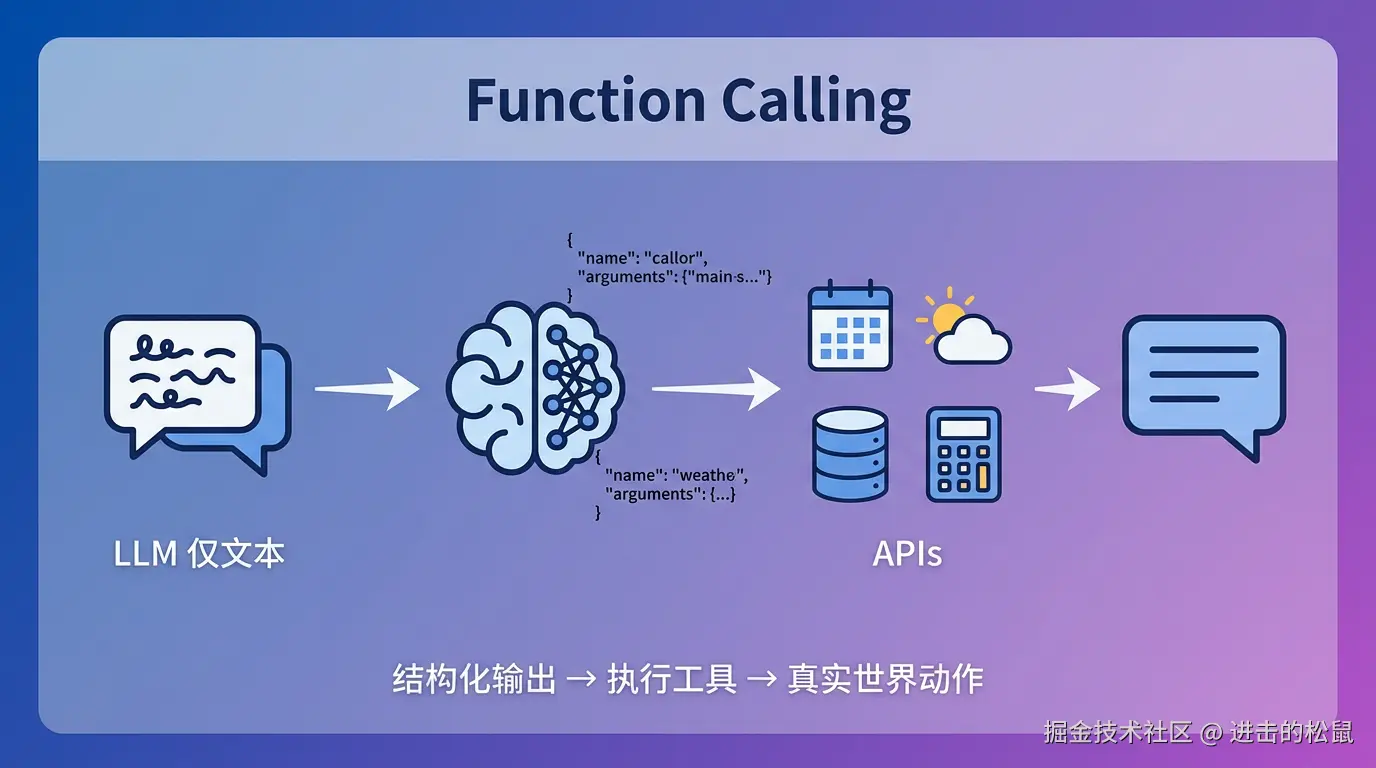
本文介绍大语言模型中的 Function Calling(函数调用 / 工具调用)的工作原理:
模型在对话中除了生成自然语言,还能在需要时以结构化方式给出要调用的函数名与参数;
由应用在本地或服务器完成真实执行 (查询、计算、调用业务接口等),再把执行结果 回传给模型用于后续回答。文章从核心闭环出发,说明它如何解决只会空谈、无法对接系统的问题。
Function Calling 产生的背景
大语言模型本身的局限性:
例如,GPT5 的模型训练的数据截止到 2025 年 8 月,在不联网的前提下,无法获取最新的信息和数据。
无法回答今天的天气怎么样这种简单的问题,尽管大模型能给出相关的文字建议,但是终究还是不能解决问题。
大模型本质是预测下一个 token,训练数据有截止日期,不能直接访问实时数据、不能可靠执行计算、也不能替你操作外部系统(发邮件、查库存、调 API)。
若只靠"编一段话",容易幻觉且无法完成真实任务。
在原生工具调用出现之前,常见做法是:
用提示词要求模型自己输出一段 JSON (函数名与参数),再由应用解析。这种方式脆弱:格式不稳定、容易夹杂废话、不同模型习惯不同,开发与排错成本高。
于是,Open AI 在 2023 年 6 月率先推出 Function Calling 功能。
让 GPT 模型可以拥有调用外部接口的能力。
什么是 Function Calling

Function Calling 本质上是:
让模型先"决定要不要调用工具",再由你的程序真正执行工具,最后把结果喂回模型继续回答。
Function Calling 让模型可以:
- 识别用户意图(比如"查北京明天天气")
- 选择合适的函数(如
getWeather(city, date)) - 生成结构化参数(JSON)
- 由你的后端真实执行函数
- 把执行结果再喂给模型,生成最终自然语言答复
所以它的核心是:模型负责理解和决策,程序负责执行和落地。
关键点:模型不会自己执行代码,它只会产出"调用意图"和参数。
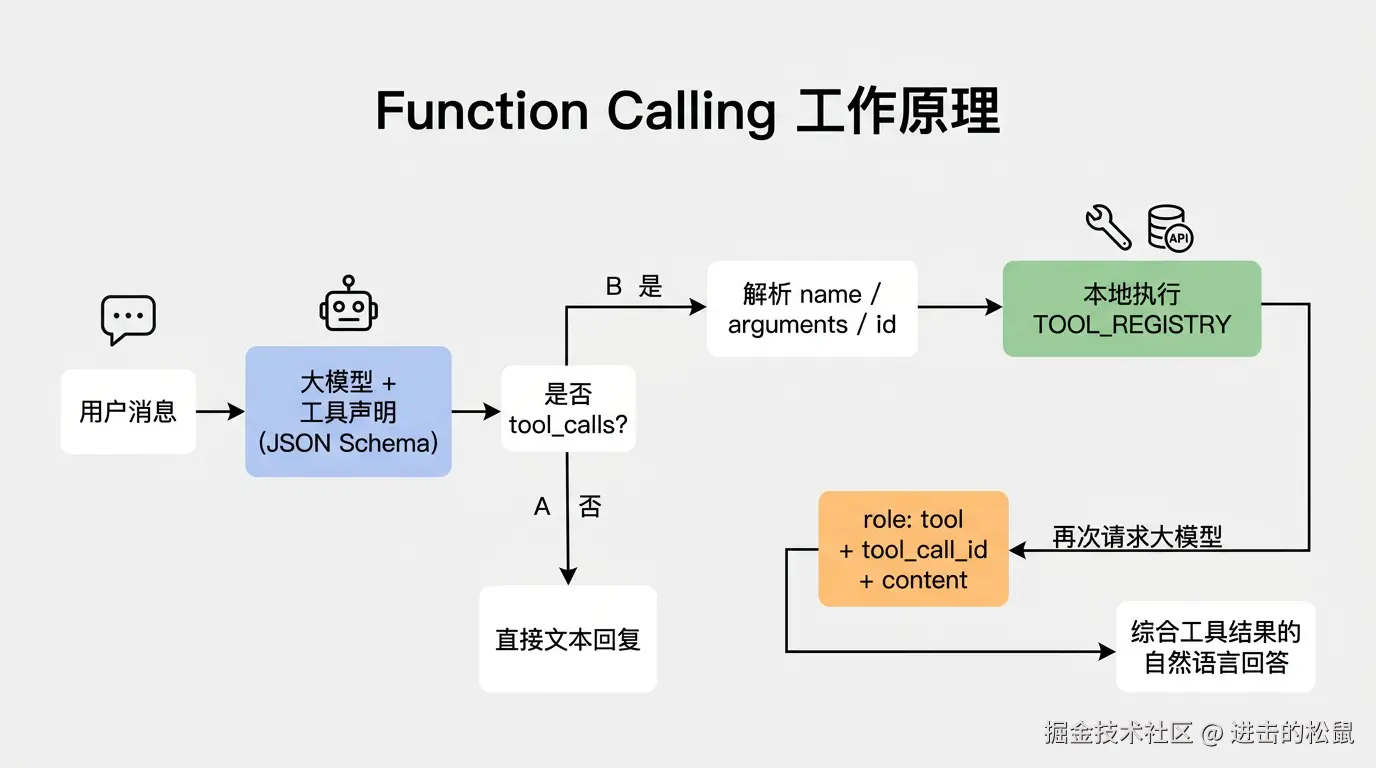
Function Calling 的工作原理
-
你先定义可用函数的"描述"(函数名、参数、参数类型、说明)
-
把用户消息 + 函数描述发给模型
-
模型判断是否需要调用函数
- 需要:返回"调用哪个函数 + 参数"
- 不需要:直接回复文本
-
你的程序收到函数调用请求,执行真实函数
-
将函数执行结果再发回模型
-
模型基于结果生成对用户的最终回答
代码示例
py
import json
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
# ---------------------------------------------------------------------------
# 1) 业务侧:真实要执行的 Python 函数(模型本身不会"直接执行",由你的代码来调)
# ---------------------------------------------------------------------------
def get_current_weather(location: str, unit: str = "celsius") -> str:
"""模拟天气查询:真实项目里这里会请求天气 API。"""
# 演示用固定返回值,便于观察整条链路
return json.dumps(
{
"location": location,
"temperature": 22,
"unit": unit,
"condition": "多云",
"humidity": 65,
},
ensure_ascii=False,
)
# 函数名 -> 本地可调用对象,按模型返回的 name 分发执行(未使用 Callable 类型注解
TOOL_REGISTRY = {
"get_current_weather": get_current_weather,
}
# ---------------------------------------------------------------------------
# 2) 给模型的「工具声明」:JSON Schema,描述有哪些函数、参数含义与类型
# 模型据此决定要不要调用、调用哪个、参数填什么
# ---------------------------------------------------------------------------
TOOLS = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "根据城市名称查询当前天气情况。",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称,例如:北京、上海。",
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "温度单位,默认摄氏度。",
},
},
"required": ["location"],
},
},
}
]
def main() -> None:
# 使用环境变量中的 Key 与 Base URL(与项目根目录 .env 一致)
api_key = os.getenv("OPENAI_API_KEY")
base_url = os.getenv("OPENAI_BASE_URL")
client = OpenAI(api_key=api_key, base_url=base_url)
messages: list[dict] = [
{"role": "user", "content": "北京现在天气怎么样?适合穿什么?"}
]
# -----------------------------------------------------------------------
# 3) 第一轮:把用户消息 + tools 发给模型
# tool_choice="auto" 表示由模型决定是否调用工具
# -----------------------------------------------------------------------
first = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=TOOLS,
tool_choice="auto",
)
# 获取模型回复,并将其添加到消息列表中
assistant_msg = first.choices[0].message
print("第一轮模型回复:", assistant_msg.model_dump())
print("============================================")
messages.append(assistant_msg.model_dump())
# 获取模型回复中的工具调用
tool_calls = assistant_msg.tool_calls
print("第一轮模型回复中的工具调用:", tool_calls)
print("============================================")
if not tool_calls:
# 模型认为不需要工具,直接输出文本(例如闲聊场景)
print(assistant_msg.content or "")
return
# -----------------------------------------------------------------------
# 4) 执行模型请求的每个工具调用,并把结果以 role=tool 写回对话
# 注意:必须带上 tool_call_id,便于服务端把结果与某次调用对应起来
# -----------------------------------------------------------------------
for call in tool_calls:
# 获取工具调用中的函数名和参数
name = call.function.name
args = json.loads(call.function.arguments or "{}")
fn = TOOL_REGISTRY.get(name)
# 调用本地函数,并获取返回结果
if fn is None:
tool_content = json.dumps(
{"error": f"未知工具: {name}"}, ensure_ascii=False
)
else:
tool_content = fn(**args)
# 将工具结果添加到消息列表中
messages.append(
{
# 工具角色,用于标识工具调用的结果
"role": "tool",
# 工具调用ID,用于将结果与调用对应
"tool_call_id": call.id,
# 工具结果,可以是字符串或JSON字符串
"content": (
tool_content
if isinstance(tool_content, str)
else json.dumps(tool_content, ensure_ascii=False)
),
}
)
print("把工具结果添加到消息列表中:", messages)
print("============================================")
# -----------------------------------------------------------------------
# 5) 第二轮:把工具执行结果一并发给模型,生成最终自然语言回答
# -----------------------------------------------------------------------
second = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=TOOLS,
tool_choice="auto",
)
final = second.choices[0].message
print("第二轮模型回复内容:", final.content or "")
if __name__ == "__main__":
main()注意点
1. 消息里 tool 角色要带 tool_call_id
因为 一次回复里可能有多个 tool_calls,服务端需要用 id 把哪次调用的结果 对齐到哪次调用,避免错乱。
2. 漏传工具结果
模型在第二轮看不到工具输出,会瞎编或重复请求。
3. Schema 与实现不一致
例如声明了必填参数但 Python 函数没该参数。
4. 未处理不调用工具
若用户纯闲聊,可能没有 tool_calls,应直接打印 assistant_msg.content(示例已分支处理)。
5. 多轮工具
可在循环里反复模型 → tool → 模型 直到不再出现 tool_calls。
6. 流式
流式响应里工具调用分段到达,需按 SDK 文档拼接完整 tool_calls 再执行。
总结
Function Calling 不是让模型自己跑代码:
而是让模型产生标准化的调用指令,由你的系统安全、可控地执行函数。
Function Calling 的本质,是把「会说话的模型 」与「能做事的系统」用一条清晰契约连接起来:
模型负责理解意图并给出可解析的调用意图,应用侧负责执行、鉴权与容错再把真实结果交回模型完成闭环。
虽然 Function Calling 是三年前的产物 ,但它确实为后续 MCP、A2A、Skill 等技术的发展奠定重要的基础。
学会 Function Calling 的原理,我们也就更容易掌握 Agent 内部的工具部分是如何运行的。