上篇文章:C++算法:哈希表(简介|两数之和|判断是否互为字符重排)
目录
1.存在重复元素
https://leetcode.cn/problems/contains-duplicate/

算法原理
和之前做的两数之和很相似,在本题中固定一个值,再将其放入哈希表中进行查值即可,也不需要运用下标。
cpp
class Solution {
public:
bool containsDuplicate(vector<int>& nums) {
unordered_set<int> hash;
for(auto x : nums)
{
if(hash.count(x)) return true;
else hash.insert(x);
}
return false;
}
};2.存在重复元素II
https://leetcode.cn/problems/contains-duplicate-ii/description/

算法原理
与上一题的区别就是,不仅要找相同数,还要判断其下标是否<=k
细节问题:当碰到相同值,并且将其放入哈希表时后面放入的值会覆盖掉之前的值,那么正确做法是什么?
观察题目要求,abs(i - j) <= k,也就是说只有下标距离很近时才能满足条件,而当前值不满足条件,那么其之后的相同数肯定也不会满足条件,因此大胆的将前数覆盖掉就好。
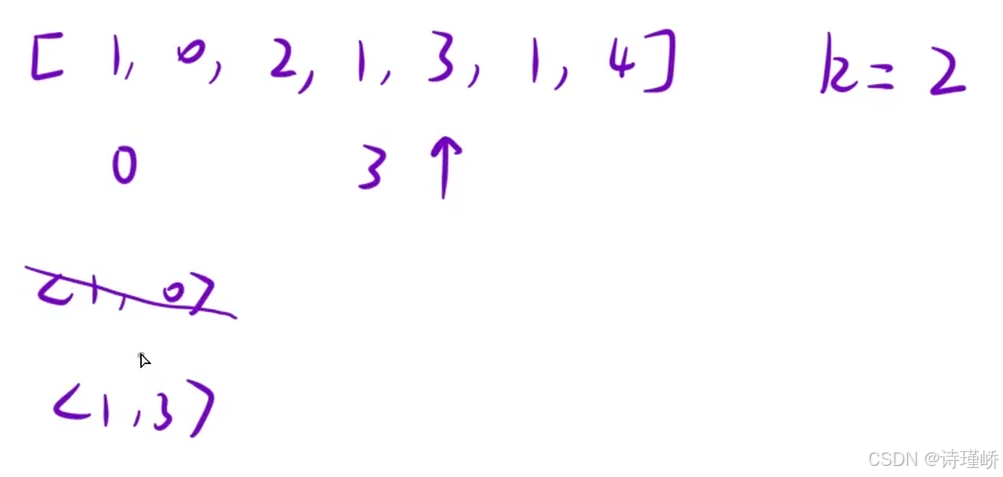
cpp
class Solution {
public:
bool containsNearbyDuplicate(vector<int>& nums, int k) {
unordered_map<int, int> hash;
for(int i = 0; i < nums.size(); i++)
{
if(hash.count(nums[i]))
{
if(i - hash[nums[i]] <= k) return true;
}
hash[nums[i]] = i;
}
return false;
}
};3.字母异位词分组
https://leetcode.cn/problems/group-anagrams/


算法原理
使用哈希表,先判断两个字符串是否是字母异位词,在之前做题中,我们使用的是hash表对其进行判断(遇到相同的字符,次数减一)。在本题中,我们可以通过排序,对其ASCII码值进行判断,也能完成排序任务。
接下来,我们需要对不同的异位词进行分组,此处,我们使用string和string数组对其进行分组,当我们遍历完第一个字符串时,先对其进行排序(排序会将其排为相同的字符串),其后进行判断,若原字符串中有,则将其接入后面,若没有,则重新创建一个数组。
cpp
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string, vector<string>> hash;
// 分组
for(auto& s : strs)
{
string tmp = s;
sort(tmp.begin(), tmp.end());
hash[tmp].push_back(s);
}
// 提取结果
vector<vector<string>> ret;
for(auto& [x, y] : hash)
{
ret.push_back(y);
}
return ret;
}
};代码中,我们只需要提取y即可,以示例一为例,其分组后的结果是:
"aet" : ["eat","tea","ate"]"ant" : ["tan","nat"]"abt" : ["bat"]
而x存储first,y存储second,因此返回y即可。
本章完。