
本期主题
本篇文章主要是给各位看官介绍如何使用 LangChainGo 手动地构建 RAG 应用。注意我这里使用了"手动"这个词,区别于 Dify 类似的平台,它们创建 RAG 相关的智能体都是全自动的。从文档知识上传再到切分策略、文本向量化入库这整个流程都是傻瓜式的。开发者只需要关注他的业务逻辑就行了,但是这样对于开发者来说平台就是一个黑盒,无法定制化,调优比较困难。
如果公司需要整个流程都要高度定制化,那么掌握类 LangChain 的库构建 RAG 应用还是十分有必要的。
相关术语
核心概念
- RAG:(Retrieval-Augmented Generation,检索增强生成)把外部知识库 + 大模型结合起来。
- Retriever(检索器):负责"找资料"的模块,比如向量检索(最主流)、关键词检索(BM25)。
- Generator(生成器):就是大模型,比如 GPT、Claude、本地 LLM。
- Knowledge Base(知识库):RAG的数据来源,比如文档(PDF、Word)、数据库、日志 FAQ。
向量检索
- Embedding(向量化):把文本转成向量(数字表示),语义相似 ≈ 向量距离近。
- Vector Store(向量数据库):存储向量 + 做相似度搜索,比如 Milvus、FAISS、Qdrant。
- Similarity Search(相似度搜索):常见算法比如 Cosine similarity(余弦相似度)、L2 距离。
- Top-K Retrieval:从知识库中取最相关的 K 条。
文本处理
- Chunking(分块):把长文档拆成小段。
- Overlap(重叠窗口):相邻 chunk 之间有重复内容。
- Metadata(元数据):附加信息,比如来源、时间、文档类型。
检索优化
- Re-ranking(重排序):对检索结果再次排序。
- Hybrid Search(混合检索):结合向量搜索、关键词检索。
- Query Expansion(查询扩展):把用户问题改写/扩展。
- Multi-query Retrieval(多查询检索):生成多个查询一起检索。
生成阶段优化
- Prompt Engineering(提示词工程):控制大模型输出。
- Context Window(上下文窗口):模型一次能处理的最大 token 数。
- Grounding(基于事实生成):让回答严格基于检索内容。
- Hallucination(幻觉):模型"编答案"。
评估与工程化
- Recall(召回率):检索是否找到了正确内容。
- Precision(准确率):返回的内容是否真的相关。
- Latency(延迟):响应速度。
- Cost(成本):主要来自 Embedding、LLM 调用。
模型参数配置
这些参数本质上是在"控制大模型怎么说话",而不是"知道什么"。
- model:模型名称
- frequency_penalty (频率惩罚):惩罚"重复使用过的词"。值越大 → 越不喜欢重复词。可以减少:啰嗦、模板化输出、重复字段名。
- 使用建议:结构化输出 → 0~0.3,文本生成 → 0.5 左右。
- max_tokens:限制模型最多生成多少个 token(不是字数)
- n:一次生成多少个候选回答,不建议滥用:成本 = n 倍增长。
- presence_penalty (出现惩罚):惩罚"已经出现过的话题"。
- 和 frequency_penalty 的区别:frequency → 针对"词重复",presence → 针对"内容是否重复"。
- 效果:值越大 → 越倾向讲新内容。
- presence_penalty=1:不太会重复同一个观点、更容易"发散"。
- 创作 → 可以高一点(0.5~1),严格任务(JSON 校验) → 设为 0。
- tempreature (温度):控制"随机程度",范围:0 ~ 2(常用 0~1)。
- 低温(0~0.3)→ 稳、保守、重复性高
- 中等(0.5)→ 平衡
- 高温(0.8+)→ 发散、创意、多样
- temperature = 0 → 像"死记硬背的学生"
- temperature = 1 → 像"自由发挥的人"
- 写代码 / 数据处理 → 0~0.2
- 问答 / RAG → 0.2~0.5
- 文案 / 创作 → 0.7~1.0
- top_p (核采样):控制"从概率前多少的词里选"。模型会按概率排序词,只从"累计概率 ≤ top_p"的词里选。
top_p=0.9→ 只在"最可能的那 90% 概率词"里选
环境搭建
首先我们需要搭建向量库 Milvus 向量库容器。
向量库介绍
向量数据库(Vector Database)本质上是专门用来存储"向量"并进行相似度搜索的数据库,它和传统数据库最大的区别在于:不是按"精确匹配"查数据,而是按"相似程度"找结果。
在 AI 里,文本、图片、音频都会被模型转成一串数字,比如:
"猫" →
[0.12, -0.98, 0.33, ...]"小猫" →
[0.11, -0.95, 0.30, ...]
这些数字数组就是向量(Embedding) 。
向量数据库和传统结构化数据库对比:
| 维度 | 传统数据库 | 向量数据库 |
|---|---|---|
| 查询方式 | 精确匹配 | 相似匹配 |
| 数据类型 | 结构化数据 | 向量(Embedding) |
| 索引 | B+树 | HNSW / IVF |
| 使用场景 | 业务系统 | AI / 搜索 / 推荐 |
常见的向量数据库
常见的向量数据库有以下这些:
| 数据库 | 特点 |
|---|---|
| Qdrant | ✅ 单二进制 + API,开箱即用 |
| Milvus | ❌ 组件多(etcd、MinIO、QueryNode) |
| FAISS | ❌ 只是库,不是数据库 |
| Pinecone | ✅ 云服务,最省事 |
Milvus介绍
本篇文章主要介绍的向量库是 Milvus,它现在是主流厂商 RAG 场景使用的向量库。
Milvus 是鹰科 (Accipaitridae) Milvus 属的一种猛禽,以飞行速度快、视力敏锐、适应性强而著称。
Zilliz 采用 Milvus 作为其开源高性能、高扩展性向量数据库的名称,该数据库可在从笔记本电脑到大规模分布式系统等各种环境中高效运行。它既是开源软件,也是云服务。
Milvus 由 Zilliz 开发,并很快捐赠给了 Linux 基金会下的 LF AI & Data 基金会,现已成为世界领先的开源向量数据库项目之一。它采用 Apache 2.0 许可发布,大多数贡献者都是高性能计算(HPC)领域的专家,擅长构建大规模系统和优化硬件感知代码。核心贡献者包括来自 Zilliz、ARM、英伟达、AMD、英特尔、Meta、IBM、Salesforce、阿里巴巴和微软的专业人士。
有趣的是,Zilliz 的每个开源项目都以鸟命名,这种命名方式象征着自由、远见和技术的敏捷发展。
非结构化数据、Embeddings 和 Milvus
非结构化数据(如文本、图像和音频)格式各异,蕴含丰富的潜在语义,因此分析起来极具挑战性。为了处理这种复杂性,Embeddings 被用来将非结构化数据转换成能够捕捉其基本特征的数字向量。然后将这些向量存储在向量数据库中,从而实现快速、可扩展的搜索和分析。
Milvus 提供强大的数据建模功能,使您能够将非结构化或多模式数据组织成结构化的 Collections。它支持多种数据类型,适用于不同的属性模型,包括常见的数字和字符类型、各种向量类型、数组、集合和 JSON,为您节省了维护多个数据库系统的精力。
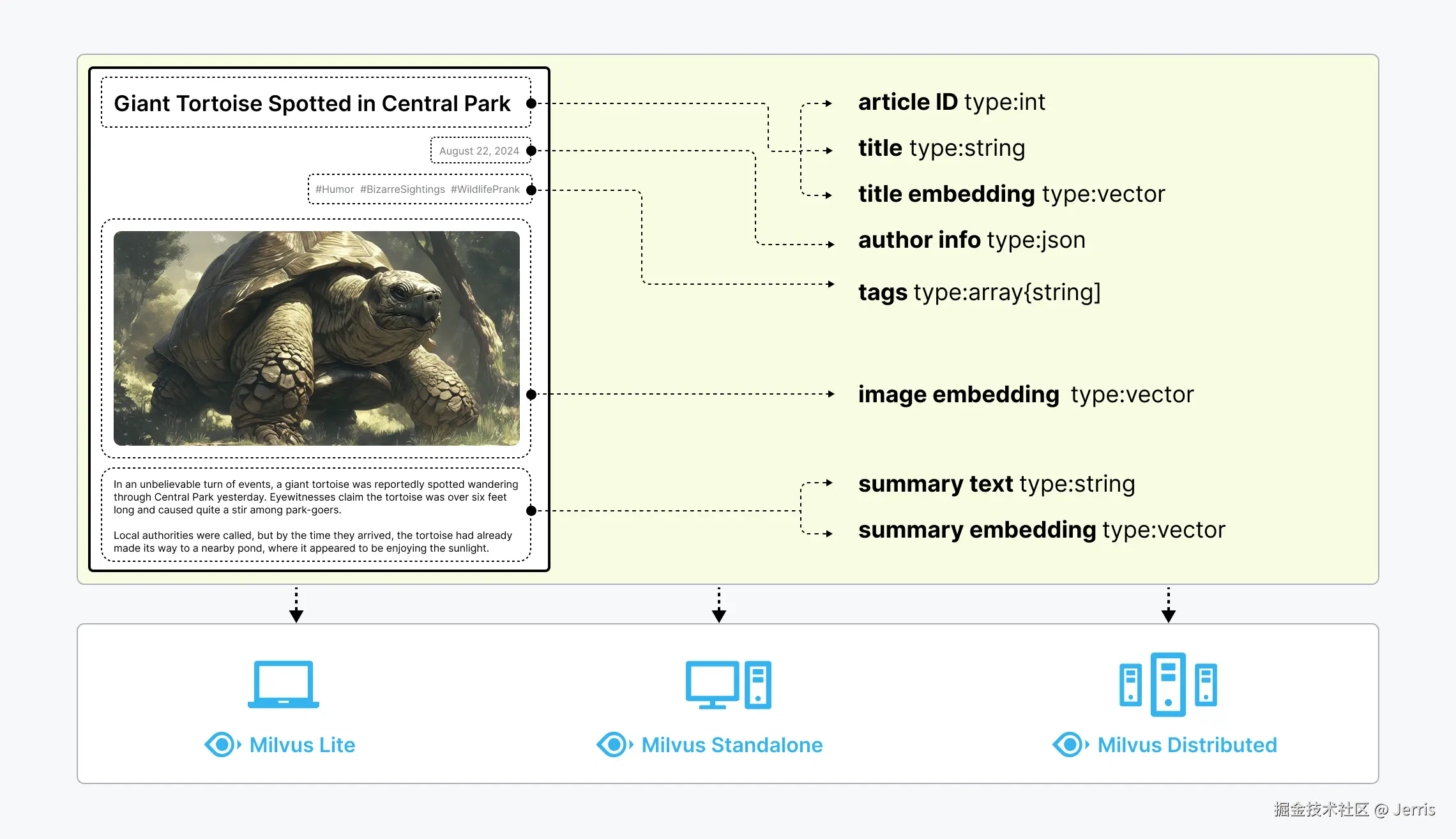
Milvus 提供三种部署模式,涵盖各种数据规模--从 Jupyter Notebooks 中的本地原型到管理数百亿向量的大规模 Kubernetes 集群:
- Milvus Lite 是一个 Python 库,可以轻松集成到您的应用程序中。作为 Milvus 的轻量级版本,它非常适合在 Jupyter Notebooks 中进行快速原型开发,或在资源有限的边缘设备上运行。了解更多信息。
- Milvus Standalone 是单机服务器部署,所有组件都捆绑在一个 Docker 镜像中,方便部署。了解更多。
- Milvus Distributed 可部署在 Kubernetes 集群上,采用云原生架构,专为十亿规模甚至更大的场景而设计。该架构可确保关键组件的冗余。了解更多。
Milvus高性能的底层原理
Milvus 从设计之初就是一个高效的向量数据库系统。在大多数情况下,Milvus 的性能是其他向量数据库的 2-5 倍(参见 VectorDBBench 结果)。这种高性能是几个关键设计决策的结果:
硬件感知优化:为了让 Milvus 适应各种硬件环境,我们专门针对多种硬件架构和平台优化了其性能,包括 AVX512、SIMD、GPU 和 NVMe SSD。
高级搜索算法:Milvus 支持多种内存和磁盘索引/搜索算法,包括 IVF、HNSW、DiskANN 等,所有这些算法都经过了深度优化。与 FAISS 和 HNSWLib 等流行实现相比,Milvus 的性能提高了 30%-70%。
C++ 搜索引擎向量数据库性能的 80% 以上取决于其搜索引擎。由于 C++ 语言的高性能、底层优化和高效资源管理,Milvus 将 C++ 用于这一关键组件。最重要的是,Milvus 集成了大量硬件感知代码优化,从汇编级向量到多线程并行化和调度,以充分利用硬件能力。
面向列:Milvus 是面向列的向量数据库系统。其主要优势来自数据访问模式。在执行查询时,面向列的数据库只读取查询中涉及的特定字段,而不是整行,这大大减少了访问的数据量。此外,对基于列的数据的操作可以很容易地进行向量化,从而可以一次性在整个列中应用操作,进一步提高性能。
Milvus高扩展性
2022 年,Milvus 支持十亿级向量,2023 年,它以持续稳定的方式扩展到数百亿级,为 300 多家大型企业的大规模场景提供支持,包括 Salesforce、PayPal、Shopee、Airbnb、eBay、NVIDIA、IBM、AT&T、LINE、ROBLOX、Inflection 等。
Milvus 的云原生和高度解耦的系统架构确保了系统可以随着数据的增长而不断扩展:
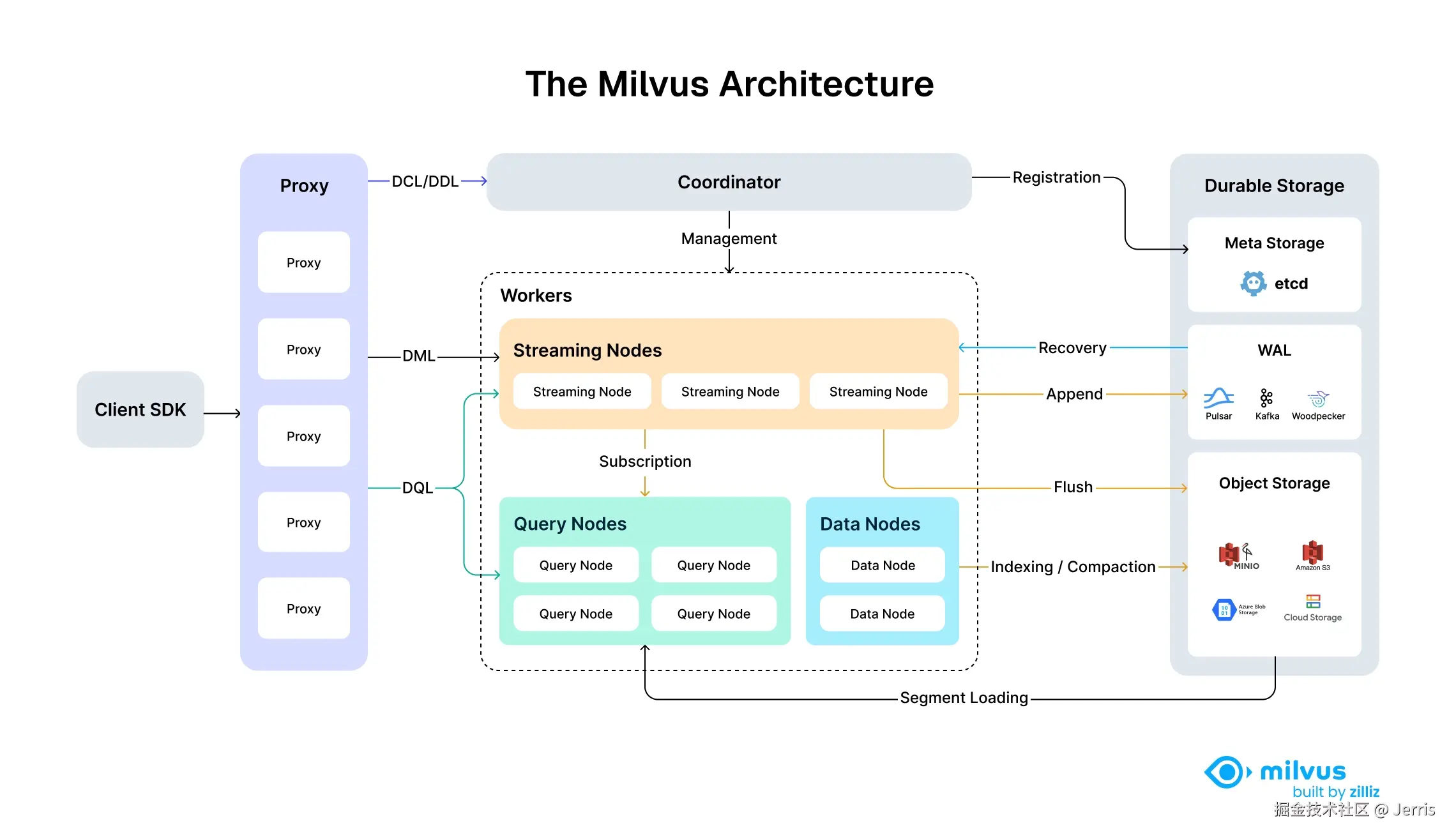
Milvus 本身是完全无状态的,因此可以借助 Kubernetes 或公共云轻松扩展。此外,Milvus 的各个组件都有很好的解耦,其中最关键的三项任务--搜索、数据插入和索引/压实--被设计为易于并行化的流程,复杂的逻辑被分离出来。这确保了相应的查询节点、数据节点和索引节点可以独立地向上和向下扩展,从而优化了性能和成本效率。
使用Docker Compose部署
我们使用 Docker Compose 来部署 Milvus 向量库。Milvus 向量库它依赖其他几个组件:MinIO、ETCD。MinIO 主要是用来存储数据用,而 ETCD 主要是用于元数据存储和分布式协调。
docker-compose.yml 文件内容如下:
yml
version: '3.5'
services:
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.5
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
healthcheck:
test: ["CMD", "etcdctl", "endpoint", "health"]
interval: 30s
timeout: 20s
retries: 3
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
ports:
- "9001:9001"
- "9000:9000"
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data --console-address ":9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.4.4
command: ["milvus", "run", "standalone"]
security_opt:
- seccomp:unconfined
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9091/healthz"]
interval: 30s
start_period: 90s
timeout: 20s
retries: 3
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- "etcd"
- "minio"
networks:
default:
name: milvus然后输入 docker compose up -d 启动容器组,最后可以在 docker desktop containers 面板中看到运行的容器:
开始撸码
阿里云百炼平台OpenAI兼容接口
因为我们用的库是 LangChainGo,所以它的接口规范支持 OpenAI、Google AI、Anthropic、Ollama。本篇文章使用的是 OpenAI 兼容接口,几乎国内每家大模型厂商都会提供 OepnAI 兼容接口,简单说就是你用 LangChainGo 调用国内厂商的和 OpenAI 接口参数、响应体一样的接口,而你的业务层代码不需要任何改动,只需要修改 baseUrl、apiKey、model 这几个参数就行了。
向量嵌入用到的接口为:/v1/embeddings,阿里云百炼的 Embedding 模型兼容 OpenAI 接口规范。将原有 OpenAI 应用迁移至阿里云百炼只需调整三个参数:
- base_url:替换为
https://dashscope.aliyuncs.com/compatible-mode/v1 - api_key:替换为阿里云百炼 API Key
- model:替换为以下模型列表中的模型名称
创建VectorStore实例
首先我们需要创建一个 github.com/tmc/langchaingo/vectorstores 包的 VectorStore 引用,后面的所有操作都依赖这个实例。
go
package store
import (
"context"
"fmt"
"github.com/milvus-io/milvus-sdk-go/v2/client"
"github.com/milvus-io/milvus-sdk-go/v2/entity"
"github.com/tmc/langchaingo/embeddings"
"github.com/tmc/langchaingo/llms/openai"
"github.com/tmc/langchaingo/vectorstores"
"github.com/tmc/langchaingo/vectorstores/milvus"
)
const (
ApiKey = "your api key"
ApiUrl = "https://dashscope.aliyuncs.com/compatible-mode/v1"
EmbeddingModel = "text-embedding-v4"
)
// NewStore 创建并返回 Milvus 向量存储(不删除旧数据)
func NewStore() (vectorstores.VectorStore, error) {
return createStore(false)
}
// MustNewStore 创建 store,如果失败则 panic(不删除旧数据,用于搜索)
// 遵循 Go 命名惯例:Must 前缀表示失败时会 panic
func MustNewStore() vectorstores.VectorStore {
store, err := NewStore()
if err != nil {
panic(fmt.Sprintf("Failed to create store: %v", err))
}
return store
}
// NewStoreWithDrop 创建并返回 Milvus 向量存储(删除旧数据,用于重新索引)
func NewStoreWithDrop() (vectorstores.VectorStore, error) {
return createStore(true)
}
// MustNewStoreWithDrop 创建 store,如果失败则 panic(删除旧数据,用于重新索引)
func MustNewStoreWithDrop() vectorstores.VectorStore {
store, err := NewStoreWithDrop()
if err != nil {
panic(fmt.Sprintf("Failed to create store with drop: %v", err))
}
return store
}
// createStore 内部函数,根据 dropOld 参数决定是否删除旧集合
func createStore(dropOld bool) (vectorstores.VectorStore, error) {
llm, err := openai.New(openai.WithBaseURL(ApiUrl), openai.WithEmbeddingModel(EmbeddingModel), openai.WithToken(ApiKey))
if err != nil {
return nil, err
}
embedder, err := embeddings.NewEmbedder(llm)
if err != nil {
return nil, err
}
idx, err := entity.NewIndexAUTOINDEX(entity.L2)
if err != nil {
return nil, err
}
ctx := context.Background()
milvusConfig := client.Config{
Address: "http://localhost:19530",
}
opts := []milvus.Option{
milvus.WithCollectionName("langchaingo_example"),
milvus.WithIndex(idx),
milvus.WithEmbedder(embedder),
}
if dropOld {
opts = append(opts, milvus.WithDropOld())
}
store, err := milvus.New(ctx, milvusConfig, opts...)
return store, err
}城市名称向量化入库
下面这段代码主要是把城市名称转为向量然后填入向量库:
go
package main
import (
"context"
"fmt"
"log"
"github.com/tmc/langchaingo/schema"
"langchango-rag-first/internal/store"
)
func main() {
fmt.Println("Starting document indexing...")
// 使用 MustNewStoreWithDrop 删除旧数据并重新创建集合
st := store.MustNewStoreWithDrop()
type meta = map[string]any
documents := []schema.Document{
{PageContent: "Tokyo", Metadata: meta{"population": 9.7, "area": 622}},
{PageContent: "Kyoto", Metadata: meta{"population": 1.46, "area": 828}},
{PageContent: "Hiroshima", Metadata: meta{"population": 1.2, "area": 905}},
{PageContent: "Kazuno", Metadata: meta{"population": 0.04, "area": 707}},
{PageContent: "Nagoya", Metadata: meta{"population": 2.3, "area": 326}},
{PageContent: "Toyota", Metadata: meta{"population": 0.42, "area": 918}},
{PageContent: "Fukuoka", Metadata: meta{"population": 1.59, "area": 341}},
{PageContent: "Paris", Metadata: meta{"population": 11, "area": 105}},
{PageContent: "London", Metadata: meta{"population": 9.5, "area": 1572}},
{PageContent: "Santiago", Metadata: meta{"population": 6.9, "area": 641}},
{PageContent: "Buenos Aires", Metadata: meta{"population": 15.5, "area": 203}},
{PageContent: "Rio de Janeiro", Metadata: meta{"population": 13.7, "area": 1200}},
{PageContent: "Sao Paulo", Metadata: meta{"population": 22.6, "area": 1523}},
}
// 分批添加文档,每批最多10个(阿里云Embedding API限制)
batchSize := 10
for i := 0; i < len(documents); i += batchSize {
end := i + batchSize
if end > len(documents) {
end = len(documents)
}
batch := documents[i:end]
_, err := st.AddDocuments(context.Background(), batch)
if err != nil {
log.Fatalf("AddDocument batch [%d:%d]: %v\n", i, end, err)
}
fmt.Printf("Added batch [%d:%d] successfully\n", i, end)
}
fmt.Println("Document indexing completed successfully!")
}结果如下:
问题向量化检索
这段代码同样使用了上面定义的 MustNewStore 函数,然后用来检索问题:
go
package main
import (
"context"
"fmt"
"log"
"github.com/tmc/langchaingo/schema"
"github.com/tmc/langchaingo/vectorstores"
"langchango-rag-first/internal/store"
)
type exampleCase struct {
name string
query string
numDocuments int
options []vectorstores.Option
}
func main() {
fmt.Println("Starting similarity search...")
st := store.MustNewStore()
exampleCases := []exampleCase{
{
name: "Up to 5 Cities in Japan",
query: "Which of these are cities are located in Japan?",
numDocuments: 5,
options: []vectorstores.Option{
vectorstores.WithScoreThreshold(0.8),
},
},
{
name: "A City in South America",
query: "Which of these are cities are located in South America?",
numDocuments: 1,
options: []vectorstores.Option{
vectorstores.WithScoreThreshold(0.8),
},
},
{
name: "Cities in Europe",
query: "Which of these are cities are located in Europe?",
numDocuments: 100,
options: []vectorstores.Option{
vectorstores.WithScoreThreshold(0.8),
},
},
}
ctx := context.Background()
results := make([][]schema.Document, len(exampleCases))
for ecI, ec := range exampleCases {
fmt.Printf("\n========== Searching: %s ==========\n", ec.name)
fmt.Printf("Query: %s\n", ec.query)
fmt.Printf("Max documents: %d\n", ec.numDocuments)
docs, err := st.SimilaritySearch(ctx, ec.query, ec.numDocuments, ec.options...)
if err != nil {
log.Fatalf("SimilaritySearch failed: %v\n", err)
}
fmt.Printf("Found %d document(s)\n", len(docs))
if len(docs) > 0 {
for i, doc := range docs {
fmt.Printf(" [%d] %s\n", i+1, doc.PageContent)
}
} else {
fmt.Println(" ⚠️ No documents found (similarity score may be below threshold)")
}
results[ecI] = docs
}
// 打印结果摘要
fmt.Printf("\n\n========================================\n")
fmt.Printf(" FINAL RESULTS SUMMARY\n")
fmt.Printf("========================================\n")
for ecI, ec := range exampleCases {
texts := make([]string, len(results[ecI]))
for docI, doc := range results[ecI] {
texts[docI] = fmt.Sprintf("%s (pop: %v area: %f)", doc.PageContent, doc.Metadata["population"], doc.Metadata["area"])
}
fmt.Printf("\n%d. %s\n", ecI+1, ec.name)
if len(texts) == 0 {
fmt.Printf(" ❌ No results found\n")
} else {
fmt.Printf(" ✅ Found %d result(s):\n", len(texts))
for _, text := range texts {
fmt.Printf(" - %s\n", text)
}
}
}
fmt.Println("\nSearch completed successfully!")
}结果如下:
txt
Starting similarity search...
========== Searching: Up to 5 Cities in Japan ==========
Query: Which of these are cities are located in Japan?
Max documents: 5
Found 4 document(s)
[1] Tokyo
[2] Nagoya
[3] Fukuoka
[4] Kyoto
========== Searching: A City in South America ==========
Query: Which of these are cities are located in South America?
Max documents: 1
Found 1 document(s)
[1] Buenos Aires
========== Searching: Cities in Europe ==========
Query: Which of these are cities are located in Europe?
Max documents: 100
Found 0 document(s)
⚠️ No documents found (similarity score may be below threshold)
========================================
FINAL RESULTS SUMMARY
========================================
1. Up to 5 Cities in Japan
✅ Found 4 result(s):
- Tokyo (pop: 9.7 area: 622.000000)
- Nagoya (pop: 2.3 area: 326.000000)
- Fukuoka (pop: 1.59 area: 341.000000)
- Kyoto (pop: 1.46 area: 828.000000)
2. A City in South America
✅ Found 1 result(s):
- Buenos Aires (pop: 15.5 area: 203.000000)
3. Cities in Europe
❌ No results found
Search completed successfully!不知道为什么 Paris、London 和 Europe 相似度那么低,结果没有查询出来,不知道是不是大模型的问题。
笔者发现把第 3 个问题稍微修改一下就可以检索到结果,可能 Europe 和城市之间的关联性在大模型看来比较低。
txt
========== Searching: Cities in Britain ==========
Query: Which of these are cities are located in Britain?
Max documents: 100
Found 1 document(s)
[1] London
3. Cities in Europe
✅ Found 1 result(s):
- London (pop: 9.5 area: 1572.000000) 实战案例:构建RAG应用
下面给大家介绍如何使用 LangChainGo 库切分知识资产文档向量化入库,然后再结合向量库检索问题。
文档切分入库
我这里准备一个高等数学空间解析几何的学习资料 Markdown 文件,下面我将会把它切分完向量化入库:
go
package main
import (
"context"
"fmt"
"log"
"os"
"path/filepath"
"github.com/tmc/langchaingo/schema"
"github.com/tmc/langchaingo/textsplitter"
"langchango-rag-first/internal/store"
)
func main() {
// 获取当前工作目录
wd, err := os.Getwd()
if err != nil {
log.Fatal(err)
}
// 构建文件路径
markdownFile := filepath.Join(wd, "cmd/markdown/space_geometry_rag_latex.md")
content, err := os.ReadFile(markdownFile)
if err != nil {
panic(fmt.Sprintf("Failed to read file %s: %v", markdownFile, err))
}
text := string(content)
mdSplitter := textsplitter.NewMarkdownTextSplitter()
mdChunks, err := mdSplitter.SplitText(text)
if err != nil {
panic(err)
}
rcSplitter := textsplitter.NewRecursiveCharacter(
textsplitter.WithChunkSize(500),
textsplitter.WithChunkOverlap(50),
)
var finalChunks []string
for _, chunk := range mdChunks {
subChunks, _ := rcSplitter.SplitText(chunk)
finalChunks = append(finalChunks, subChunks...)
}
var docs []schema.Document
for _, c := range finalChunks {
docs = append(docs, schema.Document{
PageContent: c,
Metadata: map[string]any{
"source": "test.md",
},
})
}
fmt.Printf("Split markdown into %d chunks\n", len(docs))
// 创建 Milvus store(删除旧数据)
fmt.Println("Creating Milvus vector store...")
st := store.MustNewStoreWithDrop()
// 分批添加文档到 Milvus(每批最多10个,符合阿里云 API 限制)
fmt.Println("Adding documents to Milvus...")
batchSize := 10
for i := 0; i < len(docs); i += batchSize {
end := i + batchSize
if end > len(docs) {
end = len(docs)
}
batch := docs[i:end]
_, err := st.AddDocuments(context.Background(), batch)
if err != nil {
log.Fatalf("Failed to add batch [%d:%d]: %v\n", i, end, err)
}
fmt.Printf("Added batch [%d:%d] (%d documents)\n", i, end, len(batch))
}
fmt.Printf("\n✅ Successfully indexed %d documents to Milvus!\n", len(docs))
}结果输出如下:
txt
Split markdown into 31 chunks
Creating Milvus vector store...
Adding documents to Milvus...
Added batch [0:10] (10 documents)
Added batch [10:20] (10 documents)
Added batch [20:30] (10 documents)
Added batch [30:31] (1 documents)
✅ Successfully indexed 31 documents to Milvus!准备一个markdown文件
事先准备好一个 markdown 文件如下:
markdown
# 空间解析几何学习笔记(RAG专用版)
## 1. 空间直角坐标系
### 1.1 坐标系定义
空间直角坐标系由三条互相垂直的坐标轴组成:
- x轴
- y轴
- z轴
任意一点表示为:
$$P(x, y, z)$$
---
### 1.2 两点间距离公式
$$d = \sqrt{(x_2 - x_1)^2 + (y_2 - y_1)^2 + (z_2 - z_1)^2}$$
---
### 1.3 中点公式
$$M = \left(\frac{x_1 + x_2}{2}, \frac{y_1 + y_2}{2}, \frac{z_1 + z_2}{2}\right)$$
---
## 2. 向量基础
### 2.1 向量表示
$$\mathbf{a} = (x, y, z)$$
---
### 2.2 向量模长
$$|\mathbf{a}| = \sqrt{x^2 + y^2 + z^2}$$
---
### 2.3 数量积(点积)
$$\mathbf{a} \cdot \mathbf{b} = x_1x_2 + y_1y_2 + z_1z_2$$
性质:
- 判断垂直:$\mathbf{a} \cdot \mathbf{b} = 0$
- 夹角公式:
$$\cos\theta = \frac{\mathbf{a} \cdot \mathbf{b}}{|\mathbf{a}||\mathbf{b}|}$$
---
### 2.4 向量积(叉积)
$$
\mathbf{a} \times \mathbf{b} =
\begin{vmatrix}
\mathbf{i} & \mathbf{j} & \mathbf{k} \\
x_1 & y_1 & z_1 \\
x_2 & y_2 & z_2
\end{vmatrix}
$$
结果:
$$\mathbf{a} \times \mathbf{b} = (y_1z_2 - z_1y_2,\; z_1x_2 - x_1z_2,\; x_1y_2 - y_1x_2)$$
性质:
- 结果垂直于两个向量
- 模长表示平行四边形面积
---
## 3. 空间直线
### 3.1 参数方程
已知点 $P_0(x_0, y_0, z_0)$,方向向量 $\mathbf{a}(l, m, n)$:
$$
\begin{cases}
x = x_0 + lt \\
y = y_0 + mt \\
z = z_0 + nt
\end{cases}
$$
---
### 3.2 对称式方程
$$\frac{x - x_0}{l} = \frac{y - y_0}{m} = \frac{z - z_0}{n}$$
---
### 3.3 两直线位置关系
判断方法:
- 平行:方向向量成比例
- 相交:解方程有唯一解
- 异面:既不平行也不相交
---
## 4. 空间平面
### 4.1 平面的一般方程
$$Ax + By + Cz + D = 0$$
法向量:
$$\mathbf{n} = (A, B, C)$$
---
### 4.2 点法式方程
已知点 $P_0$ 和法向量 $\mathbf{n}$:
$$A(x - x_0) + B(y - y_0) + C(z - z_0) = 0$$
---
### 4.3 三点确定平面
通过三个不共线点构造两个向量,再求法向量(叉积)
---
## 5. 位置关系
### 5.1 直线与平面
判断:
- 平行:方向向量 $\perp$ 法向量
- 垂直:方向向量 $\parallel$ 法向量
---
### 5.2 平面与平面
判断:
- 平行:法向量成比例
- 垂直:法向量点积为 0
---
## 6. 距离公式
### 6.1 点到平面距离
$$d = \frac{|Ax_0 + By_0 + Cz_0 + D|}{\sqrt{A^2 + B^2 + C^2}}$$
---
### 6.2 点到直线距离
$$d = \frac{|\overrightarrow{P_0P} \times \mathbf{a}|}{|\mathbf{a}|}$$
---
### 6.3 两条异面直线距离
$$d = \frac{|\overrightarrow{P_1P_2} \cdot (\mathbf{a} \times \mathbf{b})|}{|\mathbf{a} \times \mathbf{b}|}$$
---
## 7. 典型题型
### 7.1 求直线方程
步骤:
1. 找一点
2. 找方向向量
3. 写参数或对称式
---
### 7.2 求平面方程
方法:
- 点法式
- 三点法
- 法向量法
---
### 7.3 判定位置关系
核心:
- 点积 → 垂直
- 比例 → 平行
---
## 8. RAG切分建议(重点)
### 推荐Chunk结构
```json
{
"topic": "点到平面距离",
"formula": "...",
"explanation": "...",
"keywords": ["距离", "平面", "公式"]
}尝试检索向量库回答一个问题
go
package main
import (
"context"
"fmt"
"log"
"strings"
"github.com/tmc/langchaingo/chains"
"github.com/tmc/langchaingo/llms/openai"
"github.com/tmc/langchaingo/prompts"
"github.com/tmc/langchaingo/vectorstores"
"langchango-rag-first/internal/store"
)
const (
// 大模型配置(用于生成答案)
LLMApiKey = "your api key"
LLMApiUrl = "https://dashscope.aliyuncs.com/compatible-mode/v1"
LLMModel = "qwen-plus" // 使用聊天模型
)
func main() {
fmt.Println("========== RAG Query System ==========\n")
// 1. 创建向量存储(不删除旧数据)
fmt.Println("Connecting to Milvus vector store...")
st := store.MustNewStore()
// 2. 创建大语言模型(用于生成答案)
fmt.Println("Initializing LLM...")
llm, err := openai.New(
openai.WithBaseURL(LLMApiUrl),
openai.WithModel(LLMModel),
openai.WithToken(LLMApiKey),
)
if err != nil {
log.Fatalf("Failed to create LLM: %v\n", err)
}
// 3. 定义测试问题
questions := []string{
"两点间距离公式是什么?",
"平面的一般方程是什么?",
"两条异面直线距离如何计算?",
}
// 4. 执行 RAG 查询
ctx := context.Background()
for i, question := range questions {
fmt.Printf("\n========================================\n")
fmt.Printf("Question %d: %s\n", i+1, question)
fmt.Printf("========================================\n")
answer, err := ragQuery(ctx, st, llm, question)
if err != nil {
log.Printf("Failed to answer question %d: %v\n", i+1, err)
continue
}
fmt.Printf("\nAnswer:\n%s\n", answer)
}
fmt.Println("\n========== All queries completed ==========\n")
}
// ragQuery 执行 RAG 查询:检索相关文档 + 大模型生成答案
func ragQuery(ctx context.Context, vs vectorstores.VectorStore, llm *openai.LLM, question string) (string, error) {
// Step 1: 从向量库检索相关文档
fmt.Println("🔍 Searching relevant documents...")
docs, err := vs.SimilaritySearch(ctx, question, 3) // 返回最相关的3个文档
if err != nil {
return "", fmt.Errorf("similarity search failed: %w", err)
}
if len(docs) == 0 {
return "Sorry, I couldn't find any relevant information in the knowledge base.", nil
}
fmt.Printf("📄 Found %d relevant document(s)\n", len(docs))
// Step 2: 构建上下文(将检索到的文档内容拼接)
var contextBuilder strings.Builder
for i, doc := range docs {
contextBuilder.WriteString(fmt.Sprintf("Document %d:\n%s\n\n", i+1, doc.PageContent))
}
contextText := contextBuilder.String()
// Step 3: 构建 Prompt 模板
template := `Based on the following context, please answer the question.
If the context doesn't contain relevant information, say "I don't have enough information to answer this question."
Context:
{{.context}}
Question: {{.question}}
Answer:`
prompt := prompts.NewPromptTemplate(template, []string{"context", "question"})
// Step 4: 使用 LLM Chain 生成答案
chain := chains.NewLLMChain(llm, prompt)
result, err := chains.Call(ctx, chain, map[string]any{
"context": contextText,
"question": question,
}, chains.WithTemperature(0.3)) // 较低的温度使回答更准确
if err != nil {
return "", fmt.Errorf("LLM chain failed: %w", err)
}
// 从结果中提取文本
answer, ok := result["text"].(string)
if !ok {
return "", fmt.Errorf("unexpected result format")
}
return answer, nil
}输出如下:
txt
========== RAG Query System ==========
Connecting to Milvus vector store...
Initializing LLM...
========================================
Question 1: 两点间距离公式是什么?
========================================
🔍 Searching relevant documents...
📄 Found 3 relevant document(s)
Answer:
两点间距离公式是:
$$
d = \sqrt{(x_2 - x_1)^2 + (y_2 - y_1)^2 + (z_2 - z_1)^2}
$$
该公式适用于三维空间中两点 $(x_1, y_1, z_1)$ 和 $(x_2, y_2, z_2)$ 之间的距离计算。
========================================
Question 2: 平面的一般方程是什么?
========================================
🔍 Searching relevant documents...
📄 Found 3 relevant document(s)
Answer:
平面的一般方程是:
$$
Ax + By + Cz + D = 0
$$
========================================
Question 3: 两条异面直线距离如何计算?
========================================
🔍 Searching relevant documents...
📄 Found 3 relevant document(s)
Answer:
两条异面直线距离的计算公式为:
$$
d = \frac{|\overrightarrow{P_1P_2} \cdot (\mathbf{a} \times \mathbf{b})|}{|\mathbf{a} \times \mathbf{b}|}
$$
其中:
- $P_1$、$P_2$ 分别是两条异面直线上各取的一点;
- $\mathbf{a}$、$\mathbf{b}$ 分别是这两条直线的方向向量;
- $\overrightarrow{P_1P_2}$ 是连接两直线上两点的向量;
- $\mathbf{a} \times \mathbf{b}$ 是两方向向量的叉积,其模长表示以 $\mathbf{a}, \mathbf{b}$ 为邻边的平行四边形面积;
- 分子是 $\overrightarrow{P_1P_2}$ 在 $\mathbf{a} \times \mathbf{b}$ 方向上的投影长度(绝对值),即两直线间公垂线段的长度。
该公式本质上是求两异面直线间的最短距离(即公垂线段长度)。
========== All queries completed ==========工作流程图
RAG 应用整个工作流程图如下: