Prompt Engineering 提示词工程基础开发实践总结
一、提示词工程核心定位
-
定义 :通过设计、优化、结构化输入指令 ,引导大语言模型输出准确、稳定、可控 结果的工程化方法,是 LLM 应用开发的基础核心技能。
-
价值:提升输出质量、降低 API 成本、扩展应用场景、支撑 RAG/Agent/ 对话系统等复杂系统。
二、提示词工程核心原则
教程明确 6 条黄金原则,贯穿所有场景:
-
清晰具体:指令明确,避免模糊、歧义、隐含需求。
-
设定角色:先定义 AI 身份(专家 / 助手 / 分析师),锚定输出风格与知识域。
-
结构化表达:分点、分段、用分隔符,提升模型理解效率。
-
明确输出约束:指定格式、长度、语气、结构(JSON / 列表 / 表格)。
-
迭代优化:测试→评估→修正→再测试,持续调优。
-
控制上下文:精简信息,避免冗余干扰核心任务。
三、标准提示词结构(万能模板)
教程推荐5 要素结构,覆盖 90% 开发场景:
-
角色(Role):你是 XX 领域专家 / 助手
-
背景(Context):任务相关信息、数据、约束
-
任务(Instruction):明确要做什么(核心指令)
-
示例(Examples):Few‑shot 提供参考样例(可选但强烈推荐)
-
输出格式(Format):指定结构、长度、风格、禁用内容
万能公式
角色 + 背景 + 任务 + 示例 + 输出格式
四、提示词工程核心模块
4.1 简介与基础概念
4.1.1 LLM Token 机制
LLM 实际上并不是重复预测下一个单词,而是重复预测下一个 token 。对于一个句子,语言模型会先使用分词器将其拆分为一个个 token ,而不是原始的单词。对于生僻词,可能会拆分为多个 token 。这样可以大幅降低字典规模,提高模型训练和推断的效率。
对于英文输入,一个 token 一般对应 4 个字符或者四分之三个单词;对于中文输入,一个 token 一般对应一个或半个词。不同模型有不同的 token 限制,需要注意的是,这里的 token 限制是输入的 Prompt 和输出的 completion 的 token 数之和,因此输入的 Prompt 越长,能输出的 completion 的上限就越低。
4.1.2 LLM 提问范式
1.LLM 提问范式
在设计Prompt之前,必须要了解LLM专门的提问范式:
messages = [
{"role": "system",
"content": "You are an assistant... "},
{"role": "user",
"content": "Tell me a joke "},
{"role": "assistant",
"content": "Why did the chicken... "},
...
]2.核心角色
绝大多数LLM接口都支持的基础角色:System、User and Assistant Messages
三个核心角色的作用:
| 角色 | 作用 | 示例说明 |
|---|---|---|
| system(系统消息) | 给大模型设定全局人设、行为规则、约束条件,是整个对话的 "总纲领",通常放在对话最开头 | 示例中定义了助手的基础身份,也可以写 "你是专业的 Python 工程师,只回答技术问题" 这类定制化要求 |
| user(用户消息) | 代表用户的提问 / 指令 / 输入,是对话的触发源 | 示例中用户让模型 "讲个笑话" |
| assistant(助手消息) | 代表大模型的历史回复,用于维持多轮对话的上下文连贯性 | 示例中是模型讲的笑话内容,后续对话会基于这段历史理解上下文 |
3.为什么这个结构是 LLM 对话的核心?
大模型本身是 "无状态" 的,所有对话上下文都靠这个 messages 数组传递:
-
系统消息:全局人设,全程生效
-
用户 + 助手历史:多轮对话的上下文,让模型记得之前聊了什么
-
新的用户消息:当前轮次的任务指令
4. 实际开发中的关键用法
-
系统提示词(System Prompt)是提示词工程的核心:好的系统提示能让模型输出更稳定、更符合需求,比如设定角色、输出格式、安全规则等。
-
多轮对话必须完整传递历史消息:否则模型会 "失忆",无法承接上下文。
-
角色顺序有规范 :通常
system在最前,user和assistant交替出现,不能出现连续的user或assistant消息(部分模型支持特殊格式,但通用 API 不允许)。
4.2 提示原则(核心)
-
指令清晰化、角色设定、上下文管理、输出约束、否定指令(不要做什么)
-
温度(temperature)、top_p 等参数对输出的影响
4.3 迭代优化(工程化关键)
流程:初版 Prompt → 测试 → 问题定位 → 修改 → 验证 → 固化模板
目标:稳定输出、减少幻觉、提升可复现性。
4.4 基础Prompt类型
文本概括(Summarizing)
-
精简摘要、要点提取、指定长度 / 角度、多文档合并总结
-
实战:新闻、评论、报告、客服记录总结
推断(Inferring)
-
情感分析、主题提取、实体识别、意图分类、观点抽取
-
零样本 / 少样本分类,适合业务标签、舆情分析。
文本转换(Transforming)
-
翻译、文风改写、格式转换(文本→JSON/HTML/ 表格)
-
语气调整、语言标准化、代码注释生成
文本扩展(Expanding)
-
扩写、润色、续写、内容丰富化
-
控制创意度、保持信息一致性、避免冗余
聊天机器人(Chatbot)
-
系统人设、多轮对话、上下文记忆、回复风格统一
-
安全过滤、意图识别、任务闭环设计
五、高级提示技巧
1. 思维链推理(CoT)
-
强制模型分步思考,大幅提升逻辑题、数学题、推理题准确率
-
用法:请一步步思考并给出推导过程。
2. 提示链(Chaining Prompts)
-
复杂任务拆分为多步 Prompt,前一步输出作为后一步输入
-
适合:长文本处理、多阶段分析、复杂决策系统。
3. 少样本提示(Few‑shot)
-
提供 3--5 个高质量示例,模型快速对齐任务范式
-
比零样本更稳定,比微调成本更低。
4. 自我一致性(Self‑Consistency)
- 生成多个答案,投票选最优,降低随机性与错误率
5. 输出校验(Check Outputs)
-
用规则 / 模型二次校验,过滤幻觉、错误、敏感内容
-
工程化必备,提升系统可靠性。
六、提示词工程开发流程
-
需求拆解:明确任务、输入、输出、约束、评估指标
-
Prompt 编写:按 5 要素模板构建初版
-
API 调用:Python + Jupyter + LLM API(OpenAI 等)
-
效果评估:准确率、一致性、格式合规性、幻觉率
-
迭代调优:优化指令、增删示例、调整参数
-
模板固化:封装为可复用函数 / 配置文件,用于生产系统
七、与 LangChain 结合(工程落地)
-
模型 + 提示 + 解析器:统一管理 Prompt,自动解析结构化输出
-
记忆(Memory):对话历史管理,多轮 Prompt 上下文保持
-
链(Chains):将多步 Prompt 封装为可调用链路
-
RAG 场景:文档检索 + 提示词工程,实现私有数据问答
-
Agent:用 Prompt 定义能力边界与工具调用规则。
八、中文提示词最佳实践
-
提供中英等效 Prompt,适配中文语境理解与生成
-
避免直译英文句式,用清晰、简洁、符合中文表达的指令
-
长文本用分隔符(---/###),提升模型注意力
-
复杂任务优先分步 + 示例 + 格式三重保障。
九、开发路线
-
初级:面向开发者的提示词工程 → 搭建 AI 问答系统
-
进阶:LangChain 提示管理 → 提示链 + 评估 + 输出校验
-
高阶:RAG 提示优化 → 高级检索 + 复杂 Agent 提示设计。
十、智能问答系统基础Prompt Engineering开发实践
核心目标
- 实现一个提示模板子系统,支持用户创建、编辑、选择和复用带动态变量的提示。
- 后端通过 JSON 文件存储模板,提供 API 接口;
- 前端配套管理 UI 并在聊天页集成选择 / 变量表单;
- 运行时将填充后的模板作为系统提示注入模型调用。
实施步骤
1. 数据模型与存储
- 定义
Prompt结构(含id/name/description/template)。 - 新建
backend/prompts.json(空数组)和backend/prompt_manager.py(带文件锁的模板加载 / 保存逻辑)。
prompts.json 结构
[
{
"id": "ae8f20f2-5309-407a-baa7-f0dda7dc2c32",
"name": "multi-assistant",
"description": "动态assistant助手",
"system": "你是一个{role},请用{style}方式回答。参考信息:{last_assistant_message}",
"template": "请用{style}的方式回答这个问题:{input}"
}
]prompt_manager.py
"""
Prompt 管理模块
- 负责从文件加载/保存 prompt 模板
- 提供 CRUD 辅助函数
存储格式为 JSON 列表,列表中的每项代表一个 prompt:
{
"id": "uuid",
"name": "...",
"description": "...",
"template": "..."
}
文件级别 I/O 使用简单的线程锁以避免并发写入冲突。
"""
import json
import threading
import uuid
from typing import List, Dict, Optional
import os
# store file next to this module to avoid relative path issues
PROMPT_FILE = os.path.join(os.path.dirname(__file__), "prompts.json")
_lock = threading.Lock()
logger = __import__('logging').getLogger(__name__)
def _load_all() -> List[Dict]:
"""从磁盘读取所有 prompt"""
try:
with open(PROMPT_FILE, "r", encoding="utf-8") as f:
data = json.load(f)
if isinstance(data, list):
return data
except FileNotFoundError:
# 文件不存在时返回空列表
logger.warning(f"Prompt file '{PROMPT_FILE}' not found. Returning empty list.")
return []
except Exception as e:
# 出现问题时尽量返回空
logger.error(f"Error occurred while loading prompts from '{PROMPT_FILE}': {e}. Returning empty list.")
return []
return []
def _save_all(prompts: List[Dict]) -> None:
"""写回 prompt 列表到磁盘"""
with _lock:
with open(PROMPT_FILE, "w", encoding="utf-8") as f:
json.dump(prompts, f, indent=2, ensure_ascii=False)
def list_prompts() -> List[Dict]:
"""返回所有 prompt
新版本的 prompt包含 ``system`` 字段,旧数据会保持兼容。
会在返回前补齐缺失字段。
"""
prompts = _load_all()
for p in prompts:
if "system" not in p:
p["system"] = ""
if "template" not in p:
p["template"] = ""
return prompts
def get_prompt(prompt_id: str) -> Optional[Dict]:
"""根据 id 查找单个 prompt
如果找到了 prompt,会确保返回值包含 ``system`` 和 ``template`` 键(老数据兼容)。
"""
for p in _load_all():
if p.get("id") == prompt_id:
# compatibility: ensure both keys exist
if "system" not in p:
p["system"] = ""
if "template" not in p:
p["template"] = ""
return p
return None
def add_prompt(name: str, description: str, system: str, template: str) -> Dict:
"""创建新的 prompt 并返回它
Args:
name: 提示词名称
description: 可选描述
system: 系统消息内容(会作为 system-role 注入)
template: 变量模板,用于可选的用户消息/展示等
"""
prompts = _load_all()
new_prompt = {
"id": str(uuid.uuid4()),
"name": name,
"description": description,
# keep both fields for backward compatibility
"system": system,
"template": template,
}
prompts.append(new_prompt)
_save_all(prompts)
return new_prompt
def update_prompt(prompt_id: str, name: str, description: str, system: str, template: str) -> Optional[Dict]:
"""更新现有的 prompt,返回更新后的对象或 None"""
prompts = _load_all()
for idx, p in enumerate(prompts):
if p.get("id") == prompt_id:
prompts[idx] = {
"id": prompt_id,
"name": name,
"description": description,
"system": system,
"template": template,
}
_save_all(prompts)
return prompts[idx]
return None
def delete_prompt(prompt_id: str) -> bool:
"""删除指定 id 的 prompt,成功返回 True"""
prompts = _load_all()
new_list = [p for p in prompts if p.get("id") != prompt_id]
if len(new_list) == len(prompts):
return False
_save_all(new_list)
return True2. 后端 API
-
新增 Flask 路由:提示的 CRUD 接口(
GET/POST/PUT/DELETE /api/prompts)。API 接口
GET /api/prompts→ listPOST /api/prompts→ createPUT /api/prompts/<id>→ updateDELETE /api/prompts/<id>→ removeGET /api/prompts/<id>→ get
-
扩展聊天接口(
/api/chat//api/chat/stream),支持接收prompt_id和variables。@app.route('/api/chat/stream', methods=['POST'])
@require_llm
@require_session
def chat_stream():
"""
聊天接口(流式响应)Request: { "session_id": "...", "message": "用户输入", "max_tokens": 512, "temperature": 0.7, "top_p": 0.95 } Yields: SSE 格式的数据流:data: <token>\n\n """ try: data = request.get_json() session_id = data['session_id'] user_message = data.get('message', '') max_tokens = data.get('max_tokens', 512) temperature = data.get('temperature', 0.7) top_p = data.get('top_p', 0.95) prompt_id = data.get('prompt_id') variables = data.get('variables', {}) if not user_message: return jsonify({ "code": 400, "error": "Empty message" }), 400 # 处理 prompt 和用户消息 system_content = None if prompt_id: prompt = pm_get(prompt_id) if prompt: system_content = prompt.get("system", "") # 填充 system 内容中的变量 if system_content: system_content = fill_template(system_content, variables, user_message, context_manager.get_conversation_history(session_id)) # 填充用户消息,如果有 template if "template" in prompt and prompt["template"]: user_message = fill_template(prompt["template"], variables, user_message, context_manager.get_conversation_history(session_id)) # persist prompt selection server-side for multi-device context_manager.set_prompt(session_id, prompt_id, variables) else: return jsonify({"code": 400, "error": "Invalid prompt_id"}), 400 logger.info(f"Received chat stream request: session_id={session_id}, user_message='{user_message}', prompt_id={prompt_id}, variables={variables}") # 添加用户消息到上下文 context_manager.add_message(session_id, "user", user_message) # 获取基础对话历史 base_history = context_manager.get_conversation_history(session_id) # 构建最终对话历史,确保system在最前面 conversation_history = build_conversation_with_system(base_history, system_content) def generate(): """生成流式数据""" full_response = "" try: for token in llm_inference.chat_generate_stream( messages=conversation_history, max_tokens=max_tokens, temperature=temperature, top_p=top_p ): full_response += token # 以 SSE 格式返回数据 yield f"data: {json.dumps({'token': token, 'session_id': session_id})}\n\n" # 添加完整响应到上下文 context_manager.add_message(session_id, "assistant", full_response) # 发送完成标记 yield f"data: {json.dumps({'done': True, 'session_id': session_id})}\n\n" except Exception as e: logger.error(f"Error in stream generation: {e}") yield f"data: {json.dumps({'error': str(e)})}\n\n" return Response( stream_with_context(generate()), mimetype='text/event-stream', headers={ 'Cache-Control': 'no-cache', 'X-Accel-Buffering': 'no' } ), 200 except Exception as e: logger.error(f"Error in chat stream endpoint: {e}") return jsonify({ "code": 500, "error": str(e) }), 500 -
聊天请求时:加载模板 → 变量替换(
{var}语法 + 会话保留令牌如last_user_message)→ 作为系统提示前置到消息列表。def fill_template(template: str, variables: dict = None, user_input: str = "", session_history: list = None) -> str:
"""使用 Python str.format 风格的变量替换- 占位语法:`{name}` 或 `{name=default}`(类似 Python str.format) - 优先使用传入的 ``variables``,否则使用模板中的默认值 - 支持保留关键词: - {input}: 用户输入的问题内容 - {last_user_message}: 上一条用户消息 - {last_assistant_message}: 上一条助手消息 Args: template: 包含占位符的模板字符串 variables: 用户提供的变量字典 user_input: 用户输入的问题内容,用于填充 {input} session_history: 会话历史列表,用于填充保留关键词 Returns: 填充后的字符串 """ if not template: return "" variables = variables or {} session_history = session_history or [] # 准备保留值 last_user = "" last_assistant = "" # 从session_history中提取最后的user和assistant消息 if session_history: for msg in reversed(session_history): if msg.get("role") == "user" and not last_user: last_user = msg.get("content", "") if msg.get("role") == "assistant" and not last_assistant: last_assistant = msg.get("content", "") if last_user and last_assistant: break def replace_func(match): name = match.group(1) default = match.group(2) or "" # 保留关键词(优先级最高) if name == "input": return user_input if name == "last_user_message": return last_user if name == "last_assistant_message": return last_assistant # 用户提供的变量(优先级其次) if name in variables: return str(variables[name]) # 返回默认值(优先级最低) return str(default) import re # 匹配 {name} 或 {name=default},支持前后空格 pattern = re.compile(r"\{\s*([\w_]+)(?:=([^}]*))?\s*\}") result = pattern.sub(replace_func, template) logger.info(f"Filled template: '{template}' with variables {variables} to '{result}'") return result
3. 前端 UI
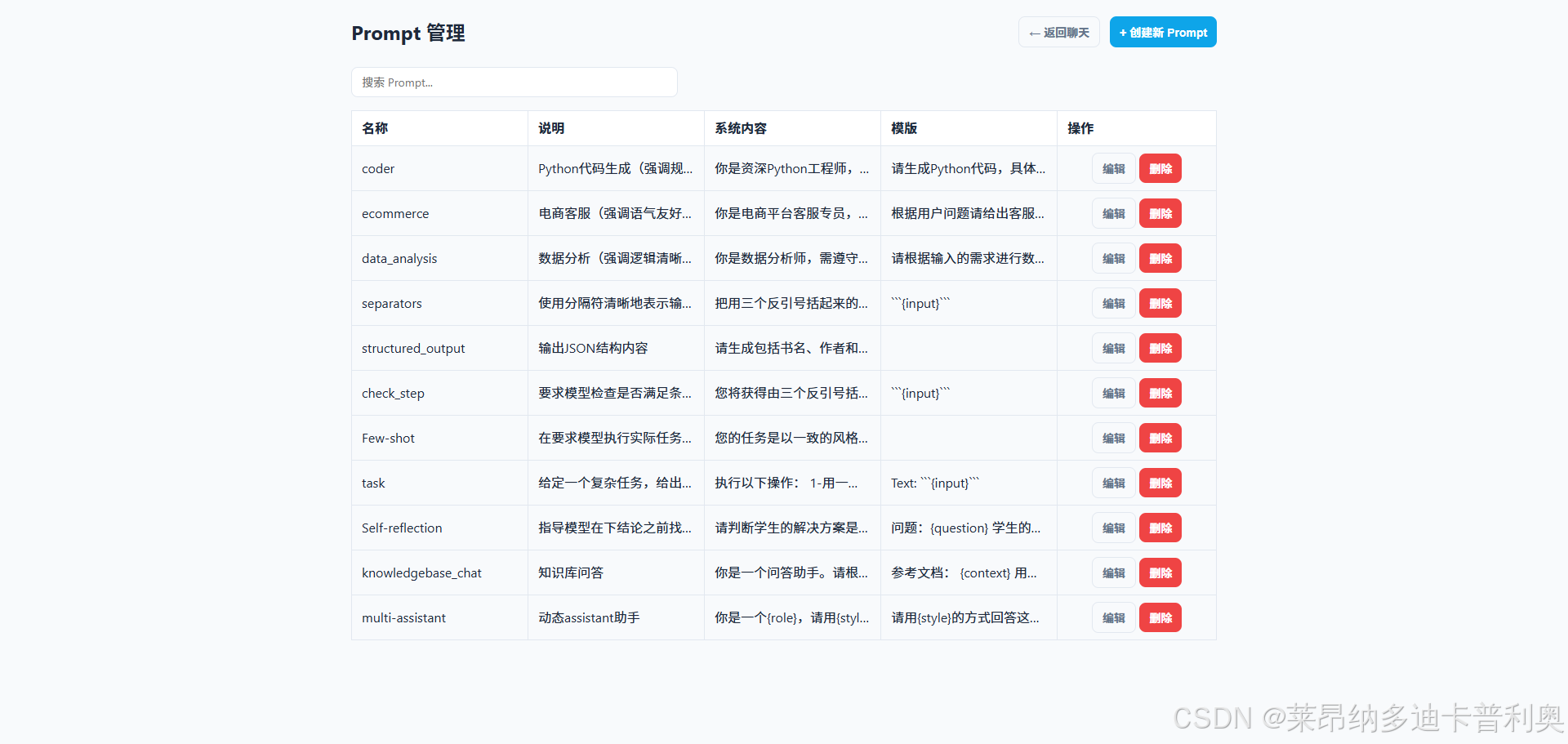
- 提示管理页:列表 / 搜索、创建 / 编辑表单(名称 / 描述 / 模板文本域)、保存 / 删除。
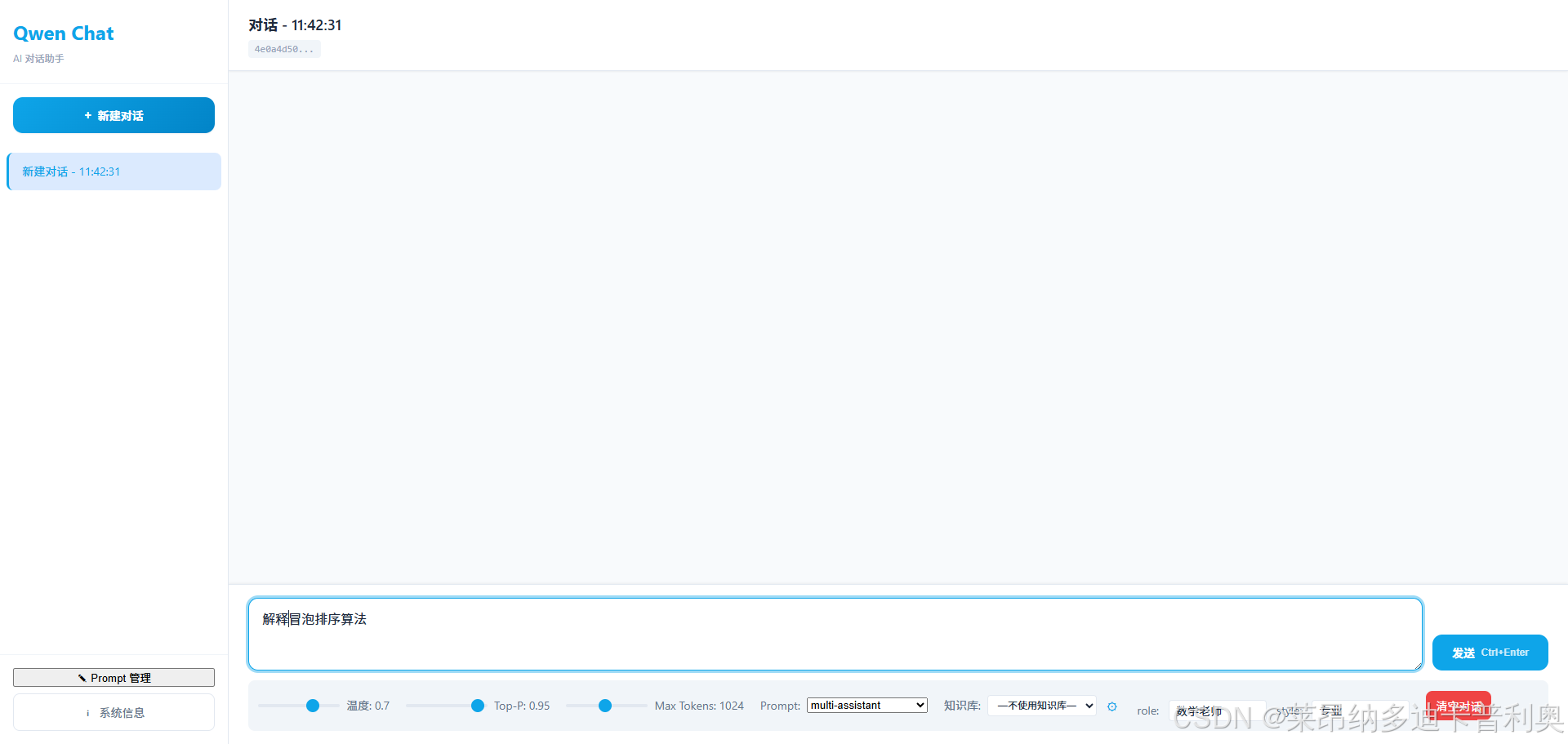
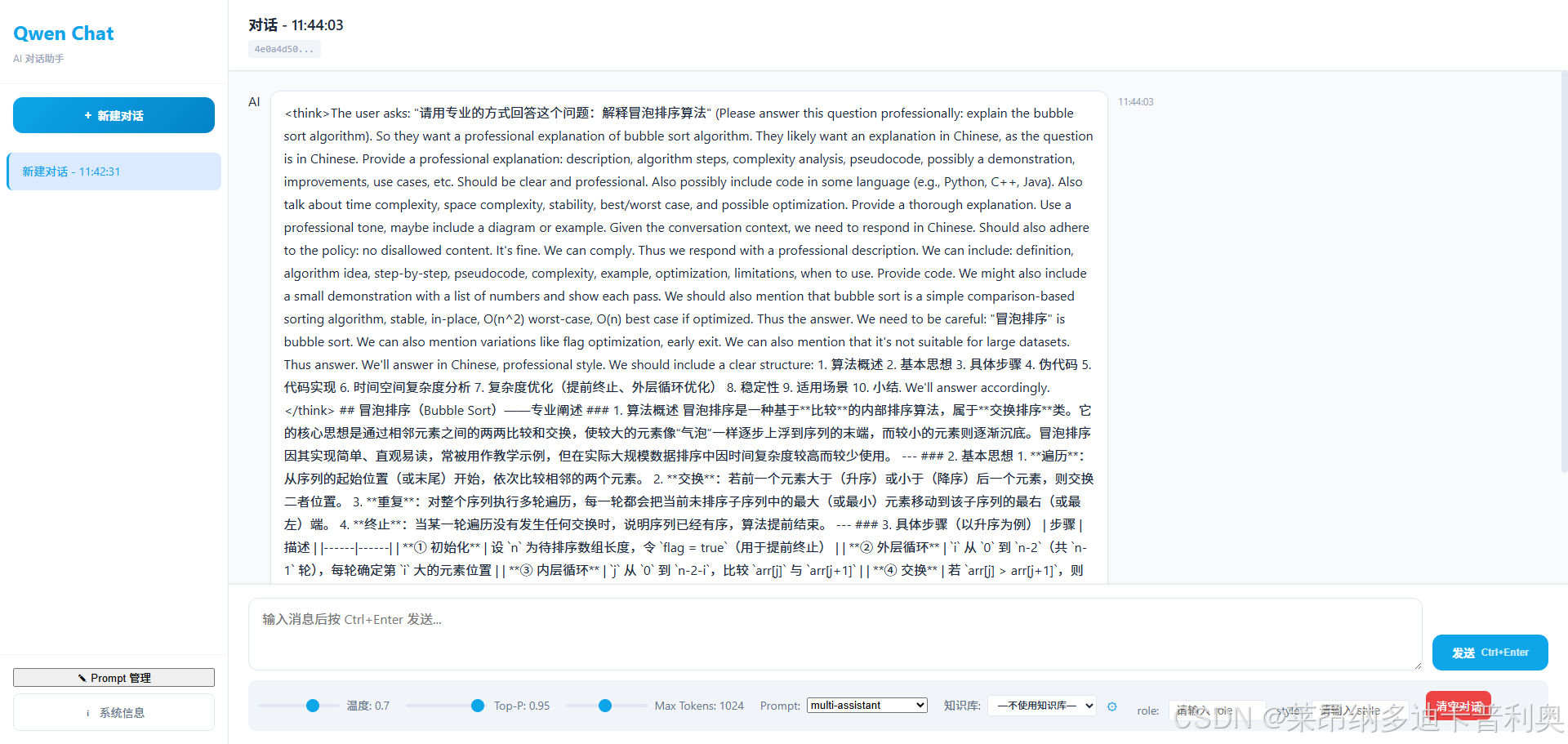
- 聊天界面 :添加提示下拉框,选中后解析
{...}变量并展示输入框,请求时携带prompt_id和变量映射。
十一、核心总结
提示词工程不是 "写咒语",而是用自然语言做编程:
-
以清晰原则为基础
-
以结构化模板为工具
-
以迭代优化为方法
-
以工程化落地为目标
掌握这套体系,可快速开发稳定可用的摘要、分类、翻译、对话、RAG、Agent 等 LLM 应用。