我们这次将输入从之前的状态向量改为图像输入。这一节。你需要学会如何构建一个DDQN智能体类,包括如何构建模型。
KerasRL2由于版本冲突和维护,问题非常非常多,极其不建议实践本项目。建议移步复现【强化学习实战1-8】(不带负号)
因此首先就把Cube对象类的RETURN_IMAGE改了吧~

【课程17:编写自己的Double-DQN程序】 https://www.bilibili.com/video/BV1uF411i76R/?share_source=copy_web\&vd_source=2c56c6a2645587b49d62e5b12b253dca
DQN理论简介
之前我们的训练对象是一个q_table,其记录了当前状态下各个动作的预计Q值,但其有一大缺陷,就是对离散动作空间有效,但是在连续控制领域就完犊子了,而这次我们用一个神经网络来代替q_table,这样就可以在没有记录Q的连续区间进行控制了!
总而言之,DQN是用神经网络代替了q_table
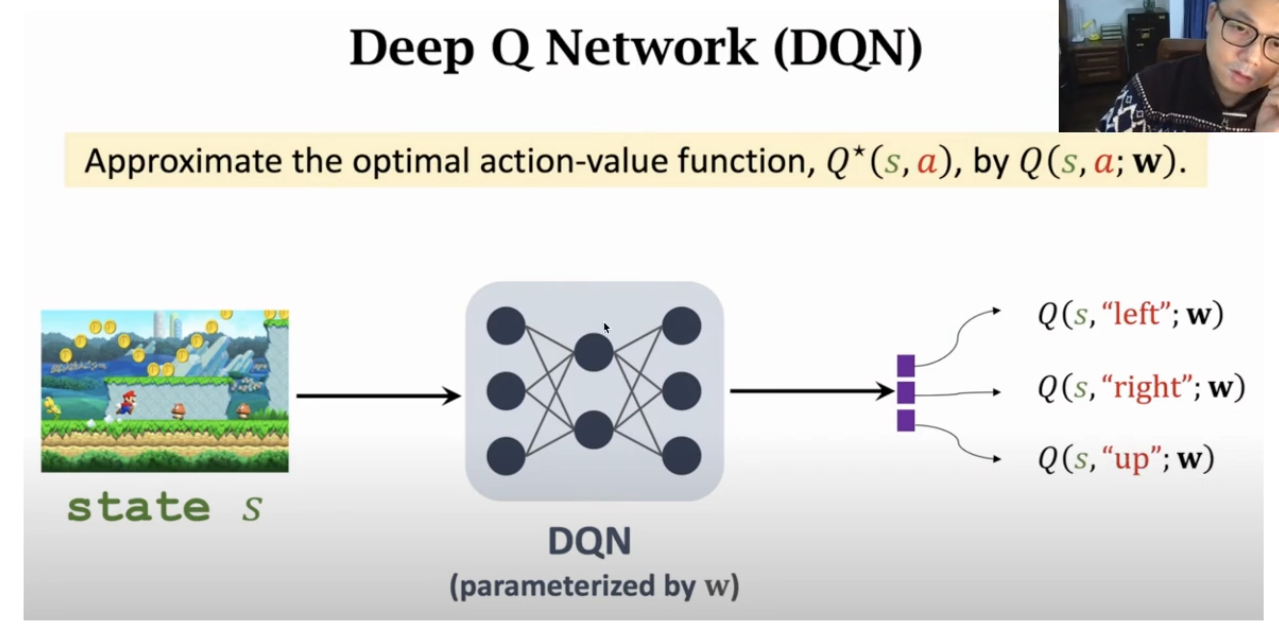
我们输入一个状态(图片或状态向量),经过神经网络计算,输出一个动作概率分布。
具体流程:

在整个过程中,神经网络的作用就是预测Q,核心是如何去拟合连续的Q。
首先Agent观察环境获取st,然后随机选择一个动作at。
然后环境会反馈一个新状态st+1,以及奖励rt。
接下来,就可以计算TD目标,也就是当前这一步预计的奖励(更接近真实值,尽管maxQ(st+1,a;w)仍然也是预计值,但是这一步以及之前的收益已经是真实的了)
然后计算TD误差,也就是【在执行这一步前,神经网络估计的Q值】 与 【当前执行完这一步,获得的实际奖励与下一步预计的奖励】 的差值。
显然,我们希望 【执行这一步前的预计的Q值】能更接近【执行完这一步预计的Q值】,因此我们的目标就是最小化TD error。
最小化TD error的方法就是梯度下降了,首先构造误差函数,为了消除非负性,我们用δt的平方刻画误差,又因为梯度下降需要求导,因此再除以二,这样求导完正好没有系数了。
这样,我们就得到了L(w),因此把每一步加和求均值。后面的内容就是正常的随机梯度下降了。

经验回放
然后介绍一下DQN的杀手锏,经验回放,这个在我们第一节也讲过
经营回放就像你现在回去看我们第一节的内容,把过去的经验(状态、动作、奖励、新状态)都存在一个"记忆池"里,训练时随机抽取一批来学习。这打破了数据之间的相关性,让学习更稳定。

那么在加入经验回放后的DQN的过程又是怎么样的呢?

在整个过程中,神经网络的作用就是预测Q,核心是如何去拟合连续的Q。
首先Agent观察环境获取st,然后随机选择一个动作at。
然后环境会反馈一个新状态st+1,以及奖励rt。
接下来,我们不直接计算TD目标,而是把当前的transition(st,at,rt,st+1)存进上图的replay buffer中。
每次更新网络的时候,执行
- 采样:从 Replay Buffer 里随机抽取了一个小批量(mini-batch)的数据。比如,你抽出了 32 条过去的经验。
- 遍历 :你会对这 32 条数据中的每一条都进行一次 TD Target 的计算。计算TD目标,也就是当前这一步预计的奖励(更接近真实值,尽管maxQ(st+1,a;w)仍然也是预计值,但是这一步以及之前的收益已经是真实的了)
- 计算 :假设你正在处理采样出来的其中一条数据,我们叫它
(s_old, a_old, r_old, s_next_old)。那么,为这条数据计算的 TD Target 就是:
yt_old = r_old + γ * max Q(s_next_old, a; w)
所以,你最终会得到 32 个不同的 yt 值,每一个都对应着采样出来的那 32 条旧数据中的一条。
然后计算这32条数据的TD误差,也就是这32条数据的【在执行这一步前,神经网络估计的Q值】 与 【执行完这一步,获得的实际奖励与下一步预计的奖励】 的差值。
显然,我们希望 【这一步前的预计的Q值】能更接近【执行完这一步预计的Q值】,因此我们的目标就是最小化TD error。
最小化TD error的方法就是梯度下降了,首先构造误差函数,为了消除非负性,我们用δt的平方刻画误差,又因为梯度下降需要求导,因此再除以二,这样求导完正好没有系数了。
这样,我们就得到了L(w),而我们希望每一步的Q都能接近执行完这一步预计的Q,因此把每一步加和求均值。后面的内容就是正常的随机梯度下降了。
自举问题与解决



如果听不懂,看一下这张图就理解了:
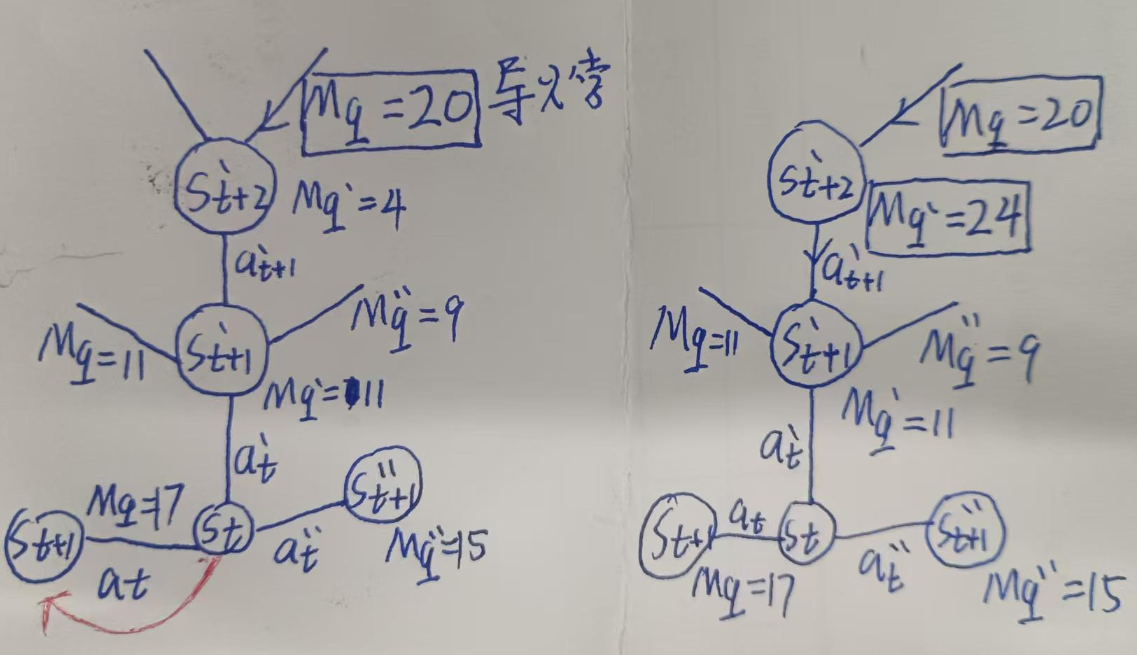
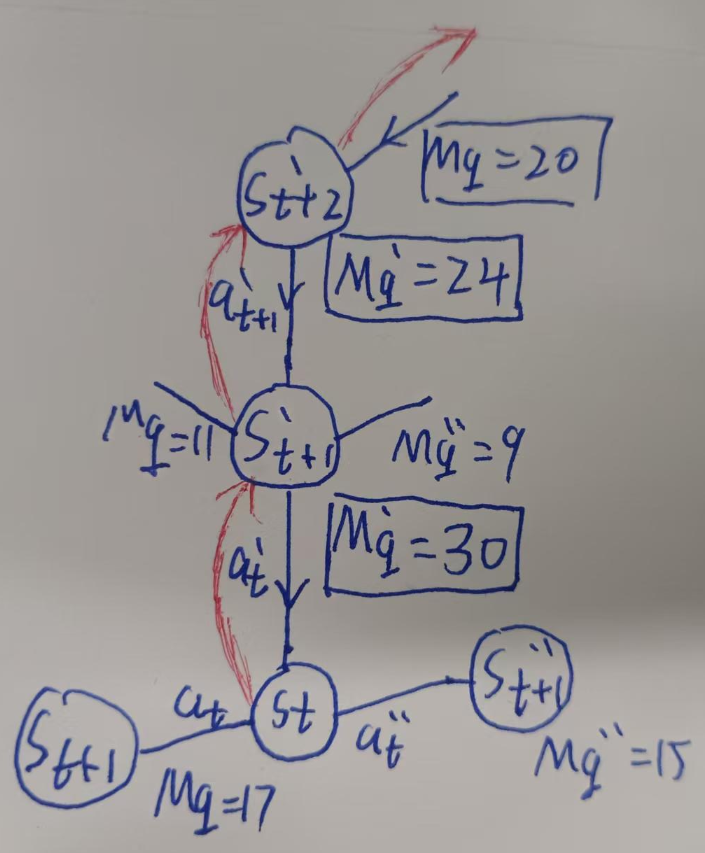
原先st状态会选择Mq最大的St+1,但是由于上面St+2'预测误差过大的Mq=20的更新,产生了放大,接着受其影响的是St+1',Mq'被更新为24,再往前传,St的Mq'被跟新到惊人的30,那么下一次训练,到St,Agent很大概率会选择at'动作,而不是原先的at了!(因为还是基于ε-greedy策略或玻尔兹曼策略,有一定概率选择其他动作)
如何解决自举?
Q的过高预测是由于策略网络自己估计maxQ(s',a'),还自己拟合Q(s,a),
如果我们能给他找个老师,给他目标值maxQ(s',a'),策略网络只负责拟合,不负责估计就可以了!
因此DQN引入了双网络。
- 目标网络( θtarget ) :负责选出那个"Q最大值"。虽然它选出的动作可能也是错的(包含噪声),但是 ,这个噪声是固定的。
- 策略网络( θ ):负责去拟合这个目标。
计算目标值时,用的是目标网络冻结的 Qtarget ,而不是那个时刻在变的 Q。
-
训练时 (每一步):
- 策略网络接收梯度,参数发生变化(学生学到了新知识)。
- 目标网络纹丝不动(老师保持旧的知识,确保教学目标稳定)。
- 此时:策略网络参数 != 目标网络参数
-
更新时 (每隔 N 步):
- 触发
target_update_interval。 - 动作 :再次把策略网络最新的权重硬拷贝给目标网络。
- 此时:策略网络参数 == 目标网络参数(同步了)
- 触发
但是,实际上这并不能解决估计过高的问题,只能减缓这个过程。
代码编写
第一步就是编写一个DQNAgent类,构建整个DQN架构,由于我们状态输入的是一张图片,因此需要先经过卷积层Convolution、dense等。
python
class DQNAgent():
def __init__(self):
pass
def create_model(self):
pass创建模型就需要引入这些库,要在前面import一下。
python
env=envCube()
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Conv2D,Flatten
from tensorflow.keras.optimizers import Adam, SGD
from tensorflow.keras.losses import CategoricalCrossentropy1. Sequential:模型的"流水线框架"
- 作用 :导入模型容器。
- 它是什么 :
Sequential是 Keras 提供的一种最简单的模型组织方式(API)。它就像一个**"空盒子"** 或者**"流水线"**。 - 为什么要用它 :它的作用是管理层的顺序。它告诉 TensorFlow:"我要建立一个网络,数据从第一层进去,依次经过第二层、第三层,最后输出。"
2. Dense Conv2D Flatten:模型的"具体架构"
- 作用 :导入具体的网络层(组件)。
- 它们是什么 :这些是神经网络中真正干活的数学模块 。
Dense:全连接层。负责综合所有信息,通常用于网络末端进行分类判断。Conv2D:二维卷积层。专门用于处理图像(网格数据),负责提取图像的特征(如边缘、纹理)。Flatten:展平层 。负责把二维的图像数据(如 28x28)拉成一维的长条(784),以便传给Dense层。
- 为什么要用它:光有架子(Sequential)是没法计算数据的,你必须往架子里放入具体的层来处理数据。
3. Adam SGD:模型的"优化器"
- 作用 :导入模型的"引擎"或"执行策略"。
- 它是什么:优化器(Optimizer)是驱动模型参数更新的算法。你可以把它想象成模型训练时的"引擎"或"下山策略"。
- 为什么要用它:模型在训练初期,其内部参数(权重)是随机的,预测结果很差。优化器的作用就是根据损失函数提供的"错误信息",计算出应该如何调整这些参数,让模型的预测越来越准。它决定了参数更新的"步长"和"方向"。
- 常见类型 :
SGD(随机梯度下降):最基础的优化器。它就像蒙着眼睛下山,每一步都沿着脚下最陡的坡度走。简单,但可能走得慢或迷路。Adam:目前最常用、最强大的优化器之一。它不仅知道坡度,还带有"动量"(像滚下山的球,越走越顺)和自适应学习率(能根据路况自动调整步长),因此收敛更快、更稳定。
3. CategoricalCrossentropy:模型的"优化器"
- 作用 :导入模型的"评分标准"。
- 它是什么:损失函数(Loss Function)是用来衡量模型预测结果与真实答案之间差距的函数。
- 为什么要用它:在训练过程中,模型需要一个明确的信号来告诉它"这次预测有多差"。模型训练的唯一目标,就是让这个损失值不断变小。
- 常见类型 :
CategoricalCrossentropy(分类交叉熵) :专门用于多分类任务(如识别猫、狗、鸟)。它会严厉惩罚那些"非常自信但又预测错了"的情况,迫使模型快速学习正确的分类边界。MeanSquaredError(均方误差) :专门用于回归任务(如预测房价、温度)。它计算预测值与真实值差的平方的平均值,对大的误差非常敏感,会促使模型尽力避免大的偏差。
通常在定义好模型后,我们会在 compile 阶段使用它:
python
# 1. 导入模型容器、网络层、优化器、损失函数
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Conv2D,Flatten
from tensorflow.keras.optimizers import Adam, SGD
from tensorflow.keras.losses import CategoricalCrossentropy
# 2. 定义模型
model = Sequential([
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
# 3. 编译模型(使用优化器)
# 注意这里直接使用了类名 Adam
model.compile(optimizer=Adam(learning_rate=0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])DQN模型创建
参考这个架构,我们编写出这样的模型构建函数:
python
def create_model(self):
model = Sequential()
# 1. 卷积层:提取图像特征
# 注意:input_shape 通常不需要加 batch_size,直接写 (高, 宽, 通道)
model.add(Conv2D(32, (3,3), strides=(1,1), activation='relu', input_shape=env.OBSERVATION_SPACE_VALUES))
model.add(Conv2D(32, (3,3), strides=(1,1), activation='relu'))
# 2. 展平层:把多维图像数据拉成一维向量
model.add(Flatten())
# 3. 隐藏的全连接层:综合特征 (你漏写了 Dense)
model.add(Dense(32, activation='relu'))
# 4. 输出层:输出每个动作的 Q 值 (你漏写了 Dense)
model.add(Dense(env.ACTION_SPACE_VALUES, activation='linear'))
# 5. 编译模型
# 注意:optimizer 需要传入实例或类,不能只传字符串 'Adam'(除非用字符串 'adam' 小写)
model.compile(loss='mse', optimizer=Adam(), metrics=['accuracy'])
return model首先创建模型容器,这样才能把各层网络塞进去
python
model=Sequential()#创建序列容器Convolution卷积层设计
接着,一层层把模型塞进去
python
model.add(Conv2D(32,(3,3),(1,1),activation='relu',input_shape=env.OBSERVATION_SPACE_VALUES))由于我们输入的是10X10的图像,因此要用卷积层来接受。
卷积层参数
1. 32:卷积核的数量 (filters)
- 含义 :这表示这一层要用 32 个不同的卷积核去扫描输入图像。
- 作用:每一个卷积核都会提取一种特定的特征(比如有的负责提取横向线条,有的负责提取竖向线条,有的负责提取颜色变化)。
- 结果 :经过这一层处理后,你的数据会变成 32 层厚的特征图。你可以理解为模型现在用 32 种不同的"滤镜"在看这张图。
2. (3, 3):卷积核的大小 (kernel_size)
- 含义 :每个卷积核的长和宽都是 3 个像素。
- 作用:卷积核就像一个小窗口,每次只覆盖图像上的 3×3 个像素点,通过计算这 9 个像素的数值来提取局部特征。
3. (1, 1):步长 (strides)
- 含义 :卷积核在图像上滑动的步幅是横向 1 格、纵向 1 格。
- 作用 :
- 卷积核扫描完一行后,下一次移动的距离。
(1, 1)表示一步一步地扫,不会跳过任何像素。这是默认值,通常可以省略不写。
4. activation='relu':激活函数
- 含义 :使用 ReLU (线性整流单元) 函数。
- 作用 :给网络引入非线性 因素。
- 如果没有它,无论网络有多少层,本质上还只是一个简单的线性变换,无法处理复杂的图像(比如区分猫和狗)。
- ReLU 的规则很简单:如果是负数就变 0,是正数就保持不变。它能让模型学习到更复杂的模式,同时计算速度很快。
5. input_shape=...:输入形状
- 含义:告诉模型,喂给它的数据长什么样。
- 作用 :这通常只在第一层 需要写。它必须匹配你的环境(
env)输出的观察数据格式。- 通常格式为
(高度, 宽度, 通道数)。 - 例如:如果是灰度图且尺寸为 84x84,这里就是
(84, 84, 1);如果是彩色图,就是(84, 84, 3)。
- 通常格式为
python
model.add(Conv2D(32,(3,3),(1,1),activation='relu'))因此第二层就去掉input_shape参数即可。
Pooling池化层设计
一般在卷积层后需要加最大池化层,但由于DQN对图像的特征位置比较敏感,不建议增加池化层,因为池化会模糊特征。
池化是为了解决计算量大的问题的,在图像分类问题中,我们更在意"是什么"而不是"在哪里"的问题,因此具体的特征位置不那么重要,而是是否有这个特征更重要。为了减小计算量,会用视野中的最大值或平均值代替整个视野的特征值。
池化操作本质上是一种有损压缩。它通过丢弃一部分空间信息来换取计算效率和特征的鲁棒性。
- 最大池化:在一个小窗口(如2x2)内只保留最强的信号(最大值),而丢弃了其他所有信息。
- 结果:虽然最强的特征被保留了,但它具体在窗口内的哪个像素点,这个精确的位置信息就丢失了。
对于DQN来说,这种位置信息的丢失是不可接受的,因为它会直接影响Q值(动作价值)的预测准确性。
所以我们不加。
Flatten展平层
经过两层卷积后,数据是一个立方体(例如 10x10x32)。它保留了图像的空间结构(上下左右的关系)。
但全连接层只能接受一条数据,因此需要这一层把立方体压扁FLatten成一条线。
python
model.add(Flatten())Dense全连接层
全连接层(Dense)的输入 :只能是一维的长向量。
全连接层里的每一个神经元都需要连接上一层的所有数据。它没法直接处理"立体"的图像块。
第一层是隐藏层,综合卷积出来的空间信息,抽象出高级信息。
python
model.add(Dense(32, activation='relu'))这是网络在"看懂"图像特征后,进行逻辑思考的一层。它把 Flatten 传过来的成千上万个特征进行综合、压缩,提取出更高级的抽象信息,为最后的决策做准备。
Dense输出层
python
model.add(Dense(env.ACTION_SPACE_VALUES, activation='linear'))- 参数详解 :
Dense:表示这是一个全连接层。env.ACTION_SPACE_VALUES:这是输出神经元的数量。比如游戏里有"上、下、左、右"4个动作,这里就是 4。这 4 个神经元分别代表这 4 个动作的得分(Q值)。activation='linear':非常重要!- Q 值可以是任意实数(比如 -100, 0, 5.5, 1000)。
- 如果你用
relu,负数 Q 值会被变成 0(这就错了,因为有的动作可能是惩罚)。 - 如果你用
softmax,输出会被限制在 0-1 之间(这是概率,不是价值)。 - Linear(线性) 意味着"原样输出",不做任何截断或压缩
构建完成后别忘了compile一下,使用MSE作为损失函数,Adam作为优化器,ac作为评估器
python
model.compile(loss='mse', optimizer=Adam(), metrics=['accuracy'])我们应该意识到,DDQN是双网络的,一开始两个网络应该同参数,因此要在__init__()中传递一下:
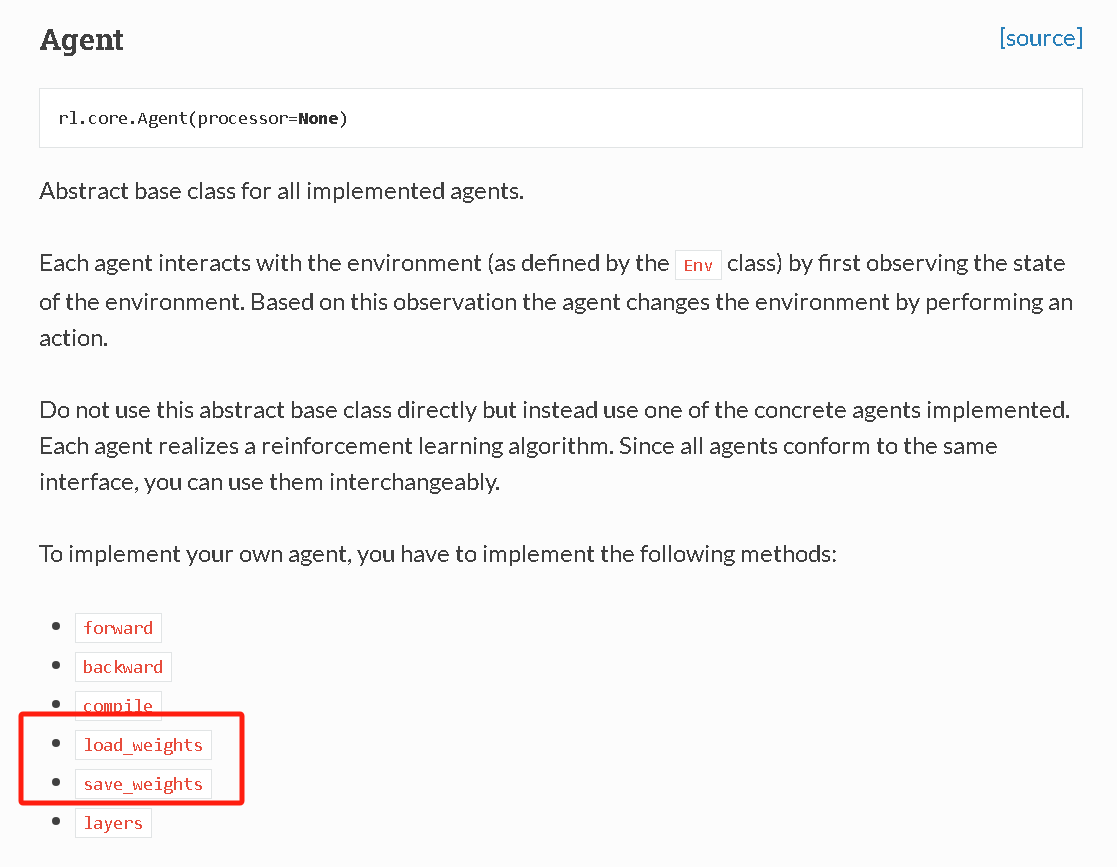
那么我们会用到赋权重和获取权重的函数,定义来自rl库https://keras-rl.readthedocs.io/en/latest/core/#agent
python
class DQNAgent():
def __init__(self):
self.model=self.create_model()
self.target_model=create_model()
self.target_model.set_weights()=self.model.get_weights()这部分完整代码:
python
# 1. 导入模型容器、网络层、优化器、损失函数
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,Conv2D,Flatten
from tensorflow.keras.optimizers import Adam, SGD
from tensorflow.keras.losses import CategoricalCrossentropy
class DQNAgent():
def __init__(self):
self.model=self.create_model()
self.target_model=create_model()
self.target_model.set_weights()=self.model.get_weights()
def create_model(self):
model = Sequential()
# 1. 卷积层:提取图像特征
# 注意:input_shape 通常不需要加 batch_size,直接写 (高, 宽, 通道)
model.add(Conv2D(32, (3,3), strides=(1,1), activation='relu', input_shape=env.OBSERVATION_SPACE_VALUES))
model.add(Conv2D(32, (3,3), strides=(1,1), activation='relu'))
# 2. 展平层:把多维图像数据拉成一维向量
model.add(Flatten())
# 3. 隐藏的全连接层:综合特征
model.add(Dense(32, activation='relu'))
# 4. 输出层:输出每个动作的 Q 值
model.add(Dense(env.ACTION_SPACE_VALUES, activation='linear'))
# 5. 编译模型
model.compile(loss='mse', optimizer=Adam(), metrics=['accuracy'])
return model