摘要:本文深入讲解了构建生产级RAG(检索增强生成)系统的完整方案。主要内容包括:1)系统架构设计,涵盖索引构建和查询处理全流程;2)向量数据库选型对比与Milvus实战部署;3)文档智能分块与向量化处理策略;4)查询优化技术,包括重写、扩展和混合检索;5)重排序优化与Cross-Encoder应用;6)完整API服务实现与Docker部署方案。文章重点分析了企业级RAG的核心挑战,如检索精度、系统性能和数据安全等,并提供了性能优化策略和演进路线建议。通过结合密集/稀疏向量检索、查询重写和重排序等技术,可显著提升召回率和回答质量,适用于从快速验证到亿级规模的不同应用场景。
一、RAG技术概述与企业级挑战

1.1 什么是RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将外部知识检索与大语言模型生成能力结合的技术架构。其核心思想是:在回答用户问题前,先从知识库中检索相关信息,将检索结果作为上下文提供给大模型,从而生成更准确、更可靠的回答。
相比单纯的模型微调,RAG具有以下优势:
-
**知识实时性**:无需重新训练即可更新知识库
-
**可解释性**:答案可追溯至具体来源文档
-
**成本效益**:降低大模型幻觉,减少API调用成本
1.2 企业级RAG的核心挑战
构建生产级RAG系统面临以下技术挑战:
| 挑战维度 | 具体问题 | 技术指标 |
|---|---|---|
| 检索精度 | 向量相似度≠语义相关,召回文档质量差 | 召回率>90%,精确率>85% |
| 系统性能 | 高并发下延迟飙升,吞吐量不足 | P99延迟<100ms,QPS>1000 |
| 数据规模 | 千万级文档的存储与检索效率 | 支持十亿级向量,PB级数据 |
| 运维成本 | 向量数据库集群管理复杂 | 自动化扩缩容,监控告警完善 |
| 数据安全 | 敏感数据泄露风险,合规要求 | 数据加密,访问控制,审计日志 |
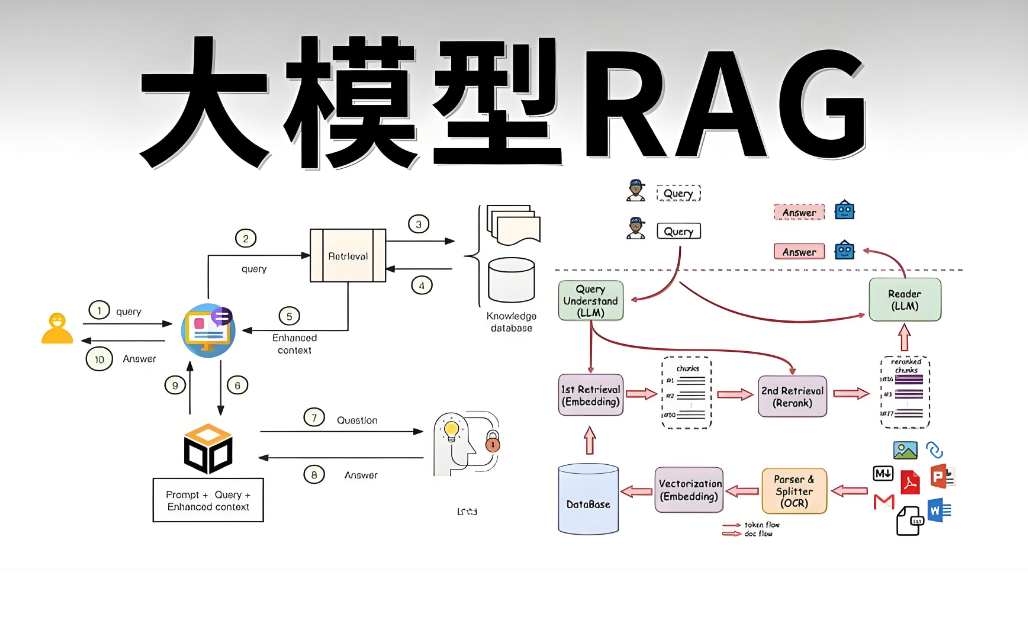
二、系统架构设计
2.1 整体架构图
RAG系统的工作流程分为两个阶段:
索引阶段(离线):
-
文档加载与解析(PDF/Word/Markdown)
-
文档分块(Chunking)与语义分割
-
向量化(Embedding)处理
-
构建索引并写入向量数据库
查询阶段(在线):
-
查询重写(Query Rewriting)
-
多路召回(向量检索 + 关键词检索)
-
重排序(Reranking)
-
上下文构建与答案生成
三、向量数据库选型与实战
3.1 主流向量数据库对比
根据数据规模和业务需求,企业级RAG系统常用的向量数据库包括:
| 数据库 | 架构特点 | 优势 | 适用场景 | 性能指标 |
|---|---|---|---|---|
| Milvus | 云原生分布式 | 十亿级规模、GPU加速、多索引类型 | 大规模企业平台、多模态RAG | P99<50ms,支持千亿向量 |
| Pinecone | 全托管SaaS | 零运维、自动扩缩容、高可用 | 快速上线、中小规模生产 | P99<100ms,按量计费 |
| Weaviate | 开源+云托管 | 内置向量化、GraphQL接口、多模态 | 需要灵活查询、知识图谱场景 | 支持亿级向量 |
| Qdrant | Rust编写 | 高性能、复杂过滤、资源占用低 | 过滤查询多、成本敏感场景 | 内存优化型 |
| Chroma | 嵌入式 | 轻量易用、开发友好 | 原型验证、小规模项目 | 本地存储 |
选型建议:
-
**数据量<100万**:Chroma或FAISS,快速验证
-
**数据量100万-5000万**:Milvus Standalone或Qdrant
-
**数据量>5000万**:Milvus分布式集群或Pinecone
-
**企业级生产**:优先考虑Milvus(开源可控)或Pinecone(全托管)
3.2 Milvus企业级部署实战
Milvus是目前企业级RAG场景的首选开源方案,支持亿级向量规模的高并发检索。
python
# milvus_manager.py
from pymilvus import (
connections, FieldSchema, CollectionSchema, DataType,
Collection, utility, AnnSearchRequest, RRFRanker
)
from sentence_transformers import SentenceTransformer
import numpy as np
from typing import List, Dict, Optional
import hashlib
class MilvusManager:
"""Milvus向量数据库管理器"""
def __init__(self, host: str = "localhost", port: str = "19530"):
# 连接Milvus集群
connections.connect("default", host=host, port=port)
self.embedding_model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
self.dim = 1024 # bge-large-zh-v1.5维度
def create_collection(
self,
collection_name: str,
enable_dynamic_field: bool = True
) -> Collection:
"""创建集合(表)"""
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
# 定义字段Schema
fields = [
FieldSchema(name="id", dtype=DataType.VARCHAR, max_length=64, is_primary=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=self.dim),
FieldSchema(name="sparse_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),
FieldSchema(name="content", dtype=DataType.VARCHAR, max_length=65535),
FieldSchema(name="metadata", dtype=DataType.JSON),
FieldSchema(name="source", dtype=DataType.VARCHAR, max_length=512),
]
schema = CollectionSchema(
fields=fields,
description="企业级RAG知识库",
enable_dynamic_field=enable_dynamic_field
)
collection = Collection(name=collection_name, schema=schema)
# 创建索引 - IVF_PQ适合大规模数据,HNSW适合高召回率
index_params = {
"index_type": "HNSW", # 或 "IVF_PQ" 用于十亿级数据
"metric_type": "COSINE",
"params": {
"M": 16, # HNSW图的平均出度
"efConstruction": 200 # 构建时的搜索范围
}
}
collection.create_index(field_name="vector", index_params=index_params)
# 稀疏向量索引(用于BM25混合检索)
sparse_index = {"index_type": "SPARSE_INVERTED_INDEX", "metric_type": "IP"}
collection.create_index(field_name="sparse_vector", index_params=sparse_index)
collection.load()
return collection
def generate_id(self, content: str) -> str:
"""基于内容生成确定性ID"""
return hashlib.md5(content.encode()).hexdigest()
def insert_documents(
self,
collection_name: str,
documents: List[Dict],
batch_size: int = 1000
):
"""
批量插入文档
Args:
documents: [{"content": str, "metadata": dict, "source": str}, ...]
"""
collection = Collection(collection_name)
# 批量处理
for i in range(0, len(documents), batch_size):
batch = documents[i:i+batch_size]
# 生成向量
contents = [doc["content"] for doc in batch]
vectors = self.embedding_model.encode(
contents,
normalize_embeddings=True,
show_progress_bar=False
).tolist()
# 生成稀疏向量(简化的BM25表示)
sparse_vectors = self._generate_sparse_vectors(contents)
# 准备数据
ids = [self.generate_id(doc["content"]) for doc in batch]
metadata = [doc.get("metadata", {}) for doc in batch]
sources = [doc.get("source", "") for doc in batch]
# 插入数据
entities = [
ids, vectors, sparse_vectors, contents, metadata, sources
]
collection.insert(entities)
collection.flush()
print(f"成功插入{len(documents)}条文档")
def _generate_sparse_vectors(self, texts: List[str]) -> List[Dict]:
"""生成稀疏向量表示(用于BM25检索)"""
# 简化的词频表示,实际可用BGE-M3等模型生成
from sklearn.feature_extraction.text import TfidfVectorizer
import scipy.sparse as sp
vectorizer = TfidfVectorizer(max_features=10000)
tfidf_matrix = vectorizer.fit_transform(texts)
sparse_vectors = []
for i in range(len(texts)):
row = tfidf_matrix[i]
coo = row.tocoo()
sparse_dict = {int(col): float(val) for col, val in zip(coo.col, coo.data)}
sparse_vectors.append(sparse_dict)
return sparse_vectors
def hybrid_search(
self,
collection_name: str,
query: str,
top_k: int = 10,
dense_weight: float = 0.7,
sparse_weight: float = 0.3,
filters: Optional[str] = None
) -> List[Dict]:
"""
混合检索:密集向量 + 稀疏向量(BM25)
Args:
dense_weight: 语义检索权重
sparse_weight: 关键词检索权重
"""
collection = Collection(collection_name)
# 生成查询向量
query_vector = self.embedding_model.encode(
[query], normalize_embeddings=True
)[0].tolist()
# 密集向量检索(语义搜索)
dense_search_params = {
"data": [query_vector],
"anns_field": "vector",
"param": {"metric_type": "COSINE", "params": {"ef": 64}},
"limit": top_k * 2
}
dense_req = AnnSearchRequest(**dense_search_params)
# 稀疏向量检索(关键词搜索)
sparse_vector = self._generate_sparse_vectors([query])[0]
sparse_search_params = {
"data": [sparse_vector],
"anns_field": "sparse_vector",
"param": {"metric_type": "IP"},
"limit": top_k * 2
}
sparse_req = AnnSearchRequest(**sparse_search_params)
# 使用RRF(Reciprocal Rank Fusion)融合排序
rerank = RRFRanker(k=60)
results = collection.hybrid_search(
reqs=[dense_req, sparse_req],
rerank=rerank,
limit=top_k,
output_fields=["content", "metadata", "source"]
)[0]
return [
{
"id": hit.id,
"content": hit.entity.get("content"),
"metadata": hit.entity.get("metadata"),
"source": hit.entity.get("source"),
"score": hit.score,
"rank": i + 1
}
for i, hit in enumerate(results)
]
def delete_by_filter(self, collection_name: str, expr: str):
"""根据条件删除文档"""
collection = Collection(collection_name)
collection.delete(expr)
collection.flush()
def get_stats(self, collection_name: str) -> Dict:
"""获取集合统计信息"""
collection = Collection(collection_name)
return {
"total_documents": collection.num_entities,
"index_type": collection.indexes[0].params if collection.indexes else None,
"loaded": collection.is_loaded
}
# 使用示例
if __name__ == "__main__":
manager = MilvusManager()
# 创建集合
collection = manager.create_collection("enterprise_kb")
# 插入示例数据
docs = [
{
"content": "RAG(检索增强生成)是一种结合外部知识检索的AI技术...",
"metadata": {"category": "AI技术", "author": "技术团队"},
"source": "https://company.com/docs/rag-guide"
},
# ... 更多文档
]
manager.insert_documents("enterprise_kb", docs)
# 混合检索
results = manager.hybrid_search("enterprise_kb", "什么是RAG技术?", top_k=5)
for r in results:
print(f"Score: {r['score']:.4f}, Content: {r['content'][:100]}...")四、文档处理与向量化 pipeline
4.1 智能文档分块策略
文档分块(Chunking)是RAG系统的关键环节,直接影响检索质量。
python
# document_processor.py
from langchain.document_loaders import (
PyPDFLoader,
UnstructuredWordDocumentLoader,
TextLoader,
UnstructuredMarkdownLoader
)
from langchain.text_splitter import (
RecursiveCharacterTextSplitter,
SemanticChunker,
MarkdownHeaderTextSplitter
)
from langchain.embeddings import HuggingFaceEmbeddings
from typing import List, Dict
import os
class SmartDocumentProcessor:
"""智能文档处理器"""
def __init__(self):
self.embedding_model = HuggingFaceEmbeddings(
model_name="BAAI/bge-large-zh-v1.5"
)
def load_document(self, file_path: str) -> List[Dict]:
"""加载不同格式的文档"""
ext = os.path.splitext(file_path)[1].lower()
loaders = {
'.pdf': PyPDFLoader,
'.docx': UnstructuredWordDocumentLoader,
'.md': UnstructuredMarkdownLoader,
'.txt': TextLoader
}
loader_class = loaders.get(ext, TextLoader)
loader = loader_class(file_path)
documents = loader.load()
return [
{
"content": doc.page_content,
"metadata": doc.metadata
}
for doc in documents
]
def semantic_chunking(
self,
documents: List[Dict],
min_chunk_size: int = 200,
max_chunk_size: int = 1000
) -> List[Dict]:
"""
语义感知的文档分块
策略:
1. 先按段落分割
2. 对小段落进行语义合并
3. 对大段落进行递归分割
4. 保持上下文连贯性
"""
chunks = []
for doc in documents:
content = doc["content"]
metadata = doc["metadata"]
# 使用语义分割器
text_splitter = SemanticChunker(
self.embedding_model,
breakpoint_threshold_type="percentile",
breakpoint_threshold_amount=85
)
texts = text_splitter.split_text(content)
for i, text in enumerate(texts):
# 如果chunk太小,尝试与下一个合并
if len(text) < min_chunk_size and i < len(texts) - 1:
continue
chunk_metadata = {
**metadata,
"chunk_index": i,
"chunk_size": len(text),
"total_chunks": len(texts)
}
chunks.append({
"content": text,
"metadata": chunk_metadata
})
return chunks
def hierarchical_chunking(self, markdown_content: str) -> List[Dict]:
"""
基于文档结构的层次化分块(适用于Markdown/HTML)
"""
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on
)
md_header_splits = markdown_splitter.split_text(markdown_content)
return [
{
"content": doc.page_content,
"metadata": doc.metadata
}
for doc in md_header_splits
]
def sliding_window_chunking(
self,
text: str,
chunk_size: int = 512,
overlap: int = 128
) -> List[str]:
"""
滑动窗口分块,保持上下文连贯
Args:
chunk_size: 每个块的大小(字符数)
overlap: 相邻块的重叠大小
"""
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunk = text[start:end]
chunks.append(chunk)
start = end - overlap # 向前滑动,保持重叠
return chunks
# 处理Pipeline
class DocumentIngestionPipeline:
"""文档摄入流水线"""
def __init__(self, milvus_manager: MilvusManager):
self.processor = SmartDocumentProcessor()
self.milvus = milvus_manager
async def process_and_index(
self,
file_path: str,
collection_name: str,
metadata: Dict = None
):
"""完整处理流程:加载->分块->向量化->入库"""
# 1. 加载文档
documents = self.processor.load_document(file_path)
# 2. 智能分块
if file_path.endswith('.md'):
chunks = self.processor.hierarchical_chunking(
documents[0]["content"]
)
else:
chunks = self.processor.semantic_chunking(documents)
# 3. 增强元数据
for chunk in chunks:
chunk["metadata"].update(metadata or {})
chunk["metadata"]["file_path"] = file_path
chunk["source"] = file_path
# 4. 批量入库
self.milvus.insert_documents(collection_name, chunks)
return len(chunks)五、查询优化与高级检索策略
5.1 查询重写(Query Rewriting)
用户原始查询往往存在口语化、指代不明等问题,需要通过查询重写优化。
python
# query_optimizer.py
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from typing import List
class QueryOptimizer:
"""查询优化器"""
def __init__(self):
self.llm = ChatOpenAI(model="gpt-4o", temperature=0)
async def rewrite_query(self, original_query: str, chat_history: List[Dict] = None) -> str:
"""
查询重写:澄清意图,优化表达
策略:
1. 消除歧义和指代
2. 补充缺失的上下文
3. 转换为适合检索的形式
"""
rewrite_prompt = ChatPromptTemplate.from_messages([
("system", """你是一个专业的查询优化助手。你的任务是:
1. 分析用户原始查询的意图
2. 消除模糊表达和代词指代
3. 补充必要的上下文信息
4. 输出一个清晰、具体、适合向量检索的查询语句
注意:
- 保持原意不变
- 使用专业术语
- 避免口语化表达
- 如有多重意图,拆分为明确的问题"""),
("human", """历史对话:
{history}
原始查询:{query}
优化后的查询:""")
])
history_str = "\n".join([
f"{'User' if msg['role'] == 'user' else 'Assistant'}: {msg['content']}"
for msg in (chat_history or [])[-3:] # 最近3轮
])
chain = rewrite_prompt | self.llm | StrOutputParser()
result = await chain.ainvoke({
"query": original_query,
"history": history_str or "无"
})
return result.strip()
async def expand_query(self, query: str, num_expansions: int = 3) -> List[str]:
"""
查询扩展:生成多个相关查询,提高召回率
"""
expansion_prompt = ChatPromptTemplate.from_messages([
("system", f"""基于用户查询,生成{num_expansions}个语义相关但角度不同的查询变体。
这些变体应:
- 覆盖不同的专业术语表达
- 包含上下位概念
- 考虑不同的提问方式
仅输出查询列表,每行一个,不要编号。"""),
("human", "原始查询:{query}")
])
chain = expansion_prompt | self.llm | StrOutputParser()
result = await chain.ainvoke({"query": query})
expansions = [line.strip() for line in result.split('\n') if line.strip()]
return [query] + expansions[:num_expansions] # 包含原始查询
async def generate_hypothetical_answer(self, query: str) -> str:
"""
HyDE(假设文档嵌入):生成假设答案用于检索
"""
hyde_prompt = ChatPromptTemplate.from_messages([
("system", "基于查询,生成一个假设的答案。这个答案可能不完全准确,但应包含相关的关键词和概念,用于帮助检索相关文档。"),
("human", "查询:{query}\n\n假设答案:")
])
chain = hyde_prompt | self.llm | StrOutputParser()
return await chain.ainvoke({"query": query})
# 使用示例
async def optimized_retrieval(query: str, milvus_manager: MilvusManager):
optimizer = QueryOptimizer()
# 1. 重写查询
rewritten = await optimizer.rewrite_query(query)
print(f"原始查询: {query}")
print(f"重写后: {rewritten}")
# 2. 查询扩展
expanded_queries = await optimizer.expand_query(rewritten)
# 3. 多查询检索
all_results = []
for q in expanded_queries:
results = milvus_manager.hybrid_search("enterprise_kb", q, top_k=5)
all_results.extend(results)
# 4. 去重和重排序
unique_results = {r["id"]: r for r in all_results}
return list(unique_results.values())5.2 重排序优化(Reranking)
向量相似度排序往往不够精准,需要使用Cross-Encoder进行精排。
python
# reranker.py
from sentence_transformers import CrossEncoder
import numpy as np
from typing import List, Dict
class Reranker:
"""重排序器"""
def __init__(self, model_name: str = "BAAI/bge-reranker-large"):
self.model = CrossEncoder(model_name)
def rerank(
self,
query: str,
documents: List[Dict],
top_k: int = 5
) -> List[Dict]:
"""
对检索结果进行重排序
Args:
query: 用户查询
documents: 候选文档列表
top_k: 返回前k个结果
"""
if not documents:
return []
# 构建查询-文档对
pairs = [[query, doc["content"]] for doc in documents]
# 计算相关性分数
scores = self.model.predict(pairs)
# 合并分数和文档
for doc, score in zip(documents, scores):
doc["rerank_score"] = float(score)
# 综合分数:向量相似度 + 重排序分数
doc["final_score"] = 0.3 * doc.get("score", 0) + 0.7 * score
# 按最终分数排序
sorted_docs = sorted(
documents,
key=lambda x: x["final_score"],
reverse=True
)
return sorted_docs[:top_k]
def filter_by_threshold(
self,
documents: List[Dict],
threshold: float = 0.5
) -> List[Dict]:
"""按阈值过滤低相关性文档"""
return [doc for doc in documents if doc.get("rerank_score", 0) >= threshold]
# 集成到检索流程
class AdvancedRetriever:
"""高级检索器"""
def __init__(self, milvus_manager: MilvusManager):
self.milvus = milvus_manager
self.reranker = Reranker()
self.optimizer = QueryOptimizer()
async def retrieve(
self,
query: str,
collection_name: str,
top_k: int = 5,
use_rerank: bool = True,
use_expansion: bool = True
) -> List[Dict]:
"""
完整的检索流程:重写->扩展->召回->重排
"""
# 1. 查询重写
rewritten_query = await self.optimizer.rewrite_query(query)
# 2. 查询扩展(可选)
if use_expansion:
queries = await self.optimizer.expand_query(rewritten_query)
else:
queries = [rewritten_query]
# 3. 多路召回
all_docs = []
for q in queries:
docs = self.milvus.hybrid_search(
collection_name,
q,
top_k=top_k * 2 # 召回更多供重排
)
all_docs.extend(docs)
# 去重
seen = set()
unique_docs = []
for doc in all_docs:
if doc["id"] not in seen:
seen.add(doc["id"])
unique_docs.append(doc)
# 4. 重排序
if use_rerank and unique_docs:
final_docs = self.reranker.rerank(rewritten_query, unique_docs, top_k)
else:
final_docs = unique_docs[:top_k]
return final_docs六、RAG引擎集成与API服务
6.1 完整的RAG服务实现
python
# rag_service.py
from fastapi import FastAPI, HTTPException, BackgroundTasks
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from typing import List, Optional, Dict
import asyncio
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
app = FastAPI(title="企业级RAG系统", version="1.0.0")
# 全局组件实例
milvus_manager = MilvusManager()
retriever = AdvancedRetriever(milvus_manager)
llm = ChatOpenAI(model="gpt-4o", temperature=0.3)
# 数据模型
class QueryRequest(BaseModel):
question: str
collection: str = "enterprise_kb"
top_k: int = 5
use_rerank: bool = True
stream: bool = False
class DocumentUploadRequest(BaseModel):
file_path: str
collection: str = "enterprise_kb"
metadata: Optional[Dict] = None
class RAGResponse(BaseModel):
answer: str
sources: List[Dict]
query_time_ms: float
total_tokens: int
# RAG核心服务
class RAGService:
def __init__(self):
self.prompt_template = ChatPromptTemplate.from_messages([
("system", """你是一个专业的企业知识助手。基于以下检索到的参考资料回答问题:
【参考资料】
{context}
【回答要求】
1. 仅基于参考资料回答,不要添加外部知识
2. 如果资料不足以回答问题,明确说明"根据现有资料无法确定"
3. 引用来源时使用[^index^]格式标注
4. 保持回答简洁、专业、结构化"""),
("human", "问题:{question}")
])
self.chain = self.prompt_template | llm | StrOutputParser()
def format_context(self, documents: List[Dict]) -> str:
"""格式化检索结果作为上下文"""
contexts = []
for i, doc in enumerate(documents, 1):
source = doc.get("source", "未知来源")
contexts.append(
f"[{i}] 来源:{source}\n内容:{doc['content']}\n"
)
return "\n---\n".join(contexts)
async def answer(self, request: QueryRequest) -> RAGResponse:
"""生成答案"""
import time
start_time = time.time()
# 1. 检索相关文档
documents = await retriever.retrieve(
query=request.question,
collection_name=request.collection,
top_k=request.top_k,
use_rerank=request.use_rerank
)
if not documents:
return RAGResponse(
answer="未找到相关参考资料,无法回答该问题。",
sources=[],
query_time_ms=(time.time() - start_time) * 1000,
total_tokens=0
)
# 2. 构建上下文
context = self.format_context(documents)
# 3. 生成答案
answer = await self.chain.ainvoke({
"context": context,
"question": request.question
})
query_time = (time.time() - start_time) * 1000
return RAGResponse(
answer=answer,
sources=[
{
"id": doc["id"],
"source": doc.get("source", ""),
"score": doc.get("rerank_score", doc.get("score")),
"content_preview": doc["content"][:200]
}
for doc in documents
],
query_time_ms=query_time,
total_tokens=len(answer) + len(context) # 简化估算
)
rag_service = RAGService()
# API端点
@app.post("/api/v1/rag/query", response_model=RAGResponse)
async def query(request: QueryRequest):
"""RAG查询接口"""
try:
return await rag_service.answer(request)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/api/v1/rag/upload")
async def upload_document(request: DocumentUploadRequest):
"""文档上传接口"""
try:
pipeline = DocumentIngestionPipeline(milvus_manager)
chunk_count = await pipeline.process_and_index(
file_path=request.file_path,
collection_name=request.collection,
metadata=request.metadata
)
return {"status": "success", "chunks_indexed": chunk_count}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/api/v1/collections/{collection_name}/stats")
async def collection_stats(collection_name: str):
"""获取集合统计信息"""
try:
stats = milvus_manager.get_stats(collection_name)
return stats
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
# 健康检查
@app.get("/health")
async def health_check():
return {"status": "healthy", "service": "rag-api"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)七、性能优化与生产部署
7.1 性能优化策略
python
# optimizations.py
from functools import lru_cache
from redis import Redis
import hashlib
import json
class RAGCache:
"""多级缓存系统"""
def __init__(self):
self.redis = Redis(host='localhost', port=6379, db=0)
self.local_cache = {} # L1: 本地内存缓存
self.local_ttl = 300 # 5分钟
def get_cache_key(self, query: str, collection: str) -> str:
"""生成缓存键"""
key_str = f"{collection}:{query}"
return f"rag:query:{hashlib.md5(key_str.encode()).hexdigest()}"
async def get(self, query: str, collection: str):
"""获取缓存结果"""
key = self.get_cache_key(query, collection)
# L1缓存
if key in self.local_cache:
return self.local_cache[key]
# L2 Redis缓存
cached = self.redis.get(key)
if cached:
result = json.loads(cached)
self.local_cache[key] = result # 回填L1
return result
return None
async def set(self, query: str, collection: str, result: dict, ttl: int = 3600):
"""设置缓存"""
key = self.get_cache_key(query, collection)
# L1缓存
self.local_cache[key] = result
# L2 Redis缓存
self.redis.setex(key, ttl, json.dumps(result))
class AsyncBatchProcessor:
"""异步批处理器"""
def __init__(self, batch_size: int = 10, max_wait_ms: int = 50):
self.batch_size = batch_size
self.max_wait_ms = max_wait_ms
self.queue = asyncio.Queue()
self.results = {}
async def add(self, item):
"""添加任务到批次"""
future = asyncio.Future()
await self.queue.put((item, future))
return await future
async def process_batch(self, processor_func):
"""批量处理"""
while True:
batch = []
start_time = asyncio.get_event_loop().time()
# 收集批次
while len(batch)< self.batch_size:
timeout = self.max_wait_ms / 1000 - (asyncio.get_event_loop().time() - start_time)
if timeout <= 0:
break
try:
item, future = await asyncio.wait_for(self.queue.get(), timeout=max(0, timeout))
batch.append((item, future))
except asyncio.TimeoutError:
break
if batch:
# 批量处理
items = [item for item, _ in batch]
try:
results = await processor_func(items)
for (_, future), result in zip(batch, results):
future.set_result(result)
except Exception as e:
for _, future in batch:
future.set_exception(e)7.2 Docker Compose部署配置
python
# docker-compose.yml
version: '3.8'
services:
# RAG API服务
rag-api:
build: .
ports:
- "8000:8000"
environment:
- MILVUS_HOST=milvus-standalone
- REDIS_HOST=redis
- OPENAI_API_KEY=${OPENAI_API_KEY}
depends_on:
- milvus-standalone
- redis
- etcd
- minio
deploy:
replicas: 2
resources:
limits:
cpus: '4'
memory: 8G
# Milvus向量数据库
etcd:
image: quay.io/coreos/etcd:v3.5.5
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
volumes:
- etcd_data:/etcd
minio:
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
command: minio server /minio_data
volumes:
- minio_data:/minio_data
milvus-standalone:
image: milvusdb/milvus:v2.3.3
command: ["milvus", "run", "standalone"]
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
volumes:
- milvus_data:/var/lib/milvus
depends_on:
- etcd
- minio
ports:
- "19530:19530"
# Redis缓存
redis:
image: redis:7-alpine
volumes:
- redis_data:/data
# 监控
prometheus:
image: prom/prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- "9090:9090"
volumes:
etcd_data:
minio_data:
milvus_data:
redis_data:八、关键技术关键词解释
| 序号 | 关键词 | 解释 |
|---|---|---|
| 1 | RAG (检索增强生成) | 结合外部知识检索与大模型生成的技术架构,通过检索相关文档作为上下文,提升回答准确性和可解释性 |
| 2 | 向量数据库 | 专门存储和检索高维向量的数据库,使用近似最近邻(ANN)算法实现高效相似度搜索,如Milvus、Pinecone |
| 3 | Embedding (嵌入) | 将文本、图像等非结构化数据转换为高维向量的技术,使得语义相似的文本在向量空间中距离相近 |
| 4 | 混合检索 (Hybrid Search) | 结合密集向量检索(语义搜索)和稀疏向量检索(BM25关键词搜索),兼顾语义理解和精确匹配 |
| 5 | 查询重写 (Query Rewriting) | 使用大模型对用户原始查询进行优化,消除歧义、补充上下文,提升检索效果 |
| 6 | 重排序 (Reranking) | 在向量检索后,使用Cross-Encoder等模型对候选文档进行精排,提升最终结果的相关性 |
| 7 | HNSW | Hierarchical Navigable Small World,一种高效的近似最近邻索引算法,在Milvus等数据库中广泛使用 |
| 8 | 文档分块 (Chunking) | 将长文档切分为适合检索和模型上下文的小块,策略包括固定大小、语义分块、递归分块等 |
| 9 | RRF (Reciprocal Rank Fusion) | 倒数排名融合算法,用于合并多个检索源的结果,如混合检索中的向量检索和关键词检索结果 |
| 10 | HyDE (假设文档嵌入) | 让大模型生成假设答案,用该答案的向量去检索真实文档,解决查询-文档语义鸿沟问题 |
九、总结与最佳实践
9.1 核心经验总结
-
向量数据库选型:数据量<100万用Chroma快速验证,生产环境推荐Milvus(开源可控)或Pinecone(全托管),亿级以上必须分布式架构
-
检索质量优化:单纯向量相似度不够,必须结合查询重写、混合检索、重排序三阶段优化,召回率可提升30-50%
-
文档处理策略:根据文档类型选择分块策略,Markdown用层次分块,普通文本用语义分块,代码用语法感知分块
-
成本控制:使用多级缓存(本地+Redis)减少重复计算,合理设置向量维度和索引参数平衡精度与性能
-
可观测性:必须监控检索延迟、召回率、生成token数等指标,建立反馈闭环持续优化
9.2 演进路线建议
| 阶段 | 数据规模 | 技术重点 | 目标 |
|---|---|---|---|
| PoC验证 | <10万 | Chroma+简单分块 | 快速验证业务价值 |
| 生产上线 | 10万-1000万 | Milvus+混合检索+重排序 | 稳定服务,P99<200ms |
| 规模扩展 | 1000万-10亿 | Milvus集群+多级缓存 | 支持高并发,P99<100ms |
| 智能化 | 10亿+ | 知识图谱+Agentic RAG | 多跳推理,复杂问答 |