📚 目录
- [✍️ 前言](#✍️ 前言)
- [1️⃣ 前提与基本定义](#1️⃣ 前提与基本定义)
-
- [1.1 📌 基本信号模型](#1.1 📌 基本信号模型)
- [1.2 📎 信号与噪声独立性假设](#1.2 📎 信号与噪声独立性假设)
- [1.3 ⚠️ 前提意义](#1.3 ⚠️ 前提意义)
- [2️⃣ 后验信噪比(a posteriori SNR)](#2️⃣ 后验信噪比(a posteriori SNR))
-
- [2.1 📌 定义](#2.1 📌 定义)
- [2.2 📊 公式推导](#2.2 📊 公式推导)
- [2.3 📌 物理意义](#2.3 📌 物理意义)
- [2.4 ⚡ 特点](#2.4 ⚡ 特点)
- [3️⃣ 先验信噪比(a priori SNR)](#3️⃣ 先验信噪比(a priori SNR))
-
- [3.1 📌 定义](#3.1 📌 定义)
- [3.2 🧠 Decision-Directed(DD)算法](#3.2 🧠 Decision-Directed(DD)算法)
-
- [3.2.1 📌 背景](#3.2.1 📌 背景)
- [3.2.2 💡 核心思想](#3.2.2 💡 核心思想)
- [3.2.3 📌 核心公式](#3.2.3 📌 核心公式)
- [3.3 ⚖️DD算法核心](#3.3 ⚖️DD算法核心)
-
- [3.3.1 ⚙️即时决策策略](#3.3.1 ⚙️即时决策策略)
- [3.3.2 📊DD平滑设计思路](#3.3.2 📊DD平滑设计思路)
- [4️⃣ 噪声估计方法](#4️⃣ 噪声估计方法)
-
- [4.1 📌 最小值跟踪法](#4.1 📌 最小值跟踪法)
- [4.2 📌 VAD 引导更新](#4.2 📌 VAD 引导更新)
- [4.3📌 MCRA 方法](#4.3📌 MCRA 方法)
-
- [4.3.1 🎯目的](#4.3.1 🎯目的)
- [4.3.2 🧠策略](#4.3.2 🧠策略)
-
- [📎 平滑功率谱](#📎 平滑功率谱)
- [📎 最小值跟踪](#📎 最小值跟踪)
- [📎 语音概率](#📎 语音概率)
- [📎 核心:动态平滑噪声估计](#📎 核心:动态平滑噪声估计)
- [4.4 📊工程实现](#4.4 📊工程实现)
- [5️⃣ 先验 vs 后验 SNR(Matlab仿真)](#5️⃣ 先验 vs 后验 SNR(Matlab仿真))
-
- [5.1 🧪 MATLAB代码](#5.1 🧪 MATLAB代码)
- [5.2 📊 结果分析](#5.2 📊 结果分析)
-
- [📌 整体对比](#📌 整体对比)
- [📌 系数影响](#📌 系数影响)
- [📌 动态差异](#📌 动态差异)
- [🧾 总结](#🧾 总结)
✍️ 前言
在语音增强与降噪处理中,信噪比(SNR)是最基础也是最关键的评价指标。然而由于实际场景中无法获取干净语音,所有 SNR 相关量都必须基于观测信号进行估计。
其中,后验信噪比(a posteriori SNR)可以由当前帧直接计算得到,具有实时性强但波动较大的特点;而先验信噪比(a priori SNR)则反映语音真实功率的统计估计,通常需要结合历史信息进行递推和平滑,从而获得更稳定的结果。
这两者构成了 Wiener 滤波与 MMSE 类语音增强算法的核心基础,并广泛应用于语音降噪、回声消除与语音识别前端处理等系统中。
本文将介绍先验与后验信噪比的定义、推导关系以及 Decision-Directed 方法,并通过 MATLAB 仿真对其时频特性进行对比分析。
📌 作者:山河君,未经允许禁止转载
1️⃣ 前提与基本定义
1.1 📌 基本信号模型
假设语音信号 x ( n ) x(n) x(n) 被噪声 d ( n ) d(n) d(n) 污染,观测到的信号是:
y n = x n + d n yn=xn+dn yn=xn+dn
经过短时傅里叶变换(STFT)到频域后,表示为:
Y ( k , m ) = X ( k , m ) + D ( k , m ) Y(k,m)=X(k,m)+D(k,m) Y(k,m)=X(k,m)+D(k,m)
📌 其中:
- k k k是频率索引
- m m m是帧索引
1.2 📎 信号与噪声独立性假设
在公式推导中,通常有信号 x n xn xn与噪声 d n dn dn独立(或者正交),即:
E x \[ n d ∗ n ] = 0 Ex\[nd^*n]=0 Ex\[nd∗n]=0
📌 含义说明:
- x n xn xn:干净语音信号在时刻 n n n的样本。
- d n dn dn:噪声信号在时刻 n n n的样本。
- d ∗ n d^*n d∗n: d n dn dn 的复共轭(如果信号是实数, d ∗ n = d n d^*n=dn d∗n=dn)
- E ⋅ E\\cdot E⋅:数学期望,也就是平均值(统计意义上对所有可能信号的平均)。
这个独立性假设是 MMSE/Wiener 增益公式能简化成频域 SNR 形式的关键。因为:
E ∣ Y k ∣ 2 = E ∣ X k + D k ∣ 2 = E ∣ X k ∣ 2 + E ∣ D k ∣ 2 + 2 ℜ E X k D k ∗ E\|Y_k\|\^2=E\|X_k+D_k\|\^2=E\|X_k\|\^2+E\|D_k\|\^2+2\Re{EX_kD\^\*_k} E∣Yk∣2=E∣Xk+Dk∣2=E∣Xk∣2+E∣Dk∣2+2ℜEXkDk∗
只有当 X k X_k Xk与 D k ∗ D^*_k Dk∗正交,最后一项才为0:
E ∣ Y k ∣ 2 = E ∣ X k ∣ 2 + E ∣ D k ∣ 2 E\|Y_k\|\^2=E\|X_k\|\^2+E\|D_k\|\^2 E∣Yk∣2=E∣Xk∣2+E∣Dk∣2
1.3 ⚠️ 前提意义
- 先验 SNR 和后验 SNR 的推导都假设了语音信号和噪声不相关/正交。
- 这个假设在实际中近似成立,尤其是噪声是环境噪声、机械噪声时。
- 如果噪声与语音相关(比如混响或干扰语音),这个假设就不完全成立,SNR 估计可能偏差。
2️⃣ 后验信噪比(a posteriori SNR)
2.1 📌 定义
后验信噪比是观测信号当前帧的信噪比,定义符号 γ ( k ) \gamma(k) γ(k)表示为后验信噪比,其公式为:
γ ( k , m ) = ∣ Y ( k , m ) ∣ 2 λ d ( k , m ) \gamma(k,m)=\frac{|Y(k,m)|^2}{\lambda_d(k,m)} γ(k,m)=λd(k,m)∣Y(k,m)∣2
📌 说明:
- ∣ Y ( k , m ) ∣ 2 |Y(k,m)|^2 ∣Y(k,m)∣2是当前帧的功率谱
- λ d ( k , m ) \lambda_d(k,m) λd(k,m)是噪声功率谱(通常通过噪声估计获得)
2.2 📊 公式推导
对于公式:
γ ( k ) = ∣ Y ( k ) ∣ 2 λ d ( k ) \gamma(k)=\frac{|Y(k)|^2}{\lambda_d(k)} γ(k)=λd(k)∣Y(k)∣2
按照上文对于信噪比前提噪声与信号不相关,所以
E ∣ Y k ∣ 2 = E ∣ X k + D k ∣ 2 ⟶ E ∣ Y k ∣ 2 = λ x + λ d E\|Y_k\|\^2=E\|X_k+D_k\|\^2\longrightarrow E\|Y_k\|\^2=\lambda_x+\lambda_d E∣Yk∣2=E∣Xk+Dk∣2⟶E∣Yk∣2=λx+λd
将其带入可得:
γ ( k ) = ∣ Y ( k ) ∣ 2 λ d ( k ) = λ x + λ d λ d = 1 + λ x λ d \gamma(k)=\frac{|Y(k)|^2}{\lambda_d(k)}=\frac{\lambda_x+\lambda_d}{\lambda_d}=1+\frac{\lambda_x}{\lambda_d} γ(k)=λd(k)∣Y(k)∣2=λdλx+λd=1+λdλx
2.3 📌 物理意义
| 情况 | 表现 |
|---|---|
| λ x > > λ d → γ ( k ) > > 1 \lambda_x>>\lambda_d\rightarrow\gamma(k)>>1 λx>>λd→γ(k)>>1 | 有语音 |
| λ x < < λ d → γ ( k ) ≈ 1 \lambda_x << \lambda_d\rightarrow\gamma(k) \approx1 λx<<λd→γ(k)≈1 | 无语音 |
2.4 ⚡ 特点
在真实的语音场景下,会存在:
- 噪声是随机的,即使是纯噪声, ∣ Y ( k ) ∣ 2 |Y(k)|^2 ∣Y(k)∣2 本身也会波动,所以 γ ( k ) \gamma(k) γ(k) 会上下乱跳
- 有爆破音(突然大),有静音段(突然小),这就导致 γ ( k , m ) \gamma(k,m) γ(k,m)在时间上会剧烈波动
- 设计目的是反映了当前观测的信号比噪声强多少,只依赖于当前帧,属于"即时信噪比",即没有平滑概念
基于以上可以分析出后验信噪比的特点
| 特点 | 说明 |
|---|---|
| 实时性强 | 直接从当前帧算 |
| 抖动大 | 因为包含噪声 |
| 不稳定 | 不能直接用来控制 |
3️⃣ 先验信噪比(a priori SNR)
3.1 📌 定义
先验信噪比是指在估计语音之前,对语音信号功率的先验信念,使用 ξ ( k ) \xi(k) ξ(k)表示,其公式为:
ξ ( k , m ) = E ∣ X ( k , m ) ∣ 2 λ d ( k , m ) \xi(k,m)=\frac{\mathbb{E}\|X(k,m)\|\^2}{\lambda_d(k,m)} ξ(k,m)=λd(k,m)E∣X(k,m)∣2
其中:
- E ∣ X ( k , m ) ∣ 2 \mathbb{E}\|X(k,m)\|\^2 E∣X(k,m)∣2表示纯净语音信号功率谱
- λ d ( k , m ) \lambda_d(k,m) λd(k,m)是噪声功率谱
📌 实际问题:
在实际应用中根本不可能直接拿到干净语音,也就获取不到 X ( k , m ) X(k,m) X(k,m),所以必须用估计的 S ^ ( k , m ) \hat{S}(k,m) S^(k,m)来代替。而最常用的办法是Decision-directed算法。
3.2 🧠 Decision-Directed(DD)算法
3.2.1 📌 背景
在 1970 年代末到 1980 年代初,语音增强主要面对的问题是:
- 电话、通信系统或语音识别中的背景噪声
- 当时的方法多是谱减法(Spectral Subtraction):
X ^ ( k ) = Y ( k ) − D ^ ( k ) \hat{X}(k)=Y(k)-\hat{D}(k) X^(k)=Y(k)−D^(k)
但谱减法有两个问题:
- 产生"音乐噪声(musical noise)"
- 对低 SNR 情况下语音质量差
为了解决这些问题
- 1984 年:Yehuda Ephraim 和 David Malah 提出 MMSE 语谱幅度估计(Minimum Mean-Square Error Short-Time Spectral Amplitude, MMSE-STSA)
- 1985 年:进一步提出 Decision-directed 方法以下简称为DD算法用于先验 SNR 估计
DD算法也是被广泛应用于:
- 噪声抑制(Noise Reduction)
- 回声消除后语音增强(Post-Processing of AEC)
- 语音识别前端增强
可以经常在MMSE、winner滤波、webrtc ANS中经常看到。
3.2.2 💡 核心思想
既然无法知道干净的语音功率 X ( k , m ) X(k,m) X(k,m),那么:
- 使用上一帧的干净语音估计 X ^ ( k , m − 1 ) \hat{X}(k,m-1) X^(k,m−1)来指导当前帧的 SNR 估计
- 引入平滑系数 α \alpha α平衡历史估计和当前观测
这个方法显著改善了:
- 语音的自然性(减少"音乐噪声")
- 低 SNR 下的增强效果
3.2.3 📌 核心公式
对于DD算法公式为:
ξ ^ ( k , m ) = α ∣ X ^ ( k , m − 1 ) ∣ 2 λ d ( k , m ) + ( 1 − α ) max ( γ ( k , m ) − 1 , 0 ) \hat{\xi}(k,m)=\alpha\frac{|\hat{X}(k,m-1)|^2}{\lambda_d(k,m)}+(1-\alpha)\max(\gamma(k,m)-1,0) ξ^(k,m)=αλd(k,m)∣X^(k,m−1)∣2+(1−α)max(γ(k,m)−1,0)
其中
- ξ ^ ( k , m ) \hat{\xi}(k,m) ξ^(k,m):当前帧的先验 SNR 估计
- ∣ X ^ ( k , m − 1 ) ∣ 2 |\hat{X}(k,m-1)|^2 ∣X^(k,m−1)∣2:上一帧的干净语音估计功率
- λ d ( k , m ) \lambda_d(k,m) λd(k,m):当前噪声功率谱估计
- α ∈ 0.95 , 0.99 \alpha \in 0.95,0.99 α∈0.95,0.99:平滑系数(通常 0.95~0.99)
- 决定平滑程度,高 α → \alpha \rightarrow α→ 更平滑、响应慢
- 低 α → \alpha \rightarrow α→ 响应快、可能出现"啸叫"或抖动
3.3 ⚖️DD算法核心
3.3.1 ⚙️即时决策策略
对于公式第二项 ( 1 − α ) max ( γ ( k , m ) − 1 , 0 ) (1-\alpha)\max(\gamma(k,m)-1,0) (1−α)max(γ(k,m)−1,0),先看后验信噪比部分:
γ ( k ) = 1 + λ x λ d \gamma(k)=1+\frac{\lambda_x}{\lambda_d} γ(k)=1+λdλx
其中 λ x λ d \frac{\lambda_x}{\lambda_d} λdλx就是先验信噪比 ξ ( k ) \xi(k) ξ(k)的定义,那么在理想状态下对于后验信噪比和先验信噪比存在
ξ ( k ) ≈ γ ( k ) − 1 \xi(k)\approx\gamma(k)-1 ξ(k)≈γ(k)−1
所以 γ ( k , m ) − 1 \gamma(k,m)-1 γ(k,m)−1意思是从当前观测直接"粗暴估计"先验 SNR。
而当 γ < 1 \gamma <1 γ<1是噪声占主导,但先验 SNR 不能是负数,所以需要进行 max \max max比较,相当于:
- 有语音 → 给一个正的估计
- 没语音 → 直接认为是 0(纯噪声)
并且在实际进行先验信噪比第一帧确定时,就是来源于后验信噪比
3.3.2 📊DD平滑设计思路
可以对比 decision-directed 的两项:
| 项 | 来源 | 特点 |
|---|---|---|
| 第一项 | 上一帧估计 | 平滑、稳定 |
| 第二项 | 当前观测 | 快速、敏感 |
把它想象为一个"惯性 + 刹车"的系统
- 第一项 α \alpha α:惯性(历史记忆)
- 第二项 α \alpha α:刹车 / 修正(当前反馈)
- α \alpha α的值表示:主要相信历史,只用当前做微调
对于下面场景就可以做到
| 情况 | 上一帧状态 | 当前帧状态 | 第一项(历史项) | 第二项(即时项) | 最终效果 |
|---|---|---|---|---|---|
| 情况1:语音突然出现 | 无语音 | 有语音 | ≈ 0(因为上一帧没语音) | 很大(γ >> 1) | 先验 SNR 快速上升,能跟上语音出现 |
| 情况2:语音突然消失 | 有语音 | 无语音 | 仍然较大(有滞后) | ≈ 0(γ ≈ 1) | 先验 SNR 缓慢下降,避免突兀变化 |
4️⃣ 噪声估计方法
上文中着重讲了干净语音的频谱估计,但无论是先验信噪比还是后验信噪比,都还有一项估计即为噪声估计。噪声估计经常使用的方法为直接最小值法、VAD 引导更新和MCRA / MCRA-β。
4.1 📌 最小值跟踪法
- 思路:噪声通常能量比语音低
- 对每个频点,维护一个 滑动最小值:
λ d ( k ) = min ( λ d ( k − 1 ) , ∣ Y ( k ) ∣ 2 ) \lambda_d(k)=\min(\lambda_d(k-1),|Y(k)|^2) λd(k)=min(λd(k−1),∣Y(k)∣2) - 优点:简单、无需 VAD
- 缺点:慢响应高噪声突变
4.2 📌 VAD 引导更新
- 检测当前帧是否有语音
- 非语音帧更新噪声:
λ d ( k ) = α ( λ d ( k − 1 ) ) + ( 1 − α ) ∣ Y ( k ) ∣ 2 ) \lambda_d(k)=\alpha(\lambda_d(k-1))+(1-\alpha)|Y(k)|^2) λd(k)=α(λd(k−1))+(1−α)∣Y(k)∣2) - α \alpha α:平滑系数(如 0.95~0.99)
- 优点:更准确
- 缺点:需要可靠 VAD
4.3📌 MCRA 方法
4.3.1 🎯目的
所有的噪声估计都存在核心矛盾
噪声估计要"慢"(稳定)
语音检测要"快"(灵敏)
如果只是做平滑系数的话,可能会出现以下问题:
- α \alpha α大 → 噪声跟不上变化
- α \alpha α小 → 语音被当成噪声
而MCRA的本质:动态调 α ( k ) \alpha(k) α(k)
4.3.2 🧠策略
📎 平滑功率谱
先对功率谱做时间平滑:
S ( k , m ) = α s S ( k , m − 1 ) + ( 1 − α s ) ∣ Y ( k , m ) ∣ 2 S(k,m)=\alpha_sS(k,m-1)+(1-\alpha_s)|Y(k,m)|^2 S(k,m)=αsS(k,m−1)+(1−αs)∣Y(k,m)∣2
这一步的目的是降低瞬时波动
📎 最小值跟踪
对每个频点维护一个窗口最小值:
S min ( k , m ) = min ( S ( k , m ) , S min ( k , m − 1 ) ) S_{\min}(k,m)=\min(S(k,m),S_{\min}(k,m-1)) Smin(k,m)=min(S(k,m),Smin(k,m−1))
具体做法:
- 每 L 帧(如 1 秒):
- 重置最小值缓冲区
- 在窗口内:
- 记录局部最小值
这样避免:
- 永远卡在历史最小(过小)
- 无法适应噪声上升
📎 语音概率
定义比值
R ( k , m ) = S ( k , m ) S min ( k , m ) R(k,m)=\frac{S(k,m)}{S_{\min}(k,m)} R(k,m)=Smin(k,m)S(k,m)
典型做法:
- R 小 → p ≈ 0
- R 大 → p ≈ 1
📎 核心:动态平滑噪声估计
后验噪声功率谱递归更新:
λ d ( k , m ) = α d ( k , m ) λ d ( k , m − 1 ) + ( 1 − α d ( k , m ) ) ∣ Y ( k , m ) ∣ 2 \lambda_d(k,m) = \alpha_d(k,m) \, \lambda_d(k,m-1) + \big(1 - \alpha_d(k,m)\big) \, |Y(k,m)|^2 λd(k,m)=αd(k,m)λd(k,m−1)+(1−αd(k,m))∣Y(k,m)∣2
其中动态平滑系数由语音存在概率控制:
α d ( k , m ) = α 0 + ( 1 − α 0 ) ⋅ p ( k , m ) \alpha_d(k,m) = \alpha_0 + \big(1 - \alpha_0\big) \cdot p(k,m) αd(k,m)=α0+(1−α0)⋅p(k,m)
其中 α 0 \alpha_0 α0:基础平滑系数(如 0.9~0.99)
| 情况 | p ( k , m ) p(k,m) p(k,m) | α d ( k , m ) \alpha_d(k,m) αd(k,m) | 结果 |
|---|---|---|---|
| 无语音 | ≈ 0 | 小 | 快速更新噪声 |
| 有语音 | ≈ 1 | 大 | 几乎冻结噪声 |
4.4 📊工程实现
在工程事件中,往往会在系统启动时,可用前 0.2~0.5 秒的静音段平均计算噪声功率谱,然后再采用上述的方法:
- 对 高动态噪声,单纯平滑可能太慢 → 用 MCRA + 动态平滑系数
- 对 低功耗场景(嵌入式 / RK 芯片) → 用 VAD + EMA 就够了
5️⃣ 先验 vs 后验 SNR(Matlab仿真)
现在使用matlab进行先验信噪比和后验信噪比对比
5.1 🧪 MATLAB代码
matlab
clc; clear; close all;
%% 1. 生成示例信号和噪声
fs = 16000;
t = 0:1/fs:1-1/fs;
x = sin(2*pi*440*t); % 模拟语音
noise_power = 0.01;
d = sqrt(noise_power)*randn(size(x));
y = x + d;
%% 2. 分帧参数
frame_len = 256;
overlap = 128;
win = hamming(frame_len);
%% 3. STFT
[S_y, f, t_stft] = stft(y, fs, 'Window', win, ...
'OverlapLength', overlap, 'FFTLength', frame_len);
[S_x, ~, ~] = stft(x, fs, 'Window', win, ...
'OverlapLength', overlap, 'FFTLength', frame_len);
[S_d, ~, ~] = stft(d, fs, 'Window', win, ...
'OverlapLength', overlap, 'FFTLength', frame_len);
%% 4. 噪声功率谱估计
% 计算分母
lambda_d = zeros(size(S_d));
alpha_d = 0.98; % 噪声平滑系数
lambda_d(:,1) = abs(S_d(:,1)).^2;
for k = 2:size(S_d,2)
lambda_d(:,k) = alpha_d * lambda_d(:,k-1) + ...
(1-alpha_d) * abs(S_d(:,k)).^2;
end
% 防止除0
lambda_d = lambda_d + 1e-10;
%% 5. 后验 SNR(γ)
gamma = abs(S_y).^2 ./ lambda_d;
%% 6. Decision-directed 先验 SNR(核心改动!!!)
alpha = 0.98; % 推荐 0.96~0.99
xi = zeros(size(gamma));
% 第一帧初始化
xi(:,1) = max(gamma(:,1)-1, 0);
% 这里用"上一帧的估计语音功率",而不是直接用 S_x
for k = 2:size(gamma,2)
% 上一帧语音估计(Wiener形式近似)
G_prev = xi(:,k-1) ./ (1 + xi(:,k-1)); % Wiener增益
S_hat_prev = G_prev .* S_y(:,k-1);
xi(:,k) = alpha * (abs(S_hat_prev).^2 ./ lambda_d(:,k)) + ...
(1-alpha) * max(gamma(:,k)-1, 0);
end
%% 7. dB显示(加clipping更稳定)
gamma_db = 10*log10(gamma);
xi_db = 10*log10(xi + 1e-10);
gamma_db = max(gamma_db, -20);
xi_db = max(xi_db, -20);
%% 8. 可视化
figure;
subplot(2,1,1);
imagesc(t_stft, f, gamma_db);
axis xy;
colorbar;
title('后验信噪比 γ(k,m) [dB]');
xlabel('时间 [s]');
ylabel('频率 [Hz]');
subplot(2,1,2);
imagesc(t_stft, f, xi_db);
axis xy;
colorbar;
title('先验信噪比 ξ(k,m) [dB]');
xlabel('时间 [s]');
ylabel('频率 [Hz]');这段代码的主要工作为:
- 生成"语音 + 噪声"信号
- 用 STFT 分帧到频域
- 计算后验 SNR γ \gamma γ(瞬时)
- 用 Decision-directed 方法计算先验 SNR ξ \xi ξ(平滑)
- 用热图对比显示两者差异
5.2 📊 结果分析
📌 整体对比
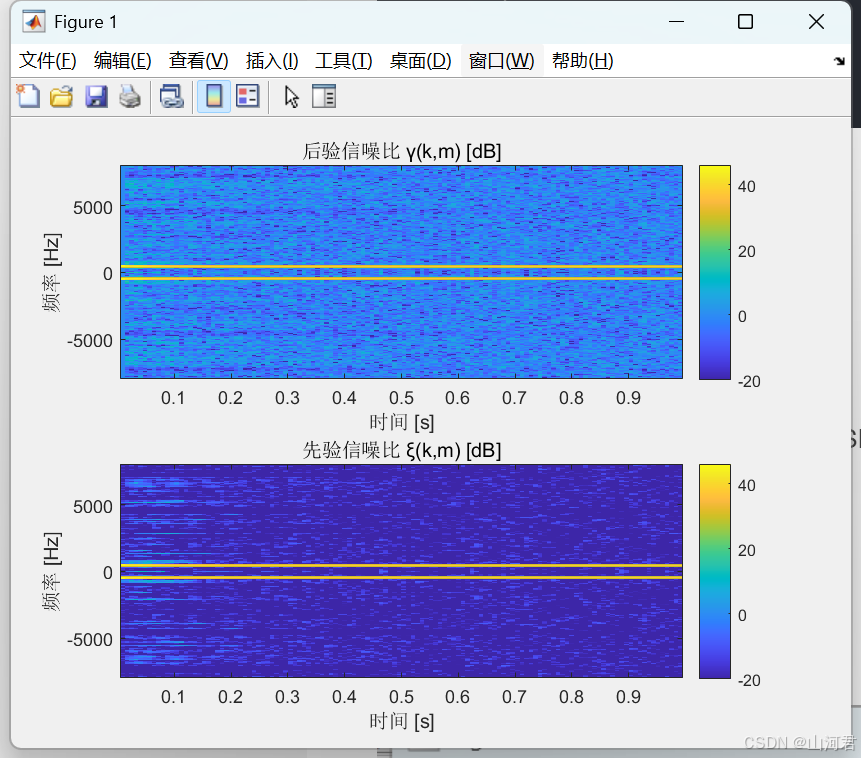
我们可以看到先验信噪比是远比后验信噪平滑更多
📌 系数影响
上文中说 α \alpha α平滑系数会影响信噪比的平滑
- α \alpha α越小,先验 SNR 对瞬时变化越敏感,杂点越多。
- α \alpha α太大,响应语音突发又会滞后。
现在我们对比 α = 0.97 \alpha=0.97 α=0.97和 α = 0.99 \alpha=0.99 α=0.99的情况
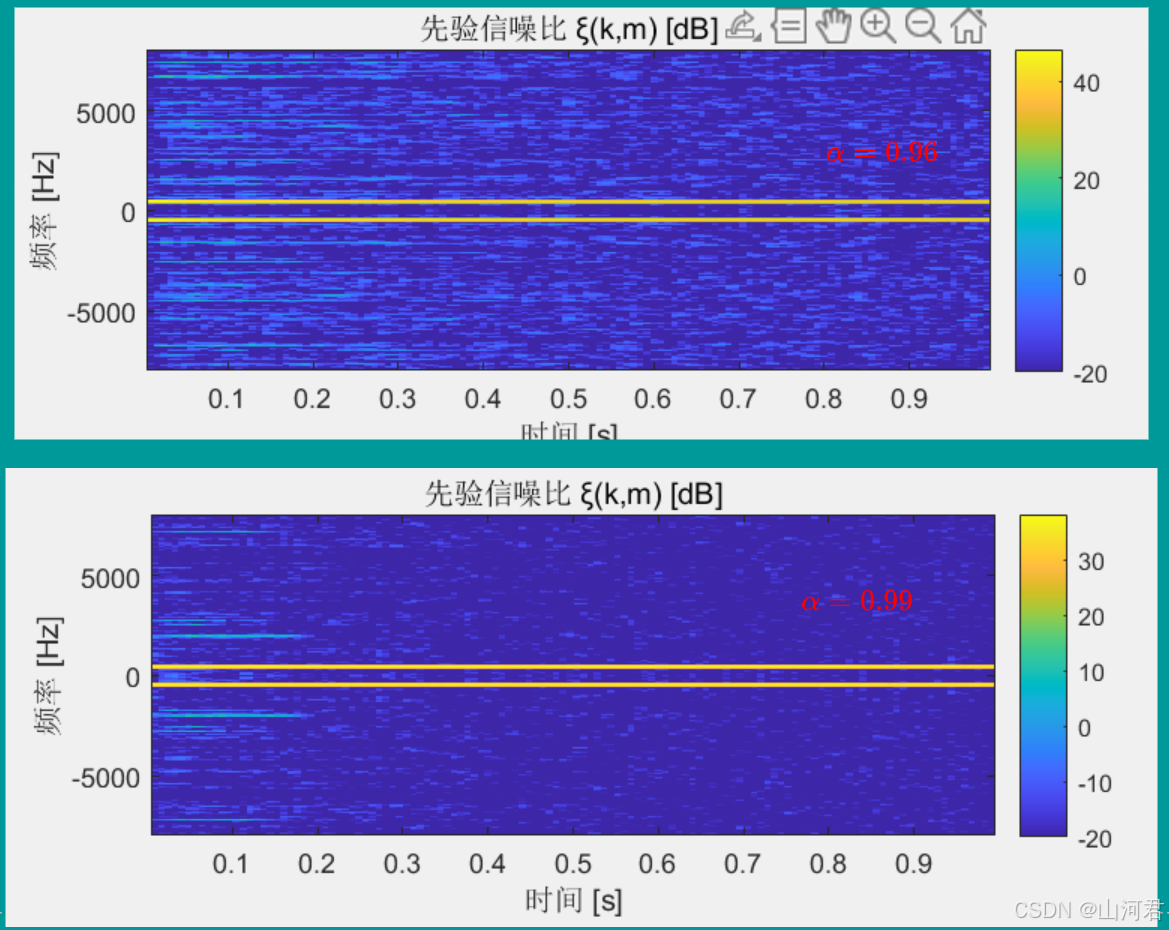
可以明显看到当 α \alpha α变大时,频谱在其他频率能量更低且更平滑
📌 动态差异
如果去除噪声平滑和Wiener增益,这个读者自行去除,那么对于先验和后验的区别如下所示:
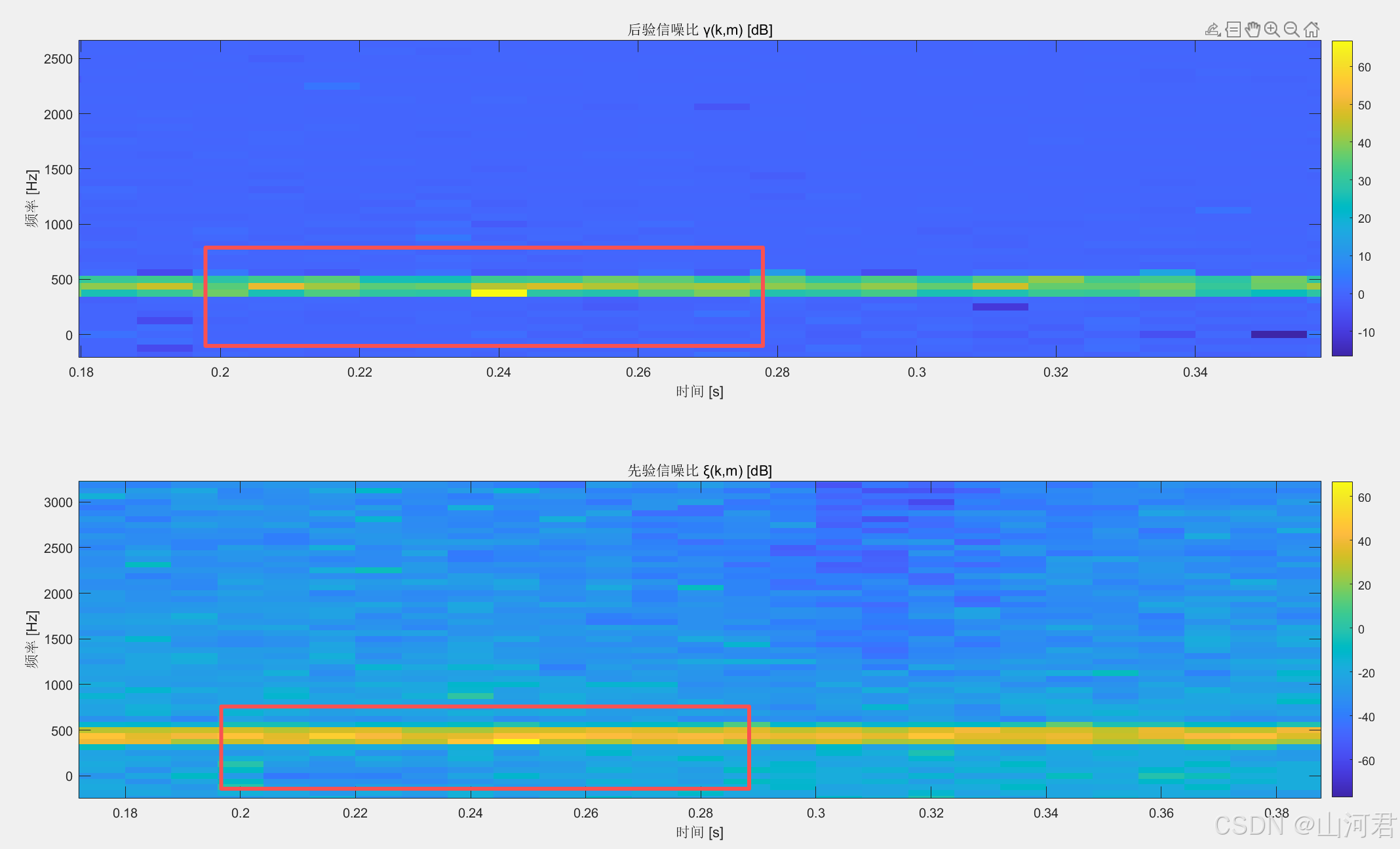
如果将时频谱放大查看,只看正频率明显可以发现,后验信噪比的平稳性远没有先验信噪比的平稳性高,如果将其画出来应该是如下图的样子:
🧾 总结
📌 核心结论
- 后验 SNR:"即时但不稳定"
- 先验 SNR:"平滑但依赖估计"
- DD算法:融合历史 + 当前信息的最优折中
🧠 一句话理解
- 后验 SNR 看"现在有多吵",
- 先验 SNR 估"真正语音有多强"。