项目总览:
数据库表可以通过hive转为数据仓库的维度表,我们只需要写sql,就可以通过hive转为可以查数据仓库的语句。
基于事实表+维度表。
比如用户下单这一个事实(业务事件),用户a,在北京,晚上12点,下单了2个篮球,总共花费120元。
转换成事实表就是:
sql
order_id //事实表id
user_id //用户id
localtion_id //地点id
date_id //时间id
produce_id //商品id
order_quantity // 数量
order_amount // 花费维度就是,时间维度,用户维度,地点维度,商品维度,分别对应上述的id。
比如用户维度
python
user_id
user_name
grader //性别
member_level //级别除了用户下单这一事实表,还可能有加入购物城等,他们可能共用这些维度表。
项目效果:
输入统计各地区销量排名前三的商品
那么得 select地区表 join 事实表 + join 商品维度表 + count(order_amount) + order排序 得到。
我们可以通过大模型转为sql直接查询数据库数据内容。
思路:
- 1 将所有数据库表的名字+字段描述统统作为prompt交给大模型,让大模型自己分析;这样做有缺点:如果表太多了,字段太多了,都作为prompt导致上下文太长,如果提示词太多,包含太多无关信息,大模型会对其中的某个字段"忘记",导致解析报错。
- 2 正确思路:使用
RAG,建立一下metadata元数据的知识库,里面包含数仓里面的信息和表的字段描述(记录有哪些表,是事实表还是维度表,有哪些字段等),然后给予问题,去知识库里面,检索跟问题密切的表相关信息,将这些表信息作为上下文交给LLm,让其生成sql。解决上下文太长问题。
基于Langgraph的数据仓库,以数据仓库的元数据为核心,使用mysql存储结构话的元数据信息,结合Odrant构建语义向量检索,Elasticsearch构建全文索引,形成统一的元数据知识库,查询过程中,根据用户的自然语言问题进行多路召回,筛选相关表,字段以及指标定义,将元数据信息和用户问题,共同作为prompt传给大模型,生成SQL,最终完成自动查询与结果返回,确保生成的准确性和可控性。
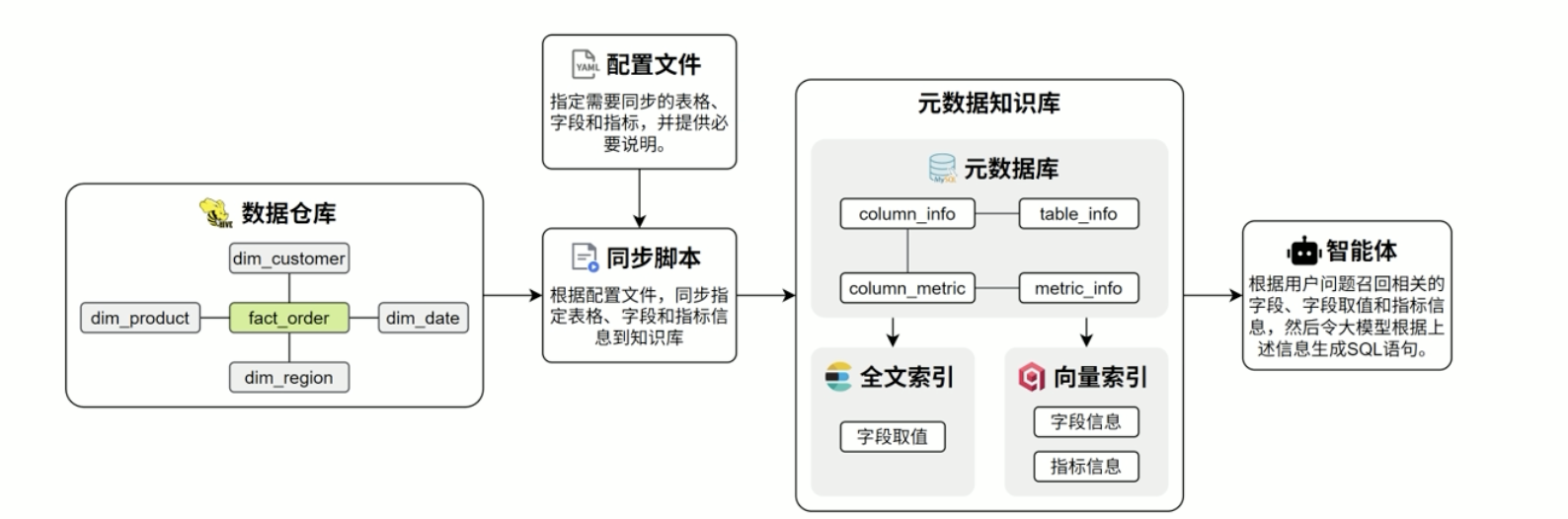
使用docker启动需要的服务
yaml
services:
mysql:
image: mysql:8.0
container_name: mysql
restart: unless-stopped
environment:
MYSQL_ROOT_PASSWORD: xxx
ports:
- "3306:3306"
volumes:
- mysql_data:/var/lib/mysql
- ./mysql:/docker-entrypoint-initdb.d
command:
--character-set-server=utf8mb4
--collation-server=utf8mb4_general_ci
elasticsearch:
build: ./elasticsearch
container_name: elasticsearch
restart: unless-stopped
environment:
discovery.type: single-node
xpack.security.enabled: "false"
ES_JAVA_OPTS: "-Xms512m -Xmx512m"
ports:
- "9200:9200"
volumes:
- es_data:/usr/share/elasticsearch/data
kibana:
image: kibana:8.19.10
container_name: kibana
restart: unless-stopped
environment:
ELASTICSEARCH_HOSTS: http://elasticsearch:9200
ports:
- "5601:5601"
depends_on:
- elasticsearch
qdrant:
image: qdrant/qdrant:v1.16
container_name: qdrant
restart: unless-stopped
ports:
- "6333:6333" # HTTP
- "6334:6334" # gRPC
volumes:
- qdrant_data:/qdrant/storage
embedding:
image: ghcr.io/huggingface/text-embeddings-inference:cpu-1.8
platform: linux/amd64
container_name: embedding
restart: unless-stopped
ports:
- "8081:80"
environment:
- MODEL_ID=BAAI/bge-small-zh-v1.5
- MAX_CONCURRENT_REQUESTS=16
- MAX_BATCH_TOKENS=16384
#- HF_ENDPOINT=https://hf-mirror.com
volumes:
- ./embedding_cache:/data
volumes:
mysql_data:
es_data:
qdrant_data:这里需要几个服务,mysql数据库,embedding向量化服务,这里我们选择自己部署向量化模型,数据安全,qdrant向量数据库,elasticsearch全文检索
qdrant向量数据库

官网介绍,在传统的 OLTP 和 OLAP 数据库中(如上图所示),数据以行和列的形式组织(这些被称为表),查询是根据这些列中的值执行的。
Qrdant是一个向量数据库,他对比传统OLTP数据库,如msqql,是基于一行一列的。
OLAP数据库,主要是针对于列的,比如查销售总和等数据.
而向量数据库,主要是由id,向量数组,payload(存放一些元数据)组合,可以通过比对向量相似性,获取较为相似的前n条数据。
在包括图像识别、自然语言处理和推荐系统在内的某些应用中,数据通常表示为高维空间中的向量,这些向量,加上一个 id 和一个有效负载,我们称之为点。这些点是我们存储在 Qdrant 等向量数据库中的一种称为集合的元素。
集合可以类比为就是表
向量相似度最常用的检索相似方式:

最常用的就是余弦相似度。
Qrant架构:
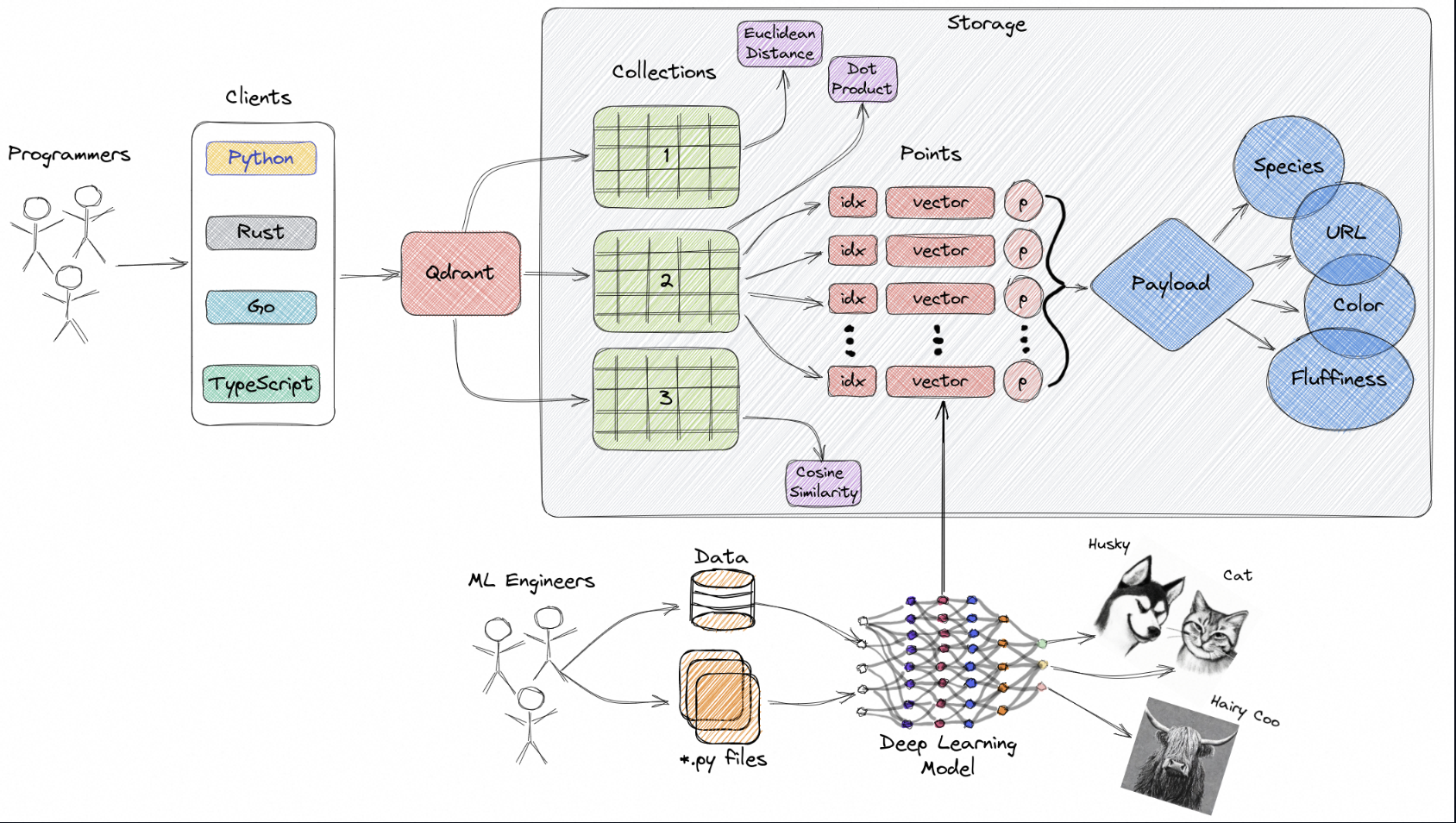
Qrant的概念:
*集合:集合是一组已命名点(带有有效载荷的向量),您可以在其中进行搜索。同一集合中每个点的向量必须具有相同的维度,并且通过单一指标进行比较。命名向量可用于在单个点中包含多个向量,每个向量可以有自己的维度和指标要求,集合就好比mysql的一张表
距离度量:这些用于衡量向量之间的相似性,并且必须在创建集合的同时选择。度量的选择取决于向量的获取方式,特别是将用于编码新查询的神经网络。选取用什么方式判断点:点是 Qdrant 操作的中心实体,它们由一个向量和一个可选的 id 和有效载荷组成。点可以类比为myql的一行数据
id:向量的唯一标识符。
向量:数据的高维表示,例如图像、声音、文档、视频等。
Payload:Payload 是一个 JSON 对象,其中包含您可以添加到向量中的额外数据。存储:Qdrant 可以使用两种存储选项之一,内存存储(将所有向量存储在 RAM 中,速度最快,因为仅需要磁盘访问才能持久化),或者内存映射存储(创建与磁盘文件关联的虚拟地址空间)。客户端:可用于连接 Qdrant 的编程语言。Qrant官方提供的qdrant_client,可以通过它操作qrant数据库。
使用demo
因为正常链接等操作是同步的,会阻塞主线程工作,所以我们需要用异步的api
先创建一个manager单例
python
import asyncio
from typing import Optional
from qdrant_client import AsyncQdrantClient, models
from app.conf.app_config import QdrantConfig, app_config
class QrantClientManager:
def __init__(self, qdrant_config: QdrantConfig):
self.qdrant_config = qdrant_config
# Optional[a] = a | None
self.client: Optional[AsyncQdrantClient] = None
pass
def _get_url(self):
return f"http://{self.qdrant_config.host}:{self.qdrant_config.port}"
def init(self):
# 使用异步api
self.client = AsyncQdrantClient(url=self._get_url())
async def close(self):
# close是异步的,需要await
await self.client.close()
qdrant_client_manager = QrantClientManager(app_config.qdrant)负责进行数据库的统一操作。
测试:
python
if __name__ == "__main__":
# 先初始化连接客户端
qdrant_client_manager.init()
async def _test():
client = qdrant_client_manager.client
# Create a collection create_collection创建向量
await client.create_collection(
collection_name="my_collection",
# size=4 --- 每个向量的维度是 4(实际项目中通常是 384、768、1024 等,取决于 embedding 模型)
# 使用余弦相似度来计算向量之间的距离,越接近 1 越相似
vectors_config=models.VectorParams(size=4, distance=models.Distance.COSINE),
)
# Insert a vector upsert插入向量
await client.upsert(
collection_name="my_collection",
points=[
models.PointStruct(
id="5c56c793-69f3-4fbf-87e6-c4bf54c28c26",
payload={
"color": "red",
},
vector=[0.9, 0.1, 0.1, 0.5],
),
],
)
# query_points查询
points = await client.query_points(
collection_name="my_collection",
query=[0.9, 0.1, 0.1, 0.5],
limit=2,
)
print(points.points)
asyncio.run(_test())如上,create_collection负责创建集合,需要指定集合名,以及向量维度和距离度量,就是vectors_config,上述我们使用了余弦相似度。
upsert负责插入点,而query_points负责查询点,他们都是异步的
结果:
python
[ScoredPoint(id='5c56c793-69f3-4fbf-87e6-c4bf54c28c26', version=3, score=1.0,
payload={'color': 'red'}, vector=None, shard_key=None, order_value=None)]- id --- 该向量记录的唯一 ID(UUID 格式)
- version --- 数据的版本号(第 3 次更新)
- score=1.0 --- 余弦相似度得分,1.0 表示完全匹配(和查询向量一模一样)
- payload={'color': 'red'} --- 存储时附带的业务数据
- vector=None --- 未返回原始向量(默认不返回,节省带宽)
- shard_key=None --- 未使用分片
- order_value=None --- 未使用自定义排序
ES客户端管理
我们使用了ES进行全文检索,也就是elasticsearch
Elasticsearch 是一个开源的分布式搜索和分析引擎,专为速度、扩展和 AI 应用而打造。作为一个检索平台,它可以实时存储结构化、非结构化和向量数据,提供快速的混合和向量搜索,支持可观测性与安全分析,并以高性能、高准确性和高相关性实现 AI 驱动的应用。
上述我们启动了一个es的docker服务,在生产中,es服务可能有多个。
ES的核心概念
- Cluter集群,一个或者多个节点的集合,共同保存整个数据,提供跨越所有节点的联合索引和搜索功能。
- Node 节点:集群的一台服务器,比如上面我们启动的es服务。
- Index(索引):包含有一对相似结构的文档数据,类比为
qrdant的集合 - Document(文档): Es中的最小数据单元,文档以JSON格式表示(类比为
qrdant的点) - Field(字段):文档中的属性,类比为
mysql的每一列 - Mapping(映射):定义文档中字段的类型(Text,keyword等),类似于表架构
schema。 - 分片和复制 :ES提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的"索引",这个"索引"可以被放置到集群中的任何节点上。当我你有一份10亿的文档数据,就可以进行分片,放到不同节点去。
复制主要是防止一个节点故障导致无法检索,所以对索引进行复制放置不同节点。
主要应用场景:
- 全文搜索:例如电商网站的商品搜索、维基百科的文章搜索。它支持分词、同义词、拼写纠错、高亮显示等强大的搜索功能。
- 日志和指标分析:通过 ELK 架构(Elasticsearch, Logstash/Beats, Kibana),集中收集和分析服务器、应用和网络设备的日志与性能指标。
- 应用性能监控 (APM):监控应用程序的代码级性能问题。
- 地理空间数据分析:支持处理经纬度等空间数据,常用于打车软件、物流追踪等寻找"附近"资源的场景
使用demo
依然使用异步的api来操作
管理端
python
import asyncio
import datetime
from typing import Optional
from elasticsearch import AsyncElasticsearch
from app.conf.app_config import ESConfig, app_config
class EsClientManager:
def __init__(self, es_config: ESConfig):
self.es_config = es_config
self.client: Optional[AsyncElasticsearch] = None
pass
def _get_url(self):
return f"http://{self.es_config.host}:{self.es_config.port}"
def init(self):
# 单节点
self.client = AsyncElasticsearch(hosts=[self._get_url()])
pass
async def close(self):
await self.client.close()
es_client_manager = EsClientManager(app_config.es)测试
python
if __name__ == "__main__":
es_client_manager.init()
async def _test():
client = es_client_manager.client
# 索引名称
index_name = "async_products"
# 判断是否存在,存在先删除
if await client.indices.exists(index=index_name):
await client.indices.delete(index=index_name)
print(f"索引 {index_name} 已删除。")
# 创建索引
await client.indices.create(
index=index_name,
mappings={
"dynamic": False, #不要动态推算字段类型
"properties": {
"product_id": {
"type": "keyword", # 关键词,不分词
},
"title": {
"type": "text",
# 使用标准分析器分词,规则是按空格和标点拆分,并转小写
#"analyzer": "standard",
},
"price": {
"type": "double",
},
"date": {
"type": "date",
"format": "yyyy-MM-dd"
}
}
}
)
# put_maping插入单条,bluk插入多条
bulk_resp = await client.bulk(
operations=[
{
"index": {
"_index": index_name,
},
},
{
"product_id": 1,
"title": "test_1",
"price": 2,
"date": "2020-01-01",
},
{
"index": {
"_index": index_name,
}
},
{
"product_id": 2,
"title": "test_2",
"price": 3,
"date": "2020-01-02",
}
],
refresh=True,
)
# 搜索
resp = await client.search(
index=index_name,
query={
"match": {
"title": "test_1"
}
}
)
for hit in resp["hits"]["hits"]:
print(hit["_source"])
print("\n")
resp1 = await client.search(
index=index_name,
query={
"term": {
"product_id": 2
}
}
)
for hit in resp1["hits"]["hits"]:
print(hit["_source"])
print("\n")
resp2 = await client.search(
index=index_name,
query={
"range": {
"price": {
# <=3
"lte": 3
}
}
}
)
for hit in resp2["hits"]["hits"]:
print(hit["_source"])
print("\n")
await es_client_manager.close();
asyncio.run(_test())如上,通过client.indices.create创建索引,可以指定mapping,keyword表示精确索搜索,默认不会分词。
通过bluk插入多条数据。
通过search查询数据,match就是全文检索,模糊搜索,而term则是精确搜索,比如搜索关键词keyword那些,range则是对范围的过滤。
python
response = await client.search(
index=index_name,
query={
"bool": {
"must": [
{"term": {"manufacturer": "Apple"}}
],
"filter": [
{"range": {"price": {"gt": 10000.0}}}
]
}
}
)如上,bool可以进行复合查询,must表示必须满足条件,且会计算得分sorce。filter则表示需要满足条件,但不会影响得分sorce。
ES 会对 filter 的结果进行缓存,因此执行效率非常高。通常用于价格范围、日期范围、状态过滤等精确条件。
search返回结果
python
{'took': 0, 'timed_out': False,
'_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0},
'hits': {'total': {'value': 1, 'relation': 'eq'},
'max_score': 0.6931471,
'hits': [{'_index': 'async_products', '_id': '3V0mdZ0BBFefatfR557V', '_score': 0.6931471, '_source': {'product_id': 1, 'title': 'test_1', 'price': 2, 'date': '2020-01-01'}}]}}字段解析:
- took: 0 --- 查询耗时 0 毫秒
- timed_out: False --- 未超时
- _shards --- 分片信息:1 个分片,全部成功
- hits.total.value: 1 --- 命中 1 条记录
- max_score: 0.6931471 --- 最高相关性得分
命中的文档:
- _index --- 所在索引 async_products
- _id --- ES 自动生成的文档 ID
- _score: 0.6931471 --- 该文档的相关性得分(基于 TF-IDF/BM25 算法计算,越高越相关)
- _source --- 文档原始内容:product_id=1, title=test_1, price=2, date=2020-01-01
有一个最高相似性得分。
Embedding 客户端管理
我们通过docker部署了文本嵌入模型,客户端使用langchain提供的HuggingFaceEndpointEmbeddings
比较简单,直接写clientManager
python
from typing import Optional
from langchain_huggingface import HuggingFaceEndpointEmbeddings
from app.conf.app_config import EmbeddingConfig, app_config
class EmbeddingClientManager:
def __init__(self, config: EmbeddingConfig):
self.client:Optional[HuggingFaceEndpointEmbeddings] = None
self.config = config
def _get_url(self):
return f"http://{self.config.host}:{self.config.port}"
def init(self):
# 使用自己部署的模型
self.client = HuggingFaceEndpointEmbeddings(model=self._get_url())
embedding_client_manager = EmbeddingClientManager(app_config.embedding)
if __name__ == "__main__":
embedding_client_manager.init()
client = embedding_client_manager.client
text = "What is deep learning?"
query_result = client.embed_query(text)
print(f"query_result = {len(query_result)}")将对应的文字转为向量。
Mysql客户端
Mysql客户端使用SQLAlchemy,
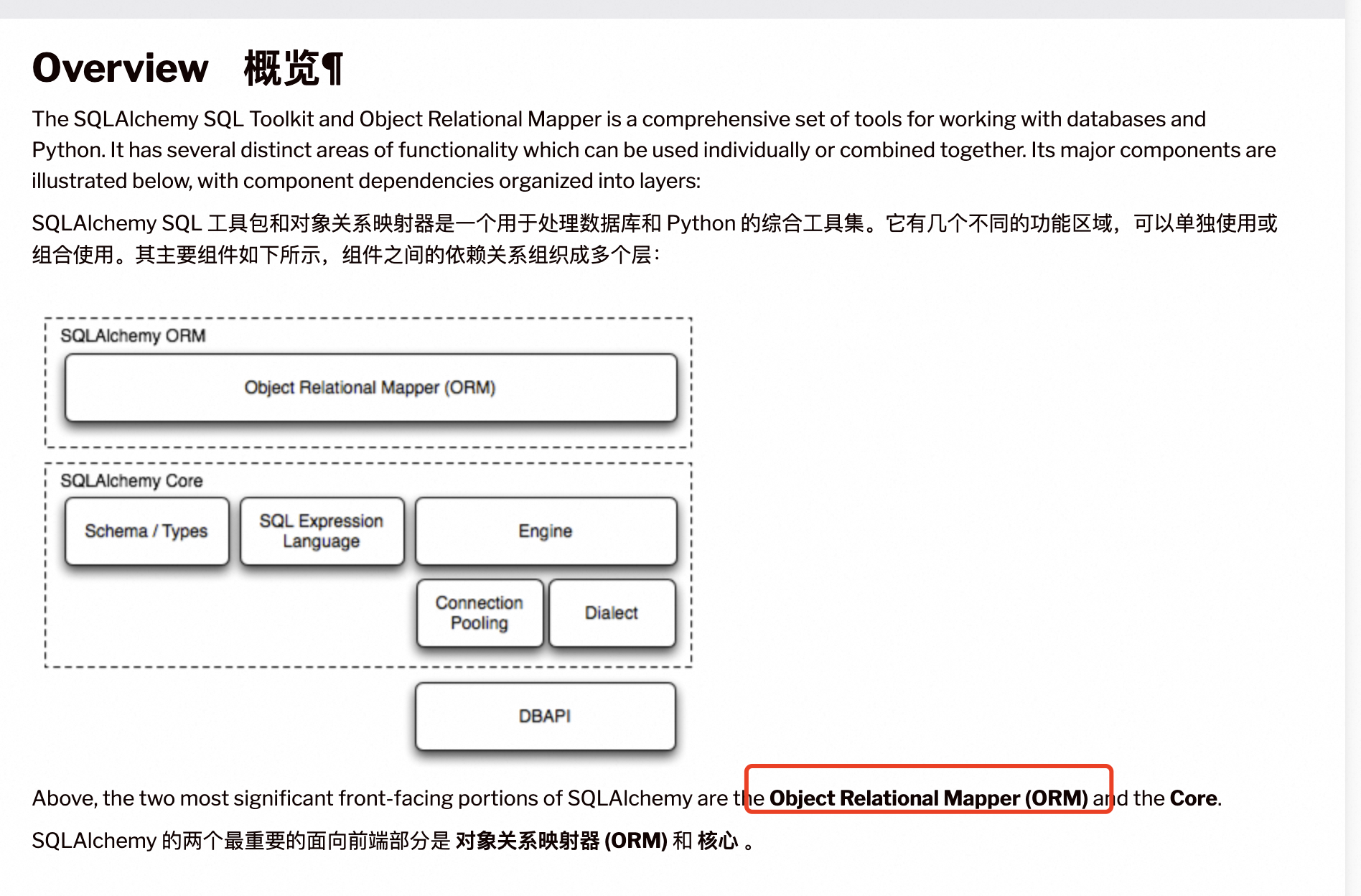
SQLAlchemy核心两个:ORM,对象跟表的映射。Core主要关键Engine,Engine就是用来操作数据库的,其中,Engine会维护数据库的连接池。
用法:
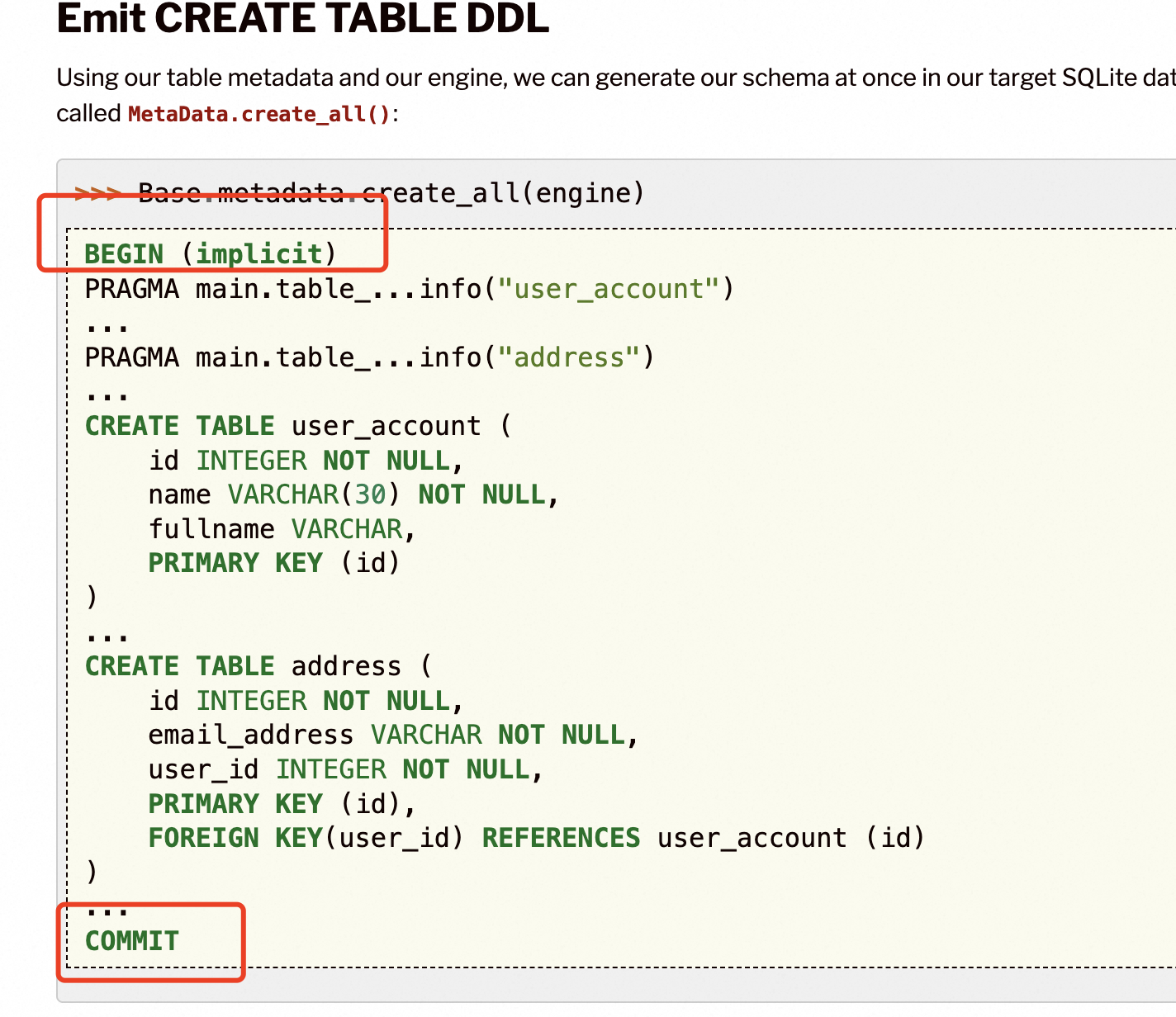
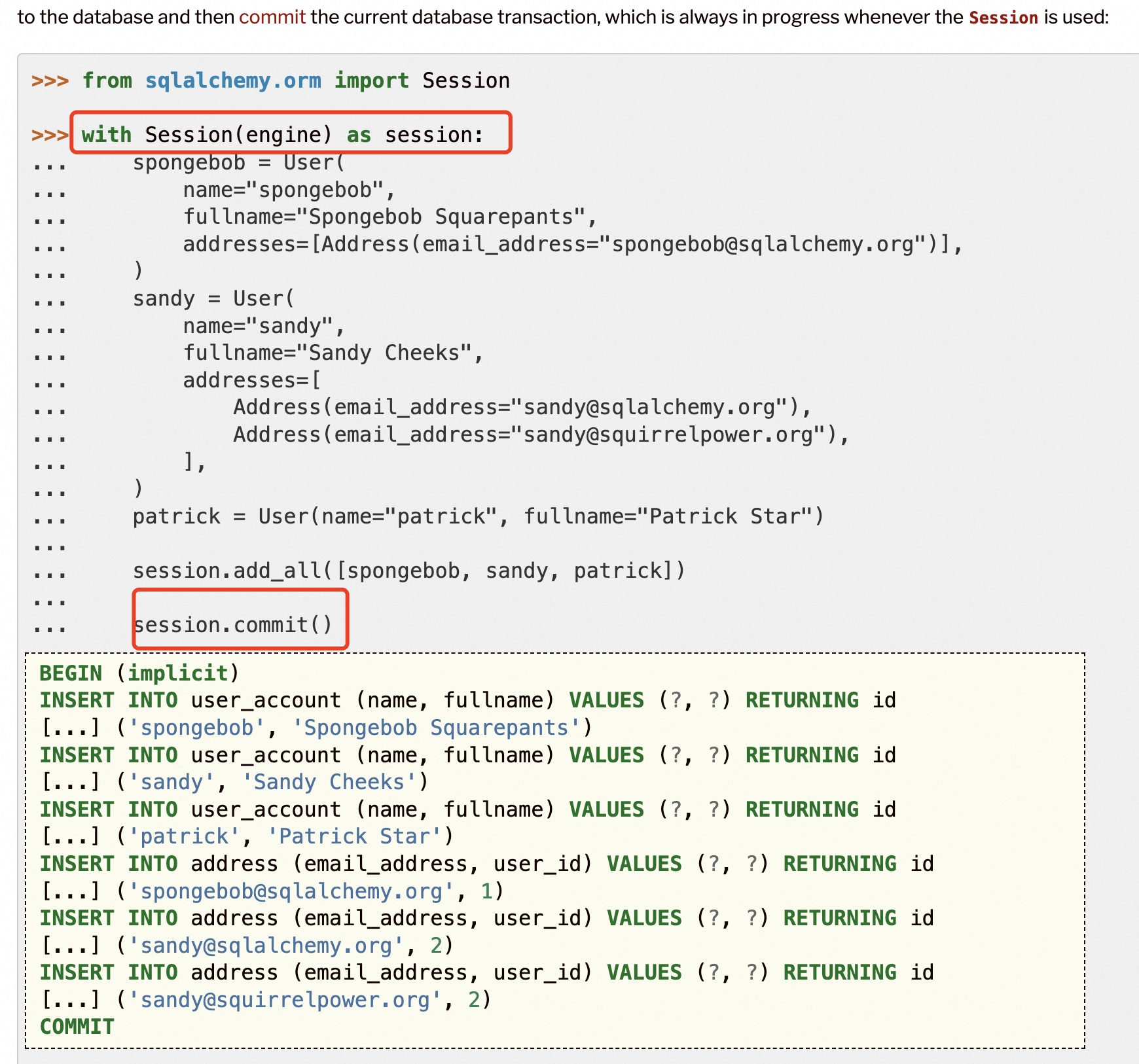
上述代码将执行如下sql,这里session.add_all后,不会真正执行sql,只有调用commit之后才会执行sql。
还是建立客户端代码
python
import asyncio
from typing import Optional
from sqlalchemy import text
from sqlalchemy.ext.asyncio import AsyncEngine, async_sessionmaker, create_async_engine
from app.conf.app_config import DBConfig, app_config
class MysqlClientManager:
def __init__(self, db_config: DBConfig):
self.db_config = db_config
self.engine: Optional[AsyncEngine] = None
self.session_factory = None
def _get_url(self):
return f"mysql+asyncmy://{self.db_config.user}:{self.db_config.password}@{self.db_config.host}:{self.db_config.port}/{self.db_config.database}?charset=utf8mb4"
def init(self):
self.engine = create_async_engine(url=self._get_url(),
# 连接池数量
pool_size=10,
# 从连接池拿到一个连接之后,需要先ping一下保证能通
pool_pre_ping=True)
# session对象,sqlalchemy用来真正对sql进行处理的对象,async_sessionmaker返回可执行的session对象
self.session_factory = async_sessionmaker(self.engine,
# 所有查询操作之前会flush,session写入的时候,并不会马上
# 写入数据库,这时候使用get肯定是拿不到的,所以需要调用flush一下,提交数据
autoflush=True,
# 默认为True,每次commit之后所有实例都会过期
# 在事务完成后进行所有属性/对象访问都将从最新的数据库状态加载。
# 异步不支持expire_on_commit
expire_on_commit=False,
#
autobegin=True)
async def close(self):
await self.engine.dispose()
# 单一实例
dw_mysql_client_manager = MysqlClientManager(app_config.db_dw)
meta_mysql_client_manager = MysqlClientManager(app_config.db_meta)这里使用异步创建engine,而且engine得保持单例模式,而session,是SQLAlchemy用来操作数据库的会话,只有创建了session,才能操作对应的数据库,如上async_sessionmaker每次都会返回一个可执行对象,执行后返回一个新的session。
使用demo
python
if __name__ == '__main__':
meta_mysql_client_manager.init()
async def test():
async with meta_mysql_client_manager.session_factory() as session:
result = await session.execute(text("select * from table_info limit 10"))
rows = result.fetchall()
print(rows)
asyncio.run(test())如果不使用with写法,就需要
python
session = Session(engine) # 1. 手动创建会话
try:
spongebob = User(...)
# ... 中间是一堆业务逻辑
session.add_all([spongebob, sandy, patrick])
session.commit() # 2. 提交事务
except Exception as e:
session.rollback() # 3. 发生错误时回滚事务
raise e
finally:
session.close() # 4. 无论是否报错,最后必须手动关闭会话释放资源使用with写法,可以自动帮助我们close,而且报错的时候,会自动rollback。
日志模块
上述我们的配置文件中有一处
yaml
logging:
file:
enable: true
level: INFO
path: logs
rotation: "10 MB"
retention: "7 days"
console:
enable: true
level: INFO对应的logger模块
python
import sys
from pathlib import Path
from loguru import logger
from app.conf.app_config import app_config
log_format = (
"<green>{time:YYYY-MM-DD HH:mm:ss.SSS}</green> | "
"<level>{level: <8}</level> | "
"<cyan>{name}</cyan>:<cyan>{function}</cyan>:<cyan>{line}</cyan> - "
"<level>{message}</level>"
)
# 移动默认配置
logger.remove()
# 使用配置文件的配置
if app_config.logging.console.enable:
# 添加输出到控制台
logger.add(sink=sys.stdout, level=app_config.logging.console.level, format=log_format)
if app_config.logging.file.enable:
path = Path(app_config.logging.file.path)
path.mkdir(parents=True, exist_ok=True)# 创建文件夹
logger.add(
sink= path / "app.log",
level=app_config.logging.file.level,
format=log_format,
rotation=app_config.logging.file.rotation,
retention=app_config.logging.file.retention,
encoding="utf-8",
)
if __name__ == "__main__":
logger.info("测试")
logger.error("测试error")
logger.warning("测试warning")通过配置决定日志打印在哪里,还能设置过期时间,大小,超过大小会自动创建新的
测试:

app.log文件会有:
python
2026-04-15 09:46:31.429 | INFO | __main__:<module>:37 - 测试
2026-04-15 09:46:31.430 | ERROR | __main__:<module>:38 - 测试error
2026-04-15 09:46:31.430 | WARNING | __main__:<module>:39 - 测试warning