1 . 大模型原理
通过上一节AI基础认知的分析,我们知道AI产生智能的三要素分别是:算法、数据、算力。本质来说,AI的智能还是基于各种数学计算产生的。
那么问题来了:现在的AI是如何通过训练理解人类语言的呢?语言是如何计算和训练的呢?
1.1 模型的训练
前面我们说过,AI的神经网络模型就是在模仿人类的神经元:
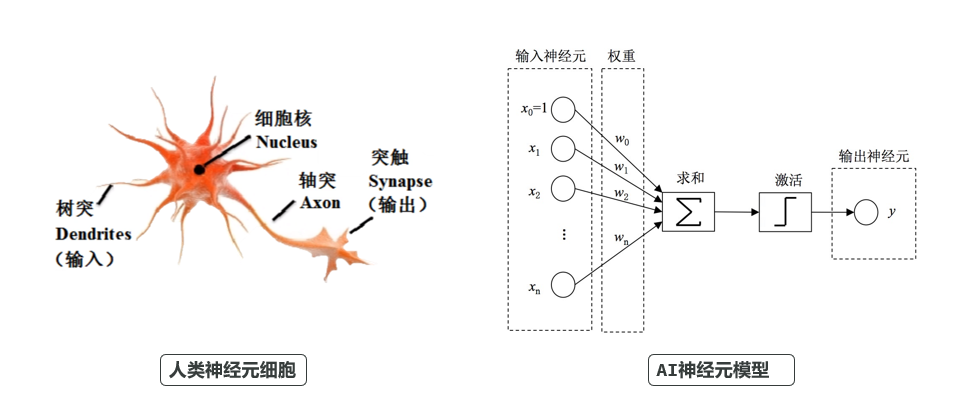
你给它输入一些参数,最终它经过计算返回一个结果。因此从某种意义上,你可以把模型看做是一个函数。
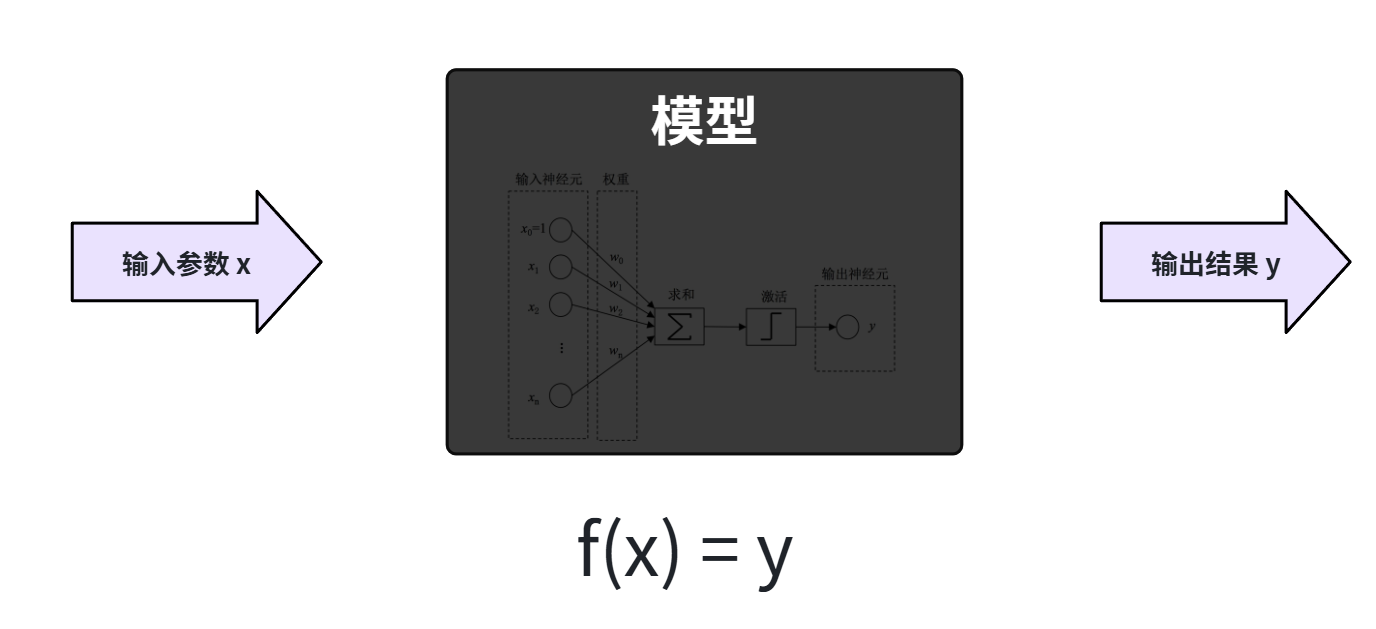
这就类似:y = ax + b,这个函数有两个参数a和b,当a和b确定时,这个函数就能表示一条直线。输入一个x,一定能得到一个结果y
当然,模型这个"函数"要复杂的多,其参数不是两个,而是可能达到千亿规模:
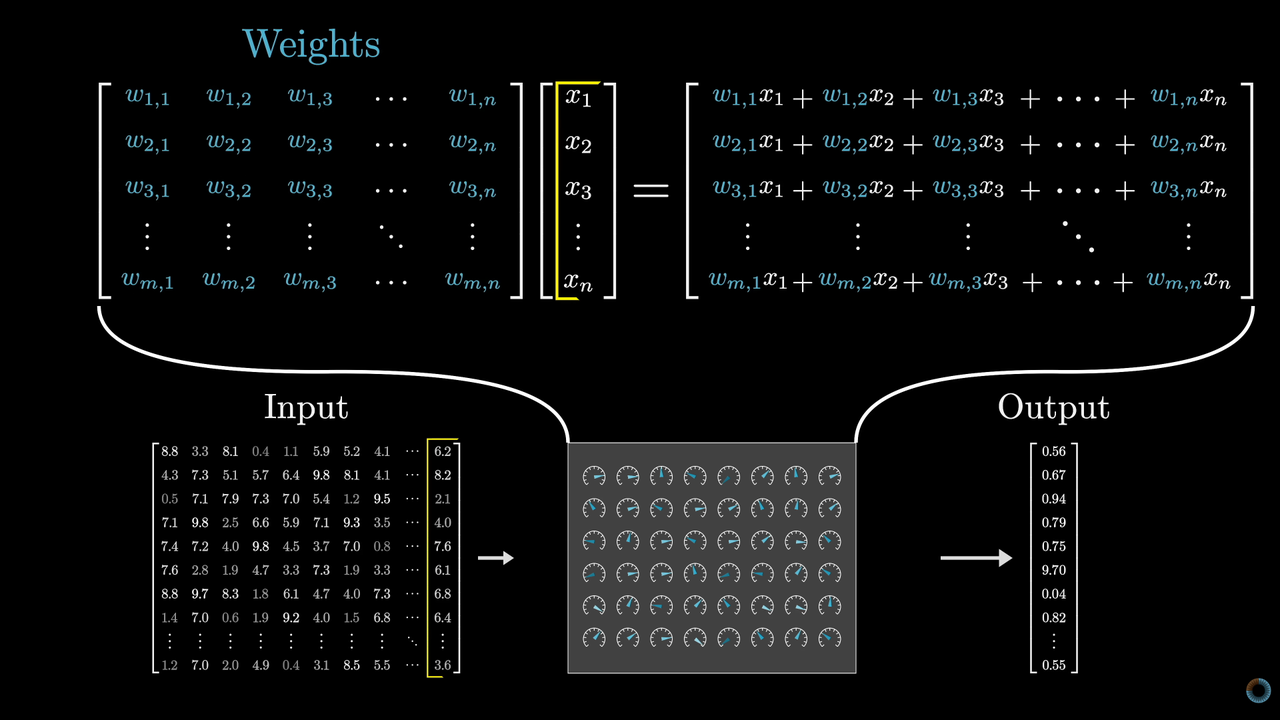
因此它表示的不是一条直线,而是表示人类复杂的语言系统。
模型训练的过程,就是求模型参数的过程,类似于求解函数参数。已知直线上两个点的坐标,就能求出这条直线对应的a和b的值。
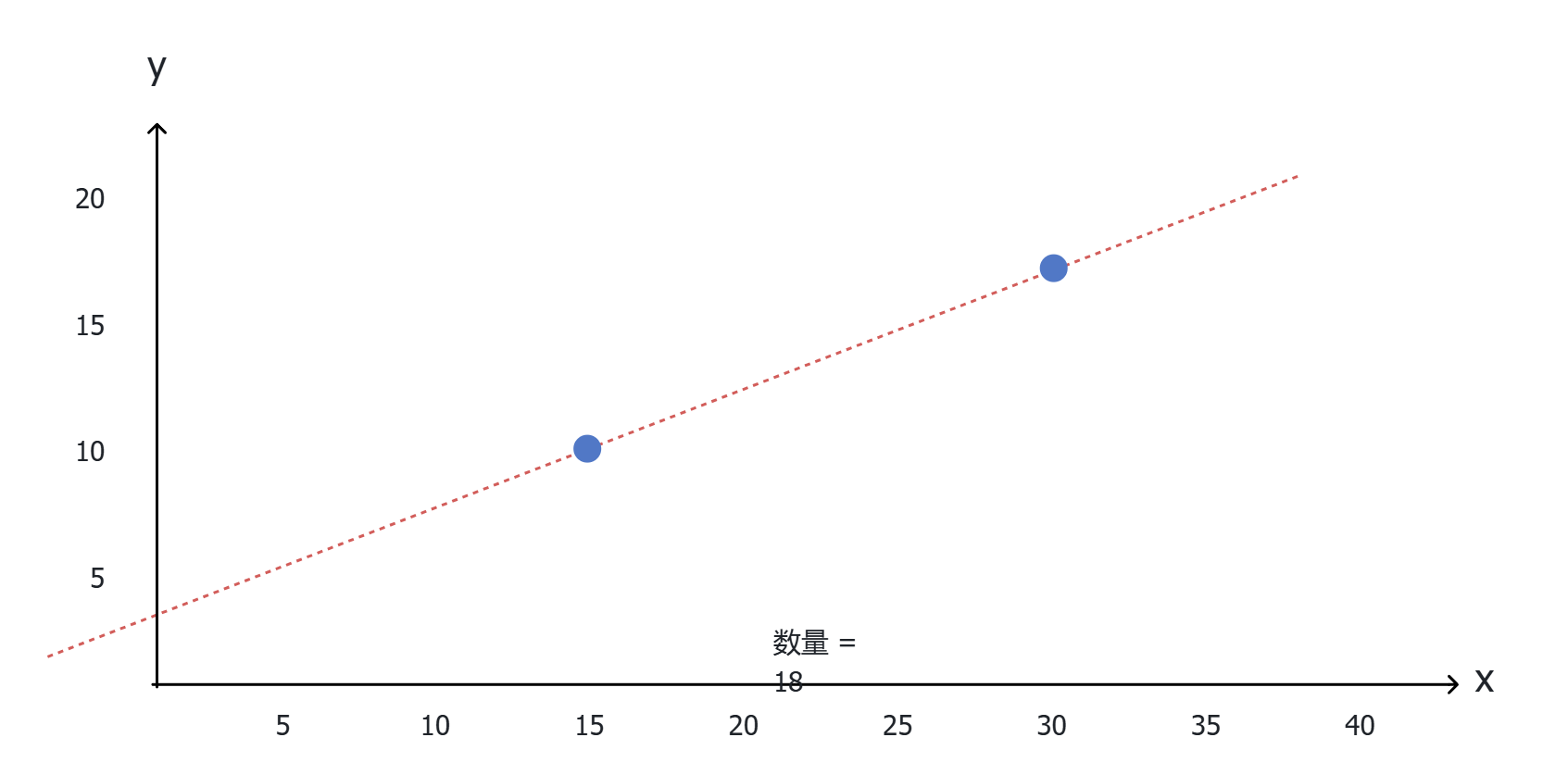
不过,大模型这个"函数"要复杂的多,其参数规模高达数千亿,模拟的也不是一条直线,它需要的"点"也是天文数字,因此根本就不可能精确计算出每一个参数的值。
所以,模型的训练更像是在猜答案:
-
先给模型参数设定为随机值
-
然后输入一个参数,再把模型计算的结果与预期的正确结果做对比
-
如果不对就调整参数,直到正确为止
这里的输入参数 和预期结果 就是所谓的训练数据 (平面上的"点")。不断的给模型提供新的训练数据,根据计算结果不断调整模型的参数 ,直到模型的计算能够与大多数的训练数据吻合,那么模型的训练就完成了。
大语言模型的训练就是拿海量的人类语言文字作为训练数据,不断调整模型参数,使其与人类的语言文字系统拟合。
但问题来了,人类的语言文字是如何参与数学运算的呢?
1.2 大语言模型
在2003年,图灵奖得主约书亚·本吉奥 (Yoshua Bengio )的一篇名为《A neural probabilistic language model》的论文开创了**神经网络语言模型(Neural Network Language Model,NNLM)**的先河。
这篇文章中首次提到了词向量 (Word Embedding)的概念雏形,这为神经网络训练学习自然语言打下了坚实的基础。
-
每个词语都可以经过模型运算转化为一个多维向量(也就是一个浮点数数组,GPT3采用12288维向量)
-
通过训练使模型计算出的多维向量 与文字语义 产生关联,使多维空间中的不同方向表示不同语义
例如,在经过训练后的向量空间中,有两个向量:中国、美国:
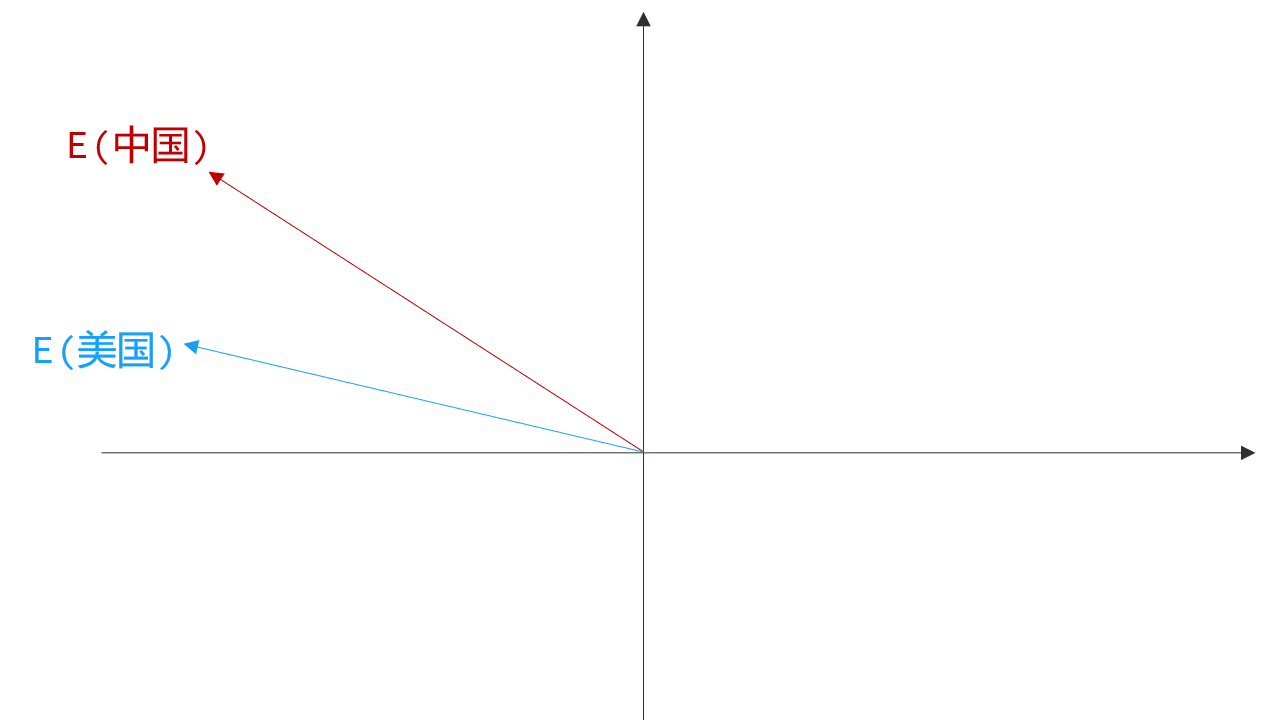
此时,我们用E(美国) - E(中国) 得到的新向量,就可以表示为美国与中国的差异。
假如此时我询问LLM在中国有什么食物与美国的汉堡类似,我们就可以这么做:
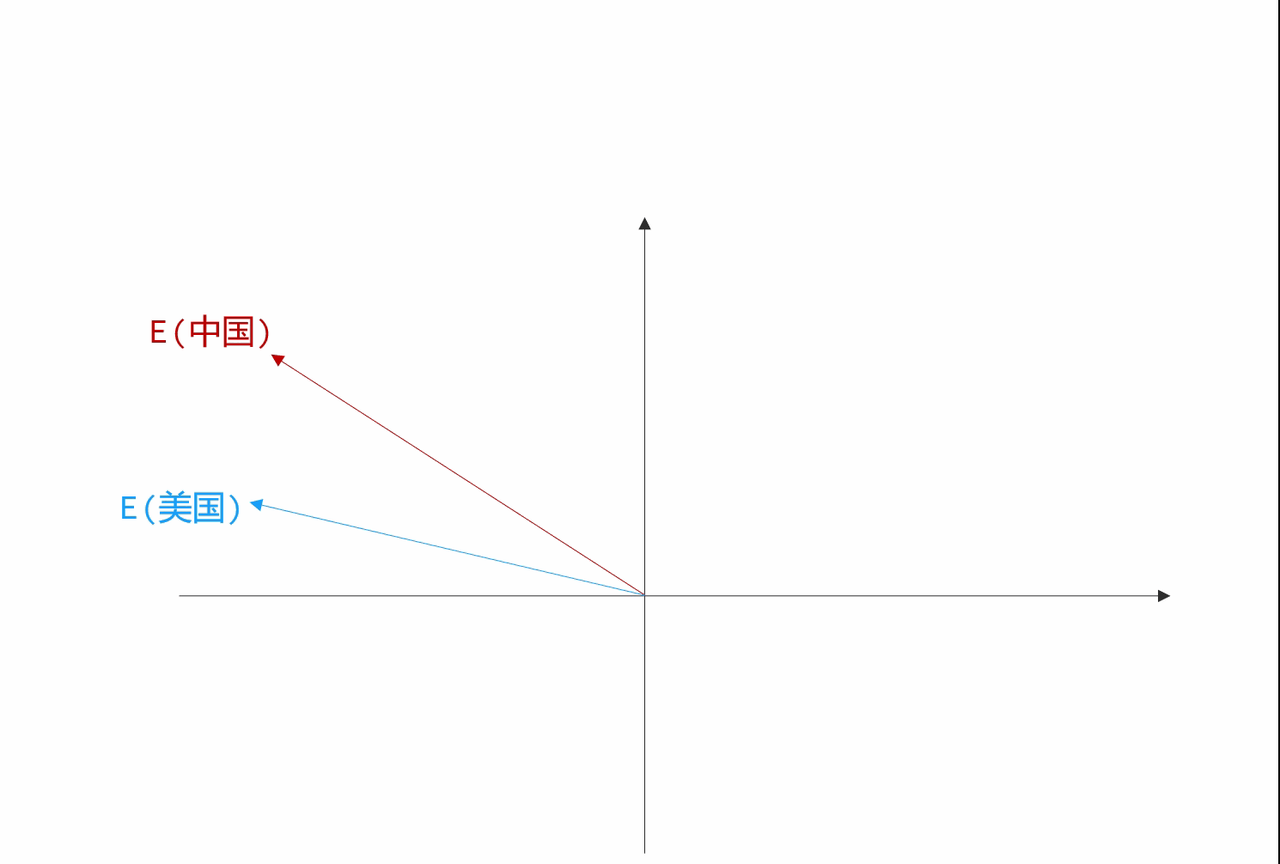
-
先找到表示汉堡的向量:E(汉堡)
-
然后加上表示两个国家差异的向量:E(美国) - E(中国)
-
从而计算出一个新向量:E(汉堡) + E(美国) - E(中国)
-
最后,将得到的向量反向量化(unembedding),大概率就是我们要的结果
当然,真实情况会比这个复杂的多,受到语句上下文的影响,和多义词的影响,运算可能得到不止一个结果,并且会根据可能性形成每一个结果的概率分布,然后通过某种函数算法选择一个最终结果。
综上,大语言模型,就是把人类语言转为可以计算的多维向量坐标,然后根据上文向量计算,来推测下文。就像这样:
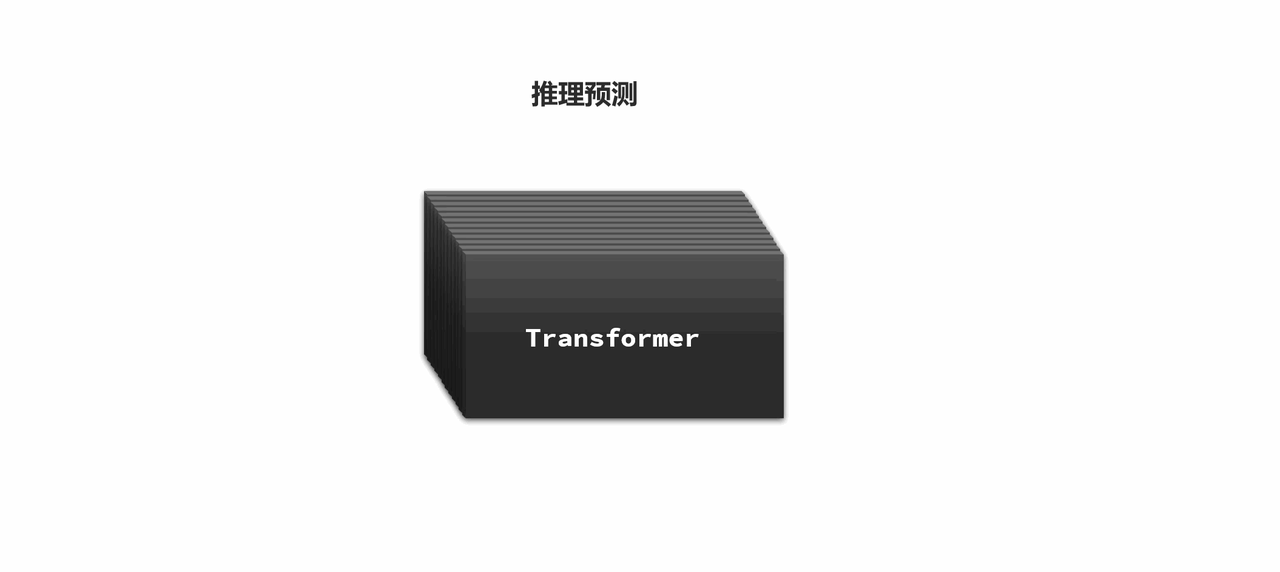
更神奇的是,人类一开始训练语言模型只是为了让它理解人类语言,起到翻译作用。但当模型和数据规模足够大 时,它不仅能够理解和生成自然语言,还能理解、推理、分析人类生活中的大部分问题,成为了可应用于各个领域的通用人工智能(AGI)!
这种因为数据和模型规模扩大而涌现出各种能力的现象,我们称之为泛化。
而这样的大规模语言模型我们就称为大语言模型 (Large Language Model ),简称LLM.
如果大家想要进一步搞清楚大模型原理,可以参考以下两个视频:
2. 大模型应用
什么是大模型应用呢?它与大模型有什么关系呢?
2.1 什么是大模型应用
别着急,我们从传统应用与大模型各种的能力边界来分析:
-
传统应用:是由程序员告诉计算机规则(编程),计算机照着规则执行。
-
擅长:规则清楚、流程固定的事情;可以确保100%准确;行为可控、可追溯
-
不擅长:没有明确规则的事情;自然语言的理解;模糊的判断和表达
-
-
大模型:计算机通过大量数据训练,自己学会规律和知识
-
擅长:理解和生成自然语言;模糊问题的合理回答;总结、改写、对话、创作
-
不擅长:准确的计算;固定的流程和规则;稳定可预测的结果
-
而大模型应用 则是把两者的能力结合:大模型负责"思考",传统程序负责"行动"。
例如,点外卖的功能,我们可以这样划分:
-
菜价、优惠、支付 → 传统程序
-
"给我推荐点清淡的" → 大模型
-
最终下单、扣钱 → 传统程序
在传统应用开发中介入AI大模型,充分利用两者的优势。既能利用AI实现更加便捷的人机交互,更好的理解用户意图,又能利用传统编程保证安全性和准确性,强强联合,这就是大模型应用开发的真谛!
综上所述,大模型应用就是整合传统程序和大模型的能力和优势来开发的一种应用。
另外,我们熟知的AI对话产品,比如通义千问、豆包这样的APP或者聊天机器人,也都属于大模型应用:
-
收集网页用户输入文本、上传的文件、图片 → 传统程序
-
分析和理解用户输入的问题 → 大模型
-
联网搜索与问题相关的资料 → 传统程序
-
根据资料生成答案 → 大模型
模型本身只具备理解、推理、生成回复的能力。我们平常使用的AI对话产品除了生成和推理,还有会话记忆功能、联网功能等等。这些都是大模型不具备的。是需要通过额外的程序来实现的,也就是基于大模型开发应用。
所以,我们现在接触的AI对话产品其实都是基于大模型开发的应用,并不是大模型本身,这一点大家千万要区分清楚。
2.2 常见的大模型
下面我把常见的一些大模型对话产品及其模型的关系给大家罗列一下:
| 大模型 | 对话产品 | 公司 | 地址 |
|---|---|---|---|
| GPT-3.5、GPT-4o | ChatGPT | OpenAI | https://chatgpt.com/ |
| Claude 3.5 | Claude AI | Anthropic | https://claude.ai/chats |
| DeepSeek-R1 | DeepSeek | 深度求索 | https://www.deepseek.com/ |
| 文心大模型3.5 | 文心一言 | 百度 | https://yiyan.baidu.com/ |
| 星火3.5 | 讯飞星火 | 科大讯飞 | https://xinghuo.xfyun.cn/desk |
| Qwen-Max | 通义千问 | 阿里巴巴 | https://tongyi.aliyun.com/qianwen/ |
| Moonshoot | Kimi | 月之暗面 | https://kimi.moonshot.cn/ |
| Yi-Large | 零一万物 | 零一万物 | https://platform.lingyiwanwu.com/ |
OK,现在我们知道了大模型应用就是把传统程序与大模型结合的应用。
2.3 与大模型的交互
那么问题来了:传统程序该如何与大模型交互呢?
答案是:调用接口。
大模型在部署时通常都会对外暴露基于HTTP协议的API接口,我们可以用任何自己喜欢的方式调用该接口,实现与大模型的交互:
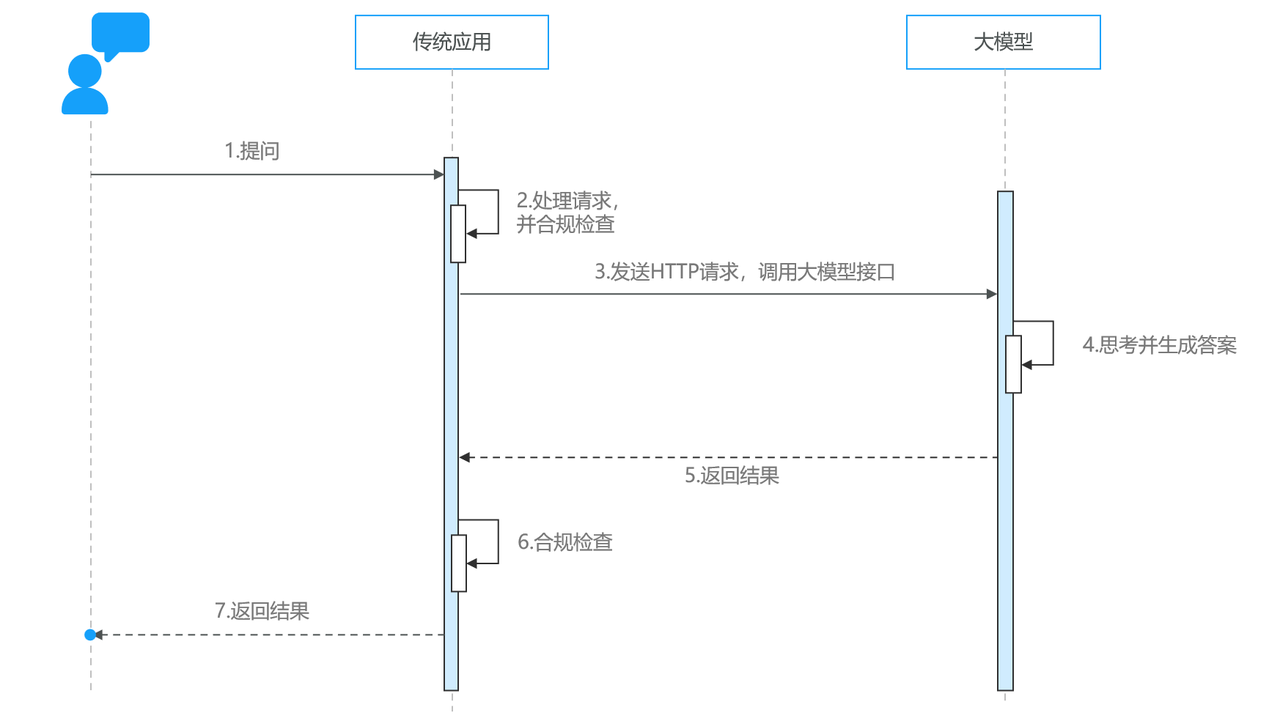
当然,首先我们需要有一个可以调用的大模型服务。
3. 大模型服务
前面说过:大模型应用开发并不是在浏览器中跟AI聊天。而是通过访问模型对外暴露的API接口,实现与大模型的交互。
因此,企业开发大模型应用,首先需要有一个可访问的大模型,通常有两种选择:
-
使用开放大模型
-
部署私有大模型
使用开放大模型API的优缺点如下:
-
优点:
- 没有部署和维护成本,按调用收费
-
缺点:
-
依赖平台方,稳定性差
-
长期使用成本较高
-
数据存储在第三方,有隐私和安全问题
-
部署私有模型:
-
优点:
-
数据完全自主掌控,安全性高
-
不依赖外部环境
-
虽然短期投入大,但长期来看成本会更低
-
-
缺点:
-
初期部署成本高
-
维护困难
-
接下来,我们给大家演示下两种部署方式:
-
公共大模型
-
私有大模型(在本机演示,将来在服务器也是类似的)
通常发布大模型的官方、大多数的云平台都会提供开放的、公共的大模型服务。大模型官方前面讲过,我们不再赘述,这里我们看一些国内提供大模型服务的云平台:
| 云平台 | 公司 | 地址 |
|---|---|---|
| DeepSeek | DeepSeek | https://www.deepseek.com |
| 阿里百炼 | 阿里巴巴 | https://bailian.console.aliyun.com |
| 腾讯TI平台 | 腾讯 | https://cloud.tencent.com/product/ti |
| 千帆平台 | 百度 | https://console.bce.baidu.com/qianfan/overview |
| SiliconCloud | 硅基流动 | https://siliconflow.cn/zh-cn/siliconcloud |
| 火山方舟-火山引擎 | 字节跳动 | https://www.volcengine.com/product/ark |
这些开放平台并不是免费,而是按照调用时消耗的token来付费,每百万token通常在几毛~几元钱,而且平台通常都会赠送新用户百万token的免费使用权。(token可以简单理解成你与大模型交互时发送和响应的文字,通常一个汉字2个token左右)
接下来,我们分别讲解DeepSeek和阿里巴巴的百炼平台。
3.1 DeepSeek模型服务
官方平台地址:
3.1.1 注册
首次访问,必须注册:

3.1.2 充值
DeepSeek官方对外提供的大模型API服务是需要收费的,因此我们必须注册账号,充值少量金额(1元也行)。
注册成功后即可进入平台管理页面,点击充值选项,进入充值页面:
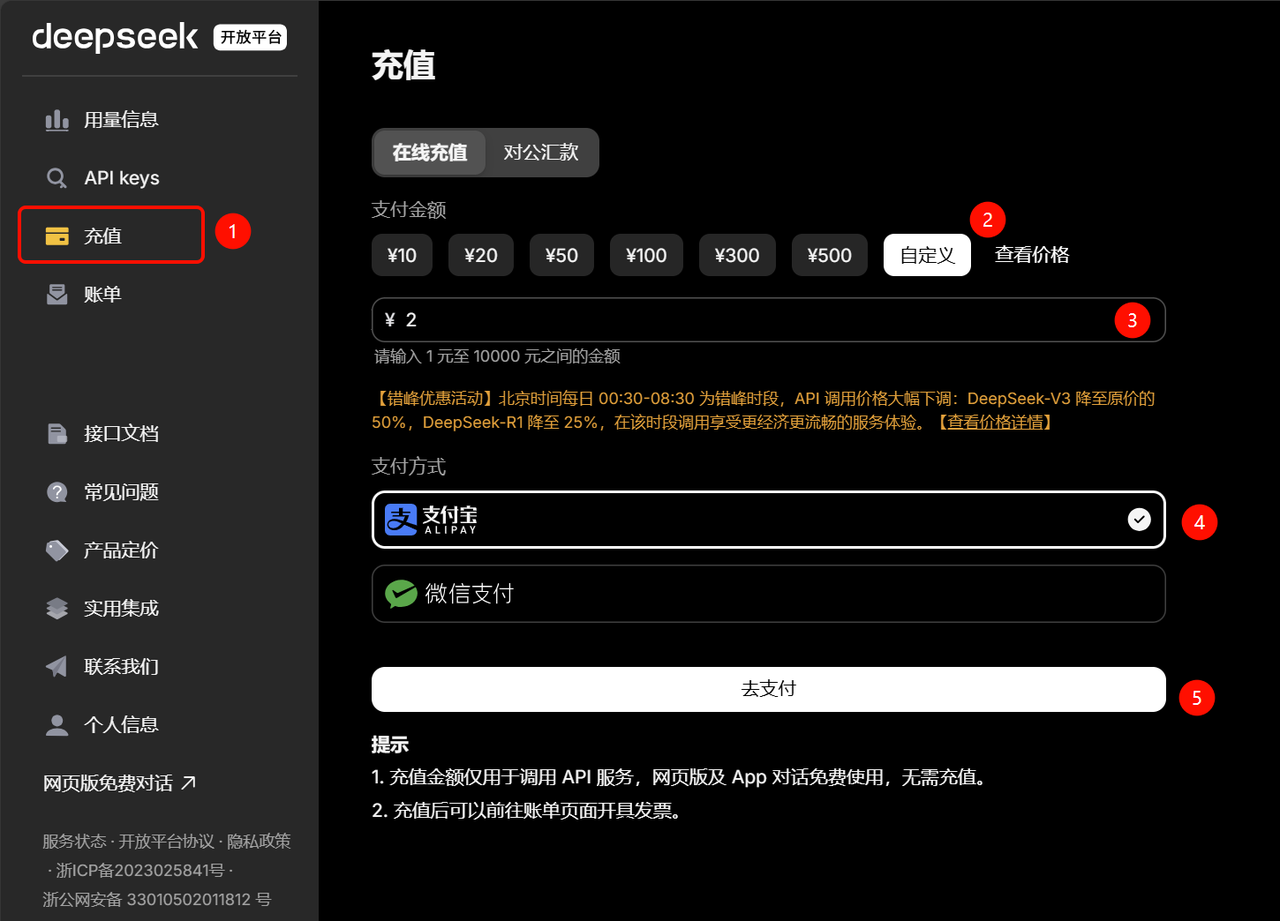
选择合适的价格充值后,即可使用DeepSeek的官方API服务。
3.1.3 创建API_KEY
由于是收费服务,为了防止别人盗用你的账号,DeepSeek的所有API都有权限校验功能。我们需要创建一个鉴权用的API_KEY可以。
点击API Keys 选项卡,进入对应页面。第一次进入应该没有API key,可以点击创建API key:
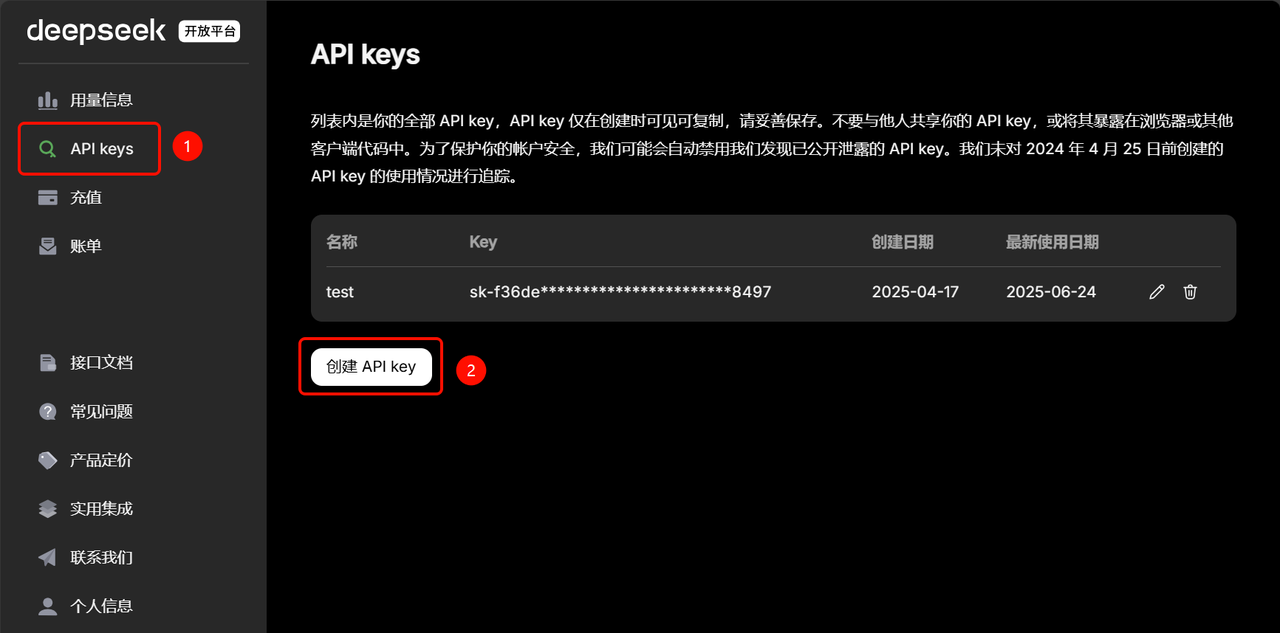
注意:API key只有在创建时可以查看,以后都无法查看了。所以需要在创建时妥善保管自己的API key
OK,准备工作完成。
3.1.4 API文档
访问公共大模型都是通过API的形式,不同模型的API标准略有差异,但基本都兼容OpenAI规范。
接下来,我们一起学习DeepSeek的官方API文档。地址如下:
可以看到,在文档中有这样一段调用对话的API示例:
这段信息就描述了调用DeepSeek大模型的API要求:
-
请求头:
-
Content-Type: application/json,请求参数的格式,必须是application/json
-
Authorization: Bearer <DeepSeek API Key>,上一节创建的API_KEY
-
-
请求体:json格式,稍后解释
-
请求方式:虽然没说,但是由于带请求体,所以这里用POST方式
3.1.5 测试
我们可以使用任意的Http客户端来测试API:
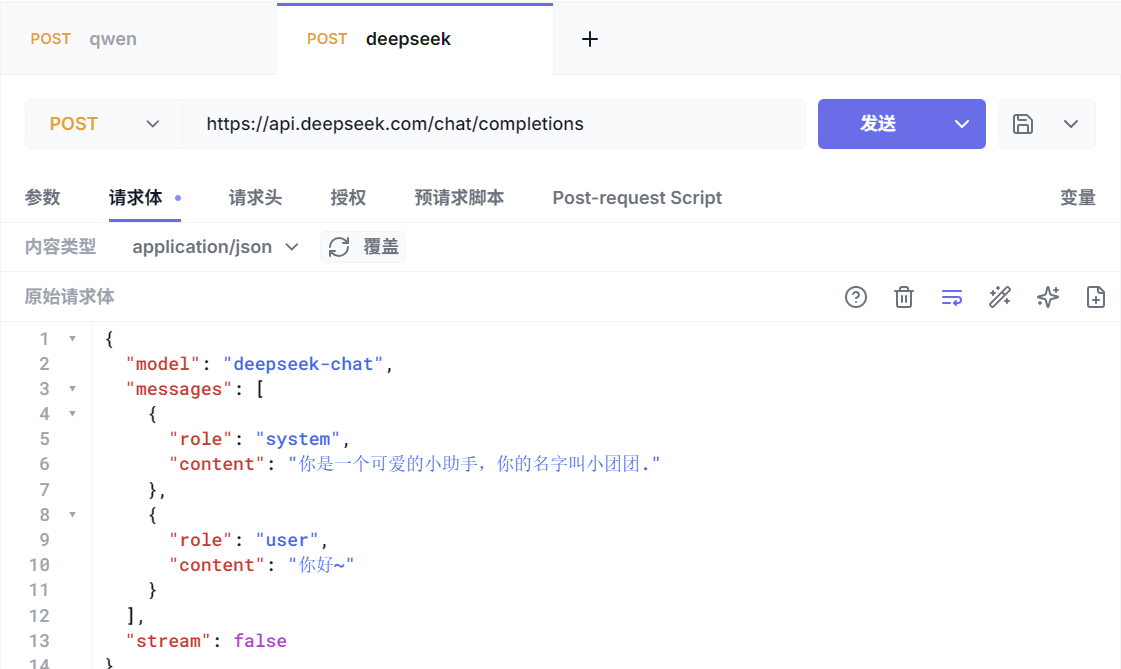
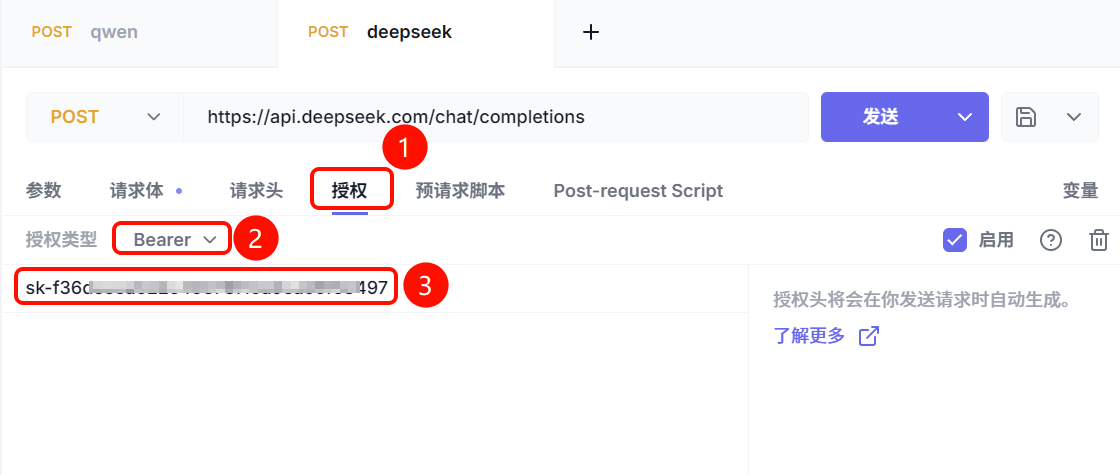
注意:需要在请求头中添加刚刚我们注册时准备的API_KEY:
3.2 阿里巴巴百炼模型服务
我们以阿里云百炼平台为例。
3.2.1 注册账号
首先,我们需要注册一个阿里云账号:
注意:账号需要进行个人实名认证,否则后续会有警告~
然后访问百炼平台,开通服务:
首次访问会弹出窗口,询问是否同意开通百炼服务:
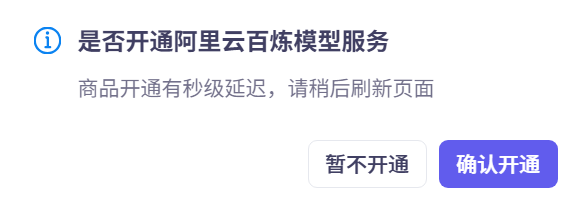
点击确认开通后,如果未进行实名认证,会提醒账户异常:
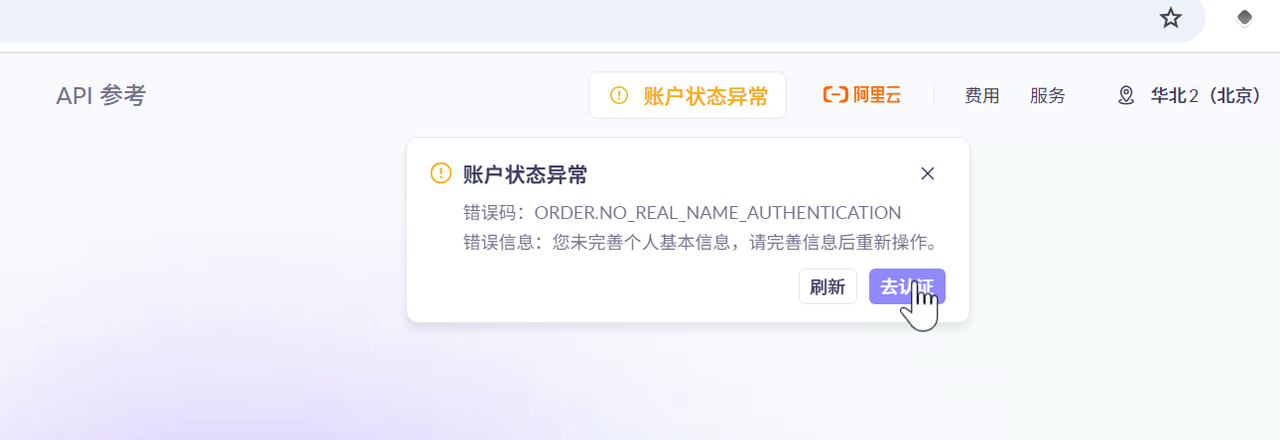
点击去认证,申请个人认证即可,此处略过。
首次开通应该会赠送百万token的使用权,包括DeepSeek-R1模型、qwen模型等等,有效期是3~9个月不等。大家可以在《模型控制台》-> 《模型用量》查看到你的免费额度使用情况:
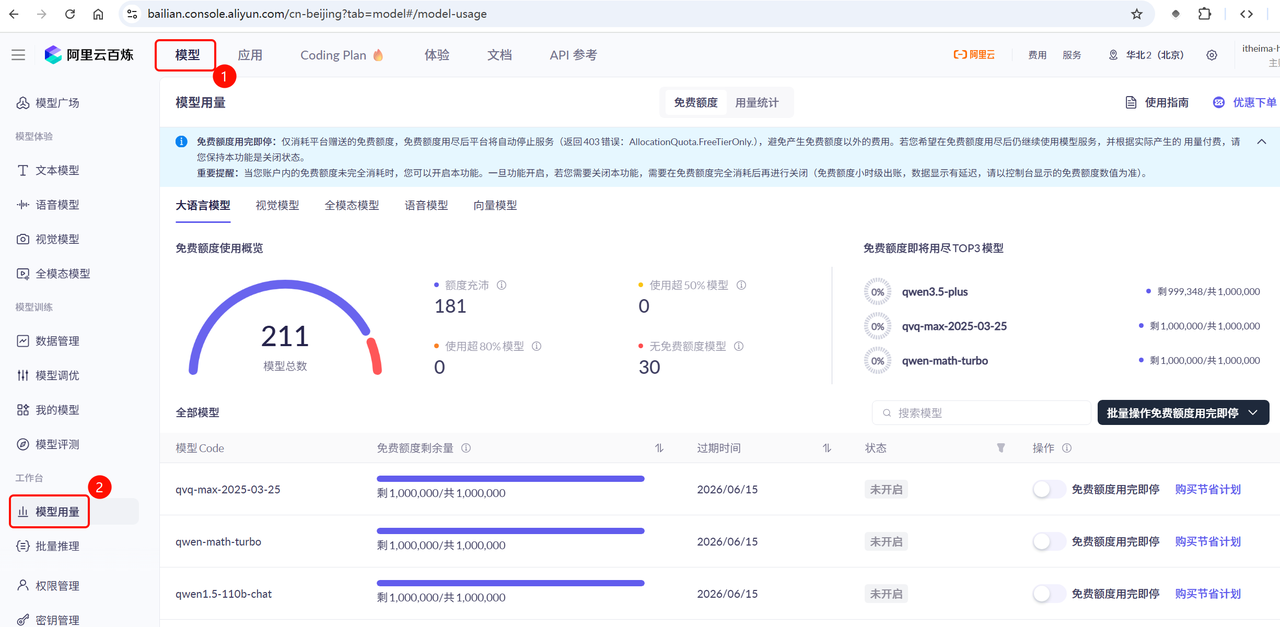
由于阿里巴巴免费赠送了额度,所以我们就跳过充值的过程了。😊
3.2.2 申请API_KEY
注册账号以后还需要申请一个API_KEY才能访问百炼平台的大模型。
注册成功后进入阿里云百炼首页,点击模型:
在阿里云百炼平台的左侧菜单的最下方,有一个《密钥管理》选项:
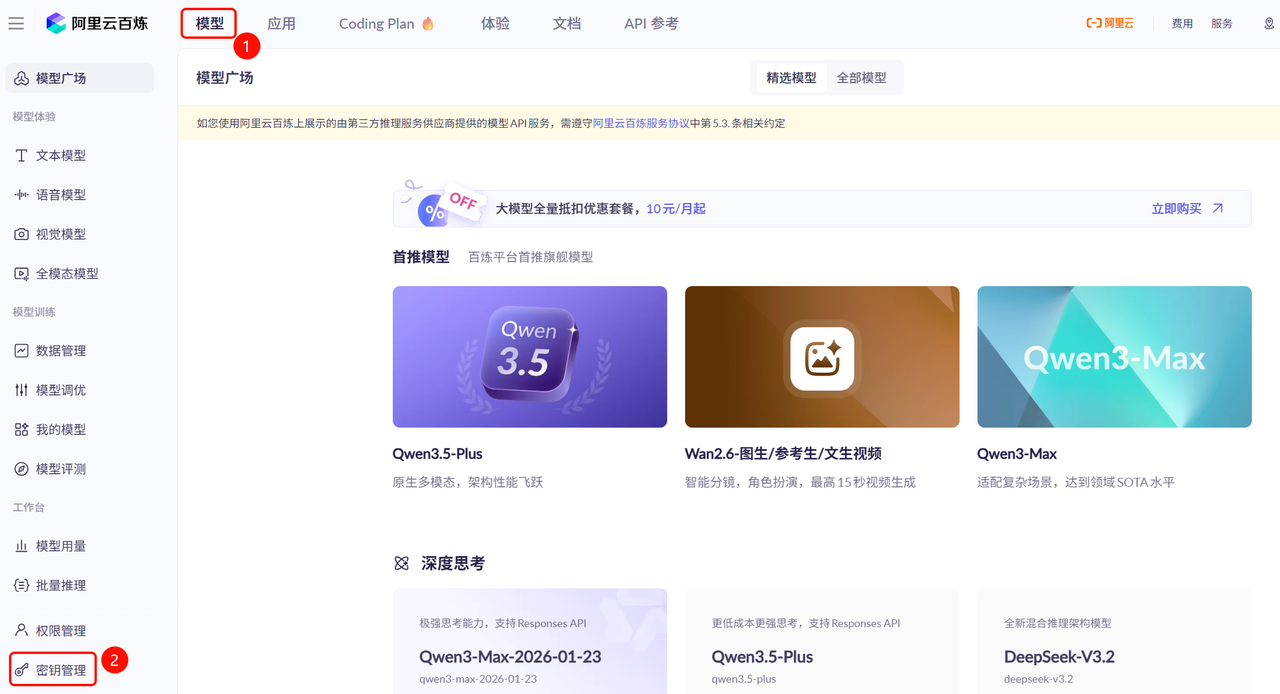
点击后,进入《密钥管理》页面,点击创建API-KEY:
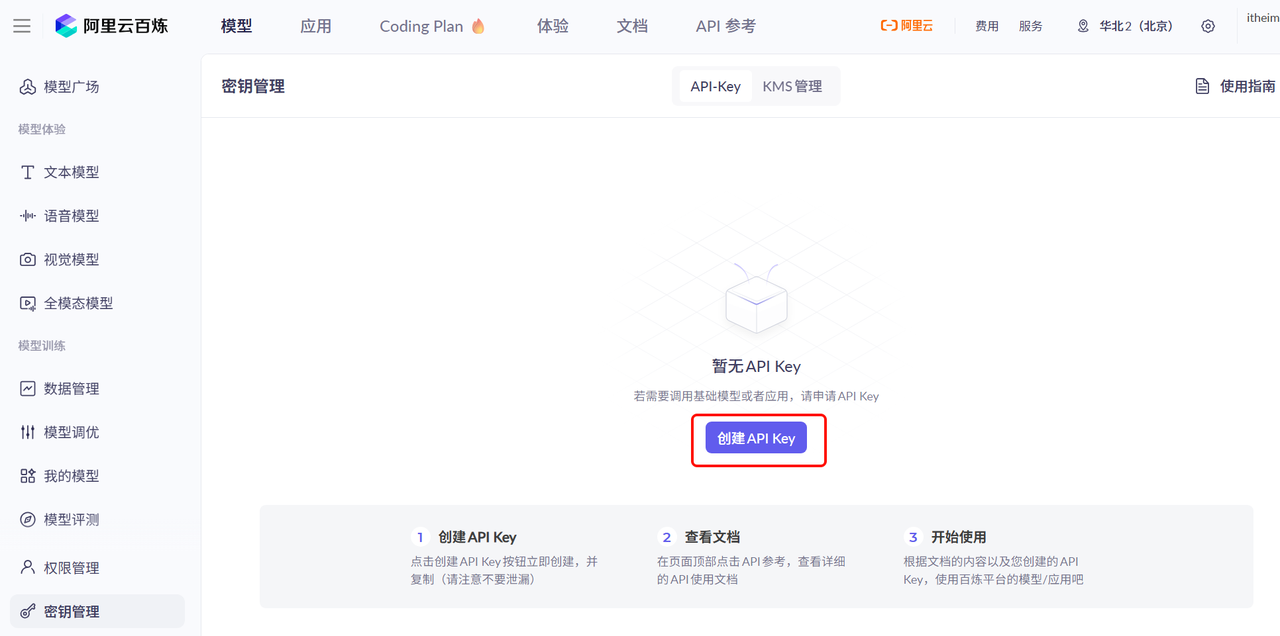
选择创建API-KEY后,会弹出表单,只有一个选项,勾选后点击确定即可:
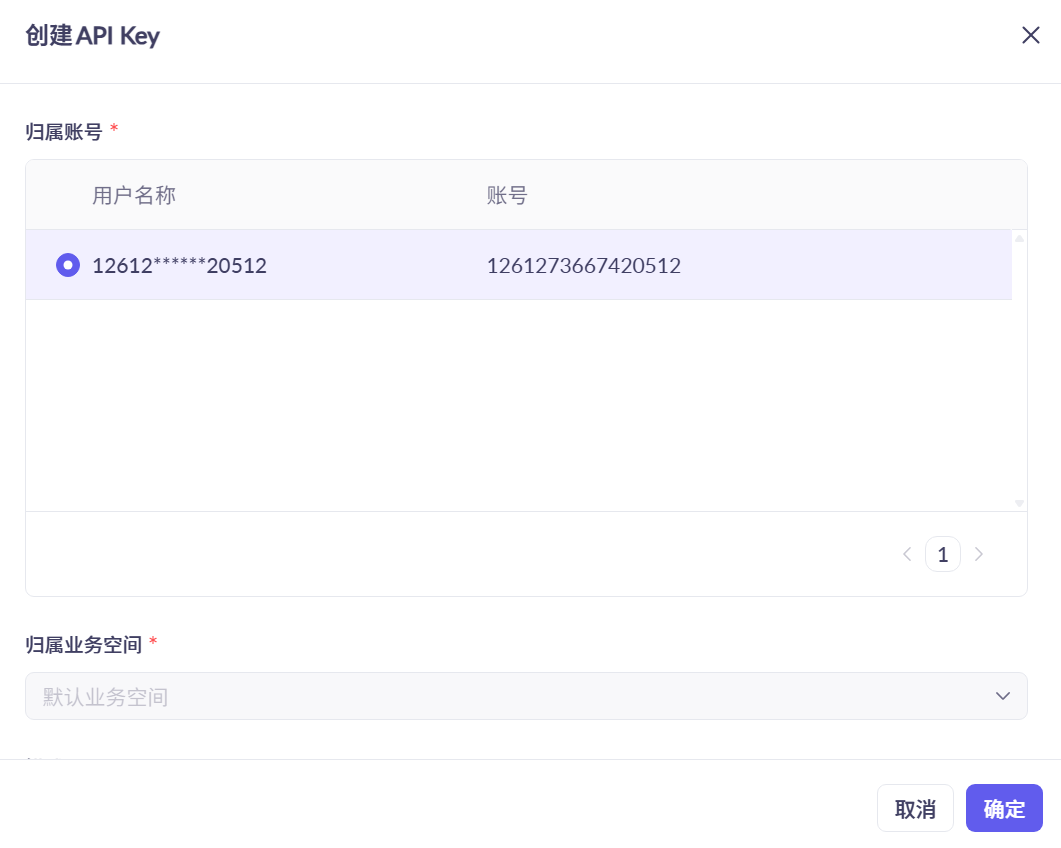
点击确定,即可生成一个新的API-KEY:

后续开发中就需要用到这个API-KEY了,一定要记牢。而且要保密,不能告诉别人。
3.2.3 体验模型
访问百炼平台,点击模型:
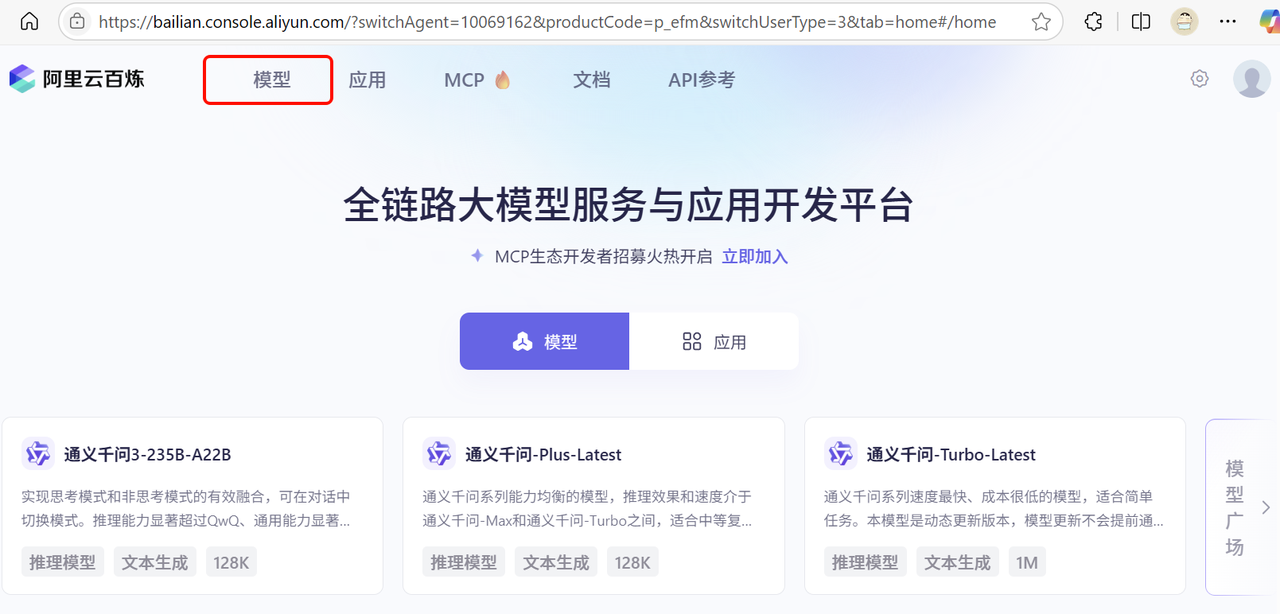
即可进入模型广场:
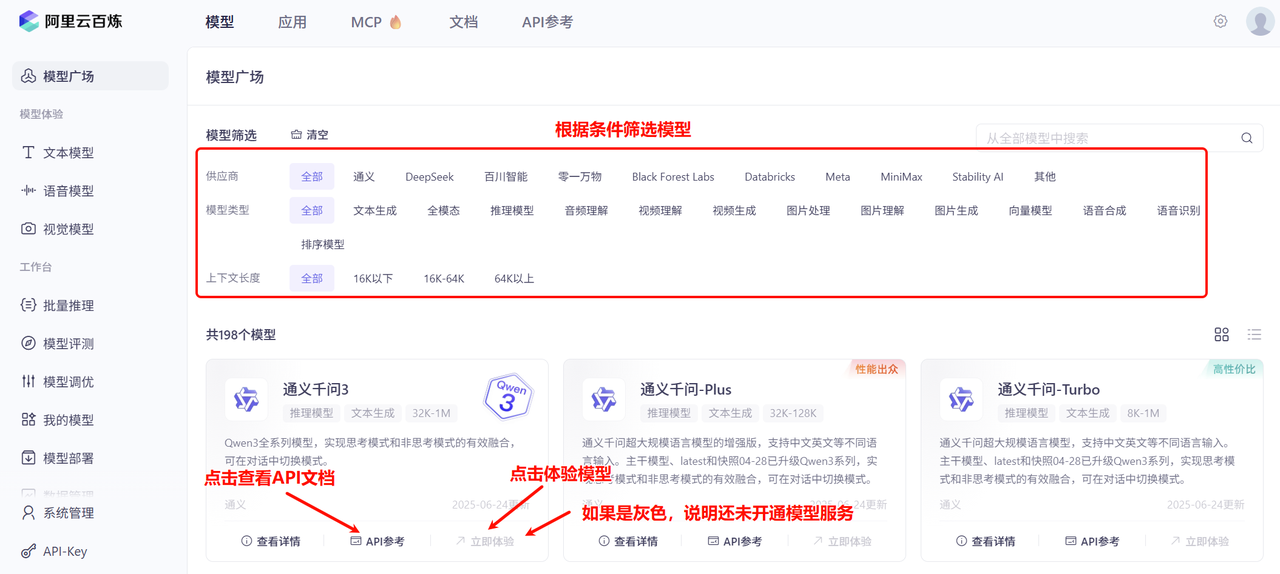
3.2.4 API文档
点击API参考即可进入API文档页面:
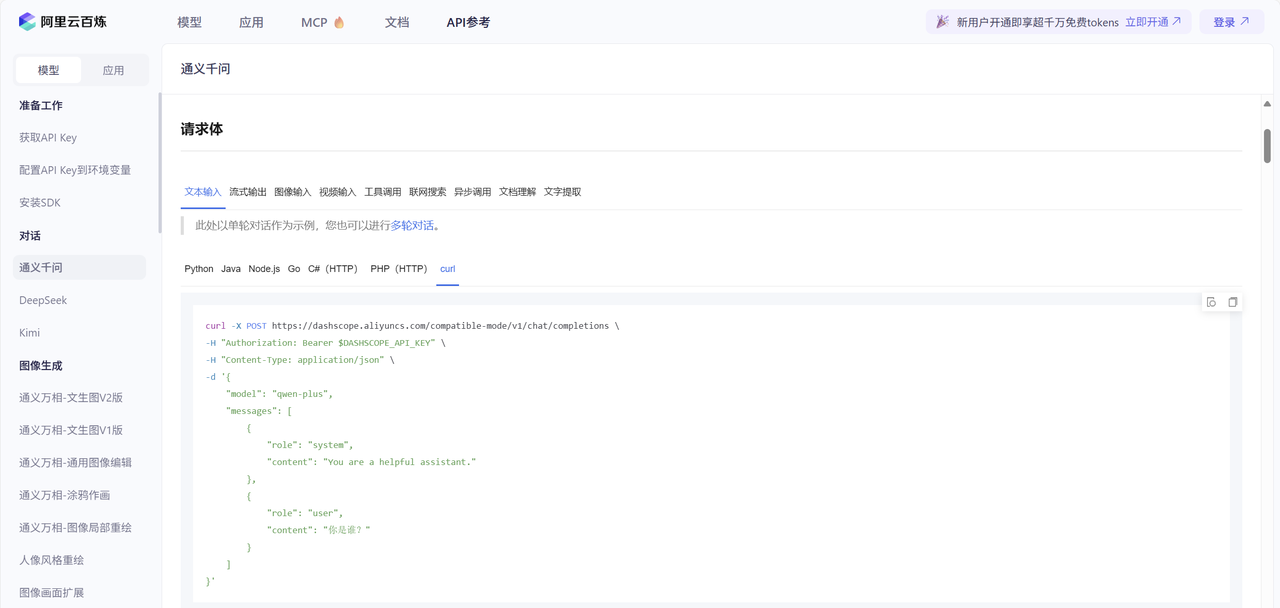
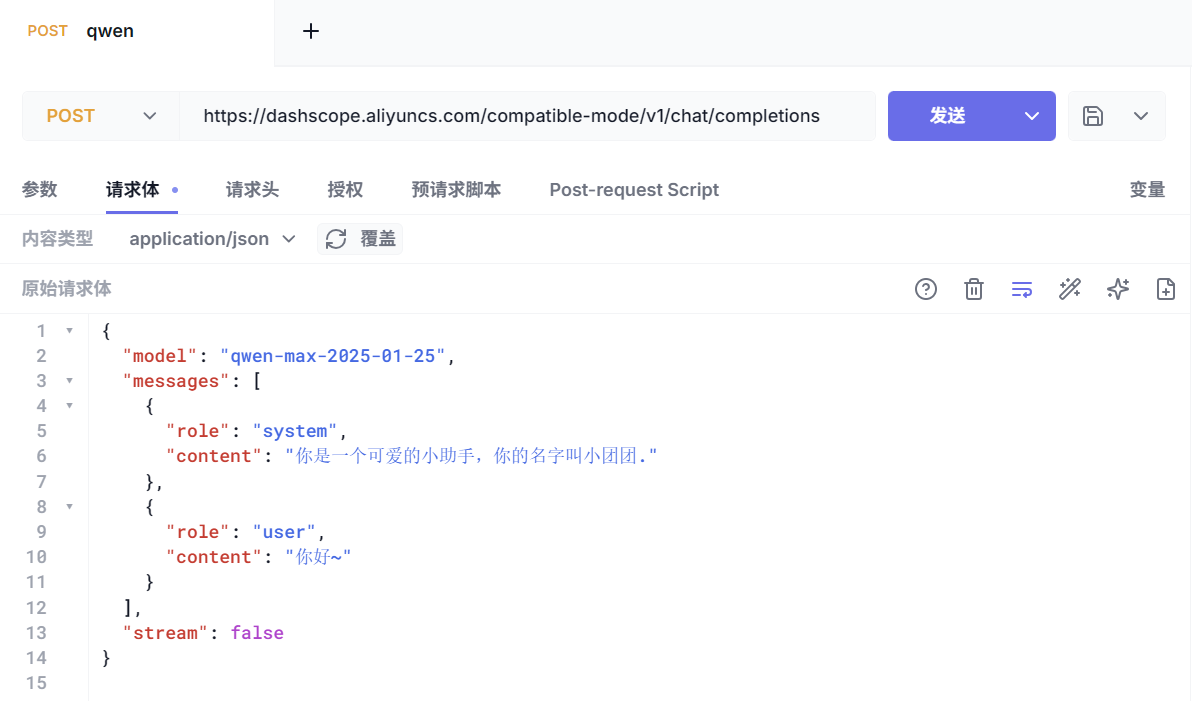
3.2.5 测试
我们使用Http客户端来调试(不要忘了设置API_KEY):
3.3 本地部署
很多云平台都提供了一键部署大模型的功能,这里不再赘述。我们重点讲讲如何手动部署大模型。
手动部署最简单的方式就是使用Ollama,这是一个帮助你部署和运行大模型的工具。官网如下:
3.3.1 下载安装ollama
首先,我们需要下载一个Ollama的客户端,在官网提供了各种不同版本的Ollama,大家可以根据自己的需要下载。
下载后双击就会弹出安装界面:
注意:
Ollama默认安装目录是C盘的用户目录,如果不希望安装在C盘 的话(其实C盘如果足够大放C盘也没事),就不能直接双击安装了。需要通过命令行安装。
命令行安装方式如下:
在OllamaSetup.exe所在目录打开cmd命令行,然后命令如下:
运行命令后,同样会弹出刚才的安装窗口,但是安装的位置已经是你设定的位置了。
点击Install即可安装,可以看到安装目录是自定义的D盘,而不是C盘:
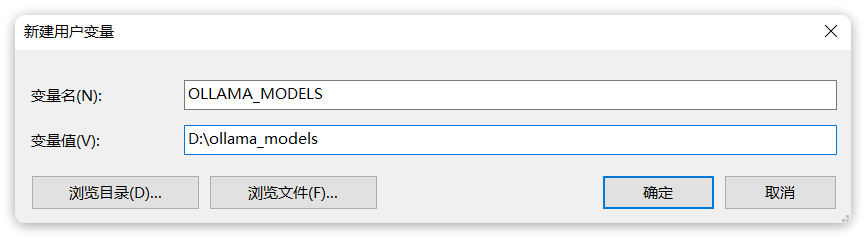
OK,安装完成后,还需要配置一个环境变量,更改Ollama下载和部署模型的位置。环境变量如下:
环境变量配置方式相信学过Java的都知道,这里不再赘述,配置完成如图:
3.3.2 搜索模型
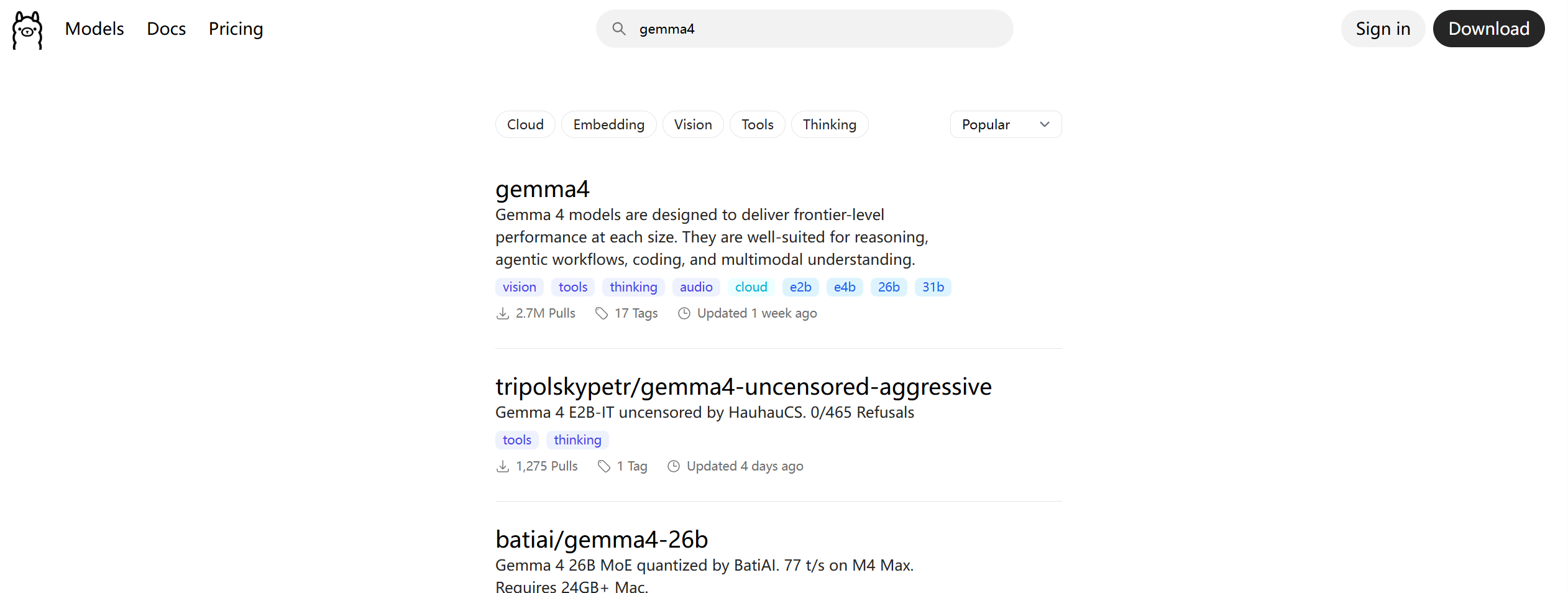
ollama是一个模型管理工具和平台,它提供了很多国内外常见的模型,我们可以在其官网上搜索自己需要的模型:
3.3.3 运行模型
选择自己合适的模型后,ollama会给出运行模型的命令:
复制这个命令,然后打开一个cmd命令行,运行命令即可,然后你就可以跟本地模型聊天了:
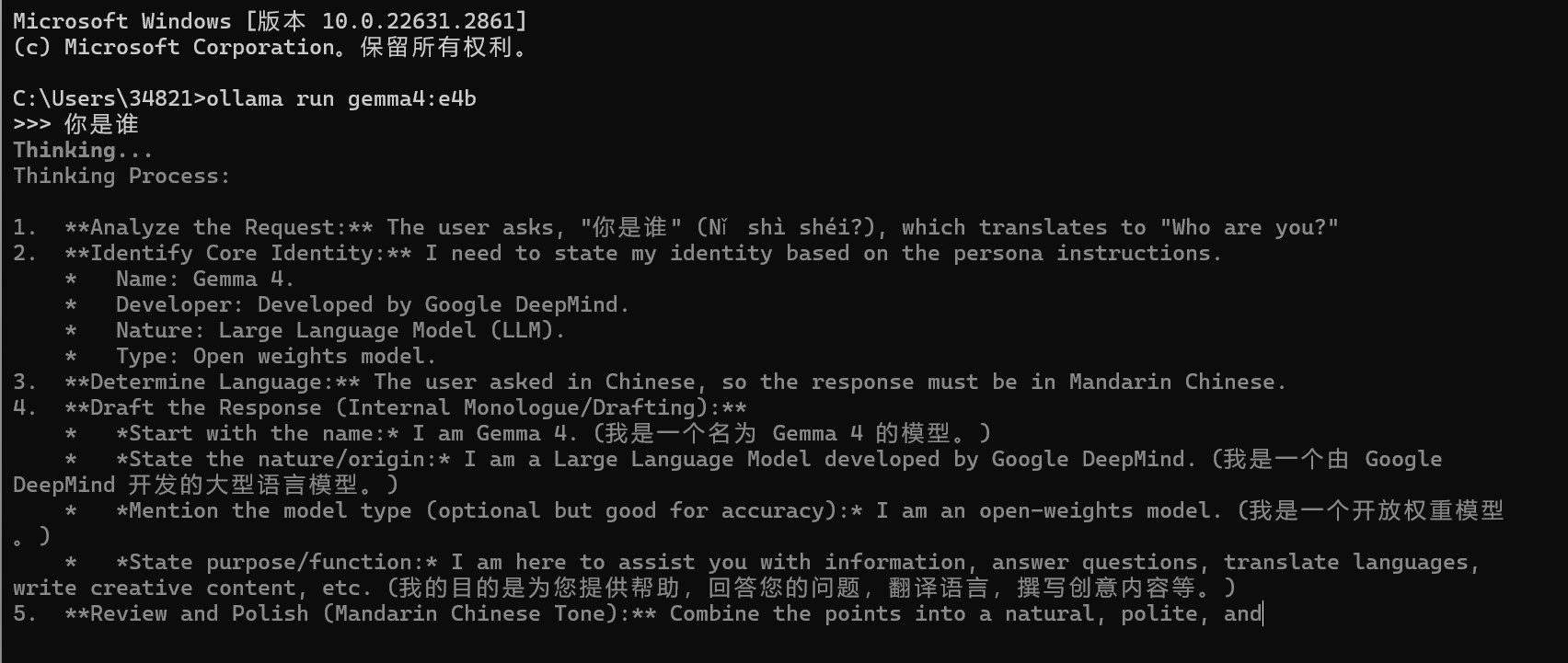
注意:
首次运行命令需要下载模型,根据模型大小不同下载时长在5分钟~1小时不等,请耐心等待下载完成。
ollama控制台是一个封装好的AI对话产品,与ChatGPT类似,具备会话记忆功能。
ollama也提供了供程序访问的HTTP接口,默认地址是http://127.0.0.1:11434/api/chat