PageIndex 是一种无向量、基于推理的检索增强生成(RAG)方法,无需 Embedding、分块或向量数据库即可从长文档中检索答案。
它不依赖语义相似度搜索,而是从文档中构建一棵层次化的目录树(TOC),再由大语言模型对该结构进行推理。模型先借助文档的层级结构定位最相关的章节,然后导航至该章节,生成精确且带引用的答案。
传统 RAG 通过相似度进行检索。PageIndex 通过对结构的推理进行检索。
财务报告、法律合同、监管文件、政策文档、学术论文这种结构清晰的长文档都是它的优势领域。
多数 RAG 系统依赖 Embedding 和向量数据库:把文档拆成块,转成向量,用余弦相似度找答案。但相似度不是推理。PageIndex 采用了另一个方法,通过文档结构的推理而非语义搜索来检索信息。文档不再是一堆扁平文本,而是一个带层级的结构体系,类似于一本附有目录的教科书。
下面用经典电影《Sholay》来演示其工作原理。
核心思想:先理解结构,再进行搜索
把《Sholay》的剧本或详细剧情概要输入 PageIndex,它不会将文档拆分为任意的 500 词分块,而是构建故事的结构树:
Document → Hierarchical Index → Reasoning-Based Retrieval → Answer传统路径则是:
Document → Chunks → Embeddings → Vector DB → Similarity Search → Answer阶段一:创建树结构(索引阶段)
第一阶段完成结构化索引,分为两步。
1、结构检测
LLM 读取剧本,检测自然边界:场景标题("SCENE 1 --- THE TRAIN ROBBERY")、角色介绍、幕次分隔、重要叙事转折。它依赖的是叙事结构,而非固定的分块大小。
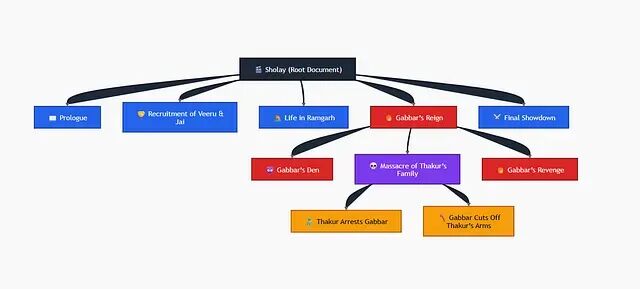
- 🎬 深色根节点 → 代表完整文档
- 🔵 蓝色 → 主要故事段落
- 🔴 红色 → Gabbar 相关故事线
- 🟣 紫色 → 关键事件节点
- 🟠 金色 → 具体事实事件
2、层次化映射
PageIndex 构建一棵树。根节点是 Sholay,第一级分支可能包括:序幕、招募 Veeru 和 Jai、Ramgarh 的生活、Gabbar 的恐怖统治、最终决战。每个分支还可以包含子节点。
以 Gabbar's Den 为例,其摘要为:"本节涵盖 Gabbar Singh 的出场介绍、'Kitne aadmi the'台词以及对手下的惩罚。"
每个节点包含:
titlenodeIdsummarychild nodes
关键在于LLM 为每个节点写一段简洁的语义描述的摘要说明该章节发生了什么,这段摘要在后续查询阶段将充当检索信号。
阶段二:查询阶段
假设用户提问:
为什么 Thakur 失去了双臂?
完整剧本不会被整体发送,不会生成 Embedding,也不会执行向量相似度搜索。LLM 接收到的只有三样东西:用户的问题、层次化映射(JSON 树)、每个节点的摘要。不是完整剧本,只有结构。
LLM 如何找到答案(推理,而非数学计算)
步骤 1:结构搜索
LLM 读取这棵树,看到"Thakur 家族的屠杀""Gabbar 的复仇""Ramgarh 的生活"等节点。根据摘要进行推理:答案很可能存在于涉及 Gabbar 和 Thakur 受伤的章节中。这是逻辑推理,不是向量相似度计算。
步骤 2:深入探索
PageIndex 随后仅检索这些特定节点对应的原始文本。不扫描 50 页内容,只取回 2-3 个聚焦章节。
步骤 3:最终回答
LLM 读取这段高度相关的文本片段,给出回答:
Thakur 失去双臂是因为 Gabbar Singh 为报复 Thakur 多年前的逮捕行为而将其双臂砍断。
同时附上引用:
(nodeId: massacre-thakur-family)检索过程可解释、可追溯。
PageIndex 与传统 RAG 的差异(针对结构化文档)
传统向量 RAG 系统中,搜索"Thakur 的手臂"可能返回:Jai 和 Veeru 打斗中使用手臂的场景、包含相似词汇的对话,以及"手"或"受伤"的无关提及。向量搜索按语义接近度检索,不考虑叙事相关性------本质上是在做"氛围匹配"。
PageIndex 不存在这个问题。屠杀场景的摘要已经明确写道:
"本节描述了 Gabbar 如何攻击 Thakur 的家族并砍断了他的双臂。"
LLM 不是在猜测,而是在导航。
PageIndex 有效的原因
它将两个认知任务分开处理:导航,确定答案应该存在的位置;提取,仅阅读该章节并生成答案。
这与人类的阅读方式相同。想知道小说中某件事为何发生,不会随机翻阅每一页,而是直接翻到相关事件所在的章节,PageIndex 让 LLM 遵循同样的行为模式。
适用场景
这种架构在以下场景中表现突出:财务报告、法律文档、政策文件、监管备案、学术研究、长篇叙事内容。凡是结构重要性超过表面相似度的场合,都是它的用武之地。
总结
传统 RAG 的假设:相关性等于语义相似度。PageIndex 的假设:相关性等于结构化推理。
差异看似微小,在长篇层次化文档中却影响深远。PageIndex 没有去造一个更好的搜索引擎,而是画了一张导航地图,让 LLM 先思考,再阅读。
https://avoid.overfit.cn/post/5a974d0889904edeb9cdca7945e132be
by Vishal Mysore