前言
今天继续学习一些 LangGraph 常用到的基础 API。废话少说上干货。
.点语法
Graph 的创建可以使用看着更简洁的 .语法。
Python
graph = (
StateGraph(State)
.add_node(a)
.add_node(b)
.add_edge(START, "a")
.add_edge("a", "b")
.add_edge("b", END)
.compile()
)步骤序列
Python
StateGraph(State).add_sequence([step_1, step_2, step_3])并行运行
Python
graph = (
StateGraph(State)
.add_node(a)
.add_node(b)
.add_node(c)
.add_node(d)
.add_edge(START, "a")
.add_edge("a", "b")
.add_edge("a", "c")
.add_edge("b", "d")
.add_edge("c", "d")
.add_edge("d", END)
.compile()
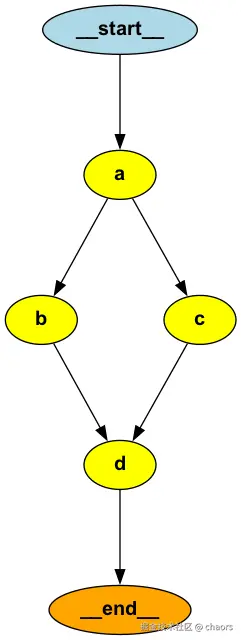
)上面的 Graph就是支持并行的,b, c 两个节点就是并行运行的两个节点。这个时候图的结构为:
MapReduce
MapReduce 模式,是一套用于构建动态、可扩展的智能体(Agent)或数据处理流水线的核心架构模式。
-
本质:将经典的"分而治之"并行计算
-
Map:"分"与"散"-
输入:一个包含多个待处理项(如文档列表、查询列表、任务对象)的总体状态。
-
过程 :通过一个条件边(
Conditional Edge) 中的路由函数,利用SendAPI 将输入列表"映射"为多个独立的子任务。每个Send对象指定一个目标处理节点和一份独立的、仅包含该子任务数据的私有状态。 -
关键 :这些
Send出的子任务会并行执行,实现高效扇出(Fan-out)。
-
-
Reduce:"合"与"聚"-
输入:所有并行 Map 节点处理完成后产生的多个中间结果状态。
-
过程 :通过预定义的 Reducer (如
operator.add用于列表合并)自动将所有子任务的结果状态"归约"合并,更新回主工作流状态。 -
关键:自动声明式,无需编写结果收集与合并代码,实现扇入(Fan-in)
-
图状态:
Python
class OverallState(TypedDict):
"""全局状态:贯穿整个工作流"""
topic: str # 输入的大主题(如 animals)
subjects: list # 生成的子主题列表
jokes: Annotated[list, operator.add] # 自动合并多条并行生成的笑话
best_selected_joke: str # 最终选中的最佳笑话
class JokeState(TypedDict):
"""子任务状态:仅给 generate_joke 使用"""
subject: str核心:
Python
def continue_to_jokes(state: OverallState):
"""
核心技术:Map-Reduce 并行执行
给每个子主题分发一个独立的 generate_joke 任务
"""
return [Send("generate_joke", {"subject": sub}) for sub in state["subjects"]]recursion_limit
- recursion_limit:LangGraph 强制安全上限 ,防止死循环,我们可以控制的最大步数
- 步数:每个
Node的执行为一步
- 步数:每个
以下代码表示:程序最多执行 100步。
Pyth
result = graph.invoke({"aggregate": []}, {"recursion_limit": 100})RemainingSteps
- RemainingSteps:LangGraph 的一个内置托管值,表示程序还剩多少步
- ReadOnly:完全由框架自动维护
- RemainingSteps =
recursion_limit- 已走步数(框架自动算)
RetryPolicy
RetryPolicy 是一个声明式的重试策略配置对象。你通过参数告诉 LangGraph:"当这个节点执行失败时,请按我定的规矩再试几次,而不是立刻报错"。核心参数:
-
max_attempts: 最大重试次数(含首次)。 -
initial_interval: 首次重试前的等待时间(s)。 -
backoff_factor: 退避因子。每次重试间隔会乘以这个因子,用于实现"**指数退避 -
jitter: 是否在重试间隔中加入随机抖动。用于"重试风暴"。 -
retry_on: 一个异常类型或函数,用于判断何种失败才需要重试。
赶脚是不是和 http 请求的重试差不多,我们也模拟一个 http 节点 的重试case。这里实现重试策略有两种方式:
- 内置的
RetryPolicy方法
Python
# 2. 定义针对此节点的"重试作战计划"
api_retry_policy = RetryPolicy(
max_attempts=3, # 最多尝试3次(首次+2次重试)
initial_interval=1.0, # 第一次重试等1秒
backoff_factor=2.0, # 指数退避:第二次等2秒,第三次等4秒
jitter=True, # 增加随机抖动,避免重试风暴
retry_on=(requests.exceptions.Timeout,
requests.exceptions.ConnectionError,
requests.exceptions.HTTPError) # 只针对网络和5xx错误重试
)- 自定义的 retry 方法
Python
# 方法2:自定义函数匹配 - 更精细地控制,例如只重试特定HTTP状态码
def retry_on_policy(exception: Exception) -> bool:
"""
自定义重试判断函数:
1. 对所有网络连接错误(ConnectionError)和超时(Timeout)进行重试。
2. 仅对特定HTTP状态码(429, 503)进行重试。
"""
# 规则1: 如果是连接错误或超时,立即决定重试
if isinstance(exception, (requests.exceptions.ConnectionError,
requests.exceptions.Timeout)):
return True
# 规则2: 如果是HTTP错误,则检查状态码
if isinstance(exception, requests.exceptions.HTTPError):
# 注意:exception.response 可能为 None(例如在请求未发出时)
if exception.response is not None:
if exception.response.status_code in (429, 503):
return True
# 其他所有情况,不重试
return False重试方法和节点绑定:
Python
builder.add_node("call_api", call_external_api, retry=api_retry_policy)长时记忆(向量检索)
前面我们知道 checkpointer 用于 LangGraph 中工作流的快照,但是他只能保存基于上下文的短期记忆。那么如果我们要做长时记忆该怎么做呢?
InMemoryStore
InMemoryStore 是 LangGraph 中基于 Python 字典实现的内存键值存储库。其核心主要在:
-
存储 (
put)namespace:命名空间,是一个元组,用于逻辑隔离,如("users", "123", "preferences")。键 (key):字典 key值 (value):字典 value
-
读取 (
get) :通过命名空间和键精确获取数据。 -
检索 (
search) :可检索某个命名空间下的所有条目,如果配置了嵌入模型,还能支持基于语义相似度的查询。
和用于 checkpointer 的 InMemorySaver 不同,InMemorySaver用于保存单个对话线程(Thread)的完整状态,数据与 thread_id 强绑定。而 InMemoryStore 更像一个共享的白板或缓存 ,用结构化的方式(通过命名空间)存储和检索任意数据,这些数据可以被多个不同的线程或会话访问和复用。一个管"对话流程状态",一个管"共享知识记忆"。
InMemoryStore 构造代码:
- embed:文本嵌入模型,用于文本向量化
- dims:嵌入模型维度。各个模型可能不同!!!
Python
in_memory_store = InMemoryStore(
index={
"embed": get_ali_embeddings(), # 文本向量化
"dims": 1024, # 嵌入模型固定输出维度。各个模型可能不同!!!
}
)咿?存储就存储呗,怎么参数还需要文本嵌入,这是为什么呢?我们上面也看到了 InMemoryStore 有检索 功能。长期记忆若只支持精确键值检索,则效用有限。向量LLM 的引入,将其升级为一个支持模糊联想、概念匹配 的智能检索系统。这也正是轻量化的 RAG 在记忆系统中的实践。
记忆 + 对话
记忆和对话是长时记忆的核心与灵魂。
Python
def call_model(state: MessagesState, config: RunnableConfig, *, store: BaseStore):
# 获取用户ID → 每个用户独立记忆空间
user_id = config["configurable"]["user_id"]
namespace = ("memories", user_id)
# 向量检索:从长时记忆中匹配当前对话相关信息
user_query = state["messages"][-1].content
memories = store.search(namespace, query=user_query)
user_info = "\n".join([data.value["data"] for data in memories])
# 构建系统提示:注入用户记忆
system_prompt = f"""
你是乐于助人的助手。
用户信息(请记住并使用):{user_info}
"""
# 判断:用户提到 remember → 自动存储记忆
last_msg = user_query.lower()
if "请记住" in last_msg:
# 提取用户真实输入的内容
new_memory = user_query.strip()
# 存储:命名空间 + 唯一ID + 记忆内容
store.put(namespace, str(uuid.uuid4()), {"data": new_memory})
# 调用AI生成回复(系统提示 + 对话历史)
response = model.invoke(
[{"role": "system", "content": system_prompt}] + state["messages"]
)
return {"messages": response}Graph 构造
Python
workflow = (
StateGraph(MessagesState)
.add_node("dialogue_with_memory", call_model)
.add_edge(START, "dialogue_with_memory")
)工作流编译
双记忆配置的 Graph:
checkpointer:短时对话记忆(聊天上下文)store:长时永久记忆(用户信息)
Python
agent = workflow.compile(
checkpointer=MemorySaver(),
store=in_memory_store
)示例代码
Python
config1 = {"configurable": {"thread_id": "1", "user_id": "1"}}
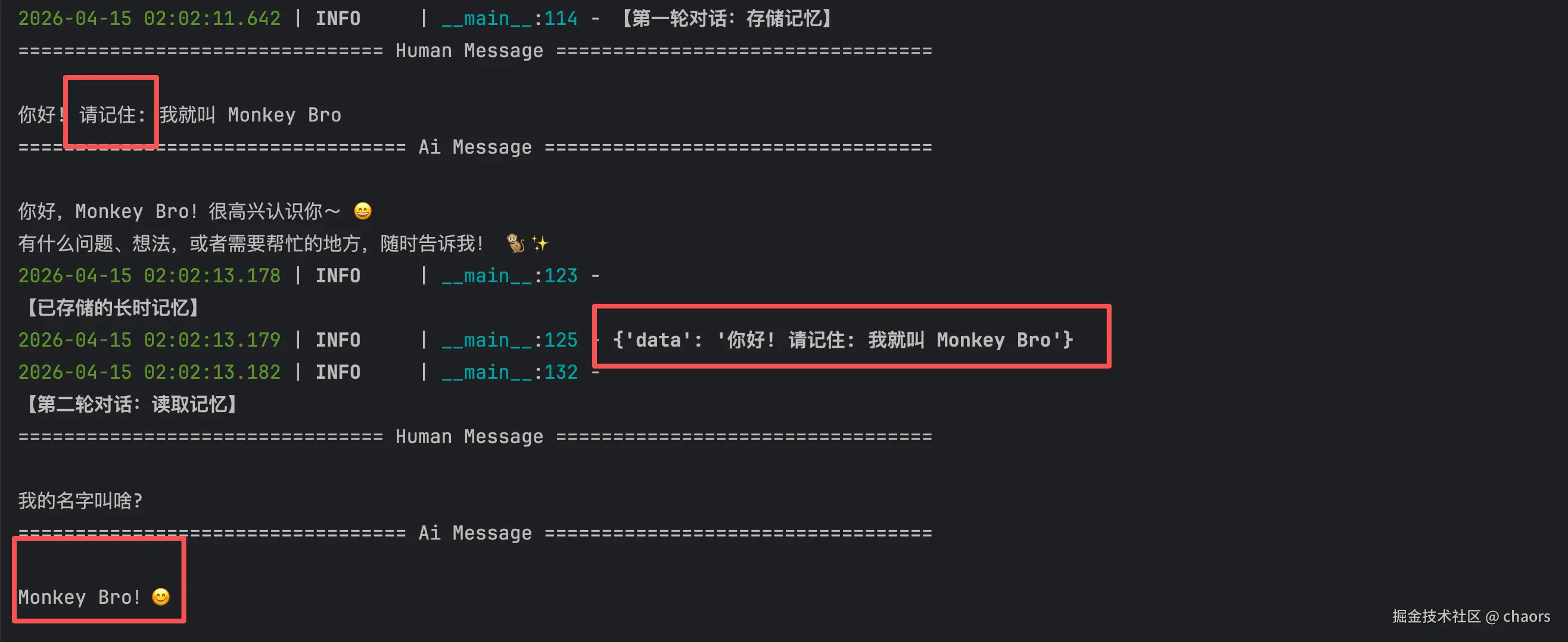
logger.info("【第一轮对话:存储记忆】")
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "你好! 请记住: 我就叫 Monkey Bro"}]},
config1,
stream_mode="values"
):
chunk["messages"][-1].pretty_print()
# 查看存储的记忆
logger.info("\n【已存储的长时记忆】")
for memory in in_memory_store.search(("memories", "1")):
logger.info(memory.value)
# --------------------------
# 测试2:跨线程读取记忆
# 换thread_id,依然能读取同一user_id的记忆
# --------------------------
config2 = {"configurable": {"thread_id": "3", "user_id": "1"}}
logger.info("\n【第二轮对话:读取记忆】")
for chunk in agent.stream(
{"messages": [{"role": "user", "content": "我的名字叫啥?"}]},
config2, stream_mode="values"
):
chunk["messages"][-1].pretty_print()Running