload 长度 6 字节 |
64 00 00 00 CE FF |
PAYLOAD | 按CMD_VEL解析:- 64 00 → vx=100 mm/s 00 00 → vy=0 mm/s CE FF → wz=-50 mrad/s |
B2 4F |
CRC16 | 小端 CRC 校验值,校验通过 |
66 BB |
EOF | 帧尾,校验通过 |
四、大小端(字节序)详解
在通信协议中,当一个数值占用多个字节时,这些字节在数据流中的排列顺序并不是随意的,而是需要提前约定,这种排列规则称为字节序(Endianness)。如果发送端和接收端对字节序的理解不一致,即使字节本身没有出错,解析出来的数值也会完全错误,因此字节序是二进制通信协议中非常基础且重要的概念。
常见的字节序有两种:大端序 和小端序。
大端序(高位字节在前):高位字节存储在内存的低地址处,低位字节存储在内存的高地址处。
很多网络协议(如 TCP/IP 协议)都是采用的大端序,所以大端序也常称为网络字节序。
小端序(低位字节在前):低位字节存储在内存的低地址处,高位字节存储在内存的高地址处。
对于STM32等基于Cortex-M内核的MCU,其内部存储基本用的都是小端格式,所以在嵌入式通信协议中常使用小端序。
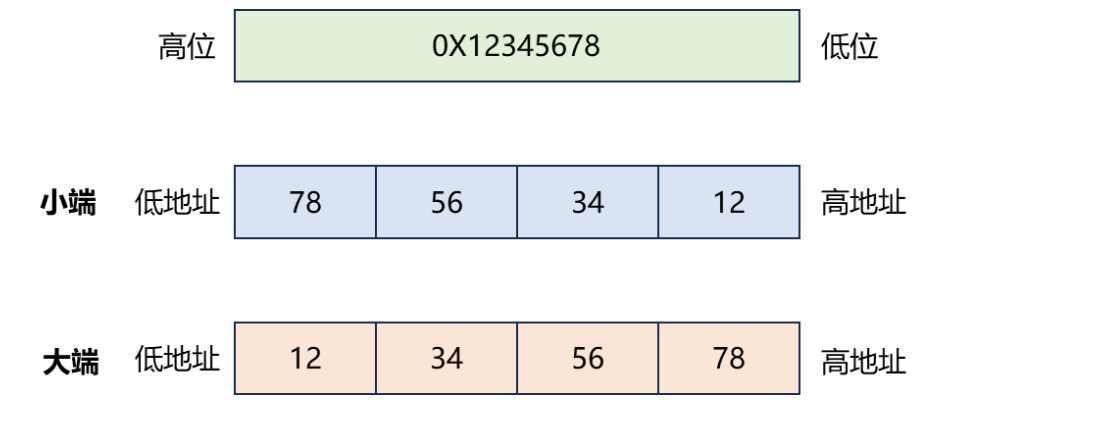
以 16 位数值0x1234为例:
大端存储:低地址0x12(高位),高地址0x34(低位)
小端存储:低地址0x34(低位),高地址0x12(高位)
五、CRC16 校验原理与实现
在通信中,可能因为某些原因会导致比特发生错误,为了判断一帧数据在传输过程中是否被破坏,通信协议中常常会引入一种完整的校验机制,CRC就是其中常用的一种。
5.1、CRC核心思想
CRC 的核心思想为:发送端根据数据计算出一个校验值,并将该校验值附加在数据末尾一起发送,接收端在收到数据后,使用相同算法计算一次校验值,与接收的校验值进行比较,一致则数据有效,不一致则丢弃。
本次采用的是CRC-16/ CCITT-FALSE算法。这是一种在嵌入式系统和工业通信中广泛使用的CRC变体。该算法关键参数固定如下:
多项式:0x1021 初始值:0xFFFF
不对输入或输出数据进行位反转,也不额外进行异或处理。
5.2、CRC 计算范围
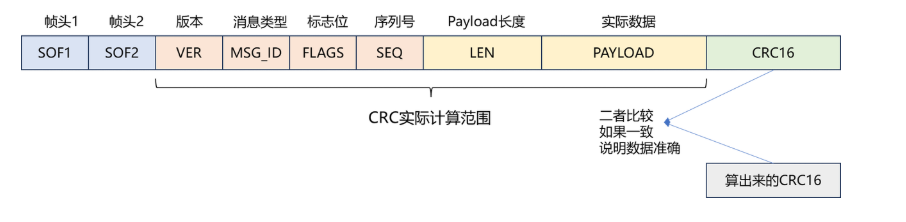
本协议中,CRC 计算范围为 VER到PAYLOAD的所有字节,不包含帧头(SOF1/SOF2)、CRC 字段本身和帧尾,收发端需严格遵循该范围,否则校验失败。
从实现层面来看,CRC 校验并非等整帧数据接收完成后再一次性计算,而是采用逐字节累加迭代的方式:解析器每收到一个属于 CRC 计算范围的字节,就会立刻更新当前的 CRC 校验值(边接收、边计算)。当 payload(有效载荷)全部接收完成时,本地的 CRC 计算结果也已经生成,此时只需再接收对方发来的 2 字节 CRC 校验码,直接对比两者是否一致,就能完成校验。
5.3、CRC 计算步骤
初始化 CRC 值:初始值设为0xFFFF。
确定计算范围:从VER字节开始,到PAYLOAD最后一个字节结束。
逐字节更新 CRC:每收到一个属于 CRC 范围的字节,立即更新 CRC 值(边收边算)。
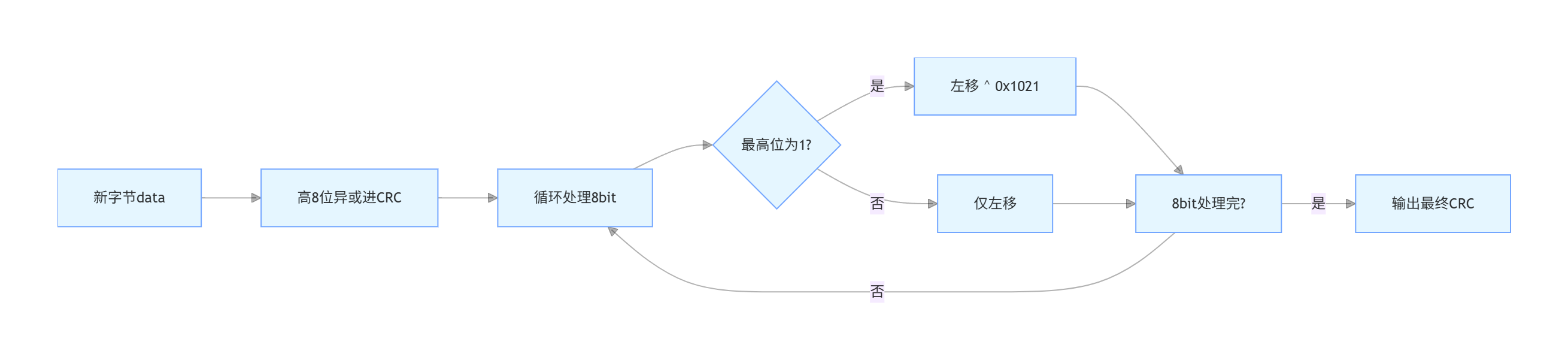
一个字节内部的计算过程:
对 "每一个字节",CRC 内部会做三件事:把当前字节放到 CRC 的高 8 位、循环 8 次(因为 1 个字节共 8 位),每一位都进行一次左移,并根据最高位决定是否异或多项式 0x1021。
接收端校验方式:payload接收完成后,将本地计算的 CRC 与接收的 CRC16 字段对比,一致则校验通过。
具体如下图所示:
5.4、具体CRC代码实现
cpp
// ==============================================
// CRC-16/CCITT-FALSE(位运算版)
// 参数:
// poly = 0x1021 多项式
// init = 0xFFFF 初始值
// refin = false 输入不反转
// refout = false 输出不反转
// xorout = 0x0000 结果不异或
// 说明:
// - 每收到一个字节就更新一次CRC(流式计算)
// - CRC 起算点: VER 字节(见 parser 状态机)
// ==============================================
static inline uint16_t crc16_ccitt_update(uint16_t crc, uint8_t data)
{
// 1. 将新字节 异或 进 CRC 的高 8 位
crc ^= (uint16_t)data << 8;
// 2. 对 8 bit 逐位计算
for (int i = 0; i < 8; i++) {
if (crc & 0x8000) // 如果最高位是 1
{
// 左移1位 + 异或多项式 0x1021
crc = (crc << 1) ^ 0x1021;
}
else // 如果最高位是 0
{
// 只左移1位
crc = crc << 1;
}
}
return crc;
}新字节 → 塞到 CRC 高 8 位
从高位到低位逐位移位
最高位为 1 → 左移 + 异或 0x1021
最高位为 0 → 只左移
循环 8 次完成 1 字节计算
5.5、为什么选择边收边算 CRC?
减少内存占用:无需为每一帧分配完整缓冲区,适合 MCU 资源受限场景,避免内存浪费
适配状态机模型:协议解析采用状态机逐字节推进,边收边算与状态机流程天然契合,无需额外缓存
实时性更高:数据接收完成即可完成 CRC 计算,无需等待整帧接收,提升解析效率
总结
本文完整实现了一套 STM32+FreeRTOS 平台的工业级串口通信方案,核心要点如下:
任务架构:CommTask+DMA + 流缓冲区,实现中断与任务解耦,保证通信稳定性
协议设计:自定义双帧头 + 变长 payload+CRC 校验,兼顾兼容性、扩展性与可靠性
细节处理:小端格式适配 STM32,边收边算 CRC 优化资源占用,临界区保证线程安全
工程复用:整套方案可直接复用在机器人、物联网等嵌入式项目中,支持快速扩展新指令