论文/报告:SoulX-FlashTalk Technical Report
项目:Soul-AILab / SoulX-FlashTalk
关键词:实时数字人、音频驱动视频生成、流式推理、chunk 级自回归、双向蒸馏、长视频稳定性、DiT
一、前言:这篇报告真正要解决的,不是"能生成视频",而是"能不能实时、稳定、连续地一直生成"
最近看了 Soul AI Lab 开源的 SoulX-FlashTalk 技术报告和项目代码,我觉得这不是一篇单纯"又一个 talking avatar 模型"的工作。它真正有价值的地方在于,它试图回答一个更难的问题:
大规模视频生成模型,能不能用于真实交互场景?
这里的"真实交互场景"不是生成一个 5 秒 demo,而是:
- 用户一说话,数字人要尽快开口回应
- 视频要持续生成,而不是只做一小段
- 生成时间长了以后,人物不能漂、不能崩、不能突然断掉
- 还要保证嘴型同步、动作自然、背景稳定
这也是为什么 SoulX-FlashTalk 在报告里反复强调三个指标:
- 0.87s start-up latency
- 32 FPS
- infinite / ultra-long streaming stability
如果只看这三个指标,很多人可能会把它理解成"更快的数字人模型"。但如果结合 Figure 1 和 Figure 2 去看,会发现它真正提出的是一套很明确的方法论:
在流式视频生成里,不应该简单把模型做成严格单向因果结构,而应该保留强块内双向建模能力,再通过 chunk 级自回归蒸馏,把模型训练成适合实时部署的生成系统。
这篇文章就围绕这个核心思想展开。
二、先看 Figure 1:SoulX-FlashTalk 到底在和谁做对比,它想表达什么?
Figure 1 是理解整篇报告的第一把钥匙。

图中对比的是 LiveAvatar 和 SoulX-FlashTalk 两种路线。报告给出的几个关键信息非常明确:
- SoulX-FlashTalk 启动延迟 0.87s
- LiveAvatar 启动延迟 2.89s
- SoulX-FlashTalk 32 FPS
- LiveAvatar 20 FPS
- SoulX-FlashTalk 训练收敛只需 1.2k steps
- LiveAvatar 需要 27.5k steps
- 图中还特别标出了:
- LiveAvatar:Causal Attention
- SoulX-FlashTalk:Bidirectional Attention
这说明作者不是简单在比"谁更快",而是在比两种不同的流式视频生成思路。
2.1 LiveAvatar 代表什么路线?
从图示和报告描述看,LiveAvatar 更接近一种 严格单向/因果式流式生成范式:
- 当前生成更强调只能看过去
- 结构上更接近 causal attention
- 推理逻辑与在线生成一致性较强
这种思路的优点是直观,问题也很明显:
- 块内时空交互受限
- 细节建模能力下降
- 动作更容易僵
- 长时连续性未必理想
- 训练和收敛效率不一定高
2.2 SoulX-FlashTalk 代表什么路线?
SoulX-FlashTalk 的核心观点可以概括为一句话:
流式推理不等于必须把模型结构彻底做成严格单向。
它选择的是另一条路:
- 块内保留双向注意力
- 块间通过历史运动帧做因果递推
- 再通过双向流式蒸馏,把模型训练成适合在线部署
所以 Figure 1 里的"Bidirectional Attention"不是一个装饰信息,而是作者在明确表达自己的立场:
他们不同意"为了流式推理,就必须牺牲块内双向建模能力"的做法。
这也是后面 Figure 2 中"Self-Correcting Bidirectional Distillation"的理论基础。
三、Figure 2 才是核心:两阶段训练到底在做什么?
如果说 Figure 1 告诉我们"作者主张什么",那 Figure 2 讲的就是"作者具体怎么做"。
Figure 2 把整个方法拆成两个阶段:
- Stage 1: Latency-Aware Spatiotemporal Adaptation
- Stage 2: Self-Correcting Bidirectional Distillation
这两个阶段分别解决两个不同层面的问题。
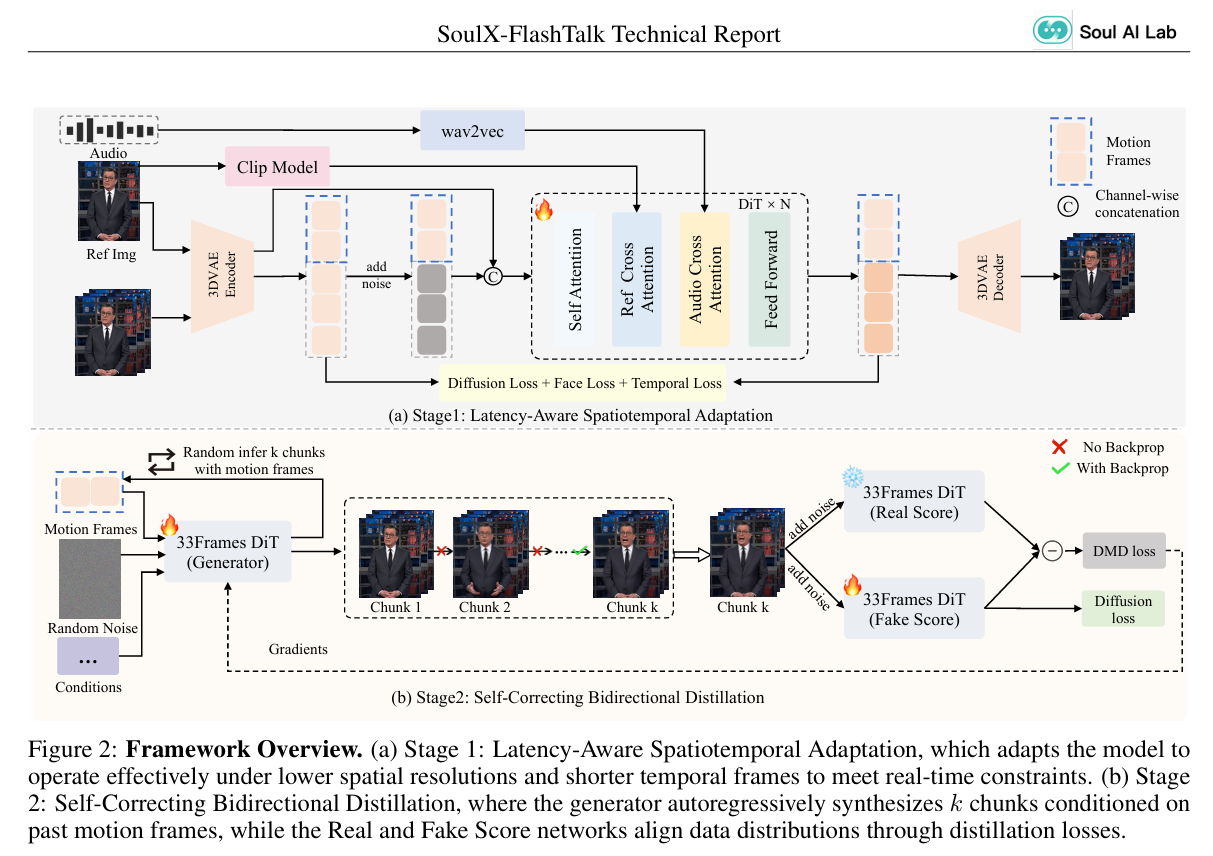
3.1 Stage 1:Latency-Aware Spatiotemporal Adaptation
这个阶段的目标并不是直接解决长视频稳定性,而是先解决一个更现实的问题:
14B 的视频生成模型太重了,原始高质量模型并不适合实时场景。
报告里明确提到,SoulX-FlashTalk 的架构来源于:
- WAN2.1-I2V-14B
- InfiniteTalk
也就是说,它不是从零设计一个轻量模型,而是站在一个高质量大模型基础上继续做实时化改造。
问题在于,大模型原本适合的是:
- 更高分辨率
- 更长帧数
- 更离线的生成流程
但实时场景要求的是:
- 更低启动延迟
- 更短时间窗口
- 更快单步推理
- 更稳定的流式输出
因此,作者先做了一个专门的适配阶段,把模型拉到"低时延、短时序、较低空间分辨率"的工作点上。
Figure 2(a) 可以看出这个阶段的基本结构:
- 音频经过
wav2vec - 参考图像经过
CLIP和3D VAE Encoder - 历史 motion frames 编码后进入 latent 空间
- 当前目标 latent 加噪
- 与参考条件做 channel-wise concatenation
- 送入
DiT × N - 最后通过
3D VAE Decoder解码
loss 由三部分组成:
- Diffusion Loss
- Face Loss
- Temporal Loss
这说明第一阶段不是简单"压缩模型",而是在做有针对性的时空适配,让模型在实时约束下仍能维持:
- 人脸一致性
- 时序连续性
- 基本视觉质量
3.2 Stage 2:Self-Correcting Bidirectional Distillation
第二阶段才是 SoulX-FlashTalk 最核心的创新。
Figure 2(b) 的图示信息量很大,里面至少有四个关键点:
(1)生成器按 chunk 自回归生成
图中写得很明确:
the generator autoregressively synthesizes k chunks conditioned on past motion frames
这句话非常重要,因为它直接回答了一个常见误区:
SoulX-FlashTalk 虽然保留了双向注意力,但它在 chunk 之间仍然是因果递推的。
也就是说,它不是整段视频一次性离线生成,而是:
- 一次生成一个 chunk
- 当前 chunk 条件化于过去的 motion frames
- 按 chunk 逐段向前滚动
这就是典型的 chunk-level autoregression。
(2)历史 motion frames 是块间连续性的关键
图中左侧明确给出了:
Motion FramesRandom NoiseConditions
说明当前 chunk 的生成不是只看音频和参考图像,而是还要看过去 chunk 的动态状态。
这也对应了一个重要的却容易让人忽视的问题:
为什么固定生成一个 chunk,还要额外给前面 5 帧?
答案就是:
因为当前 chunk 不只是要"生成出来",还要"接得上前一个 chunk"。
这几个历史帧的作用主要不是身份建模,而是:
- 提供姿态延续
- 提供嘴部运动惯性
- 提供头部/身体动作趋势
- 保证 chunk 之间不断裂
(3)Real Score / Fake Score 不是普通蒸馏,而是在做分布对齐
图中右边有三个 33Frames DiT:
GeneratorReal ScoreFake Score
并通过:
- DMD loss
- Diffusion loss
来训练。
这说明作者并不是简单地拿一个 teacher 输出去做 L2 拟合,而是在做一种更接近 distribution matching distillation 的训练。
它的意义在于:
- 学生不仅要"像教师"
- 还要在自己真实 rollout 的历史条件下,学会生成合理分布的当前 chunk
这也是为什么报告把它叫做:
Self-Correcting Bidirectional Distillation
而不是普通 distillation。
(4)随机 rollout k 个 chunk,是为了提升长时鲁棒性
Figure 2 里有一句:
Random infer k chunks with motion frames
结合报告中的 Table 2,可以看到作者专门做了消融:
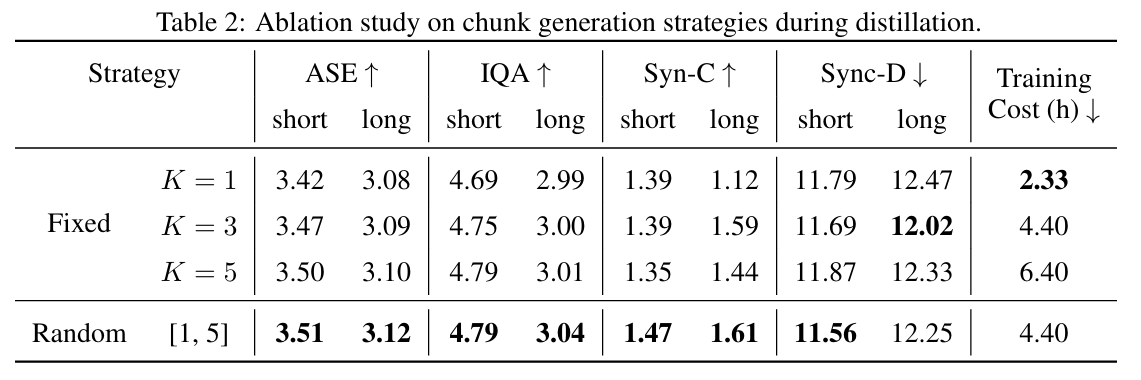
- 固定 K=1K=1
- 固定 K=3K=3
- 固定 K=5K=5
- 随机 K∈1,5K∈1,5
结果最优的是:
Random 1,5
报告原文解释也很直接:
exposing the model to varying autoregressive lengths during distillation effectively improves robustness against accumulated errors
也就是说:
训练时让模型经历不同长度的自回归 rollout,可以显著增强它抵抗误差累积的能力。
这一点对于长视频生成非常关键,因为真正的难点从来不是"第一个 chunk 生成得好不好",而是:
第 50 个、第 100 个 chunk 还能不能接着稳。
四、为什么说 SoulX-FlashTalk 的关键不是"更快",而是"块内双向 + 块间因果"的解耦?
这是我认为这篇报告最值得写出来的一点。
很多流式生成方法会把"在线推理"直接等同于:
- 训练也严格因果
- 注意力也严格因果
- 当前只能看过去,不能看未来
这个思路在语言模型里非常自然,但在视频生成里未必最优。
因为视频 chunk 内部存在非常强的:
- 空间耦合
- 时序耦合
- 局部纹理一致性
- 动作连续性
如果把整个时空建模都粗暴改成严格单向,代价通常是:
- 块内建模能力下降
- 细节变差
- 动作更硬
- 训练更慢
- 收敛更差
SoulX-FlashTalk 的做法其实是在做一个重要解耦:
4.1 块内:保留双向建模
当前 chunk 内部的若干帧,允许更充分的双向交互。
这样有利于:
- 纹理细节
- 姿态自然度
- 局部时空一致性
- 人物结构完整性
这也是报告里 Figure 3 强调的点:
相比 Ditto、StableAvatar、InfiniteTalk、LiveAvatar,SoulX-FlashTalk 在手部结构、背景一致性、身份保真上更稳。
4.2 块间:坚持因果递推
虽然块内保留双向建模,但当前 chunk 的生成仍然只依赖:
- 参考图像
- 当前音频条件
- 历史 motion frames
- 过去已经生成的 chunk 状态
而不依赖未来 chunk 的真实视频。
所以它在 块间 依然是严格因果的。
这就是一个非常重要的认识:
流式视频生成不一定要"处处因果",但必须在块间递推关系上满足因果。
五、回到几个最容易混淆的问题:帧、chunk、历史 5 帧、固定视频段到底怎么理解?
这是很多人看这类论文最容易糊涂的地方。
5.1 帧、chunk、固定视频段的关系
- 帧(frame):视频最小单位,就是一张图
- chunk:若干连续帧组成的一段小视频
- 固定视频段:本质上就是一个固定长度的 chunk
在 SoulX-FlashTalk 的训练图里,核心生成单元是 33Frames DiT,所以可以理解为:
模型一次主要生成一个 33 帧左右的小视频段。
5.2 为什么还要给前一个 chunk 的最后几帧?
因为当前 chunk 不是从零开始生成,而是要"接着前面生成"。
所以历史帧的作用不是"重复提供身份",而是提供:
- 动作起点
- 姿态惯性
- 表情延续
- 嘴型过渡
- 块间连续性
换句话说:
- 参考图像 负责"我是谁"
- 历史运动帧 负责"我刚才怎么动"
- 当前音频 负责"我现在该怎么说"
5.3 历史 5 帧是输入吗?
是,而且是非常关键的输入条件。
但它不是最终要重建的目标,而是 motion context。
5.4 历史帧加噪以后,为什么仍然算自回归?
因为自回归看的不是"输入是不是干净像素",而是:
当前输出是否依赖过去输出/过去状态。
即使历史 5 帧在 latent 空间里被加噪,它仍然表示过去时刻的状态,并参与当前 chunk 的生成条件,因此本质上仍然是自回归。
只是这个自回归不是逐帧的,而是:
chunk 级自回归
即:
p(ct∣c<t,at,I)p(ct∣c<t,at,I)
其中:
- ctct:当前 chunk
- c<tc<t:过去 chunk 的状态
- atat:当前音频条件
- II:参考图像
六、"双向蒸馏"到底双向在哪里?是不是推理时能看未来?
这个问题非常值得单独讲,因为很多人第一次看到"bidirectional distillation"会直接误解。
答案先说在前面:
不是。双向蒸馏不代表推理时能看未来。
报告里有一句非常关键的话:
we diverge from the strictly unidirectional paradigm by adopting a bidirectional-teacher to bidirectional-student strategy
这句话的意思是:
作者没有采用"单向教师教单向学生"的严格因果范式,而是采用"双向教师 → 双向学生"的蒸馏策略。
所以"双向"主要体现在:
- 教师模型保留双向建模能力
- 学生模型也保留双向建模能力
- 蒸馏传递的是这种更强的块内时空表示能力
而不是说:
- 推理时当前 chunk 可以访问未来 chunk 的真实视频
推理阶段仍然是 chunk-by-chunk 往前走的,未来视频并不可见。
所以更准确的理解是:
双向是块内建模方式,因果是块间生成约束。
七、为什么不直接把学生做成因果注意力模型?这不更符合推理吗?
这个问题其实是 SoulX-FlashTalk 想回答的核心争议点。
直觉上看,既然推理时只能看过去,那训练时也把模型做成因果注意力,不是最自然吗?
表面上是这样,但视频生成和语言生成不完全一样。
7.1 严格因果结构的问题
如果整个模型都做成严格 causal attention,常见代价是:
- 块内时空交互不足
- 细节纹理下降
- 动作更僵
- 长时视觉一致性不一定更好
- 收敛速度变慢
Figure 1 里给出的对比已经说明,SoulX-FlashTalk 在:
- 启动延迟
- FPS
- 收敛速度
- 连续性
上都优于 LiveAvatar 这类更严格因果路线。
7.2 SoulX-FlashTalk 的选择:行为上因果,而不是结构上全因果
这是一个非常值得记住的表述:
它不是把整个网络硬改成严格因果,而是通过训练任务设计,让模型学会因果流式行为。
也就是说:
- 模型内部保留强双向块内建模
- 训练时只给历史 motion frames 和当前条件
- 让学生在这种真实流式上下文中生成当前 chunk
- 再用双向教师进行蒸馏
所以它更像是在做:
流式行为蒸馏
而不是:
结构硬约束式因果训练
八、为什么 Predicted Latents + Noise 反而比 GT Latents 更好?
报告中的消融非常有意思。
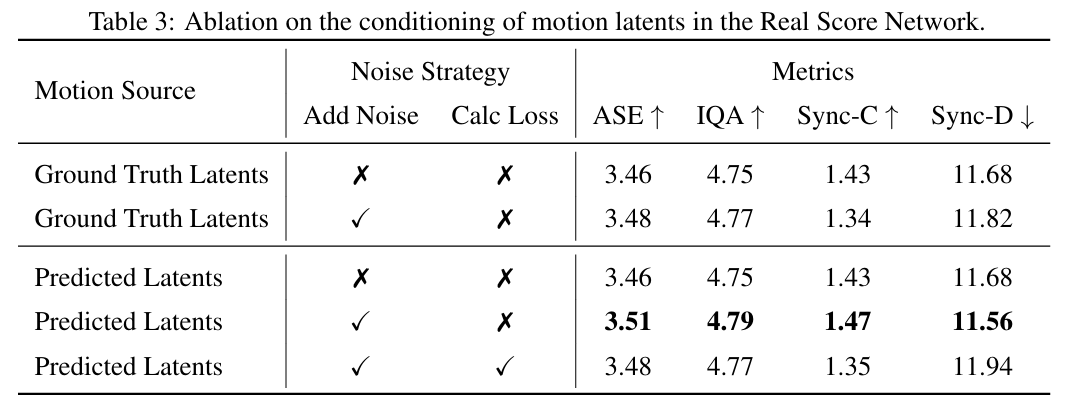
作者发现:
- 使用 student-predicted motion latents
- 并且 注入噪声
反而比直接使用 GT latents 视觉质量更好。
这个结果其实非常合理。
8.1 因为真实推理时,历史不是 GT
在线生成时,当前 chunk 看到的历史上下文,不可能是 ground truth,只能是:
- 模型自己刚刚生成出来的结果
- 带误差
- 带噪声
- 可能有轻微漂移
如果训练时总给 GT 历史,学生就会学到一个不真实的分布。
8.2 加噪让训练分布更接近真实 rollout
对 predicted motion latents 加噪,本质上是在模拟:
- 历史条件不完美
- 误差会累积
- 当前 chunk 要在这种条件下继续稳定生成
所以这种训练更鲁棒,也更符合流式部署场景。
这也是为什么 SoulX-FlashTalk 在长视频 benchmark 上能明显优于很多 baseline。
九、Figure 3 和 Figure 4 说明了什么?为什么不仅是"嘴型同步",而是"整体结构稳定"?
报告里除了速度和流程图,还给了两个非常重要的定性结果:
- Figure 3:5 秒视频质量对比
- Figure 4:10s 到 1000s 的长时稳定性对比
这两个结果说明 SoulX-FlashTalk 的提升不是单点的。
9.1 Figure 3:短时质量

报告指出:
- Ditto 的手部动作基本静止
- Echomimic-v3 和 StableAvatar 在手部区域有结构畸变
- InfiniteTalk 存在过曝和运动模糊
- SoulX-FlashTalk 能保持更清晰的手部结构和背景一致性
这说明它提升的不只是嘴型同步,而是:
- 结构完整性
- 动作合理性
- 细节保真
- 背景稳定
9.2 Figure 4:长时稳定

Figure 4 更关键,因为它展示了从:
- 10s
- 100s
- 500s
- 1000s
的连续生成对比。
报告结论很明确:
- 许多 baseline 会在长时间生成后出现明显模糊、漂移、细节丢失
- SoulX-FlashTalk 由于双向流式蒸馏和自纠正机制,能显著缓解误差传播
这说明它真正解决的是:
长时流式生成中的误差累积问题
而这恰恰是在线数字人系统最难的部分。
十、这篇工作最大的思想价值:把"流式推理"从结构问题,变成训练范式问题
这是我读完之后最强烈的感受。
很多方法把流式生成理解成一个"结构设计问题":
- 既然要在线,就用 causal attention
- 既然不能看未来,就把 mask 加死
- 既然要快,就减少上下文
SoulX-FlashTalk 给出的答案更成熟:
流式生成不只是结构约束问题,更是训练分布和蒸馏范式问题。
它真正做的是三件事:
10.1 保留强生成能力
不轻易牺牲块内双向时空建模。
10.2 让训练更贴近真实推理
通过历史 motion frames、随机 rollout 长度、predicted latent + noise,让学生面对真实流式上下文。
10.3 用蒸馏把高质量能力迁移给在线生成器
不是让学生在弱监督下自己摸索,而是用双向教师给出更高质量的分布目标。
所以这篇工作最值得借鉴的,不只是结果,而是它的思路:
不要为了流式部署而过早牺牲模型表达能力,而应该通过更合理的训练设计,把强模型蒸馏成可流式运行的模型。
十一、最后总结:SoulX-FlashTalk 的核心思想到底是什么?
如果只用一句话总结,我会写成:
SoulX-FlashTalk 的本质,不是简单把 talking avatar 做得更快,而是提出了一种"块内双向、块间因果、通过自纠正双向蒸馏实现流式部署"的视频生成范式。
再展开一点,就是四句话:
- 先做低延迟时空适配,让 14B 大模型进入实时工作区间
- 再做自纠正双向蒸馏,把高质量双向建模能力迁移给流式生成器
- 通过历史 motion frames 做 chunk 级自回归递推,保证块间连续性
- 通过随机 rollout 和带噪 predicted latent 训练,提升长时稳定性和抗误差累积能力
所以它真正先进的地方,不只是:
- 0.87s
- 32 FPS
- 1.2k steps
而是它背后的方法论:
在实时视频生成里,最优解未必是"全因果结构",而可能是"强双向建模 + 因果流式蒸馏"的组合。
十二、附:适合放在文末的"个人理解"
最后补一句我自己的理解。
SoulX-FlashTalk 这篇报告最有启发性的地方,在于它把一个很容易被简单化的问题重新讲清楚了:
- 推理是因果的
- 但模型不一定要处处严格因果
- 真正关键的是:训练时如何让模型学会在真实历史条件下稳定续写
这也是为什么它不是单纯"更大的数字人模型",而更像是:
一篇关于流式生成系统该如何训练的技术报告。
参考信息
- SoulX-FlashTalk Technical Report:arxiv.org/pdf/2512.23379
- Soul-AILab / SoulX-FlashTalk GitHub 项目页:GitHub - Soul-AILab/SoulX-FlashTalk: SoulX-FlashTalk is the first 14B model to achieve sub-second start-up latency (0.87s) while maintaining a real-time throughput of 32 FPS on an 8xH800 node. · GitHub
- 报告中 Figure 1、Figure 2、Figure 3、Figure 4、Table 2 的公开描述与指标