做时间序列预测的时候,我越来越强烈地感受到一件事:很多预测问题,真正难的不是模型不够强,而是原始序列本身就太复杂。
我最开始做这类任务时,也走过最常见的路线:直接上 LSTM,或者直接上 Transformer,希望模型自己把趋势、周期、噪声和突发波动全部学明白。但实际跑下来,我发现这类做法在面对非平稳信号时总会遇到几个很典型的问题。第一,原始序列往往混合了多种频率成分,模型需要同时处理高频扰动和低频趋势,学习负担很重;第二,单一网络通常只能在某一类特征上表现突出,比如 Transformer 擅长长依赖,CNN 擅长局部模式,LSTM 擅长时序记忆,但很难靠一个模块把所有问题都解决掉;第三,序列里如果高频噪声比较重,模型很容易出现"趋势能跟住,但细节抓不住"的情况。
于是我开始反过来想:既然原始序列不好学,那我能不能先把它拆开,再让模型去学?
这就是我设计这套 CEEMDAN-VMD-Transformer-CNN-BiLSTM 模型的出发点。我的思路不是简单拼模型,而是先从信号层面降低问题难度,再从网络层面做能力互补。具体来说,我先对目标序列做 CEEMDAN 分解,把复杂信号拆成多个 IMF 分量;再把最高频的 IMF1 送进 VMD 做二次分解,进一步细化快速波动部分;然后把这些分解得到的特征,与原始多变量特征一起融合;最后再送入 Transformer-CNN-BiLSTM 混合网络做预测。到这里,整条链路就不再是"一个模型盯着一条难学的原始曲线硬啃",而是变成了"模型面对一组已经被整理过的信息去学习"。
一、我为什么会想到先做分解,再做深度学习建模?
我一开始遇到的问题非常典型:时间序列看起来是一条曲线,但本质上往往是多种成分叠加的结果。它既有慢变化的趋势项,也有周期项,还会混入随机噪声和局部高频波动。对于这样的序列,如果我直接把原始数据喂给深度学习模型,那么模型在训练时其实要同时完成很多任务:既要识别长期变化规律,又要追踪局部扰动,还要尽量忽略噪声干扰。这个任务并不轻松。
从这个角度看,时间序列预测可以理解成一个"先信号拆解、再规律学习"的问题。设原始目标序列为
其中, 表示趋势成分,
表示周期成分,
表示高频波动,
表示随机噪声。
如果我不做任何预处理,模型其实是在直接拟合这个混合结果;但如果我先把它拆开,那么模型面对的每个部分都会更规整、更容易学习。
也正是在这个阶段,我开始明确这套方法的第一原则:
先尽可能把原始序列变得"可学习",再谈模型结构。
所以我没有一上来就纠结"到底用 LSTM 还是 Transformer",而是先去想,怎样把序列里的不同频率成分拆开。最后我选择了 CEEMDAN + VMD 这条路线。
二、为什么是 CEEMDAN + VMD,而不是只做一次分解?
这是我设计这套算法时最关键的一步。
我之所以先用 CEEMDAN,是因为它对非线性、非平稳信号的适应性很好。CEEMDAN 可以把原始序列分解为若干本征模态函数 IMF,它不像固定基函数分解那样要求序列必须满足比较强的先验假设,更适合真实时间序列这种复杂信号。按照 CEEMDAN 的分解特点,前面的 IMF 一般对应更高频的波动,后面的 IMF 更接近低频趋势。
但我在实际看分解结果时很快发现,只做一次 CEEMDAN 还不够。原因在于,IMF1 往往最"乱"。它确实代表最高频成分,但也正因为频率最高,里面经常混合了局部震荡、快速扰动和一部分噪声。换句话说,CEEMDAN 把"大问题"拆小了,但 IMF1 这一块仍然是最难学的部分。
于是我继续问自己一个问题:
既然 IMF1 还是复杂,那我能不能对 IMF1 再拆一次?
这个问题,直接把我带到了 VMD。VMD 的优势在于,它可以把一个复杂的振荡分量进一步分离成若干带限子模态。于是我最终决定:先用 CEEMDAN 做第一层粗粒度分解,再对 IMF1 做 VMD 二次分解,专门把最复杂的高频部分继续细化。
用公式表达,我的思路大致可以写成:
然后再对最高频分量继续处理:
最终我不再直接使用原始的,而是把它替换为更细粒度的 VMD 子模态,于是新的分解特征可以写成:
这一步的本质,就是把原本最复杂的那一块高频信息拆得更细,降低后续深度模型的学习难度。
三、源码里我是怎么把这套"双重分解"写出来的?
在我的项目里,双重分解逻辑主要放在 decomposition.py 里。这个文件不大,但它承担的是整条预测链路最前面的工作,也就是"把一条难学的目标序列,转成一组更容易学习的模态特征"。
我把 CEEMDAN 和 VMD 拆成了三个函数:perform_ceemdan()、perform_vmd() 和 dual_decomposition()。其中前两个分别负责单独分解,第三个函数负责把两步串起来。
python
def perform_ceemdan(data, trials=100):
ceemdan = CEEMDAN(trials=trials)
imfs = ceemdan.ceemdan(data)
return imfs
def perform_vmd(data, alpha=2000, tau=0, K=3, DC=0, init=1, tol=1e-7):
u, u_hat, omega = VMD(data, alpha, tau, K, DC, init, tol)
return u
def dual_decomposition(series, config):
ceemdan_imfs = perform_ceemdan(series, config.ceemdan_trials)
imf1 = ceemdan_imfs[0]
vmd_imfs = perform_vmd(
imf1,
config.vmd_alpha,
config.vmd_tau,
config.vmd_K,
config.vmd_DC,
config.vmd_init,
config.vmd_tol
)
combined_features = np.vstack((vmd_imfs, ceemdan_imfs[1:]))
return combined_features.T这段代码看起来不复杂,但它对应的设计思路非常明确。
第一步,我先用 perform_ceemdan() 对原始目标序列做 CEEMDAN 分解,得到多个 IMF 分量。
第二步,我明确只取 ceemdan_imfs[0],也就是 IMF1。因为在我的设定里,最值得进一步细化的就是最高频成分。
第三步,我用 perform_vmd() 对 IMF1 做 VMD 分解,把它拆成 K 个子模态。
第四步,我把 VMD 得到的若干子模态,与 CEEMDAN 剩余的 IMF2、IMF3、... 一起重新拼接,形成新的分解特征矩阵。
这里有一个很容易被忽略但其实非常关键的细节:最后我返回的是 combined_features.T,而不是原始堆叠结果。原因是 np.vstack() 堆出来的矩阵形状是"模态数 × 序列长度",而后续在 data_processing.py 里,我要把它和原始多变量特征按列拼接,所以必须把它转成:

也就是说,在后续数据处理中,每一个时间步都对应一行特征,而不是每一个模态对应一行。这一步如果不转置,后面的特征融合根本接不上。
我把大部分核心超参数统一放在 config.py 里,这是为了让整套工程更清晰,也方便后续实验调整。
在双重分解这一块,比较关键的参数有:
ceemdan_trials = 100vmd_alpha = 2000vmd_tau = 0.vmd_K = 3vmd_tol = 1e-7
ceemdan_trials 决定了 CEEMDAN 在加入噪声辅助分解时的试验次数。次数太少,分解稳定性可能不足;次数太多,计算开销会增加。这里我取了 100,属于一个比较稳妥的经验值。
vmd_K 决定 VMD 把 IMF1 再拆成多少个子模态。我没有把它设得太大,而是先取 3,原因很简单:我希望它能细化最高频分量,但不想把高频部分过度切碎,导致后续特征维度膨胀太快。
vmd_alpha 是惩罚因子,本质上在控制各模态带宽约束的强弱。它越大,VMD 对模态带宽的限制越明显。vmd_tau 则可以理解为噪声容忍相关参数,这里我先用默认偏保守的设定。vmd_tol 是收敛阈值,用于控制 VMD 的停止条件。
这类参数其实没有绝对最优值。我的做法是:先用一组能跑通、能看见分解效果的参数起步,再考虑系统搜索。 这也是工程里更现实的做法。
五、做完分解后,我为什么还要和原始多变量特征融合?
这是我一开始就非常明确的一件事:
我做分解,不是为了只拿分解模态去预测,而是为了增强原始输入表达能力。
我构造了一份多变量时间序列,其中除了目标列 target 外,还有两个辅助特征 feat1 和 feat2:
python
target = 10 * np.sin(2 * np.pi * 0.1 * t) + 5 * np.cos(2 * np.pi * 0.5 * t) + np.random.normal(0, 1, n_samples)
feat1 = target * 0.5 + np.random.normal(0, 0.5, n_samples)
feat2 = np.roll(target, 5) + np.random.normal(0, 0.5, n_samples)从构造方式就能看出来,feat1 和 feat2 都和目标序列有相关性。也就是说,预测目标值时,除了目标本身的多尺度分解信息,我仍然希望保留这些原始外生特征。
我是这样处理的:
python
other_features = df.drop(columns=[config.target_col]).values
final_features = np.hstack((decomposed_features, other_features))这一步的含义非常直接:
我把"目标序列分解后的模态特征"和"原始数据中 target 以外的其他变量"横向拼接起来,作为最终输入。
从数学上可以写成:
其中,表示时刻
的分解特征向量,
表示时刻
的原始多变量辅助特征。最终输入不是单一来源,而是这两类信息的融合结果。
六、我是怎么把时间序列样本变成监督学习格式的?
做完特征融合后,接下来就要把连续序列切成可训练样本了。核心函数是 create_sliding_windows()。
python
def create_sliding_windows(data, target, seq_len, pred_len):
X, y = [], []
for i in range(len(data) - seq_len - pred_len + 1):
X.append(data[i:(i + seq_len)])
y.append(target[i + seq_len: i + seq_len + pred_len])
return np.array(X), np.array(y)我这里采用的是经典的滑动窗口构造。设输入窗口长度为 ,预测步长为
,那么第
个样本可以表示为:
在当前配置中,seq_len = 24,pred_len = 1,所以它的实际含义就是:
用过去 24 个时间步的输入特征,预测下一个时间步的目标值。
为什么我要这样构造?因为时间序列预测本质上就是利用历史去推断未来,而滑动窗口恰好能把这个过程转换成监督学习能直接处理的 (X, y) 样本对。
在归一化处理上,我用了两个 MinMaxScaler:
python
scaler_X = MinMaxScaler()
scaler_y = MinMaxScaler()
scaled_X = scaler_X.fit_transform(final_features)
scaled_y = scaler_y.fit_transform(df[[config.target_col]].values)我把输入特征和输出目标分开归一化,是因为后面预测完成后,我只需要对预测值做反归一化,不需要再管输入端的尺度恢复。这个设计在工程里很常见,也更稳妥。
另外,我把训练集和测试集按时间顺序做了 8:2 划分:
python
train_size = int(len(X) * 0.8)
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]我没有在原始时间轴上乱序切分,因为那样会破坏时间因果关系。对时间序列来说,时间顺序本身就是信息。
七、为什么我的主干网络不是单一模型,而是 Transformer + CNN + BiLSTM?
当我完成双重分解和特征融合后,接下来的问题就变成了:
什么样的网络结构,能把这些信息尽量吃干净?
我当时没有选单一 LSTM,也没有直接选纯 Transformer,而是选择了一个混合架构。原因很现实:我不想让一个模块承担所有任务,我更倾向于让不同模块各自做自己擅长的事。
1. 先做特征映射
第一层是一个线性映射:
python
self.feature_map = nn.Linear(self.input_dim, self.d_model)输入张量形状是:
经过映射后变成:
这样做的目的,是把融合后的原始输入维度统一投影到 Transformer 可处理的隐空间维度
2. 用位置编码和 Transformer 抓长期依赖
我在模型里加入了标准的正弦余弦位置编码,然后接了 TransformerEncoder。这一层是为了补足传统循环网络在长程依赖建模上的不足。时间序列中,很多信息并不是只靠最近几个时间步就能解释的,较远位置上的模式同样可能重要。
Transformer 的核心注意力机制可以概括为:
这条公式的意义在于,模型能够让每个时间步和序列中其他时间步建立联系,从而学习全局依赖关系。
在我的代码里,这一部分是这样走的:
python
x = self.feature_map(x)
x = self.pos_encoder(x.transpose(0, 1)).transpose(0, 1)
x = self.transformer_encoder(x)这里之所以先转置再转回来,是因为我的位置编码实现是按 (seq_len, batch, d_model) 形式组织的,而 TransformerEncoder 设置了 batch_first=True,所以中间需要做一次适配。
3. 用 CNN 抓局部模式和短期波动
只用 Transformer,我总觉得还不够。因为 Transformer 更偏向全局关系建模,而时间序列里很多局部短波动、高频片段和小范围模式,用卷积其实更直接。
所以我在 Transformer 后面接了一层 1D CNN:
python
self.cnn = nn.Sequential(
nn.Conv1d(in_channels=self.d_model, out_channels=config.cnn_hidden, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool1d(kernel_size=2, stride=2)
)这里的卷积核大小取 3,是一个很典型的局部感受野设置。它会让模型重点关注相邻时间步之间的局部模式。卷积之后再接 MaxPool1d,一方面可以提取更显著的局部特征,另一方面也能压缩时间维度,减少后续时序层的处理负担。
在张量维度上,这一段的变化是:
- Transformer 输出:
(batch_size, seq_len, d_model)- CNN 前转置:
(batch_size, d_model, seq_len)- CNN + Pool 后:
(batch_size, cnn_hidden, seq_len/2)- 转回时序格式:
(batch_size, seq_len/2, cnn_hidden)
4. 最后用 BiLSTM 强化时序表达
卷积之后,我没有直接输出,而是又接了一层 BiLSTM:
python
self.lstm = nn.LSTM(
input_size=config.cnn_hidden,
hidden_size=config.lstm_hidden,
num_layers=config.lstm_layers,
batch_first=True,
bidirectional=True,
dropout=config.dropout
)为什么还要加 BiLSTM?因为我想让模型在卷积提取完局部模式之后,再重新站回"时序建模"的视角去组织这些特征。尤其是双向结构,能够同时利用前向和后向上下文来增强表示能力。
LSTM 的门控机制可以用下面几条式子概括:
而 BiLSTM 的输出可以理解为:
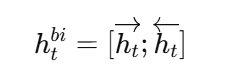
也就是说,每个时间步的最终表示同时包含前向和后向两个方向的信息。
5. 最终输出层
在 forward() 的最后,我取的是 BiLSTM 最后一个时间步的输出:
python
out = x[:, -1, :]
out = self.fc(out)然后通过全连接层,把高维时序表示映射到最终预测值上。由于当前 pred_len = 1,所以模型做的是单步预测。
整条网络的张量流可以概括为:
python
输入 x: (B, seq_len, input_dim)
特征映射后: (B, seq_len, d_model)
Transformer 后: (B, seq_len, d_model)
CNN前转置: (B, d_model, seq_len)
CNN后: (B, cnn_hidden, seq_len/2)
转回时序格式: (B, seq_len/2, cnn_hidden)
BiLSTM后: (B, seq_len/2, 2*lstm_hidden)
取最后时间步: (B, 2*lstm_hidden)
全连接输出: (B, pred_len)八、训练时我做了哪些工程上的选择?
我没有追求特别花哨的训练技巧,而是选择了一套相对稳健的配置:MSE 损失、Adam 优化器、早停机制和最佳模型保存。
核心部分是:
python
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)
early_stopping = EarlyStopping(patience=config.patience, verbose=True)损失函数 MSE 可以写成:
我选择它的原因很直接:这是时间序列回归里最基础也最常用的误差度量方式,对大误差更敏感,能够督促模型尽量减少偏差较大的预测点。
优化器我用的是 Adam,因为它在这类中小规模深度模型里通常比较稳,调起来也省心。
另外,我很重视早停机制。原因是时间序列模型在训练后期很容易开始过拟合,尤其是在样本量不算特别大的情况下。我在配置里把 patience 设成了 7,也就是如果验证损失连续 7 个 epoch 没有改善,就停止训练。这个逻辑不仅能节省时间,也能让最终保留下来的模型更稳。
EarlyStopping 里还有一个很实用的动作,就是每当验证损失刷新最优值时,就自动保存当前模型参数:
python
torch.save(model.state_dict(), 'best_model.pth')训练结束后再重新加载这个最优权重。这样做的好处是,即使最后几个 epoch 出现波动,我最终拿到的也仍然是验证集表现最好的那一版模型。
九、三张图对我来说分别意味着什么?
在这个项目里,我特意保留了三类可视化输出,因为我不希望只看最后一张预测图。我更想知道:分解是否有效、训练是否稳定、预测是否可信。
1. 分解结果图:
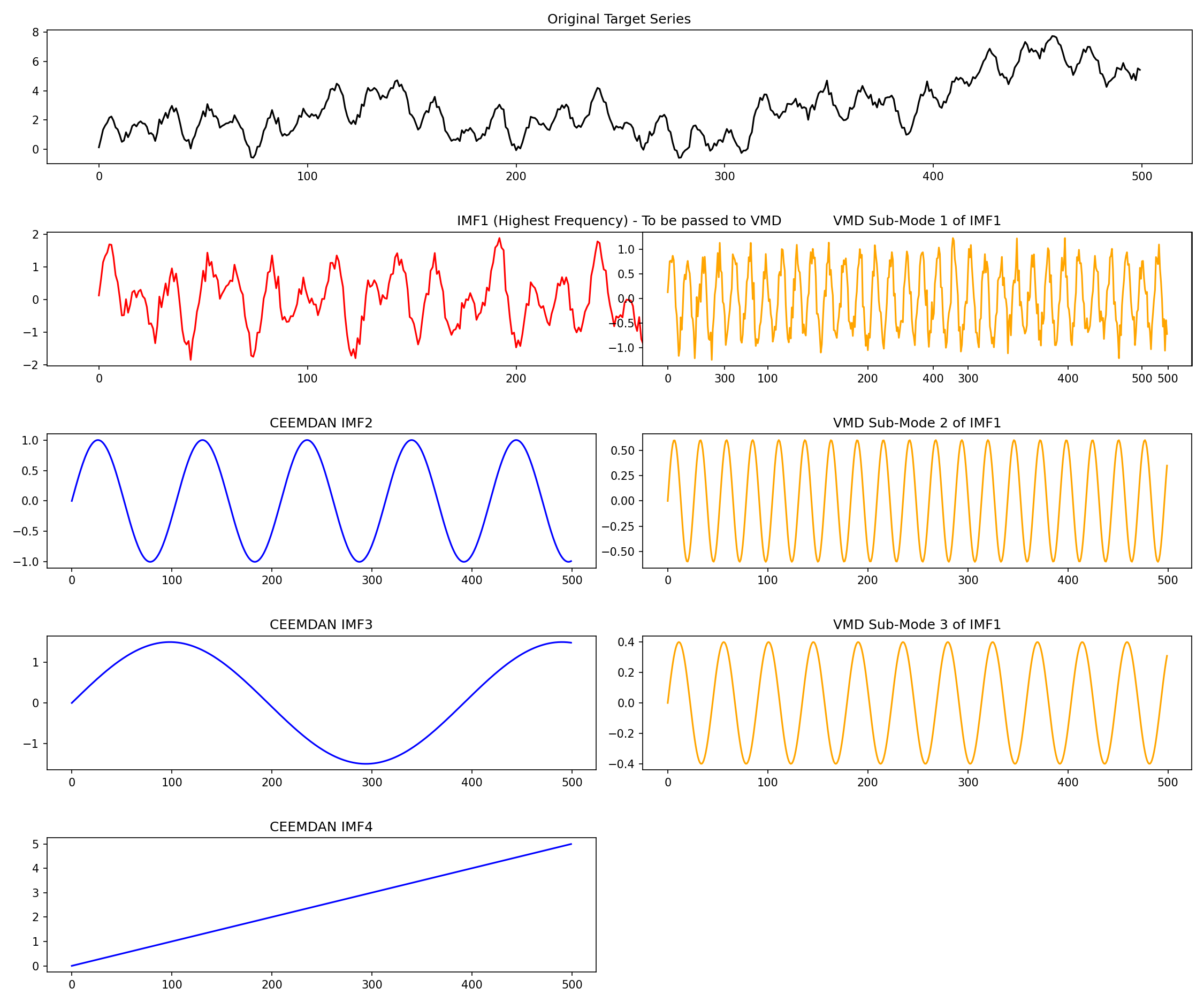
这张图里,我会同时看原始序列、CEEMDAN 的 IMF 分量以及 IMF1 对应的 VMD 子模态。对我来说,这张图最重要的意义不是"展示我做了分解",而是让我直观看见:高频成分有没有被继续细化,剩余 IMF 是否逐步走向更低频、更平滑的趋势结构。
如果 VMD 之后的子模态比 IMF1 本身更规整、更有层次,那就说明这一步二次分解是有价值的。
2. 损失曲线图:
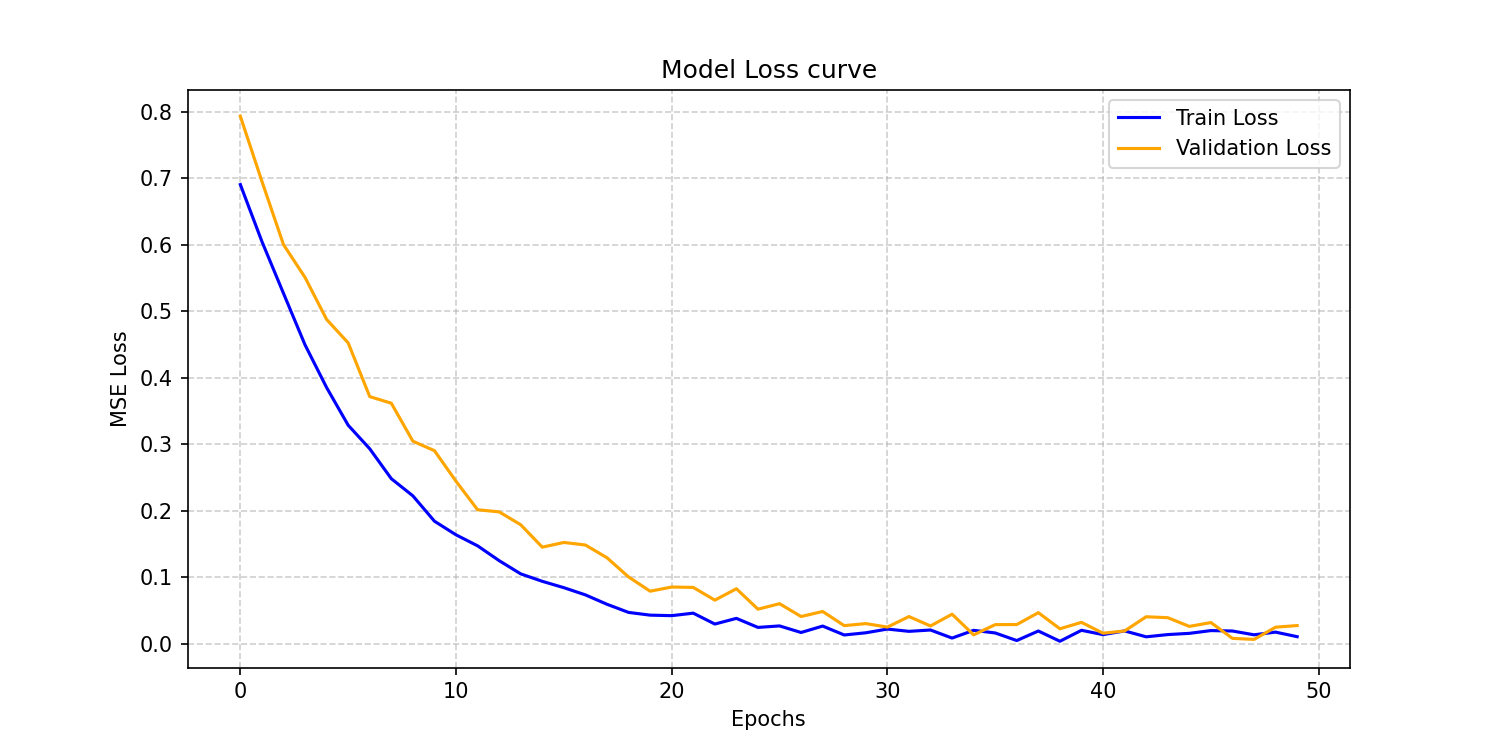
这张图用来判断训练是否稳定。如果训练损失和验证损失都能比较平滑地下降,说明模型优化过程比较正常;如果训练损失持续下降但验证损失提前反弹,那说明模型已经开始过拟合,早停机制就会变得很重要。
3. 预测结果图:
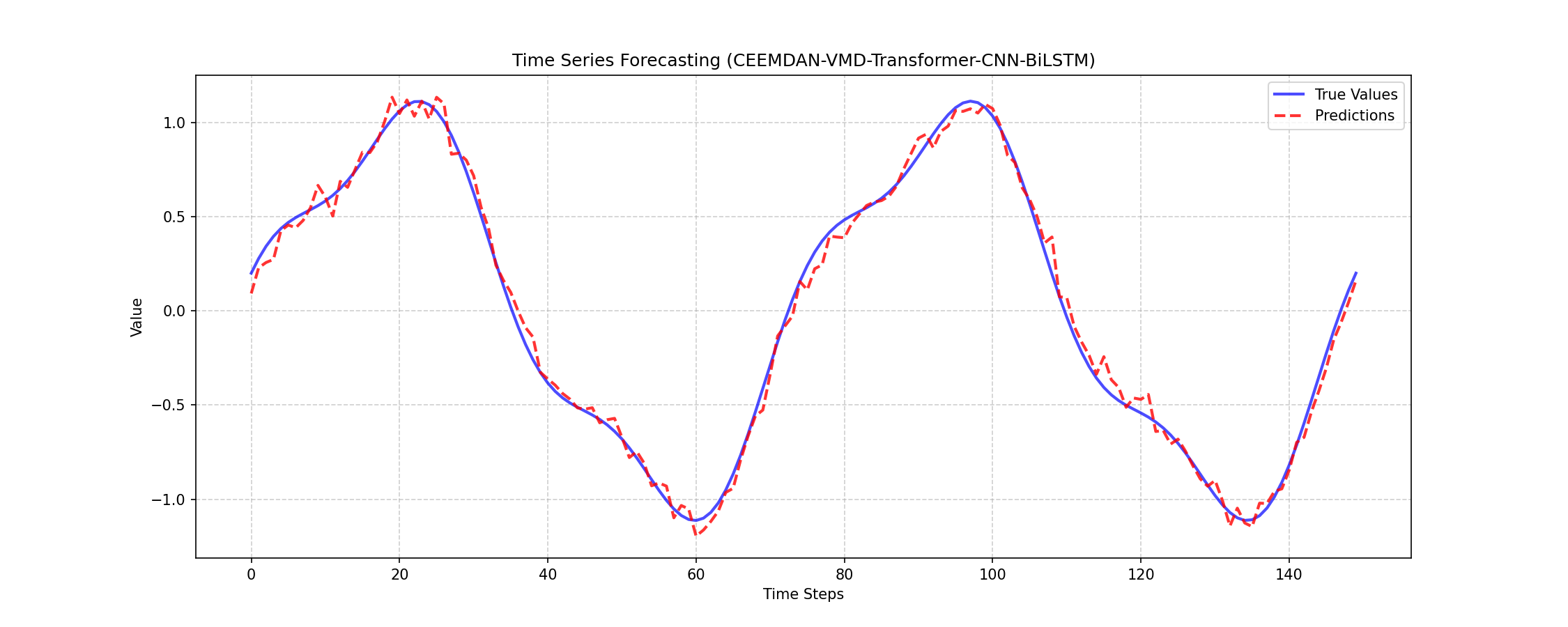
这是最终的效果展示。我在看这张图时,通常不会只看"拟合得像不像",而是更关注三个细节:
第一,整体趋势是否跟住了;
第二,局部波峰波谷是否能对齐;
第三,快速震荡区域是否存在明显滞后或者过度平滑。
如果一个模型只能跟住大趋势,但细节很差,那它说明对局部波动感知不够;如果它能追住细节,但整体走势又不稳定,那说明全局建模还不够。也正因为如此,我才会把 Transformer、CNN 和 BiLSTM 组合起来。
结语:我最后真正确定的,不是一个模型,而是一种建模思路
这套 CEEMDAN-VMD-Transformer-CNN-BiLSTM 项目做完之后,我最大的感受其实不是"我又搭了一个复杂网络",而是我更加确认了一种做时间序列预测的思路:
面对复杂、非平稳、噪声重的时间序列,先想办法把信号整理清楚,再让模型去学习,比一开始就把所有希望都压在单一模型上更有效。
也正是因为这个认识,我才会先选择 CEEMDAN 做模态分解,再用 VMD 专门处理最复杂的高频 IMF1,最后再让 Transformer、CNN 和 BiLSTM 分别负责全局依赖、局部模式和时序整合。
如果用一句话总结这篇文章想表达的核心,那就是:
我不是在做一个"模型拼盘",而是在尝试把时间序列预测拆成一条更合理的工程链路。
而这条链路,从我的实验结果和源码实现来看,至少已经证明了一点:当原始序列很复杂时,先分解,再融合,再建模,确实是一条值得认真走下去的路线。
需要源码的请联系作者,作者会在半个小时内回复,制作不易,请点个关注和收藏,+v Guigui1213812